



We're excited to introduce the Kafka Visual Ingestion Feature, a no-code visual feature within VeloDB Cloud that helps you ingest data from Confluent Cloud (a managed cloud service powered by Kafka) into VeloDB Cloud (a managed cloud service powered by Apache Doris).
The Kafka Visual Ingestion Feature is built into VeloDB Cloud, part of our broader Visualized Ingestion capabilities. It pulls data from Kafka or Confluent Cloud directly into VeloDB Cloud via an intuitive, no-code interface. The ingestion feature is different from the VeloDB Kafka Connector (learn more), which is deployed inside Confluent Cloud and pushes data into VeloDB Cloud. These two features serve different roles within the overall Confluent and VeloDB integration plan, designed to give users flexibility depending on their architecture.
The Kafka Visual Ingestion Feature operates natively within VeloDB Cloud, turning Routine Load tasks into an intuitive visual workflow. The feature provides a visual way to connect to various data sources on Confluent Cloud, supports private network connectivity (e.g., AWS PrivateLink) and multi-scenario authentication (SASL_PLAIN, SASL_256/512), and various data formats like JSON and CSV.
With the feature, you can configure the ingestion from Confluent to VeloDB without writing SQL, lowering the barrier to using real-time data ingestion and helping more teams to enjoy the real-time analytics power of Apache Doris in VeloDB Cloud.
Demo: Using Kafka Visual Ingestion Feature for Real-Time Streaming Data Ingestion
Follow our demo below to see how to use the Kafka Visual Ingestion Feature in VeloDB Cloud:
First, we use Confluent Cloud's built-in "Orders" sample data, which continuously generates and writes data to a specified Topic. Next, with just a few simple configurations in VeloDB Cloud, we launch an ingestion job that streams real-time data from the Topic directly into a data warehouse.
1. Environment Preparation
A. Create a Cluster on Confluent Cloud:
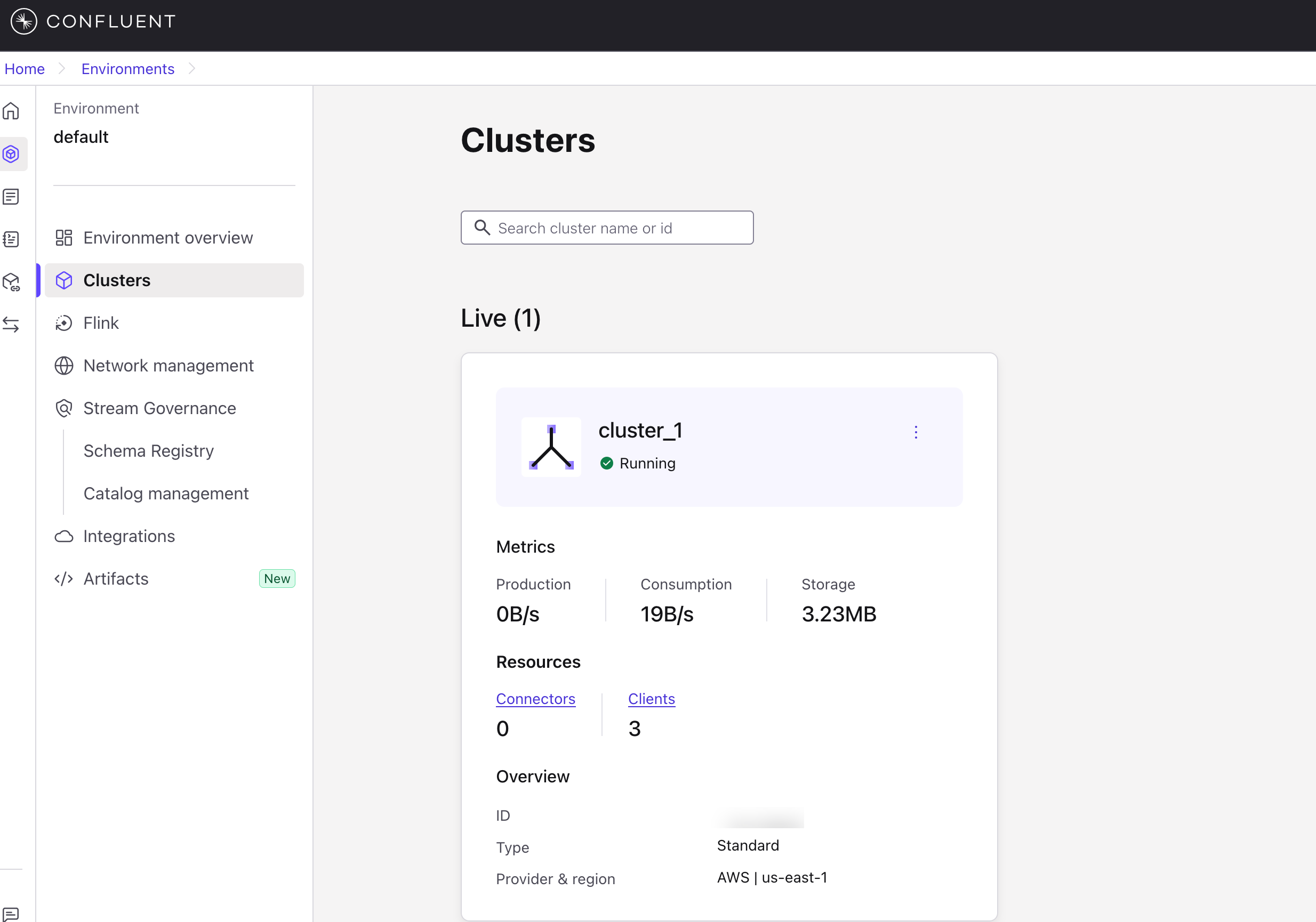
B. Create a Warehouse and Cluster on VeloDB Cloud
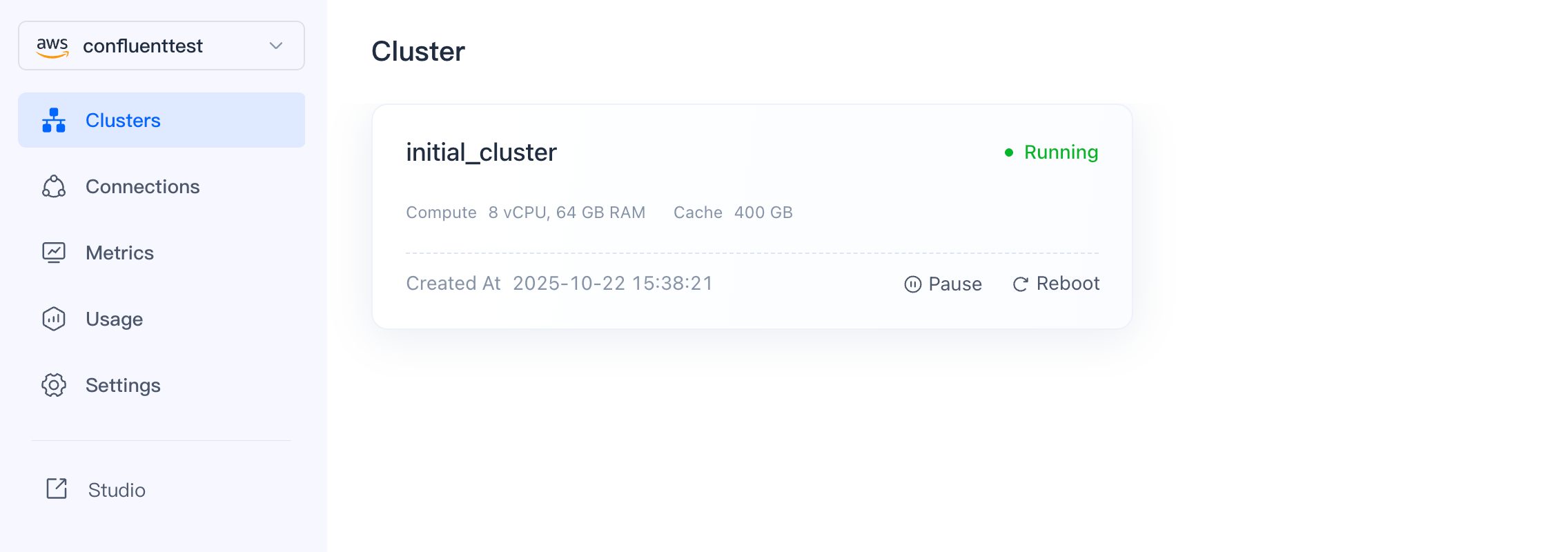
Note: Both must be located in the same region.
