ZTO Express is one of the largest express delivery companies in Asia, handling more than 35 billion packages annually and with a 20% local market share. To put its scale in perspective, ZTO delivers more packages per year than FedEx and UPS combined in the US market.
As the logistics industry in Asia grows rapidly, ZTO's original Hadoop-based data warehouse (with Trino as the query engine) struggled to keep pace. As data volume and business needs evolve, the data architecture began to show its limits. Queries are slowing down, real-time data freshness can't be achieved, and the system had trouble handling concurrency. These issues are a blocker for ZTO's core requirement for real-time tracking, reporting and operations across its massive delivery network.
In order to address the requirements for real-time analytics at scale with high concurrency, ZTO decided to adopt Apache Doris, offered through VeloDB.
The results of the transformation were significant:
-
10x faster queries: 90% of analytics tasks reduced from ~10 minutes to under 1 minute
-
2,000+ QPS for concurrent point queries in offline analytics
-
67% cost savings compared to their previous Trino-based analytics, resulting in using only 1/3 of the original hardware.
We will now dive deeper into ZTO's journey from their legacy architecture to a VeloDB-powered lakehouse, covering the challenges they faced, their technology selection process, and detailed use cases in BI reporting and real-time analytics.
Challenge with Hadoop and Trino
Before adopting VeloDB, ZTO relied on a Hadoop-based on-prem data warehouse to handle its analytics needs. As data volume grows and the business demands more real-time and high-concurrent processing, this architecture faced several challenges:
-
Poor data freshness: The T+1 data extraction model of the on-prem data warehouse could not meet the real-time update requirements for dashboards and reports.
-
Slow query performance: Data is written in batches by Spark and queried by Trino, leading to latency of minutes or even 10 minutes. The architecture itself was never suited for real-time.
-
Weak query stability and concurrency: At the scale of ZTO's Hadoop cluster, even minor NameNode fluctuations could seriously affect the stability of ad-hoc queries and report analysis. Trino's performance under high-concurrency queries also fell far below expectations, struggling to meet growing demands.
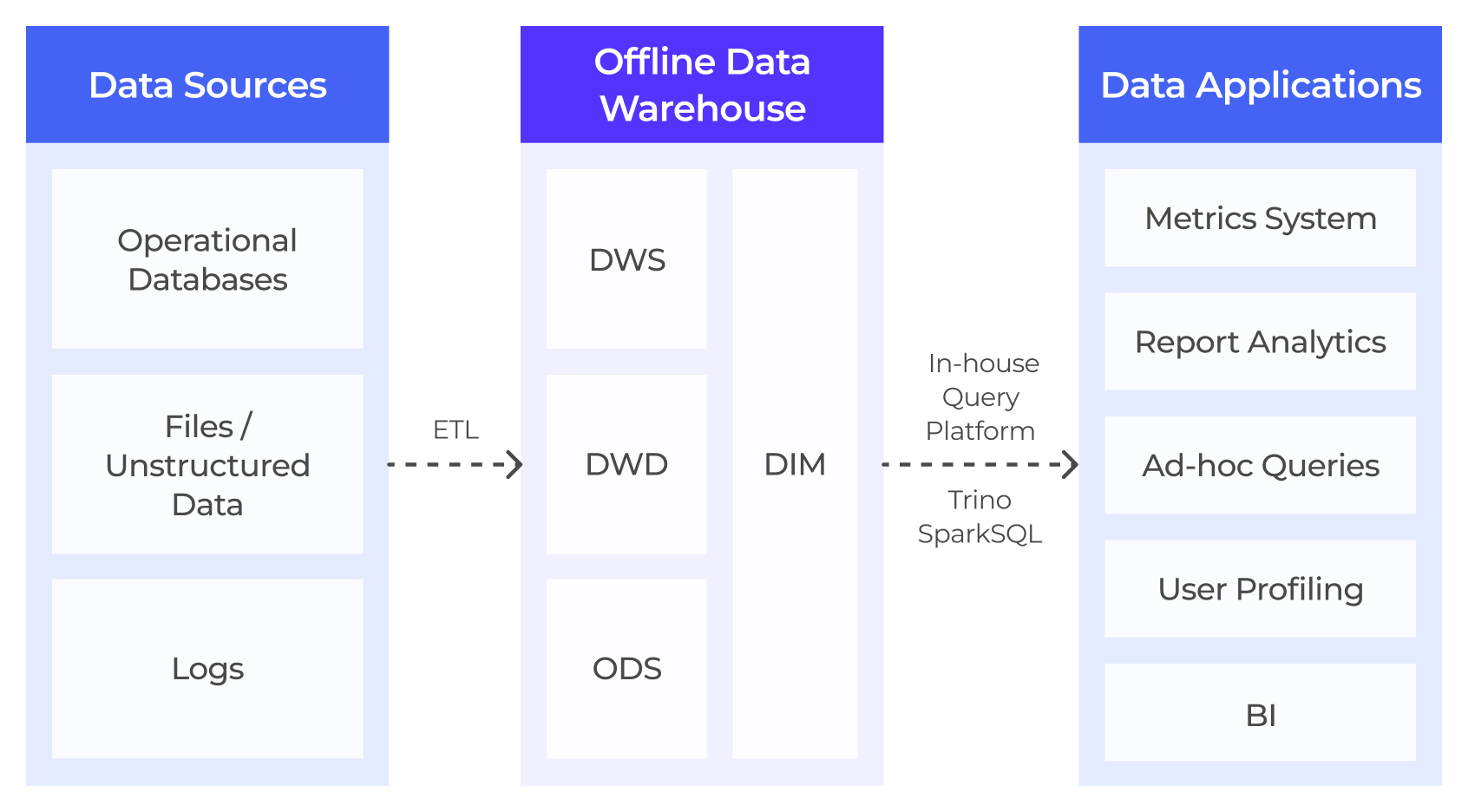
