


This article is based on a Doris Summit 2025 presentation by Vadim Apolovsky, Senior Data Engineer at DXC Technology.
Vadim Apolovsky built Social Sentry, a real-time AI alerting system, with Apache Doris, Kafka, Spark, and Claude Code. The same architecture applies to any high-volume event stream that needs AI enrichment, real-time scoring, threshold-based alerting, and historical retention for BI or model retraining.
Social Sentry helps schools monitor public social media posts and catch warning signs of safety incidents (aggression, self-harm, threats of violence) before they escalate.
The system pipeline design:
-
Data ingestion: public social posts from students participating in an opt-in school monitoring program
-
Data processing: filters and pre-scores posts for aggression signals
-
AI Enrichment: Sends suspicious posts to AI models for deeper text and image sentiment analysis
-
Scoring: Each post scores 1–5 points based on which enrichment layer processed it (regex = 1, local LLM = 3, Azure AI = up to 5), and the rolling score uses a 24-hour sliding window with decay, so older posts lose weight over time.
-
Alerting and Notification: Triggers real-time alerts to police, teachers, or counselors when a score crosses a threshold
The goal is prevention, not surveillance. When a student's rolling score hits 10 points, the notification service pages the right people before something bad happens.
The question Vadim wanted to answer: could Apache Doris sit at the center of a system like this, without spending weeks on a traditional POC? Using Claude Code with Spec-Driven Development (via the open-source SpecKit), he went from an architecture sketch to a running MVP in under 30 minutes, then validated the design against real code and real data within a week.
This post covers the full Social Sentry architecture, why Apache Doris became the real-time backend data store and the Claude Code + SpecKit workflow used to prototype it.
The Challenges: Why Streaming AI Pipelines Are Hard
Streaming AI pipelines look clean on paper. They get complicated fast in practice. Social Sentry ran into four problems, and any one of them could break the alerting path.
Unstable throughput and latency: Social media post volume spikes in the mornings and evenings. When the system detects a potentially dangerous post, it needs to reach the alerting layer immediately. During peak hours, that high-priority post gets stuck behind a flood of low-priority ones. It's an ambulance in traffic: fast on its own, but only if the road is clear.
External AI services impose rate limits and can fail: The pipeline depends on Azure AI for text sentiment and a separate image processor for visual content. When either hits a quota ceiling or goes down, cascading timeouts ripple through the enrichment layer, and critical posts stop getting scored.
