


TL;DR: AI ETL combines artificial intelligence and machine learning with traditional ETL (Extract, Transform, Load) processes to automate data integration. Instead of relying on manual rules, AI-powered ETL systems can automatically detect schema changes, clean data, optimize transformations, and build adaptive data pipelines. Modern AI ETL platforms provide capabilities such as automated schema mapping, anomaly detection, intelligent data cleaning, and real-time data processing. Popular AI ETL tools include Fivetran, Airbyte, Informatica, Matillion, Integrate.io, Estuary and Unstructured.io.
What Is AI ETL?
AI ETL (Artificial Intelligence Extract, Transform, Load) combines machine learning and AI with traditional data pipelines to automate, accelerate, and optimize data integration. Unlike manual, rule-based systems, AI-driven ETL platforms automatically map schemas, detect data quality anomalies, and process unstructured data to make it AI-ready for LLMs and RAG workflows.
The core advantages of AI in ETL include:
- Automated Schema Mapping & Adaptability: AI understands semantic meaning, automatically handling source modifications and schema drift without breaking pipelines.
- Intelligent Data Cleaning: ML models detect anomalies, impute missing values, and format data in real-time.
- Unstructured Data Handling: Prepares text, documents, and images for modern AI workloads.
- Speed & Efficiency: Replaces manual coding with low-code/no-code, self-correcting pipelines.
Traditional ETL vs AI ETL
Traditional ETL pipelines have long been used to move data from operational systems into analytics platforms. In these pipelines, data engineers manually define how data should be extracted, transformed, and loaded. Transformation logic, schema mappings, and data cleaning rules are typically written and maintained by engineers.
However, modern data environments are becoming increasingly complex. Organizations now deal with rapidly changing schemas, large numbers of data sources, and growing volumes of unstructured data. In these environments, traditional ETL pipelines often require frequent manual updates and maintenance.
AI ETL extends traditional ETL by incorporating machine learning models into the pipeline. Instead of relying solely on static rules, AI-powered systems can analyze data patterns, automatically map schemas, detect anomalies, and adapt to schema changes. This allows pipelines to become more resilient and reduces the amount of manual data engineering work required.
As a result, AI ETL is increasingly used in modern data platforms that require scalable, adaptive, and real-time data integration.
| Feature | Traditional ETL | AI ETL |
|---|---|---|
| Schema mapping | Manual mapping rules | AI-assisted semantic mapping |
| Data cleaning | Rule-based scripts | Machine learning anomaly detection |
| Handling schema drift | Manual pipeline updates | Automatic adaptation |
| Data types | Mostly structured data | Structured + unstructured data |
| Pipeline optimization | Manual tuning | AI optimization and auto-scaling |
The main difference is that AI ETL systems learn from data patterns, allowing pipelines to adapt automatically instead of relying entirely on predefined rules.
How AI Improves the ETL Process
AI technologies enhance every stage of the traditional ETL pipeline. By applying machine learning models to data ingestion, transformation, and loading workflows, AI-powered ETL systems can automate tasks that previously required manual configuration and continuous maintenance.
Instead of relying solely on static rules and predefined mappings, AI ETL platforms analyze data patterns and adapt pipelines dynamically as data sources evolve.
Extract: Handling Unstructured Data and CDC
In the extraction phase, AI-powered ETL systems can ingest data from both structured and unstructured sources. These may include:
- documents and PDFs
- images and scanned files
- logs and text data
- APIs and operational databases
- SaaS platforms and cloud applications
Traditional ETL tools often struggle to process unstructured data because it requires additional parsing and preprocessing steps. AI models can analyze text, detect entities, and extract meaningful information automatically, allowing unstructured data to be integrated into analytical pipelines.
AI can also work alongside Change Data Capture (CDC) technologies to detect real-time changes in source systems and stream updates into analytics platforms. Instead of periodically copying entire datasets, CDC pipelines capture only incremental updates, which significantly reduces latency and system overhead.