Building a Lakehouse for High Concurrency and Real-Time Analytical Performance
As ZTO's business grew alongside Asia's e-commerce shopping events, what was once peak-day volume (like Singles' Day, a Black Friday-like event in Asia) became a daily reality. To meet real-time analytics requirements across various scenarios and ensure fast data ingestion and efficient queries, ZTO needed a suitable OLAP engine to complement its existing architecture.
Performance Requirement Technology Selection
After in-depth research and testing, ZTO's technical team selected VeloDB, a real-time search and analytics database built on Apache Doris. VeloDB stood out for its vectorized engine, pipeline execution model, comprehensive caching mechanisms, MySQL-compatible SQL syntax, and flexible open lakehouse architecture
To validate VeloDB's high-performance query capabilities, the team at ZTO ran multiple rounds of comparative testing:
-
In production SQL tests with 100GB single-table queries, VeloDB showed 1-2x performance improvement over Trino.
-
In the 1TB TPC-DS benchmark, VeloDB completed all 99 queries in just 1/5 of the time of Trino
ZTO's New Lakehouse Architecture with VeloDB
With VeloDB at its core, ZTO built a new lakehouse analytics architecture, using VeloDB as a unified, high-performance query engine layered on top of their data lake. The data remains cataloged in the Hive Metadata Store (HMS), with the data persisting in ZTO's existing HDFS storage.
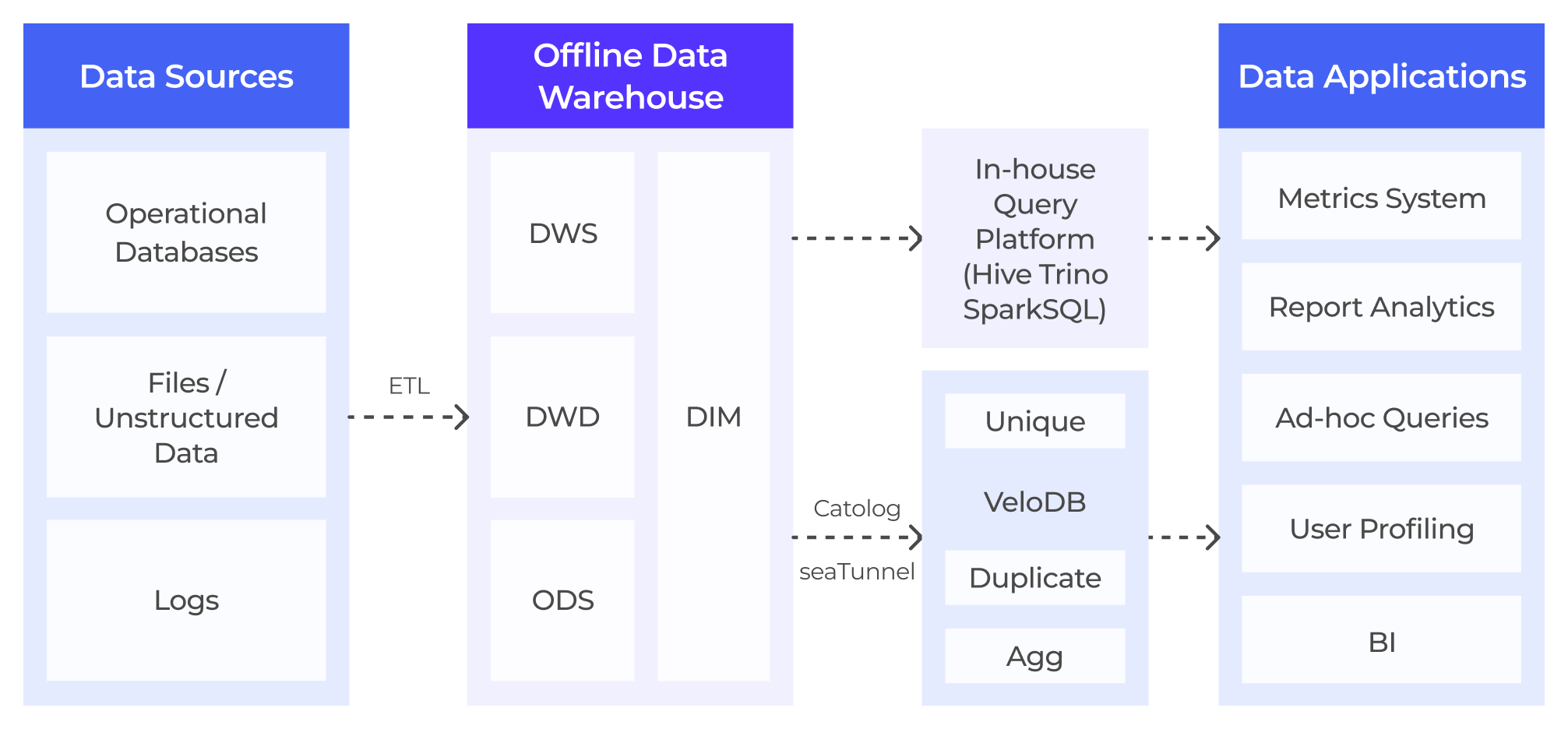
VeloDB connects directly to Hive Metastore and can create external tables in ZTO's existing data lake without data migration, enabling direct, high-speed queries on Hive tables. To further improve query performance, ZTO extensively leveraged VeloDB's caching acceleration, data prefetching, indexes, and partitioning/bucketing capabilities, ensuring system stability and query efficiency.
One comparison puts VeloDB's efficiency in perspective: ZTO's Trino cluster runs on 130+ nodes and handles daily peak traffic of 560,000 queries. VeloDB uses just 60 nodes across three clusters, yet handles 900,000 queries at peak. That's VeloDB handling 60% more queries with less than half the hardware.
ZTO's Main Use Cases and Specific Challenges Solved by VeloDB
1. BI Reporting and Ad-Hoc Analytics
