


As AI systems move from experimentation to production, one challenge becomes increasingly clear: building the model is only part of the problem—the real complexity lies in managing the data behind it.
Modern AI applications depend on continuous streams of data from logs, user interactions, APIs, and external sources. Without a structured way to collect, process, and deliver this data, even the most advanced models struggle to produce accurate or reliable results.
This is where an AI data pipeline becomes essential.
An AI data pipeline defines how data flows through a system—from ingestion and transformation to storage, retrieval, and model interaction. It forms the backbone of use cases such as RAG systems, LLM applications, real-time recommendations, and AI observability.
In this guide, we’ll explain what an AI data pipeline is, how its workflow and architecture are designed, and how to build one step by step for modern AI systems.
What Is an AI Data Pipeline?
An AI data pipeline is a system that continuously collects, processes, and delivers data to AI models for training, inference, and ongoing improvement.
Unlike traditional data pipelines, which are often designed for batch analytics or reporting, an AI data pipeline is built to support dynamic, real-time, and feedback-driven workflows.
In practice, it connects multiple stages of the AI lifecycle, including:
- data ingestion from sources such as logs, user interactions, APIs, and databases
- data transformation and feature engineering, including tasks like cleaning, normalization, and embedding generation
- storage and retrieval of structured data, unstructured data, and high-dimensional vectors
- interaction with AI models for training, inference, or retrieval (e.g., RAG systems)
- monitoring and feedback loops that evaluate outputs and continuously improve system behavior
A key characteristic of modern AI data pipelines is that they are not static workflows. Instead, they operate as continuous systems where data flows in real time and outputs are fed back into the pipeline.
For example:
- in RAG systems, pipelines retrieve and update knowledge dynamically
- in LLM applications, pipelines manage prompts, context, and outputs
- in observability systems, pipelines process logs, traces, and metrics in real time
The key idea is simple: an AI data pipeline does not just move data—it ensures that AI systems always operate on relevant, up-to-date, and usable information.
Why AI Data Pipelines Matter
AI systems are fundamentally data-driven—and in many cases, the pipeline can be as important as the model itself.
Even the most advanced models cannot perform well if the underlying data is incomplete, outdated, or poorly structured. This is why many real-world AI issues are not model problems, but data pipeline problems.
The main reasons AI data pipelines matter include:
- Data freshness directly impacts accuracy: AI systems rely on up-to-date data. Stale data can lead to outdated recommendations, incorrect predictions, or irrelevant responses.
- Data quality determines model reliability: Poorly processed or inconsistent data can introduce bias, errors, or instability in model outputs.
- AI systems require continuous feedback loops: Unlike traditional systems, AI applications improve over time. Pipelines enable this by feeding outputs, user interactions, and evaluation results back into the system.
- Modern AI workloads are real-time and complex: Applications such as RAG, LLM observability, and recommendation systems depend on continuous data flow rather than static datasets.
- System performance depends on pipeline design: Latency, scalability, and cost are often determined by how efficiently data moves through the pipeline.
Without a well-designed AI data pipeline, models may appear to work—but gradually degrade in accuracy, relevance, and reliability.
In practice, AI data pipelines are what make AI systems usable in production.
AI Data Pipeline vs Traditional Data Pipeline
Although they share similar concepts, AI data pipelines differ significantly from traditional data pipelines.
| Aspect | Traditional Data Pipeline (ETL) | AI Data Pipeline |
|---|---|---|
| Data Types | Structured data (tables, rows, columns) | Multi-modal (text, vectors, logs, unstructured) |
| Purpose | Reporting and Business Intelligence (BI) | Model training, inference, and Retrieval (RAG) |
| Data Freshness | Batch-oriented (daily/hourly) | Real-time or near real-time (continuous streaming) |
| Output | Dashboards and reports for humans | Predictions, context, and decisions for machines |
| Feedback Loop | Limited or manual | Continuous, automated learning loop |
At first glance, AI data pipelines may look similar to traditional data pipelines. Both involve moving data from one system to another, performing transformations, and storing results.
However, the underlying goals—and therefore the design—are fundamentally different.
Traditional data pipelines are typically built for analytics and reporting. They focus on preparing data for dashboards, business intelligence tools, and historical analysis. These pipelines are often batch-oriented, meaning data is processed at scheduled intervals rather than continuously.
