



AI agents have changed what databases need to deliver. A single agent request can trigger dozens of queries at once, and agents work in chains, where each answer shapes the next query. One slow response delays the entire reasoning chain.
That makes two capabilities non-negotiable for any database serving AI workloads: high concurrency and real-time response.
Snowflake built its reputation on ease of setup and elastic computing: pay only for what you query, skip infrastructure management, spin up a virtual warehouse, and start running analytics.
However, problems surface at scale. For teams approaching TB-scale data, running interactive dashboards, ad hoc analytics, or any workload where latency matters, Snowflake hits two structural limits. First, it handles concurrency by adding compute clusters, each billed at full cost, so scaling users means multiplying the bill. Second, ingestion runs in batches, so latency stays in the minutes.
One fintech company running TB-scale analytics on Snowflake hit exactly these limits. After migrating to Apache Doris on AWS, the team reduced costs by 80% and achieved up to 90x faster query performance. We will cover the full results later in this article.
The same trade-offs apply to any team running concurrent analytics at TB scale on Snowflake: e-commerce platforms tracking real-time orders, ad tech companies powering campaign dashboards, and logistics companies serving live reports to hundreds of users.
This article walks through the full approach to replacing Snowflake with VeloDB on AWS, covering architecture, ingestion, processing, cost-performance benchmarks, and when a migration makes sense.
VeloDB Cloud is the managed service built on Apache Doris, available on AWS and other cloud providers. It gives teams the performance and cost benefits of Apache Doris without the operational overhead of self-hosting.
Snowflake's Architecture and Limitations
Snowflake separates storage from compute across three layers: a storage layer that holds data in cloud object storage, a compute layer (Virtual Warehouses) that runs queries independently, and a services layer that handles optimization, metadata, and authentication.
Snowflake Limits
This works well at a small scale, but Snowflake's problems are structural, and they compound as data volume and concurrency grow.
-
Cost scales with usage: Snowflake's pay-per-query model is flexible early on, but as concurrency and volume increase, costs rise fast. High-usage teams often find the bill growing faster than the business value it delivers.
-
