Streaming data is only as valuable as a team's ability to analyze it in real-time; however, connecting Kafka event streams to a fast analytics engine often requires building custom ingestion layers, facing high maintenance cost for data sync interruptions and throughput fluctuations.
We're excited to announce the new VeloDB Kafka Connector, a native connector that helps you stream data from Confluent Cloud (a managed cloud service for Kafka) into VeloDB (a managed cloud service for Apache Doris).
The connector combines the power of Kafka's event streaming and Apache Doris' real-time analytics through their respective managed cloud services, making it easier than ever to build real-time dashboards, user behavior insights, and monitoring systems without requiring heavy custom development.
VeloDB Kafka Connector: How it Works
Here's an overall architecture of the VeloDB Kafka Connector:
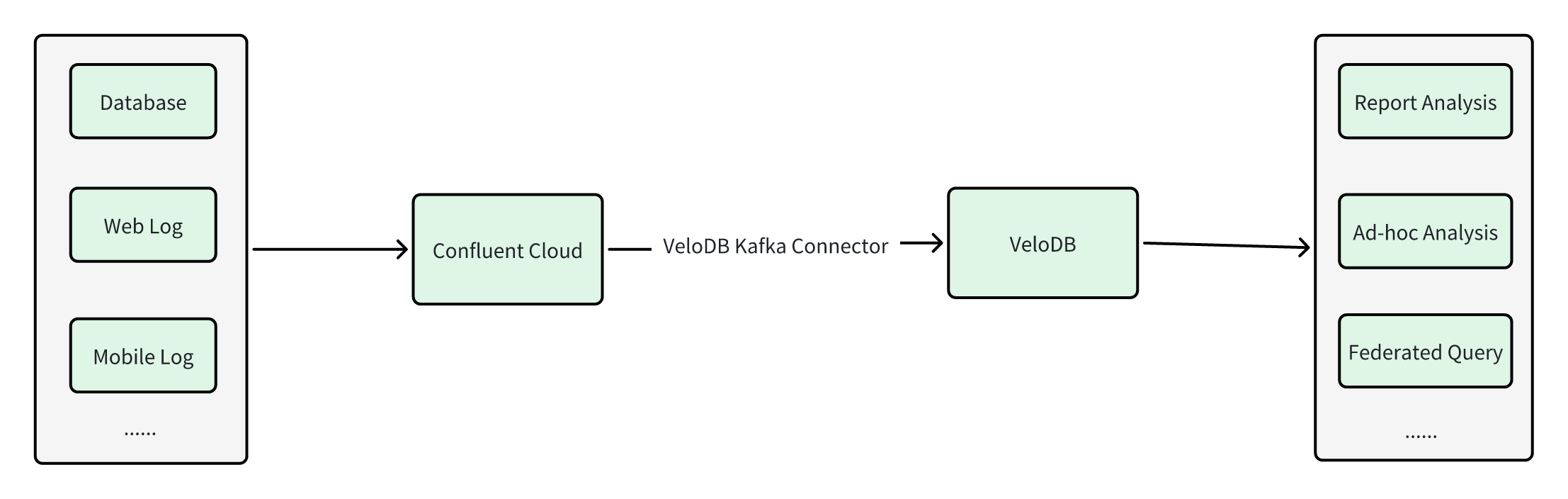
Upstream data from various business applications (including operational databases, web logs, and mobile logs) is streamed into Confluent Cloud and organized as Kafka topics. The VeloDB Kafka Connector, deployed in Confluent Cloud, continuously consumes data from specified topics and writes the data into VeloDB. Once the data is in VeloDB, users can immediately use it for report analysis, ad-hoc queries, and even federated queries, unlocking instant insights from fresh, live data across the business.
With the VeloDB Kafka Connector, there's no need for additional development. Users can easily synchronize upstream data to VeloDB in real-time through a simple UI-based configuration, allowing them to focus on business operations.
Additionally, the VeloDB Kafka Connector supports direct consumption of Kafka messages in multiple formats, such as JSON, Avro, and Protobuf, meeting the needs of various business scenarios.
Demo: How to Use the VeloDB Kafka Connector
In this demo, we'll use the Order data from Confluent Cloud's sample data. As the data source continuously generates data and writes it to a topic, we'll start the VeloDB Kafka Connector to write the real-time generated data to a VeloDB instance.