Event delivery and consistency: Most Kafka consumers default to at-least-once delivery, so duplicate messages are common after crashes and recoveries. In a risk-scoring system, a duplicate post inflates a student's aggression score and can trigger a false alert.
Three AI services return three different schemas: The project uses three enrichment services (Azure AI, the self-hosted LLM, and the regex classifier), each producing a different response format. Downstream consumers need a consistent format, and those formats drift as models get updated. Without a schema contract, every model update risks breaking the pipeline.
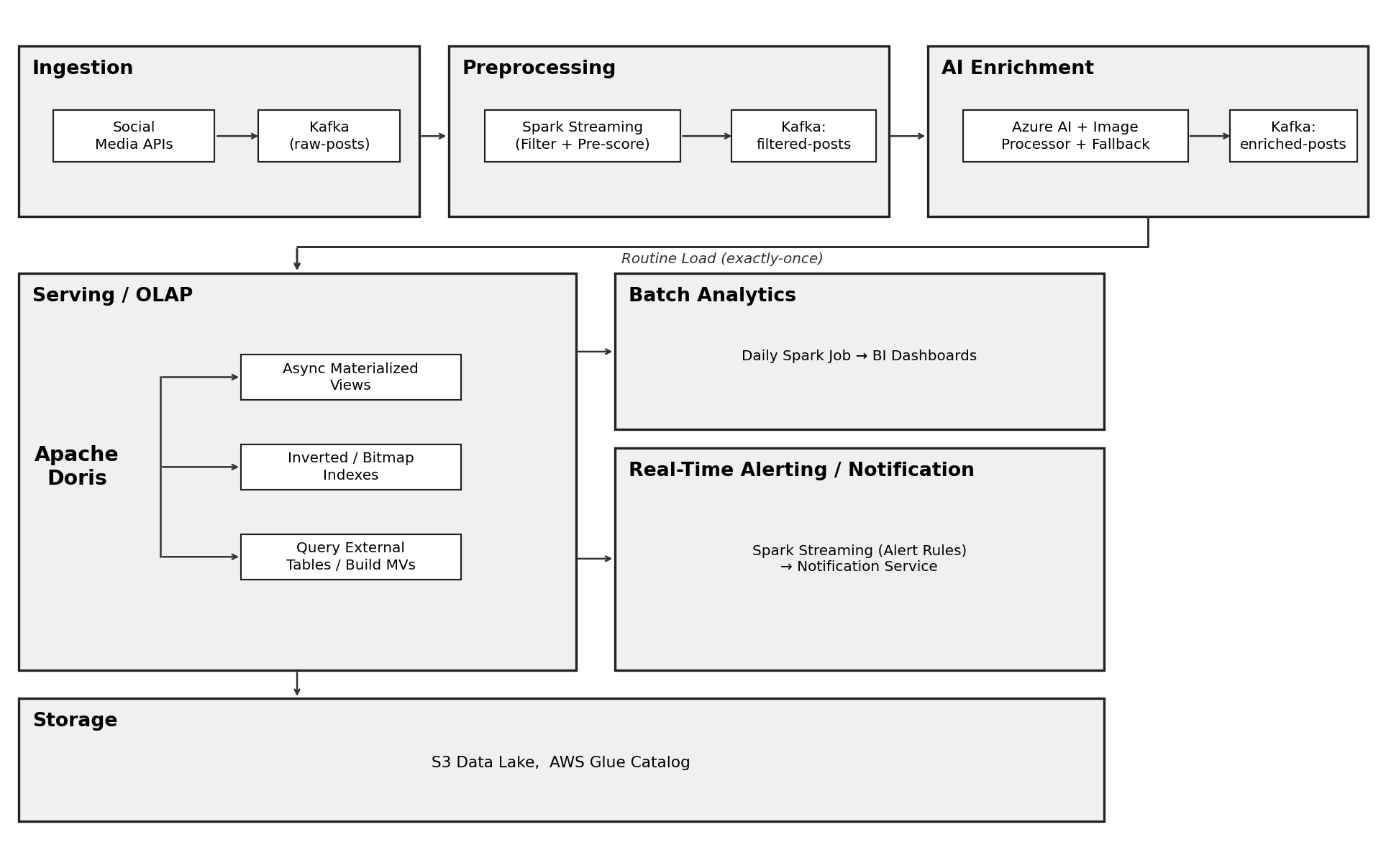
The Architecture: A Streaming Pipeline with Apache Doris at the Core
The full architecture has six layers. Apache Doris handles the most critical one: real-time serving and alerting.
1. Ingestion with Kafka
Backend connectors pull posts from Twitter, Instagram, and Facebook and publish them to Kafka. For large payloads like images or videos, the raw content goes to S3 and only the reference link lands on Kafka. This keeps the message bus lightweight and the storage cost predictable.
2. Pre-filtering with Spark Streaming
Spark Streaming (Flink works here too) applies keyword filters and programmatic pre-scoring. Obvious safe posts get routed directly to historical storage for batch analytics. Posts that might indicate risk get forwarded to AI enrichment. This early filter cuts the load on expensive AI services downstream.
3. AI Enrichment with a Multi-Level Fallback
This is where external dependencies become a liability. The fix is a multi-level fallback that keeps high-priority posts moving even when the primary is unavailable.
-
Primary: Azure AI Language for full-text sentiment and opinion mining. A separate image processor handles visual content.
-
Secondary: A self-hosted local LLM (a smaller BERT-family model). A health monitor checks the rate limit every 30 seconds. When usage crosses 80 percent of the quota, traffic automatically shifts to the local model.
-
Backup: A Redis embeddings cache. When the same post text reappears (retweets, reposts), the cached embedding is used directly, skipping the model call entirely.
-
Emergency: Regex-based pattern matching. Lower accuracy, but zero dependency on any model. Kicks in when every other layer is unavailable.
Rate limits and outages might degrade enrichment quality, but they never stop the system from processing high-risk posts.
4. Priority Routing with RabbitMQ
Not all enriched posts deserve the same urgency. A post flagged as dangerous needs to reach the alerting layer immediately, even during a traffic spike. RabbitMQ's priority queue handles this natively: high-priority messages jump ahead regardless of arrival order.
