TL;DR: Apache Doris combines vector search, full-text search, and structured analytics into a single SQL engine, offering a hybrid search and anlytical processing infrastructure solution for AI-related workloads.
Data analytics is changing fast in the AI era. In the past, databases mostly served human analysts, powering dashboards and ad-hoc queries. But today's databases must also serve AI agents and agent-facing systems. This often means LLMs query databases directly.
These agents are far more demanding: they require fresh, real-time data, unified access to structured and unstructured data and embeddings, and high-throughput data processing.
Traditional analytical data systems struggle to meet the dynamic demands of AI workloads. They are too slow, too single-purpose (whether keyword-based or vector-based), and too fragmented. AI workloads such as RAG and others need a unified way to search, filter, and analyze multimodal data with millisecond-level latency.
This is why we built Apache Doris 4.0 with Hybrid Search and Analytical Processing (HSAP): combining vector search, full-text search, and structured analytics in a single SQL engine with a single execution model.
In this article, we take a deep dive into why hybrid search is necessary, how hybrid search works in Apache Doris using ANN indexes and inverted indexes, and how to use hybrid search in practical demos.
Why Do We Need Hybrid Search in the AI Era
1. The Challenges of Multi-System Architectures
Many teams adopt a stitched multi-system architecture that combines a vector database + search engine + OLAP database to support hybrid search and analytics workloads. While this approach can approximate hybrid search capabilities, it introduces many challenges:
- Data duplication and complex ETL pipelines: Text, vector, and analytical systems each maintain their own copies of the data in different formats. Any update must be synchronized across systems, which increases latency, operational complexity, and maintenance costs.
- Long query paths and high latency: A single hybrid query often involves multiple hops, for example, recalling candidates from a vector database, filtering them in a search engine, and finally aggregating results in an OLAP system. This multi-stage execution dramatically increases end-to-end latency compared to running everything in a single engine.
- Data inconsistency: Data is written to different systems at different times, meaning search results and structured analytics may be based on different data versions. This inconsistency undermines result reliability and makes it hard to ensure stable behavior for AI agents.
- No unified query planning or scheduling: Each system has its own optimizer and execution model. There is no global query plan, and optimizations such as shared filtering, partition pruning, or index pushdown cannot be coordinated across systems.
Together, these issues create the so-called “data silo” effect. Hybrid queries that should be executed in a single pass are instead fragmented into multiple stages, increasing complexity and making it difficult to meet the strict latency requirements of RAG, agent-based systems, and recommendation workloads.
2. HSAP: Hybrid Search and Analytical Processing for AI Applications
Compared to a fragmented multi-system approach, Hybrid Search and Analytical Processing (HSAP) represents a more effective modern approach. HSAP enables structured analytics, full-text search, and vector search to run within a single engine, offering a unified optimizer and execution framework.
| Capabilities | DocDB | VectorDB | OLAP | HSAP |
|---|---|---|---|---|
| Fast Structured Analytics | ❌ | ❌ | ✅ | ✅ |
| Strong Text Search | ✅ | ❌ | ❌ | ✅ |
| ANN Vector Search | ❌ | ✅ | ❌ | ✅ |
| Unified Optimizer | ❌ | ❌ | ❌ | ✅ |
| Single Source of Truth | ❌ | ❌ | ❌ | ✅ |
Under the HSAP model, different retrieval systems no longer operate in isolation. Instead, one unified system can meet the demands for semantic recall, precise keyword matching, and structured filtering. In practice, HSAP queries follow a streamlined and highly efficient execution pattern:
A. Single Query Request
Users submit a single query that can enable text search, vector similarity search, and complex analytical logic such as filtering, aggregation, and sorting. All of these requirements are expressed in SQL and compiled into one unified execution plan.
B. Parallel Execution
The system executes multiple search workloads in parallel:
- Full-text search runs on inverted indexes, performing keyword matching and BM25-based ranking.
- Vector search runs on ANN indexes to retrieve semantically similar results, with structured predicates applied consistently as either pre-filters (to reduce the candidate set) or post-filters (to refine retrieved results).
This parallel, pushdown-based execution model ensures that overall latency is bounded by the slowest individual search path, rather than by the cumulative latency of chained calls across multiple systems, fundamentally improving query efficiency.
