In this blog, we will walk through how to build a knowledge store with VeloDB, powered by Apache Doris, and discuss how the workflow fits into the overall AI-powered feedback system that turns unstructured data into insights.
Why Build Your Own AI Knowledge Store
Most useful business data is unstructured and siloed. User feedback lives in forums. Bug reports pile up in GitHub and Jira. Customer pain points surface in support tickets. Each system holds a piece of the picture, and none of them talk to each other.
Take a real-life example at VeloDB: As Product Managers at VeloDB, we conduct extensive user research to understand behaviors and inform on the next actions or priorities. Some of these questions may be:
-
Which features do users use most frequently?
-
Which features have pain points in what scenarios?
-
What are the changing trends of new requirements and existing issues?
This information is scattered across forums, GitHub, Jira, ticket systems, and customer communication records, almost all of which are unstructured data and are stored in separate silos. Traditionally, a person would manually review each source of insight and leverage experience/heuristic judgment to turn this information into action.
Many of these systems have begun to offer AI solutions, but that only added to the existing silo problems. Each vendor's AI only sees its own data: GitHub's AI works on your issues, CRM AI surfaces customer patterns, and forum AI bots only work on posts and chats. None of them can answer a question that requires connecting all three. The insights stay fragmented by source.
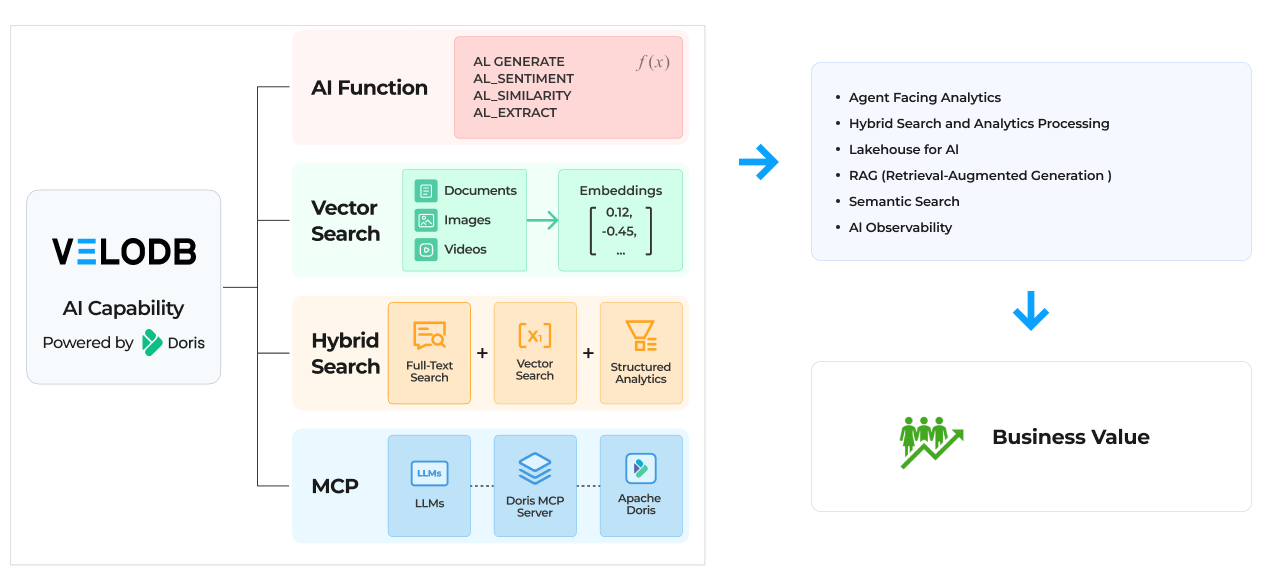
Building your own knowledge store is what breaks this data siloed problem. With VeloDB, powered by Apache Doris 4.0, teams can pull data out of these silos and make it queryable in one place. Below are the features for teams to build a dedicated knowledge store with efficient retrieval to supply AI and agents with the right context:
-
Semi-Structured Data Analysis Ability (Variant)
-
Full-text Search (BM25)
-
Vector Search (ANN)
-
AI Functions (Embedding, LLM Inference, etc.)
