TL;DR: Vibe coding can break enterprise codebases not because the model is bad, but because code retrieval is structurally harder than document search: code is a graph of dependencies, uses technical symbols that don't match natural language queries, and changes every hour. CocoIndex + VeloDB solve this with a single-table architecture that combines semantic search, keyword matching, and code graph traversal. Incremental indexing keeps the context fresh with every commit.
The Ceiling Isn't the Model
Typical vibe code scenario: You describe what you want in plain language, the AI writes the code, you iterate. On a weekend project, it feels like a superpower. The AI sees most of the codebase, understands the structure, and generates something that fits.
Now try vibe code on a monorepo that's been growing for three years. Fifty microservices, shared libraries that predate half the current team, import chains that cross team boundaries, and six squads pushing code every day.
For example, you can try asking your coding agent: "Add retry logic to the payment service." You'll likely run into three gaps:
The semantic gap: The agent runs a semantic search for your query. It returns PaymentConfig type definitions and a billing_constants.py file, both semantically close to "payment." But the actual error handling lives in transaction_recovery.py, inside a function called handle_failed_charge(). Neither the file name nor the function name overlaps with your query. Embedding similarity isn't strong enough to surface it.
The graph gap: After some back-and-forth, the agent locates payment_handler.py. It reads the file and writes a new retry loop from scratch. The problem: payment_handler.py already imports retry_policy.py, which wraps circuit_breaker.py. Three other services use the same retry infrastructure. The agent never follows the import retry_policy statement at the top of the file, so it never discovers the shared retry module. It reinvents what already exists.
The freshness gap: The next morning, a teammate refactors retry_policy.py to add exponential backoff and pushes the change. You ask the agent the same question. It returns yesterday's answer, still referencing the old retry interface. Yesterday's index does not know about this morning's commit.
This is one coding task. But three retrieval failures. The AI isn't failing at code generation. It's failing at finding the right code before it starts writing.
Fixing these three gaps requires four capabilities working together: semantic search to find code by meaning, keyword search to match exact symbols, graph traversal to follow imports and calls across files, and incremental indexing to keep pace with every commit. The conventional approach is to bolt together a vector database, a search engine, and a graph database. CocoIndex + VeloDB take a different path: one table, three indexes.
The Architecture: One Table, Three Indexes
