As we step into the Thanksgiving season, we want to extend our heartfelt gratitude to everyone in the Apache Doris and VeloDB community. Thank you to all the users, developers, engineers, and partners who continue to support, build, and grow with us. Your trust, contributions, and collaboration are what make this community thrive.
Wishing you and your loved ones a joyful and restful holiday. Happy Thanksgiving!
As we wrap up the month, we've gathered some of the highlights, updates, and user stories you may have missed.
Highlights
1.AI-Ready with Vector Search, AI Functions, and Hybrid Search:
- Vector Search: Doris 4.0 introduces vector indexing to support vector search. This allows users to do vector search, as well as regular SQL analytics directly in Apache Doris, with no need for external vector databases.
- AI Functions: These functions allow data analysts to call large language models directly via SQL for tasks like information extraction, sentiment analysis, and text summarization, all within Doris. Less glue codes and cleaner pipelines.
- Hybrid Search and Analytics Processing (HSAP): Doris 4.0 combines vector search, full-text search, and structured analytics all in one engine. This unified approach enables precise keyword search, semantic matching, and complex analytical queries to run seamlessly in a single SQL workflow, without external systems or duplicated data.
2.Better Full-Text Search:
A brand-new SEARCH() function brings a lightweight DSL syntax similar to Elasticsearch Query String, offering faster, more flexible, and easier-to-use text retrieval.
3.Stronger ETL/ELT:
Doris 4.0 introduces a new Spill Disk feature to improve heavy ETL/ELT processing and multi-table materialized views. The feature automatically writes intermediate data to disk when memory limits are exceeded, ensuring greater stability and fault tolerance for large-scale ETL tasks.
4.Performance Optimization:
Doris 4.0 delivers major performance gains through TopN lazy materialization and SQL cache improvements. TopN queries now execute up to dozens of times faster in certain wide-table scenarios. We also improved SQL cache, now enabled by default, achieving a 100x improvement in SQL parsing efficiency.
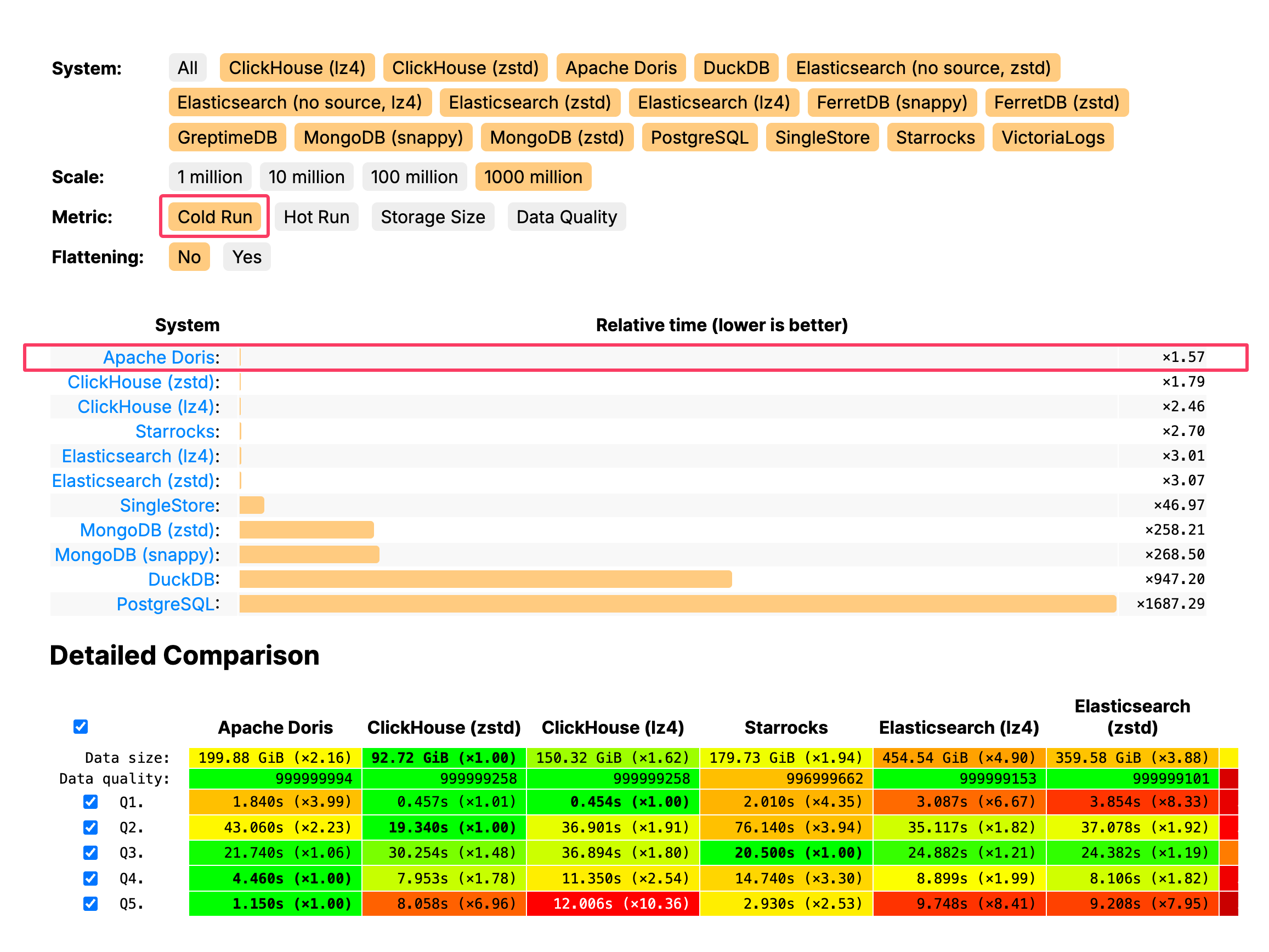
Apache Doris Tops JSONBench in Cold Queries and Data Quality
Apache Doris ranked first in cold queries in the latest JSONBench test.
It is about 2x faster than Elasticsearch, 160x faster than MongoDB, and over 1,000× faster than PostgreSQL in cold queries.
Event Recap
1.Apache Doris Summit 2025 has successfully wrapped up!
This year, we brought together some of the most exciting discussions around AI and real-time data:
- Matt Yi, Apache Doris PMC Member, introduced several AI-related features in Apache Doris 4.0, including Vector Search, and shared insights on MCP Server, Full-Text Search, Hybrid Search, and new AI functions.
