Major crypto exchanges operate under extreme data pressure: high-frequency transactions, rapidly growing historical data, and stringent requirements for low latency, high concurrency, and strong data consistency. These data workloads form the foundation for key use cases, including risk control, trading analysis, user behavior analytics, commission calculation, and other user-facing analytics.
For Web3 builders, the speed and volume of crypto data raises a key question: What kind of database architecture actually works for real-time Web3 analytics?
This article breaks down how a top-5 global crypto exchange designed its real-time analytics platform using VeloDB (a real-time search and analytics database powered by Apache Doris). We'll cover architectural design and detailed use cases.
Customer Profile: Top-5 Global Crypto Exchange
Founded in 2018 and headquartered in Singapore, this top-five crypto exchange operates across Dubai, Hong Kong, and multiple global regions. The platform serves over 80 million registered users worldwide and processes more than $10 billion in average daily trading volume. Its product offering includes spot trading, derivatives (including futures and options), and quantitative trading, supporting a diverse global user base across APAC, North America, and Europe.
The exchange was facing explosive growth in trading data, increasingly complex business workloads, and strict compliance requirements, all of which place extreme demands on data platform performance and reliability.
A. Data & Analytics Challenges:
- High-performance analytics: Crypto trading generates massive volumes of structured data every day. The platform must support second-level queries over hundreds of terabytes of trading data to enable both real-time decision-making and long-term analysis.
- High-concurrency query handling: Query traffic fluctuates sharply with user activity peaks. The system needs to sustain thousands of QPS while keeping P99 under 500 ms, even during traffic spikes.
- Real-time data processing: Data freshness directly impacts risk control and user experience. Trading data must be queryable within seconds of creation, with minimal end-to-end ingestion latency.
- Cross-AZ High Availability: As a global trading platform, core data services must provide redundant storage and compute across availability zones (AZs) to ensure uninterrupted service and zero data loss.
- Simple architecture: The platform should be easy to operate and evolve, avoiding unnecessary complexity while supporting elastic scaling and rapid iteration with minimal operational overhead.
B. Core Use Cases
- Withdrawal Risk Control: Real-time analysis of user withdrawal behavior, fund flow patterns, and account anomalies to identify theft, fraud, and other risks, reducing operational risk
- Anti-Money Laundering (AML) Analysis: Leveraging Web3's on-chain transparency to track cross-platform trading behavior and fund relationships, building multi-dimensional behavioral profiles to meet global regulatory compliance requirements
- Commission Calculation: Real-time settlement based on referral relationships and trading fees, supporting bi-directional revenue sharing mechanisms to ensure commission data accuracy and timeliness for user acquisition
- User Trading Analysis: Building user trading behavior tag systems to analyze trading preferences, position characteristics, and profit/loss patterns, providing data support for personalized recommendations and strategy optimization
Solution: Stream Processing, Real-Time Analytics, and Lakehouse Integration with VeloDB
To meet the real-time analytics requirements, the exchange built its analytics platform on VeloDB, an analytical and search database based on Apache Doris. VeloDB serves as the core engine of the overall architecture, enabling consistent performance, real-time responsiveness, and operational simplicity across various use cases.
VeloDB's Core Capabilities:
- Real-Time Capability: In real-time analytics scenarios, data is synchronized from MySQL/PostgreSQL to VeloDB via Flink CDC, achieving 1-3 second data ingestion. On the query side, VeloDB easily handles thousands of QPS concurrent requests. In actual risk control and AML scenarios, using the Kafka→Flink→VeloDB pipeline, raw data can be written directly with peak QPS reaching 5,000 and P95 latency stable within 500ms, providing precise support for multi-TB data.
- High-Concurrency, Low-Latency Queries: In the World Trading Competition, VeloDB's second-level ingestion capability enables 1000+ QPS, high-concurrency point queries with P95 latency of 30ms, enabling real-time rankings and audience targeting to drive user acquisition. In commission calculation scenarios, VeloDB computes commission fees without additional real-time processing, achieving P95 latency of only 30ms and P99 latency of 100ms at 100+ QPS.
- Large-Scale Data Processing with Flexibility: In trading analysis scenarios, VeloDB stores 400TB+ of user data, supporting ad hoc detail analysis and multi-dimensional reporting at 200+ QPS with P95 latency of 1-3 seconds. In the transaction tracking system, VeloDB integrates 50TB+ of multi-source data, enabling real-time analysis of large-scale transaction records at 300+ QPS with P95 latency of 500ms.
- Lakehouse Architecture: In the lakehouse architecture, VeloDB supports both ad hoc queries in data lakes and lightweight data processing. In the tax reporting solution, lightweight ETL tasks that previously took 30 minutes in Spark were completed in just 3-5 minutes, significantly improving performance and flexibility.
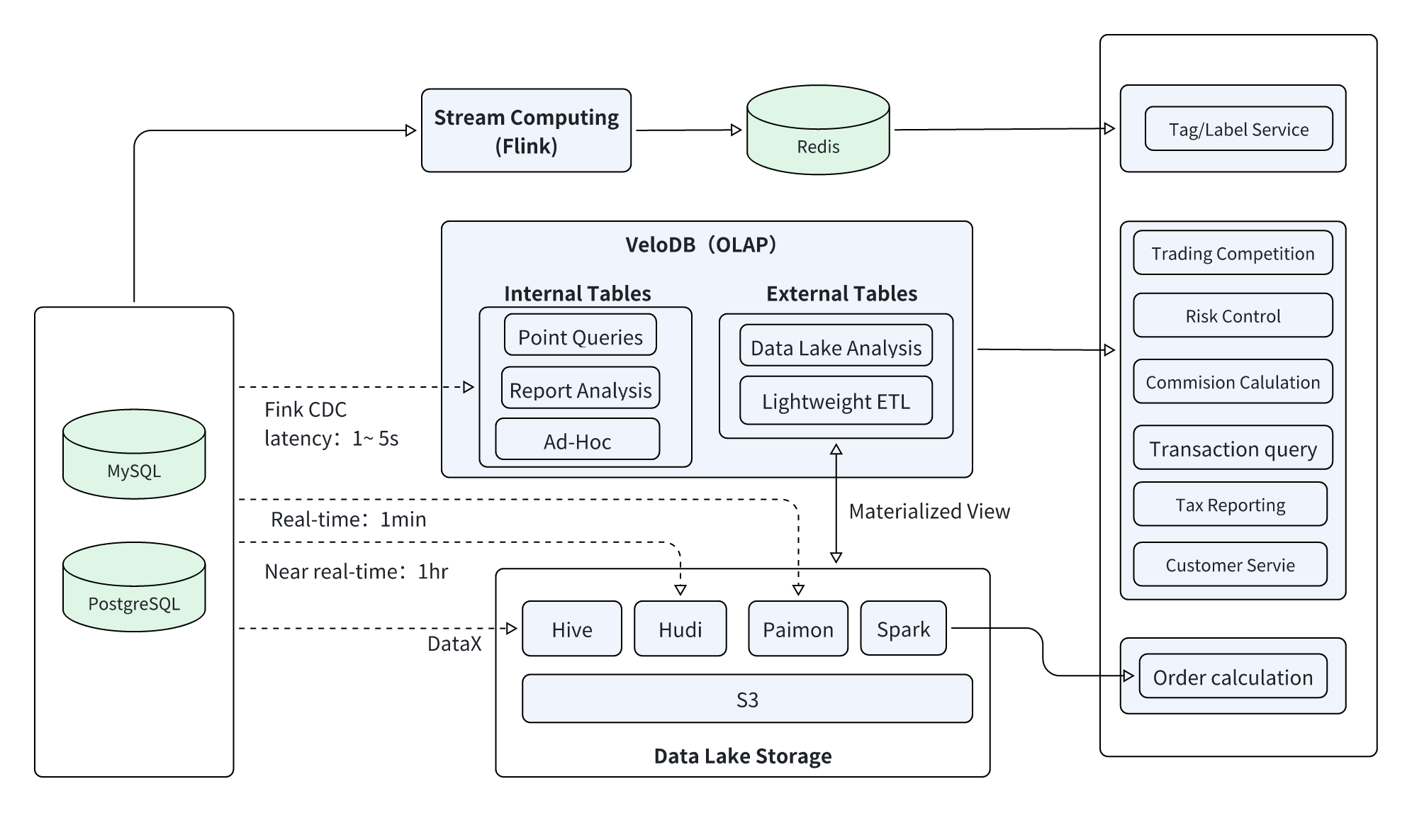
Based on the exchange's business requirements and VeloDB's technical capabilities, the platform built a three-layer technical architecture combining stream processing, real-time analytics, and lakehouse integration to form an end-to-end data pipeline from collection through processing, storage, and application.