-
MCP Server
Demo: Building a Knowledge Store with VeloDB
As a product manager, I am considering the functional evolution of materialized views. One of the directions is: Should subsequent versions support the incremental update capability of materialized views? To make this decision and design the product solution, we need to understand the users' real situation. Therefore, I would like to understand the following two questions:
-
Question 1: In the materialized view feature, which external data sources do users most frequently use, and how many users are there for each?
-
Question 2: How many users have mentioned pain points or requirements regarding data timeliness, and what data sources do they use?
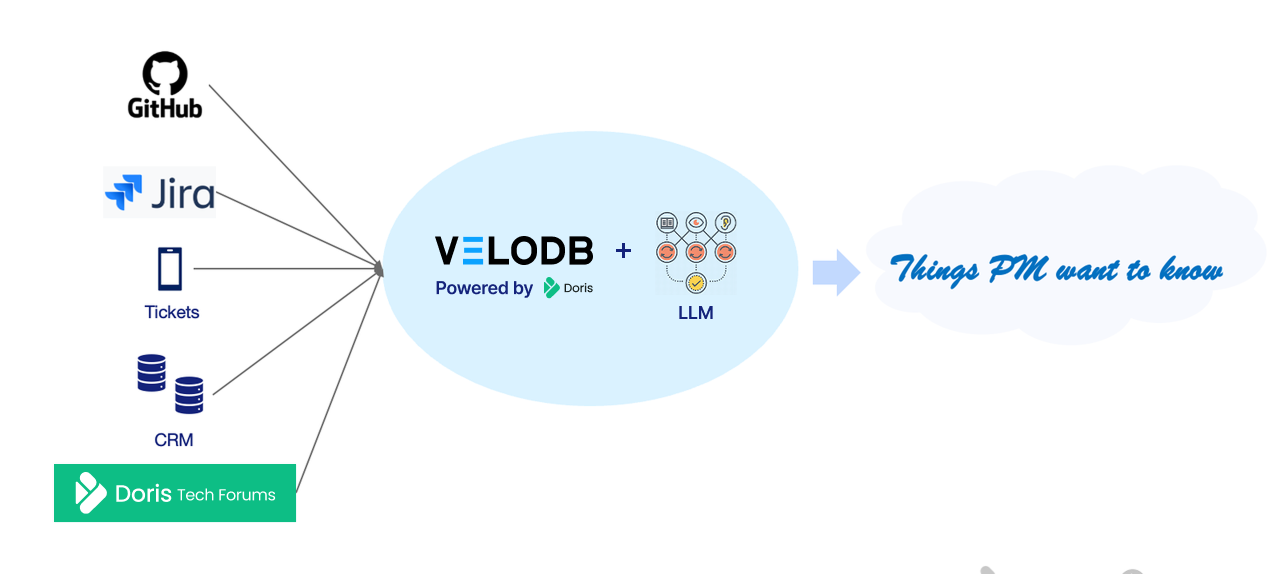
To answer my questions above, I collect and synchronize user feedback data scattered across forums, GitHub, Jira, ticketing systems, customer communication records, and other locations into VeloDB. We then leverage Apache Doris 4.0's AI capabilities for data processing, as well as hybrid search and analysis. The overall steps are as follows:
-
Initialization
- Doris table creation and raw data synchronization: Ingest unstructured data from forums, GitHub, Jira, ticketing systems, etc.
- AI resource initialization
-
Data Processing
- Chunking & Embedding: Segment unstructured text data and use the EMBED function for vectorization, storing it in vector format.
- Key information extraction from user feedback: Utilize AI Functions to understand, categorize, and summarize feedback content, storing it in Variant type
-
Hybrid Search and Analysis
- Gain user feedback insights through precise recall via Hybrid Search and analytical capabilities.
Here are the exact steps I used to implement the steps outlined above.
1. Table creation and raw data synchronization
A. Table design for Doris Technical Forum data
An inverted index has been added to the content field to support full-text search and scoring.
CREATE TABLE forum_questions (
question_id BIGINT, --Question ID
user_id BIGINT, --User ID
title STRING, --Title
content STRING, --Question and Answer Contents
INDEX idx_content (`content`) USING INVERTED PROPERTIES("lower_case" = "true", "parser" = "chinese", "support_phrase" = "true")
)
UNIQUE KEY(question_id)
DISTRIBUTED BY HASH(question_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
B. Forum Q&A Vector Table
An ANN index has been created on the embedding field to support vector search.
