



In express delivery, every shipment has a record. A delivery company's daily operations revolve around this shipment record. The record updates continuously from pickup to final delivery, tracking changes in transit status, exception flags, timeliness metrics, routing changes, and more.
ZTO Express (NYSE: ZTO and SEHK:2057) is one of the largest express delivery companies in Asia, handling over 35 billion packages annually (more than FedEx and UPS combined in the US market). At that scale, ZTO's shipment record table holds 4.5 billion rows, 200+ columns, and 600 million new daily records (80% of the new records, about 500 million, are updates to existing records, not new inserts).
We previously covered how ZTO built a lakehouse architecture with VeloDB, replacing Trino over HDFS for BI reporting and batch analytics. This post covers ZTO's real-time analytics pipeline and breaks down each VeloDB capability that made the difference: Merge-on-Write, partial column updates, inverted indexes, and Workload Group isolation.
Results after migrating to VeloDB:
-
60x faster point queries: Multi-dimensional filtering reduced from over 1 minute to under 1 second
-
5-10x faster aggregations: Complex analytical queries reduced from 5-10 minutes to under 1 minute
-
2x higher concurrency: Stable at 100+ concurrent queries, up from under 50
-
1/3 the hardware cost: Covering the full workload with a fraction of the original resources
Old Architecture: Struggling to Handle a Growing Workload
ZTO's shipment data infrastructure went through two generations before reaching its limits.
1. Starting with MySQL and PostgreSQL for Analytics
When data volumes were smaller, ZTO used MySQL and PostgreSQL to handle shipment record queries and management. However, as daily volumes scaled, the business needed multi-dimensional analytical queries: aggregations by time, region, status, and exception type, across hundreds of millions of records.
Transactional databases weren't built for these complex, multi-dimensional queries. ZTO experienced wasted I/O, resource contention, and high latency during complex aggregations. The team moved to a dedicated analytical database.
2. HTAP Architecture
ZTO faced two core data challenges: large data volume and an update-heavy write pattern. 80% of incoming changes to shipment records are updates to existing records, not new appends. Standard OLAP systems can't sustain that ratio of real-time updates, so the team chose an HTAP architecture: a dual-engine setup with Flink writing to a row store, which automatically synced to a columnar store for analytics.
The stack had four layers:
-
Message queue: Real-time sync of multiple core data streams
-
Flink processing: Per-table tasks handling partial column updates on the wide table
-
Storage: A single un-partitioned wide table in the HTAP database
-
Application layer: Direct queries from monitoring and analytics systems
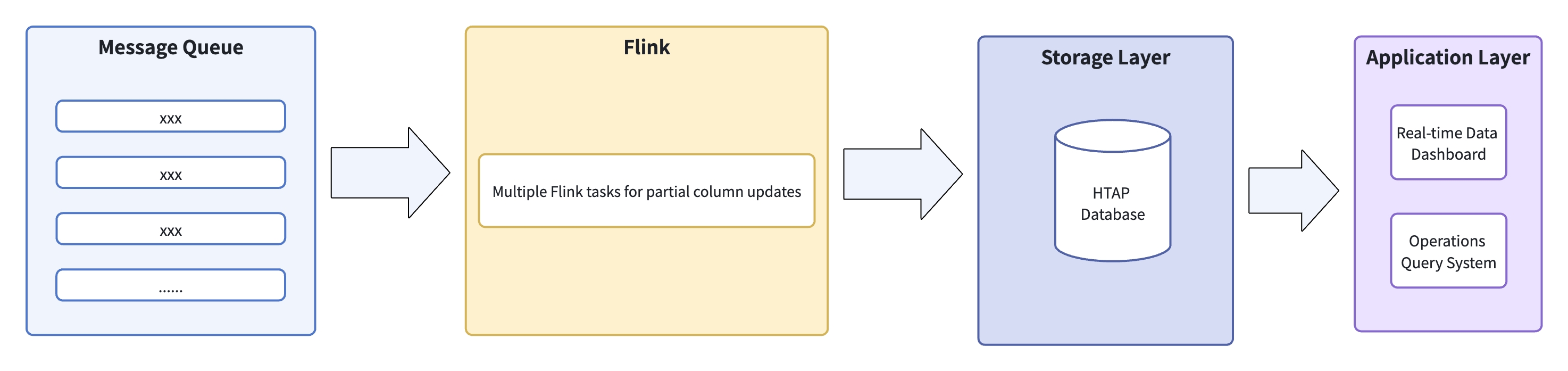
As daily volumes grew to 600 million records, this HTAP design showed its limitations:
-
Slow queries: Multi-dimensional equality filter queries took more than 1 minute to complete. Queries involving 3+ dimensions of aggregation ran 5-10 minutes per SQL statement, well outside ZTO's real-time requirement.