In BI reporting and ad-hoc analytics scenarios, ZTO's original Trino architecture faced two challenges: poor query stability and concurrency bottlenecks. During morning peak hours, when many business users accessed the reporting system at the same time, they often experienced query timeouts and system slowdowns. Trino showed significant performance degradation between expected and actual performance under high-concurrency queries.
To address query stability and timeout issues, ZTO enabled the Data Cache feature in VeloDB, using large-capacity local SSDs to persistently cache hot data. After daily data preparation, scheduled jobs are triggered to preload critical report data, ensuring it is cached locally before business peak hours. This precaching avoids high query latency and bandwidth saturation during morning peaks. Under the same query volumes, VeloDB's slow queries (>10s) were just 1% of Trino's.
To address high-concurrency challenges, ZTO wrote offline DIM dimension and application layer data into VeloDB via SeaTunnel, accelerating query performance on result tables. This helps achieve 2,000+ concurrent QPS point queries, significantly improving the timeliness of data report updates.
2. Real-Time Data Analytics
Real-time dashboards for executive decision-making and operational monitoring demand extremely low query latency and high data freshness, as well as support for flexible multidimensional filtering and aggregation. ZTO needs sub-minute level near real-time analysis on a super-wide table with 200+ columns, daily updates exceeding 600 million rows, in a table with over 4.5 billion rows. The original OLAP engine struggled to guarantee task execution timeliness under heavy load. For example, when the total concurrency exceeded 50, execution times reached 5-10 minutes
Here is how VeloDB successfully addressed the requirement for data freshness under heavy currency
Query acceleration: Inverted indexes were added to text-heavy tables for search acceleration and BloomFilter were also used for multi-dimensional analysis. Combined with proper table partitioning and bucketing to filter unnecessary data during queries, Over 90% of queries were reduced from around 10 minutes to under 1 minute, with some achieving sub-second performance, a 10x improvement.
Sub-second data freshness: VeloDB supports Unique Key tables with comprehensive support for Upsert, conditional update/delete, partial column updates, and partition overwrite operations, allowing for fast writes and instant read after. Combined with Flink, data becomes visible within seconds, meeting both efficient and flexible data-update requirements.