The architecture design uses VeloDB as the core analytics engine, combined with Flink, Redis, Hudi/Paimon, and other components, meeting both low-latency requirements for real-time business and large-scale data processing capabilities for offline analysis.
Architecture Diagram:
1. Stream Processing Platform with Flink
For scenarios requiring sub-second indicators, such as tag platforms and real-time risk control, the exchange built a stream-processing platform based on Flink and Redis to achieve sub-second calculation of trading indicators.
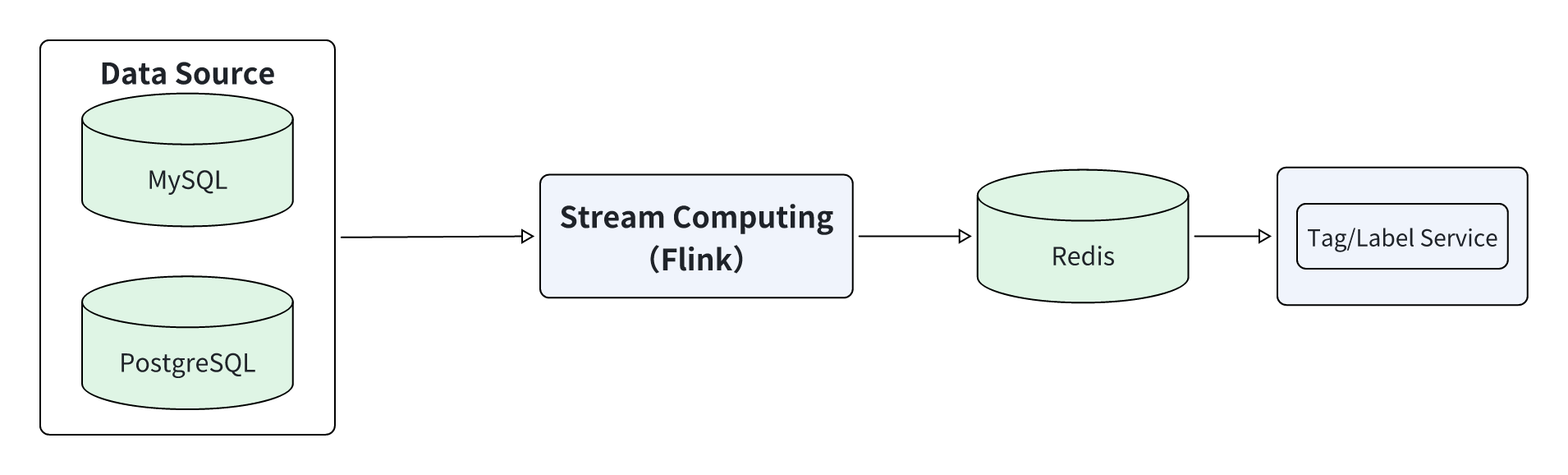
Real-time trading data and user behavior data from MySQL/PostgreSQL are captured via Flink CDC, processed by Flink for real-time indicator calculation (such as user instantaneous trading frequency and abnormal login identification), then written to Redis cache, and finally exposed through the tag service API for external data services.
Details:
- Data Pipeline: MySQL/PostgreSQL → Flink CDC → Flink → Redis → Tag Service
- Data sources: MySQL, PostgreSQL, and other business data sources
- Real-time compute platform: Flink-based real-time indicator calculation
- Storage: Indicator storage in Redis
- Indicator service: A web service that queries Redis for external data services
- Data Timeliness: Sub-second indicator calculation
- Use Cases: Tag platform and real-time risk control
2. Real-Time Analytics Platform with VeloDB
At the core of the architecture, the real-time analytics platform is built on VeloDB to handle high-concurrency point queries, report analysis, and ad hoc queries, fully leveraging VeloDB's real-time capabilities and concurrency.
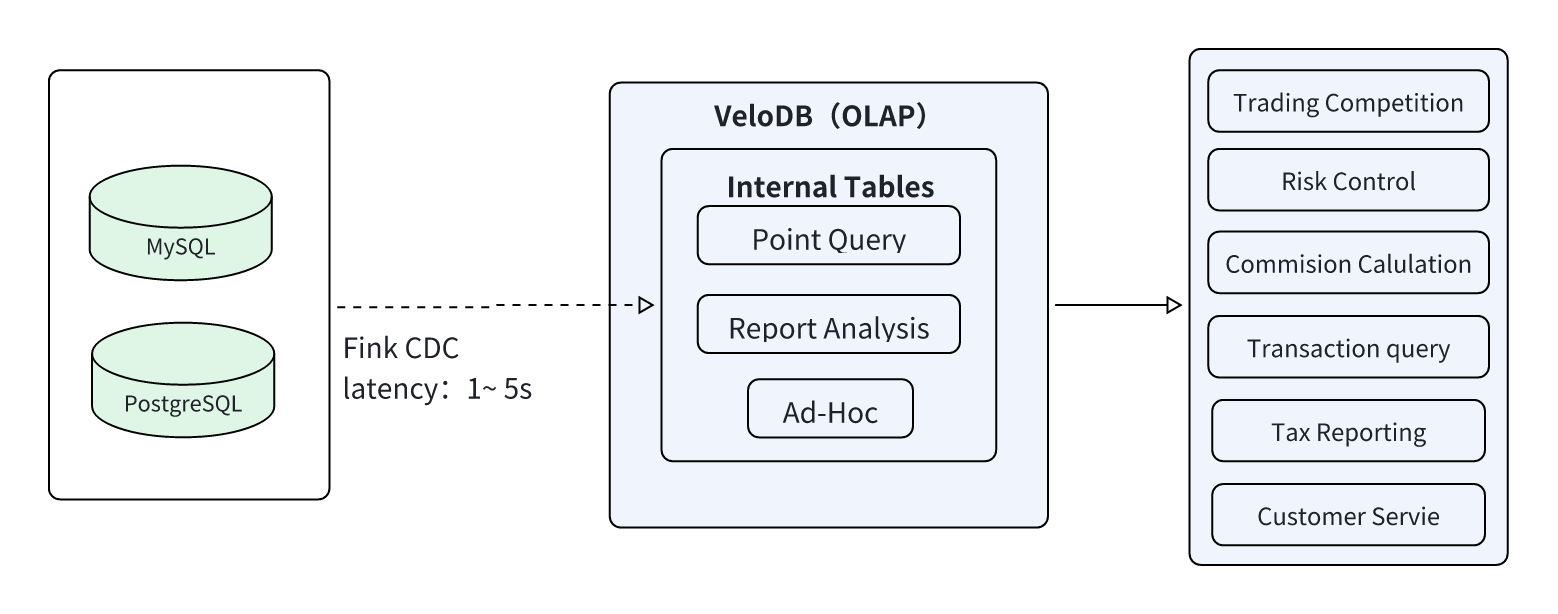
Business data from MySQL/PostgreSQL is synchronized to VeloDB in real time with 1-3 second latency via Flink CDC, written directly to VeloDB. VeloDB optimizes data storage through its columnar storage engine, pre-aggregation indexes, and other technologies, ultimately providing efficient data services for trading competitions, commission calculations, customer service queries, and other business applications.
Details:
- Data Pipeline: MySQL/PostgreSQL → Flink CDC → VeloDB → Data Applications
- Data Source: MySQL, PostgreSQL, and other business data sources
- Data Synchronization: Flink CDC, 1-3 second latency
- Data Analytics Platform: VeloDB offers efficient data storage and query services for high-concurrency point queries, report analysis, and Ad-Hoc queries
- Data Timeliness: 1-3 second ingestion, sub-second queries, thousands of QPS
- Use Cases: Trading competition, risk control, commission calculation, transaction queries, tax reporting, customer service
Key VeloDB Capabilities:
- Second-Level Data Synchronization: Supports Flink CDC direct write, with data queryable within 1-3 seconds of generation, meeting real-time business requirements for commission calculation, trading rankings, etc.