1. Environment Preparation
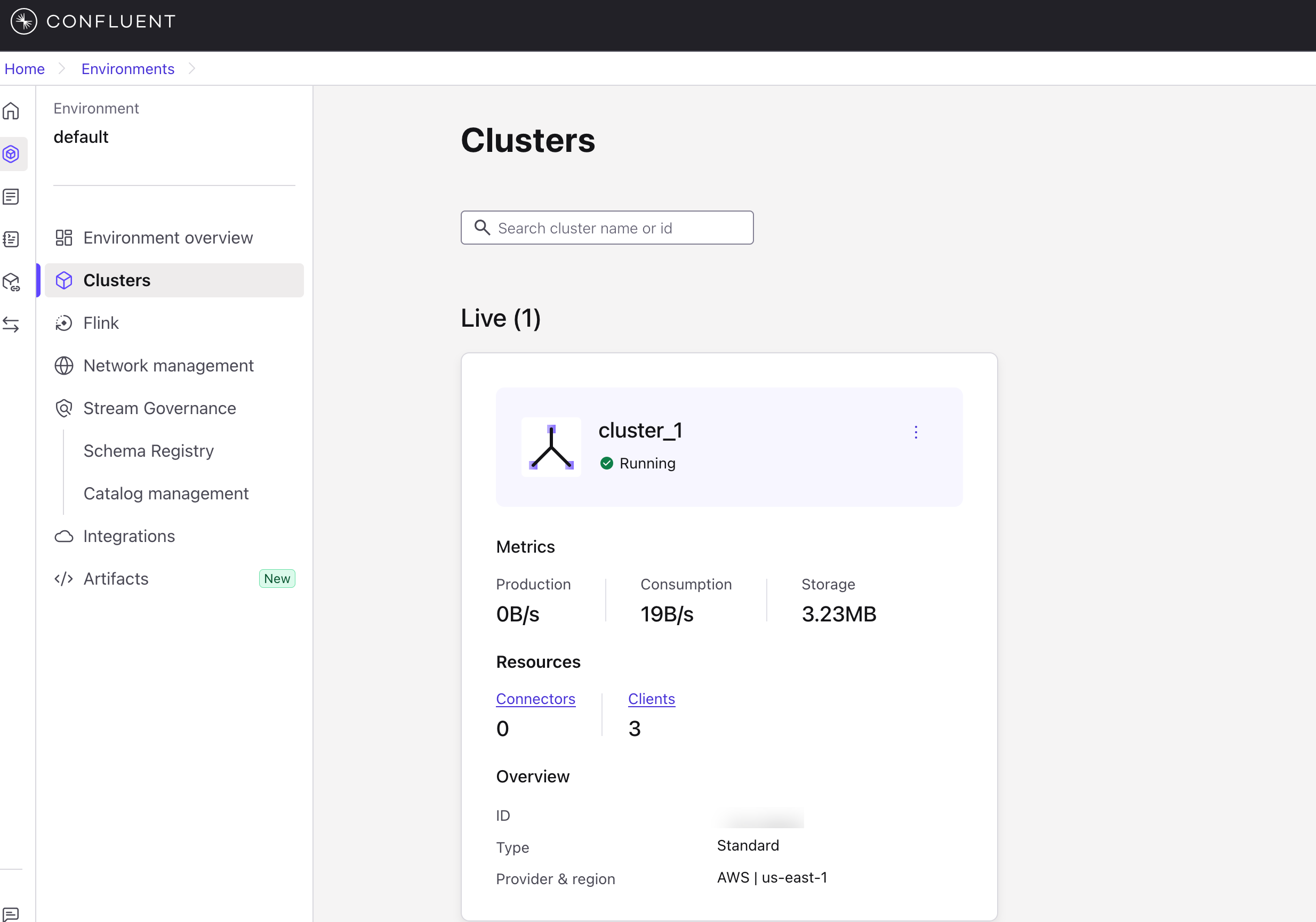
A. Create a cluster on Confluent Cloud as follows:
B. Create a repository and cluster on VeloDB as follows:
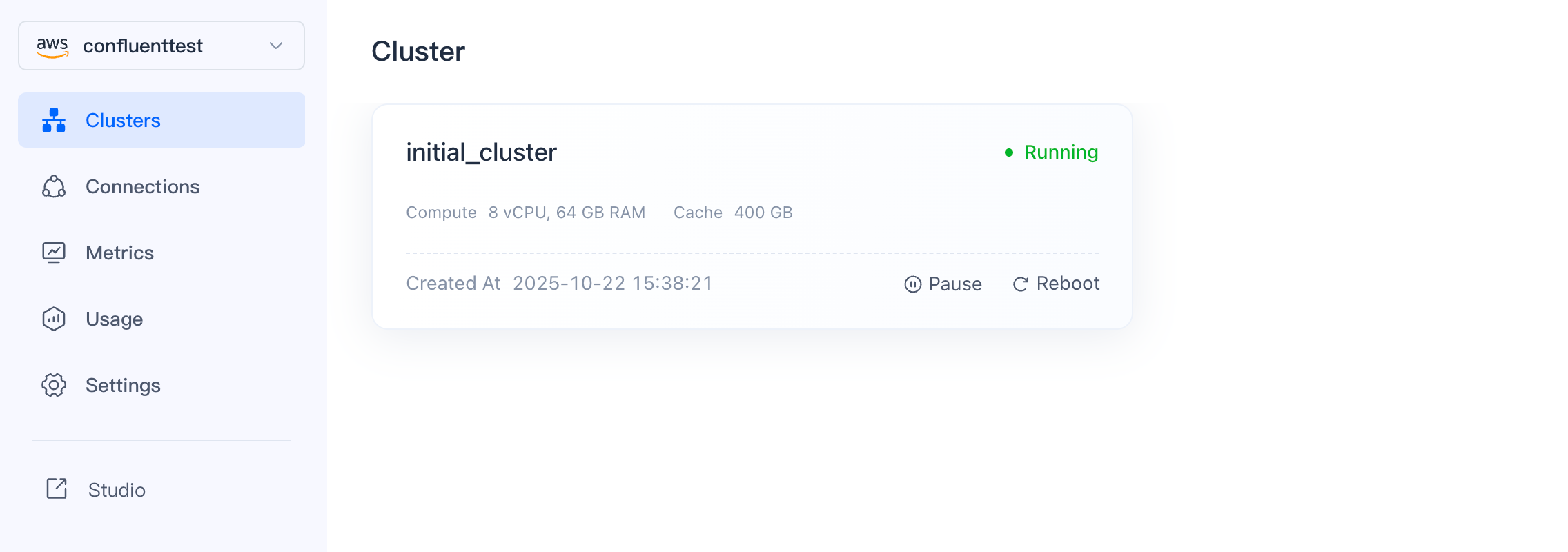
Note: Both must be located in the same region.
2. Start the Sample Data Source in Confluent Cloud
On the Connectors page, select "Sample Data" and then choose "Orders."
