



Multimodal data is becoming a priority for enterprises across industries, but most teams are still figuring out how to manage it at scale. Autonomous driving is one domain where this challenge is already being solved in production: images, point clouds, video, signals, and structured metadata all flow through the same pipelines every day. The lessons learned in the Autonomous driving domain have applications far beyond self-driving cars.
This blog will walk through how one autonomous driving company rebuilt its data platform around Apache Doris, unifying four types of search into a single engine and cutting query times from minutes to seconds.
The Scale of the Problem
This use case comes from a leading autonomous driving technology company that provides advanced driver assistance systems (ADAS) and high-level autonomous driving (AD) solutions for passenger vehicles. The company's product integrates algorithms, software, and dedicated computing platforms to cover the full pipeline from sensor perception through decision-making to vehicle control, improving both driving safety and the in-cabin experience.
The company's solutions are now deployed across multiple production vehicle models from OEM partners. Through these large-scale deployments, the company has accumulated massive volumes of real-world road data and built a data-driven R&D system around it.
The company generates hundreds of terabytes of new data daily, with total storage measured in petabytes. After segmentation and cleaning, raw sensor data becomes "clips": sequences of consecutive frames enriched with metadata. The clip count has crossed hundreds of millions, and the corresponding number of training frames is in the tens of billions.
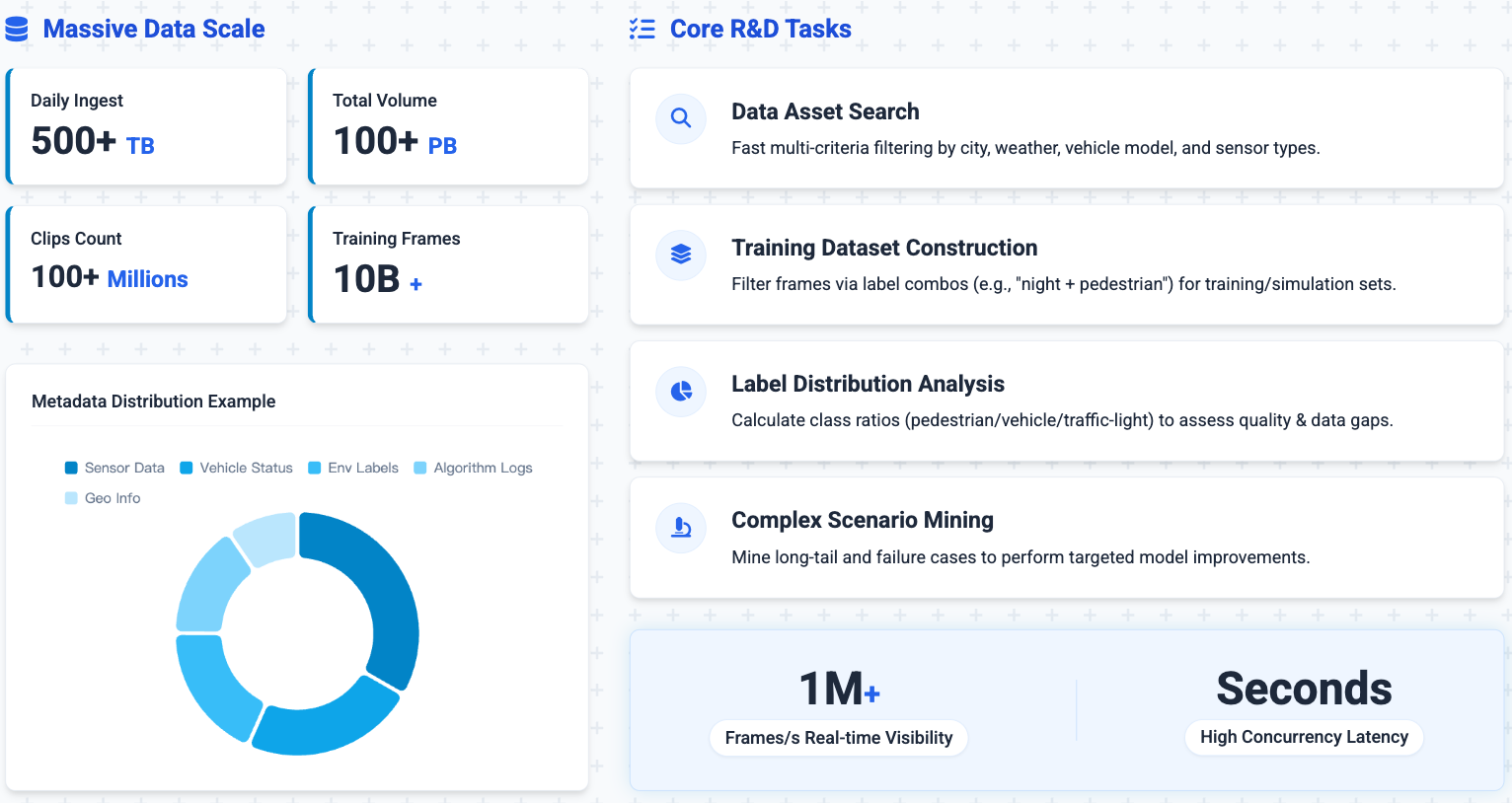
Algorithm engineers interact with this data constantly. Their daily work includes:
-
Data asset retrieval: finding clips by city, weather, vehicle model, sensor type, and dozens of other attributes.
