Apache Doris 4.1 is here. This release builds on the foundation established in the major release of Apache Doris 4.0, which introduced vector search, hybrid search, and the search() function to better serve as the infrastructure for AI agents, RAG, AI observability, and real-time analytics.
The Apache Doris 4.1 takes those capabilities significantly further, offering a unified layer for storage and retrieval for AI and search scenarios. This update targets the key problems when teams put AI applications into production:
- Storing massive volumes of AI data at low cost
- Unifying vector search, full-text search, and structured filtering in one system
- Holding long-context documents and wide semi-structured data in a single table
- Serving real-time queries and observability for LLMs, agents, and RAG
- Improving the high-performance of OLAP and lakehouse performance that Apache Doris is known for
- Unifying large-scale ETL batch processing with real-time pipelines
Key Highlights:
- AI and search: Introducing IVF and IVF_ON_DISK vector indexes, scaling vector retrieval to the billion and trillion data scale.
- Full-text search: The
search()function now supports BM25 scoring and Elasticsearch-compatible syntax, making text search and analytics native to SQL. - Long-context storage for AI: Native support for single JSON documents up to 100MB, built for agent memory and long-context AI workloads.
- OLAP performance: Compared to 4.0, Apache Doris 4.1 improved 22.6% in TPC-H, 19.1% in TPC-DS, 14.3% in SSB, and ranks first on ClickBench in cold query.
- Data lake: Full Apache Iceberg V2/V3 read and write, Apache Paimon DDL management via SQL, Parquet Page Cache +20%.
- Compute-storage separation: Deployed at 2,000+ companies, with improved file cache observability, elasticity, and cold query performance.
Download Apache Doris 4.1: GitHub releases, or official site
1. AI & Search
A. Vector Search
New ANN Algorithm: IVF
Apache Doris 4.0 introduced the HNSW vector index type. Now in 4.1, we added the IVF (Inverted File) index to handle larger-scale vector data.
The core idea of IVF: cluster vectors into buckets first, then search locally within relevant buckets, trading a small amount of precision for a large speedup. Compared to the HNSW, IVF supports larger-scale vector datasets with lower memory usage at the cost of modest recall.
To use the IVF index in Apache Doris 4.1, set "index_type"="ivf" in the index properties.
CREATE TABLE sift_1M (
id int NOT NULL,
embedding array<float> NOT NULL COMMENT "",
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="ivf",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024"
)
) ENGINE=OLAP
DUPLICATE KEY(id) COMMENT "OLAP"
DISTRIBUTED BY HASH(id) BUCKETS 1
PROPERTIES (
"replication_num" = "1"
);
Disk-Based Vector Search: IVF_ON_DISK
Open-source vector libraries like Faiss hold up well at tens-of-millions-scale vector search by keeping the full index in memory. At tens of billions of vectors or beyond, that memory requirement pushes costs up sharply.
Building on the IVF algorithm, Apache Doris implemented IVF_ON_DISK following the optimization approach described in Microsoft's SPANN paper. By combining in-memory caching with local filesystem caching, IVF_ON_DISK delivers efficient vector pruning at very low cost.
- In compute-storage separation mode, IVF_ON_DISK enables low-cost, high-performance pruning and recall at a very large scale.
- Compared to DiskANN, IVF_ON_DISK significantly reduces index build overhead, offering a practical path for trillion-scale vector search.
- A strong fit for AI knowledge bases, recommendation recall, and large-scale embedding retrieval.
Using IVF_ON_DISK is nearly identical to using IVF: just specify "index_type"="ivf_on_disk".
CREATE TABLE for_ivf_on_disk (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type"="ivf_on_disk",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024"
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
Vector Quantization
Beyond the index algorithm, Apache Doris supports three vector quantization methods:
- INT8 scalar quantization
- INT4 scalar quantization
- Product Quantization (PQ)
With a small recall trade-off, these methods compress index memory footprint to 1/4 to 1/8 of the original. Combined with IVF_ON_DISK, they further reduce machine cost for large-scale vector retrieval.