- High-Concurrency Support: Stable support for thousands of QPS through query optimizer and connection pool management, with peak QPS reaching 1000+ and P95 latency of only 30ms in trading competition scenarios
- Flexible Query Capability: Supports both structured queries and Ad-Hoc exploratory queries, meeting both fixed query scenarios like commission reports and flexible query needs for risk control analysis
3. Lakehouse Platform with VeloDB + Paimon
For scenarios requiring integration of real-time and offline data, such as order analysis, fund transfer tracing, and tax reporting, the exchange built a lakehouse architecture based on VeloDB and data lakes (Hudi/Paimon) with offline platforms (Hive/Spark), enabling "real-time lake ingestion, on-demand warehouse loading, and flexible computation."
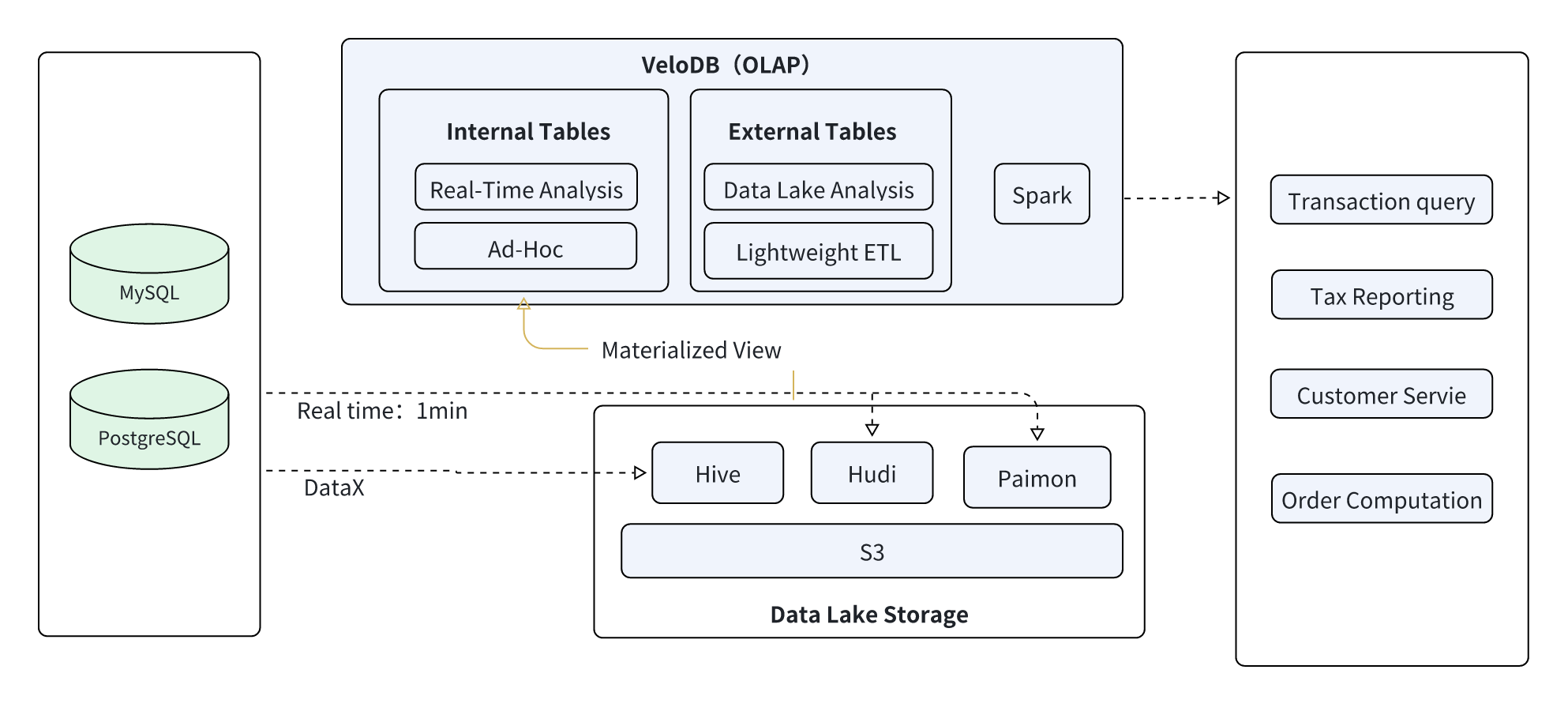
Details:
-
Data Pipelines:
-
Data Lake Ingestion: MySQL/PostgreSQL → Flink CDC → Data Lake (Hudi/Paimon) → VeloDB (1-5 min latency)
-
Offline Data Processing: MySQL/PostgreSQL → DataX → Offline Platform (Hive) → Spark (1 hour latency)
-
Lake-to-Warehouse: Data computed through Spark on the data lake written to the VeloDB data warehouse
-
-
Data Source: MySQL, PostgreSQL, and other business data sources
-
Data Synchronization:
-
Flink CDC → Data Lake (Hudi/Paimon), 1-5 min latency
-
DataX → Offline Platform (Hive) → Spark, 1 hour latency
-
-
Compute Platform: Using VeloDB for data lake Ad-Hoc queries and data lake lightweight data computation; using Spark for large-scale historical data computation
-
Use Cases: Orders, fund transfers, user information, agency, spot trading, trading bots, transaction queries, tax reporting, customer service, order calculation
VeloDB Lakehouse Core Capabilities:
- Real-Time Data Lake Ingestion: MySQL/PostgreSQL data synchronized to Hudi/Paimon via Flink CDC with 1-5 minute write latency, preserving full raw data
- Multi-Source Data Compatibility: Native support for querying Hudi/Paimon data without data migration, reducing storage costs
- Offline Data Processing: Historical trading data and batch user data synchronized to Hive via DataX, then cleaned and transformed at scale through Spark before being written to VeloDB as needed
- Elastic and Collaborative Computing: VeloDB directly connects to data lakes, handling latency-sensitive workloads, while Spark is used for large-scale historical computation, enabling unified analysis of "real-time + offline" data
- Cost-Effective Storage: Frequently accessed hot data is optimized and stored in VeloDB, while low-frequency historical data is retained in the data lake, balancing query performance and storage costs.
Use Case 1: Risk Control Platform Solution
1. Technical requirements
a. Real-Time Data: Raw trading data must be ingested and queryable within 1–3 seconds, with no additional processing delay.
Business value: Enables second-level interception of risk events, reducing fund losses.
b. High-concurrency support: The system must handle 1,500 QPS at peak and up to 5,000 QPS under stress testing, with P95 query latency ≤ 500 ms.
Business value: Ensures system stability during query surges at trading peaks.
c. High service availability: Storage and compute must be redundant across availability zones, supporting seamless failover without service interruption.
Business value: Avoid compliance risks and fund security issues caused by risk-control downtime.
2. Business requirements
A. Deposit and withdrawal risk control: Real-time validation of user identity, account status, and transaction behavior.
Business value: Blocks account takeover and fraudulent withdrawal attempts, protecting user funds.
B. Anti-money laundering (AML) analysis: Correlating on-chain and off-chain data to trace abnormal transaction paths and suspicious fund pools.
Business value: Meets international regulatory requirements such as FATF and reduces compliance risk.
3. Technical Architecture
Overall Architecture
With VeloDB as the core analytics engine, the architecture builds a complete pipeline from "Data Collection → Real-Time Synchronization → Storage Analysis → Business Application," maximizing VeloDB's technical advantages in real-time capability, concurrency, and high availability.