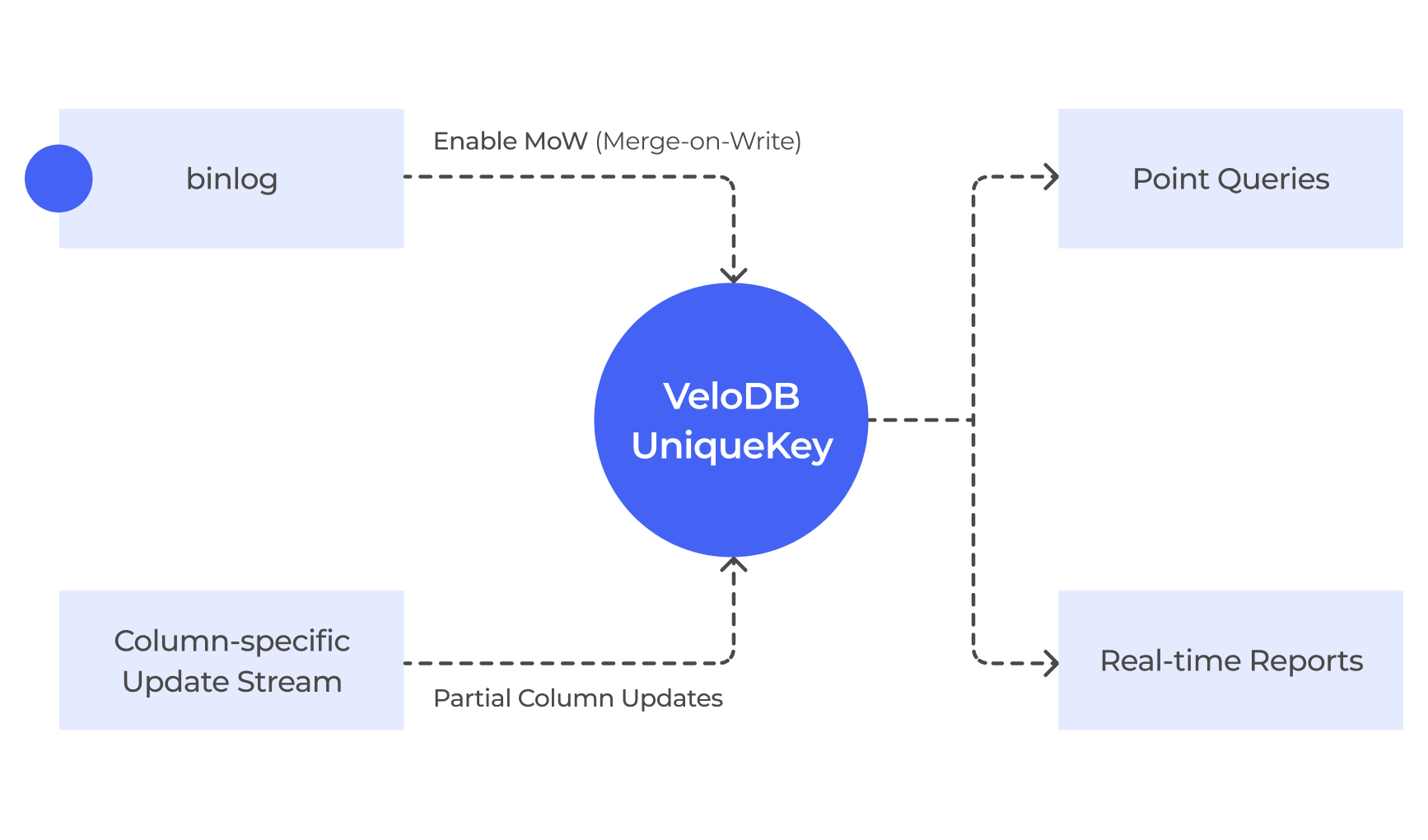
Note: Table structure design should be tailored to the business. Plan Key and partition/bucket columns carefully. Typically, columns used in WHERE conditions or JOINs are suitable for bucketing.
In this scenario, VeloDB met all business requirements with just 1/3 of the original cluster resources, delivering data that is both fast and accurate while saving costs.
Results and Future Plans
After adopting VeloDB, ZTO achieved significant improvements in query performance, with dramatically reduced latency, increased concurrency, significant cost savings, and better system stability and maintainability.
Looking ahead, ZTO plans to deepen their collaboration with VeloDB:
-
Improving usability: Leveraging VeloDB's refined, intuitive Profile information to reduce SQL tuning difficulty and complexity, improving development and operations efficiency.
-
Enhancing observability: Strengthening observability for features like file caching, improving data skew handling capabilities, and enhancing overall system reliability and maintainability.
-
Deepening lakehouse integration: Expanding Multi-Catalog functionality, improving lakehouse analytics capabilities, and testing VeloDB's ability to read and write Hive external tables for more flexible data flow.
-
Unified permissions and integration: Enabling Hive Catalog permission passthrough via JDBC accounts, seamlessly integrating with the company's existing big data permission system to ensure data security.
Want to learn more about VeloDB and its lakehouse capability? Contact the VeloDB team, or join the Apache Doris community on Slack and connect with Doris experts and users.