The example below shows DDL for PQ compression on 128-dimensional vectors:
CREATE TABLE product_quant (
id BIGINT NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX idx_emb (embedding) USING ANN PROPERTIES (
"index_type"="ivf_on_disk",
"metric_type"="l2_distance",
"dim"="128",
"nlist"="1024",
"quantizer"="pq",
"pq_m"=64,
"pq_nbits"=8
)
) ENGINE=OLAP
DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 8
PROPERTIES ("replication_num" = "1");
4x Better Vector Search Query Performance
To improve query performance, Apache Doris 4.1 adds an Ann Index Only Scan optimization that lets vector search skip I/O on raw columns during query execution, cutting query overhead significantly. Vector index query performance in 4.1 is up to 4x faster than 4.0.
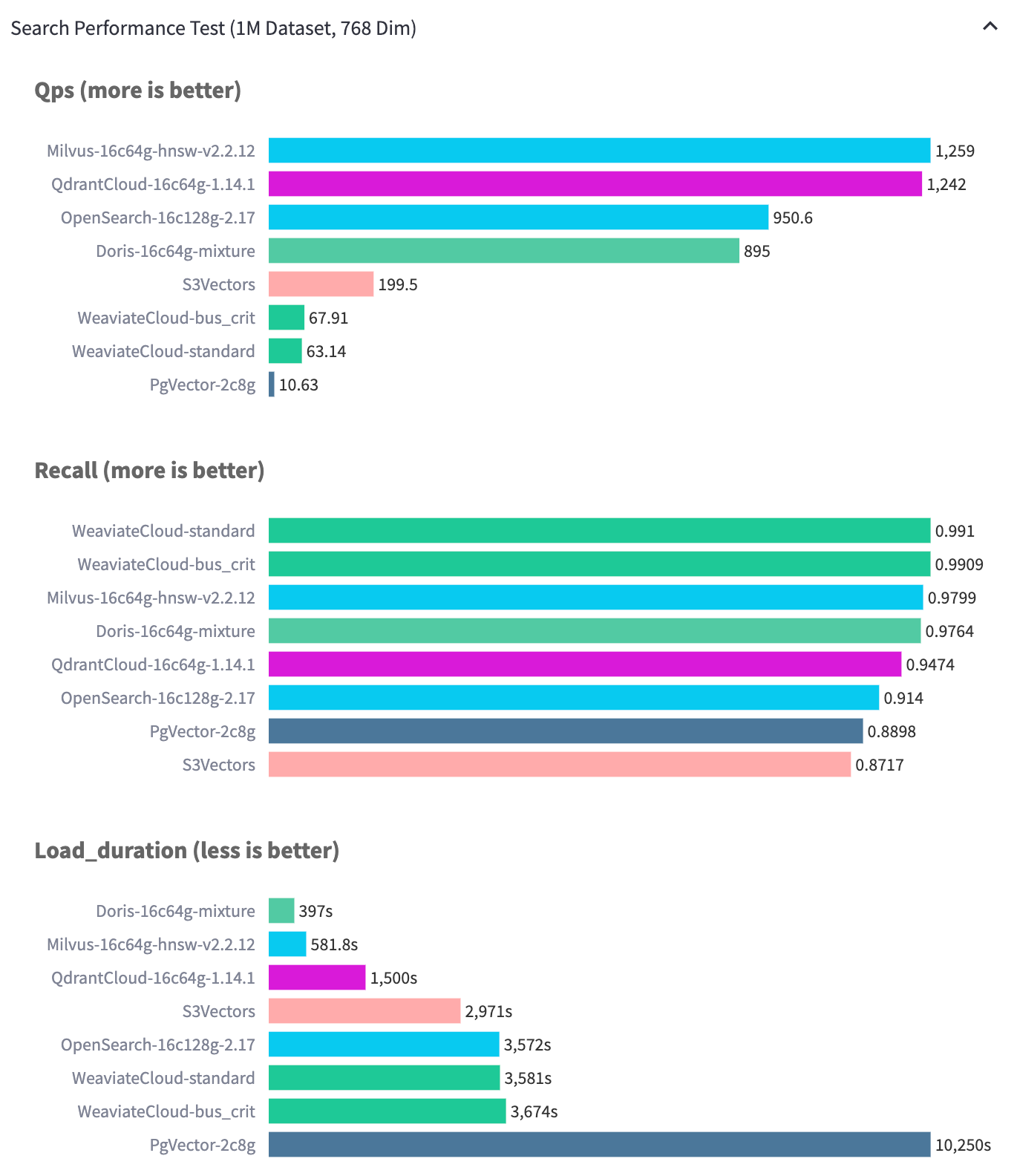
In a test setup with 1 million vectors, deployed on 16-core CPU and 64GB memory, Apache Doris delivers around 900 QPS at 97% recall, enough for most production-scale vector retrieval workloads.
