We built a real-time lakehouse with S3 Tables, AWS Glue, and Apache Doris. In this solution, S3 Tables stores data in the Apache Iceberg format on Amazon S3. AWS Glue manages and organizes metadata and schema, providing a single catalog that connects all resources. And Apache Doris (via VeloDB Cloud) runs sub-second queries directly on those Iceberg tables: no ETL, no data copies, no complex architecture.
Together, the S3 Tables + AWS Glue + Apache Doris form a real-time lakehouse that combines the openness of a data lake with the high performance of a data warehouse, providing a key data foundation for AI and agentic workloads.
You get:
- Unified metadata for easy table discovery and governance
- Open Apache Iceberg tables on S3 with ACID, time-travel, and schema evolution
- A high-performance query engine with Apache Doris offering low-latency and high-concurrency
- Interoperability across engines with Spark, Flink, Trino, Doris, and more
This is a practical, production-ready real-time lakehouse you can use to power dashboards, streaming analytics, or AI features directly from the data lake. The solution is also applicable to many other open-source combinations, with table formats like Iceberg, Paimon, catalogs like Unity, Polaris, Gravitino, and query engines like Spark, Flink, and Trino.
Query Fresh S3 Data Instantly with Apache Doris on VeloDB
In this solution, we used VeloDB, the fully managed cloud service for Apache Doris, to implement. VeloDB offers:
- Sub-second queries directly on S3 Iceberg tables
- High concurrency for BI, dashboards, apps, and AI workloads
- Native integration with Glue + S3 Tables for zero-ETL analytics
Demo: Bringing S3 Tables, AWS Glue, and Apache Doris (VeloDB) Together
Let's see how to set up this solution in a demo. We will explore how to harness the power of VeloDB and Apache Doris, as well as configure a third-party engine to work with AWS Glue Iceberg REST Catalog. The demo will include details on how to perform read/write data operations against S3 tables with AWS Glue.
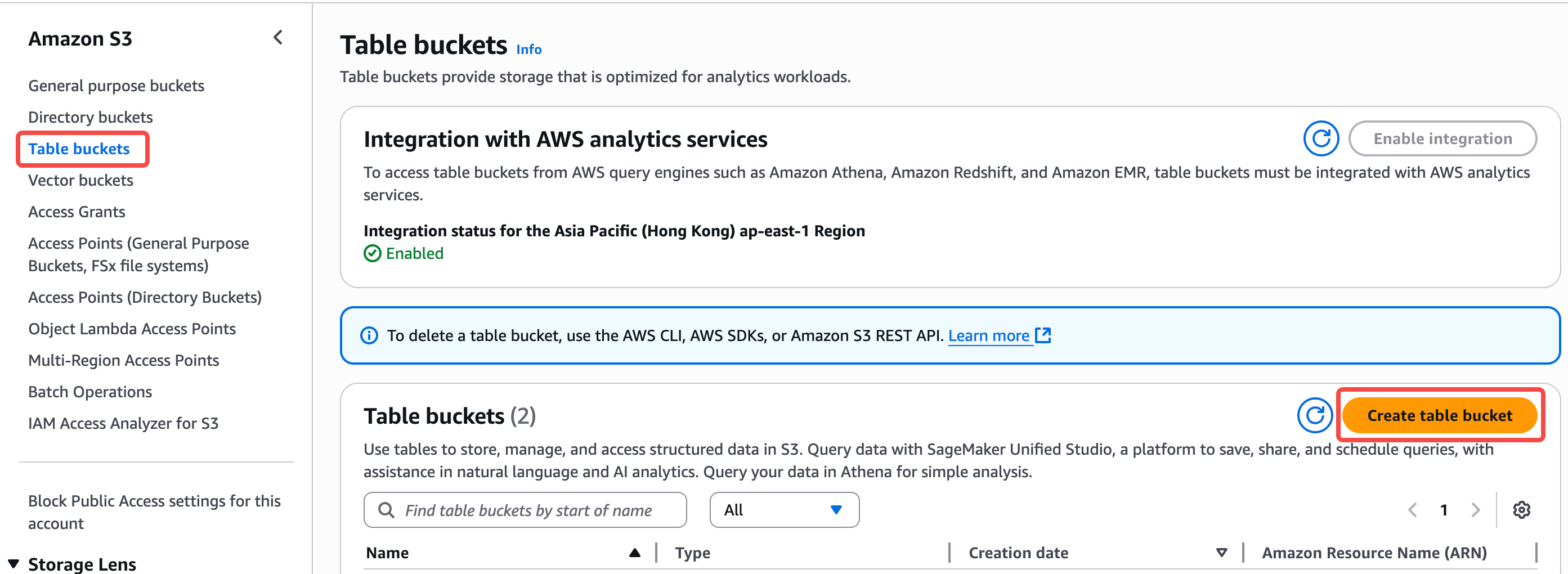
1. Create S3 Table Buckets
2. Create policy for Glue and S3 Tables

Use the following JSON policy:
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"glue:GetCatalog",
"glue:GetDatabase",
"glue:GetDatabases",
"glue:GetTable",
"glue:GetTables",
"glue:CreateTable",
"glue:UpdateTable"
],
"Resource": [
"arn:aws:glue:<region>:<account_id>:catalog",
"arn:aws:glue:<region>:<account_id>:catalog/s3tablescatalog",