C. Result Fusion and Analytics
Once each search path produces its Top-K results, the engine applies Reciprocal Rank Fusion (RRF) to generate a unified ranking. It then leverages the OLAP engine’s analytical capabilities to perform complex aggregations and detail queries, returning complete analytical results directly to the user.
3. Building Hybrid Search and Analytical Processing (HSAP) in Apache Doris
While the HSAP model provides a strong conceptual foundation, making it a reality in Apache Doris required dedicated engineering. By unifying the storage format, execution engine, and SQL workflow, Apache Doris integrates structured analytics, inverted indexes, and vector indexes into a single system, enabling efficient hybrid search and real-time analytics.
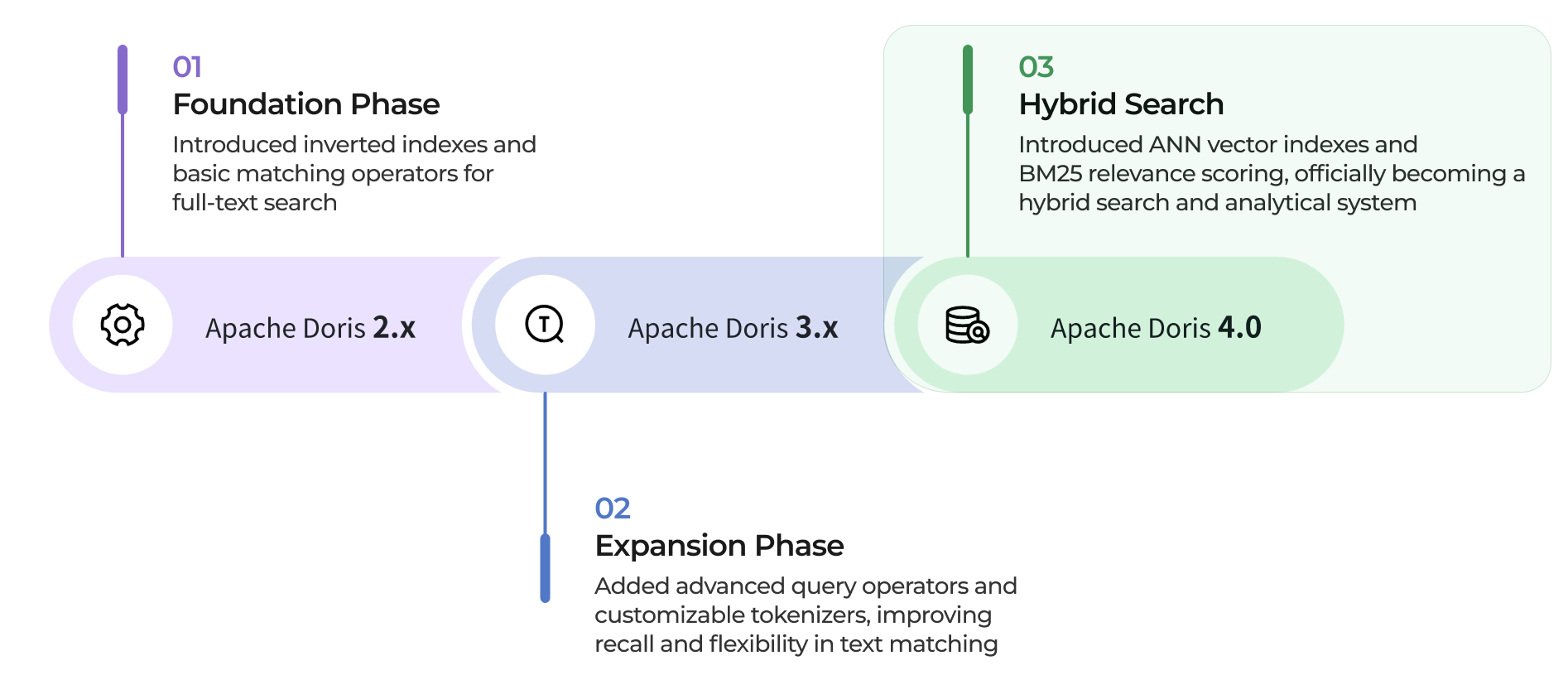
Below is a high-level view of this evolution. In the sections that follow, we will dive deeper into the core HSAP features in Apache Doris, recommended best practices, and real-world performance results:
- Apache Doris 2.x: Foundation phase. Introduced inverted indexes and basic matching operators, enabling high-performance full-text search.
