


TL;DR: Data integration architecture defines how data moves from multiple systems into a unified analytics platform. Key elements of a modern data integration architecture include:
- Data sources such as databases, APIs, and SaaS applications
- Data ingestion through batch pipelines, streaming systems, or CDC tools
- Data transformation processes for cleaning and standardizing data
- Storage systems such as data warehouses, data lakes, or lakehouses
- Analytics and applications including BI dashboards and machine learning
What Is Data Integration Architecture?
Data integration architecture is the framework that defines how data moves from multiple source systems into a unified storage or analytics platform. It typically includes data ingestion, transformation, storage, and orchestration layers designed to ensure consistent, reliable, and scalable data pipelines.
Organizations rely on data integration architecture to break down data silos and consolidate information from different operational systems—such as CRM platforms, ERP systems, SaaS tools, and application databases—into a central environment for analytics and decision-making.
A well-designed architecture enables organizations to:
- Create a single source of truth for analytics and reporting
- Enable real-time or near-real-time data pipelines
- Support AI and machine learning workflows
- Scale data infrastructure as data volumes grow
In modern data platforms, data integration architecture plays a central role in enabling reliable data pipelines, data governance, and analytics across the entire organization.
Key Components of Data Integration Architecture
A typical data integration architecture consists of several core layers that handle different stages of the data lifecycle.
Data Sources
Data sources are the systems where data originates. These can include:
- CRM platforms such as Salesforce
- ERP systems
- SaaS applications
- Operational databases
- APIs
- IoT devices or event streams
These systems often generate data in different formats and structures, which makes integration necessary.
Data Ingestion Layer
The ingestion layer is responsible for collecting data from source systems and moving it into downstream processing systems.
Common ingestion methods include:
- Batch ingestion – periodic data extraction from source systems
- Streaming ingestion – continuous ingestion of real-time events
- Change Data Capture (CDC) – capturing incremental changes from databases
This layer ensures that data from multiple sources can be reliably transported into the data platform.
Data Transformation Layer
Once data is ingested, it typically requires transformation to make it usable for analytics.
Typical transformation processes include:
- Data cleaning
- Data mapping
- Schema normalization
- Data enrichment
- Aggregation and filtering
These transformations ensure that data from different sources can be standardized and analyzed consistently.
Storage Layer
The storage layer is where integrated data is persisted for analytics and processing.
Common storage technologies include:
- Data warehouses – optimized for structured analytics queries
- Data lakes – designed to store raw, large-scale datasets
- Lakehouse architectures – combining the flexibility of lakes with warehouse performance
The storage layer provides the foundation for business intelligence, analytics, and machine learning workloads.
Data Orchestration and Processing
Data orchestration tools manage the scheduling, coordination, and execution of data pipelines.
Common orchestration responsibilities include:
- Workflow scheduling
- Dependency management
- Pipeline monitoring
- Error handling and retry logic
Popular orchestration tools include systems like Apache Airflow and other workflow engines.
Metadata and Governance
Metadata and governance layers ensure that data pipelines remain secure, reliable, and auditable.
Key components include:
- Data catalogs
- Data lineage tracking
- Access control and security policies
- Compliance management
Governance mechanisms are critical for maintaining data quality and ensuring regulatory compliance.
Core Data Integration Patterns
Data integration architectures rely on several core patterns that define how data is collected, transformed, and delivered between systems. Each pattern represents a different approach to moving and processing data across the data platform.
The most common data integration patterns include:
- ETL (Extract, Transform, Load): The traditional method where data is transformed before loading into a target system.
- ELT (Extract, Load, Transform): A modern approach that loads raw data first, leveraging the warehouse's power for transformation.
- CDC (Change Data Capture): Identifies and streams database changes in real-time to reduce latency.
- Reverse ETL: Pushes processed analytics data back into operational systems (e.g., Salesforce).
- Data Virtualization: Creates a unified query layer without physically moving the data.
- Zero-ETL: Connects analytical systems directly to operational data with minimal intermediate pipelines.