Limited data freshness: Snowflake's ingestion runs at second-to-minute latency. For use cases where freshness matters (order analytics, ad performance, live operations), that delay is a structural limitation, not a configuration problem.
-
Concurrency and performance limits: As data reaches TB scale or workloads span tens of billions of rows, query concurrency drops, and performance struggles to meet business requirements.
VeloDB on AWS: Solution Architecture and Advantages
Architecture Overview
VeloDB on AWS replaces Snowflake's analytics pipeline end to end, covering ingestion, warehousing, processing, and visualization. The diagram below shows how each layer maps to AWS services.
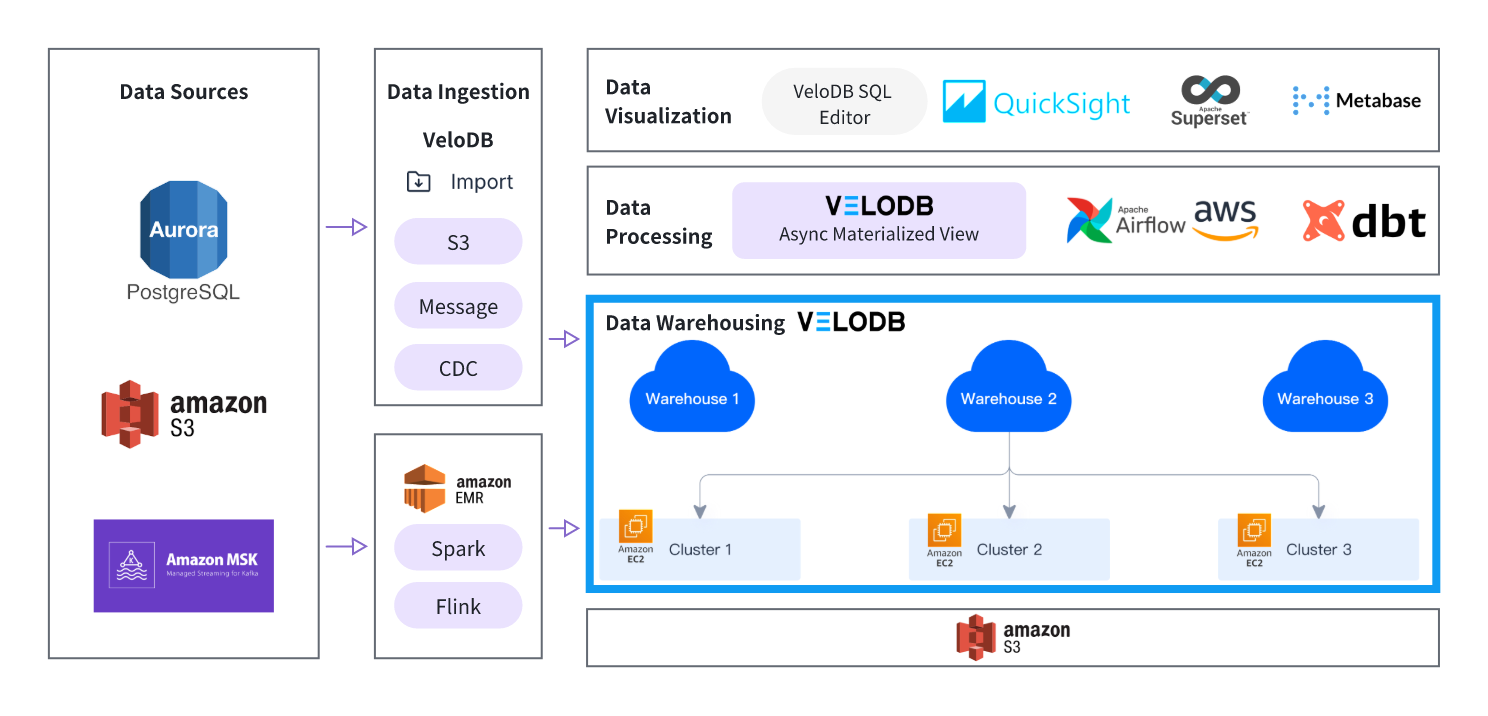
Data Sources
-
Aurora Postgres: Transactional database
-
AWS S3: Object storage, storing offline files in CSV, Parquet, ORC, and other formats
-
MSK: AWS's managed Kafka service for streaming data
Ingestion
-
VeloDB Import Service:
-
Real-time database sync: CDC sync from core transactional databases (Aurora Postgres; Aurora MySQL support coming April 2026) into VeloDB.
-
Message queue: Real-time import from Kafka and MSK via VeloDB Routine Load.
-
S3 integration: Batch data imported from S3.
-
-
AWS EMR:
-
EMR Spark: Offline batch ingestion via the Doris-Spark-Connector.
-
EMR Flink: Real-time streaming writes via the Doris-Flink-Connector.
-
Data Warehouse
VeloDB's storage-compute separated warehouse runs on three layers: a Data Storage layer, a Compute Cluster layer, and a Meta Service layer for metadata management.
Data Processing
-
dbt Connector: Data transformation workflows via the VeloDB dbt Connector.
-
Async materialized views: Automated warehouse modeling via VeloDB async materialized views.
-
AWS Airflow & ETL SQL: Pipeline orchestration and warehouse modeling via Airflow-scheduled VeloDB ETL jobs.
Dev and Visualization
-
VeloDB SQL Editor: Online SQL query and analysis.
-
AWS QuickSight: Dashboard and visual reports.
-
Open BI tools: Superset, Metabase.
Why VeloDB on AWS: The Advantages
The VeloDB on AWS solution delivers up to 6.6x better price-performance compared to Snowflake. The gains come from four areas.
- Lower cost and better performance
In terms of unit pricing, VeloDB Cloud is significantly cheaper than Snowflake Enterprise. Snowflake compute costs $0.375 per vCPU per hour; VeloDB comes in at $0.154 USD per vCPU per hour. Storage pricing is comparable ($0.040 GB/month for Snowflake vs. $0.036 for VeloDB). At a 1:1 compute-to-storage ratio, Snowflake's total resource cost runs approximately 1.5x higher than VeloDB's.