- Apache Doris 3.x: Capability expansion. Added advanced query operators and customizable tokenizers, significantly improving recall and flexibility in text matching.
- Apache Doris 4.0: Hybrid Search. Introduced ANN vector indexes and BM25 relevance scoring, officially evolving into a hybrid search and analytical system that treats text and vector search as equal citizens.
How Does Apache Doris Enable Efficient Hybrid Search and Analytical Processing
Apache Doris adopts a pre-filtering + virtual column pushdown execution framework for hybrid search, allowing full-text search, vector search, and structured operators to be executed efficiently within a unified engine.
Optimizing Pre-filtering Performance
Pre-filtering is a common execution model in hybrid search: the system first applies structured predicates to narrow down candidate rows from a large dataset, and then performs similarity calculations or relevance scoring on the filtered results. The main performance risk of this model is obvious: if the underlying engine cannot filter massive datasets efficiently, pre-filtering quickly becomes the bottleneck of the entire query.
And this is where Apache Doris excels. Its core execution capabilities are designed to eliminate this bottleneck:
- Partition and bucket pruning: During query planning, the optimizer in Apache Doris automatically applies partition and bucket pruning based on query predicates, ensuring that only relevant tablets are scanned. This significantly reduces the amount of data scanned per query.
- Index-accelerated filtering: Apache Doris employs a multi-layer indexing system, including built-in indexes (such as zone maps, prefix indexes, and sort keys) and secondary indexes (such as inverted and Bloom filter indexes). These indexes allow the engine to quickly determine whether a data block can match the query predicates, skipping large amounts of irrelevant data before scanning.
- Pipeline and vectorized execution engine: Apache Doris fully leverages multi-core CPU parallelism and memory locality, significantly increasing operator throughput and query concurrency. This ensures that pre-filtering remains fast even at scale, enabling hybrid search queries to execute efficiently.
Virtual Columns Mechanism
In traditional architectures, relevance scoring for text search and similarity calculations for vector search are often computed multiple times, both at the scan layer and again at upper aggregation or merge nodes. Apache Doris 4.0 introduces a virtual column mechanism to eliminate this redundancy.
During query planning, the frontend (FE) maps scoring and distance functions to virtual columns and pushes their computation down to the scan nodes. These virtual columns are computed directly during index filtering and carried forward as part of the scan results. As a result, upper execution layers only need to perform result fusion and sorting, significantly reducing CPU overhead and data movement.
Late Materialization for Top-N Queries
Both text relevance scoring and vector similarity search typically follow a classic Top-N query pattern, such as: SELECT ... FROM tableX ORDER BY score ASC/DESC LIMIT N
At a large data scale, traditional execution plans require scanning and sorting entire rows across the entire dataset, leading to excessive data reads and severe read amplification.
To address this, Apache Doris introduces a late materialization strategy that executes Top-N queries in two efficient phases:
- Phase one reads only the sorting column (e.g., score or distance) along with row identifiers or primary keys, and quickly selects the Top-N matching rows.
- Phase two fetches full row data only for those selected rows using the row identifiers.
This approach dramatically reduces unnecessary column reads. In wide-table scenarios with small LIMIT values, it can improve Top-N query performance by more than 10x.
Demo: Apache Doris and Hybrid Search with Real-World Data
To evaluate the hybrid search performance of Apache Doris on real-world data, we're doing a test using the publicly available Hacker News dataset. This dataset includes structured fields, text fields, and vector embeddings, making it an ideal example for validating the unified HSAP engine in Apache Doris.
Benchmark Setup and Dataset
We conducted a complete end-to-end evaluation in an AWS environment, covering the full pipeline from data ingestion to RRF-based hybrid queries. The goal is to assess Apache Doris’s performance when combining semantic search, full-text search, and structured filtering in a single query.
Hardware
- AWS EC2 instance: m6i.8xlarge (32 vCPUs, 128 GiB memory)
- Single-node deployment of Apache Doris 4.0.1
Dataset
- Source: Public Hacker News dataset
- Scale: 28.74 million records
- Vector dimension: 384 (generated using the all-MiniLM-L6-v2 model)
- Field types (examples):
- Text:
text,title - Structured:
time,post_score - Vector:
vector
- Text:
Table Schema and Index Design
Apache Doris supports defining inverted indexes and vector indexes in the same table, enabling doing “text + vector + structured” queries within a unified engine.