2. Start the Sample Data Source in Confluent Cloud
On the Connectors page, select "Sample Data," then choose "Orders."
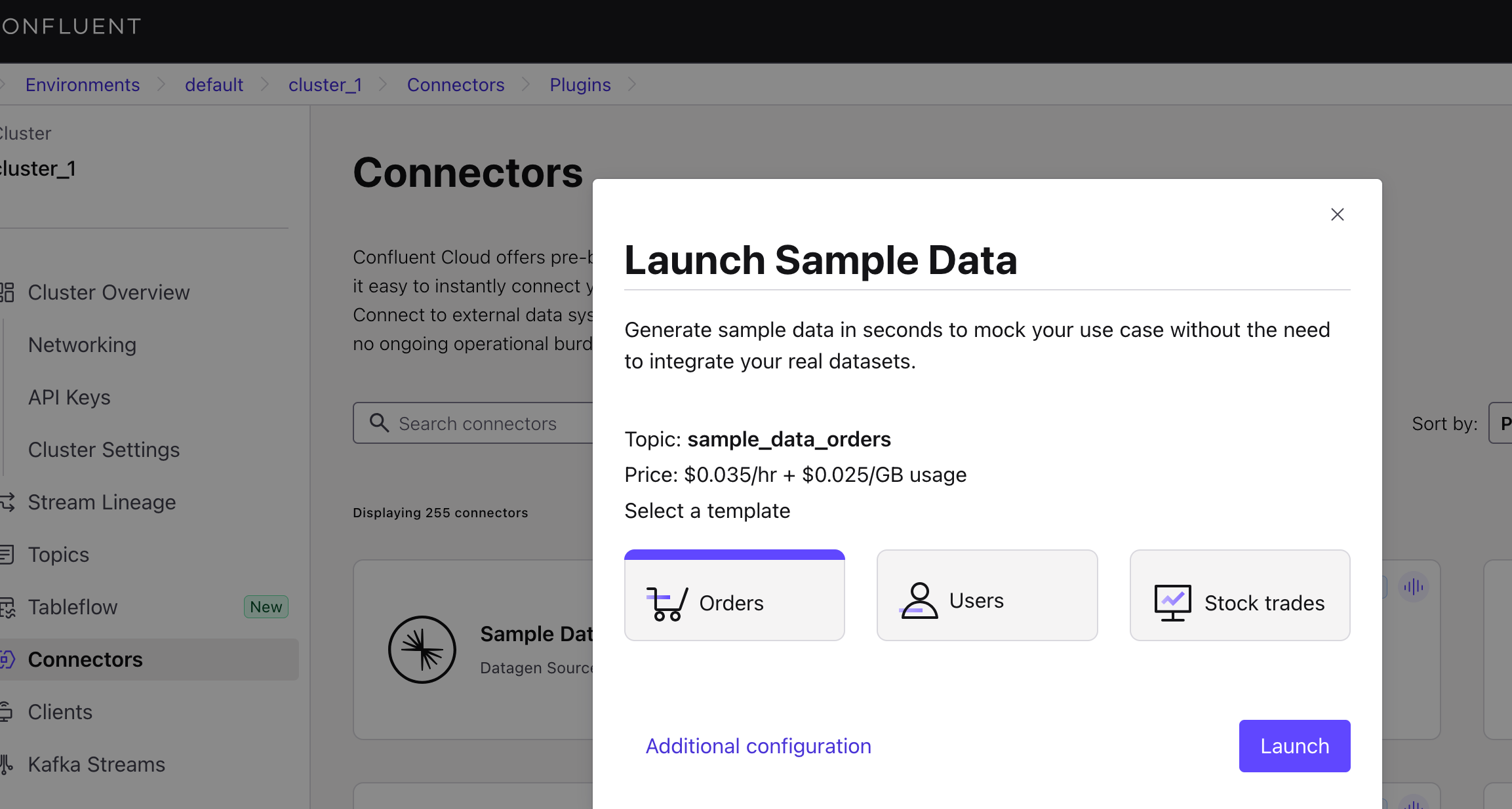
Click Additional configuration, create a Topic, and select the Format (we are using JSON for this demo).