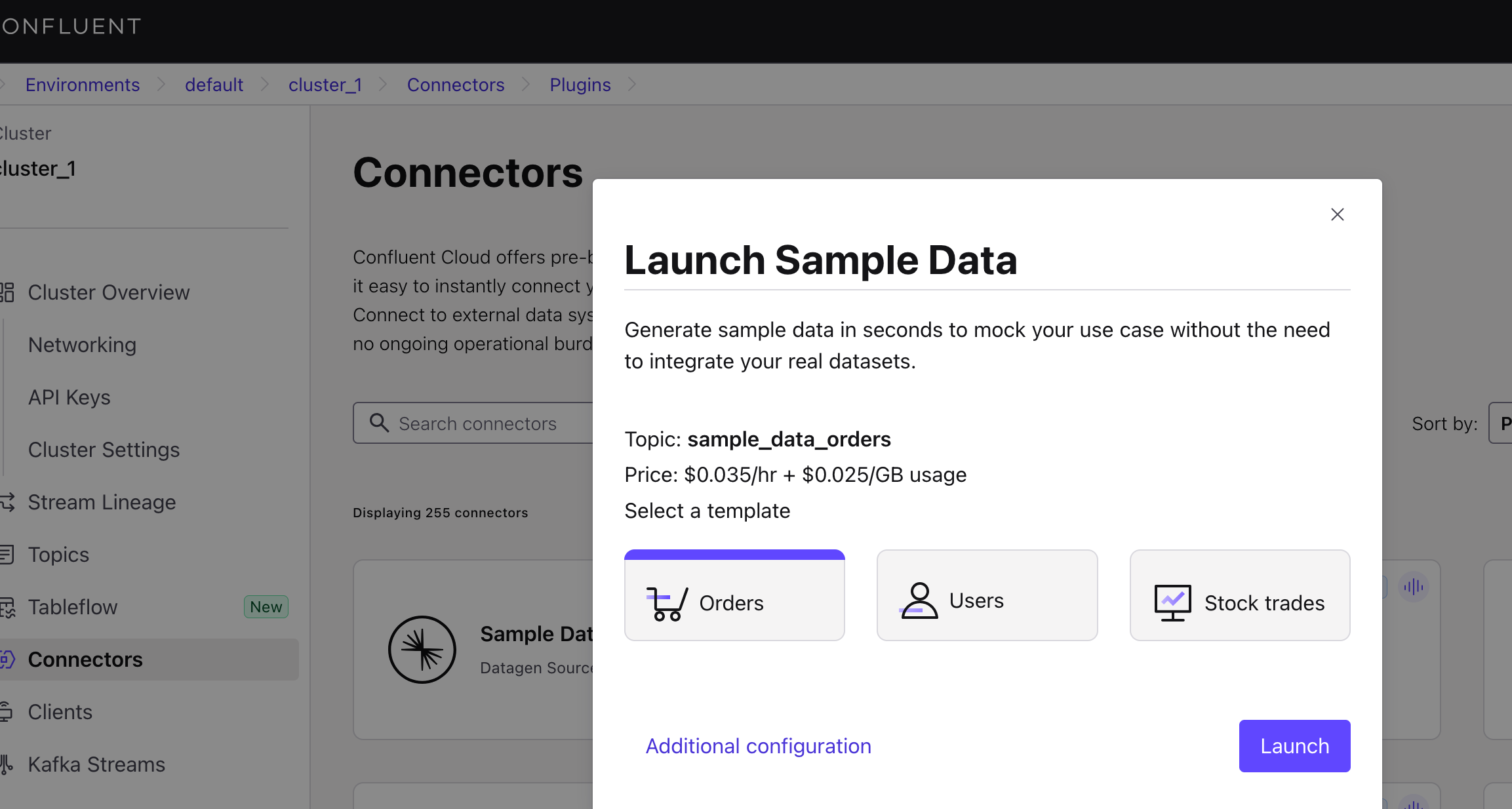
Click Additional Configuration to create a Topic and select the Format. Here, we use the JSON format for demonstration.