-
Low concurrency ceiling: During peak hours, when the number of concurrent queries exceeds 50, CPU utilization exceeds 95%, resulting in 30% of queries timing out and upstream services becoming unresponsive.
-
Resource waste: Full table scans without indexes kept CPU and I/O permanently saturated. Machines ran at 90%+ load with near-zero headroom. Disk IO saturation and CPU contention persisted even as the team added hardware.
The underlying problem was a lack of partitioning, inverted indexes, and resource isolation between workloads. Every query scanned the full table, and one expensive query could starve every other query.
Migrating to VeloDB
The ZTO team had three clear requirements when selecting their next analytics architecture:
-
Support high-frequency partial column updates
-
Support inverted index for fast multi-dimensional queries
-
High concurrency with stable, low-latency query response
VeloDB met all three. Built on Apache Doris by its core development team, VeloDB adds enterprise-grade features, fully managed cloud services, and dedicated support.
The new architecture kept Flink for data processing but replaced the analytical database with VeloDB:
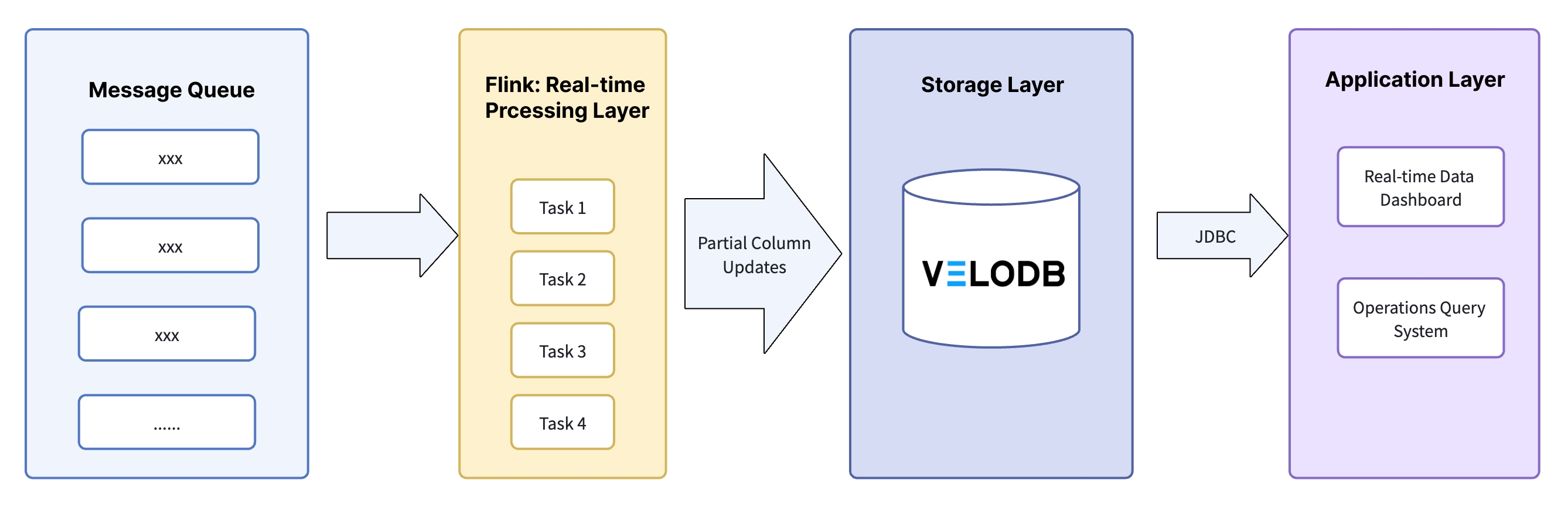
| Layer | Components | Implementation | Business Value |
|---|---|---|---|