Each pattern addresses different requirements such as batch processing, real-time synchronization, or reducing pipeline complexity.
| Pattern | Data Movement | Latency | Typical Use Case |
|---|---|---|---|
| ETL | Transform before load | Batch | Traditional data warehouses |
| ELT | Load first, transform later | Batch / near real-time | Cloud analytics |
| CDC | Incremental changes | Real-time | Operational analytics |
| Reverse ETL | Warehouse → apps | Near real-time | Operational workflows |
| Data Virtualization | No movement | Query-time | Distributed data systems |
| Zero-ETL | Minimal pipelines | Real-time | Modern data platforms |
ETL (Extract, Transform, Load)
ETL is the traditional data integration pattern in which data is extracted from source systems, transformed into the desired structure, and then loaded into a target system such as a data warehouse.
In ETL pipelines, transformations occur before data reaches the analytical storage layer. These transformations may include data cleaning, aggregation, schema mapping, and validation.
ETL pipelines are typically batch-oriented and are widely used in enterprise data warehousing environments where data is processed on scheduled intervals, such as hourly or daily jobs.
ETL works best in scenarios where:
- data transformations are complex
- strict data governance is required
- batch reporting workloads dominate
ELT (Extract, Load, Transform)
ELT is a modern variation of ETL commonly used in cloud-native data architectures.
Instead of transforming data before loading it, ELT pipelines first load raw data into a data warehouse, lakehouse, or analytical database. Transformations are then performed within the destination system using its processing capabilities.
This approach allows organizations to leverage the scalability of modern analytical engines and simplifies pipeline design.
ELT is commonly used when:
- cloud data warehouses are available
- large datasets need to be processed at scale
- transformation logic evolves frequently
Compared with ETL, ELT enables more flexible data processing and better supports large-scale analytics workloads.
CDC (Change Data Capture)
Change Data Capture (CDC) is a data integration method that captures incremental changes from source databases in real time.
Instead of repeatedly copying entire datasets, CDC tracks inserts, updates, and deletes in the source system and streams those changes to downstream systems.
This approach enables low-latency data pipelines and is widely used in real-time analytics architectures.
CDC pipelines are commonly implemented using:
- database log-based replication
- event streaming platforms
- incremental ingestion tools
CDC is especially useful when organizations need to keep analytical systems continuously synchronized with operational databases.
Reverse ETL
Reverse ETL moves processed or enriched data from analytical platforms back into operational systems.
In traditional pipelines, data typically flows from operational systems into a data warehouse for analysis. Reverse ETL reverses this direction by pushing analytical insights back into business applications.
For example, customer analytics data stored in a warehouse may be pushed into:
- CRM systems such as Salesforce
- marketing automation platforms
- customer support tools
This allows operational teams to act directly on insights generated from centralized analytics platforms.
Data Virtualization and Data Federation
Data virtualization and data federation allow organizations to query data across multiple systems without physically moving it into a central repository.
Instead of building data pipelines that copy data into a warehouse or lake, virtualization layers create a unified query interface that can access multiple sources in real time.
These approaches are useful when:
- data duplication must be minimized
- data sources are distributed across multiple systems
- real-time access to source systems is required
However, query performance may depend heavily on the performance of the underlying source systems.
Zero-ETL
Zero-ETL architectures aim to minimize or eliminate traditional ETL pipelines by enabling analytical systems to access operational data directly.
In these architectures, data can be ingested and queried with minimal transformation or movement between systems. Modern data platforms increasingly support this approach by integrating operational and analytical workloads more closely.
Zero-ETL architectures can simplify data infrastructure by reducing the number of data pipelines and intermediate processing steps.
They are particularly useful for:
- real-time analytics workloads
- streaming data pipelines
- systems that require minimal data latency
As modern analytical databases and lakehouse systems evolve, zero-ETL approaches are becoming an increasingly important trend in data integration architecture.
Common Data Integration Architectures
Organizations implement data integration architectures using several architectural models depending on their data scale, latency requirements, and system complexity. Each architecture defines how data flows between systems and how integration pipelines are organized.
Below are some of the most widely used data integration architecture models.
Hub-and-Spoke Architecture
In a hub-and-spoke architecture, a central system—typically a data warehouse or integration hub—acts as the core component that receives data from multiple source systems.
Data from operational systems is first collected into the central hub, where transformations, cleansing, and normalization processes are applied. The integrated data is then distributed to downstream consumers such as BI dashboards, reporting tools, or analytics platforms.
This architecture is widely used in traditional enterprise data warehouses because it provides strong governance and centralized control over data pipelines. However, as the number of systems increases, the hub can become a scalability bottleneck.
Data Lakehouse Architecture
A data lakehouse architecture combines the flexibility of data lakes with the performance and management capabilities of data warehouses.
