


TL;DR VeloDB and CocoIndex form a context stack that is precise, fresh, and traceable. VeloDB unifies semantic, keyword, structured, and JSON search in a single SQL query, replacing approximate vector-only retrieval with multi-signal ranking. CocoIndex gives the transformation pipeline memory at each step, only changes from the documents are reprocessed. The index stays current as sources change, and every passage traces back through the full chain of steps that produced it.
Introduction
An AI application does not answer questions from memory. It retrieves passages from your documents and feeds them to a language model. The model reasons over those passages and generates an answer. The answer is only as good as the passages it receives. Ask "What cybersecurity risks did Apple disclose last quarter?" and the system must find the right paragraphs from thousands of SEC filings, not just any paragraph that mentions cybersecurity.
In production, this context fails in three ways.
A compliance officer searches for "GDPR compliance" across SEC filings. The system returns passages about "data privacy regulations" and "European consumer protection." Close in meaning, but none mention GDPR by name. She narrows the search to filings from the past year. The system ignores it. Vectors have no concept of time.
A company retracts a risk disclosure on Tuesday. The index still serves it on Wednesday, Thursday, and Friday. A client calls about a risk that no longer exists. The reprocessing job runs on Sunday.
An AI answer leaks a customer's phone number. The team traces the passage back to its source file, but the file was scrubbed. Did the scrubber's regex miss this format, or did the chunker split the area code from the number? The system discarded every intermediate result. No one can tell.
CocoIndex and VeloDB form a two-layer context stack that addresses all three.
The Architecture of CocoIndex + VeloDB
The architecture splits into two layers. CocoIndex is the managed context layer: it owns the transformation pipeline, tracks what changed, decides what to reprocess, and records how every output was produced. VeloDB is the retrieval layer: it stores the results, indexes them across all signal types, and serves queries in real time.
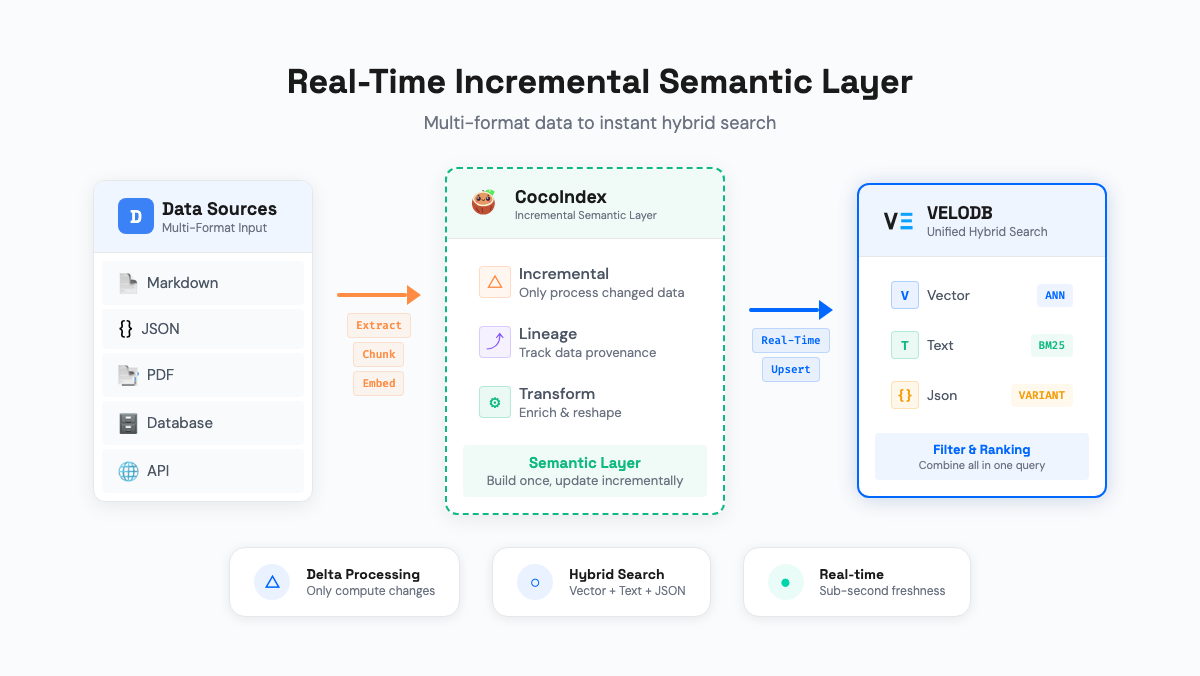
Together, these two layers address the three failures with three capabilities.