| Data ingestion | Message queue | Queues split by business operation modules to prevent data mixing | Flink tasks consume independently; failures don't cascade across streams |
| Real-time processing | Flink (multi-task + partial column updates) | 1. One Flink task per queue2. Updates only the relevant columns in the wide table3. Checkpoints set at 30 seconds | Reduced write IO |
| Storage | VeloDB (Unique model + MOW + inverted index + Workload Group) | 1. Unique Key: business identifier + time dimension fields2. MOW: merges data at write time3. Inverted index: built on high-frequency filter fields (time, dimension IDs)4. Workload Group: resource pools by query scenario | High-frequency updates with global uniqueness guarantees, faster multi-dimensional queries, no multi-user resource contention |
| Application layer | Data monitoring and analytics systems | Direct JDBC connection, users mapped to resource groups | Independent resources per query scenario, stable latency |
Key Technical Decisions
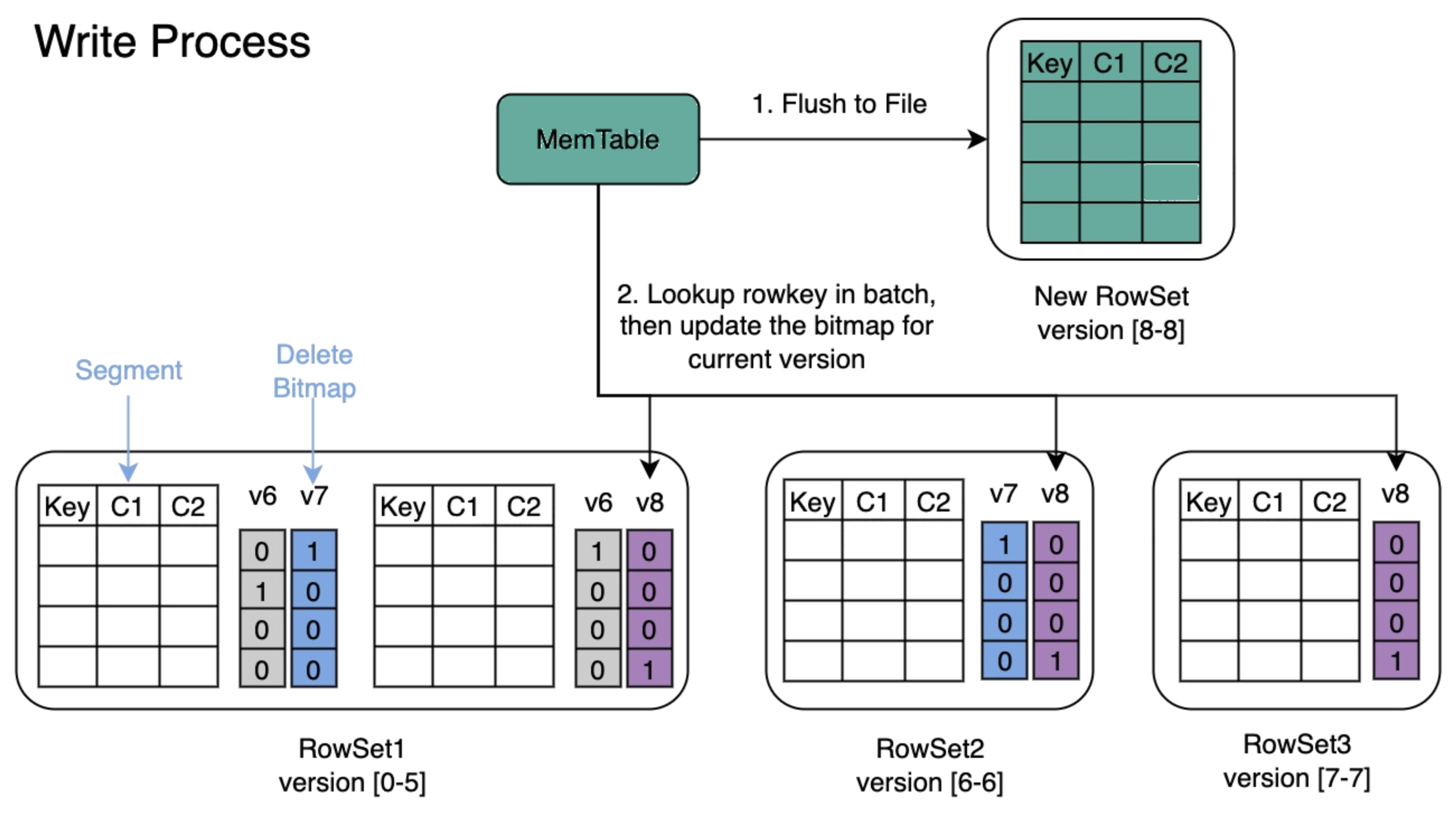
1. Merge-on-Write: Handling 500 Million Daily Updates
Each shipment record is keyed by tracking number. The same record gets updated repeatedly as a package moves through the delivery network. VeloDB's Merge-on-Write (MOW) mode handles this by merging data at write time rather than at read time, so every query returns the latest version without having to reconcile historical data on the fly.