CREATE TABLE hackernews (
id INT NOT NULL,
text STRING,
title STRING,
vector ARRAY<FLOAT> NOT NULL,
time DATETIME,
post_score INT,
dead TINYINT,
deleted TINYINT,
INDEX ann_vector (`vector`) USING ANN PROPERTIES (
"index_type"="hnsw",
"metric_type"="l2_distance",
"dim"="384",
"quantizer"="flat",
"ef_construction"="512"
),
INDEX text_idx (`text`) USING INVERTED PROPERTIES("parser"="english", "support_phrase"="true"),
INDEX title_idx (`title`) USING INVERTED PROPERTIES("parser"="english", "support_phrase"="true")
)
ENGINE=OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS 4
PROPERTIES("replication_num"="1");
- The
textandtitlefields are used for full-text search and are indexed using English analyzers with inverted indexes. - The
vectorfield is used for ANN search and is indexed with a vector index:"index_type" = "hnsw": uses the HNSW algorithm for approximate nearest neighbor search."dim" = "384": must exactly match the output dimension of the all-MiniLM-L6-v2 model."quantizer" = "flat": Uses floating-point quantization to maximize recall accuracy. In memory-constrained scenarios, this can be replaced with sq8 (scalar quantization)."ef_construction" = "512": Sets a high search bound during index construction, investing more resources to build a denser, higher-quality graph, which improves recall during query time.
Data Ingestion
Data is ingested directly from local Parquet files using Apache Doris’s INSERT INTO ... FROM local() feature
INSERT INTO hackernews
SELECT
id,
doc_id,
`text`,
`vector`,
CAST(`node_info` AS JSON) AS nodeinfo,
metadata,
CAST(`type` AS TINYINT),
`by`,
`time`,
`title`,
post_score,
CAST(`dead` AS TINYINT),
CAST(`deleted` AS TINYINT),
`length`
FROM local(
"file_path" = "hackernews_part_1_of_1.parquet",
"backend_id" = "1762257097281", -- Replace with the actual BE node ID.
"format" = "parquet"
);
RRF-Based Hybrid Query
In hybrid search, both text relevance and semantic similarity must be considered. A common way to combine these two is through the Reciprocal Rank Fusion (RRF) algorithm.
Below is an example SQL query in Apache Doris that implements RRF to fuse results from full-text search and vector search.
WITH
text_raw AS (
SELECT id, score() AS bm25
FROM hackernews
WHERE (`text` MATCH_PHRASE 'hybird search'
OR `title` MATCH_PHRASE 'hybird search')
AND dead = 0 AND deleted = 0
ORDER BY score() DESC
LIMIT 1000
),
vec_raw AS (
SELECT id, l2_distance_approximate(`vector`, [0.12, 0.08, ...]) AS dist
FROM hackernews
ORDER BY dist ASC
LIMIT 1000
),
text_rank AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY bm25 DESC) AS r_text FROM text_raw
),
vec_rank AS (
SELECT id, ROW_NUMBER() OVER (ORDER BY dist ASC) AS r_vec FROM vec_raw
),
fused AS (
SELECT id, SUM(1.0/(60 + rank)) AS rrf_score
FROM (
SELECT id, r_text AS rank FROM text_rank
UNION ALL
SELECT id, r_vec AS rank FROM vec_rank
) t
GROUP BY id
ORDER BY rrf_score DESC
LIMIT 20
)
SELECT f.id, h.title, h.text, f.rrf_score
FROM fused f JOIN hackernews h ON h.id = f.id
ORDER BY f.rrf_score DESC;
Query Execution Flow
- Parallel retrieval: The inverted index and the ANN index run independently, performing BM25-based text retrieval and L2-distance vector retrieval in parallel.
- Local ranking: Each index calculates its own internal ranking.
- Fusion scoring: The RRF formula
1 / (k + rank)is applied to combine text and semantic results. - Final table lookup: Only the Top-K results are joined back to the base table to retrieve full document content, minimizing unnecessary data access.
Query Test Performance
Using the same environment, we ran a practical benchmark to evaluate the hybrid search and analytical performance of Apache Doris. The query used “hybrid search” as a keyword. The query combined text retrieval, vector retrieval, and RRF-based fusion in a single request. The results showed an end-to-end query latency of just 65.83 ms, showing Apache Doris' ability to efficiently handle complex hybrid queries.