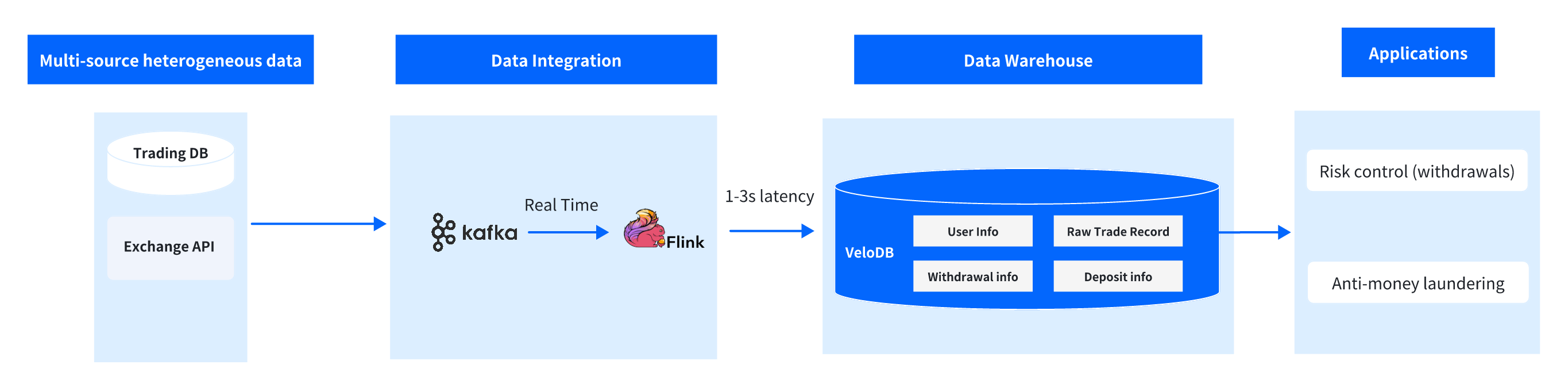
Architecture Layers:
- Data Source Layer: Dual-source data ingestion, including exchange trading database (user information, deposit/withdrawal records, order data) and on-chain API services (wallet address transactions, smart contract interactions, cross-chain transfer data), achieving "on-chain + off-chain" full data coverage
- Data Synchronization Layer: Kafka serves as a data buffer queue to handle high-throughput trading data; Flink performs real-time stream processing, using Flink Doris Sink to write raw data directly to VeloDB with synchronization latency controlled within 1-3 seconds
- Core Analytics Layer: VeloDB serves as the core storage and analytics engine, storing user information, transaction records, and deposit/withdrawal wide tables, supporting high-concurrency real-time queries and Ad-Hoc analysis through pre-aggregation indexes, partitioning strategies, and query optimizer
- Business Application Layer: Interfaces with risk control engine and AML systems to output user risk levels, transaction anomaly tags, and fund flow reports, supporting deposit/withdrawal review, violation alerts, and regulatory reporting
Primary-Standby Cluster for High Availability
The crypto exchange requires "zero interruption" for its core business. To meet that demand, VeloDB adopts cross-AZ primary-standby cluster architecture, ensuring high availability across the entire chain from write to storage to query:
- Write High Availability: Primary-standby cluster dual-write mechanism where Flink writes data simultaneously to primary and standby clusters, ensuring no data loss when a single cluster fails
- Storage High Availability: FE management nodes and BE data nodes deployed across AZs with Resource TAG mechanism that configures independent data replicas per AZ, achieving "one AZ failure, others continue to provide read/write services," significantly improving data reliability
- Query High Availability: Load balancer distributes query requests between primary (80%) and standby (20%) clusters; when the primary cluster encounters issues, automatic failover triggers with the standby cluster seamlessly taking over all requests with no user perception.
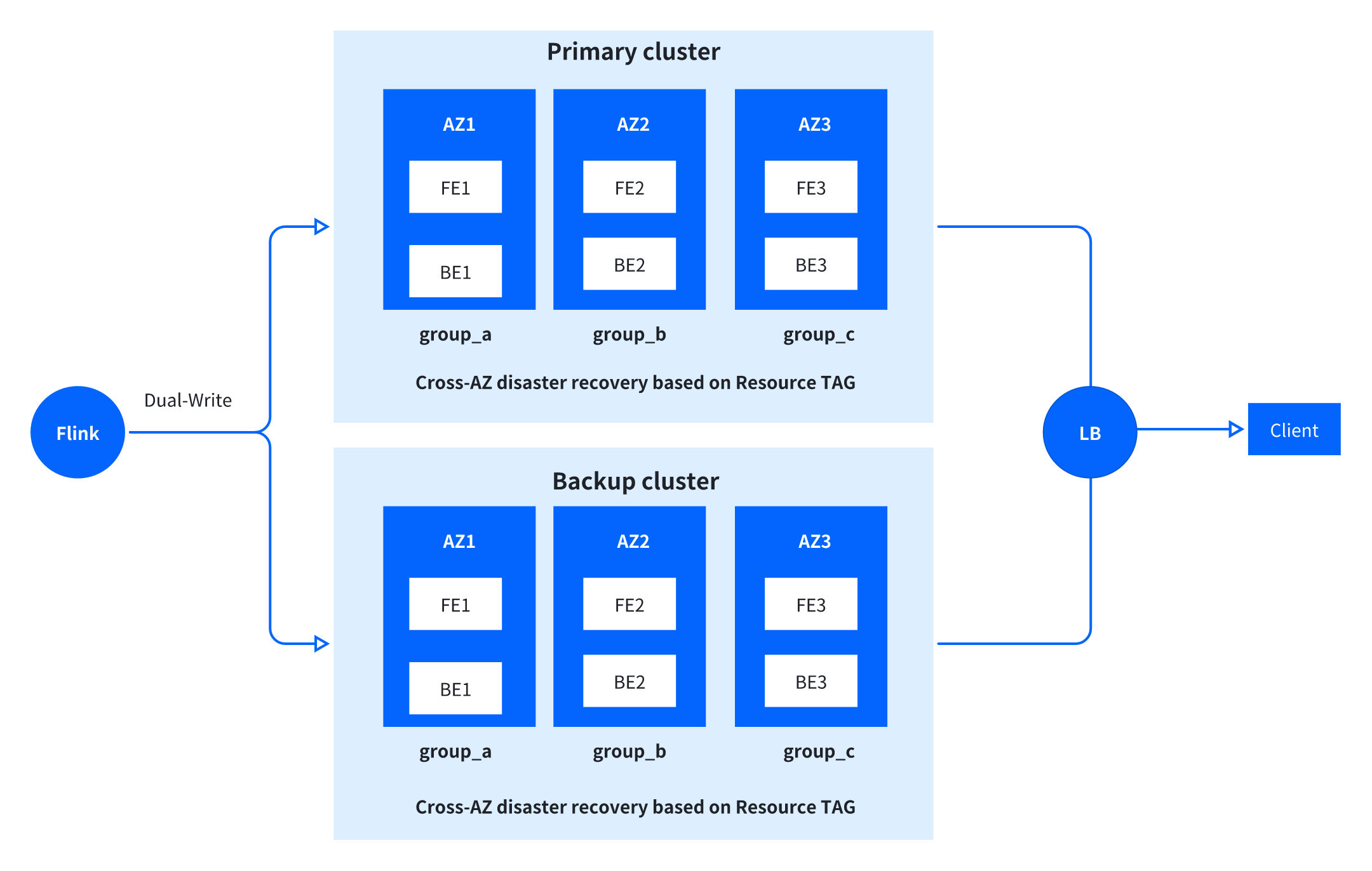
4. Use Cases
A. Deposit/Withdrawal Risk Control: Real-Time Verification, Second-Level Interception
Deposit/withdrawal is the core gateway for exchange fund safety, requiring multi-dimensional verification of "user identity, account status, transaction behavior" within 200ms after the user initiates the request. VeloDB supports the entire verification process through efficient query capabilities.
Business Flow:
- User initiates withdrawal request (amount, recipient account)
- Risk control system calls VeloDB query interface for real-time user information and historical trading data
- VeloDB returns query results within 100ms, risk control system determines the risk level based on rules
- High-risk requests are directly blocked, medium-risk requests trigger manual review, and low-risk requests auto-approve
Core Query Demo: User Real-Time Information Query
Business Requirement 1: Query the basic information and account status of target users.