ZTO's upstream systems updated records on a per-minute cadence. MOW eliminated the read-time overhead of traditional merge-on-read approaches and kept query latency consistent.
2. Partial Column Updates: Multi-Source Writes Without the Overhead
ZTO's data came from multiple upstream business operation modules, each responsible for its own subset of fields in the wide table. Rewriting all 200+ columns on every update would be prohibitively expensive. VeloDB's Unique Key model supports partial column updates natively: each Flink task writes only the columns it owns, without reading or rewriting the full row. This significantly cut write IO costs.
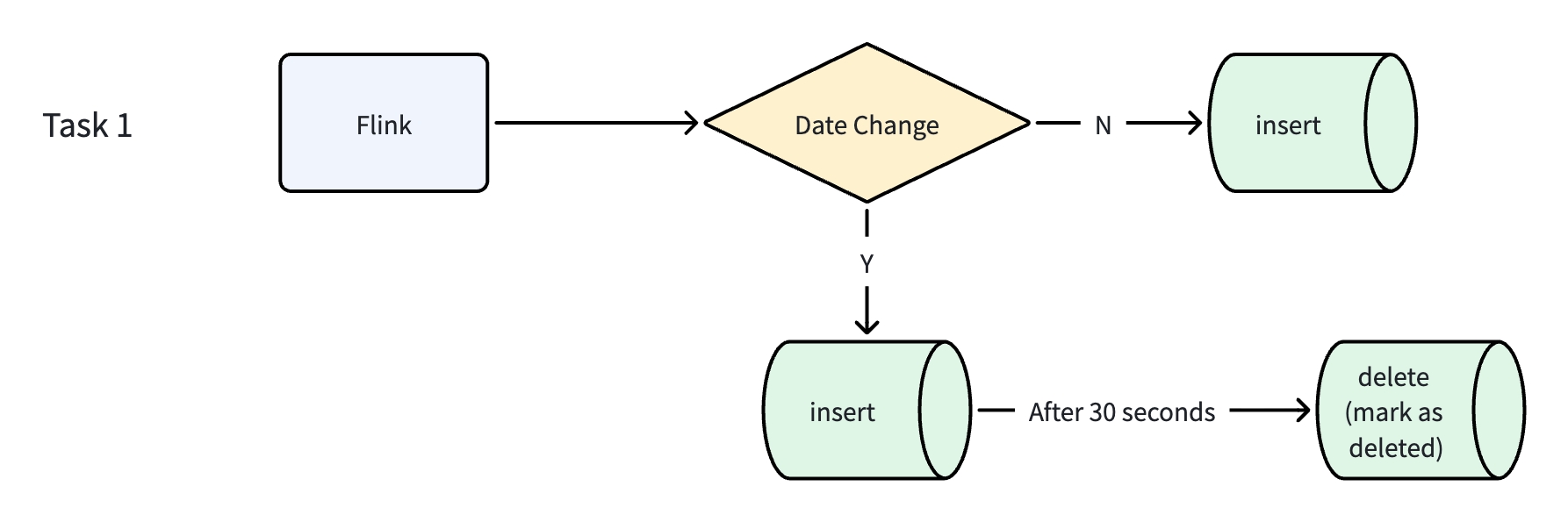
3. Unique Key Date Updates: Keeping Records Consistent
The wide table uses tracking number + time dimension fields as its Unique Key. In practice, time dimension fields occasionally need corrections, which requires updating a key component of the record's identity without creating duplicates.
The team built a dedicated Flink task to handle these changes:
-
Flink reads incoming changes to time dimension fields in real time and checks whether the target record's time field has changed.
-
If no change: a standard INSERT writes the data normally.