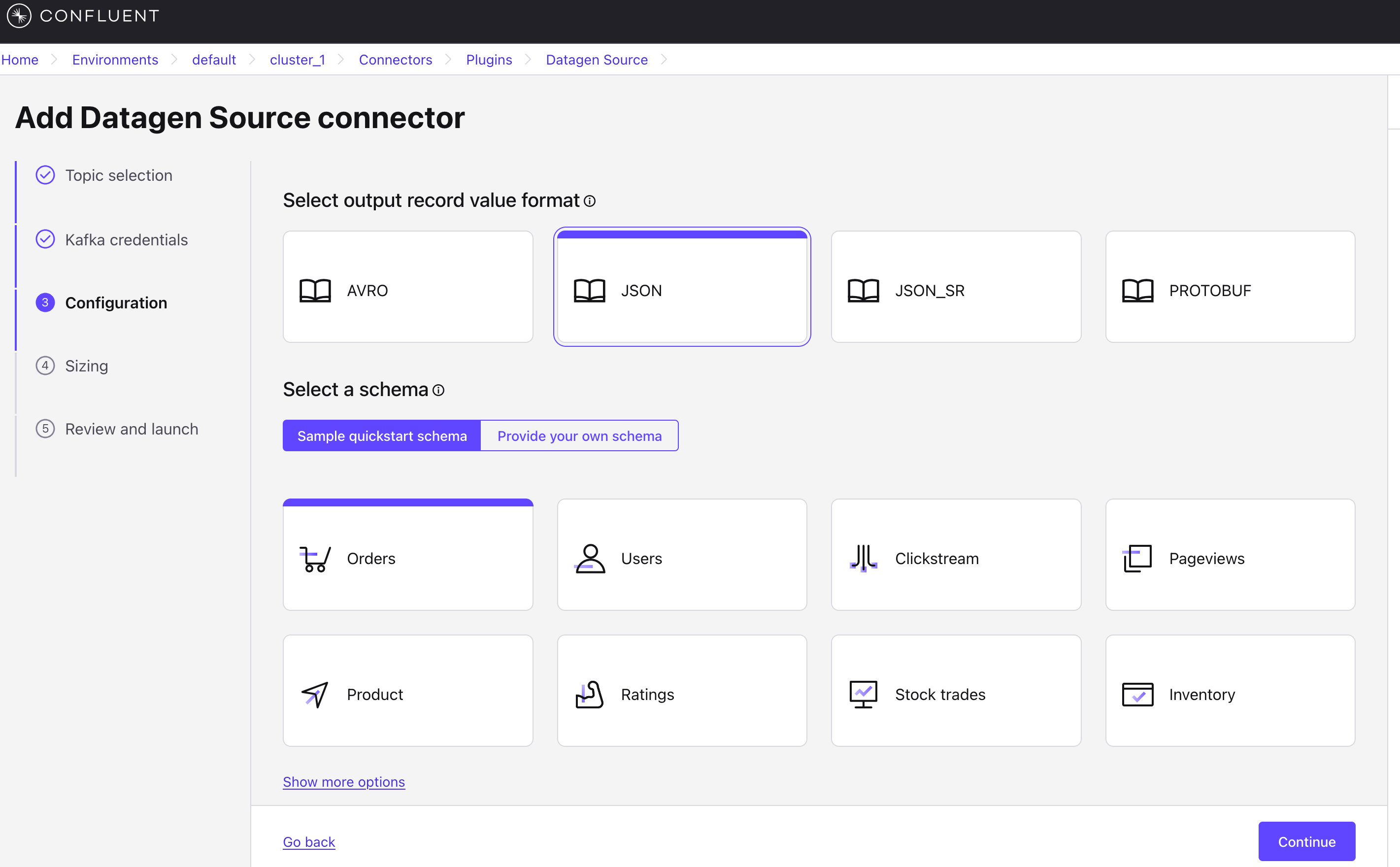
Submit after completing the configuration

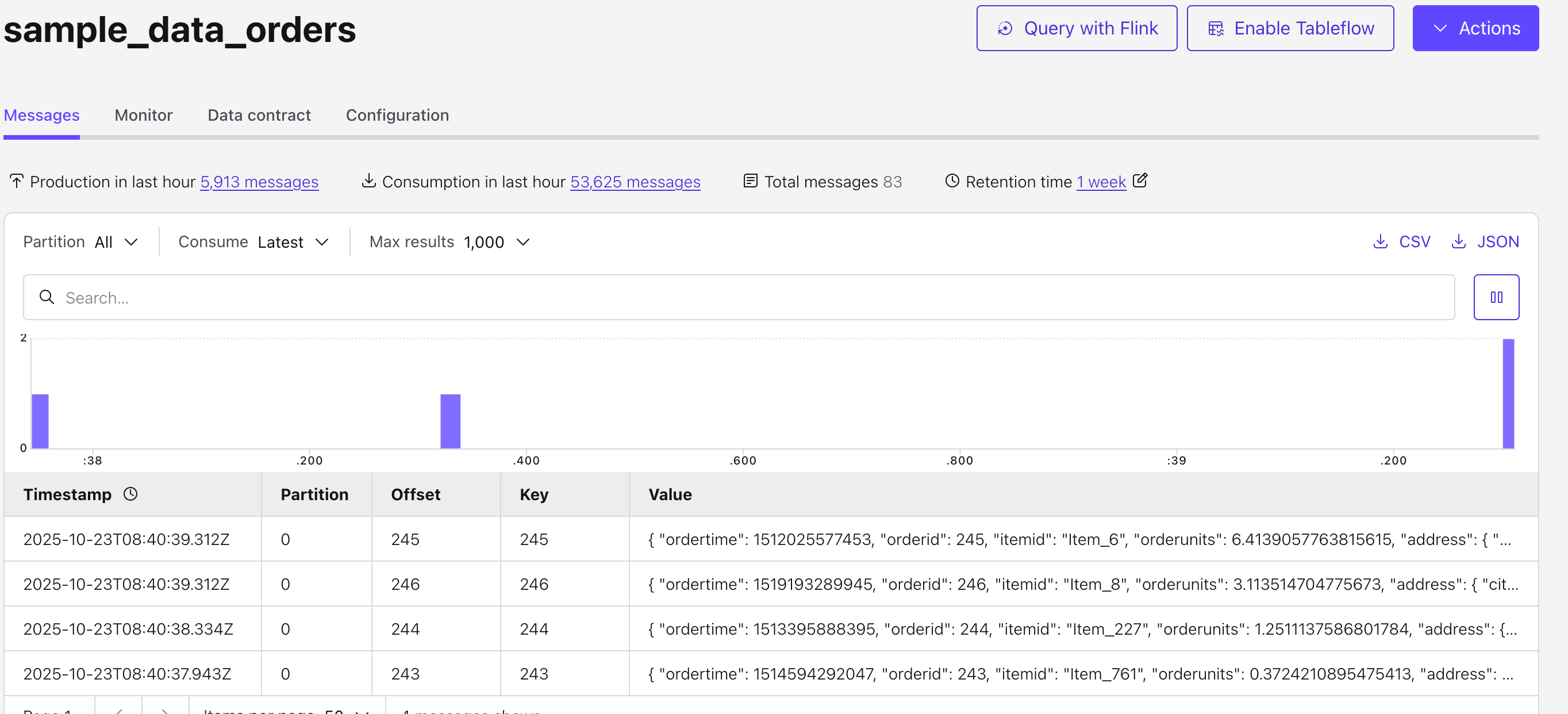
You can view the generated data in the Topic.