Building multi-signal code retrieval typically means assembling three separate databases: one for vector search, one for keyword matching, one for graph traversal. Each has its own ingestion pipeline, its own query API, and its own consistency model. Merging results across all three requires application-level stitching code that becomes its own maintenance burden.
CocoIndex + VeloDB collapse this into two layers and one table.
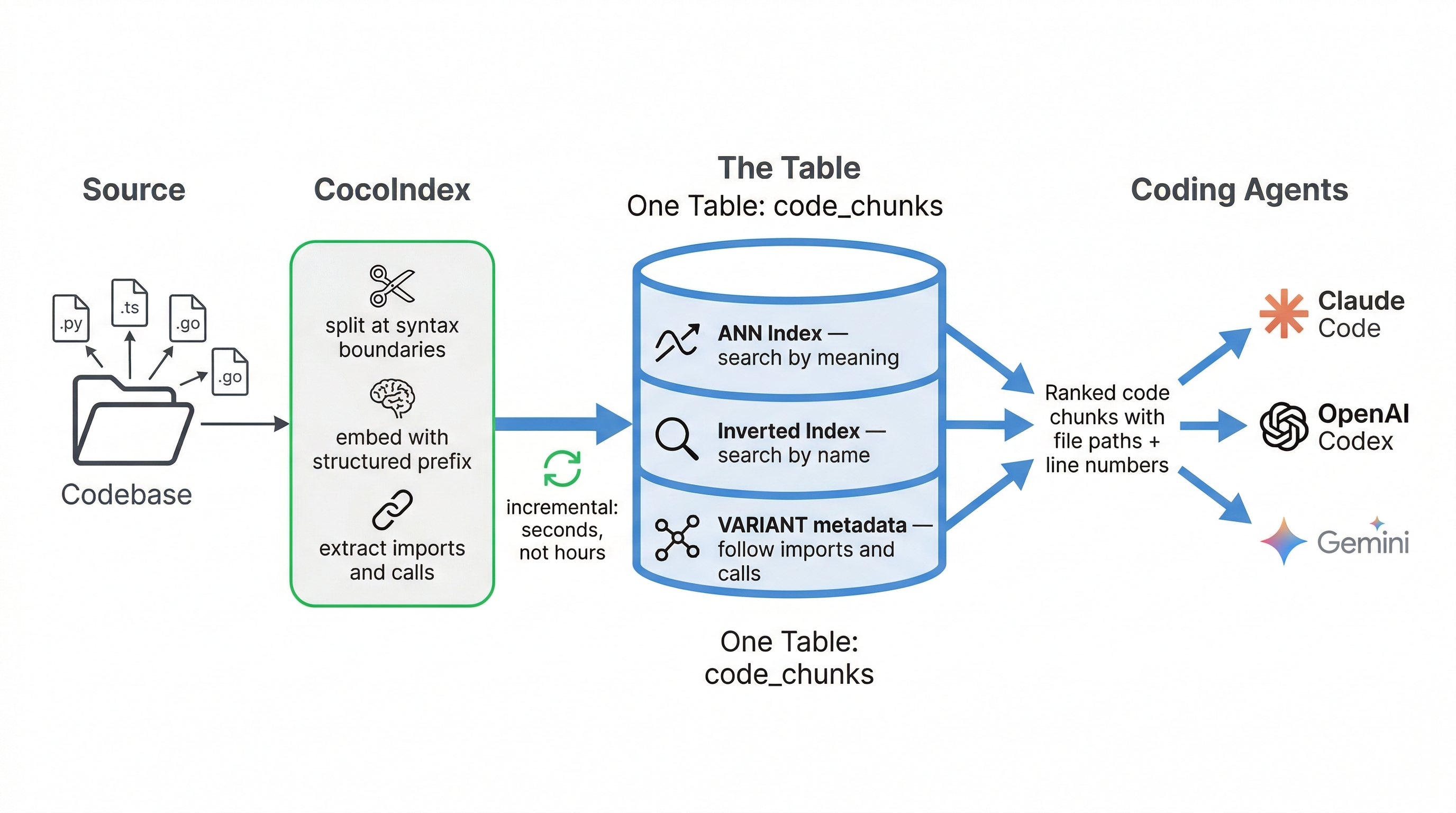
CocoIndex is the indexing layer. It walks the codebase, splits files at syntax boundaries with tree-sitter, generates structured embeddings, extracts import and call metadata, and loads everything into VeloDB via Stream Load. It tracks file checksums in a local state database, so subsequent runs re-process only changed files.
VeloDB (powered by Apache Doris) is the storage and query layer. It stores all code chunks in a single table with three types of indexes on the same rows. Semantic search, keyword search, and graph traversal all run as SQL queries against this one table. No external systems. No stitching.
The full table definition:
CREATE TABLE IF NOT EXISTS code_chunks (
`id` BIGINT NOT NULL,
`file_path` TEXT NOT NULL,
`language` TEXT NOT NULL,
`content` TEXT NOT NULL,
`start_line` INT NOT NULL,
`end_line` INT NOT NULL,
`embedding` ARRAY<FLOAT> NOT NULL,
`metadata` VARIANT<'repo_name': STRING, 'language': STRING,
'file_path': STRING, 'chunk_type': STRING,
'name': STRING, 'imports': STRING, 'calls': STRING> NULL,
-- Semantic search: HNSW approximate nearest neighbor on embeddings
INDEX idx_vec_embedding (`embedding`) USING ANN
PROPERTIES("index_type"="hnsw", "metric_type"="l2_distance", "dim"="384"),
-- Keyword search: BM25 scoring via inverted index
INDEX idx_inv_content (`content`) USING INVERTED
PROPERTIES("parser"="unicode"),
-- Graph + filtering: inverted index on structured metadata
INDEX idx_inv_metadata (`metadata`) USING INVERTED
PROPERTIES("parser"="unicode")
)
ENGINE = OLAP
DUPLICATE KEY(`id`)
DISTRIBUTED BY HASH(`id`) BUCKETS AUTO
One CREATE TABLE declares three indexes. The USING ANN index enables semantic vector search. The USING INVERTED index on content enables BM25 keyword scoring. The USING INVERTED index on metadata enables graph traversal (through stored import/call relationships) and filtered search by language, file path, or repository.
You get four capabilities from one table:
-
Semantic vector search: Search for "authentication flow" and find
verify_jwt_token(), even when the query shares no words with the function name. -
BM25 keyword precision: Search for
transcribeFirstAudioand get the exact function definition, not vaguely related audio code. -
Code graph traversal: Find
payment_handler.pyand automatically seeretry_policy.pyand circuit_breaker.py through the import chain, two hops deep. -
Incremental freshness: Change one file out of five thousand. Six seconds later, the index knows.