-
Training set construction: filtering frames by label combinations (for example, "night + pedestrian") to build new training or simulation test sets.
-
Label distribution analysis: calculating the proportion of each label type (pedestrians, vehicles, traffic lights) across a dataset to evaluate quality and identify gaps.
-
Hard example mining: searching for long-tail scenarios or cases the model misjudged, so engineers can target those weaknesses in the next training cycle.
These workflows demand real-time performance: visibility into one million frames per second and sub-second response times under high query concurrency.
Four Modes of Multimodal Search
What makes autonomous driving data uniquely challenging is the sheer variety of data types that all need to be searchable: images, point clouds, video, labels, logs, and structured or semi-structured metadata. Nearly every data task boils down to search, and those search requirements fall into four categories.
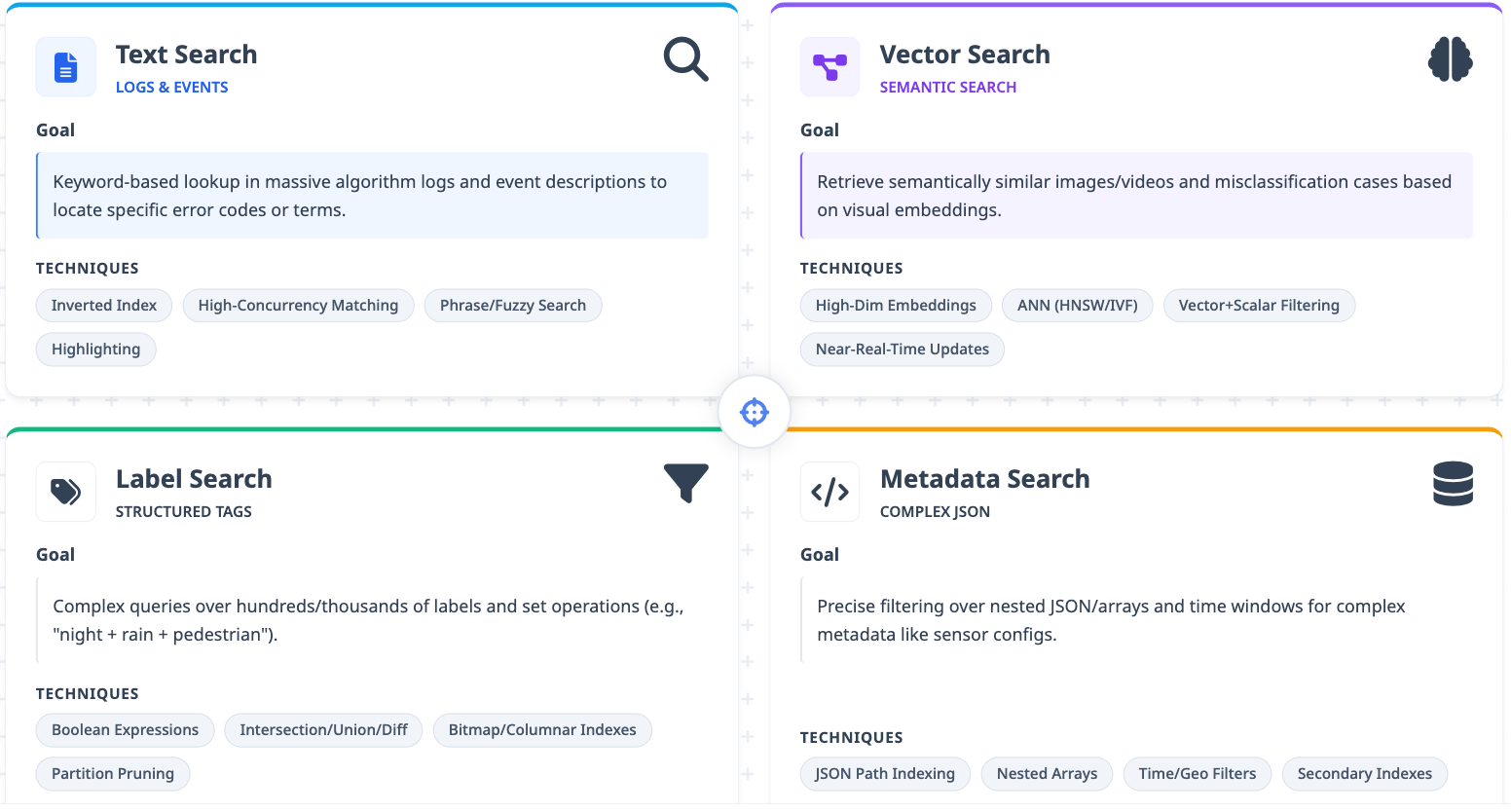
Text retrieval solves the problem of finding data that contains specific keywords, like error codes in logs or specific terms in event descriptions. It relies on inverted indexes and prioritizes efficient keyword matching.