"arn:aws:glue:<region>:<account_id>:catalog/s3tablescatalog/<bucket_name>",
"arn:aws:glue:<region>:<account_id>:table/s3tablescatalog/<bucket_name>/<db_name>/*",
"arn:aws:glue:<region>:<account_id>:database/s3tablescatalog/<bucket_name>/<db_name>"
]
},
{
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": "*"
}
]
}
3. Attach the policy to user
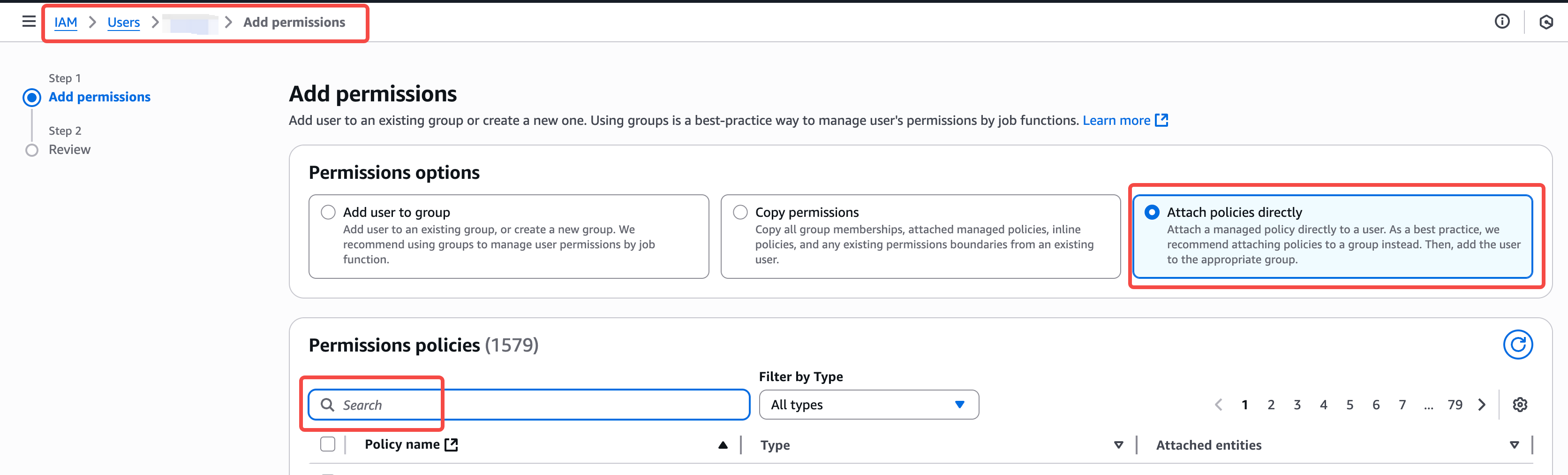
Search the policy you just created and attach it to your user.
4. Connect to Iceberg catalog using SQL
-- Create Catalog
CREATE CATALOG my_glue_catalog properties (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'warehouse' = '<acount_id>:s3tablescatalog/<bucket_name>',
'iceberg.rest.uri' = 'https://glue.<region>.amazonaws.com/iceberg',
'iceberg.rest.sigv4-enabled' = 'true',
'iceberg.rest.signing-name' = 'glue',
'iceberg.rest.signing-region' = '<region>',
'iceberg.rest.access-key-id' = '<ak>',
'iceberg.rest.secret-access-key' = '<sk>',
'test_connection' = 'true'
);
-- Switch to the catalog
SWITCH my_glue_catalog;
-- View current existing databases
SHOW DATABASES;
-- Create a new database
CREATE DATABSE gluedb;
-- Change to the newly created database
USE gluedb;
-- Create a new Iceberg table
CREATE TABLE iceberg_table(id INT, name STRING);
-- Insert values into table
INSERT INTO iceberg_table VALUES(1, "Jacky");
-- Query the Iceberg table
SELECT * FROM iceberg_table;
Replace the placeholders with the real information.
5. Integrate S3 Table with VeloDB Studio
Here's a one-minute demo showing how to integrate with AWS Glue and S3 Tables using the VeloDB Studio UI.
<video width={"100%"} height={"auto"} muted autoPlay loop controls
<source src="https://cdn.selectdb.com/static/s3_tables_velodb_studio_demo_d33e42d508.mp4" type="video/mp4"></source>
Conclusion and Next Steps
A unified data foundation is what makes real-time analytics possible, and key for companies to adopt large-scale AI and agentic workloads.
S3 Tables and AWS Glue provide an open, governed data layer, and VeloDB (powered by Apache Doris) delivers sub-second analytics directly on that data. This real-time lakehouse offers a simpler architecture, smarter governance, and AI readiness, allowing teams to query fresh information without complex ETL or data silos.
Ready to try out the solution yourself? Join the Apache Doris community on Slack and connect with Doris experts and users. For a fully managed Apache Doris cloud service, please contact the VeloDB team.