AI data pipelines, on the other hand, are designed for model-driven systems. Their purpose is not just to move data, but to ensure that AI models receive high-quality, up-to-date, and context-rich inputs at all times.
This leads to several key differences:
- From batch to real-time: Traditional pipelines often process data in batches, while AI pipelines increasingly operate in real time or near real time. This is critical for applications such as RAG, recommendations, and observability.
- From static outputs to continuous feedback loops: In traditional systems, the pipeline ends with a dashboard or report. In AI systems, outputs are fed back into the pipeline, enabling continuous learning and improvement.
- From structured data to multi-modal data: Traditional pipelines mainly handle structured data. AI pipelines must support unstructured data such as text, images, and embeddings.
- From data delivery to decision support: Traditional pipelines deliver data for human interpretation. AI pipelines directly power automated decisions and model outputs.
AI Data Pipeline Workflow (Step-by-Step)
A typical AI data pipeline workflow follows a clear sequence, but in modern systems it runs as a continuous loop rather than a one-time process.
That distinction matters. Traditional data workflows often end after data is transformed and stored. AI pipelines do not. They keep moving because models need fresh data, new context, and ongoing feedback to stay useful in production.
A modern AI data pipeline usually includes the following stages:
1. Data Ingestion
The workflow begins by collecting data from multiple sources, such as:
- application logs
- user interactions
- APIs
- databases
- documents, files, or event streams
In AI systems, these sources are often heterogeneous. A single pipeline may need to handle structured records, semi-structured logs, and unstructured text at the same time.
2. Data Processing and Transformation
Once data is ingested, it needs to be cleaned, normalized, and prepared for AI use.
This stage may include:
- removing duplicates or invalid records
- standardizing formats
- feature engineering
- text chunking for RAG
- embedding generation for semantic retrieval
This is also the point where raw data starts becoming model-ready data.
3. Storage and Analytics Layer
After transformation, data must be stored in a way that makes it both durable and immediately usable.
This layer is responsible for:
- storing raw and processed data
- supporting fast retrieval
- enabling filtering, aggregation, and analysis
- making data available for downstream AI workloads
In practice, this is where many pipelines either become efficient or break down. Data may be successfully ingested, but if it cannot be queried quickly, the pipeline becomes a bottleneck.
4. Model Training or Inference
Once the data is available, AI models use it for one of two purposes:
- training, where the model learns from prepared datasets
- inference, where the model uses current data to make predictions or generate outputs
In RAG systems, this often means retrieving relevant context before generating a response. In recommendation systems, it may mean scoring user behavior in real time. In observability systems, it may mean analyzing traces and logs as they are produced.
5. Monitoring and Feedback Loop
The final stage is not really an endpoint—it is the mechanism that keeps the pipeline improving.
This stage evaluates:
- model outputs
- retrieval quality
- latency and cost
- user feedback
- failure patterns
These signals are then fed back into the pipeline to improve prompts, data quality, retrieval logic, or model behavior.
AI Data Pipeline Architecture (Modern Systems)
Modern AI data pipeline architecture is layered, real-time, and feedback-driven.