This combination of AI-driven extraction and CDC enables near real-time data ingestion while minimizing unnecessary data movement.
Transform: Semantic Schema Mapping and Data Cleaning
One of the most powerful applications of AI in ETL is semantic schema mapping.
In traditional ETL pipelines, engineers must manually define how fields from different systems correspond to each other. AI models can analyze metadata and data values to automatically identify relationships between fields. For example:
customer_name = client_name, user_id = account_id, signup_date = registration_date
By understanding the semantic meaning of fields, AI ETL platforms can automatically generate transformation rules when integrating new datasets.
AI also improves data quality management during the transformation stage. Machine learning models can detect patterns and anomalies across large datasets, enabling automated data cleansing processes such as:
- detecting anomalies or outliers
- identifying duplicate records
- normalizing inconsistent formats
- filling missing values using predictive models
These capabilities significantly reduce the amount of manual data preparation required by data engineers and allow organizations to maintain cleaner and more reliable datasets.
Load: Autonomous Pipeline Optimization
AI can also optimize how data is loaded into analytical systems such as data warehouses, lakehouses, or real-time analytics platforms.
Machine learning models analyze pipeline performance and automatically adjust parameters such as:
- batch sizes
- resource allocation
- parallel processing strategies
- data partitioning strategies
By monitoring historical pipeline performance, AI ETL platforms can dynamically allocate computing resources and optimize data loading strategies.
This allows AI-driven pipelines to maintain consistent performance under high data volumes or high concurrency, ensuring that analytical systems receive fresh and reliable data with minimal latency.
Key Capabilities of AI-Powered ETL Systems
Modern AI ETL platforms include several advanced capabilities that go beyond traditional rule-based data pipelines. These capabilities allow organizations to build more adaptive, scalable, and intelligent data integration systems.
Automated Schema Mapping
AI-powered ETL tools can automatically understand the semantic meaning of fields across datasets and generate schema mappings without manual configuration.
For example, an AI model can detect that fields such as customer_name, client_name, and account_holder refer to the same concept across different data sources.
By analyzing both metadata and actual data values, AI systems can automatically create transformation rules and adapt them when new datasets are introduced.
This capability dramatically reduces the time required to integrate new data sources and simplifies pipeline maintenance.
Intelligent Data Cleaning
Maintaining high data quality is one of the most time-consuming aspects of traditional data engineering. AI ETL systems address this challenge by applying machine learning models to detect and correct data quality issues automatically.
These systems can continuously monitor incoming datasets and identify problems such as:
- missing values
- inconsistent data formats
- abnormal or outlier records
- duplicated entries
Once issues are detected, the platform can automatically apply cleaning strategies such as normalization, deduplication, or predictive value imputation. This ensures that data entering analytical systems is more consistent and reliable.
Handling Unstructured Data
Many modern data workflows involve unstructured or semi-structured data, including documents, images, logs, and user-generated text.
Traditional ETL pipelines often require specialized preprocessing steps to convert these formats into structured datasets. AI ETL tools simplify this process by using machine learning models to extract structured information directly from raw data sources.
For example, AI models can:
- extract entities from documents
- analyze text logs to detect patterns
- process images or scanned documents
- convert unstructured text into structured datasets
This capability is particularly important for AI and LLM workflows, where large volumes of text-based data must be prepared for model training or inference.
Adaptive Data Pipelines
AI-powered ETL pipelines can adapt automatically when data sources change.
In traditional pipelines, schema changes—such as adding new columns or renaming fields—often cause pipeline failures that require manual intervention. AI ETL systems monitor schema evolution and automatically update transformation logic when changes are detected.
These adaptive capabilities allow pipelines to:
- adjust to schema drift
- retrain transformation models
- update pipeline configurations dynamically
- maintain consistent data flows across evolving data environments
As a result, AI-driven pipelines are more resilient and require less ongoing maintenance than traditional ETL systems.
AI ETL Architecture
A typical AI ETL architecture combines traditional data pipeline components with machine learning capabilities that automate data ingestion, transformation, and pipeline optimization.