Vector retrieval addresses semantic similarity. Vision-language models and deep learning feature extractors convert images and video into high-dimensional vectors. Engineers use vector search to find historically similar scenarios: past instances of a dangerous driving situation, or cases where the model made similar mistakes. The focus here is meaning, not exact keyword matches.
Label retrieval handles the structured annotations attached to each training frame: "contains pedestrian," "night scene," "rainy day," and so on. Engineers routinely construct datasets through label combinations ("complex intersection + traffic lights"), and label dimensions can reach into the hundreds or thousands. The system needs to support fast set operations (intersection, union, difference) across these labels.
Metadata retrieval covers the semi-structured data that accompanies every collection run: vehicle configuration, software version, sensor calibration, fault records, typically stored as JSON with complex nested structures. Engineers need to filter precisely within this data, for instance finding all collections where a specific vehicle model experienced a particular fault within a given time window.
Supporting all four search modes at massive scale is the core architectural challenge.
The Problem with Separate Systems
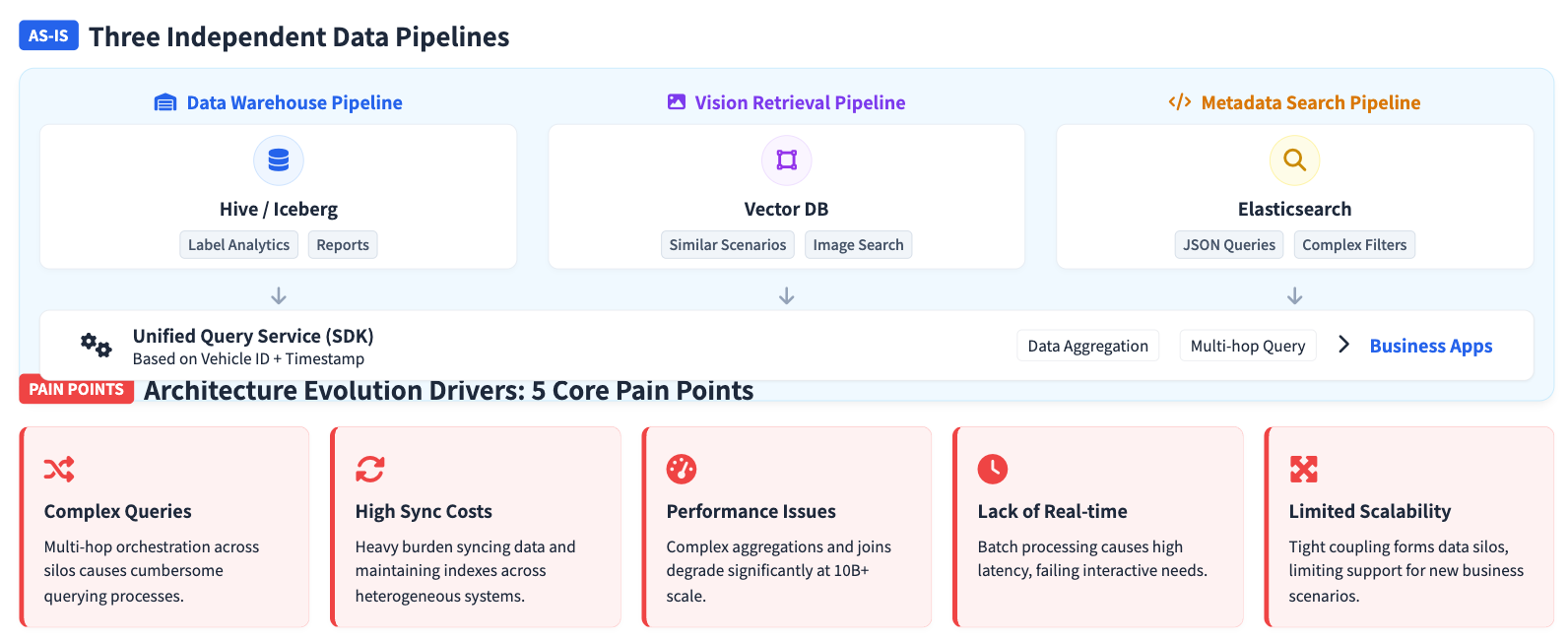
To handle these different data types, the company originally built three independent processing pipelines:
A batch data warehouse pipeline. Structured tags flowed through ETL into Hive/Iceberg for label analysis, statistical reports, and dataset construction. This pipeline ran in batch mode with high latency, making it poorly suited for interactive exploration.