==================================================================================================================================
id | title | rrf_score | text_snippet
----------------------------------------------------------------------------------------------------------------------------------
845652 | Google Bing Hybrid Search - badabingle | 0.026010 | beendonebefore: thenewguy: Sure it steals google an...
2199216 | | 0.017510 | citricsquid:FYI DDG just uses the bing API and then ...
2593213 | Ask HN:Why there's no Regular Expression search... | 0.016390 | bluegene: What's keeping Google/other search engines...
6931880 | Introducing Advanced Search | 0.016390 | mecredis:
3038364 | Bing Using Adaptive Search | 0.016120 | brandignity:
1727739 | | 0.016120 | pavs:I think the name is the only thing that is wron...
18453472 | AdaSearch: A Successive Elimination Approach to... | 0.015870 | jonbaer:
1727788 | | 0.015870 | epi0Bauqu:It's a hybrid engine. I do my own crawling...
2390509 | Reinventing the classic search model | 0.015620 | justnearme:
2199325 | | 0.015380 | epi0Bauqu:FYI: no, actually we are a hybrid search e...
26328758 | Brave buys a search engine, promises no trackin... | 0.015150 | samizdis: jerf: "The service will, eventually,...
325246 | Future of Search Won’t Be Incremental | 0.015150 | qhoxie:
3067986 | Concept-Based Search - Enter the Interllective | 0.014920 | hendler:
3709259 | Google Search: Change is Coming | 0.014920 | Steveism: victork2: Well Google, a word of warning ...
10009267 | Hulbee – A Safe, Smart, Innovative Search Engine | 0.014700 | doener: captaincrunch: My previous comment didn...
1119177 | Elastic Search - You Know, for Search | 0.014700 | yungchin:
4485350 | | 0.014490 | ChuckMcM:Heh, perhaps.<p>DDG is a great product, we ...
23476454 | | 0.014490 | Multicomp:AstroGrep! ronjouch: BareGrep! For live&#x...
7381459 | HTML5 Incremental Search | 0.014280 | ultimatedelman:
4485488 | | 0.014280 | epi0Bauqu:Hmm, we're (DDG) not a search engine? Come...
==================================================================================================================================
How Vector Search Works in Apache Doris: Semantic Search with ANN Indexes
As semantic embeddings become ubiquitous in AI and retrieval workloads, vector search has emerged as a foundational database capability. In Apache Doris 4.0, vector indexes are integrated into the unified indexing framework, allowing vector search to work seamlessly alongside structured filtering and full-text search within the same execution engine. This update enables Apache Doris to perform efficient, controllable, and scalable semantic searches.
Building vector indexes is typically compute-intensive, especially at the scale of hundreds of millions or billions of embeddings. Apache Doris addresses this by adopting a unified architecture for vector and inverted indexes. Vector indexes can be built asynchronously, just like inverted indexes, minimizing the impact on write performance. Index management is also straightforward: when tuning index parameters, users can easily drop and rebuild vector indexes as needed.
Vector Indexes in Apache Doris
Vector search inherently involves trade-offs between recall, query latency, and index build cost. To accommodate different workloads, Apache Doris provides two widely adopted ANN index types: HNSW and IVF.
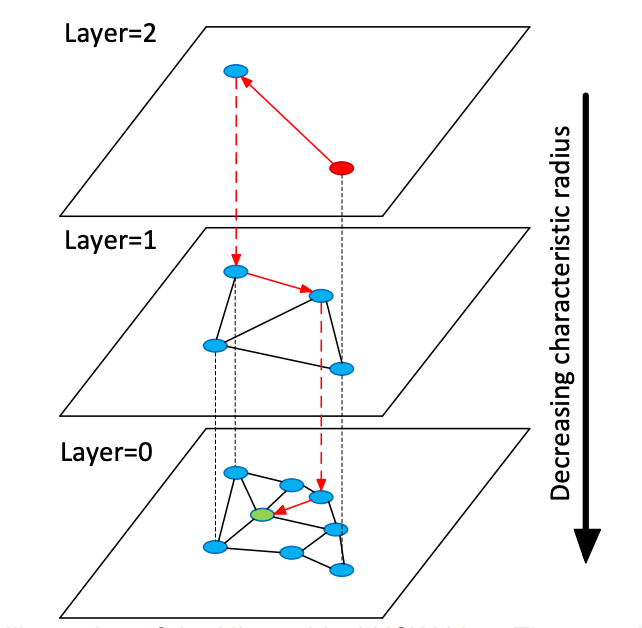
- HNSW (Hierarchical Navigable Small World): HNSW is based on a multi-layer graph structure that quickly narrows the search space at upper layers and performs fine-grained searches at lower layers. Its key advantages include high recall (often approaching exact search quality for semantic retrieval), low query latency with near O(log n) complexity, good performance in large-scale scenarios, and tunability through parameters such as
ef_search. As the most widely used ANN index in the industry, HNSW is essential for use cases like RAG, question answering, and similarity search.