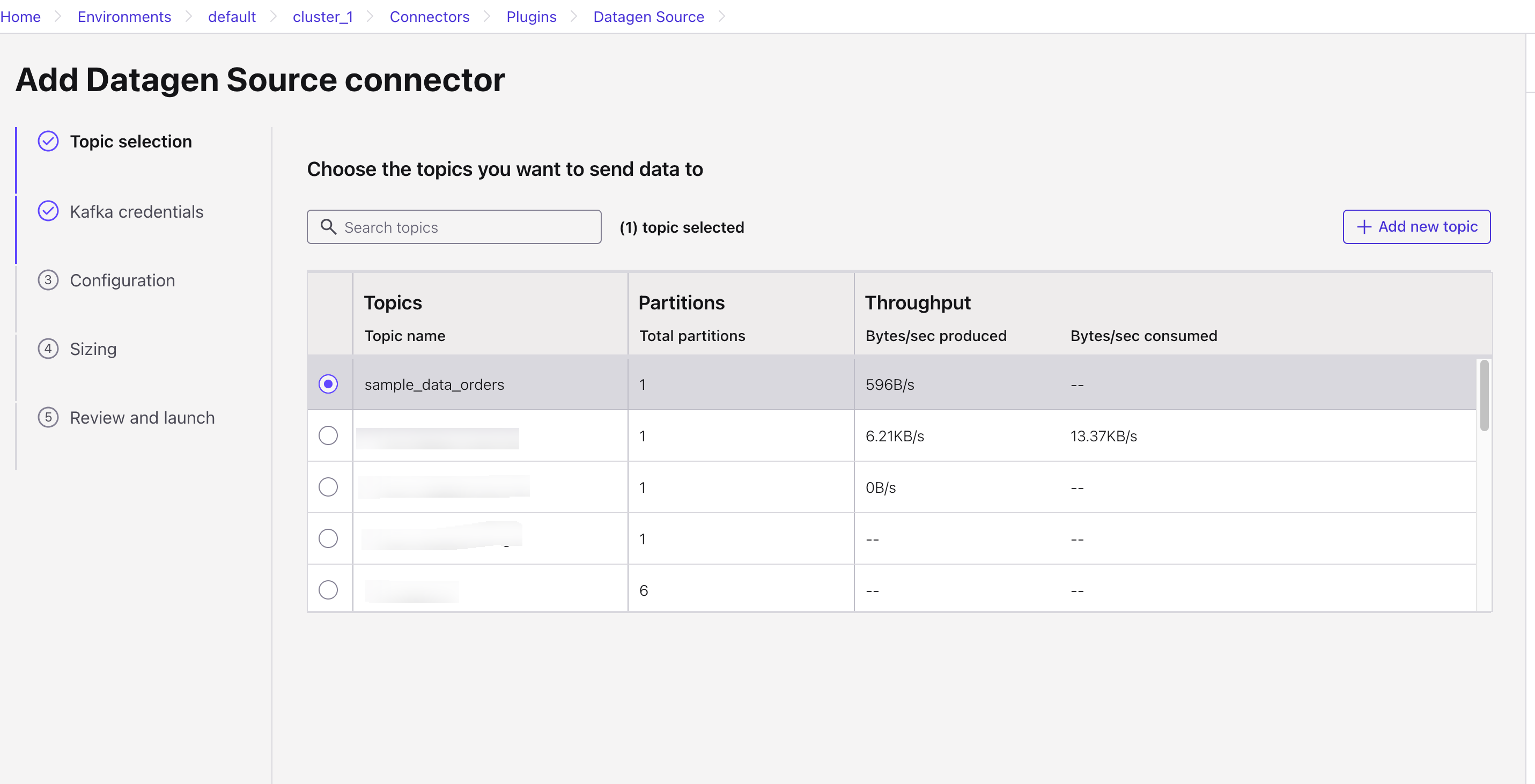
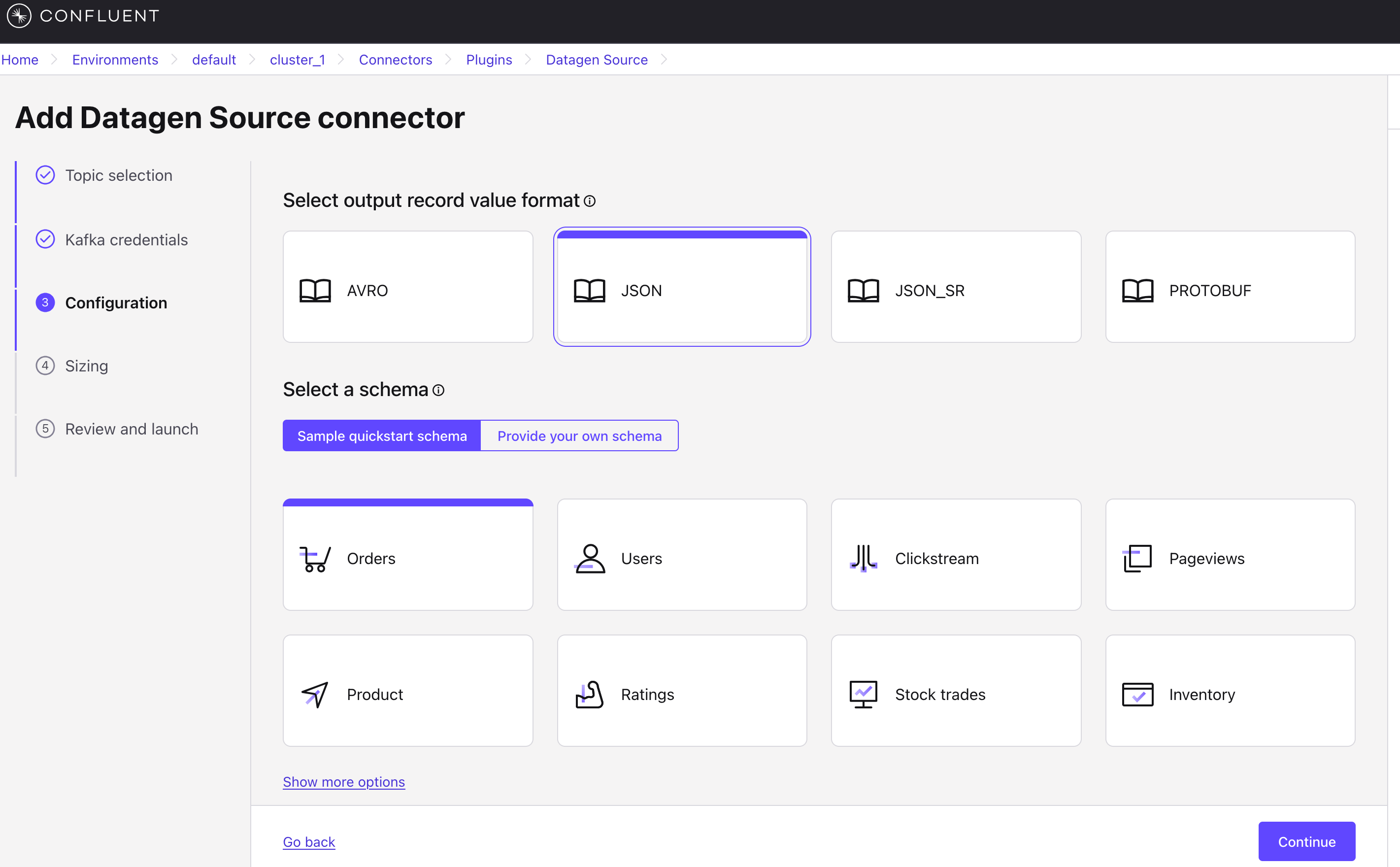
Submit the configuration after completion.

You can view the generated data in the Topic.