According to public VectorDBBench data (as of January 2026), Apache Doris builds vector indexes faster than Milvus, Qdrant, and pgvector. The advantage comes from Apache Doris's data layering architecture. 4.1 strengthens this advantage further. During index construction, Apache Doris now batches vectors in memory and builds the vector index in batches, maximizing build parallelism while maintaining index quality.
B. The search() Function: Unified Text Search and Analytics in SQL
Where vector search handles semantic recall, full-text search handles keyword lookup, troubleshooting, log search, and text analytics. The new search() function in Apache Doris 4.1 brings full-text search directly into SQL, letting a single query handle both search filtering and aggregation.
- Compatible with Elasticsearch query_string syntax: seamless migration from Elasticsearch.
- Rich query operators: TERM, PHRASE, WILDCARD, REGEXP, PREFIX, NOT, NESTED, and more. All operators are nestable and combinable.
- BM25 relevance scoring: built-in scoring with storage-layer TopN optimization, avoiding full result-set transmission.
- Nested search: combined with the VARIANT type, the
NESTEDoperator can search directly inside nested JSON arrays. - Multi-field search: supports both
best_fields(precise match within the same field) andcross_fields(distributed match across fields).
Typical usage:
-- Multi-condition: TERM + PHRASE + NOT evaluated in a single pass
SELECT request_id, error_msg, latency_ms
FROM inference_logs
WHERE search('
level:ERROR
AND error_msg:"CUDA out of memory"
AND NOT module:healthcheck
AND model_name:gpt*
')
AND log_time > NOW() - INTERVAL 1 HOUR
ORDER BY latency_ms DESC LIMIT 100;
-- BM25 relevance scoring
SELECT request_id, error_msg, score() AS relevance
FROM inference_logs
WHERE search('error_msg:"memory allocation failed" OR error_msg:"CUDA error"')
ORDER BY relevance DESC LIMIT 20;
-- Nested search: query inside a VARIANT array
SELECT * FROM agent_logs
WHERE search('NESTED(steps, status:error AND tool:code_exec)');
-- search + aggregation: filter and analyze in one query
SELECT model_name, COUNT(*) AS error_count,
PERCENTILE_APPROX(latency_ms, 0.99) AS p99_latency
FROM inference_logs
WHERE search('level:ERROR AND error_msg:"CUDA out of memory"')
AND log_time > NOW() - INTERVAL 1 HOUR
GROUP BY model_name ORDER BY error_count DESC;
Note: search() returns a boolean predicate that participates directly in joins, window functions, and subqueries, making full-text search a standard part of SQL.
C. Native 100MB JSON Document Storage for Long-Context AI Conversations
In AI agents, RAG, long-context, multi-turn use cases, the demand is growing for storing long interactive context in one place.
Apache Doris 4.1 adds native support for single rows of up to 100MB JSON documents, allowing complete AI session data to live in the database, including multi-turn conversations, long document text, audio and video transcripts, agent execution traces, tool call logs, and RAG context. No splitting, no truncation, no external storage. Once written, these large documents behave like any other data: filtering, conditional queries, aggregations, and JOINs all work. Turning large AI context data becomes a manageable, queryable, structured asset.
Apache Doris' large JSON document storage allows teams to:
- Removes the dependency on separate object storage
- Removes the consistency maintenance logic between metadata and raw content
- Removes the development overhead of segmented storage and reassembly
- Delivers lower query latency, stronger transactional guarantees, and a simpler operational footprint
D. Segment V3: Metadata Decoupling for Wide Tables
Search and AI workloads tend to produce wide, sparse, and semi-structured data: involving many fields, fast-changing schemas, and clear hot/cold access patterns. These workloads demand strong random read, point lookup, and high-concurrency write performance.