- IVF (Inverted File Index): IVF partitions vectors into clusters (for example, using k-means) and searches only the most relevant clusters at query time. It offers fast index construction and low resource consumption, making it well-suited for vector collections ranging from millions to tens of millions of entries. The
nprobeparameter allows users to balance recall and latency. Compared to HNSW, IVF is a better fit for large-scale workloads where query precision is tunable, such as logs, event data, or product embeddings.
Multiple Vector Query Modes
Apache Doris supports multiple efficient vector query patterns to accommodate different search requirements. The most common modes are outlined below, with examples provided in later sections:
A. Top-K nearest neighbor search: Supports both L2 distance and inner product similarity metrics, allowing the system to quickly retrieve the top-K vectors most similar to a query vector.
SELECT id, inner_product_approximate(embedding,[0,11,77...]) as distance FROM sift_1M ORDER BY distance limit 10
SELECT id, l2_distance_approximate(embedding,[0,11,77...]) as distance FROM sift_1M ORDER BY distance limit 10
B. Approximate range search: Allows users to specify distance thresholds and return all vectors whose similarity falls within a given range.
SELECT count(*)
FROM sift_1m
WHERE l2_distance_approximate( embedding, [0,11,77,...]) > 300
C. Combined search
Enables ANN Top-K retrieval and range-based filtering within a single SQL query, returning Top-K results that also satisfy specified distance constraints.
SELECT id,
l2_distance_approximate(
embedding, [0,11,77...]) as dist
FROM sift_1M
WHERE l2_distance_approximate(
embedding, [0,11,77...])
> 300
ORDER BY dist limit 10
Quantization and Encoding Mechanisms
Vector embeddings are often high-dimensional and large in volume, creating significant pressure in both computation and memory usage. Quantization and encoding techniques help strike a practical balance between performance, accuracy, and cost.
Apache Doris uses FLAT encoding, which stores vectors in raw format. However, HNSW indexes built on FLAT encoding can consume substantial memory and must reside fully in memory to operate efficiently. This can become a bottleneck at very large scales.
To address this, Apache Doris supports vector quantization techniques:
- Scalar Quantization (SQ) compresses FLOAT32 values to reduce memory usage.
- Product Quantization (PQ) reduces memory consumption by splitting high-dimensional vectors into sub-vectors and quantizing each independently.
Apache Doris currently supports two scalar quantization formats: INT8 and INT4 (SQ8 / SQ4). For example, in tests on the 768-dimensional Cohere-MEDIUM-1M and Cohere-LARGE-10M datasets, SQ8 reduced index size to roughly one-third of the FLAT baseline.
Apache Doris also supports product quantization, which can further compress the index size to around one-fifth of FLAT. When using PQ, additional configuration parameters are required (see the official documentation for details).
Full-Text Search and Inverted Indexes in Apache Doris
Text search is a foundational capability for LLM-powered applications, directly affecting their reliability, accuracy, and practical usefulness. In Apache Doris, high-performance text analytics is built primarily on inverted indexes.
At a high level, an inverted index breaks text into individual terms and records the documents in which each term appears. During query execution, the system can locate matching rows directly from the index, avoiding full-table scans and reducing query complexity from O(n) to approximately O(log n).
To ensure that text search truly meets the needs of AI agents and analytical workloads, Apache Doris applies systematic architectural design and engineering optimizations on top of its inverted index implementation.