Search with keywords, dates, and categories in one query. VeloDB evaluates semantic similarity, keyword matching, structured filters, and JSON path queries in a single SQL pass. All signals are ranked together, not merged after the fact. Search for "GDPR compliance from the past year in filing documents" and get exactly that, not approximate semantic matches.
The context updates in seconds, not days. CocoIndex gives the transformation pipeline per-step memory: each step's input and output are stored alongside a fingerprint of the function logic. Only changed documents reprocess. Only affected steps re-run. Doris ingests the resulting deltas and makes them queryable within one second.
Trace any passage back to its source, step by step. The same per-step memory records every transformation's input and output as a structural property of the pipeline. When a passage returns unexpected results, trace backward through the chain: embedding, chunk, scrubbed text, raw source. CocoInsight makes this visual: click any field, see upstream dependencies in blue and downstream outputs in green.
How does each capability work under the hood?
Meaning, Keywords, Dates, and Categories in One Query at Any Scale
Vector search alone captures one of the four signals a precise query needs. An embedding converts a paragraph into a list of numbers that represent its general meaning. Similar topics produce similar numbers.
A 384-dimensional vector captures that a passage concerns "regulatory compliance." It does not separately encode that the passage mentions "GDPR" specifically, that it was filed in 2024, or that it is categorized as a risk disclosure. The numeric space flattens all these details into the same representation as the general topic.
The limitation extends beyond keywords: a compliance officer needs results from the past year, but vectors have no concept of time; a researcher needs risk disclosures, not earnings discussions, but both produce similar vectors.
One engine must evaluate all signals together in a single retrieval. VeloDB is that engine.
The typical alternative chains a vector database to a search engine to a relational store, with application code merging their results.
VeloDB removes that integration layer. As an HSAP system (Hybrid Search Analytical Processing), it stores vectors, inverted indexes, and columnar data in the same segment files, sharing write-ahead logs, segment builders, and flush operations. Search is not a separate system bolted onto an analytical database. It is a native SQL predicate evaluated during query execution.
A query for "cybersecurity risks from the past year, in filing documents" becomes one SQL statement:
WITH
semantic AS (
SELECT chunk_id, text, filing_date,
ROW_NUMBER() OVER (
ORDER BY l2_distance(embedding, @query_vector)
) AS sem_rank
FROM filing_chunks
WHERE filing_date > DATE_SUB(NOW(), INTERVAL 12 MONTH)
AND source_type = 'filing'
AND json_contains(topics, '"RISK:CYBER"')
LIMIT 100
),
lexical AS (
SELECT chunk_id,
ROW_NUMBER() OVER (
ORDER BY SCORE() DESC
) AS lex_rank
FROM filing_chunks
WHERE text MATCH_ANY 'cybersecurity risks breach'
AND filing_date > DATE_SUB(NOW(), INTERVAL 12 MONTH)
AND source_type = 'filing'
AND json_contains(topics, '"RISK:CYBER"')
LIMIT 100
)
SELECT s.chunk_id, s.text, s.filing_date,
1.0/(60 + s.sem_rank) + 1.0/(60 + l.lex_rank) AS rrf_score
FROM semantic s JOIN lexical l ON s.chunk_id = l.chunk_id
ORDER BY rrf_score DESC
LIMIT 20;
The 1/(60 + rank) formula is Reciprocal Rank Fusion (RRF), a rank-merging method that combines two rankings without requiring comparable scores. Documents that rank well on both semantic relevance and keyword presence rise to the top. No weight tuning required.
Each WHERE clause addresses a gap that vector search alone cannot fill.
MATCH_ANY finds passages mentioning "cybersecurity" by name, not just semantically related passages. filing_date > ... constrains to the past year.
source_type = 'filing' excludes JSON metadata and PDF exhibits.
json_contains(topics, '"RISK:CYBER"') filters to chunks tagged as cybersecurity risks during ingestion. Four signal types, one engine, one ranking pass.
This query evaluates four signals against a table. What happens when that table holds a billion rows?