| Snowflake (Enterprise) | VeloDB Cloud (SaaS) | |
|---|---|---|
| Compute | $0.375 / vCPU / hour | $0.154 / vCPU / hour |
| Storage | $0.040 / GB / month | $0.036 / GB / month |
| Overall cost | At a 1:1 compute-to-storage ratio, Snowflake costs about 1.5x more than VeloDB | — |
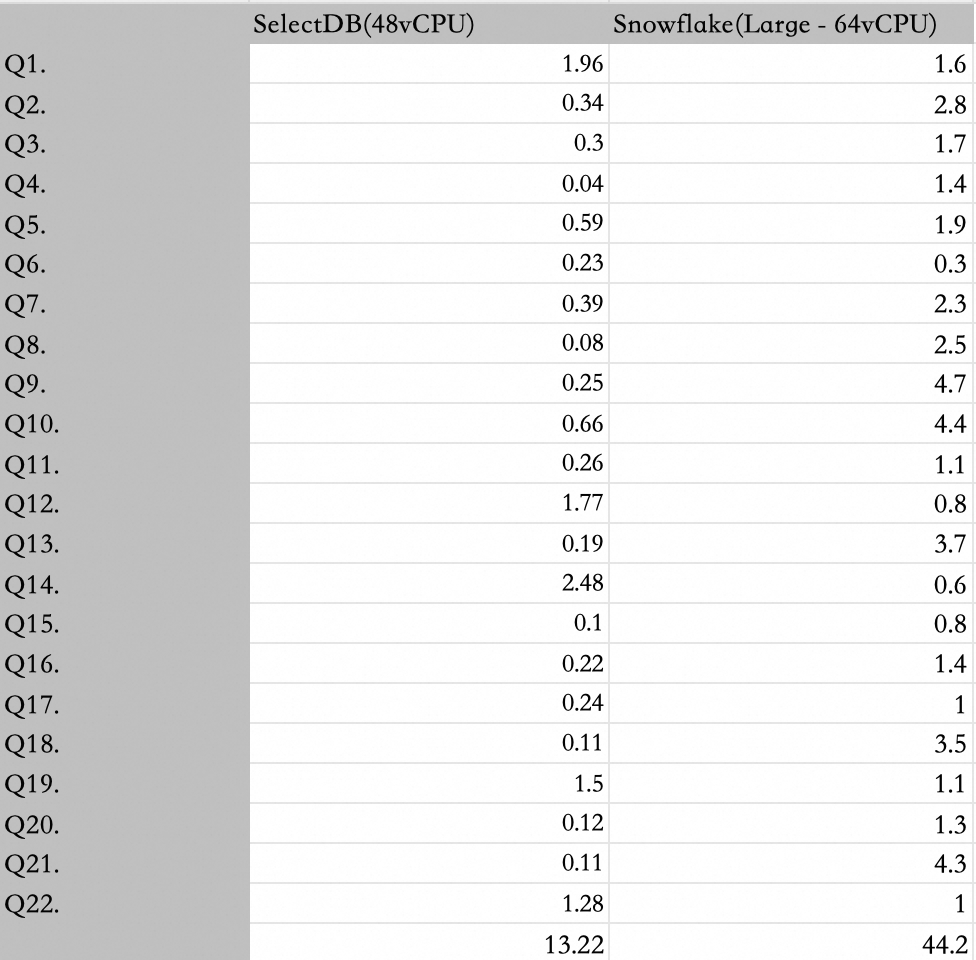
On performance, the gap widens. In the TPC-H SF100 benchmarks, a 48-core VeloDB cluster outperforms a 64-core Snowflake deployment by 3.3x for individual queries, with overall gains of 4.4x.
- Real-time analytics at scale
VeloDB addresses both of Snowflake's core limits directly:
-
High-concurrency queries: a single VeloDB cluster handles thousands of complex analytical queries per second (QPS), and tens of thousands of QPS for high-concurrency point queries.
-
Low-latency ingestion: whether syncing via database Binlog CDC or streaming through Kafka, VeloDB delivers 200ms to 10-second ingestion latency, with peak throughput up to one million records per second.
- Unified analytics engine
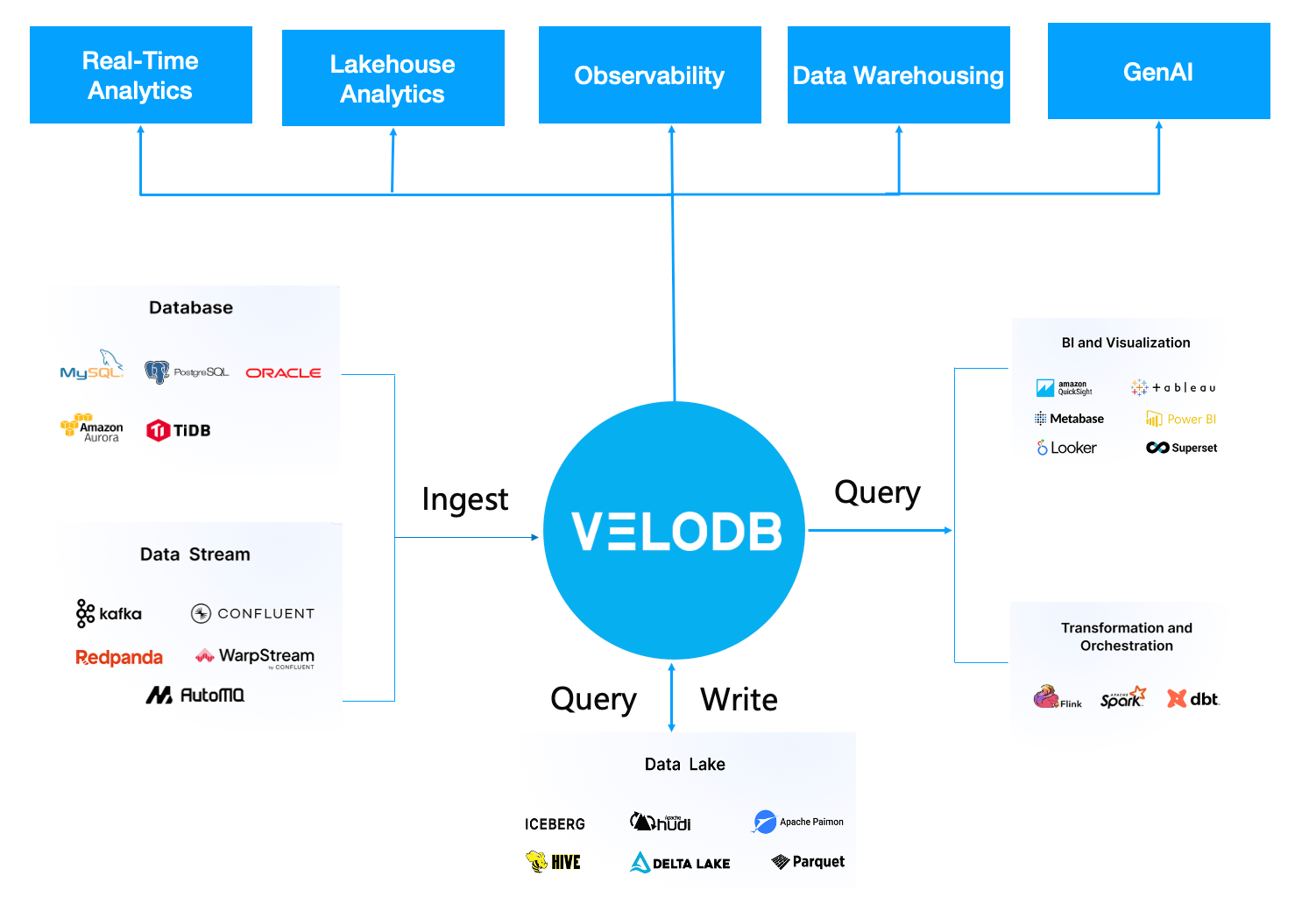
VeloDB runs real-time analytics, data warehousing, vector search, and observability on a single engine. Teams can consolidate multiple specialized tools into one platform, reducing architectural complexity and total cost.
- Open ecosystem
-
Native integrations: VeloDB supports MySQL protocol natively and integrates out of the box with Spark, Flink, Hive, Hudi, Iceberg, Paimon, Airflow, and other major data processing and data lake tools.
-
No vendor lock-in: Built on the Apache Doris open-source core under the Apache 2.0 license, VeloDB gives teams open, controllable data infrastructure without vendor lock-in.
-
Multi-cloud deployment: VeloDB deploys on AWS, GCP, and Azure, giving teams flexibility to build multi-cloud or hybrid architectures.
When Does Migrating from Snowflake to VeloDB Make Sense?