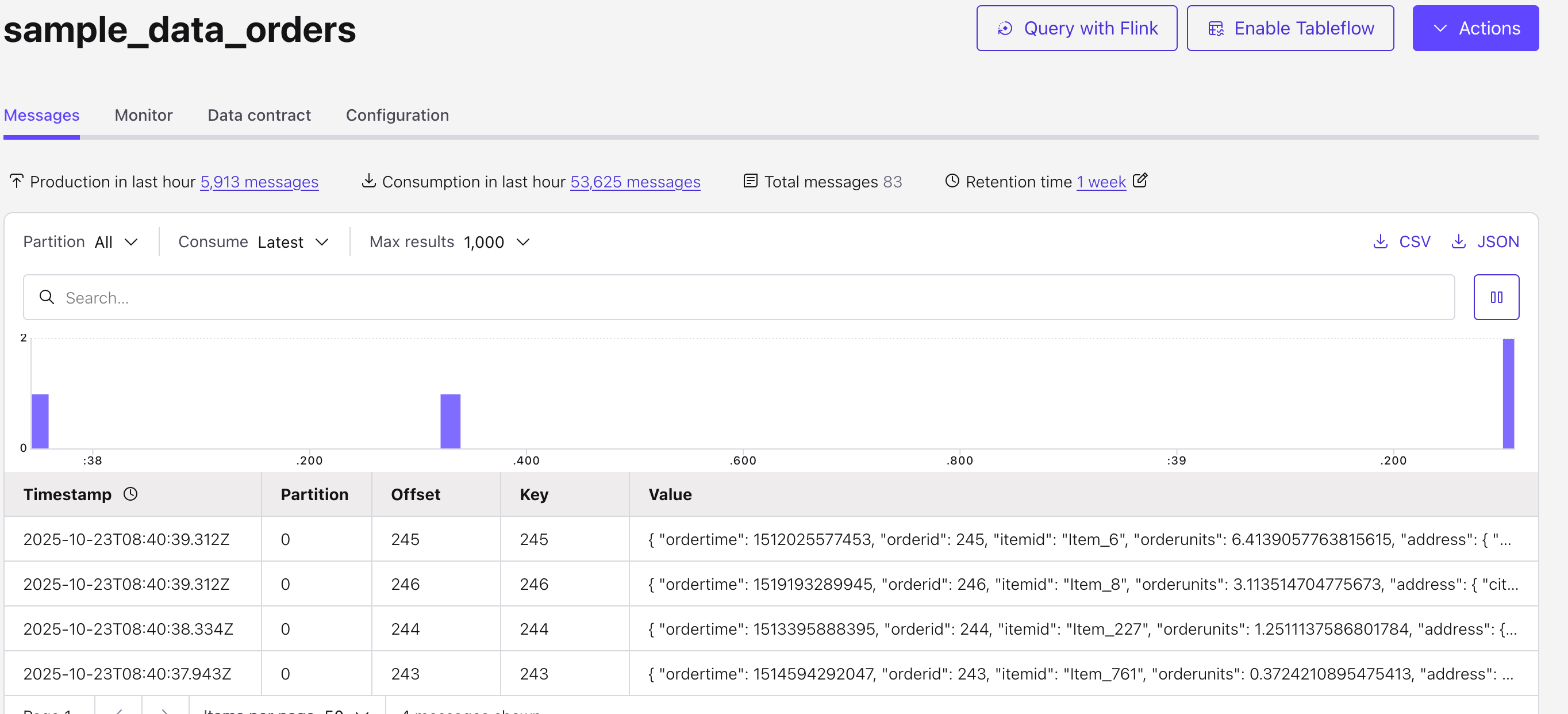
3. Set up the Ingestion Job in VeloDB Cloud
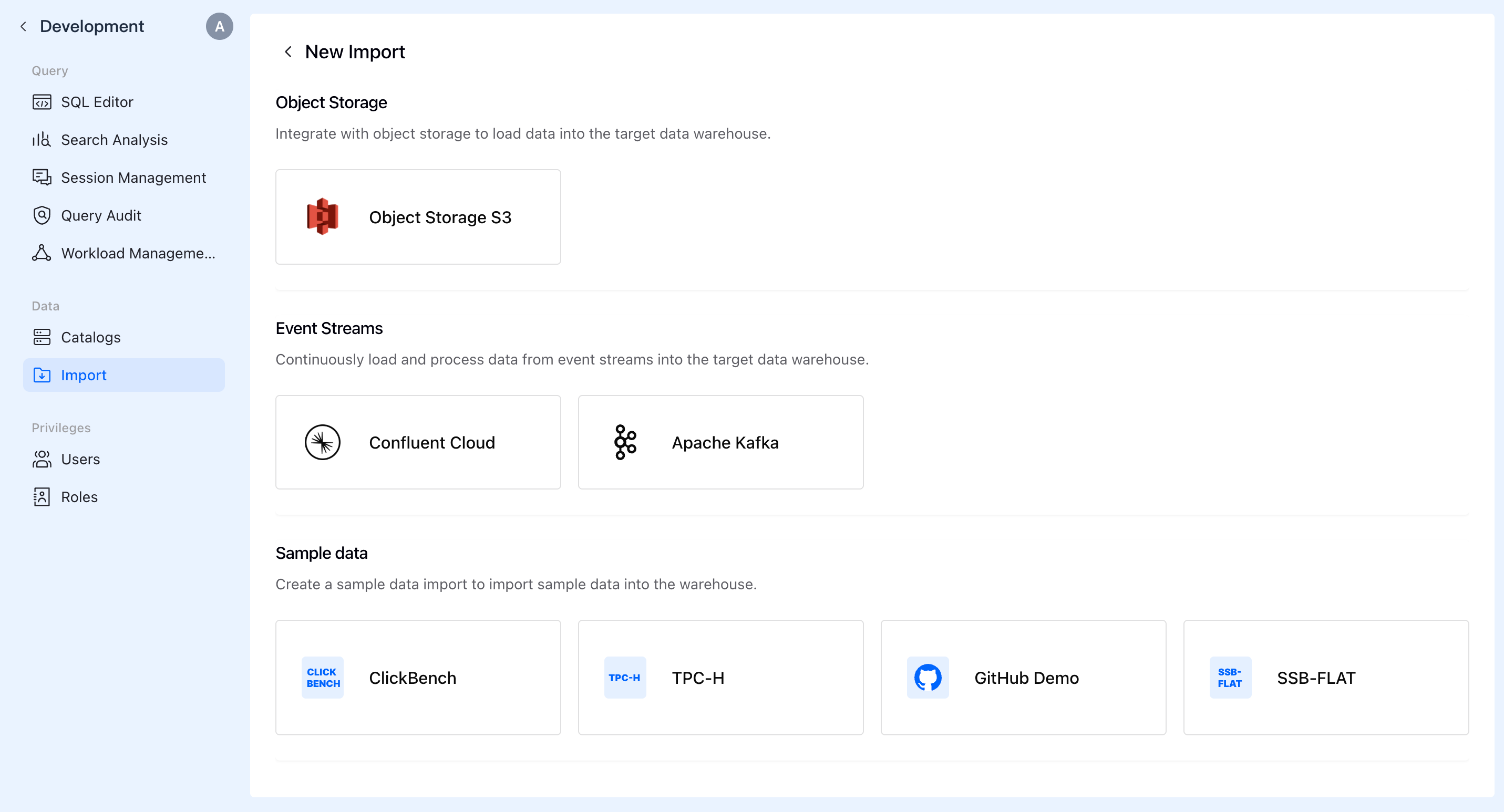
A. Select Data Source
Log in to the VeloDB Cloud console, find the Import module under the Data directory in the Development menu.