An image and text retrieval pipeline. Vector features extracted from video frames were stored in a dedicated vector database (Zilliz), supporting hybrid vector-plus-scalar retrieval for similar scene mining. But the vector database was completely separate from the data warehouse, and cross-system queries required moving data between them.
A metadata retrieval pipeline. Vehicle status, event records, and other metadata lived in Elasticsearch, leveraging its JSON search capabilities. But ES struggled with complex aggregations at massive scale and could not perform unified analysis with the label store.
A query service layer sat above all three, but real workflows still required engineers to hop between systems. A typical task might start with filtering data assets in the metadata system, then analyzing label distributions in the data warehouse, then searching for similar scenarios in the vector database. This multi-system serial process was slow and complex. Data synchronization across three platforms drove up operational costs, and any schema change required coordinated updates everywhere. As data grew into the hundreds of billions of records, all three systems faced growing pressure on query performance and scalability.
Unifying Multimodal Search on a Single Engine
The company had already adopted Apache Doris to handle label search and analysis. Doris performed well in this role: its vectorized execution engine and MPP architecture efficiently supported real-time aggregation and filtering across tens of billions of labels, a capability proven in large-scale internet user profiling and audience targeting. Once the team used Doris for label-combination queries on training frames, dataset construction became significantly faster.
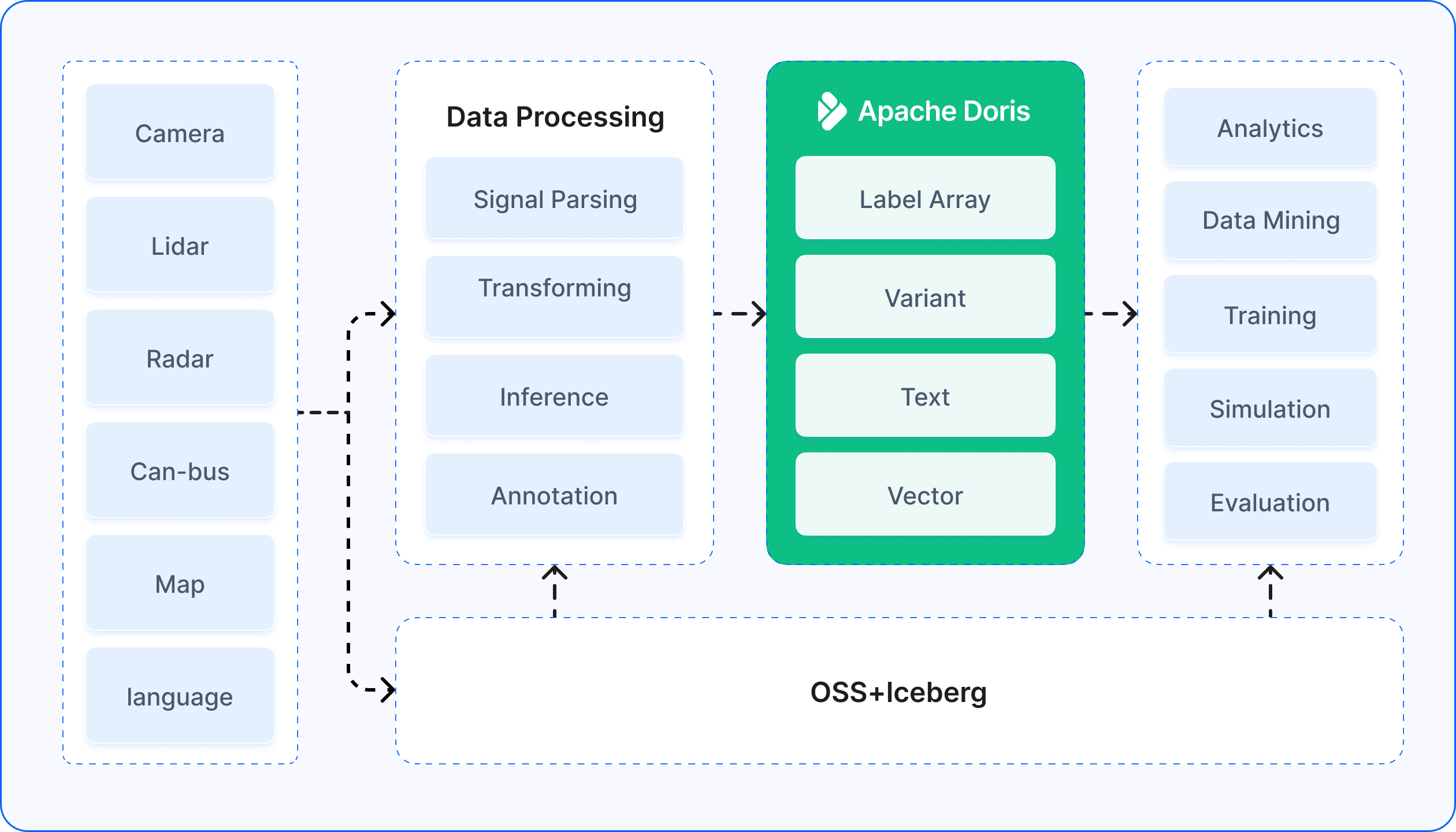
As Apache Doris expanded its capabilities to include full-text search (via inverted indexes), vector indexing, and efficient semi-structured data processing (including native JSON support), the company saw an opportunity. They began migrating toward a unified architecture with Apache Doris as the single multimodal search and analysis engine, consolidating data that had been scattered across the data warehouse, vector database, and Elasticsearch. Five design principles guided this migration:
Cold and hot data tiering. Recent, frequently accessed data lives in high-performance online storage, optimized for concurrent queries through time-based partitioning and device-based bucketing. Historical data migrates to a lower-cost data lake (Iceberg) for long-term retention. Federated query capabilities let users access both tiers transparently through the same interface.
Optimized metadata retrieval. For JSON-formatted metadata, Apache Doris provides a specialized Variant data type that stores JSON natively and combines it with inverted indexes for efficient retrieval. Complex nested fields can be expanded directly in SQL and filtered with arbitrary conditions, keeping billions of metadata records responsive.