VeloDB Table Structure Design (Core Table):
CREATE TABLE `users` (
`id` bigint NULL COMMENT "ID",
`regist_channel_id` bigint NULL COMMENT "User registration channel",
`invited_user_id` bigint NULL COMMENT "For users registered via invite code, records inviter's user_id",
`username` varchar(300) NULL COMMENT "Username",
`country_code` varchar(6) NULL COMMENT "Country code",
`mobile` varchar(300) NULL COMMENT "Mobile",
`email` varchar(300) NULL COMMENT "Email",
`password` varchar(180) NULL COMMENT "Password",
`secondary_password` varchar(765) NULL COMMENT "Secondary password",
`status` varchar(150) NULL COMMENT "User status",
`authentication_id` bigint NULL COMMENT "Identity verification info",
`email_verified` int NULL COMMENT "Email verified",
`mobile_verified` int NULL COMMENT "Mobile verified",
`google2fa_secret` varchar(48) NULL COMMENT "Google 2FA secret",
`buy_trade_count` int NULL COMMENT "Cumulative buy trade count",
`sell_trade_count` int NULL COMMENT "Cumulative sell trade count",
`avatar` varchar(5000) NULL COMMENT "Avatar",
`introduction` varchar(5000) NULL COMMENT "Introduction",
`remember_token` varchar(300) NULL COMMENT "Remember password token",
`register_ips` varchar(765) NULL COMMENT "Registration IP",
`parent_path` varchar(5000) NULL COMMENT "Parent path",
`banned_to` bigint NULL COMMENT "Account banned until",
`ban_buy_to` bigint NULL COMMENT "Buy banned until",
`ban_wallet_to` bigint NULL COMMENT "Wallet banned until",
`last_online_at` varchar(64) NULL COMMENT "Last online time",
`liq_lock` varchar(128) NULL COMMENT "User liquidation lock",
`auto_add_margin` int NULL COMMENT "Auto add margin",
`currency_code` varchar(9) NULL COMMENT "Currency",
`account_status` varchar(60) NULL COMMENT "Account type: Registered-Deposited-Traded",
`created_at` varchar(64) NULL,
`updated_at` varchar(64) NULL,
`_byhub_sink_timestamp` datetime NULL COMMENT "Byhub data write time",
`site_id` varchar(30) NOT NULL DEFAULT "" COMMENT "Site"
) ENGINE = OLAP UNIQUE KEY(`id`) COMMENT 'OLAP'
DISTRIBUTED BY HASH(`id`) BUCKETS AUTO
PROPERTIES (
"replication_allocation" = "tag.location.ap_singapore_3: 1, tag.location.ap_singapore_4: 1, tag.location.ap_singapore_2: 1",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true"
);
Query User Information by User ID:
SELECT
id AS userId,
register_ips AS registerIps,
status,
created_at AS createdAt
FROM users
WHERE id = #{userId}
Through bucket pruning based on user_id and primary key index functionality, user information can be quickly located with P95 query latency of 100ms, fully meeting business requirements.
Business Requirement 2: Query transaction record count.
Transaction Record Table Structure:
CREATE TABLE `original_operation_record` (
`user_id` bigint NULL COMMENT "User ID",
`op_time` bigint NULL COMMENT "Operation time",
`route_name` varchar(50) NULL COMMENT "Event/Scenario",
`ip` varchar(50) NULL COMMENT "First IP from ips",
`guid` varchar(64) NULL COMMENT "Device ID",
`seer_time` varchar(255) NULL COMMENT "Write time",
`env` varchar(255) NULL COMMENT "Environment, fixed as prod",
`ips` varchar(5000) NULL COMMENT "IP list",
`platform` varchar(255) NULL COMMENT "Platform",
`status_code` int NULL COMMENT "Status",
`user_agent` varchar(10240) NULL COMMENT "UA",
`remove_guid` varchar(255) NULL COMMENT "Removed device ID",
`user_name` varchar(255) NULL COMMENT "Username",
`sec_rc_etl_process_time` varchar(50) NULL COMMENT "Data receive time",
`sec_rc_etl_write_time` varchar(50) NULL COMMENT "Data receive time",
INDEX user_id_idx (`user_id`) USING INVERTED COMMENT 'user_id index',
INDEX ip_idx (`ip`) USING INVERTED COMMENT 'ip index',
INDEX op_time_idx (`op_time`) USING INVERTED COMMENT 'op_time index',
INDEX route_name_idx (`route_name`) USING INVERTED COMMENT 'route_name index',
INDEX guid_name_idx (`guid`) USING INVERTED COMMENT 'guid index'
) ENGINE = OLAP UNIQUE KEY(`user_id`, `op_time`, `route_name`, `ip`, `guid`)
COMMENT 'OLAP'
DISTRIBUTED BY HASH(`user_id`) BUCKETS 64
PROPERTIES (
"replication_allocation" = "tag.location.ap_singapore_3: 1, tag.location.ap_singapore_4: 1, tag.location.ap_singapore_2: 1",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true"
);
Query Transaction Count:
SELECT count(1)
FROM security_db.original_operation_record
WHERE user_id = #{userId}
AND route_name IN ("UnbindGoogleAuthenticator")
AND op_time BETWEEN #{startTime} AND #{endTime}
B. Anti-Money Laundering Analysis: Chain Tracing, Risk Identification
Business Requirement: Count a user's total transaction records in the past 7 days, correlate with on-chain wallet address transaction data, and analyze whether there are AML characteristics of "high-frequency small-amount transactions splitting large funds."
VeloDB Capability: Web3 exchange AML requires "transaction traceability and fund trackability." VeloDB supports Ad-Hoc queries and batch analysis by integrating on-chain and off-chain data, identifying violations such as "split transactions and cross-platform transfers."
Extended Table Structure: On-chain transaction table (on_chain_trade) storing wallet address and transaction hash correlation data.
Analysis SQL Demo:
-- Count user's past 7-day transaction records, analyze transaction frequency and amount distribution
SELECT
u.user_id,
w.wallet_address, -- User's bound wallet address
COUNT(t.trade_id) AS platform_trade_count, -- Platform transaction count
COUNT(o.on_chain_id) AS on_chain_trade_count, -- On-chain transaction count
-- Amount distribution: Small amount (<100 USDT) transaction ratio
SUM(CASE WHEN t.trade_amount < 100 THEN 1 ELSE 0 END) / COUNT(t.trade_id) AS small_amount_ratio
FROM user_info u
LEFT JOIN user_wallet w ON u.user_id = w.user_id
LEFT JOIN platform_trade t
ON u.user_id = t.user_id
AND t.trade_time > DATE_SUB(NOW(), INTERVAL 7 DAY)
LEFT JOIN on_chain_trade o
ON w.wallet_address = o.wallet_address
AND o.trade_time > DATE_SUB(NOW(), INTERVAL 7 DAY)
WHERE u.risk_level > 0 -- Focus on medium-high risk users
GROUP BY u.user_id, w.wallet_address
HAVING small_amount_ratio > 0.8 -- Small amount ratio >80% triggers alert
ORDER BY (platform_trade_count + on_chain_trade_count) DESC;
VeloDB supports efficient scanning of TB-level on-chain data, reducing I/O overhead through hash distribution and columnar compression. This Ad-Hoc query achieves P95 latency of 450ms on multi-TB data volume, meeting AML analysis real-time requirements.
5. Results and Benefits
This solution has been running stably in risk control and AML systems with core benefits:
- Performance: Peak query QPS of 1500, stress test supporting 5000 QPS, P95 latency stable within 500ms
- Data Scale: Stable storage and high-concurrency queries on multi-TB user detail data
- Business Value: Significant improvement in deposit/withdrawal risk interception rate, avoiding regulatory penalty risks
With VeloDB's capabilities for real-time writes, high-concurrency queries, and cross-AZ high availability, the solution precisely addresses core pain points in Web3 exchange risk control and AML, achieving goals of real-time data, efficient analysis, and stable service.
Use Case 2: Commission Calculation Solution
Web3 exchanges often build a healthy and growing commission ecosystem, with business logic significantly different from traditional centralized exchanges:
- Commission Mechanism Centrality: When users register through referral links, the platform returns a percentage of trading fees to referrers, with some scenarios supporting bi-directional sharing, where referrers share commission with referred users. This mechanism is key for acquiring new users and activating existing users, directly impacting user activity and ecosystem expansion speed
- Market Maker Collaboration: Web3 market makers rely on algorithms and smart contracts to automatically execute quotes, maintain market liquidity, and earn trading fees. Their commission settlement needs real-time linkage with smart contract trading fee data, requiring commission calculation to interface with on-chain trading fee data
- Multi-Terminal High-Frequency Queries: Commission data must support official website commission report display, market-maker external API calls, and internal operations data analysis. In these three high-frequency scenarios, query requests are high-concurrency and have low tolerance for latency.