CREATE TABLE forum_question_embeddings (
user_id BIGINT NOT NULL, -- User ID
question_id BIGINT NOT NULL, -- Question ID
chunk_id BIGINT NOT NULL AUTO_INCREMENT, -- Chunk ID
content_chunk STRING NOT NULL, -- Chunk Content
embedding array<float> NOT NULL, -- Vector
INDEX ann_index (embedding) USING ANN PROPERTIES(
"index_type"="hnsw",
"metric_type"="inner_product",
"dim"="1024",
"quantizer"="flat"
)
)
DUPLICATE KEY(user_id, question_id, chunk_id)
DISTRIBUTED BY HASH(user_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
C. User feedback parsing table
This table stores the results after parsing and extracting raw forum Q&A data using AI functions. Due to different analytical requirements and the flexibility of AI functions in text parsing, the parsed_data field uses the Schema-Free VARIANT data type.
CREATE TABLE parsed_results (
id BIGINT NOT NULL AUTO_INCREMENT, -- ID
feedback_id BIGINT NOT NULL, -- User feedback ID
parsed_data VARIANT NOT NULL -- parsed results(Any JSON Format Data)
)
UNIQUE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
2. AI Resource Initialization
Create resources for the Embedding model and large language model (LLM) for subsequent use in SQL.
CREATE RESOURCE "zhipu-embedding-2"
PROPERTIES (
'type' = 'ai',
'ai.provider_type' = 'Zhipu',
'ai.endpoint' = 'https://open.bigmodel.cn/api/paas/v4/embeddings',
'ai.model_name' = 'embedding-2',
'ai.api_key' = 'xxx',
'ai.temperature' = '0.7',
'ai.max_token' = '1024',
'ai.max_retries' = '3',
'ai.retry_delay_second' = '1',
'ai.dimensions' = '1024'
);
CREATE RESOURCE "glm-4-flash-250414"
PROPERTIES (
'type' = 'ai',
'ai.provider_type' = 'Zhipu',
'ai.endpoint' = 'https://open.bigmodel.cn/api/paas/v4/chat/completions',
'ai.model_name' = 'glm-4.5-flash',
'ai.api_key' = 'xxx',
'ai.temperature' = '0.7',
'ai.max_token' = '-1',
'ai.max_retries' = '3',
'ai.retry_delay_second' = '1'
);
Data Processing
1. Chunking & Embedding
Each chunk consists of 400 characters, which are embedded and stored as vectors. The example chunking method is relatively simple. The next version of Apache Doris will support Python UDFs, which will enable more complex and flexible chunking.
WITH raw AS (
SELECT
question_id,
user_id,
content,
LENGTH(content) AS content_len
FROM forum_questions_auto_inc
),
t AS (
SELECT 0 AS d UNION ALL SELECT 1 UNION ALL SELECT 2 UNION ALL SELECT 3 UNION ALL SELECT 4
UNION ALL SELECT 5 UNION ALL SELECT 6 UNION ALL SELECT 7 UNION ALL SELECT 8 UNION ALL SELECT 9
),
num AS (
SELECT
(a.d * 100 + b.d * 10 + c.d + 1) AS n
FROM t a
CROSS JOIN t b
CROSS JOIN t c
),
chunks AS (
SELECT
r.user_id,
r.question_id,
SUBSTRING(r.content, (n - 1) * 400 + 1, 400) AS content_chunk
FROM raw r
JOIN num ON (n - 1) * 400 + 1 <= r.content_len
)
INSERT INTO forum_question_embeddings (user_id, question_id, content_chunk, embedding)
SELECT
user_id,
question_id,
content_chunk,
EMBED("zhipu-embedding-2", content_chunk) AS embedding
FROM chunks;
2. Key information extraction from user feedback
Use AI Functions to extract key information from user feedback and store it in Variant type.
SET @extract_prompt = "You are a professional product feedback analysis assistant. You are provided with a piece of user feedback text (feedback_text). Please extract key information related to \"Materialized View (MV)\" from it and output in strict JSON format. If the feedback text is unrelated to MV or no relevant information can be identified, return the string NULL directly.