At a high level, the architecture looks like this:
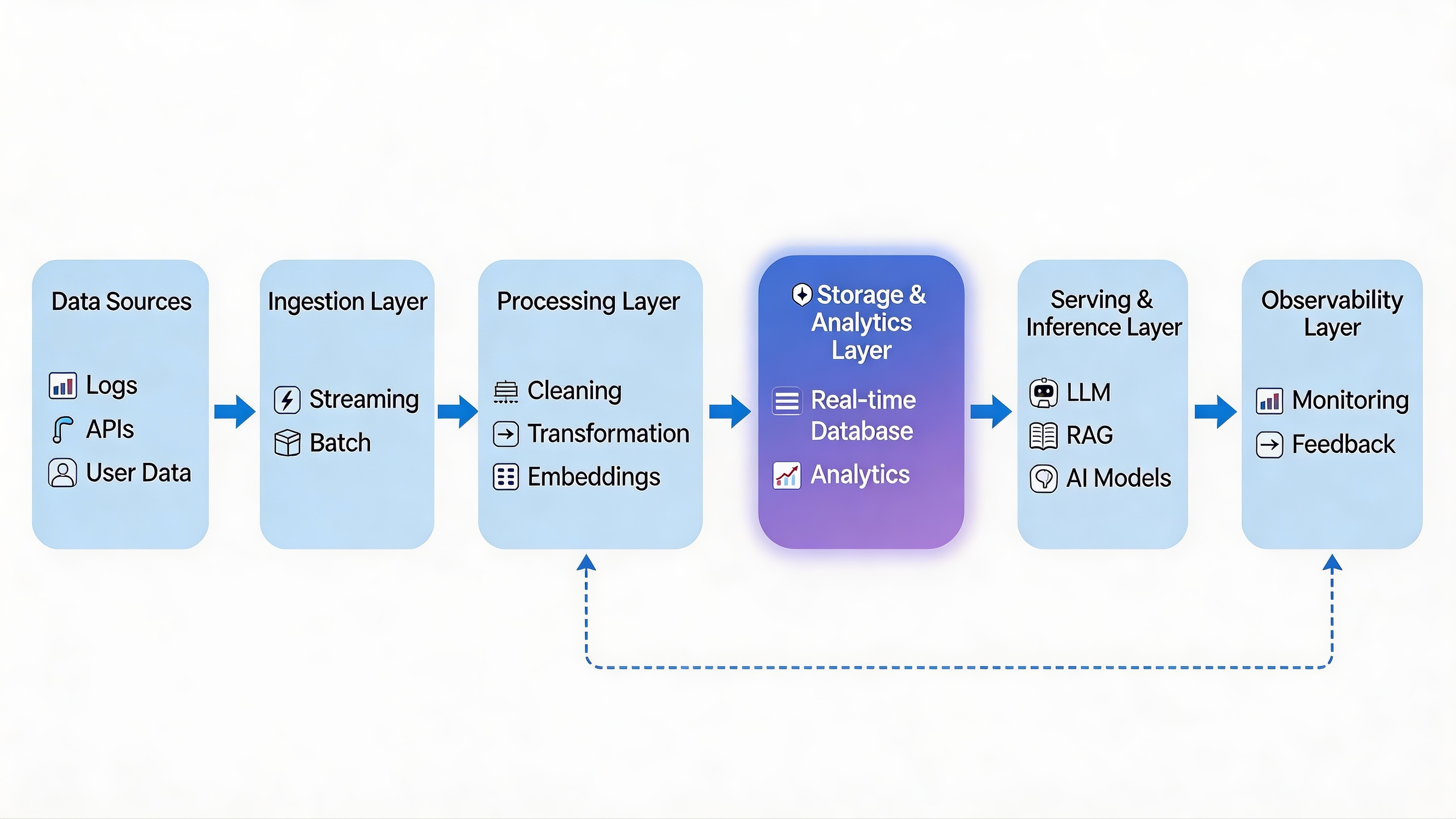
At first glance, this may look like a standard data pipeline. But in practice, modern AI systems place much more pressure on the middle of the stack—especially the storage, analytics, and retrieval layers—because that is where raw data gets turned into usable context for models.
The most important thing to understand is that an AI pipeline is not just moving data from left to right. It is also creating a loop between data, models, and feedback. That is what allows AI systems to improve over time rather than operate on static inputs.
Layer 1: Data Sources
Every AI pipeline starts with data, but in modern systems that data is rarely clean or uniform.
Common sources include:
- user activity and clickstreams
- application logs and traces
- documents and knowledge bases
- transactional databases
- APIs and third-party systems
- model outputs and user feedback
This variety is one reason AI pipelines are more complex than traditional data pipelines. They need to support structured, semi-structured, and unstructured data in the same architecture.
Layer 2: Ingestion Layer
The ingestion layer is responsible for getting data into the system reliably and quickly.
It may support:
- streaming ingestion, for logs, events, and live application data
- batch ingestion, for large scheduled imports or historical datasets
In modern AI applications, streaming is increasingly important because many workloads—such as LLM observability, recommendation systems, and RAG updates—depend on fresh data.
A weak ingestion layer leads to stale downstream systems, no matter how good the models are.
Layer 3: Processing & Transformation Layer
This is where raw data becomes AI-ready.
In a traditional pipeline, this might just mean cleaning columns and joining tables. In an AI pipeline, the processing stage is broader and often more specialized.