Before 4.1, Apache Doris used the Segment V2 storage format, which consolidates metadata in the file footer. That works well for batch scans, but in random reads and small-range queries, every access requires loading the full footer, adding I/O and parsing overhead.
Apache Doris 4.1 introduces Segment V3, drawing from newer file storage formats like Lance and Vortex. Metadata is decoupled from the footer and loaded on demand, addressing metadata bloat, slow file open times, and high random read overhead in wide-table workloads. Segment V3 is a strong fit for wide tables, tables with many VARIANT sub-columns, workloads sensitive to cold-start latency on object storage, and AI or vehicle telematics semi-structured data with significant random read access.
On a wide table with 7,000 columns and 10,000 segments, V3 delivers significant gains at segment open:
- Up to 16x faster open times
- Up to 60x lower memory usage
In wide-table and high-concurrency workloads, this translates to faster response times and lower resource cost.

How to enable: specify "storage_format" = "V3" in the table properties.
CREATE TABLE table_v3 (
id BIGINT,
data VARIANT
)
DISTRIBUTED BY HASH(id) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);
Documentation: https://doris.apache.org/docs/4.x/table-design/storage-format
E. Sparse Column Optimization: Sparse Sharding and Sparse Cache
Wide JSON data typically has a long tail of rarely-accessed paths and only a few hot paths. Apache Doris 4.1 optimizes the sparse read path so that long-tail paths no longer bottleneck a single sparse column.
- Hot/cold separation: frequently accessed paths remain as columnar sub-columns, long-tail paths go into sparse storage, preventing sub-column proliferation.
- Sparse Sharding:
variant_sparse_hash_shard_countdistributes long-tail paths across multiple sparse columns, reducing read amplification on any single column. - Sparse Cache: a read cache for sparse columns reduces repeated I/O, decoding, and deserialization overhead.
This feature is a strong fit for wide JSON data in vehicle telematics, user profiles, event logs, and similar ultra-wide JSON workloads, where data has many fields but only a few dozen to a few hundred paths are queried frequently.
Example:
CREATE TABLE user_feature_wide (
uid BIGINT,
features VARIANT<
'user_id' : BIGINT,
'region' : STRING,
properties(
'variant_max_subcolumns_count' = '2048',
'variant_sparse_hash_shard_count' = '32'
)
>
)
DUPLICATE KEY(uid)
DISTRIBUTED BY HASH(uid) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);
Docs:
Benchmark results: https://doris.apache.org/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#performance
Reference: https://doris.apache.org/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#sparse-mode Keyword: Sparse sharding
F. DOC Mode: Faster Writes and Efficient Full-Document Retrieval
When semi-structured workloads center on write efficiency or full-document JSON retrieval, DOC mode is a better fit. It keeps the raw JSON on write and defers sub-column extraction to compaction, reducing write cost and write amplification.
- Deferred materialization: raw JSON is retained at write time, lowering small-batch write overhead.
- DOC Sharding:
variant_doc_hash_shard_countsplits the Doc Store into multiple shards, improving full-document returns and path extraction. - Materialization threshold:
variant_doc_materialization_min_rowscontrols when materialization happens. Below-threshold batches are deferred to compaction.
A strong fit for AI/LLM output, Trace data, context snapshots, and event replay workloads that frequently return full documents.
How to configure: enable variant_enable_doc_mode, tune the materialization threshold and shard count to data scale. DOC mode and sparse columns are mutually exclusive: pick one. Use with storage_format = "V3".
CREATE TABLE trace_archive (
ts DATETIME,
trace_id STRING,
span VARIANT<
'service_name' : STRING,
properties(
'variant_enable_doc_mode' = 'true',
'variant_doc_materialization_min_rows' = '100000',
'variant_doc_hash_shard_count' = '32'
)
>
)
DUPLICATE KEY(ts, trace_id)
DISTRIBUTED BY HASH(trace_id) BUCKETS 32
PROPERTIES (
"storage_format" = "V3"
);
Docs:
Benchmark results: https://doris.apache.org/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#performance
Reference: https://doris.apache.org/docs/4.x/sql-manual/basic-element/sql-data-types/semi-structured/variant-workload-guide#doc-mode-template Keyword: DOC mode
2. Faster OLAP
Apache Doris is known for its fast, real-time OLAP analytics. Apache Doris 4.1 continues to improve: cutting wasted computation, reducing data movement, and improving execution efficiency so complex queries stay fast under real workloads.