Instead of relying entirely on static rules and manual configurations, AI-powered ETL architectures incorporate intelligent systems that can analyze metadata, detect schema drift, and optimize pipelines dynamically.
The following diagram illustrates a simplified modern AI ETL architecture.
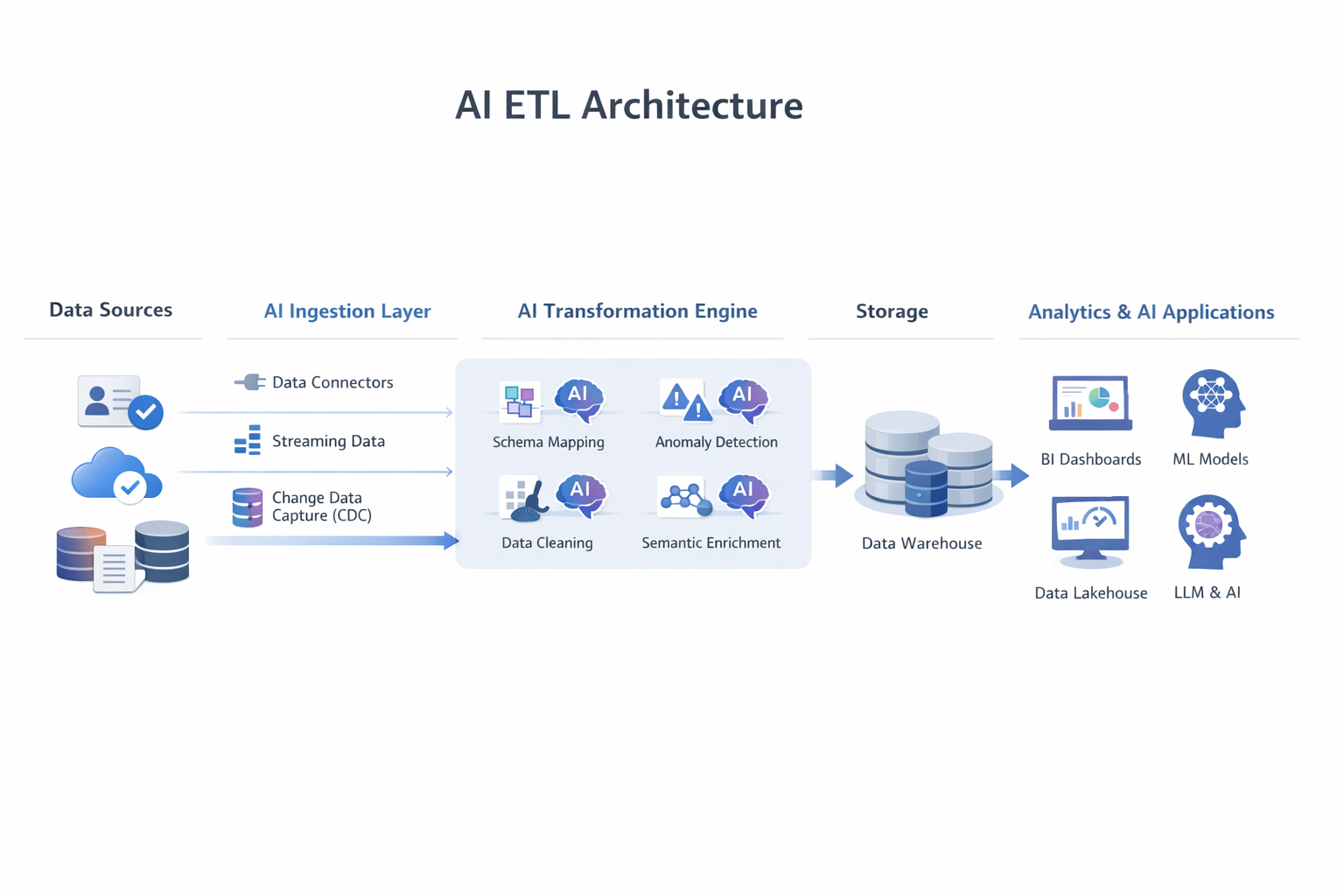
In modern data platforms, AI models often operate directly within transformation engines or orchestration layers, allowing pipelines to self-optimize and adapt automatically.