- Aranya Singh Chauhan demonstrated how OneXtel leveraged the Doris MCP Server to enable users to interact with data through natural language, transforming complex queries into instant business insights.
- Vadim Opolski walked us through how to build a streaming AI pipeline with Apache Doris to analyze social post sentiments, tackling real-world challenges like unstable throughput & latency, event delivery, consistency, schema evolution, and more.
- Parth Soni showcased real-world data platforms built on Doris, including an AI-native real-time feature store (70% cheaper than the DynamoDB/Redis combo), AI-powered intelligent log analytics, and data platforms with intelligent archival.
2. OSA CON 2025
Apache Doris PMC Chair and VP of Engineering at VeloDB, shared how Apache Doris is embracing the shift toward agent-facing analytics in the AI era. Building on its strong customer-facing analytics capabilities, Apache Doris now also powers agent memory and observability.
3. Webinar: Data Analytics in the Agentic AI Era: From User-Facing to Agent-Facing
Apache Doris PMC member has walked us through how Doris is evolving to support AI-driven analytical workloads, including hybrid search (vector search, full-text search, structured filters), LLM functions, and MCP Server. He also shared several real-world user stories on how Doris powers LLM observability, ChatBI, RAG, and GraphRAG scenarios.
4. Webinar: VARIANT Explained: Comparing JSON Analytics in Apache Doris, Iceberg, Elasticsearch, Snowflake, and ClickHouse
Apache Doris PMC member has walked us through the challenges of semi-structured data analytics and the different approaches taken across the industry:
- How do Elasticsearch, Snowflake, Apache Doris, ClickHouse, and Apache Iceberg handle JSON objects with 1K or even 10K fields?
- How do they deal with field type changes?
- How do they index extracted columns in VARIANT?
- And how do they allow users to define schemas for specific fields?
The speaker also introduced how the VARIANT data type is used in Apache Doris—from creating tables to running queries—and explained how VARIANT powers use cases in observability, IoT, SaaS, and more. Finally, theres' a demo using the VARIANT data type with a real-world dataset.
New Blogs
- Building Real-Time Lakehouse with S3 Tables, AWS Glue, and Apache Doris
- Kafka Visual Ingestion Tool: No-Code Import from Kafka and Confluent to VeloDB
- From OneLake to Insights: Building Modern Analytics with Apache Doris and Microsoft Fabric
- Introducing VeloDB Kafka Connector: Turn Kafka Streams into Real-Time Analytics
- Apache Doris Achieves 70% Better Price-Performance on ARM-based AWS Graviton
Want more VeloDB?
- Start your free trial
- Follow us on LinkedIn
- Join our Slack community to connect with developers and users around the world
- Have questions, feedback, or ideas? Drop us a message through our Contact Us form