Multi-Table Analytics
On standard multi-table join and aggregation benchmarks, Apache Doris 4.1 delivers meaningful gains compare to 4.0:
- TPC-H: +22.6%
- TPC-DS: +19.1%
- SSB: +14.3%
| Apache Doris 4.1 | Apache Doris 4.0 | Improvement | |
|---|---|---|---|
| SSB SF1000 | 10934 ms | 12495 ms | 14.28% |
| TPC-H SF1000 | 53275 ms | 65312 ms | 22.59% |
| TPC-DS SF1000 | 159562 ms | 190031 ms | 19.10% |
Wide-Table Analytics
ClickBench uses 100GB of data and 43 complex queries to stress-test columnar storage, vectorized execution, and compression, making it one of the most demanding single-table benchmarks in the industry.
Tested on c7a.metal-48xl instances, Apache Doris 4.1 ranks first on ClickBench cold query and storage space. Its overall score places second, behind only ClickHouse (web).
Cold query:

Overall score:

The sections below cover the key optimizations behind these numbers.
A. Aggregation Pushdown Through JOIN
Aggregate Pushdown Through JOIN splits high-aggregation operators and pushes them down to both sides of the JOIN. It first performs local aggregation on each table, then joins the reduced data, and finally completes the global aggregation. This approach of compressing first, JOIN later, reduces the amount of data involved in the JOIN at the source, significantly lowering memory usage and computation latency.
In benchmark tests, Apache Doris' overall performance improved by more than 200%. Over half of the test cases improved by more than 50%. Nearly one-third improved by more than 100x.
B. Grouping Sets Optimization
By intelligently identifying the finest-grained aggregation group and its aggregation ratio, the execution strategy can be changed from parallel aggregation across multiple groups to a two-step approach: first complete the most granular aggregation to drastically reduce the data volume, then derive the other aggregation groups from that result. This significantly lowers computation latency.
In benchmark tests, Apache Doris' overall performance improved by more than 10%. More than one-fifth of test cases improved by over 20%, with a maximum improvement of 160% and a maximum regression under 5%.
C. Nested Column Pruning
Nested column pruning can precisely interpret nested field structures. When a query involves only a specific subfield, it reads only the relevant data and skips unrelated fields, significantly reducing I/O overhead. In Apache Doris 4.1, nested column pruning applies to internal tables as well as external ORC and Parquet data.
In benchmark tests, Apache Doris' overall performance improved by more than 60%. In extreme cases, improvement exceeded 700%.
D. Condition Cache
In large-scale analytics, queries often reuse the same filter conditions across executions:
SELECT * FROM orders WHERE region = 'ASIA';
SELECT count(*) FROM orders WHERE region = 'ASIA';
Running the same filter repeatedly against the same segments wastes CPU and I/O. Condition Cache caches the per-segment filter result and reuses it in later queries, reducing redundant scans and compute. In complex query workloads, overall performance improved by more than 10%.
Docs: https://doris.apache.org/docs/4.x/query-acceleration/condition-cache
E. Query Cache: Reusing Intermediate Aggregation Results
In analytical workloads, the same aggregation query often runs repeatedly against unchanged data:
SELECT region, SUM(revenue) FROM orders WHERE dt = '2024-01-01' GROUP BY region;
Each execution scans the same tablets and recomputes the same aggregations. Apache Doris Query Cache caches intermediate aggregation results. When the query context matches, it returns cached results directly, cutting compute and I/O.
Docs: https://doris.apache.org/docs/4.x/query-acceleration/query-cache
F. CASE WHEN Optimization
CASE WHEN is a core analytical construct for business classification, row-level logic, and conditional aggregation across dimensions.
