- Products
- Solutions
Real-Time Analytics
Sub-second dashboards and data products on petabytes of data at any concurrency
Data Warehousing
Sub-second analytics on open lakehouse formats with no vendor lock-in
Observability in the AI Era
The most cost-effective alternative to Elasticsearch observability
Context Engineering
Hybrid search and fresh context for RAG, agents, and LLMs
- Docs
- Resources
- Pricing
- Contact us



Context Engineering
on VeloDB
Store vectors, full-text, structured data, and JSON in one database. Retrieve with hybrid search and fusion re-ranking. Serve fresh context to LLMs and agents in milliseconds.
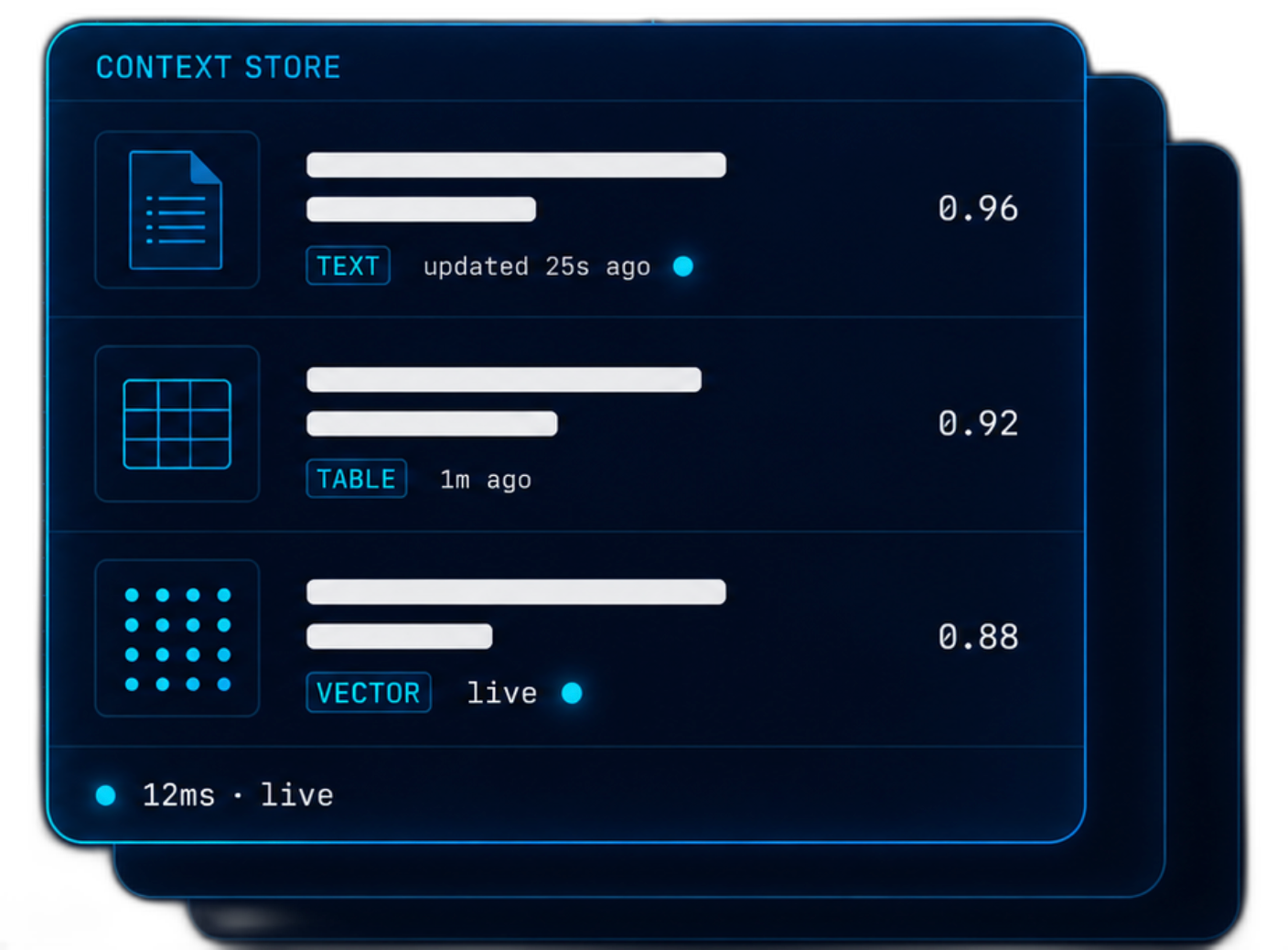
Context that's
fresh
Retrieval that's accurate
The quality of every AI answer depends on the context behind it. VeloDB keeps that context fresh, stores it all in one place, and retrieves exactly what matters
AI teams run on VeloDB
ByteDance searches 1 billion vectors for talent matching with 94% relevance, up from 58% on pure vector search, at 400ms latency.
“Per-segment BM25 caused ranking instability on every segment merge. Global statistics in Doris 4.0 with progressive filtering fixed it. Relevance jumped from 58% to 94%. Latency dropped from 2.8 seconds to 400 milliseconds. Storage shrank from 10TB on 20 servers to 500GB on a single server.”
Challenges building
production RAG and agents
VeloDB for generative AI
Ingest documents, transactional records, and event streams. Embed and chunk incrementally. Store vectors, text, structured metadata, JSON, and labels in one engine. Retrieve and rank via progressive filtering. Serve fresh context to LLMs and agents.
Deep dives and
customer stories
Technical blogs, integration guides, benchmarks, and real-world case studies for every part of the context store and GenAI stack.
Stop juggling four systems.
Run your context on one.
Spin up VeloDB Cloud in under 60 seconds and run hybrid search across vectors, text, structured data, and JSON in a single SQL query.