For applications with deeply nested data, VeloDB provides the VARIANT type. JSON fields are automatically extracted into columnar subcolumns. A path like user.id becomes an independent BIGINT column, while sparse fields stay in compressed binary format. This delivers 160x faster JSON analytics than MongoDB and 1000x faster than PostgreSQL without requiring a separate flattening pipeline.
At production scale, the question shifts from "does hybrid search work?" to "does it scale to my data?" ByteDance faced this with billion-scale vector search. Their HNSW index for one billion 768-dimensional vectors originally required approximately 10TB of memory across 20 to 30 servers. Using IVPQ compression (Inverted File + Product Quantization), they reduced this to 500GB on a single server, a 20x memory reduction, while maintaining 92% recall at p95 latency of 400ms.
Query and ingestion performance scale together. VeloDB achieves 989 QPS at over 97% recall on million-scale vector benchmarks, and sustains 10 GB/s ingestion throughput with sub-second write-to-query latency. Parallel HNSW construction across cluster nodes keeps ingestion speed constant as tables grow: a table with 10 million vectors ingests new batches at the same speed as a table with 1 million.
VeloDB can ingest new data in under a second, but that speed only helps if the pipeline feeding it knows what changed. That is the problem CocoIndex solves.
Changed Documents Sync in Seconds
Reprocessing an entire corpus to update a few hundred documents wastes over 99% of the compute. A knowledge base has 100,000 documents and roughly two million indexed passages. Today, 200 documents changed. The pipeline reprocesses all 100,000. Every document re-enters the chain from step one. Every embedding is regenerated.
The efficient response would be surgical: only the 200 changed documents enter the pipeline, and within the chain, only the steps whose inputs changed re-run. This requires per-step memory: a record of what each transformation produced in the previous run, so the system can compare each step's current input against its last input and decide whether to reprocess or reuse.
Most pipelines do not store intermediate results. They process documents end to end and discard everything except the final output. Without per-step memory, cost scales with the total corpus, not with the rate of change. Teams reprocess weekly. Between runs, the index drifts. A document updated Tuesday returns Monday's content until Sunday's run. Staleness and cost reinforce each other, a loop with no good equilibrium.
CocoIndex breaks this loop. It transforms the pipeline from a stateless script into a stateful system. When a document changes, only that document enters the pipeline. Within the pipeline, only the steps whose inputs changed re-run. The 200 changed documents generate roughly 4,000 new embeddings instead of two million. Compute cost becomes proportional to the rate of change, and the index updates within minutes.
CocoIndex achieves this through cached transformations. Each function in the pipeline is decorated with a caching directive:
@cocoindex.op.function(cache=True, behavior_version=1)
def scrub_pii(text: str) -> str:
"""Remove personally identifiable information."""
# ... scrubbing logic ...
cache=True stores the function's output alongside a fingerprint of its input. On the next run, if the input has not changed, the cached output is returned without re-executing the function. behavior_version tracks the logic itself. Bump the version number when you change the function's behavior, and CocoIndex automatically recomputes all affected outputs. A version bump triggers reprocessing for all documents at that step and every downstream step, the same targeted recomputation, applied to logic changes instead of data changes.
This is not application-level caching. It is per-step memory built into the pipeline's execution model. The system knows what every transformation produced in the previous run, compares against the current input, and makes a precise decision: reprocess or reuse.