5. Real-Time Serving with Apache Doris
Apache Doris sits at the core of the system. Every other component feeds into it, and the alerting decision happens inside Doris. Below are four critical capabilities that supports this system:
-
Routine Load with deduplicated ingestion is the first reason Doris fit. Routine Load is the built-in Kafka connector for Doris. Strictly speaking, it delivers at-least-once, but Doris reaches the same end result by deduplicating with Unique Key at the storage layer. Duplicate posts get collapsed before they can inflate a student's risk score, so the at-least-once default that ships with most Kafka consumers stops being a problem.
-
The Unique Key model adds another guarantee. With sequence columns and partial updates, the stored record always reflects the latest enriched version of each post, even when scoring services finish out of order.
-
Asynchronous materialized views and indexes keep query latency low. Materialized views pre-compute scores, so the notification service can check thresholds without running a full aggregation on every query. Inverted indexes accelerate searches over post text. Bitmap indexes filter across dimensions like student ID or risk level.
-
Schema drift handling lets the system absorb format changes without table locks or downtime. The more immediate schema-consistency problem (three AI services returning three different formats) gets handled upstream: an agent-to-agent (A2A) protocol standardizes output before data reaches Doris.
6. Batch Storage and Notification
Historical posts land in S3 as Parquet files, cataloged by AWS Glue for batch analytics and BI dashboards. A notification service watches the Doris score tables and triggers alerts to teachers or counselors when a student's rolling risk score crosses the threshold.
Prototyping the MVP in 30 Minutes with Claude Code
Vadim built the Social Sentry MVP in under 30 minutes using Claude Code and Spec-Driven Development via SpecKit, an open-source tool.
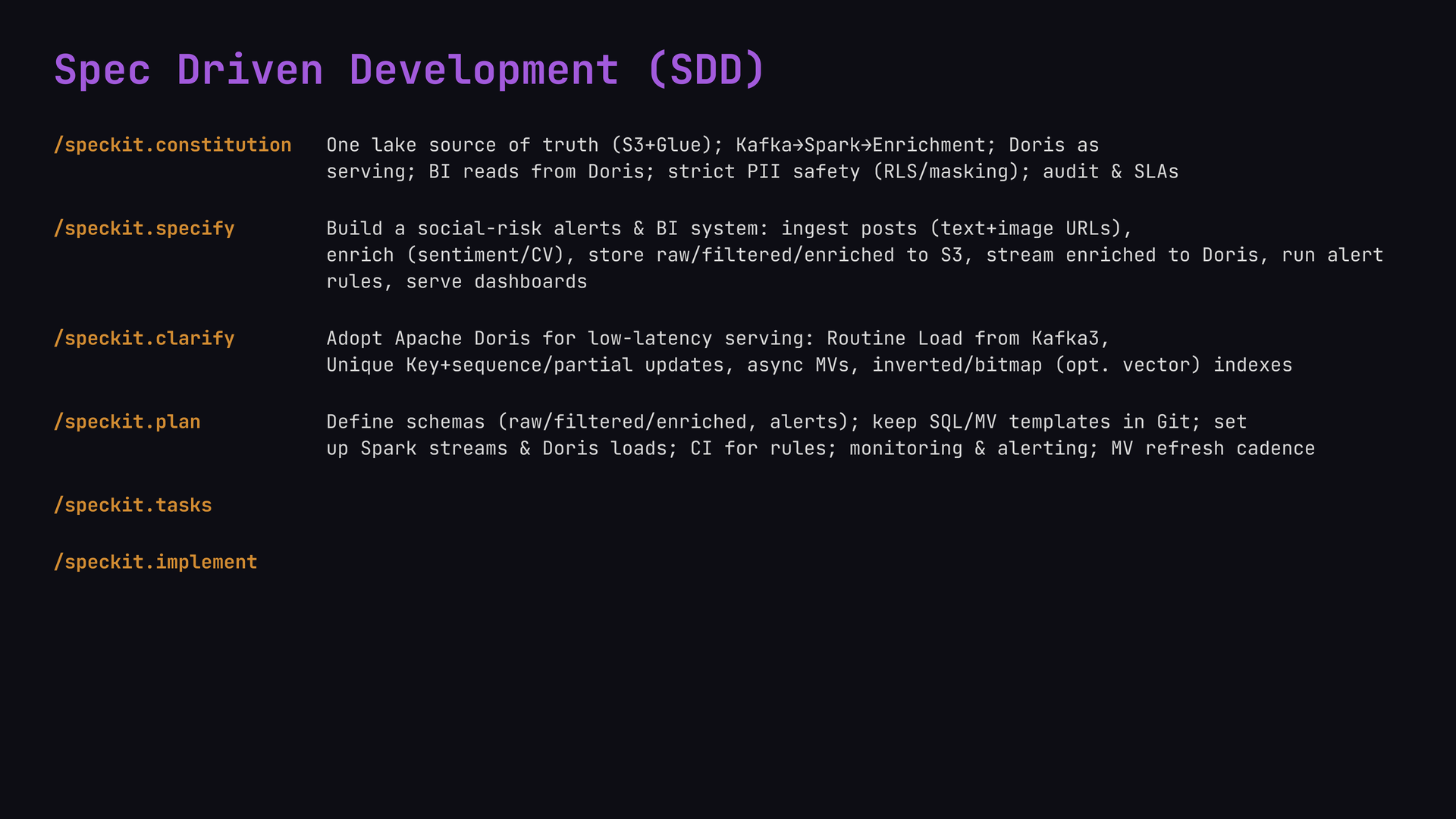
Prompt-driven coding with an AI agent drifts. A vague prompt like "build me a social sentiment pipeline" produces inconsistent code, security gaps, and architecture that doesn't match what you need. Spec-Driven Development fixes this by walking the agent through a sequence of named stages, each producing a strict, versioned document. The agent reads each stage's output as input to the next, so context stays grounded in written artifacts rather than chat memory.
SpecKit exposes this as six slash commands inside Claude Code:
-
/speckit.constitution sets the non-negotiable rules: one lake source of truth (S3+Glue), Kafka→Spark→Enrichment, Apache Doris as serving layer, BI reads from Doris, strict PII safety, audit and SLAs. The output is a constitution.md with seven core principles, architecture constraints, and governance rules. Everything that follows has to align to this document.