3. Create a database and table in VeloDB
CREATE DATABASE demo;
USE demo;
CREATE TABLE orders (
orderid BIGINT,
ordertime BIGINT,
itemid STRING,
orderunits DECIMAL(15, 4),
address JSON
)
UNIQUE KEY(orderid)
DISTRIBUTED BY HASH(orderid) BUCKETS 8;
4. Deploy the VeloDB Connector in Confluent Cloud
A. Install the VeloDB Connector
First, you need to install the VeloDB Connector in Confluent. On the Connector interface, click "Add Connector", then "Add plugin" in sequence, and configure the settings for the VeloDB Connector.
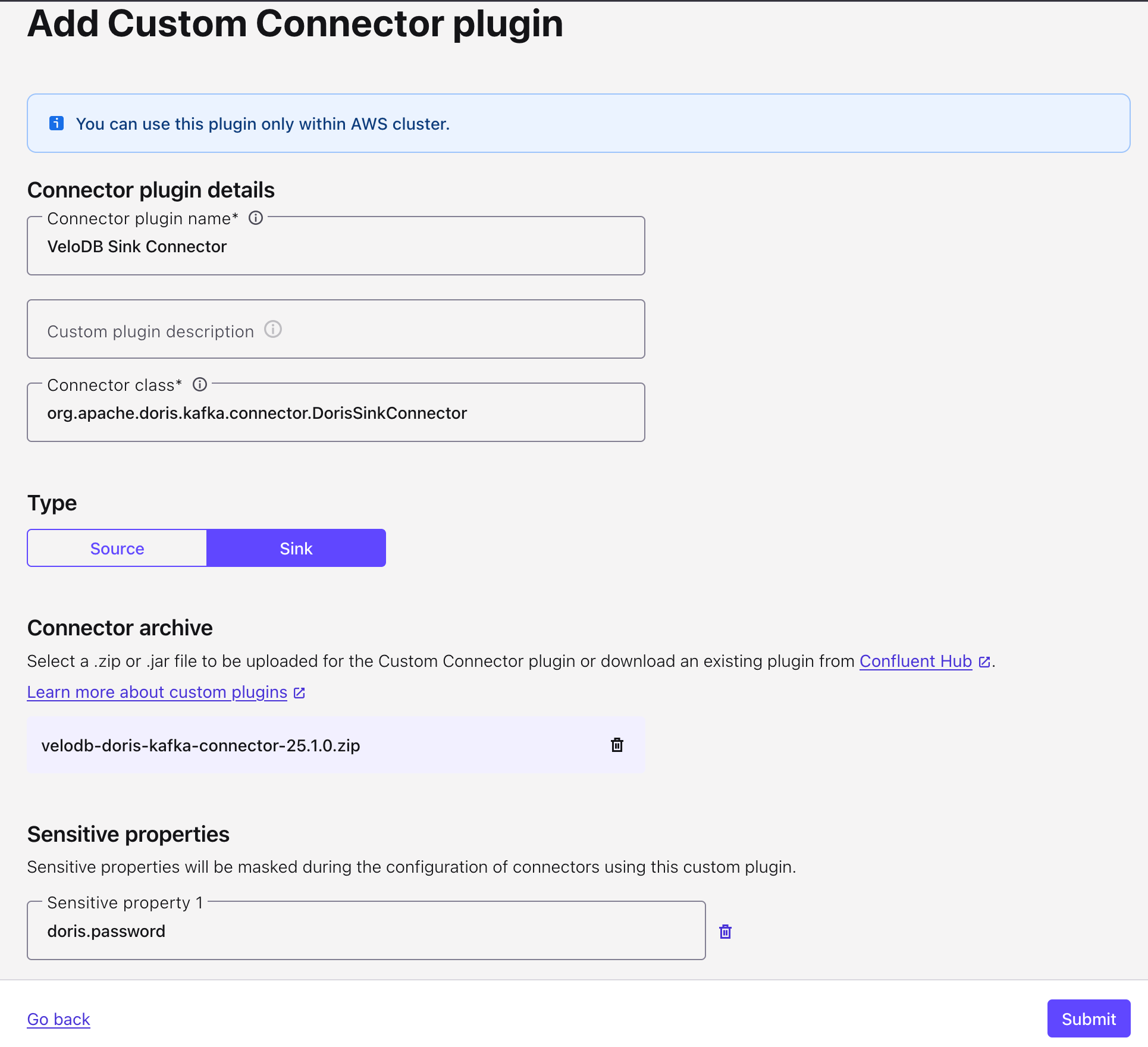
Connector class: org.apache.doris.kafka.connector.DorisSinkConnector
Connector type: Sink
Connector archive:
The Confluence Cloud custom connector requires us to upload the connector package in zip format. You can click here to download it.
Sensitive properties: doris.password
After successful installation, go to the Connector Plugins interface and click the Connector to configure it.