7 Best AI ETL Tools in 2026
A growing ecosystem of AI ETL tools helps organizations automate data pipelines, detect schema drift, and integrate large volumes of data from multiple sources. These platforms combine traditional ETL capabilities with machine learning models that automate schema mapping, anomaly detection, and pipeline optimization.
Below are some of the most widely used AI-powered ETL tools.
| Tool | Key Strength | Best For |
|---|---|---|
| Fivetran | Automated connectors and schema adaptation | SaaS data integration |
| Airbyte | Open-source ETL platform | Flexible pipelines |
| Informatica (CLAIRE) | Enterprise AI automation | Large organizations |
| Matillion | AI-assisted SQL optimization | Cloud data warehouses |
| Integrate.io | Low-code AI ETL | Rapid pipeline development |
| Estuary | Real-time streaming ETL | Event-driven data pipelines |
| Unstructured.io | Unstructured data parsing for RAG | LLM and AI workflows |
Fivetran
Fivetran is one of the most widely adopted managed data integration platforms. It focuses on automated data ingestion and synchronization between SaaS platforms and analytical systems.
Key capabilities include:
- fully managed connectors for hundreds of data sources
- automatic schema adaptation when source schemas change
- built-in data normalization and transformation support
- continuous data synchronization
Fivetran’s automation significantly reduces the amount of engineering effort required to maintain pipelines, making it a popular choice for teams building modern analytics stacks.
Airbyte
Airbyte is an open-source data integration platform that provides a flexible framework for building ETL pipelines.
Key features include:
- a large library of connectors for databases, APIs, and SaaS tools
- open-source architecture that allows custom connectors
- automation features for connector management and pipeline configuration
- deployment options for self-hosted or cloud environments
Because of its open architecture and extensive connector ecosystem, Airbyte is often used by engineering teams that require greater control over their data pipelines.
Informatica (CLAIRE)
Informatica is a long-standing enterprise data integration platform that has incorporated AI through its CLAIRE engine.
CLAIRE provides intelligent automation for data management tasks such as:
- metadata discovery
- automated schema mapping
- anomaly detection in datasets
- intelligent pipeline optimization
Informatica is widely used by large enterprises that require strong governance, security, and compliance features alongside AI-driven automation.
Matillion
Matillion is a cloud-native ETL platform designed to work closely with cloud data warehouses such as Snowflake, BigQuery, and Redshift.
Its AI-assisted features include:
- automated SQL generation and optimization
- AI-driven pipeline recommendations
- visual transformation workflows
- integrated orchestration for complex pipelines
Recent versions of Matillion include AI agents that help automate data engineering tasks and reduce manual pipeline development work.
Integrate.io
Integrate.io focuses on low-code and no-code data integration workflows. The platform provides a visual interface for building ETL pipelines and integrates AI-driven automation features to simplify pipeline development.
Key capabilities include:
- visual pipeline builder for rapid development
- automated data transformations
- pipeline monitoring and error detection
- integration with major cloud data warehouses
Integrate.io is often used by teams that want to accelerate pipeline development without writing extensive custom code.
Estuary
Estuary is designed for real-time data integration and streaming ETL pipelines. It enables organizations to synchronize operational databases, SaaS systems, and analytics platforms continuously.
Key features include:
- real-time streaming data pipelines
- built-in support for change data capture (CDC)
- automated schema management
- low-latency data synchronization
Because of its streaming architecture, Estuary is commonly used for event-driven systems and real-time analytics use cases.
Unstructured.io
Unstructured.io specializes in ingesting and processing unstructured data—such as PDFs, HTML, and Word documents—making it ready for Large Language Models (LLMs) and RAG (Retrieval-Augmented Generation) workflows.