Please extract the following information from feedback_text and generate JSON:
{
\"used_external_source\": \"Whether the user mentioned using any external data sources, such as MySQL, Oracle, Hive, Iceberg, etc. If not mentioned, this should be null.\",
\"transparent_rewrite\": \"Whether transparent rewrite was used or mentioned (true / false / null).\",
\"usage_scenario\": \"The usage scenario described by the user. If none, this should be null.\",
\"problems_or_gaps\": \"Problems or deficiencies the user believes exist with MV. If none, this should be null.\",
\"other_insights\": \"Any additional information related to MV that is valuable for product improvement. If none, this should be null.\"
}
Requirements:
1. The output must be pure JSON, with the object starting with { and ending with }.
2. Do not output any Markdown code block markers such as json, json, etc.
3. Do not output any additional text, descriptions, explanations, prefixes, or suffixes.
4. Do not output line breaks, spaces, or comments outside the JSON.";
INSERT INTO parsed_results (feedback_id, parsed_data)
SELECT
question_id,
content,
AI_GENERATE(
'glm-4-flash-250414',
concat(@extract_prompt ,'\nfeedback_text: ```' ,content, '```')
) AS extracted_info
FROM forum_questions where search('content:物化视图');
Hybrid Search and Analysis
1. Search and Analysis of Question 1
Question 1: In the materialized view feature, which external data sources do users most frequently use, and how many users are there for each?
Directly perform aggregate analysis on the parsing table of the feedback results from the previous step.
SELECT
lower(CAST(c.used_external_source AS string)) AS used_external_source,
COUNT(*)
FROM (
SELECT a.parsed_data.usage_scenario, a.parsed_data.transparent_rewrite, a.parsed_data.used_external_source AS used_external_source, a.parsed_data.problems_or_gaps, a.parsed_data.other_insights
, b.content
FROM parsed_results a
JOIN forum_questions b ON a.feedback_id = b.question_id
WHERE a.parsed_data.used_external_source != ""
AND a.parsed_data.used_external_source != "null"
) c
GROUP BY lower(CAST(c.used_external_source AS string));
2. Search and Analysis of Question 2
Question 2: How many users have mentioned pain points or requirements regarding data timeliness, and what data sources do they use?
To answer this question, we need to combine text search and semantic search to retrieve users who have "pain points or requirements related to data timeliness," and then perform aggregate analysis on these users.
--the text for vector search
SET @search_text="Poor data timeliness, ETL delays, untimely materialized view refresh, non-real-time data, real-time queries not meeting business needs, report delays, synchronization lag, high latency, slow updates, unable to meet real-time monitoring requirements, slow data landing, data delays affecting decision-making";
CREATE TEMPORARY TABLE retrieved_question_ids (
question_id BIGINT
)
UNIQUE KEY(question_id)
DISTRIBUTED BY HASH(question_id) BUCKETS 2
PROPERTIES (
"replication_num" = "1"
);
insert into retrieved_question_ids(question_id)
SELECT question_id --vector search
FROM forum_question_embeddings
where inner_product_approximate(
embedding,
EMBED("zhipu-embedding-2", @search_text)
) > 0.5
union ALL
select a.question_id from
(
SELECT question_id,score() as relevance --text search
FROM forum_questions
where content MATCH_ANY 'Timeliness, real-time, delay, latency, untimely updates, slow refresh, lag'
ORDER BY relevance DESC
LIMIT 100
)a;
SELECT
lower(CAST(c.used_external_source AS STRING)) AS used_external_source,
COUNT(DISTINCT c.question_id) AS feedback_cnt
FROM (
SELECT
a.feedback_id AS question_id,