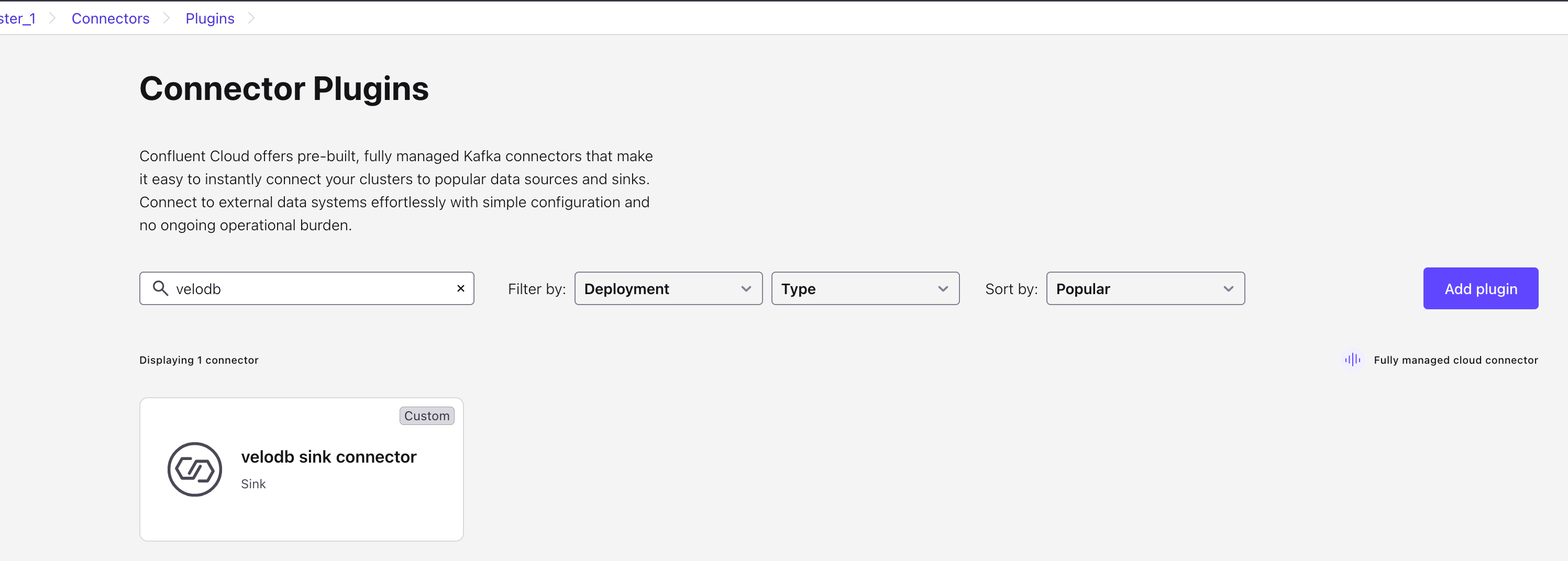
B. Configure the VeloDB Connector Task
Configure the synchronization task on the Connector Task interface.
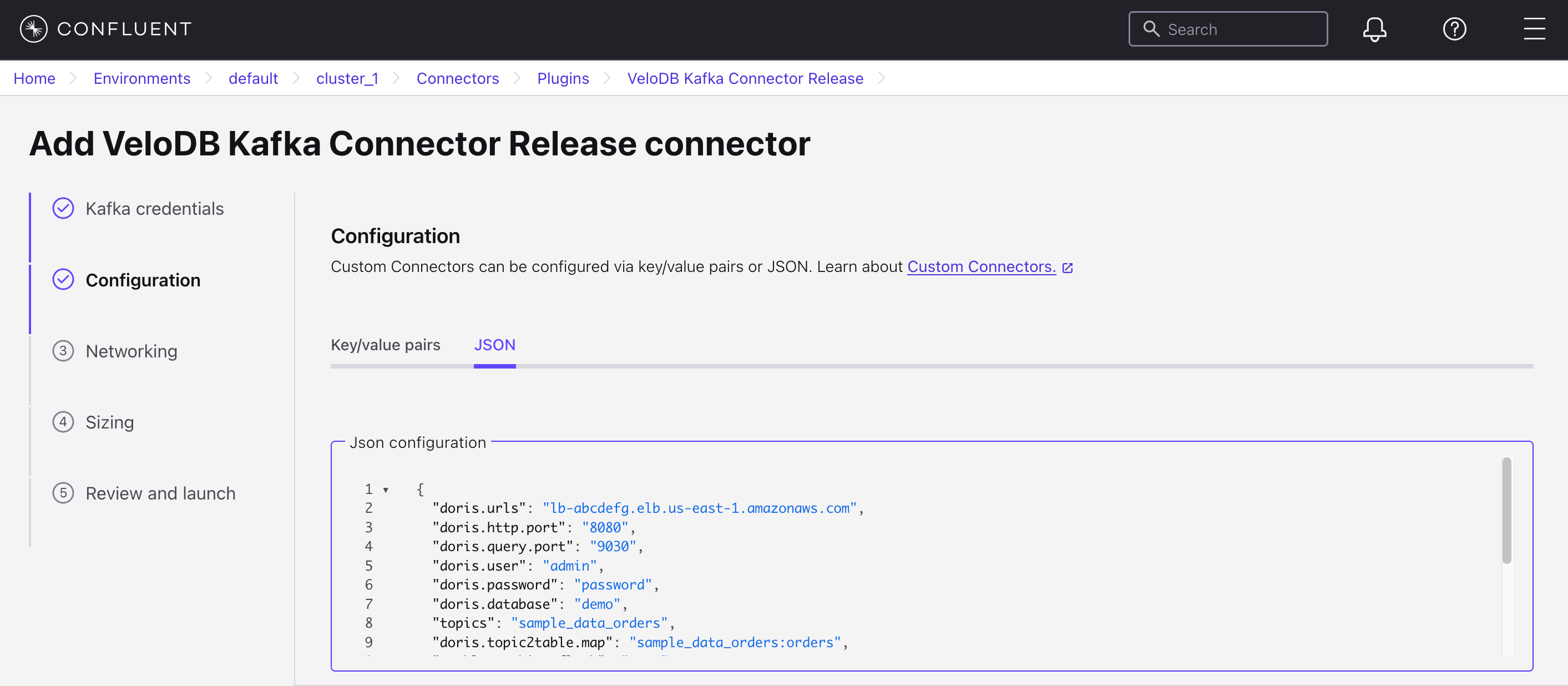
The complete configuration is as follows:
{
"doris.urls": "lb-abcdefg.elb.us-east-1.amazonaws.com",
"doris.http.port": "8080",
"doris.query.port": "9030",
"doris.user": "admin",
"doris.password": "password",
"doris.database": "demo",
"topics": "sample_data_orders",
// defines the mapping relationship between topics and VeloDB tables
"doris.topic2table.map": "sample_data_orders:orders",
"enable.combine.flush": "true",
"buffer.flush.time": "10",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": "false"