In this model, raw data is first stored in a scalable data lake. Analytical engines then provide structured querying, indexing, and governance capabilities on top of the lake. This approach allows organizations to store large volumes of structured and unstructured data while still supporting high-performance analytics.
Lakehouse architectures are increasingly popular in modern cloud data platforms because they support both batch analytics and machine learning workloads in a unified environment.
Enterprise Service Bus (ESB)
The Enterprise Service Bus (ESB) model is commonly used in legacy enterprise integration environments.
An ESB acts as a centralized communication backbone that allows multiple applications to exchange data through standardized messaging protocols. Instead of building point-to-point integrations between systems, applications communicate through the bus, which handles message routing, transformation, and protocol conversion.
While ESB architectures simplify integration in traditional enterprise systems, they can become complex and difficult to scale in modern data-intensive environments.
Data Mesh and Data Fabric
Modern data architectures increasingly adopt decentralized models such as data mesh and data fabric.
Data mesh focuses on domain-oriented data ownership, where different teams manage their own data products while following shared governance standards. This approach reduces bottlenecks created by centralized data teams.
Data fabric architectures, on the other hand, use metadata-driven automation to integrate data across distributed systems. They rely heavily on metadata management, data catalogs, and intelligent data discovery to simplify integration across complex data environments.
Both approaches aim to improve scalability and organizational agility when managing large and distributed data ecosystems.
Event-Driven and Streaming Architecture
Event-driven architectures integrate systems using real-time event streams instead of batch pipelines.
In this model, applications publish events whenever data changes occur. These events are delivered through streaming platforms such as Kafka, enabling downstream systems to process updates in real time.
Streaming architectures are particularly useful for:
- real-time analytics
- operational monitoring
- fraud detection
- customer-facing applications
By processing events as they occur, organizations can significantly reduce data latency and enable near real-time insights.
Benefits of a Well-Designed Data Integration Architecture
A well-designed data integration architecture provides the technical foundation for modern data-driven organizations. By enabling reliable data pipelines and unified data access, it helps organizations transform fragmented operational data into consistent analytical insights.
Below are some of the most important benefits.
Single Source of Truth
One of the primary goals of data integration is to create a single source of truth across the organization.
Without integration architecture, different systems often store conflicting or duplicated data. By consolidating data from multiple sources into a unified environment, organizations can ensure that analytics and reporting are based on consistent and reliable datasets.
Improved Data Quality and Consistency
Data integration pipelines often include transformation and validation processes that improve overall data quality.
These processes can detect inconsistencies, standardize data formats, and remove duplicate records. As a result, integrated datasets become more reliable for analytics, reporting, and machine learning applications.
Real-Time Analytics Capabilities
Modern integration architectures increasingly support real-time or near-real-time data pipelines.
Technologies such as streaming ingestion and change data capture allow organizations to process data updates continuously instead of relying on periodic batch jobs. This enables faster insights for operational analytics, monitoring, and decision-making.
Better Decision-Making
When data from different systems is integrated into a unified analytics platform, organizations gain a more complete view of their operations.
Business teams can analyze customer behavior, operational performance, and financial metrics using consistent datasets, which leads to more accurate and informed decision-making.
Scalability for Growing Data Volumes
As organizations generate increasing amounts of data from applications, IoT devices, and digital services, scalable integration architectures become essential.
Modern architectures allow organizations to ingest, process, and analyze large volumes of data while maintaining reliable performance and governance.
Faster Data Access for Analytics and AI
Integrated data platforms make it easier for analytics teams and data scientists to access the datasets they need.
Instead of manually collecting data from multiple systems, teams can work with centralized and curated datasets, significantly reducing the time required to build dashboards, reports, or machine learning models.
Common Challenges in Data Integration Architecture
Although data integration architecture enables unified analytics and scalable data pipelines, implementing and maintaining it can introduce several technical and organizational challenges.
Below are some of the most common issues organizations face when building data integration systems.
Data Silos
Many organizations operate multiple systems across different departments, such as CRM platforms, financial systems, operational databases, and SaaS applications. These systems often store data independently, which creates data silos.
When data is isolated across systems, it becomes difficult to generate consistent reports or combine datasets for analytics. Data integration architectures must address this challenge by establishing pipelines that continuously synchronize and unify data across these systems.