-
If there is a change, an INSERT writes the new record with the updated time dimension fields. After 30 seconds, a delete marks the old record (with the original time fields) as removed.
This kept the table globally consistent while supporting the dynamic key updates that ZTO's operations require.
4. Inverted Index: Multi-Dimensional Queries on a 200-Column Table
The wide table has 200+ columns. The most common queries involve filtering by time, dimension IDs, and status fields, then aggregating across multiple metrics. Without indexing, every query required a full table scan.
The team built inverted indexes on the high-frequency filter fields to support real-time monitoring, multi-dimensional analytics, and precise filtering queries. The index maps field values (e.g., dimension_id='xxx', status='xxx') directly to row addresses, so VeloDB skips to relevant rows instead of scanning the full table. The same index also accelerates date range filters (e.g., time_col >= '2025-12-01' AND time_col < '2026-01-01').
Multi-dimensional equality filter queries dropped from over 1 minute to under 1 second, a 60x improvement. Multi-dimensional aggregations dropped from 5-10 minutes to under 60 seconds.
5. Workload Group: Resource Isolation Under High Concurrency
Before the migration, a heavy query from one team could consume enough CPU to trigger timeouts for everyone else. VeloDB's Workload Group mechanism solved this by assigning users to isolated resource pools, each with its own CPU weight and concurrency limit.
With Workload Group isolation:
-
Latency variance for critical queries dropped from ±3 seconds to ±1 second
-
Timeout rate for critical queries dropped from 30% to under 5%
Results
The before/after across the metrics the team tracked:
| Metric | Previous Architecture | New Architecture |
|---|---|---|
| Multi-dimensional equality filter queries | > 1 minute | < 1 second |
| Multi-dimensional aggregation queries | 5-10 minutes | < 60 seconds |
| Concurrent queries supported (critical workloads) | < 50 | > 100 |
| Critical query timeout rate | 30%, latency variance ±3s | ≤5%, latency variance ±1s |
| Hardware footprint | Required continuous expansion | Covers full workload on 1/3 the original hardware |
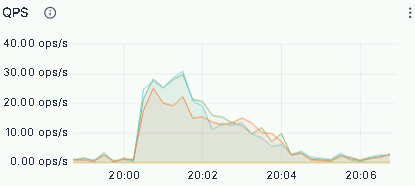
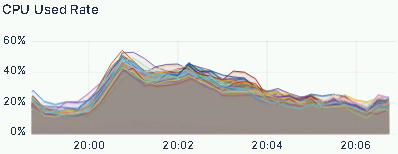
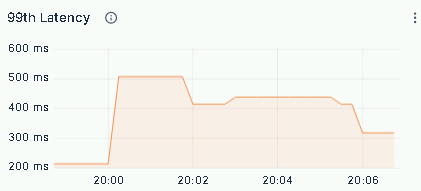
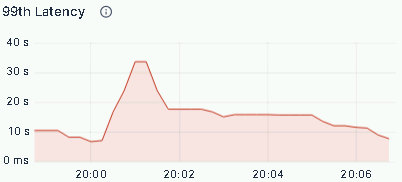
The ZTO team also ran peak load tests, tracking QPS, CPU utilization, and P99 latency for critical queries:
-
QPS peaked above 80 requests/second with no request queuing
-
CPU utilization remained flat throughout, with no spikes
-
P99 latency: equality filters held at milliseconds; aggregations stayed consistently under 1 minute
Summary
Three changes drove most of the improvement:
-
Write layer: Partial column updates combined with MOW handled ZTO's 80% update-heavy write pattern. Multi-source data from different business modules now lands in the wide table with events visible in queries within seconds (down from minutes) and lower write IO.
-
Storage layer: Tracking number + time dimension fields as the Unique Key guarantees global record uniqueness and supports dynamic key corrections. Data stays consistent across the full shipment lifecycle.
-
Query layer: Inverted indexes on high-frequency filter fields cut multi-dimensional query times from minutes to seconds. Workload Group isolation eliminated cross-user CPU contention and brought critical query timeouts down from 30% to under 5%.
The result: ZTO's 4.5-billion-row, 200-column shipment table now handles 500 million daily updates with real-time visibility, low-latency analytics, and fine-grained resource control. All at a third of the original hardware cost.
Interested in building a similar architecture? VeloDB brings Apache Doris to production with enterprise-grade reliability and support. To connect with other users, join the Apache Doris community.