}
Fine detailed configuration information in our documentation: https://doris.apache.org/docs/dev/ecosystem/doris-kafka-connector
C. Specify the Connection Endpoints
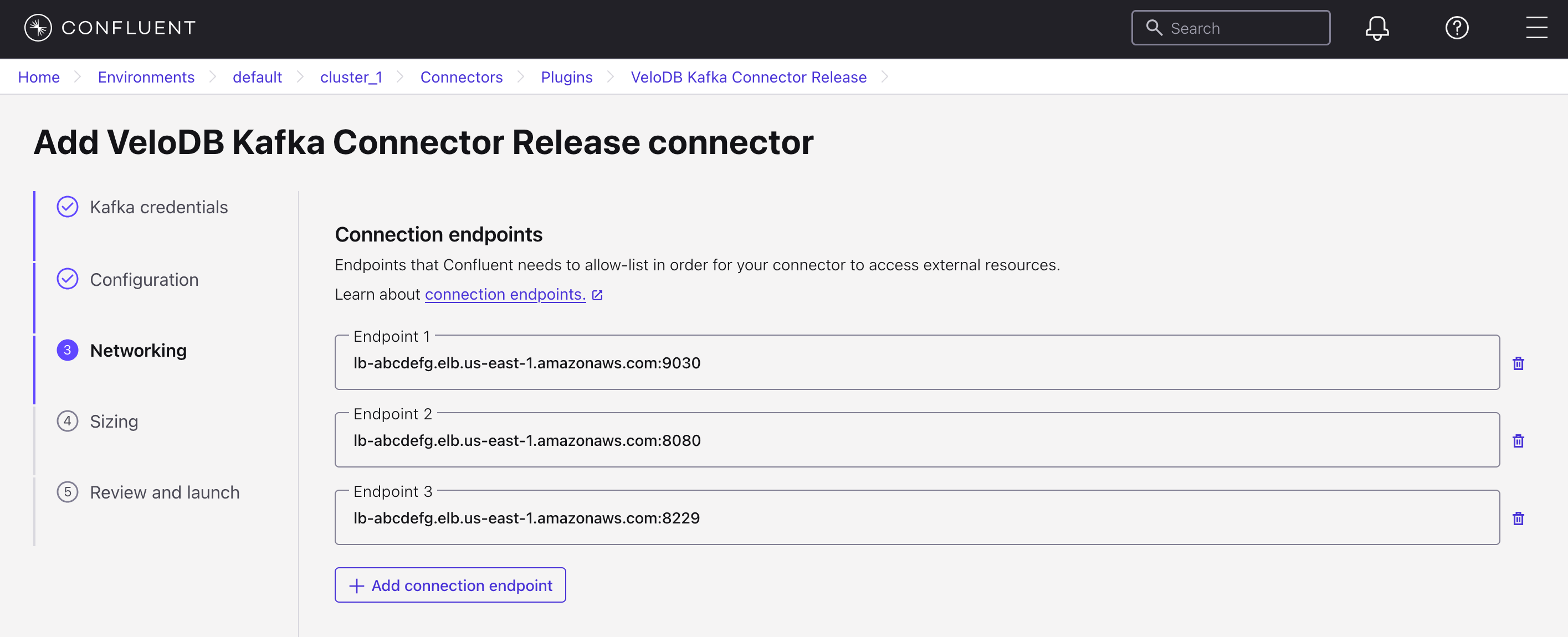
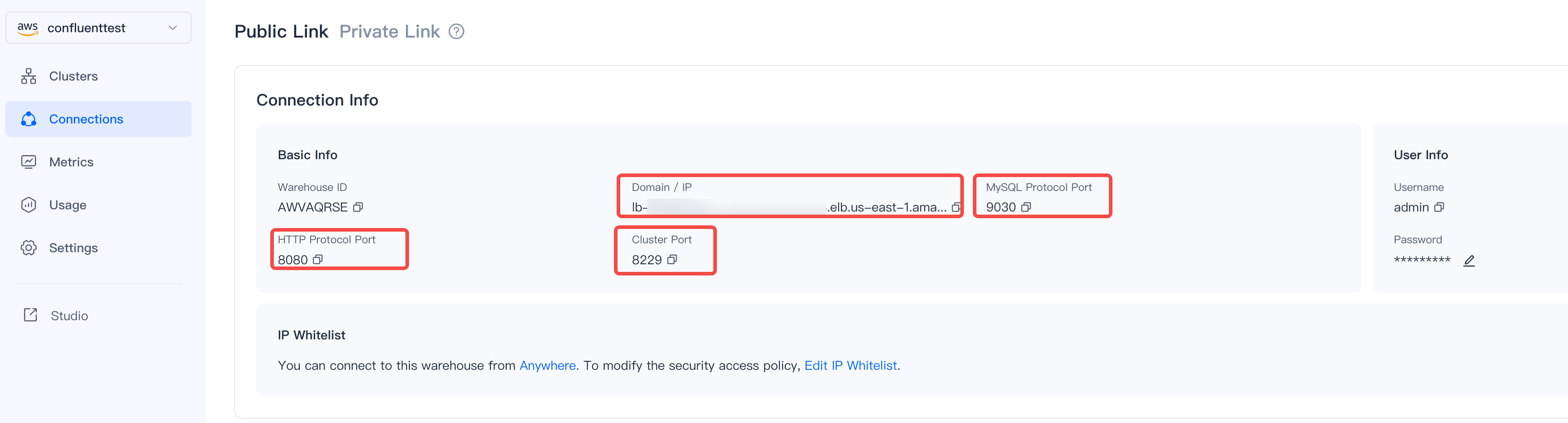
Fill in the [Domain:MySQL Protocol Port], [Domain:HTTP Protocol Port], and [Domain:Cluster Port] of the VeloDB repository here, respectively. This information can be obtained from the Connections section of VeloDB, as shown below:
D. Submit the Connector Task
After a successful submission, the interface displays the following information, indicating that it is running successfully.