Deletions are equally precise.When a paragraph is removed from a document that still exists, the chunks derived from that paragraph disappear from the index while the rest of the document's entries remain. CocoIndex's tracking records map each index entry back to the specific content that produced it. No orphaned vectors. No ghosts lingering until the next run
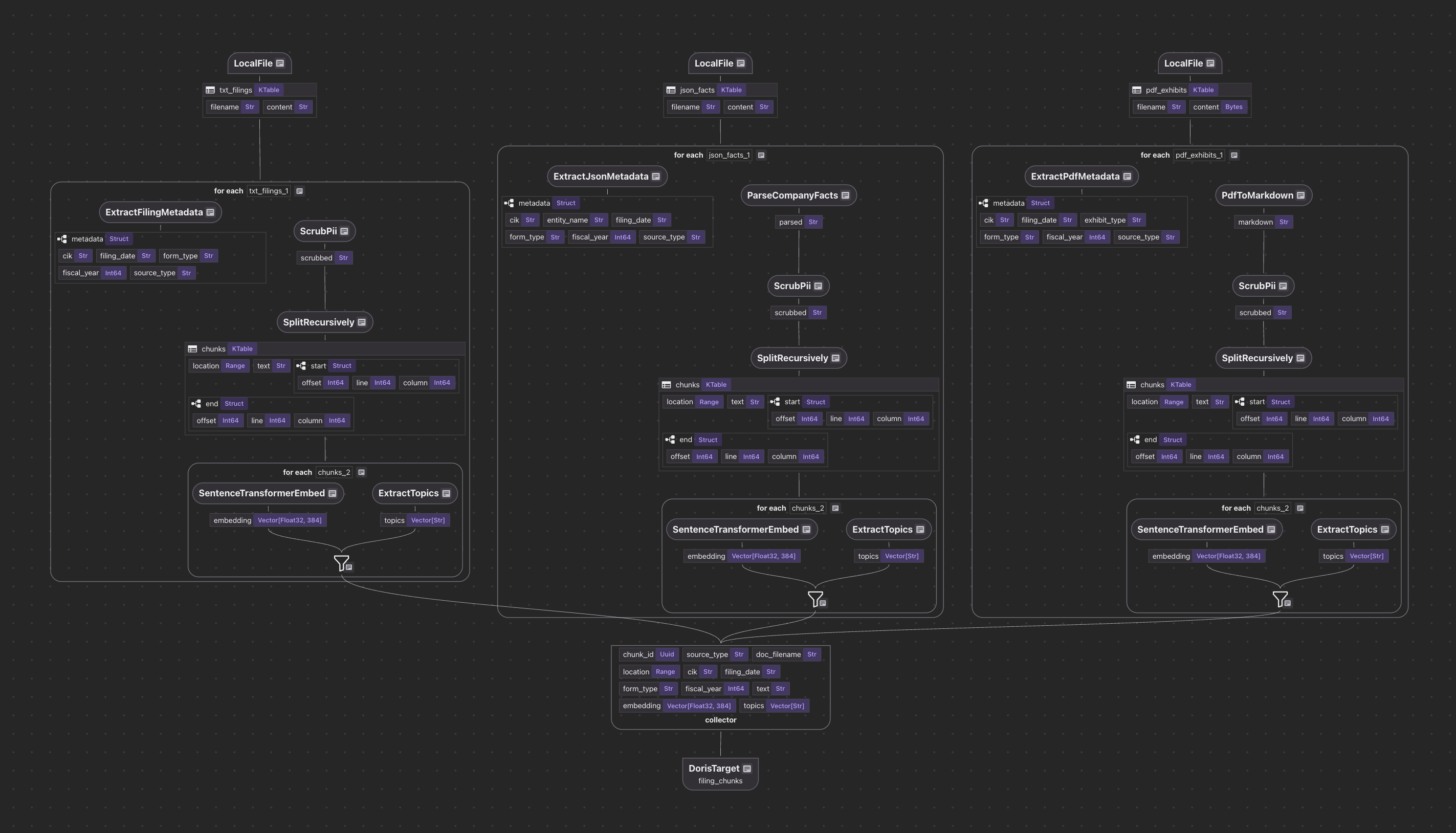
Multi-source ingestion works through a unified collector pattern. Different data formats (text files, JSON APIs, PDFs) each have their own source definition and parsing logic, but all feed into a single collector that writes to the target:
@cocoindex.flow_def(name="SECFilingAnalytics")
def pipeline(flow_builder, data_scope):
# Sources
data_scope["filings"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="data/filings", included_patterns=["*.txt"])
)
data_scope["facts"] = flow_builder.add_source(
cocoindex.sources.LocalFile(path="data/company_facts", included_patterns=["*.json"])
)
# Single collector: all sources merge here
collector = data_scope.add_collector()
# TXT filings: extract metadata from filename, then process
with data_scope["filings"].row() as filing:
filing["metadata"] = filing["filename"].transform(extract_filing_metadata)
process_and_collect(filing, "content", filing["metadata"], collector)
# JSON facts: parse structured data into searchable text
with data_scope["facts"].row() as facts:
facts["metadata"] = facts["filename"].transform(
extract_json_metadata, content=facts["content"]
)
facts["parsed"] = facts["content"].transform(parse_company_facts)
process_and_collect(facts, "parsed", facts["metadata"], collector)
# Export to VeloDB
collector.export(
"filing_chunks",
DorisTarget(host=..., port=..., database=..., table=...),
primary_key_fields=["chunk_id"],
vector_indexes=[
cocoindex.VectorIndexDef(
field_name="embedding",
metric=cocoindex.VectorSimilarityMetric.L2_DISTANCE,
)
],
fts_indexes=[
cocoindex.FtsIndexDef(field_name="text", parameters={"parser": "unicode"})
],
)
Each source is processed independently. The collector handles deduplication and target management. For the full working example with SEC EDGAR filings, including TXT, JSON, and PDF ingestion with four search modes, see the tutorial notebook.