- Architecture: Apache Doris adopts a pluggable index architecture that decouples inverted indexes from segment data files and stores them as independent files. This design is highly flexible: inverted indexes can be added directly to existing tables without rebuilding data or taking services offline. Indexes can also be built asynchronously and incrementally on demand, minimizing impact on online workloads. During compaction, indexes do not require data rewriting; only index contents are merged, significantly reducing the resource overhead caused by tokenization.
- Query Execution: Apache Doris introduces a two-layer index caching system. Object caching reduces file I/O, while query caching avoids redundant execution. It also optimizes index-only query execution. For scenarios such as
COUNTaggregations or pure predicate filtering, where results can be determined solely from inverted indexes, the execution engine skips reading and decompressing Data Segments, completing the computation using only index files. This minimizes I/O and substantially improves analytical throughput. - Storage: To balance performance and storage efficiency, Apache Doris employs multiple adaptive compression algorithms to compactly store inverted index components, including term dictionaries, posting lists, and phrase position information.
- Built-in and Custom Tokenizers: Apache Doris provides a wide range of built-in tokenizers, covering Chinese, English, multilingual Unicode, and ICU internationalization. It also supports custom analyzers, allowing configuration of character normalization, tokenization strategies, stop words, pinyin conversion, and case normalization.
- Rich Query Operators: Building on inverted indexes, Apache Doris implements a comprehensive set of search operators, as illustrated in the figure below.
| Operator | Typical Use Case | Syntax Example |
|---|---|---|
| MATCH_ANY | Match documents containing any of the query terms | SELECT * FROM table_name WHERE content MATCH_ANY 'keyword1 keyword2'; |
| MATCH_ALL | Match documents containing all query terms | SELECT * FROM table_name WHERE content MATCH_ALL 'keyword1 keyword2'; |
| MATCH_PHRASE | Match documents where terms appear adjacent and in order | SELECT * FROM table_name WHERE content MATCH_PHRASE 'keyword1 keyword2'; |
| MATCH_PHRASE slop (Phrase match with slop) | Allow gaps between terms, as long as the distance does not exceed the specified slop value | SELECT * FROM table_name WHERE content MATCH_PHRASE 'keyword1 keyword2 ~3'; |
| MATCH_PHRASE_PREFIX | Phrase match where the last term supports prefix matching | SELECT * FROM table_name WHERE content MATCH_PHRASE_PREFIX 'keyword1 keyword'; |
| MATCH_REGEXP | Match documents based on a regex pattern; query terms are not tokenized | SELECT * FROM table_name WHERE content MATCH_REGEXP '^key_word.*'; |
- BM25 Relevance Scoring