Typical operations include:
- data cleaning and normalization
- feature engineering
- deduplication and filtering
- text chunking for retrieval
- embedding generation for semantic search
- metadata extraction for filtering and ranking
This layer is critical because poor transformation choices directly affect model quality. If the pipeline introduces noisy chunks, weak embeddings, or inconsistent metadata, the model will inherit those problems.
Layer 4: Storage & Analytics Layer
This is the core of the modern AI data pipeline.
It is not enough to simply store data. The system must also make that data queryable, filterable, and analyzable with low latency.
A strong storage and analytics layer needs to support:
- large-scale data storage
- high-dimensional data such as vectors
- structured metadata
- real-time ingestion
- low-latency analytical queries
- hybrid retrieval across vector and relational data
This is the layer that turns stored data into something AI systems can actually use.
For example, in a RAG system, this layer may need to retrieve semantically similar documents while also filtering by time, user, or source. In observability systems, it may need to analyze logs, traces, and model events in real time. In recommendation systems, it may need to query recent user behavior with minimal delay.
This layer is often implemented using real-time analytical databases such as VeloDB, which support fast ingestion and low-latency queries on large-scale data. In practice, this is where VeloDB fits best in the architecture: not as a general pipeline tool, but as the analytics and query layer that makes real-time AI workflows practical.
A lot of AI systems fail here. They can ingest data, and they can store it somewhere, but they cannot query it fast enough to support production use cases. That is why this layer is usually the architectural turning point between a prototype and a scalable system.
Layer 5: Serving & Inference Layer
This is the layer where models actually consume data and produce outputs.
Depending on the application, that may include:
- retrieving context in RAG systems
- generating responses with LLMs
- scoring user behavior for recommendations
- running fraud detection or anomaly detection models
- orchestrating agent workflows
This layer depends heavily on everything that came before it. If the upstream data is delayed, poorly transformed, or slow to retrieve, inference quality suffers even if the model itself is strong.
That is why model performance is often a pipeline problem, not just a model problem.
Layer 6: Observability & Feedback Layer
No modern AI system is complete without observability.
This layer monitors:
- model outputs
- retrieval quality
- hallucinations or failure patterns
- latency and token usage
- system performance and cost
- user feedback and downstream outcomes
Its purpose is not just monitoring for alerts. It closes the loop between production behavior and system improvement.
For example, teams may use this layer to:
- identify poor retrieval results in RAG
- detect latency spikes in inference
- analyze token costs across requests
- feed evaluation results back into prompts or pipeline logic
This is what makes the architecture feedback-driven rather than static.
A modern AI data pipeline is not just a sequence of layers, but a feedback-driven system where data, models, and analytics continuously interact to produce and improve outcomes in real time.
Key Components of an AI Data Pipeline
While AI data pipeline architectures may vary across systems, most production pipelines are built around a common set of components. What matters is not just the presence of these components, but how they work together to support real-time, model-driven workflows.
Data Ingestion
Every AI pipeline starts with data ingestion.
This component is responsible for collecting data from multiple sources, including:
- application logs
- user interactions
- APIs and external systems
- databases and data lakes
In modern AI systems, ingestion is often a mix of streaming and batch processing, depending on the use case. Real-time ingestion is especially important for applications such as observability, recommendations, and RAG systems, where data freshness directly impacts output quality.
Data Transformation
Once data is ingested, it must be transformed into a format that AI models can use.
This goes beyond simple cleaning and includes:
- normalization and filtering
- feature engineering
- text chunking (for retrieval systems)
- embedding generation (for semantic search)
- metadata extraction
This stage plays a critical role in determining model performance. Poor transformation leads to poor inputs—and ultimately poor outputs.
Storage
The storage layer holds both raw and processed data.
Unlike traditional systems, AI pipelines must handle:
- structured data (tables, records)
- unstructured data (text, documents, logs)
- high-dimensional data (vectors and embeddings)
Storage is not just about durability—it must also support efficient access patterns for downstream AI workloads.
Analytics / Query Layer
This is one of the most important—and often underestimated—components of an AI data pipeline.
The analytics layer enables:
- fast data retrieval
- filtering and aggregation
- hybrid queries (structured + semantic)
- real-time analysis of large datasets
In many modern systems, this layer is powered by real-time analytical databases such as VeloDB, which allow teams to query large-scale data with low latency.
This is where many pipelines succeed or fail. Data may be successfully ingested and stored, but if it cannot be queried efficiently, it cannot support real-time AI applications.