The end-to-end path closes the staleness loop. A source document changes. CocoIndex detects the delta, reprocesses only the affected documents and steps, and produces new embeddings in minutes. VeloDB ingests those embeddings and makes them queryable in under a second. Freshness is no longer traded against cost.
Incremental updates keep the index current, but they also create a new question: when a passage produces unexpected results, how do you trace it back through the chain of transformations that produced it?
Trace Any Passage Through Every Step That Shaped It
A passage in the index is not a copy of the source document. It is the end product of several transformations: the pipeline extracted text, scrubbed sensitive data, split the text into chunks, generated embeddings, and assigned topics. Every step shaped the final result. Most pipelines record none of this. The source file exists. The final passage exists. Everything in between was computed and discarded.
This matters when something goes wrong. A passage contains an unredacted phone number. Did the scrubber's regex fail to match this format, or did the chunker split the text between the area code and the number? Without intermediate outputs, you cannot tell.
It matters equally when something changes: you improve the topic classifier, but without a record of which function version produced each passage's topics, you must re-run the full chain to re-classify. The pipeline did not store the intermediate output that feeds the classification step.
Every step's input and output are already preserved; the same mechanism that enables incremental updates also enables debugging. For debugging, this means any output field can be traced backward through the full transformation chain:
embedding (384-dim vector)
← generated from: text chunk "We face significant cybersecurity risks..."
← split from: scrubbed content (PII removed)
← scrubbed from: raw filing text
← extracted from: 0000320193_2024-11-01_10-K.txt
CocoInsight makes this lineage visual and interactive. The interface presents two panels: the right panel shows the dataflow graph (every transformation step, connected by data dependencies), and the left panel shows the actual values at each step, cell by cell.
An embedding produces unexpected search results. You click the embedding field in CocoInsight. The upstream chain highlights in blue: the text chunk that was embedded, the scrubbed text it was split from, the raw source it was extracted from. You inspect the actual data at each step. The scrubber mangled a sentence? You see it. The chunker split mid-sentence? You see it. The black box is open.
CocoIndex's dataflow model enforces this traceability by design. Every transformation creates new fields solely from input fields, with no hidden state and no value mutation. Lineage is not reconstructed from logs. It is the execution model itself.
The remaining question is when to adopt this architecture and when simpler alternatives suffice.
When This Architecture Fits
Your context goes stale, and freshness carries consequences. Most use cases tolerate nightly or weekly reprocessing. But when source data changes daily and stale results affect compliance decisions, clinical lookups, or customer-facing answers, the gap between runs becomes the gap in your product. If "the index is stale" has appeared in incident reports, incremental indexing addresses the root cause.
Search requires combining capabilities that currently live in separate systems. Your application needs semantic understanding, keyword precision, date filtering, and structured queries. Delivering that today means running a vector database, a search engine, a relational store, and application logic to merge results. If the integration complexity is the reason search quality remains a known limitation, a single engine that handles all four signals makes the capability achievable.
You need to trace a bad answer back to its source. When a passage produces wrong results, someone must determine whether the embedding was misleading, the chunk boundary was wrong, or the scrubber mangled the text. If your debugging process today is "re-run the pipeline and hope to reproduce it," transformation lineage replaces guesswork with a clickable chain from output to source.
For a working implementation covering multi-format SEC filing ingestion, four search modes (hybrid, lexical, topic-filtered, portfolio comparison), and row-level access control, see the tutorial notebook.
Ready to build production-grade search? Start with VeloDB Cloud for unified hybrid search. For incremental indexing with built-in lineage, explore CocoIndex on GitHub and CocoIndex Documentation.