5. Verification
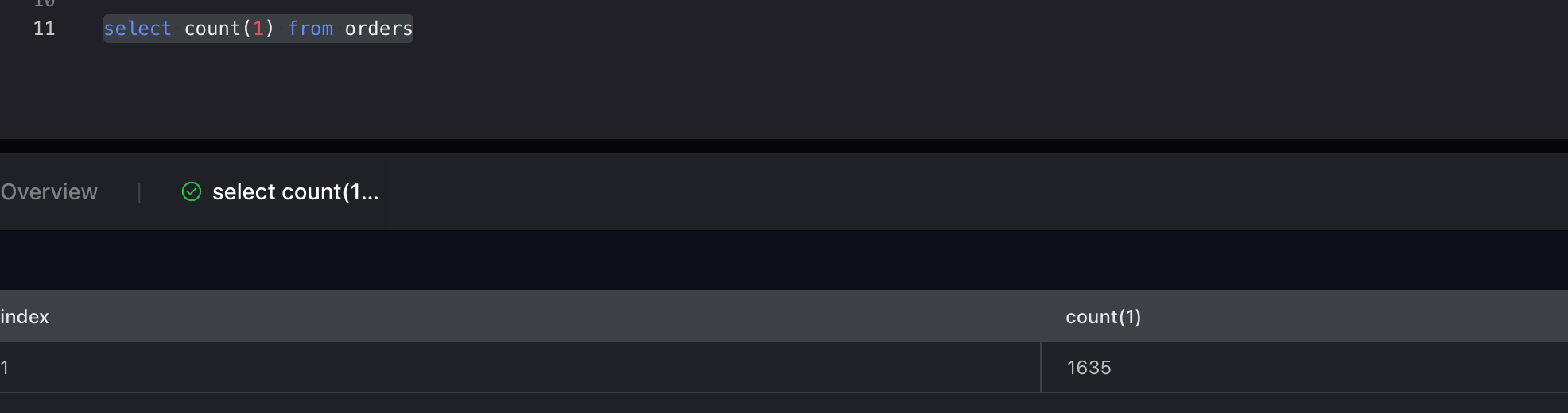
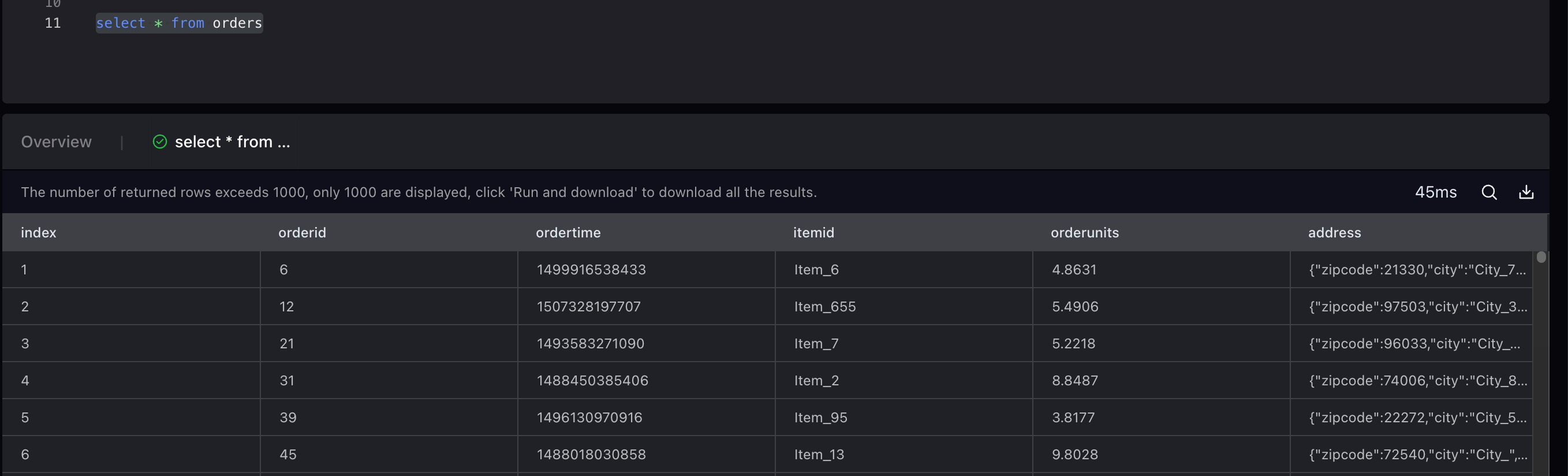
After running a query in VeloDB Studio, you can see that the data is continuously updated.
Summary
With the VeloDB Kafka Connector, users can easily stream Kafka data from Confluent Cloud and analyze real-time data in VeloDB, with no complex setup required. The connector enables instant insights at scale, allowing teams to focus on insights rather than pipeline complexity.
Want to learn more about Apache Doris and its fully managed cloud service VeloDB? Contact the VeloDB team to discuss with technical experts and connect with other users, or join the Apache Doris community.