Data Quality Issues
Data collected from multiple sources often contains inconsistencies such as:
- duplicate records
- missing fields
- inconsistent formats
- conflicting definitions of metrics
Without proper transformation and validation processes, these inconsistencies can propagate across downstream analytics systems.
Maintaining strong data quality controls is essential for ensuring that integrated datasets remain reliable and usable for business intelligence and machine learning.
Real-Time Data Processing
As organizations increasingly require real-time insights, supporting low-latency data pipelines becomes more important.
However, building real-time integration pipelines introduces several challenges, including:
- managing streaming infrastructure
- ensuring fault tolerance in event processing
- handling large volumes of continuously generated data
Real-time architectures often require additional technologies such as streaming platforms, message queues, and incremental data processing frameworks.
Security and Governance
Data integration architectures must enforce strong governance and security controls, especially when handling sensitive data.
Key governance concerns include:
- controlling access to sensitive datasets
- maintaining audit trails and data lineage
- complying with data protection regulations
Without proper governance mechanisms, organizations risk exposing sensitive information or violating compliance requirements.
Scalability
Data volumes continue to grow as organizations adopt cloud applications, IoT systems, and digital services. Integration pipelines must therefore be able to scale efficiently.
Architectures that rely heavily on centralized processing or tightly coupled pipelines may struggle to handle increasing data volumes and user demand.
Designing scalable architectures that can distribute processing and storage across multiple systems is critical for long-term sustainability.
Data Integration Architecture Best Practices
Designing a reliable data integration architecture requires careful planning and adherence to proven architectural principles. The following best practices can help organizations build scalable and maintainable integration systems.
Design for Scalability
Data integration systems should be designed to accommodate growing data volumes, new data sources, and increasing query workloads.
Scalable architectures typically use distributed processing systems and cloud-native storage platforms that can expand as data demand grows. This approach helps prevent performance bottlenecks as the organization’s data ecosystem evolves.
Use Metadata-Driven Pipelines
Metadata-driven architectures use centralized metadata to manage schemas, transformations, and pipeline dependencies.
By leveraging metadata, organizations can automate tasks such as:
- schema evolution handling
- pipeline orchestration
- data lineage tracking
This approach reduces operational complexity and improves the maintainability of large-scale data pipelines.
Implement Strong Data Governance
Clear governance policies are essential for maintaining trust in integrated data systems.
Organizations should establish policies for:
- data ownership and stewardship
- access control and security policies
- data classification and compliance management
Strong governance ensures that integrated data remains secure, traceable, and compliant with regulatory requirements.
Adopt Real-Time Pipelines When Needed
Not all data workloads require real-time processing. However, when low-latency insights are necessary—such as in monitoring systems, customer analytics, or fraud detection—organizations should implement streaming pipelines or CDC-based architectures.
These technologies allow data to flow continuously between systems, enabling analytics platforms to access the most up-to-date information.
Automate Monitoring and Data Quality Checks
Data integration pipelines should include automated monitoring systems that detect failures or anomalies.
Effective monitoring strategies typically include:
- pipeline health monitoring
- data freshness checks
- automated alerts for pipeline failures
- data quality validation rules
Automation ensures that issues in data pipelines are detected early and resolved before they affect downstream analytics systems.
Example Modern Data Integration Architecture
A modern data integration architecture typically consists of multiple layers that connect operational systems with analytics platforms.