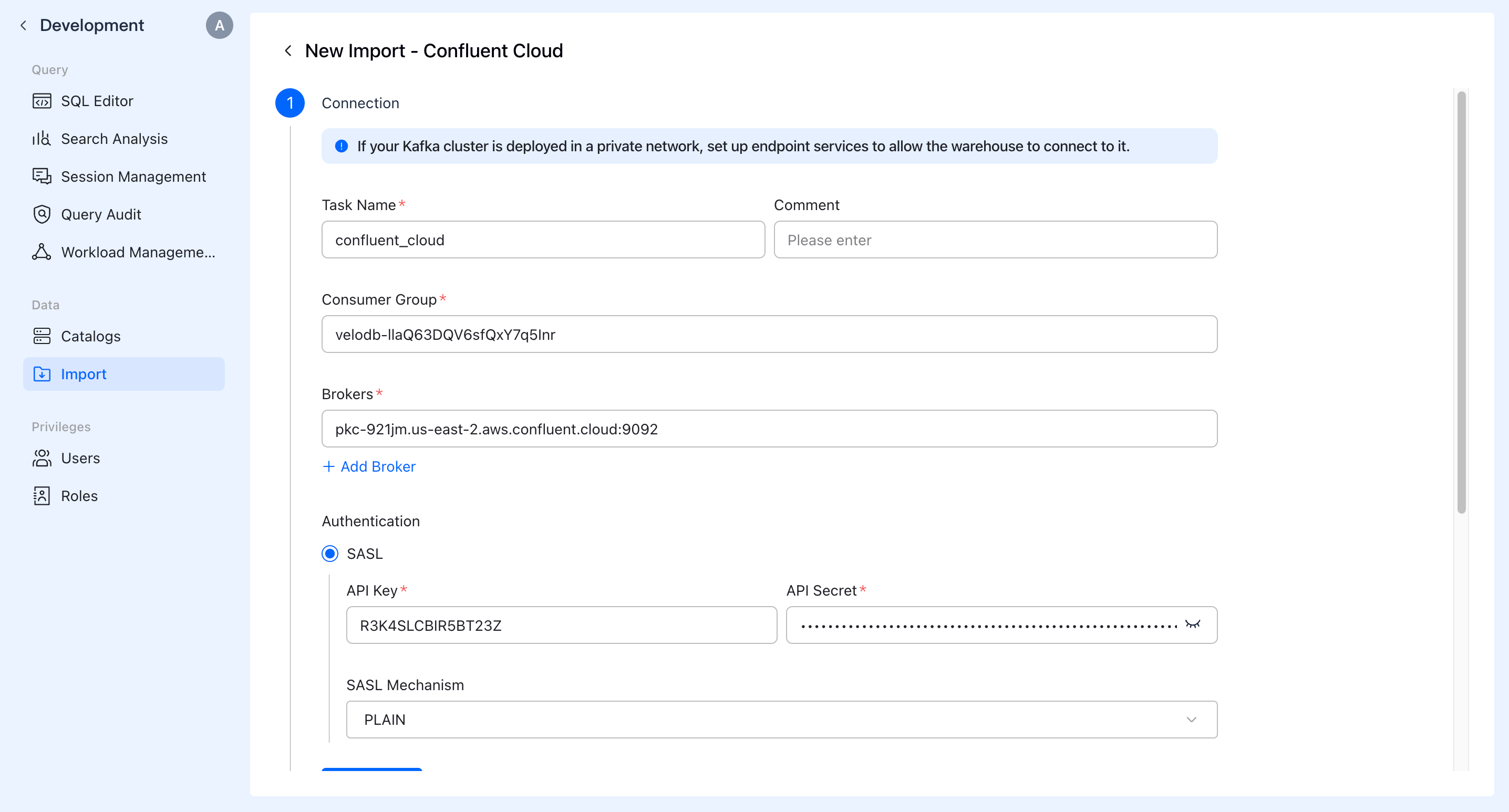
B. Configure Data Source
Provide name, description (optional), cluster address, and authentication information of the ingestion job.
C. Specify Topic for Source Data
Select the Topic and specify the starting consumption point and the source data format.
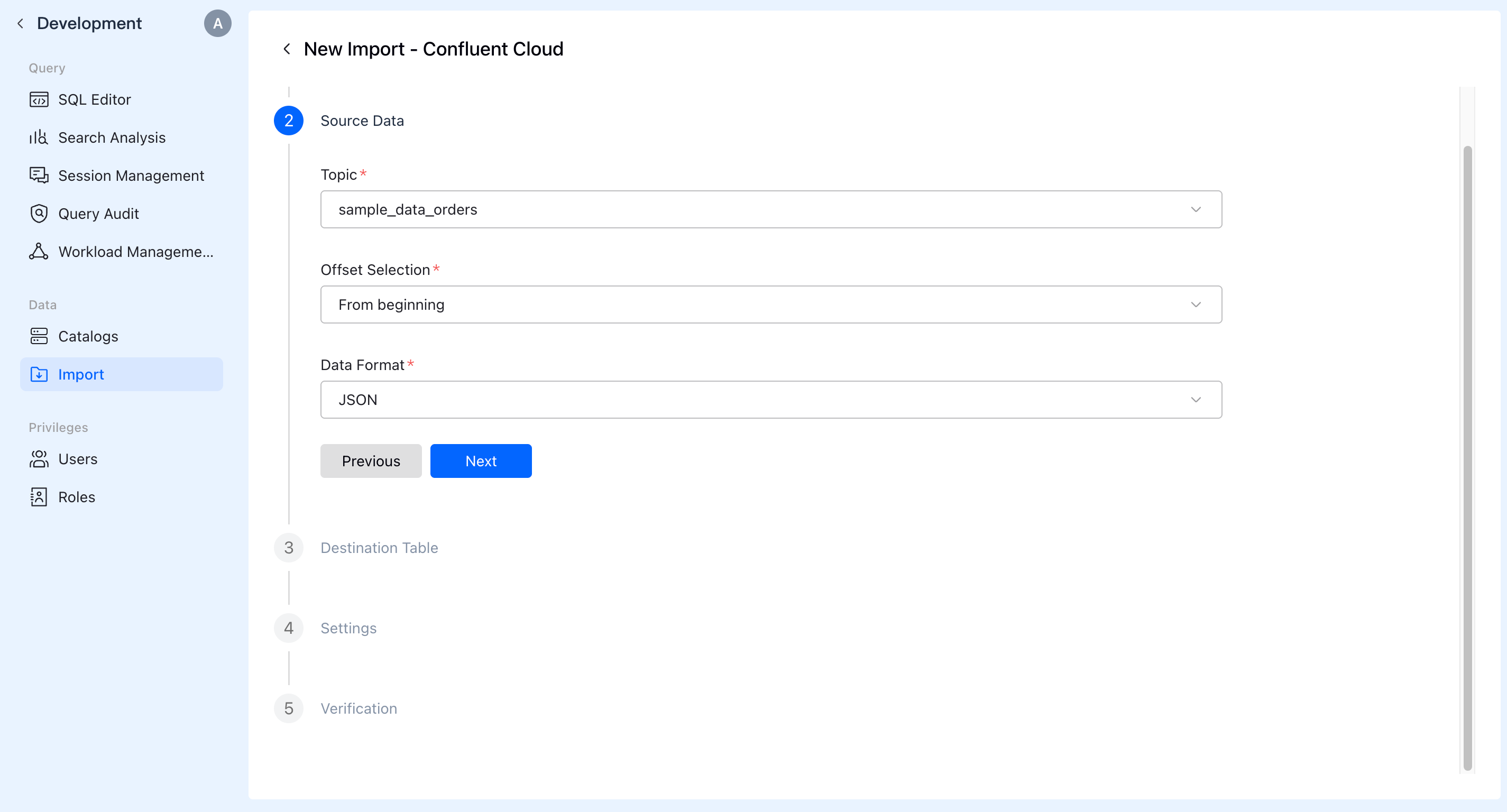
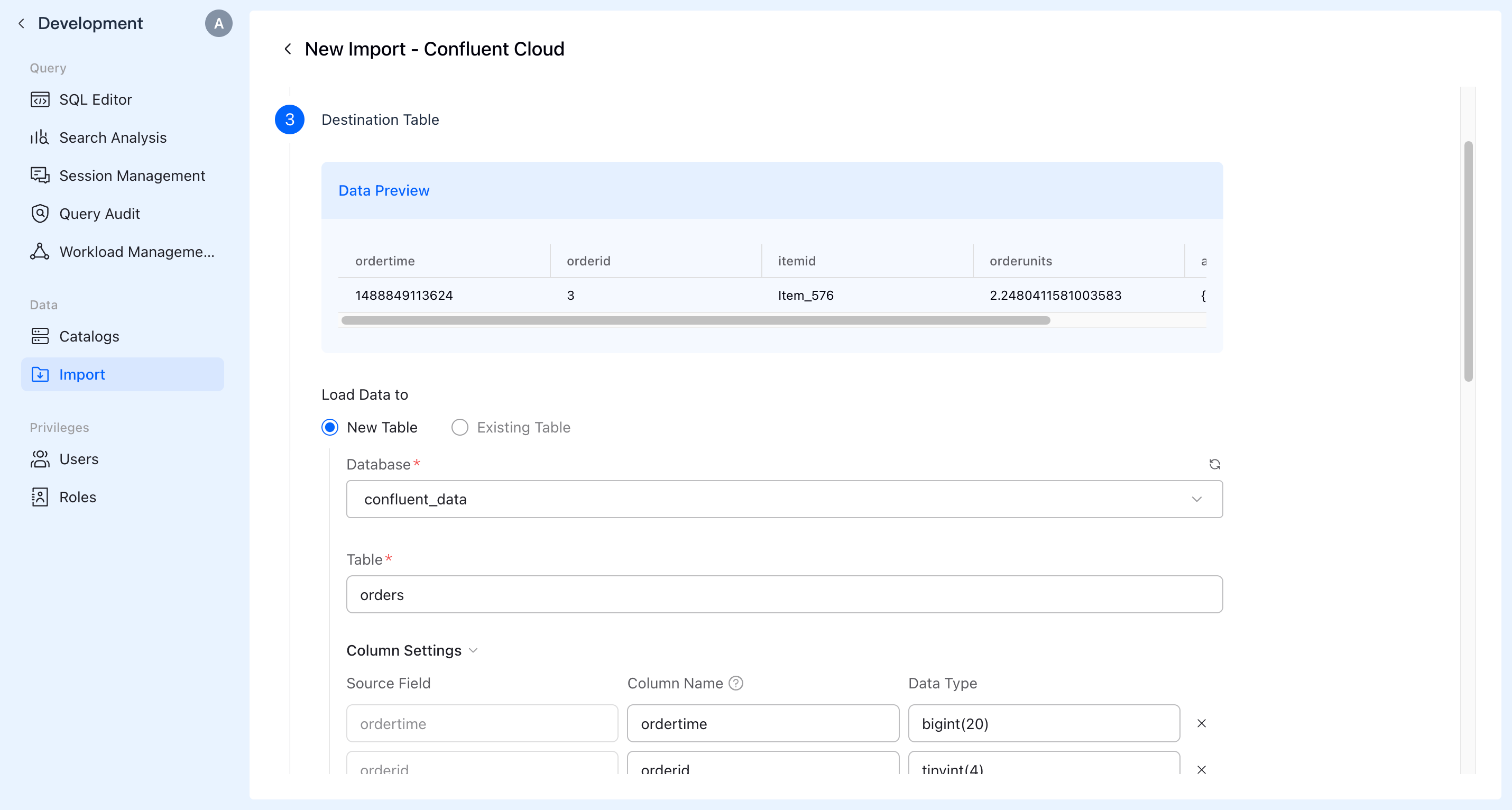