Apache Doris 4.1 introduces branch merging, branch elimination, common sub-expression extraction, and enum value extraction and pushdown. Together, these significantly improve execution for any query that uses CASE WHEN.
On the benchmark set, average performance improved by more than 200%. In extreme cases, improvement exceeded 50x.
3. Compute-Storage Separation
The Apache Doris compute-storage separation architecture now runs at 2,000+ production users. As adoption has grown, stability and query performance have become the primary focus areas. Apache Doris 4.1 continues to improve on that front.
A. File Cache Improvements
File cache metadata is now persisted, avoiding the heavy I/O that previous versions incurred when rebuilding cache state at startup. A new system table, information_schema.file_cache_info, exposes block-level cache details via SQL, queryable by tablet_id, be_id, cache_path, and type. This makes it straightforward to locate hotspot data, diagnose cache imbalance, and detect abnormal cache growth.
Typical use 1: drill into a single tablet's cache composition.
mysql> select * from information_schema.file_cache_info where TABLET_ID = 1761571031445;
+----------------------------------+---------------+-------+--------+-------------+-----------------+---------------+
| HASH | TABLET_ID | SIZE | TYPE | REMOTE_PATH | CACHE_PATH | BE_ID |
+----------------------------------+---------------+-------+--------+-------------+-----------------+---------------+
| 468448215c52334ae5bee147259b1027 | 1761571031445 | 15120 | index | | /mnt/disk1/project/filecache | 1761571031251 |
| 71bb73d34cd8ffe280b16dd329df5ba1 | 1761571031445 | 13117 | index | | /mnt/disk1/project/filecache | 1761571031251 |
| 77c6b69d1a7c4fe740a11bab5c1bbaa3 | 1761571031445 | 12249 | index | | /mnt/disk1/project/filecache | 1761571031251 |
+----------------------------------+---------------+-------+--------+-------------+-----------------------------------------------------------------------------+---------------+
Typical use 2: aggregate cache distribution to evaluate balance and resource usage across BE nodes.
SELECT be_id, tablet_id, type, SUM(size) AS cache_bytes
FROM information_schema.file_cache_info
WHERE tablet_id = 1761571031445
GROUP BY be_id, tablet_id, type
ORDER BY cache_bytes DESC;
B. Elastic Scaling, Cold Queries, and Other Improvements
- Elastic scaling: In compute-storage separation mode, scaling operations on millions of tablets complete in minutes. Scheduling no longer depends on global tablet counts, significantly improving elasticity.
- Cold query optimization: Prefetching based on Apache Doris's page-scanning semantics improves cold query performance on internal tables. By tuning parameters, Doris can better utilize remote storage bandwidth, improving I/O performance.
- Large-scale deployment: Replica and tablet objects in the FE have been slimmed down, reducing FE memory usage by 30%+ at millions-of-tablets scale.
- Meta-service performance: A caching layer reduces repeated requests to the Meta Service, improving metadata throughput. Access paths for certain system tables under compute-storage separation have also been optimized.
- Object storage cost: In high-frequency import scenarios, node-level request merging reduces object storage requests and small-file counts. Overall cost can be cut by up to 90%.
- Column compression and encoding: More efficient binary encoding with pre-decoding reduces runtime decode cost. The default compression algorithm is gradually moving to ZSTD, balancing compression ratio with decompression performance. In wide-table and detail-table workloads, this translates to lower storage footprint and better cold read performance.
4. Data Lakehouse
Apache Doris 4.1 advances the unified lakehouse capability across format support, query performance, and ecosystem compatibility. Users can read, write, and manage data in major open lake formats like Apache Iceberg and Apache Paimon using Doris SQL alone, without relying on Apache Spark or other external engines.
A. Lakehouse Lifecycle Management
Apache Doris 4.1 adds full lifecycle management for the major open lake formats. Table creation, data insertion, updates, and deletes all run through Doris SQL: one engine covering the full data lake workflow.
- Full Apache Iceberg V2/V3 read and write support: INSERT, UPDATE, DELETE, and MERGE INTO are supported, along with Iceberg V3 features including Deletion Vector and Row Lineage. Data ingestion, updates, and deletes all run end-to-end without external engines.