Not every team needs to migrate. But two situations consistently favor VeloDB:
-
Rising compute costs: As data volume and query frequency grow, Snowflake's compute costs climb fast and don't improve with scale. VeloDB's higher query performance and more efficient resource utilization significantly reduce total compute cost for the same workloads.
-
Real-time or high-concurrency workloads: When the business requires sub-second response times, higher query concurrency, or lower-latency ingestion, VeloDB is purpose-built for those scenarios: real-time analytics, high-concurrency dashboards, and streaming data pipelines.
Real-World Results: Replacing Snowflake in AWS to Cut 80% of Costs
A fintech company running TB-scale event analytics on Snowflake migrated to VeloDB on AWS. The company processes 3 billion user-generated events per day (10 TB), plus 1 TB of aggregated data daily. Here are the results:
-
80% cost reduction: Monthly spend dropped from $25,000 to $5,000.
-
Data latency cut from minutes to seconds: Ingestion latency went from 5-10 minutes (Snowflake micro-batch) to 1-2 seconds (VeloDB Stream Load)
-
Up to 90x query performance improvement on large dataset scans (475M rows)
-
5x concurrency improvement: Under 100-user concurrent load, response times dropped from 6 seconds to 1.2 seconds
For the full technical details of this migration, including architecture diagrams, ingestion pipeline design, and workload-level benchmarks, read the complete case study.
Get Started
If your team is hitting Snowflake's cost or performance ceiling on AWS, VeloDB can help.
-
Try VeloDB Cloud: Start a free trial or contact the VeloDB team to discuss your use case.
-
Explore Apache Doris: VeloDB is built on Apache Doris, an open-source project with an active community. Join the Apache Doris community to ask questions, share feedback, and connect with other users.