D. Configure Target Table
Preview the source data. Choose whether to ingest the data into a new VeloDB Cloud table or reuse an existing table. Specify the table name and adjust field names and data types.
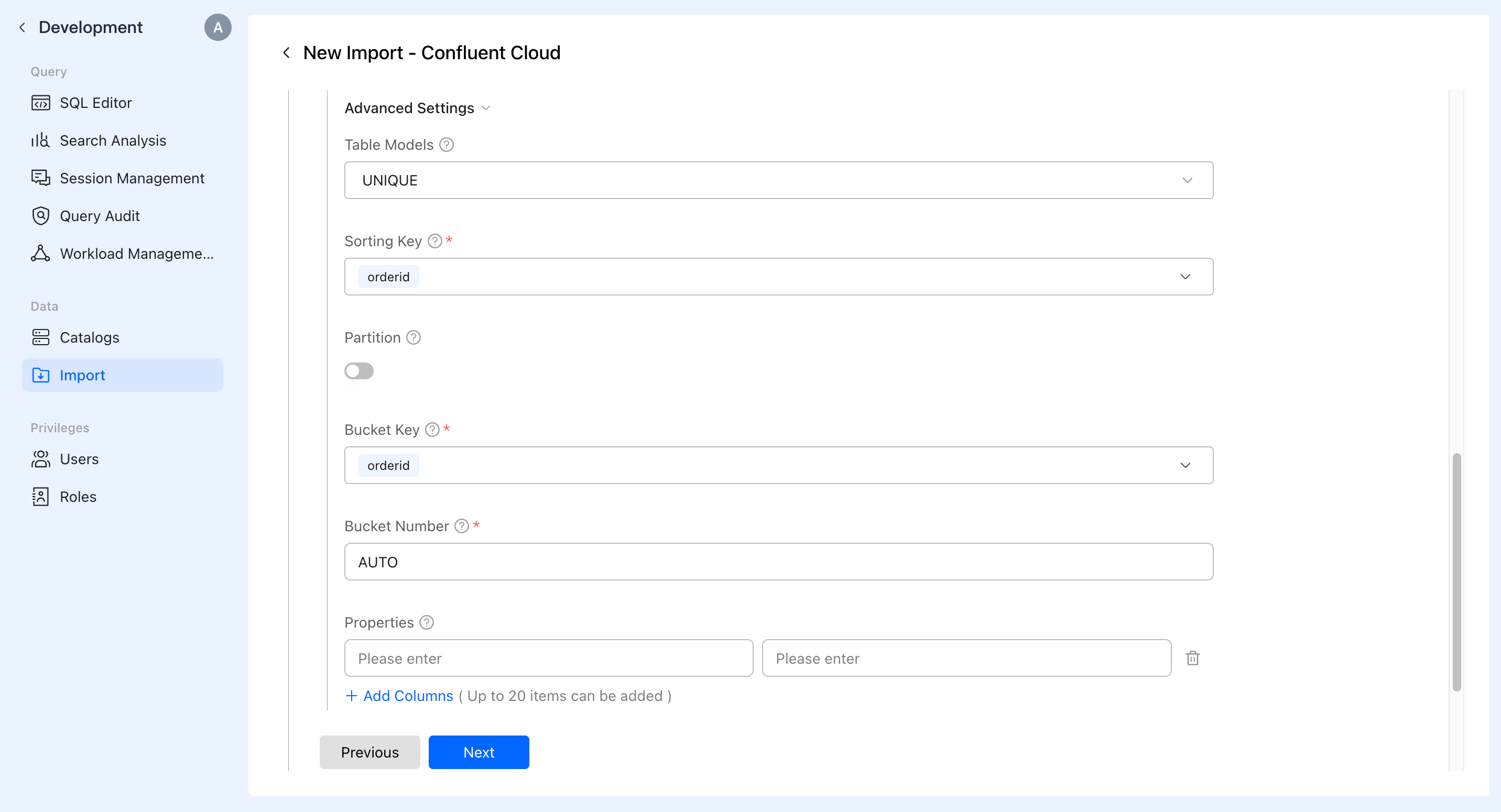
Additionally, in the Advanced Configuration section, you can configure the table schema, sort keys, partitions, buckets, etc.