BM25 (Best Matching 25) is a probabilistic relevance-scoring algorithm widely used in full-text search engines. Apache Doris 4.0 introduced BM25 for relevance scoring in inverted-index queries. By dynamically adjusting term frequency weights based on document length, BM25 significantly improves result relevance and retrieval accuracy in scenarios involving long texts and multi-field searches, such as log analysis and document retrieval.
In a distributed system like Doris, the BM25 scoring process is executed in three stages. Statistics are collected separately at the tablet and segment levels, which helps ensure scoring stability and consistency across the cluster.
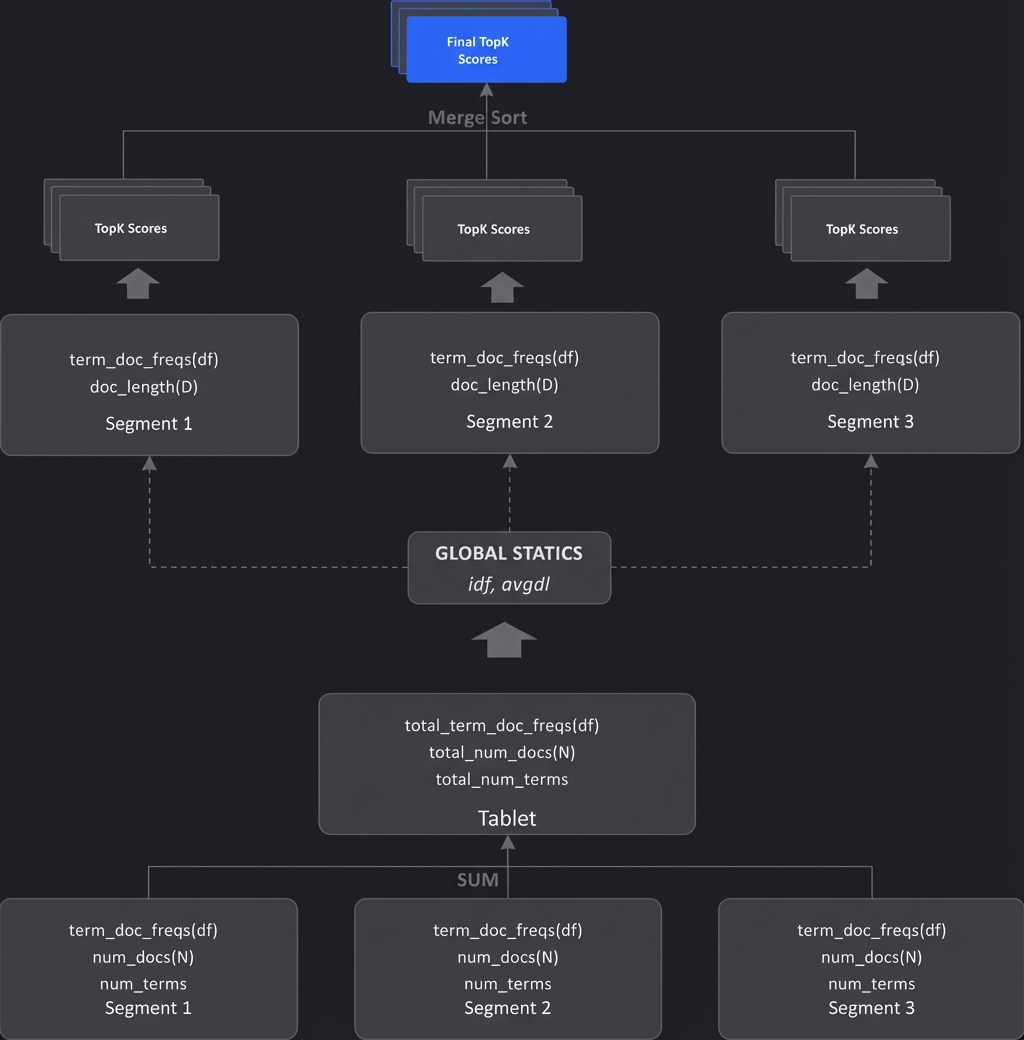
Three‑Phase Execution Flow
In Apache Doris' distributed architecture, the BM25 scoring process decouples the statistics collection layer (at the tablet level) from the score computation layer (at the segment level). This design ensures data consistency and stable scoring results.
Phase 1: Tablet Level – Collect Global Statistics
This phase runs at the tablet level and scans all segments to gather the global metadata needed for BM25 scoring:
- Statistics collection: Aggregate the total number of documents (N) and the global document frequency for each term (f(qᵢ, D)).
- Average calculation: Sum up total word counts across all documents to compute the global average document length (avgdl).
- Core output: Use N and f(qᵢ, D) to compute the global inverse document frequency (IDF) for each query term.
Phase 2: Segment Level – Parallel Scoring and Local Top‑K Selection
This is the parallel scoring phase. Because BM25 scores are independent per document (once the global IDF is fixed), each segment can compute scores and perform local ranking in parallel:
- Parallel scoring: Each segment applies the global IDF along with its local term frequencies (f(qᵢ, D)) and document lengths (|D|) to calculate BM25 scores for all matching documents.
- Local pruning: Each segment performs a local Top‑K selection, keeping only the highest‑scoring document IDs and scores. This minimizes data transfer in later stages.
Phase 3: Aggregation Level – Merge Top‑K Results
Finally, the aggregation node (e.g., the backend merge layer) collects the local Top‑K results from all segments, merges and sorts them globally, and returns the final Top‑K results to the user.
Conclusion
As AI continues to reshape how we interact with data, having a database that natively understands both structured queries and unstructured semantics isn't just convenient, it's essential to compete.
By unifying vector search, full-text search, and structured analytics in a single engine, Apache Doris reduces system complexity and data synchronization.
It's not just cost saving, for teams building RAG applications, recommendation systems, or any hybrid scenarios that need a combination of search and analytics, Apache Doris 4.0 offers a production-ready data foundation that combines the semantic understanding of vector search with the precision of full-text search, all within a familiar SQL interface.
Want to learn more about Apache Doris and its AI hybrid search use cases? Join the Apache Doris community on Slack and connect with Doris experts and users. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.