Before these indexes can work, CocoIndex must turn source files into rows. It splits each file at syntax boundaries using tree-sitter, so each chunk is a complete function or class rather than a truncated fragment. It prepends a structured prefix (Type: function, Name: charge, Language: python) so the embedding model knows what it's looking at, then loads the results into VeloDB. The pipeline supports Python, TypeScript, Rust, Go, Java, and more.
This hybrid approach already works at production scale outside code search. ByteDance uses Apache Doris's combined vector and BM25 search to query over one billion 768-dimension vectors for their talent search platform. The result: 7x lower latency than pure vector search and 89% accuracy versus 80-85% for vector-only, running on a single server instead of 20-30. ByteDance's full case study is here.
With clean, well-labeled chunks loaded, let's walk through how each search capability closes the three gaps (the semantic gap, the graph gap, and the freshness gap) we mentioned earlier.
Closing the Semantic Gap: Hybrid Search
Semantic search alone returns what is similar, not what is right. Keyword search alone returns exact matches but misses code described in different terms. Neither mode finds the implementation on its own.
VeloDB runs both in parallel against the same table. Vector search uses the ANN index to find code by meaning:
SELECT metadata['file_path'], content,
l2_distance_approximate(embedding, [0.03, -0.12, ...]) AS distance
FROM code_chunks
ORDER BY distance ASC
LIMIT 10
BM25 search uses the inverted index to find code by exact terms:
SELECT metadata['file_path'], content,
SCORE() AS relevance
FROM code_chunks
WHERE content MATCH_ANY 'payment retry handler'
ORDER BY relevance DESC
LIMIT 10
Each mode has a blind spot the other covers. Hybrid search runs both in parallel and merges the results using Reciprocal Rank Fusion (RRF), which ranks chunks by how consistently they appear across both lists instead of by raw scores.
We tested this on real data: a 43,000-chunk open-source codebase. The query: "telegram message handling."
-
Vector alone returned config type definitions. Semantically related to Telegram, but not the implementation.
-
BM25 alone returned changelog entries that happened to mention "message." Right keywords, wrong context.
-
Hybrid returned bot-handlers.ts. The actual message handler.
Neither signal found the implementation on its own. Together, they did.
Hybrid search closes the semantic gap. But it still treats every chunk as independent text. It has no concept of "this file imports that file." Closing the graph gap takes a different approach.
Closing the Graph Gap: Following Imports in Pure SQL
Hybrid search now finds payment_handler.py. But reading a file in isolation isn't enough: the agent needs to follow the import chain (payment_handler.py → retry_policy.py → circuit_breaker.py) to discover the shared infrastructure.
Graph traversal expands search results by following code relationships. It typically requires a separate database and a separate query language. VeloDB handles it in the same table, using the same SQL.
The graph data comes from the indexing step. CocoIndex's code_analysis.py module extracts imports and function calls from each file using language-specific regex patterns (covering Python, TypeScript, Rust, Go, Java, and more). It stores these relationships as comma-separated strings in the VARIANT metadata column:
{
"chunk_type": "function",
"name": "payment_handler",
"imports": "retry_policy,transaction_recovery,db_client",
"calls": "process_payment,handle_failed_charge,log_event"
}
No separate graph database. The graph edges live in the same rows as the code chunks and embeddings.
The traversal runs as a single CTE (Common Table Expression) query in five steps:
-
Seeds: Hybrid search returns
payment_handler.pyand related chunks. These are hop-0 results. -
Extract edges: A query reads each seed's
importsandcallsfrom the VARIANT metadata column, usingexplode_split()to turn the comma-separated strings into individual rows. -
Hop-1: A name match finds the chunks whose
metadata['name']corresponds to those imported module names:retry_policy,transaction_recovery,db_client. These are direct dependencies of the seeds. -
Extract hop-1 edges: The same explode-and-match process repeats on hop-1's metadata.
-
Hop-2: Chunks matching hop-1's edges are the dependencies of the dependencies.
retry_policyimportscircuit_breaker, socircuit_breaker.pyappears at hop-2.