E. Import Configuration
Configure the import job's concurrency, maximum runtime, maximum number of rows to read, and maximum bytes to read.
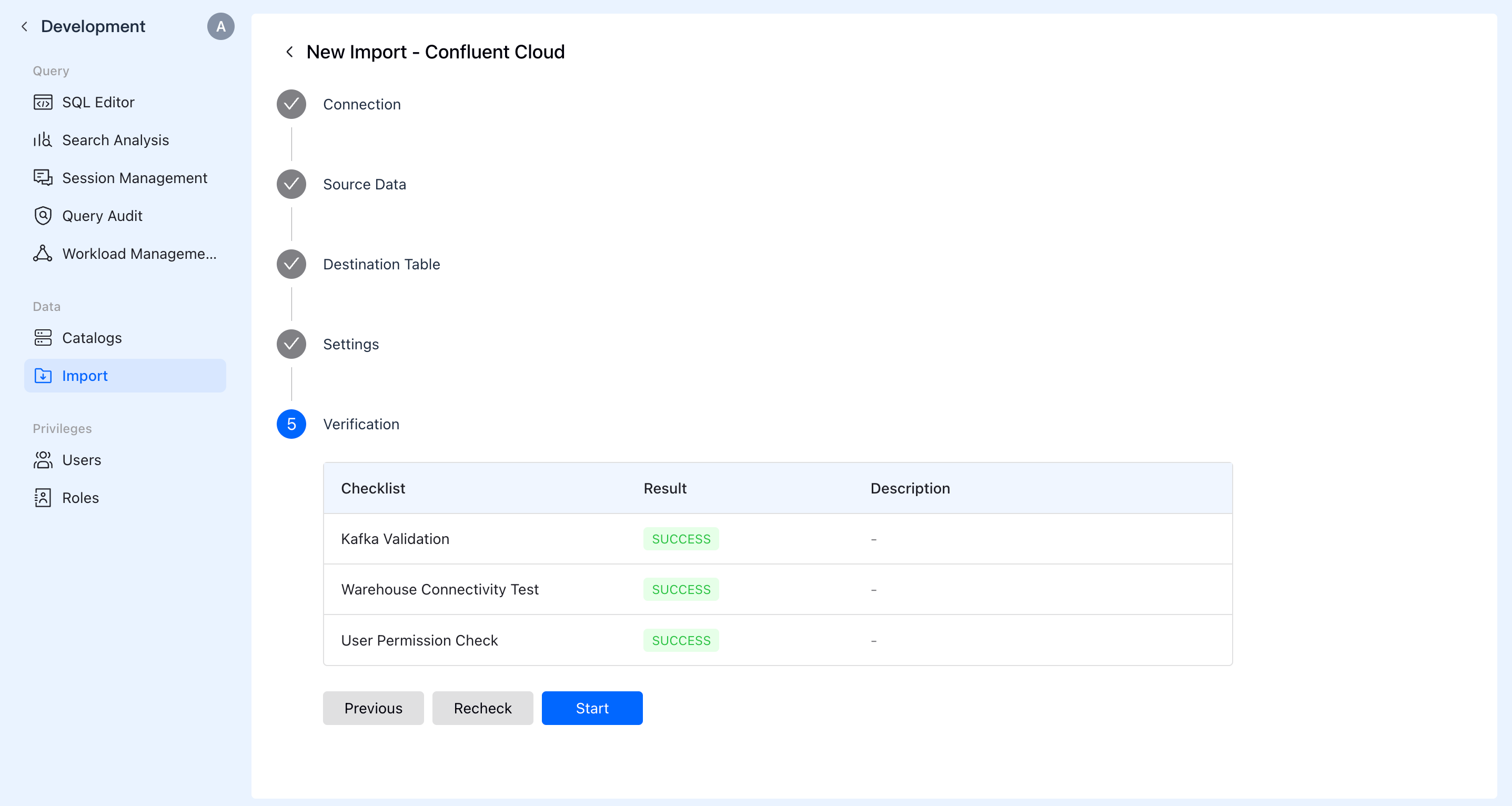
After the system check passes, create and run the import job.