-
/speckit.specify turns the idea into a formal spec. Vadim gave it a short description: build a social-risk alerts and BI system that ingests posts with text and image URLs, enriches via sentiment and computer vision, stores raw/filtered/enriched data to S3, streams enriched data to Apache Doris, runs alert rules, and serves dashboards. The output had three user stories, 15 functional requirements, seven success criteria, and six edge cases with behavior descriptions.
-
/speckit.clarify refines ambiguous design decisions without rewriting the spec from scratch. It was used to lock in the Apache Doris design: Routine Load from Kafka, Unique Key with sequence and partial updates, async materialized views, inverted and bitmap indexes. The command appended a timestamped clarifications section to the spec rather than overwriting it, so the decision trail stays auditable.
-
/speckit.plan converts the spec into a technical implementation plan: plan.md, research.md with tech decisions, data-model.md with entities and data flow, an OpenAPI 3.0 contract, quickstart.md, and CLAUDE.md as context for the implementation phase.
-
/speckit.tasks breaks the plan into 60-plus implementation tasks, ready to import into Jira or Confluence, with dependency markers and flags for parallel work.
-
/speckit.implement writes the actual code. Claude Code offered four scoping options (Full MVP at 66 tasks, Phase 1 only, Skeleton stubs, or Custom scope) and generated a working prototype ready to test against a real Doris cluster, without weeks of setup.
The result is a runnable codebase, not a production deployment, but complete enough to load real data into Apache Doris, run real queries, and pressure-test the architecture. If it holds up, the same spec becomes the foundation for the production build. If it doesn't, you've lost an afternoon, not a quarter.
Summary
Two takeaways from the Social Sentry project:
-
Apache Doris handles the full set of demands for a real-time AI alerting pipeline: deduplicated ingestion from Kafka, fast queries for the alerting path, and schema flexibility as the system evolves. You don't need to bolt on a separate system for each one.
-
Spec-Driven Development with Claude Code takes the friction out of the POC stage. The constitution and spec documents become durable artifacts. The MVP validates the architecture in days, not quarters. And if the architecture works, the same documents drive the production build.
For teams building something similar, join the Apache Doris Slack community to compare notes on Routine Load, materialized views, and exactly-once ingestion patterns.