Model Integration
This component connects the data pipeline to AI models.
Depending on the system, this may include:
- training pipelines
- inference services
- retrieval workflows (e.g., RAG)
- agent orchestration
The pipeline provides the data context that models rely on to generate outputs or make decisions.
Monitoring and Feedback
AI pipelines do not end at inference. They must continuously evaluate and improve.
This component tracks:
- output quality and relevance
- latency and system performance
- token usage and cost
- user feedback and downstream impact
These signals are fed back into the pipeline to improve prompts, data quality, and model behavior.
Types of AI Data Pipelines
AI data pipelines can be categorized based on how they process and deliver data. In practice, most real-world systems combine multiple types rather than relying on a single approach.
Batch Pipelines
Batch pipelines process data at scheduled intervals, such as hourly or daily jobs.
They are typically used for:
- offline model training
- historical data processing
- large-scale data preparation
Batch pipelines are reliable and cost-efficient, but they introduce latency. As a result, they are less suitable for applications that require immediate responses.
Real-Time Pipelines
Real-time pipelines process data continuously as it is generated.
They are designed for:
- LLM observability
- real-time recommendations
- fraud detection
- dynamic RAG systems
Because they operate on fresh data, real-time pipelines enable AI systems to respond instantly and adapt to changing conditions.
Real-time pipelines are becoming the default for AI systems that depend on up-to-date data.
Hybrid Pipelines
Hybrid pipelines combine batch and real-time processing.
A common pattern is:
- batch pipelines for training and historical data
- real-time pipelines for inference and live updates
This approach balances cost, scalability, and responsiveness, and is widely used in production AI systems.
RAG Pipelines
RAG (Retrieval-Augmented Generation) pipelines are a specialized type of AI data pipeline.
They combine:
- data retrieval (from documents or knowledge bases)
- semantic search (using embeddings)
- LLM-based generation
In RAG systems, the pipeline must support:
- fast retrieval
- context filtering
- real-time updates
This makes the storage and analytics layer particularly important, as it determines how quickly and accurately relevant context can be retrieved.
How to Build an AI Data Pipeline (Step-by-Step)
Designing an AI data pipeline is not just about connecting tools—it is about aligning your data flow with how your AI system actually works in production.
In practice, the right design depends heavily on your use case, latency requirements, and data complexity. The following steps outline a practical approach to building a modern AI data pipeline.
1. Define Your Use Case First
Start with the problem you are trying to solve—not the tools.
Common AI use cases include:
- RAG systems (retrieval + generation)
- recommendation engines
- LLM observability
- fraud detection or anomaly detection
Each use case has different requirements for:
- data freshness
- query complexity
- latency tolerance
For example, a RAG system requires fast retrieval and filtering, while offline training pipelines can tolerate higher latency.
2. Identify and Classify Data Sources
Next, determine where your data comes from and what type it is.
Typical sources include:
- logs and event streams
- user interactions
- documents and knowledge bases
- transactional databases
- third-party APIs
It is important to classify data early:
- structured vs unstructured
- real-time vs batch
- high-frequency vs low-frequency
This directly affects how you design ingestion and storage later.
3. Design the Ingestion Layer
The ingestion layer determines how data enters your system.
Key decisions include:
- streaming (e.g., Kafka) vs batch ingestion
- ingestion throughput requirements
- data reliability and ordering guarantees
For modern AI systems, streaming ingestion is often essential, especially for:
- observability pipelines
- real-time recommendations
- continuously updated RAG systems
A weak ingestion layer will limit the entire pipeline, regardless of downstream components.
4. Choose the Storage & Analytics Layer (Critical Step)
This is arguably the most important—and most underestimated—decision in the entire AI pipeline. In traditional systems, data is just stored. In AI systems, this layer must instantly retrieve, filter, and serve context to the model.
A common mistake developers make is building a "Frankenstein" architecture by stitching together multiple disconnected systems:
- A relational database (e.g., PostgreSQL) for structured user metadata.
- A dedicated vector database (e.g., Pinecone) specifically for embeddings.
- A separate search engine (e.g., Elasticsearch) for system logs and observability events.
While this works in prototypes, moving it to production often leads to:
- Fragmented Architecture: Engineering teams spend more time maintaining data pipelines than building AI features.
- Complex Data Synchronization: Keeping metadata and vectors in sync across multiple databases introduces race conditions and data inconsistency.