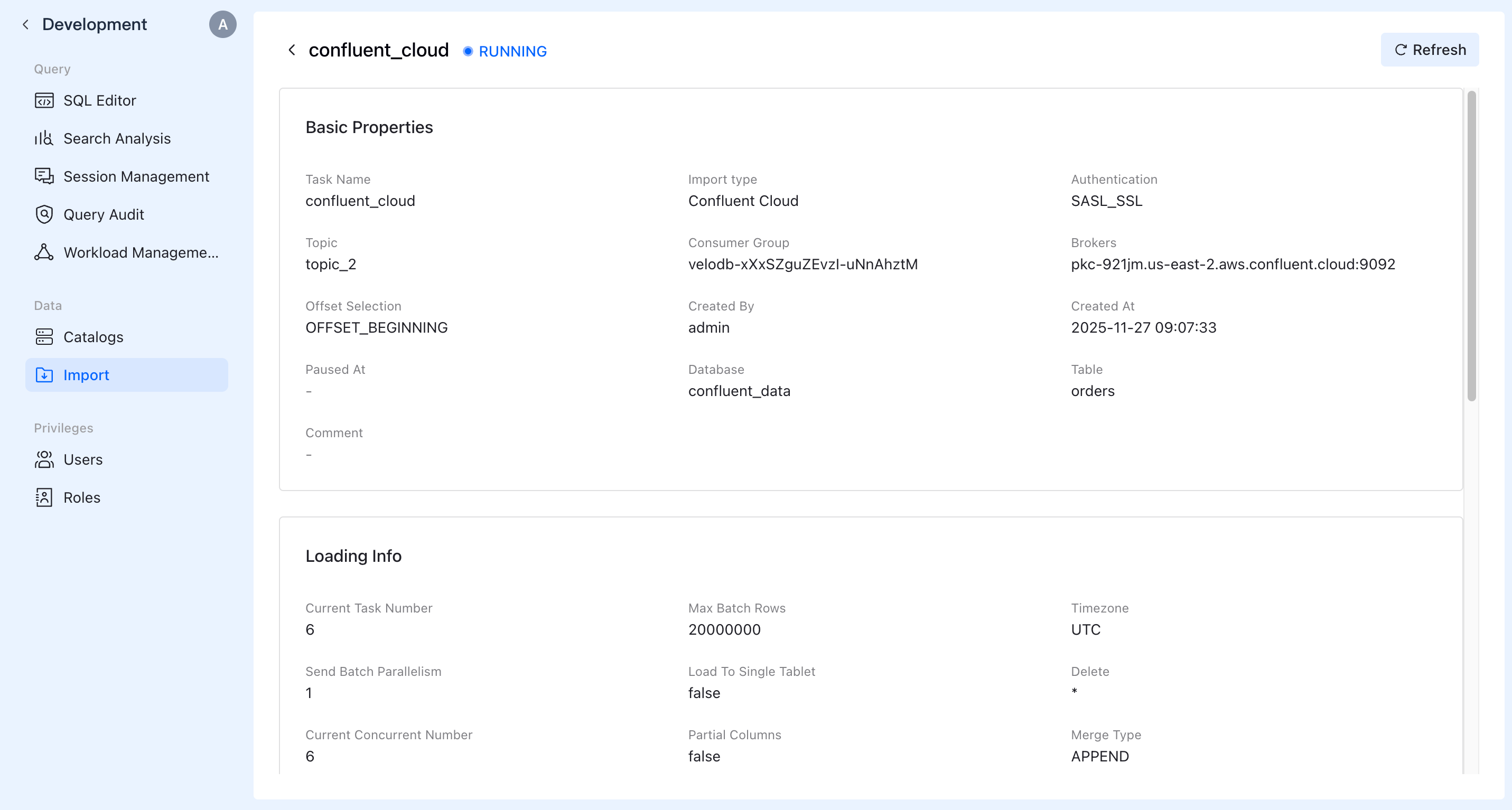
F. Verification
Query the data in SQL Editor. You can see the data being continuously updated.
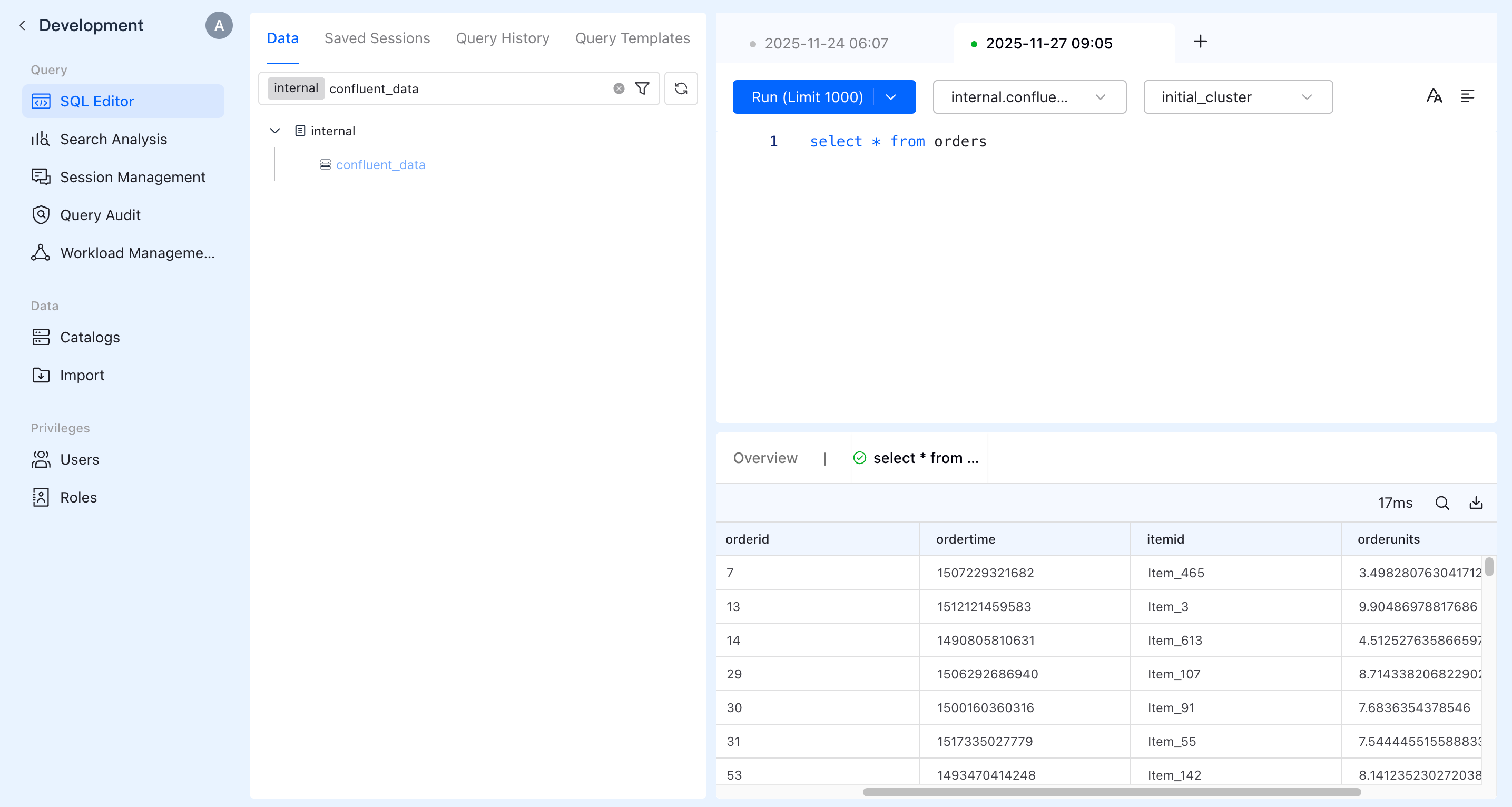
More Streaming Data Source Integrations Coming Soon
For Kafka users, the integration provided by VeloDB Cloud (which includes the Kafka Visual Ingestion Feature and VeloDB Kafka Connector) offers highly flexible configuration options. These options support SSL/TLS encrypted transmission, SASL authentication, customizable consumer groups, and initial offset positions. This flexibility caters to various scenarios, including private deployments and hybrid clouds.
Integrating with Confluent is just a start. VeloDB Cloud aims to rapidly expand support for additional data sources, including AWS MSK, MySQL, PostgreSQL, and more in the future.
We'd love to hear your feedback on our future development direction. Contact the VeloDB team, or join the Apache Doris community on Slack to discuss with us.