Key features include:
- Extracting text and tables from complex document formats
- Preparing unstructured data for vector databases
- Seamless integration with modern AI application stacks
Unstructured.io is the go-to AI ETL tool for data engineering teams building internal AI assistants or chatbots that rely on proprietary enterprise documents.
Real-World Applications of AI Data Integration
AI ETL technologies are increasingly used across industries to automate data preparation, improve data quality, and enable real-time analytics. By integrating machine learning into data pipelines, organizations can process large volumes of data more efficiently and unlock insights that were previously difficult to obtain.
Finance
Financial institutions generate enormous volumes of transactional and behavioral data every second. AI ETL pipelines help financial organizations integrate and analyze this data more efficiently.
Common use cases include:
- fraud detection: AI models analyze transaction data in real time to identify suspicious patterns
- transaction monitoring: continuous ingestion of payment data across banking systems
- risk analysis: integrating market data, customer behavior, and historical transactions
Compared with traditional rule-based pipelines, AI-driven ETL systems can identify complex patterns and anomalies more accurately, enabling faster detection of fraud and financial risks.
Healthcare
Healthcare organizations rely on large and diverse datasets, including patient records, clinical data, and medical imaging. AI ETL pipelines help integrate data from multiple healthcare systems while maintaining compliance with strict regulatory standards.
Typical applications include:
- integrating patient data across electronic health record (EHR) systems
- standardizing medical data formats from different hospitals
- enabling real-time patient monitoring and analytics
By automating data integration and improving data quality, AI ETL systems allow clinicians and researchers to analyze healthcare data more effectively while ensuring regulatory compliance.
E-commerce and Customer Analytics
E-commerce platforms collect data from multiple systems, including user activity logs, order systems, payment gateways, and marketing tools.
AI ETL pipelines enable organizations to:
- build unified customer profiles
- analyze user behavior in real time
- personalize recommendations and marketing campaigns
Machine learning models can automatically clean and merge data from different sources, allowing businesses to generate customer insights faster.
IoT and Real-Time Analytics
In IoT environments, millions of devices continuously generate streaming data from sensors, machines, and connected systems. AI ETL pipelines help process these high-volume event streams and integrate them into analytics platforms where data can be analyzed in near real time.
Common use cases include:
- predictive maintenance for industrial equipment
- real-time monitoring of sensors and connected devices
- anomaly detection in operational systems
- performance monitoring across distributed IoT infrastructure
By combining streaming ingestion technologies with machine learning models, organizations can process large volumes of telemetry data and detect issues as they occur. In many modern data architectures, the processed data is streamed into real-time analytical databases such as VeloDB, enabling sub-second queries for operational dashboards, monitoring systems, and real-time analytics applications.
This architecture allows IoT platforms to move from delayed batch analysis to continuous, real-time decision-making.
Challenges of AI ETL
Although AI ETL provides powerful automation capabilities, implementing these systems also introduces several technical and organizational challenges.
Model Explainability
AI-driven transformations are often based on machine learning models rather than explicit rules. This can make it difficult for engineers and analysts to understand exactly how certain transformations or decisions were generated.
Organizations working in regulated industries must ensure that automated transformations remain transparent and auditable.
Data Governance and Compliance
As data pipelines become more automated, maintaining strong governance practices becomes increasingly important.
Organizations must ensure that AI ETL systems enforce:
- access control policies
- data lineage tracking
- regulatory compliance requirements
Without proper governance mechanisms, automated pipelines may inadvertently expose sensitive data or violate compliance policies.
AI Bias and Data Quality Risks
Machine learning models rely on training data to make decisions. If the training data contains bias or inconsistencies, the AI ETL system may propagate those issues across the pipeline.
This makes it important to implement monitoring systems that continuously evaluate model performance and data quality.
Pipeline Observability
Traditional ETL pipelines rely on deterministic rules that are relatively easy to monitor. AI-driven pipelines introduce additional complexity because machine learning models can dynamically adjust pipeline behavior.