Core Technical and Business Requirements
Technical requirements
-
Real-time computation: Commission amounts are calculated dynamically at query time based on the latest trading data, without precomputation.
Business value: Supports flexible commission rate adjustments and dynamic changes to two-way revenue-sharing rules.
-
High-concurrency support: The system must reliably handle 100+ QPS and scale to peak traffic without query contention.
Business value: Ensures smooth access across the website, external APIs, and internal operational queries.
-
Low-latency response: P95 latency ≤ 30 ms and P99 latency ≤ 100 ms, enabling users to view commission earnings in real time.
Business value: Improves the experience for both referrers and referees, increasing participation in commission-based promotions.
Business requirements
-
Accurate calculation: Strict matching of referral relationships, commission rates, and two-way revenue-sharing rules, with zero calculation errors.
Business value: Prevents user complaints caused by incorrect commission payouts and protects platform credibility.
-
Multi-scenario support: Simultaneous support for website report generation, market-maker API data output, and operational detail queries.
Business value: Provides a unified data source and reduces cross-team coordination overhead.
-
Historical traceability: Supports commission queries for any time range to meet reconciliation, audit, and compliance requirements.
Business value: Aligns with regulatory and compliance needs specific to Web3 exchanges.
Technical Architecture
This solution uses VeloDB as the core engine, building a Kafka → Flink → VeloDB data pipeline that maximizes VeloDB's advantages in query-time computation and handling high-concurrency queries.
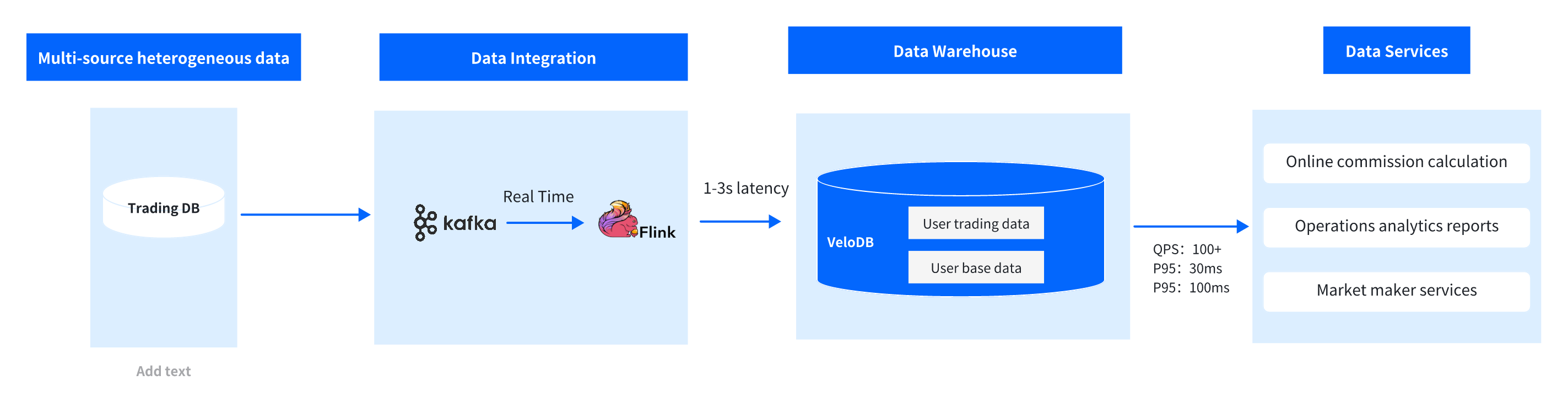
Data Synchronization Layer: Real-Time Data Ingestion
- Data Source: Focus on the crypto exchange's trading database core data, including user basic information, trading order details, and fee settlement data, covering all dimensions for commission calculation input.
- Synchronization Mechanism: Using Flink real-time stream processing and a dedicated Flink Doris Sink component, trading data is synchronized to VeloDB with low latency, controlling synchronization latency to 1-3 seconds, ensuring commission calculation is based on the latest trading data.
Core Computation and Storage Layer: VeloDB Core Capability Implementation
VeloDB serves as the solution core, taking dual responsibility for data storage + query-time commission computation, with key capabilities perfectly matching business requirements:
- Query-Time Computation: Unlike the pre-compute commission on ingestion approaches, this solution performs commission ratio matching, referral relationship matching, and bi-directional sharing rules computation within VeloDB. This eliminates the need for complex computation logic on the Flink side, flexibly adapting to commission rule adjustments (such as ratio changes, sharing mode additions), reducing business iteration costs
- High-Concurrency, Low-Latency Support: Leveraging VeloDB's three core technologies of distributed architecture, vectorized computation, and query optimizer, it supports 100+ QPS high-concurrency queries with P95 latency stable within 30ms. Partition bucketing and columnar storage significantly improve trading data scan efficiency, query optimizer automatically optimizes multi-table join logic (user table, referral table, trading table), ensuring millisecond-level response.
Application Layer
VeloDB provides unified data services to three core applications through a standard SQL interface:
- Official Website Commission Reports: Support users' real-time queries of personal commission details and cumulative earnings, with report data refreshed periodically (based on VeloDB query results)
- Market Maker External API: Provide a standardized commission data interface, market makers obtain commission data for their referred users via API, supporting their revenue settlement
- Internal Operations System: Support operations staff Ad-Hoc queries, such as commission totals for specific time periods, TOP referrer rankings, bi-directional sharing ratios, etc., assisting operations decisions
Results and Benefits
Core Performance Metrics
| Metric | Performance | Business Value |
|---|---|---|
| Query QPS | Stable 100+, peak 200+ | Support concurrent access from official website, API, and operations |
| Latency | P95=30ms, P99=100ms | Users can view commission in real-time with no perceived delay |
| Data Storage | Stable support for tens of TB | Store 3+ years of historical commission data for traceability |
| Rule Iteration Efficiency | Adjustments completed within 1 day | Commission ratio and sharing rule changes don't require pipeline modifications |
Core Business Benefits
- User Acquisition Efficiency Improved: Real-time, accurate commission calculation enables referrers to instantly view earnings and referred users to quickly receive sharing (if applicable), significantly boosting user promotion enthusiasm
- Market Maker Ecosystem Strengthened: Low-latency API supports market maker real-time revenue settlement, reducing disputes from data delays, improving market maker cooperation satisfaction
- Operations Cost Reduced: VeloDB's ability of query-time computation eliminates complex computation logic development on the Flink side, reducing rule iteration costs, shortening operations report generation time from hours to seconds
Use Case 3: Trading Analysis Solution
Web3 exchange trading analysis differs fundamentally from traditional centralized exchanges with core characteristics:
- Multi-Dimensional Data: Integration of off-chain platform trading data (spot/derivatives orders, fees, fund transfers) and on-chain blockchain data (wallet address transactions, smart contracts, cross-chain transfers), forming an integrated on-chain + off-chain analysis with data structures covering structured trading details, semi-structured on-chain logs, and other types.
- Diverse Query Scenarios: Business needs to support four core query scenarios: user self-service queries (historical trading records, asset details), customer service assisted queries (user trading dispute tracing), operations analysis (multi-dimensional report statistics), and compliance auditing (historical data retrospection), with query types including precise point queries, range queries, complex join queries, and Ad-Hoc free exploration.
- Explosive Data Scale: An exchange with over $10 billion daily trading volume can accumulate 400TB+ trading data, requiring long-term storage (3-5 years) to meet compliance and retrospection needs, placing extremely high demands on balancing storage capacity and query performance.
- Real-Time and Historical Data: User asset queries and latest trading record queries need near-real-time response, while historical trading retrospection and annual report analysis need efficient large-scale historical data scanning—both requirements must be simultaneously met.