- Apache Paimon table management:
CREATE DATABASE,CREATE TABLE, and other DDL operations run directly via Doris SQL. Write support for Paimon tables is planned for future releases.
Docs:
https://doris.apache.org/docs/4.x/lakehouse/catalogs/iceberg-catalog
https://doris.apache.org/docs/4.x/lakehouse/catalogs/paimon-catalog
B. Lakehouse Query Performance
Several targeted optimizations improve query performance on lake data.
- Iceberg sorted writes: Data can now be written in a specified sort order, generating sorted metadata (lower/upper bounds) that the query engine uses for efficient file pruning. On TPC-DS, query performance improved by approximately 15%.
- Iceberg Manifest caching: Manifest-level metadata caching avoids repeated reads and parsing during query planning, reducing I/O and CPU overhead. Under frequent-query workloads, complex metadata resolution drops to the hundred-millisecond range.
- Parquet Page Cache: Decompressed data pages are cached in memory, reducing repeated decompression and disk I/O. Under frequent-query workloads, latency drops significantly. On ClickBench, overall performance improved by approximately 20%.
Docs:
https://doris.apache.org/docs/4.x/lakehouse/catalogs/iceberg-catalog#creating-and-dropping-tables
https://doris.apache.org/docs/4.x/lakehouse/catalogs/iceberg-catalog#meta-cache
https://doris.apache.org/docs/4.x/lakehouse/best-practices/optimization#parquet-page-cache
C. Federated Analytics Usability
Apache Doris 4.1 also improves data interoperability and ease of use:
- Cache admission control: Fine-grained rules across User, Catalog, Database, and Table control which queries can write to the cache, preventing cold data from evicting hot data and improving hotspot hit rates. Rules live as JSON files in a designated directory and hot-reload on change: no FE restart needed.
EXPLAINexposes admission decisions, making tuning observable. - MaxCompute write support:
CREATE TABLEandINSERTare now supported in the MaxCompute external Catalog, completing the export path from Apache Doris to MaxCompute. ARN cross-account access is also supported, making integration with the Alibaba Cloud ecosystem straightforward. - Parquet metadata inspection: A new Parquet metadata TVF exposes partition, row group, and column statistics via SQL, useful for debugging file structure, validating partition pruning, and optimizing query performance.
Docs:
https://doris.apache.org/docs/4.x/lakehouse/data-cache
https://doris.apache.org/docs/4.x/lakehouse/catalogs/maxcompute-catalog
https://doris.apache.org/docs/4.x/sql-manual/sql-functions/table-valued-functions/parquet-meta
5. Batch Processing
Apache Doris continues to unify interactive analytics and large-scale batch processing in a single engine, reducing the architectural complexity of running multiple systems side by side. Apache Doris 4.1 further strengthens native ETL and ELT.
A. MERGE INTO
A single standard SQL MERGE INTO statement now handles INSERT, UPDATE, and DELETE (UPSERT), simplifying incremental data merge workflows like CDC and reducing development and maintenance costs.
MERGE INTO target t
USING source s
ON t.id = s.id
WHEN MATCHED THEN
UPDATE SET t.value = s.value
WHEN NOT MATCHED THEN
INSERT (id, value) VALUES (s.id, s.value);
B. Enhanced Spill-to-Disk
Large table joins, high-cardinality aggregations, and global sorts are memory-intensive. Apache Doris 4.1 extends spill-to-disk across these operators:
- Recursive multi-level spill: intermediate data can be spilled across multiple stages, avoiding sudden memory pressure.
- Works across JOIN, Aggregation, and Sort operators.
- Dynamic spill triggering: balances memory against disk I/O to keep queries stable.
With these improvements, Apache Doris can run all TPC-DS 10TB queries on a single BE node with 8GB of memory, a practical demonstration of stronger query performance at lower resource cost than traditional Hadoop, Greenplum, or Apache Spark setups.
6. Usability Enhancements
Apache Doris 4.1 rounds out the analytical syntax set, strengthens complex-scenario expressiveness, and improves cross-system compatibility.
A. Execution Engine Extensions
- UNNEST: native
UNNESTsyntax simplifies analysis of ARRAY or nested structures in JSON and log data, avoiding complex function rewrites.