Organizations therefore need advanced observability tools to monitor:
- pipeline health
- model performance
- data quality metrics
Without proper monitoring, it can be difficult to diagnose issues in AI-driven pipelines.
Infrastructure and Compute Costs
Running machine learning models as part of the ETL process can increase infrastructure costs.
AI ETL systems may require additional compute resources for:
- model inference
- large-scale data processing
- real-time analytics pipelines
Organizations must balance the benefits of automation with the cost of running AI infrastructure.
How to Choose an AI ETL Tool
Selecting the right AI ETL platform depends on an organization’s data architecture, data volume, and integration requirements. When evaluating AI ETL tools, teams typically consider several key factors.
Connector Ecosystem
A strong connector ecosystem is essential for integrating data from multiple sources.
Organizations should look for tools that support connectors for:
- databases
- SaaS applications
- APIs
- event streaming platforms
A large connector library reduces the effort required to integrate new data sources.
AI Automation Capabilities
Different AI ETL platforms offer varying levels of automation. Key features to evaluate include:
- automated schema detection
- intelligent schema mapping
- anomaly detection in datasets
- automatic pipeline optimization
Platforms with stronger AI automation capabilities can significantly reduce manual engineering effort.
Governance and Security
Enterprise data pipelines often process sensitive or regulated data. AI ETL platforms should therefore include robust governance features such as:
- role-based access control
- data lineage tracking
- encryption and security policies
These features help ensure that data pipelines remain compliant with regulatory requirements.
Scalability and Performance
As data volumes grow, ETL pipelines must be able to scale efficiently.
Organizations should evaluate whether a platform supports:
- distributed data processing
- streaming data pipelines
- high-volume batch processing
Scalable ETL systems ensure that data pipelines remain reliable as workloads increase.
Pricing and Operational Costs
Pricing models for AI ETL tools can vary widely. Some platforms charge based on data volume, while others use subscription-based pricing.
When evaluating tools, organizations should consider:
- infrastructure costs
- licensing fees
- operational overhead
Understanding the total cost of ownership helps organizations select a platform that fits their long-term budget.
The Future of AI ETL
AI ETL is evolving rapidly as data platforms integrate more advanced automation and machine learning capabilities. Several emerging trends are likely to shape the future of AI-driven data integration.
Generative AI for Data Pipelines
Generative AI models are increasingly being used to generate transformation logic automatically. Instead of writing complex transformation scripts, engineers may describe transformations in natural language and allow AI models to generate the necessary pipeline code.
Agentic Data Engineering
A new concept known as agentic data engineering is emerging, where autonomous AI agents manage pipeline orchestration, monitor data quality, and automatically resolve pipeline issues.
These AI agents can continuously analyze pipeline performance and make adjustments without human intervention.
Real-Time AI Data Pipelines
As organizations demand faster insights, AI ETL systems are increasingly moving toward real-time data processing.
Future pipelines will integrate streaming ingestion, machine learning inference, and analytics processing into a unified real-time architecture.
LLM-Powered Data Transformation
Large language models (LLMs) are beginning to play a role in data engineering workflows. LLMs can interpret data schemas, generate transformation logic, and assist with data pipeline development.
This capability may allow non-technical users to interact with data pipelines using natural language queries.
FAQ
Will AI replace ETL?
AI will not replace ETL but will automate many ETL tasks. Instead of manually writing transformation rules, engineers will increasingly rely on AI-assisted pipelines.
What are AI ETL tools?
AI ETL tools are data integration platforms that use machine learning to automate schema mapping, data cleaning, pipeline optimization, and anomaly detection.
What is the difference between ETL and AI ETL?
Traditional ETL pipelines rely on manual rules and scripts, while AI ETL systems use machine learning to automate transformations and adapt to schema changes.
Can AI automate data pipelines?
Yes. AI models can automate tasks such as schema detection, anomaly detection, and pipeline optimization, significantly reducing manual engineering work.
How does AI handle schema drift in data pipelines?
AI models monitor incoming data structures and automatically update transformation logic when schema changes are detected.