Example architecture:
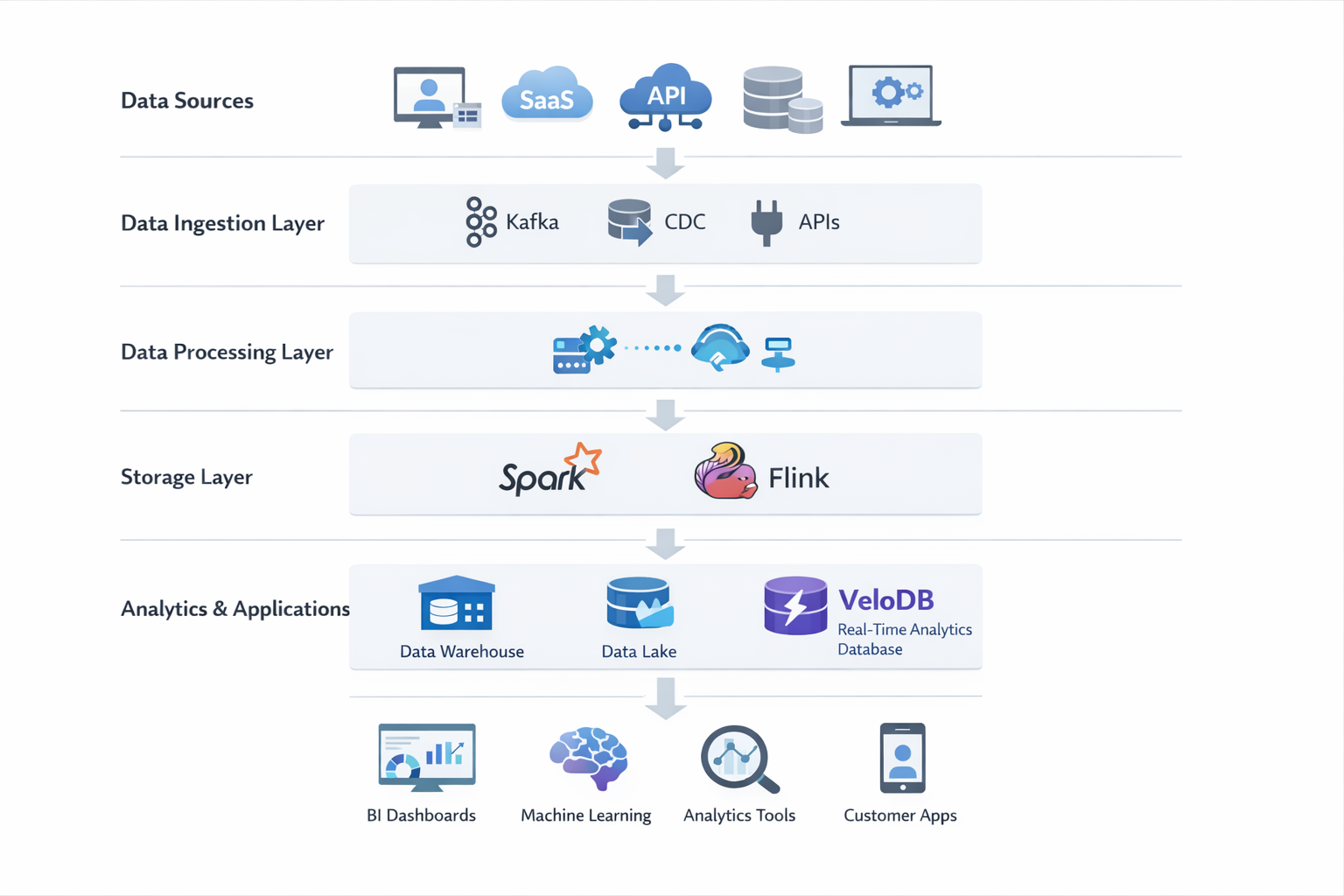
In many modern architectures, a real-time analytical database such as VeloDB can serve as the low-latency query layer for integrated data. Data streams captured through CDC or event pipelines can be ingested into the analytical engine, enabling sub-second queries for dashboards, customer-facing analytics, or operational reporting.
This architecture allows organizations to combine reliable operational data pipelines with high-performance analytical workloads.
Data Integration Architecture vs Data Pipeline
Although often used interchangeably, data integration architecture and data pipelines represent different concepts.
A data pipeline refers to a specific workflow that moves data from one system to another.
A data integration architecture, on the other hand, describes the overall framework that governs how multiple pipelines interact, how data is stored, and how analytics systems access integrated data.
In other words:
- Data pipelines are individual processes
- Data integration architecture is the system design that organizes those processes
Frequently Asked Questions
What is the difference between data architecture and data integration architecture?
Data architecture describes the overall structure of data systems within an organization, including storage, governance, and analytics platforms. Data integration architecture focuses specifically on how data moves between systems and becomes unified for analysis.
What are common data integration patterns?
Common patterns include ETL, ELT, Change Data Capture (CDC), Reverse ETL, data virtualization, and streaming data integration.
What is the difference between ETL and ELT?
ETL transforms data before loading it into the target system, while ELT loads raw data first and performs transformations afterward within the analytics system.
What tools are used for data integration architecture?
Common tools include data ingestion systems, streaming platforms, workflow orchestration tools, transformation frameworks, and analytical databases used for querying integrated data.