The full query:
WITH
-- Hop-1: chunks whose name matches seed edges
hop1 AS (
SELECT metadata['file_path'] AS file_path,
metadata['name'] AS name,
metadata['imports'] AS imports,
metadata['calls'] AS calls,
content, start_line, end_line,
1 AS hop
FROM code_chunks
WHERE metadata['name'] IN ('retry_policy', 'transaction_recovery', 'db_client')
),
-- Extract hop-1 edge terms for the next hop
hop1_edges AS (
SELECT DISTINCT trim(t.term) AS name
FROM hop1
LATERAL VIEW explode_split(concat_ws(',', imports, calls), ',') t AS term
WHERE trim(t.term) != ''
),
-- Hop-2: chunks matching hop-1 edges
hop2 AS (
SELECT metadata['file_path'] AS file_path,
metadata['name'] AS name,
content, start_line, end_line,
2 AS hop
FROM code_chunks
WHERE metadata['name'] IN (SELECT name FROM hop1_edges)
)
SELECT * FROM hop1
UNION ALL
SELECT * FROM hop2
Two SQL round trips total: one for the hybrid search seeds, one for this CTE. Score decay ensures neighbors don't outrank direct matches: seeds get full score (1.0x), hop-1 neighbors get 0.5x, hop-2 gets 0.25x.
In practice, 10 seed results expand to 25 results with full dependency context. The AI now sees payment_handler.py, plus retry_policy.py and transaction_recovery.py that it imports, plus circuit_breaker.py that retry_policy depends on. The agent discovers the shared retry infrastructure before writing a single line of code.
Why stop at two hops? One hop finds direct dependencies: the files your code imports. Two hops find the implementation details that those dependencies rely on. Beyond two hops, the signal-to-noise ratio drops rapidly as the neighborhood expands to include increasingly tangential code. Two hops is the depth where "I found the function" becomes "I understand how this function works and what it relies on."
That leaves the third problem from the opening: the teammate who refactors retry_policy.py overnight, leaving the agent stuck on yesterday's code.
Closing the Freshness Gap: Six-Second Incremental Indexing
Your teammate refactors retry_policy.py at 11 pm. Re-indexing the entire 5,472-file codebase from scratch would take 25 minutes. With CocoIndex, we don't need to re-index, because it tracks file checksums and re-processes only what changed:
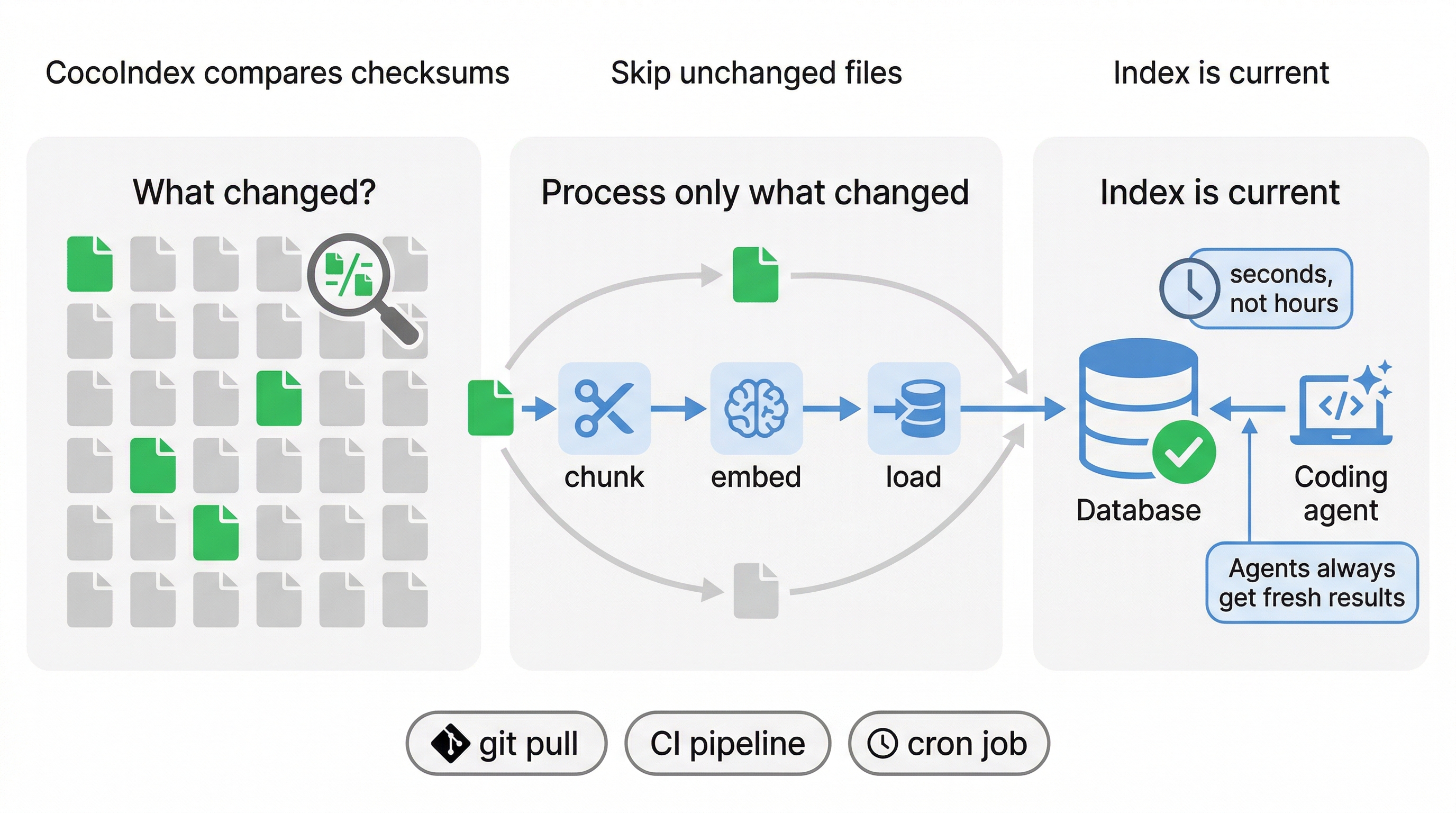
Wire this into a git pull hook, a CI step, or a background cron job. The teammate's refactor is in the index before the morning standup.
Making It Practical
A unified index is only useful if your AI tools can actually talk to it. In this stack, we use CocoIndex-Code to connect to your workflow.
MCP integration: CocoIndex-Code ships an MCP server that exposes a single search tool. Any MCP-compatible agent (Cursor, Claude Desktop, and others) can call it with a natural language query and get back ranked code chunks with file paths and line numbers.