- Slower Query Performance: Joining data across different systems drastically increases latency, killing the real-time experience of AI apps.
The Solution: Unified Analytical Databases
Modern real-time analytical databases like VeloDB are designed to simplify this complexity. Instead of maintaining three separate systems, VeloDB acts as a unified engine by supporting:
- High-throughput streaming ingestion (for live logs and events).
- Hybrid retrieval (executing blazing-fast vector similarity searches simultaneously with structured SQL filtering).
- Real-time analytics on massive, high-cardinality datasets.
By consolidating multiple components into a single, high-speed analytics layer, teams can significantly reduce operational costs, eliminate synchronization lag, and ensure their AI models always operate on the freshest data. In practice, the real-world usability of your AI system depends heavily on the speed and reliability of this specific layer.
5. Integrate with AI Models
Once data is available and queryable, it needs to be integrated with AI models.
This may include:
- training pipelines (offline or batch)
- inference services (real-time APIs)
- retrieval workflows (RAG systems)
- agent-based decision systems
The goal is to ensure that models always receive the right data, at the right time, with the right context.
6. Add Monitoring and Observability
AI systems cannot be treated as black boxes.
A robust pipeline must include monitoring for:
- model output quality
- retrieval relevance
- latency and performance
- token usage and cost
- system errors and edge cases
This is especially important for production systems, where silent failures (e.g., hallucinations or poor recommendations) may not trigger traditional alerts.
Observability enables teams to understand not just what happened, but why it happened.
7. Optimize for Performance, Cost, and Scale
Once the pipeline is running, continuous optimization becomes necessary.
Key areas include:
- reducing query latency
- optimizing data storage and indexing
- controlling token and compute costs
- scaling ingestion and query workloads
In many cases, bottlenecks appear in unexpected places—such as slow queries, inefficient data layouts, or overly complex architectures.
In practice, building an AI data pipeline is less about selecting individual tools and more about designing a system where data can be ingested, queried, and used by AI models in real time.
Real-World AI Data Pipeline Examples
AI data pipelines are best understood through real-world applications. Different use cases place very different demands on data freshness, query speed, and system design.
RAG Systems (Retrieval-Augmented Generation)
RAG pipelines combine retrieval and generation to produce context-aware responses.
In this setup, the pipeline must:
- ingest and update documents continuously
- generate embeddings for semantic search
- retrieve relevant context with filtering (e.g., time, source, metadata)
- pass results into an LLM for response generation
The key challenge is balancing retrieval accuracy and latency. If retrieval is slow or irrelevant, the final output quality degrades—even if the model itself is strong.
This is why RAG pipelines rely heavily on an efficient analytics and retrieval layer.
LLM Observability
LLM observability pipelines focus on understanding how AI systems behave in production.
They typically process:
- prompts and inputs
- model outputs
- traces of multi-step workflows
- logs, metrics, and user feedback
These pipelines must operate in real time to detect:
- hallucinations
- latency spikes
- abnormal behavior patterns
Unlike traditional monitoring, observability pipelines require both high-cardinality data handling and fast analytical queries, making the pipeline architecture particularly important.
Recommendation Systems
Recommendation pipelines process user behavior to generate personalized results.
They often involve:
- continuous ingestion of user interactions
- real-time feature updates
- scoring or ranking models
- feedback loops based on user actions
In these systems, even small delays can reduce relevance. A recommendation that is a few minutes late may no longer be useful.
This makes real-time processing and low-latency querying critical for maintaining user experience.
Common Challenges in AI Data Pipelines
Building AI data pipelines is significantly more complex than building traditional data pipelines.
The difficulty is not just in moving data—but in making that data usable, timely, and reliable for AI systems.
Data Quality and Consistency
AI models are highly sensitive to input quality.
Problems such as:
- missing data
- inconsistent formats
- noisy or duplicated records
can directly lead to incorrect outputs, unstable behavior, or degraded performance.
Latency and Performance Trade-offs
Many AI systems require both:
- real-time data processing
- complex queries or transformations
Balancing these two is difficult. Improving latency may increase cost, while optimizing for cost may introduce delays.