Core Technical and Business Requirements
Technical requirements
-
Large-scale storage: Reliably supports 400 TB+ of long-term storage for user trading data, user profile data, asset data, and on-chain transaction data.
Business value: Meets compliance audits, historical transaction tracing, and long-term data analysis needs.
-
High-concurrency queries: Stably handles 200+ QPS, with elastic scaling during peak periods and no query congestion.
Business value: Ensures concurrent multi-user access, batch processing by customer support, and parallel generation of operational reports.
-
Low-latency response: P95 latency ≤ 3 seconds for Ad-Hoc detailed analysis, and ≤ 1 second for precise point lookups (e.g., asset queries).
Business value: Improves self-service query experience, reduces customer support response time, and supports faster operational decision-making.
-
Flexible query support: Compatible with standard SQL syntax, supporting multi-table joins, complex filtering, aggregations, and pagination for Ad-Hoc exploration.
Business value: Meets personalized analysis needs across operations, product, and compliance teams without relying on engineering development.
-
Real-time data synchronization: Off-chain transaction data and on-chain API data are synchronized to the analytics platform within 1–3 seconds, ensuring data freshness.
Business value: Supports real-time asset queries and up-to-date transaction history lookups.
Business requirements
-
Full-spectrum querying: Supports queries across user trading data (order details, fees, transaction status), user profile data (registration time, verification status), asset data (positions, balances, historical changes), and on-chain transaction data (wallet flows, contract interactions).
Business value: Enables end-to-end analysis across users, trades, assets, and on-chain behavior to cover diverse analytical scenarios.
-
Multi-dimensional reporting: Supports aggregation by trade type, time dimension, region, and user tier to generate reports on trading volume, turnover, and user activity.
Business value: Informs operational strategy optimization, product iteration, and marketing effectiveness evaluation.
-
Historical data traceability: Enables precise queries over any time range (e.g., up to three years back), with filtering by order ID, wallet address, or user ID.
Business value: Resolves user transaction disputes and satisfies regulatory and compliance audit requirements.
-
On-chain and off-chain correlation: Supports joint analysis of platform trading data and on-chain transaction data to identify cross-context user behavior.
Business value: Provides deeper insight into trading preferences and supports personalized product recommendations and risk identification.
Technical Architecture
Using VeloDB as the core analytics engine, we built a streamlined and efficient architecture: Data Collection → Real-Time Sync → Storage Analysis → Multi-Terminal Applications. The design meets the large-scale Web3 exchange's trading, technical, and business requirements.
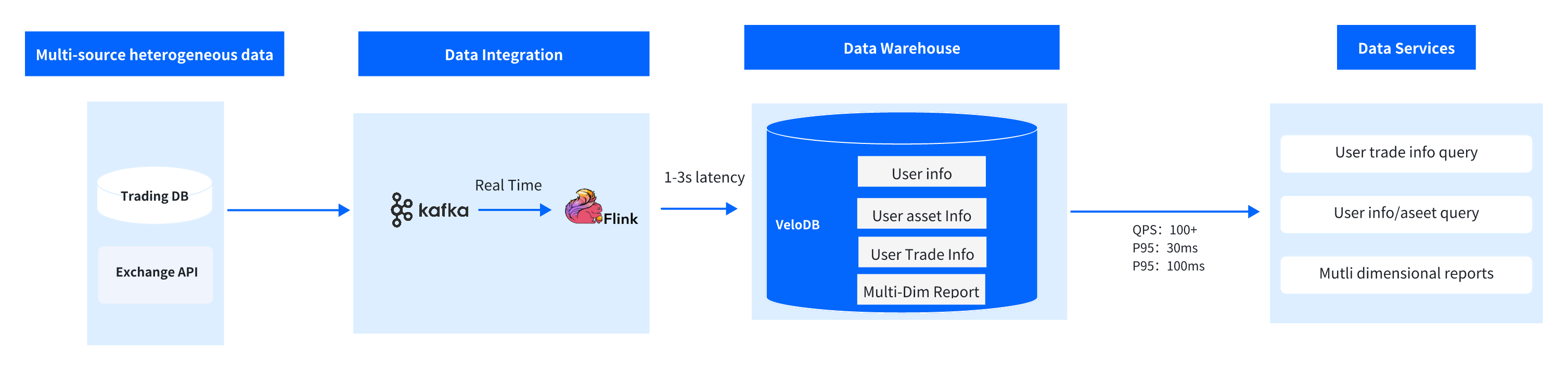
1. Core Business Flow:
- Data Collection: Off-chain trading data (orders, assets) written to Kafka in real-time
- Real-Time Sync: Flink consumes Kafka data, standardizes format, and micro-batch writes to VeloDB via Flink Doris Sink
- Query Trigger: Users, customer service, and operations initiate queries through respective terminals (e.g., asset queries, report statistics)
- Analysis Response: VeloDB returns results quickly through index optimization, partition filtering, and parallel computation based on query type
- Result Application: Query results used for user self-service viewing, customer service dispute handling, operations decision optimization, and compliance audit archiving
2. Data Synchronization Layer
- Data Source: On one hand, ingest off-chain data from exchange trading database (user basic info, order details, asset balances, fund transfer records); on the other hand, ingest on-chain data via exchange API (wallet address transaction records, smart contract interaction logs, cross-chain transfer details), achieving on-chain + off-chain integrated data collection
- Data Synchronization Flow: Kafka handles high-throughput trading data (peaks can reach millions per second), preventing data loss; Flink performs lightweight data cleaning (format standardization, field completion), then batch writes to VeloDB via a dedicated Flink Doris Sink component, controlling synchronization latency within 1-3 seconds, ensuring data timeliness while avoiding high-frequency write impact on query performance
3. VeloDB Storage and Analytics Layer
VeloDB serves as the solution core, taking dual responsibility for 400TB+ data storage + full-scenario query analysis, with key capabilities precisely matching business requirements:
- Large-Scale Storage Optimization: Columnar storage + partitioning + bucketing three-tier strategy. Time-based (day/month) partitioning for historical data, queries only scanning target partitions, avoiding full table scans; user ID/wallet address hash bucketing for improved join query efficiency, perfectly supporting 400TB+ data long-term storage and fast retrieval.
- High-Concurrency Query Support: Through vectorized computation and a pipeline execution engine, the system can stably support 200+ QPS with millisecond-level query latency.
- Low-Latency Response: Point queries (such as user asset queries) achieve 200ms latency through primary key index. Ad-Hoc detail analysis achieves P95 latency of 1-3s through partition filtering, columnar scanning, and parallel computation, meeting multi-scenario response requirements.
4. Data Service Layer
VeloDB provides the following data services in trading analysis scenarios through standard SQL interface and JDBC/ODBC drivers:
- User Query Terminal: Support users' self-service queries of historical trading records, asset details, and on-chain trading flows with real-time result returns.
- Customer Service System: Provide user trading dispute tracing queries, quickly locate order status and fund flows, assisting dispute handling.
- Operations Report Platform: Support automatic generation of multi-dimensional statistical reports such as daily/weekly/monthly trading volume rankings, user-level trading distribution, and on-chain/off-chain trading activity comparison.
- Compliance Audit System: Provide precise retrospection and export functionality for historical trading data, meeting regulatory audit requirements.