a.parsed_data.used_external_source AS used_external_source
FROM parsed_results a
JOIN retrieved_question_ids r
ON a.feedback_id = r.question_id
WHERE a.parsed_data.used_external_source IS NOT NULL
AND a.parsed_data.used_external_source != ""
AND lower(a.parsed_data.used_external_source) != "null"
) c
GROUP BY lower(CAST(c.used_external_source AS STRING))
ORDER BY feedback_cnt DESC;
How a Knowledge Store fits into the User Feedback insight system
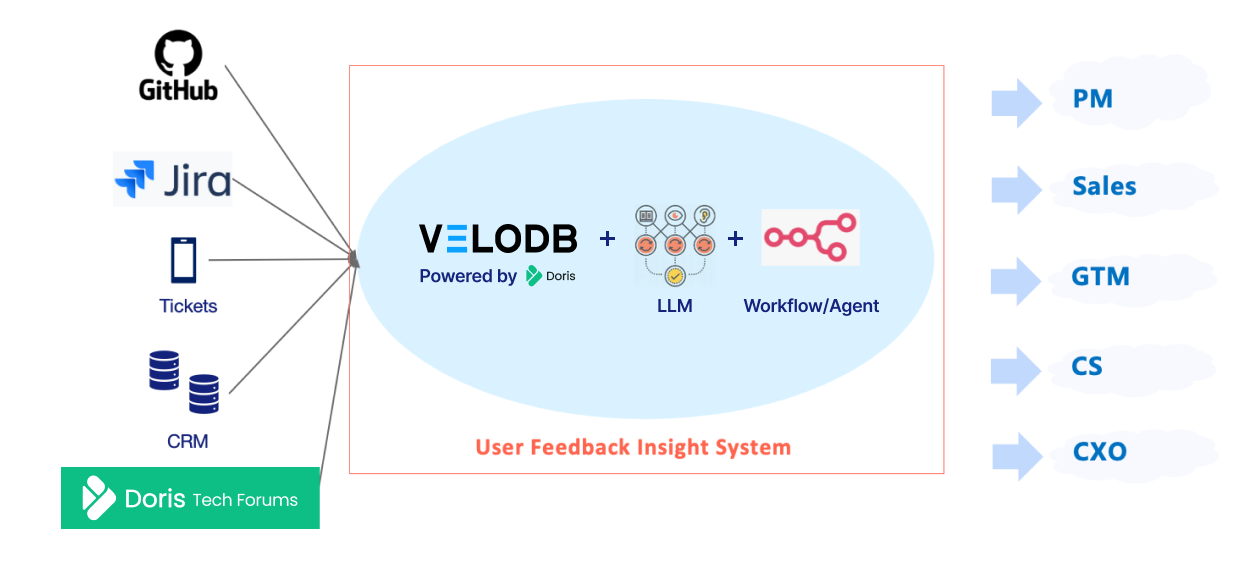
A knowledge store is just a single fundamental element that makes up an agentic system. And in the case of building a knowledge store using VeloDB, we also need the following elements:
-
Embedding models to turn the unstructured data into a vector representation
-
LLM to humanize the contextual input provided by
-
Workflows to orchestrate and route the user prompt to the correct tools and databases
With the above architecture, the system enables:
-
Continuously ingest multi-source unstructured user feedback
-
Users can create topics of interest and customize parsing rules through natural language
-
Automatically complete semantic recall, understanding, and categorization for topics users care about
-
Results can be further analyzed, aggregated, and compared
To integrate VeloDB with your AI workflow, we have built Apache Doris MCP, enabling seamless integration with code agents. If writing SQL is still too much friction, stay tuned, Skills are coming to Apache Doris and VeloDB.
Feedback systems are everywhere in plain sight
Taking this further, when we shift our focus from user feedback data to other unstructured data, we find that almost all mature business analysis systems are naturally accompanied by large amounts of unstructured data, and not surprisingly, they are also siloed. Below are a few scenarios that VeloDB and a knowledge store can help with:
-
User Profiling and Behavior Analysis. In the past, we could only see users' behavioral paths and conversion outcomes, but couldn't determine why users churned or got stuck. After introducing unstructured data such as user feedback and customer service conversations, we can directly correlate specific behaviors with issues expressed by users, explain the reasons behind behaviors, and verify whether subsequent product or operational adjustments are effective, forming a closed loop from problem discovery to improvement validation.
-
Risk Control Platform. Traditional risk control relies mainly on rules and metrics, with limited capability to identify complex or emerging risks. After introducing text data such as review notes and appeal explanations, we can identify abnormal statements and potential risk signals, and distill these experiences into new risk control strategies, achieving a closed loop from manual judgment to sustainable optimization.
-
Manufacturing Operations. Manufacturing analysis previously remained mostly at post-event statistics, with fault causes relying on manual investigation. After introducing unstructured data such as equipment logs and maintenance work orders, we can automatically correlate current faults with historical cases, quickly pinpoint causes, and continuously reuse handling experience to reduce recurring issues.
-
IoT and Connected Vehicles. Traditional platforms can only detect anomalies but struggle to promptly determine what the anomalies mean. After introducing operational logs, anomaly descriptions, and maintenance records, we can identify high-frequency fault patterns, provide early warnings for potential issues, and transform operations from passive response to proactive intervention.
Interested in trying VeloDB out for AI and knowledge stores? Get started with a free SaaS trial now.