Scaling: A solo developer can start building with SQLite: zero setup, everything local. When the team scales, you only need to change one environment variable:
export COCOINDEX_CODE_BACKEND=doris # was "sqlite"
From there, you can move the knowledge store to managed VeloDB infrastructure and still use the same CLI, same MCP server, and get the same results. The shared infrastructure lets multiple developers query the database concurrently, with multiple repositories living in one cluster, filtered by repo_name.
The Context Layer Vibe Coding Has Been Missing
Let's go back to the payment service scenario mentioned earlier. With Cocoindex + VeloDB, the same task plays out differently:
The agent searches for "add retry logic to the payment service." Vector search picks up payment_handler.py (semantically close to "payment service"). BM25 picks up transaction_recovery.py (keyword match on "retry"). Hybrid fusion ranks both in the top results. The agent now sees the implementation code it missed before. Semantic gap closed.
Graph traversal reads metadata in payment_handler.py and follows the import chain. Hop-1 pulls in retry_policy.py. Hop-2 pulls in circuit_breaker.py. The agent discovers that retry infrastructure already exists, shared by three other services. It extends the module instead of reinventing it. Graph gap closed.
At night, a teammate refactors retry_policy.py. CocoIndex detects one changed checksum, re-processes that single file in under six seconds, and the index is current again by morning. Freshness gap closed.
The same coding task went from three retrieval failures to zero.
Vibe coding's promise is real. On a small project, it delivers. On an enterprise codebase, it breaks, not because the model can't write good code, but because it can't find the right code to learn from. A bigger context window won't close that gap. The solution is to build a knowledge store that understands code structure, and allows users to search it by meaning, name, and dependency, and keeps pace with every commit.
CocoIndex + VeloDB are that knowledge store. One CREATE TABLE replaces three databases. The future of vibe coding at enterprise scale isn't waiting for a better model. It's building the right context layer that the model needs.
Note: The VeloDB/Doris connector in CocoIndex-Code is currently in private preview. Contact us if you'd like early access.
Further Reading
- How ByteDance Solved Billion-Scale Vector Search with Apache Doris 4.0
- Real Time Context Engineering Webinar
- Real Time AI Context Stack Blog
Ready to build production-grade search? Start with VeloDB Cloud for unified hybrid search. For incremental indexing with built-in lineage, explore CocoIndex Code in Github.