Accelerated label set operations. Frame-level labels are modeled using Bitmap data structures: each label maps to a bitmap of frame IDs, and label-combination queries become set operations (intersection, union, complement) on those bitmaps. This approach achieves second-level response times for complex scenarios even at tens-of-billions scale. Real-time writes in the primary key model ensure new label data becomes visible within seconds, handling hundreds of billions of label updates per day.
Integrated vector retrieval. The platform embeds vector indexing natively, storing image and text feature vectors alongside scalar data. This enables mixed retrieval across vectors, labels, and metadata in a single query, eliminating the data transfers that slowed down similar-scenario mining and laying the groundwork for true multimodal joint queries.
A unified query engine. A single SQL interface accesses all data types: tags, metadata, and vectors. Engineers complete complex data exploration in one query without switching systems. Unified index and storage management also cuts development and operational overhead significantly.
Results
After this migration, the company saw measurable improvements across the board:
Query performance jumped from minutes to seconds. Algorithm engineers can now explore data distributions under different label combinations in real time, making interactive analysis practical for the first time.
Data preparation cycles shortened dramatically. Dataset sampling shifted from offline batch processing to real-time interaction, compressing what used to take hours into minutes.
The platform scales to production demands. The unified system stably supports retrieval across nearly one trillion records over a seven-day window and handles concurrent loads approaching 1,000 QPS.
Operational complexity dropped. A single data engine now handles scalar, JSON, and vector retrieval, replacing three separate systems and eliminating the synchronization and maintenance burden that came with them.
Takeaways
In autonomous driving, the core data platform challenge is building a unified system that can process text, vectors, labels, and metadata simultaneously while supporting efficient retrieval and analysis at a massive scale. Moving from a fragmented architecture to a converged one does not just improve query performance and developer productivity; it creates the foundation for more intelligent, data-driven R&D workflows.
These lessons extend well beyond self-driving cars. Any industry dealing with multimodal data at scale (smart cities, industrial quality inspection, content recommendation, and increasingly, AI agent infrastructure) faces the same architectural choice. A unified real-time analytics platform like Apache Doris offers a proven path forward.
Join the Apache Doris community and connect with Doris experts and users. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.