Trading Detail Query Example
1. Platform Trading Detail Table:
CREATE TABLE platform_trade_detail (
trade_id VARCHAR(64) NOT NULL COMMENT 'Platform trading order unique ID',
user_id VARCHAR(64) COMMENT 'Trading user ID',
trade_time DATETIME COMMENT 'Trading time',
trade_type VARCHAR(32) COMMENT 'Trading type (Spot/Futures/Options/Leverage)',
symbol VARCHAR(32) COMMENT 'Trading pair (e.g., BTC-USDT)',
order_type VARCHAR(16) COMMENT 'Order type (Limit/Market/Stop-loss)',
trade_amount DECIMAL(20,8) COMMENT 'Trading amount (USDT)',
trade_price DECIMAL(20,8) COMMENT 'Trading price (USDT/unit)',
fee_amount DECIMAL(20,8) COMMENT 'Fee amount (USDT)',
trade_status VARCHAR(16) COMMENT 'Trading status (Success/Failed/Cancelled)',
fund_flow_type TINYINT COMMENT 'Fund flow: 1-Inflow, 2-Outflow'
) ENGINE=OLAP
DUPLICATE KEY(`trade_id`, `user_id`, `trade_time`)
PARTITION BY RANGE(`trade_time`)
(
PARTITION p20241004 VALUES [('2024-10-04'), ('2024-10-05')),
-- Other partitions omitted
)
DISTRIBUTED BY HASH(`user_id`) BUCKETS 8
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY"
-- Other properties omitted
);
Table Design Highlights:
- Partition Filtering: Filter by
trade_timefor 2025 January to present, scanning only the corresponding partitions to avoid a full scan of 400TB of data. - Hash Bucketing: Store by
user_idbucketing, quickly locate the target users' trading records, improving query efficiency 10x. - Pagination Optimization: Support efficient
LIMIT OFFSETpagination, even when querying historical data, and pagination response latency remains ≤1s, meeting user self-service query experience
2. Query:
Query all spot trading records from January 1, 2025, to present, sorted by trading time descending, including trading pair, amount, price, fee, trading status, with pagination support (20 per page).
SELECT
trade_id AS Trading_Order_ID,
trade_type AS Trading_Type,
symbol AS Trading_Pair,
order_type AS Order_Type,
trade_amount AS Trading_Amount_USDT,
trade_price AS Trading_Price_USDT_Unit,
fee_amount AS Fee_USDT,
trade_status AS Trading_Status,
DATE_FORMAT(trade_time, '%Y-%m-%d %H:%i:%s') AS Trading_Time
FROM platform_trade_detail
WHERE user_id = 'web3_usr_6666' -- Target user ID
AND trade_type = 'Spot' -- Filter spot trading
AND trade_time >= '2025-01-01 00:00:00'
ORDER BY trade_time DESC
LIMIT 20 OFFSET 0; -- Pagination: Page 1, 20 per page
Results and Benefits
Production Core Metrics:
| Metric | Performance | Business Value |
|---|---|---|
| Data Storage | Stable support for 400TB+ | Store 3+ years of full trading data for compliance |
| Query QPS | Stable 200+, peak 300+ | Support concurrent queries from multiple users, customer service, and operations |
| Latency | Precise point query ≤1s, Ad-Hoc analysis P95=1-3s | Improved user experience, reduced customer service and operations wait time |
| Historical Query Efficiency | 3-year-old data query ≤3s | Meet long-term historical data traceability requirements |
Business Benefits:
1. Operations Decision Acceleration: User historical trading and asset detail query response time completed within 1-3s
2. Compliance Risk Reduction: 400TB+ full trading data long-term storage, supporting precise retrospection for any time period, meeting global regulatory audit requirements
3. Better on-chain and off-chain analytics: Enables unified analysis of platform trading data and on-chain activity, providing deeper insight into users' cross-scenario trading behavior and preferences.
Why VeloDB: Core Capabilities for Web3 Exchange Real-Time, Stable Data Services
VeloDB, built on an optimized Apache Doris core, offers high concurrency, low latency, high availability, and easy scalability, capabilities that closely align with the operational demands of modern Web3 and crypto exchanges. Below is how these characteristics address key business scenarios:
1. High-Availability Architecture: Ensuring Business Continuity
For a global trading platform, any service disruption can result in significant financial losses and loss of user trust. VeloDB provides end-to-end high availability through cross-AZ deployment, active-standby clusters, and multi-replica storage:
- Both frontend management nodes (FE) and backend data nodes (BE) are deployed across availability zones, ensuring each AZ maintains an independent data replica and preventing a single-zone failure from causing data unavailability.
- Mission-critical data is written to both active and standby clusters simultaneously. Query traffic is load-balanced, and in the event of a primary cluster failure, failover occurs within seconds, ensuring uninterrupted operation of critical functions such as withdrawal risk controls and anti-money laundering controls.
- Write operations are atomic, preventing partial writes that could lead to data inconsistency and ensuring compliance with the stringent data reliability standards required in financial applications.
In anti-money laundering (AML) and withdrawal risk control scenarios, this architecture ensures continuous access to risk analytics data, providing a solid foundation for fund security. In production, the system has achieved 99.99% service availability.
2. Second-Level Real-Time Capability: Supporting High-Frequency Business Decisions
Cryptocurrency prices fluctuate frequently, and real-time data processing directly impacts business outcomes. VeloDB achieves second-level data processing through CDC direct connection + pre-aggregation indexes + query optimization:
- Supports Flink CDC direct write with data synchronization latency controlled within 1-3 seconds, enabling trading data to quickly enter the analysis pipeline after generation.
- For high-frequency query scenarios like commission calculation and trading ranking, builds pre-aggregation indexes to front-load computation logic, avoiding repeated computation, with commission query P95 latency of only 30ms.
- The query optimizer automatically selects optimal execution plans based on query statements, enabling Ad-Hoc query scenarios to achieve 1-3 seconds of latency for 400TB+ data-detail queries.
In World Trading Competition scenarios, this capability enables second-level updates and ranking computations for participant trading data, supporting real-time broadcasting of competition data and enhancing user engagement.
In commission calculation scenarios, real-time updates to user commission amounts ensure referrers receive earnings promptly, driving higher conversion rates.
3. Large-Scale Data Processing: Petabyte-Level Data Storage and Analysis
With transaction data now reaching hundreds of terabytes, it continues to grow at a terabyte-scale daily rate. VeloDB handles this volume efficiently through columnar storage optimization, partitioning strategies, and parallel processing:
- Columnar storage with compression and encoding reduces the storage costs of trading data by over 60% while improving query performance.
- Data can be partitioned by dimensions such as time or user ID. Historical data is archived by partition, and queries scan only the relevant partitions, significantly speeding up retrieval.
- Backend (BE) nodes scale horizontally, with queries automatically split and executed in parallel across nodes. A multidimensional analysis of 400 TB of transaction data can be completed in seconds.
In transaction analysis scenarios, these capabilities enable the platform to perform full historical analysis across 400TB+ of user trading data, uncovering long-term trading patterns and preferences. For tax reporting, VeloDB has reduced ETL processing time from several hours to just 1–10 minutes compared to the legacy Spark and S3 architecture, achieving an 8x performance improvement.
4. Ease of Use: Rapid Response to Business Changes
Web3 exchanges operate in a fast-moving environment where new use cases and requirements emerge constantly. VeloDB reduces the cost of adapting to change through its streamlined architecture, rich interfaces, and low operational overhead:
- The architecture requires no complex middleware, keeping deployment and maintenance costs low. Technical teams can get up to speed quickly, bringing new use cases from integration to production in just a few days.
- Standard SQL interfaces allow seamless integration with existing data infrastructure, minimizing the need for code changes.
- Dynamic schema modifications, adding or removing fields and indexes on the fly, make it easy to adapt to evolving requirements such as changes to rebate rules or updates to risk models.
In blockchain transaction tracking, for example, when the platform needed to ingest new on-chain data sources, VeloDB's flexible table design and data synchronization capabilities enabled rapid integration. This allowed the team to quickly correlate on-chain activity with internal platform data, thereby enhancing the platform's risk-detection capabilities.
Summary
VeloDB has become the core data foundation for this global Top 5 cryptocurrency exchange.
VeloDB meets the high-throughput, high-sensitivity requirements of cryptocurrency trading, providing solid guarantees for business security and efficiency improvements, demonstrating irreplaceable technical value. VeloDB supports a variety of real-time analytical use cases, including supporting sub-second queries across hundreds of terabytes of data, thousands of concurrent QPS queries, real-time risk control, and offline analysis.
Key Achievements:
- 400TB+ trading data with real-time analytics
- 5000 QPS peak concurrent query support
- 30ms P95 latency for high-concurrency point queries
- 99.99% service availability for mission-critical applications
- 8x performance improvement in data lake ETL processing
- 60%+ storage cost reduction through columnar compression
Whether you're building real-time risk control systems, implementing compliance analytics, or scaling your trading data infrastructure, VeloDB provides the performance, reliability, and flexibility that Web3 exchanges demand.
Contact the VeloDB team to discuss your specific requirements with our technical experts, or join the Apache Doris community on Slack to learn more about real-time analytics for Web3 applications.