Pipeline Complexity Across Multiple Systems
A common architecture pattern involves multiple tools:
- ingestion systems
- processing frameworks
- vector databases
- analytical databases
- monitoring tools
While each component solves a specific problem, combining them often leads to:
- integration overhead
- data synchronization issues
- operational complexity
Data Silos and Fragmentation
When data is spread across different systems, it becomes harder to:
- perform unified queries
- maintain consistency
- debug issues
This is especially problematic in AI systems, where models often require combined context from multiple data sources.
Best Practices for AI Data Pipelines
Effective AI data pipelines are not defined by how many components they include, but by how well those components work together.
Design for Real-Time Processing When Possible
As AI applications become more interactive, real-time pipelines are increasingly the default.
Even when full real-time processing is not required, reducing latency often improves:
- model accuracy
- user experience
- system responsiveness
Prioritize Data Usability Over Data Volume
More data does not always lead to better results.
What matters is:
- relevance
- quality
- accessibility
Pipelines should focus on delivering the right data, not just more data.
Monitor Outputs, Not Just System Metrics
Traditional monitoring focuses on:
- latency
- errors
- throughput
AI pipelines must also monitor:
- output quality
- relevance
- correctness
This requires combining system-level metrics with model-level evaluation.
Simplify Architecture Where Possible
Overly complex pipelines are harder to maintain and debug.
Reducing the number of systems—especially in the storage and analytics layer—can significantly improve:
- performance
- reliability
- operational efficiency
Build for Scalability Early
AI systems often scale quickly once deployed.
Designing for scale from the beginning helps avoid:
- performance bottlenecks
- costly redesigns
- infrastructure limitations
The Future of AI Data Pipelines
AI data pipelines are evolving rapidly as AI systems become more complex and more widely adopted.
Real-Time-First Architectures
Batch pipelines are no longer sufficient for many modern AI applications.
There is a clear shift toward architectures where:
- data is processed continuously
- insights are generated instantly
- decisions are made in real time
AI Agents and Autonomous Systems
As AI agents become more common, pipelines must support:
- multi-step reasoning
- tool usage
- dynamic decision-making
This increases the need for fast data access and flexible pipeline design.
Continuous Feedback Loops
Future pipelines will increasingly integrate:
- user feedback
- model evaluation
- system performance signals
into a unified loop that continuously improves outputs.
Convergence of Data and Analytics Systems
The boundaries between:
- storage
- processing
- analytics
are becoming less distinct.
Modern systems are moving toward unified platforms that can handle ingestion, querying, and analysis in a single layer.
FAQ
Is an AI data pipeline the same as MLOps?
While closely related, they are not the same. MLOps (Machine Learning Operations) is a broad discipline that covers the entire lifecycle of an AI model, including training, deployment, versioning, and infrastructure management. An AI data pipeline, on the other hand, is a foundational subset of MLOps. It focuses strictly on the automated engineering process of ingesting, transforming (e.g., chunking and embedding), and delivering high-quality data to feed those models.
What tools are used to build AI data pipelines?
A modern AI data pipeline requires a specialized stack across different architectural layers. Common tools include Apache Kafka or Fivetran for real-time data ingestion, Airflow or dbt for orchestration, and AI frameworks like LangChain or LlamaIndex for data processing. For the critical storage and retrieval layer, modern architectures rely on unified real-time analytical databases like VeloDB, which can simultaneously handle streaming ingestion, hybrid vector search, and observability log analytics.
What is AI ETL, and how is it related to an AI data pipeline?
AI ETL refers to extracting, transforming, and loading data specifically for AI workflows.
Compared to traditional ETL, it often includes tasks such as:
- processing unstructured data (e.g., text or logs)
- generating embeddings
- preparing data for model training or retrieval (e.g., RAG)
In practice, AI ETL is just one part of a larger AI data pipeline.
- AI ETL focuses on preparing data
- AI data pipelines manage the full data flow, including ingestion, model interaction, and feedback loops
Conclusion
An AI data pipeline is the foundation of modern AI systems.
As applications shift toward real-time decision-making, the ability to process and query data instantly becomes essential. From RAG systems to LLM observability, data pipelines are what enable AI to operate reliably at scale.
In practice, building an effective pipeline is less about individual tools and more about how data flows through the system. Architectures that combine real-time ingestion, scalable storage, and low-latency analytics are better suited for modern AI workloads.
As AI systems continue to evolve, data pipelines will move from a supporting component to a core infrastructure layer—powering how AI systems learn, adapt, and deliver value.