SELECT user_id, tag
FROM user_profile,
UNNEST(tags) AS t(tag);
- Recursive CTE: recursive queries now work for organization trees, hierarchies, graph paths, and similar traversal and relationship analysis.
WITH RECURSIVE org_tree AS (
SELECT id, parent_id, name
FROM org
WHERE parent_id IS NULL
UNION ALL
SELECT o.id, o.parent_id, o.name
FROM org o
JOIN org_tree t ON o.parent_id = t.id
)
SELECT * FROM org_tree;
- ASOF JOIN:
ASOF JOINsupports nearest-match joins on a time column (<=/>=), useful for financial, IoT, and monitoring workloads that need time-series alignment and nearest-value matching.
SELECT t1.ts, t1.value, t2.price
FROM trades t1
ASOF JOIN prices t2
ON t1.symbol = t2.symbol
AND t1.ts >= t2.ts;
B. Data Ingestion and Write Path Improvements
- Continuous S3 import: continuous import jobs can now be created from S3 file sources. The system automatically detects new files and keeps importing them, a good fit for incremental ingestion from object storage.
- MySQL / PostgreSQL real-time sync: Doris now support real-time update and ingestion from MySQL and PostgreSQL, covering both full initialization and incremental sync. This simplifies building real-time analytics pipelines from operational databases into Apache Doris, supporting real-time data warehousing, data consolidation, and analytics acceleration.
Docs:
- https://doris.apache.org/docs/4.x/data-operate/import/streaming-job/continuous-load-s3
- https://doris.apache.org/docs/4.x/data-operate/import/streaming-job/continuous-load-mysql-table
- https://doris.apache.org/docs/4.x/data-operate/import/streaming-job/continuous-load-postgresql-table
C. Write and Update Model Improvements
- Adaptive write scheduling: the MemTable flush thread pool adapts dynamically to cluster load, matching write concurrency to current conditions. In high-write workloads, this improves throughput, resource utilization, and stability.
- Primary key model multi-stream updates (sequence-aware):
sequence_mappingsupports multi-stream merge updates. Different data streams can update different columns on the same table and merge according to their own sequence fields, a strong fit for concurrent real-time stream updates and offline backfills. - Routine Load enhancements: flexible partial updates on non-primary-key columns, dynamic parameter adjustment, and adaptive batching improve stability under high-throughput workloads.
- Import audit observability: Stream Load records can be written to the audit log system table for unified query history, debugging, and audit analysis.
D. TIMESTAMPTZ: Native Time Zone Support
In global and multi-time-zone workloads (cross-region logs, user behavior analytics, financial transactions), timestamps carry explicit time zone information. Using the time-zone-less DATETIME type means converting at the application layer, which is error-prone and adds development cost.
Apache Doris 4.1 introduces TIMESTAMPTZ (TIMESTAMP WITH TIME ZONE), providing standard time-zone-aware time handling:
- Unified storage: values are stored in UTC on write.
- Automatic conversion: queries convert to the session time zone automatically.
- Flexible input: input with or without time zone is parsed and converted automatically.
- Type compatibility: TIMESTAMPTZ and DATETIME can be converted mutually and work with existing functions.
This design moves time zone handling from the application layer into the database kernel, improving cross-system data consistency and reducing complexity when handling multi-time-zone data.
Summary
Apache Doris 4.1 is a meaningful step forward in building Apache Doris into a core data infrastructure for AI applications and real-time analytics. Vector search capability is expanded to large-scale data thanks to the introduction of IVF index. Native 100MB JSON document storage supports long-context AI conversations, and OLAP and lakehouse performance keeps its edge with measurable gains over 4.0.
Apache Doris 4.1 provides a unified data infrastructure solution to support AI and agent workloads, covering vector search, full-text search, real-time analytics, and a unified lakehouse, reducing the need for a separate stack of vector databases, search systems, and query engines.
- Documentation: https://doris.apache.org
- GitHub: https://github.com/apache/doris
Join the Apache Doris community and connect with Apache Doris experts and users. For a fully managed Apache Doris cloud service, contact the VeloDB team.