- Products
- Solutions
Real-Time Analytics
Sub-second dashboards and data products on petabytes of data at any concurrency
Data Warehousing
Sub-second analytics on open lakehouse formats with no vendor lock-in
Observability in the AI Era
The most cost-effective alternative to Elasticsearch observability
Context Engineering
Hybrid search and fresh context for RAG, agents, and LLMs
- Docs
- Resources
- Pricing
- Contact us



Real-Time
Analytics
on VeloDB
Ship interactive dashboards and data products that respond in milliseconds, on petabytes of data, at any concurrency.
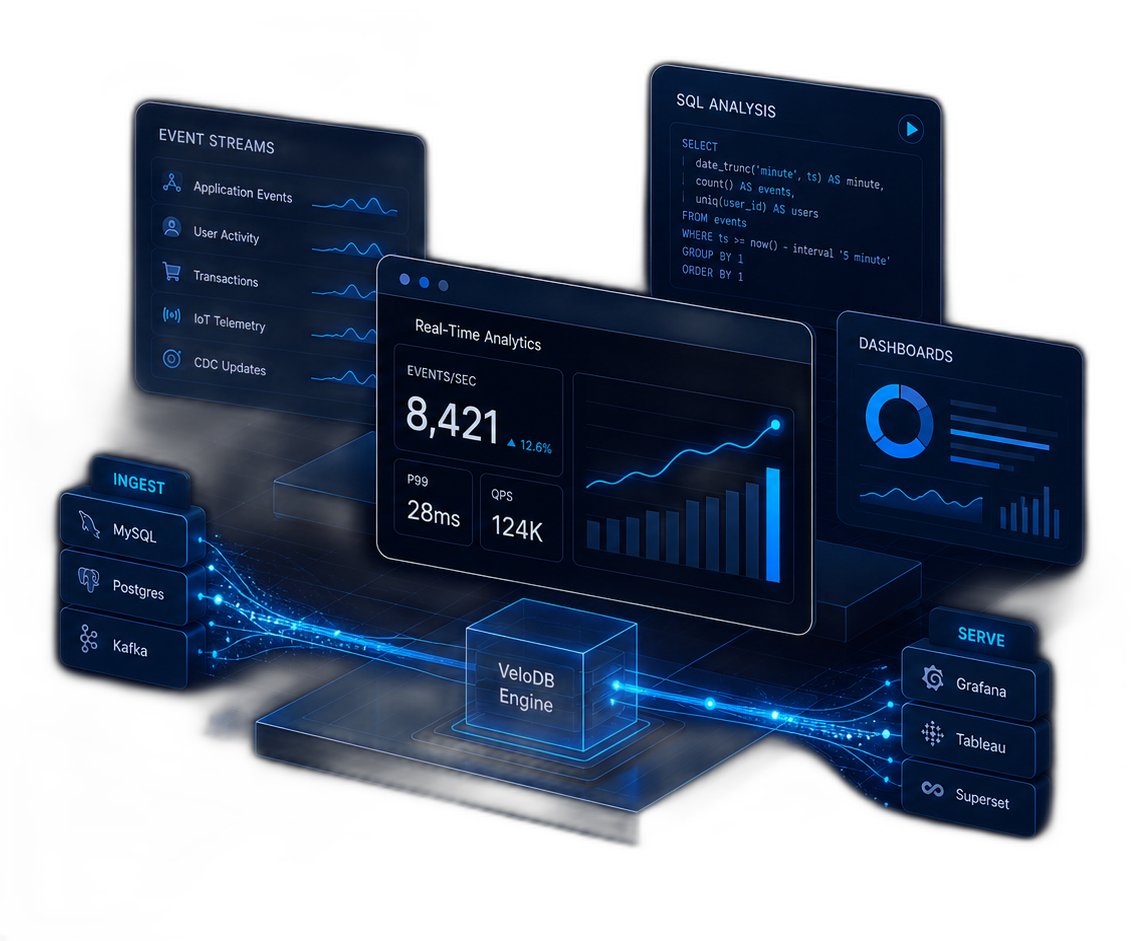
Real-time isn't a feature
It's how you win
Faster and better decisions made the moment the problem appears, not hours after it does
Industry leaders run on VeloDB
Kwai unified trillion-scale ad analytics on a single engine, replacing ClickHouse and Elasticsearch.
“We dropped slow query rate from 35% to under 5% and reduced point query latency from 250ms to 12ms. Real-time campaign attribution across 4,000 query templates and 700 fields now runs on one engine instead of three.”
Challenges with real-time
analytics at scale
VeloDB for real-time analytics
Ingest fresh events and CDC changes, keep mutable records current, transform data with materialized views, and run live SQL joins from one unified engine.
Deep dives and
customer stories
Technical blogs, integration guides, and real-world case studies for every part of the real-time analytics stack.
Stop choosing between
fresh and fast.
Spin up a VeloDB Cloud cluster in under 60 seconds and run your first sub-second query on real-time data.