Many Web3 analytics platforms use a multi-engine stack for their lakehouse: Spark for batch processing and a query engine like Trino or Presto for ad‑hoc lake queries, and an OLAP database for real‑time dashboards and user‑facing analytics. All engines run on top of a data lake storage built on object storage, such as S3, with Hive, Iceberg/Hudi, or other table formats.
But this stack often struggles to deliver low‑latency analytics at scale. Spark batch jobs for large lake tables can easily run for more than 10 minutes, which is fine for offline pipelines but too slow for interactive work. Trino can face performance issues in low-latency data lake queries. Moving data between the data lake and the data warehouse also creates duplication and lag, which can slow down workloads like metric computation, tax and compliance reporting, and near‑real‑time trading or risk analysis.
This article walks through how to replace this multi-engine stack with a unified lakehouse built on Apache Doris and Apache Paimon. The results: 5x faster than Spark for ETL, 2x faster than Trino for data lake queries, and data freshness improving from T+1 to minutes. We'll cover the architecture, key capabilities, and real use cases from crypto exchanges, including tax reporting, customer support, and order analytics.
The Challenge of Multi-Engine Web3 Analytics Architecture
Below is a common architecture for a multi-engine Web3 analytics stack, combining multiple engines in the computation layer to handle different workloads:
-
Apache Doris: Used for user-facing real-time reporting and analytics.
-
Trino (or Presto): Used for ad-hoc, detailed queries directly on the data lake.
-
Apache Spark: Used for offline ETL and data processing pipelines.
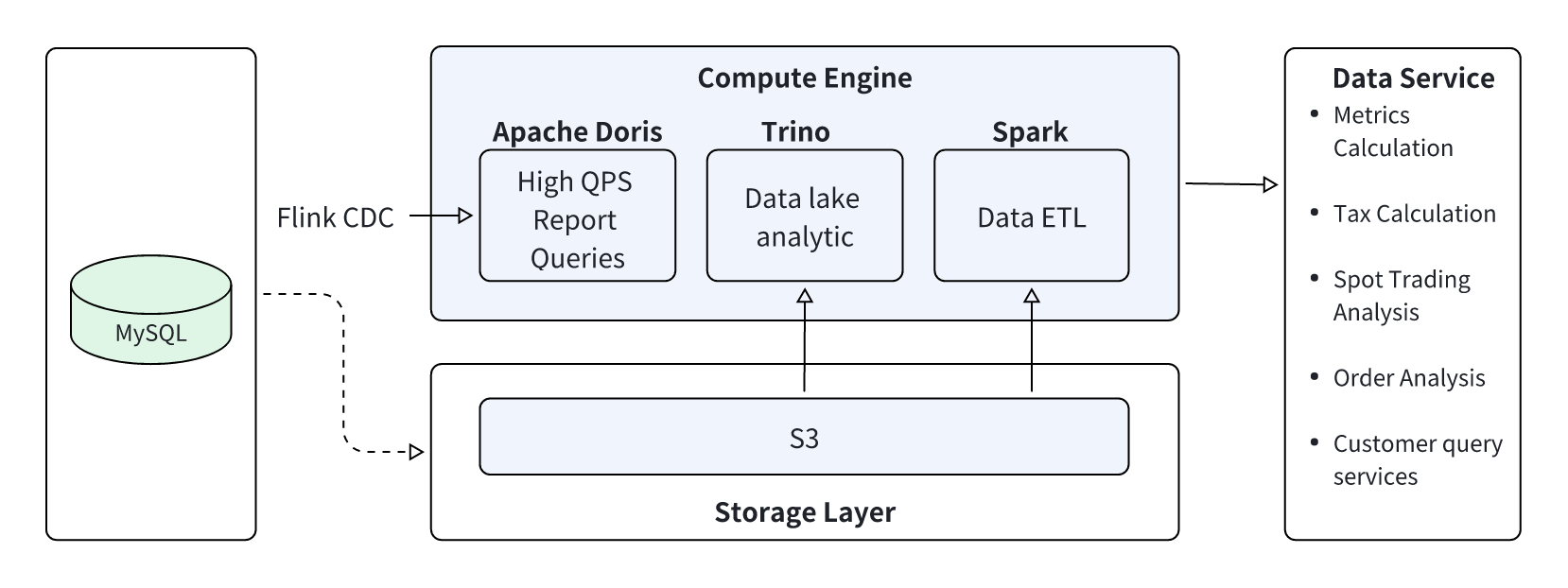
While functional, this multi-engine approach introduces significant pain points:
-
Architectural Complexity: Managing three separate compute engines (Doris, Trino, Spark) is complex and increases operational overhead.
-
Performance Bottlenecks:
- Trino's performance for large-scale data lake queries is often insufficient.
- Spark's offline batch jobs can be slow, with ETL pipelines taking 10-20 minutes or longer, leading to high data latency.
-
Data Silos & Poor Flexibility:
- Detailed raw data resides in the data lake (e.g., object storage) and is processed by Spark.
- Aggregated, analytics-ready data is loaded from Spark into a Doris data warehouse for high-concurrency queries.
- This separation creates a rigid barrier between the data lake and the warehouse, making data fusion and interaction difficult.
- Neither the lake nor the warehouse has native support for real-time data flow based on changelogs.
The Solution: A Unified Lakehouse with Apache Doris and Paimon
To address these challenges, we propose a unified Web3 lakehouse platform with Apache Doris and Apache Paimon.
Solution Benefits Summary:
-
Unified Compute Engine: The architecture consolidates computations previously spread across Doris, Trino, and Spark into a single Apache Doris engine. This dramatically simplifies the overall architecture and reduces maintenance complexity.
-
Faster lake queries: With Apache Doris querying Paimon directly, data lake analytics run 2x faster than Trino and 5x faster than Spark.
-
Seamless Lakehouse Integration: Using Doris's Paimon Catalog and Materialized View capabilities, the platform deeply integrates the data lake and data warehouse. This breaks down data silos and enables efficient interaction and data sharing.
-
Real-Time Data Updates: Paimon's changelog subscription mechanism lets the platform stream every change made in the lake to downstream systems. This keeps data in sync in real time and makes it easy to reuse the same lake data for different real‑time analytics and applications.
This architecture has been proven in real-world business scenarios. For instance, in a crypto exchange's tax reporting workflow, this solution replaced slow, cold-start Spark SQL jobs, enabling rapid data computation and export.
Apache Doris + Paimon Architecture
The unified lakehouse architecture is built around three core data pipelines, all powered by Apache Doris and Paimon.
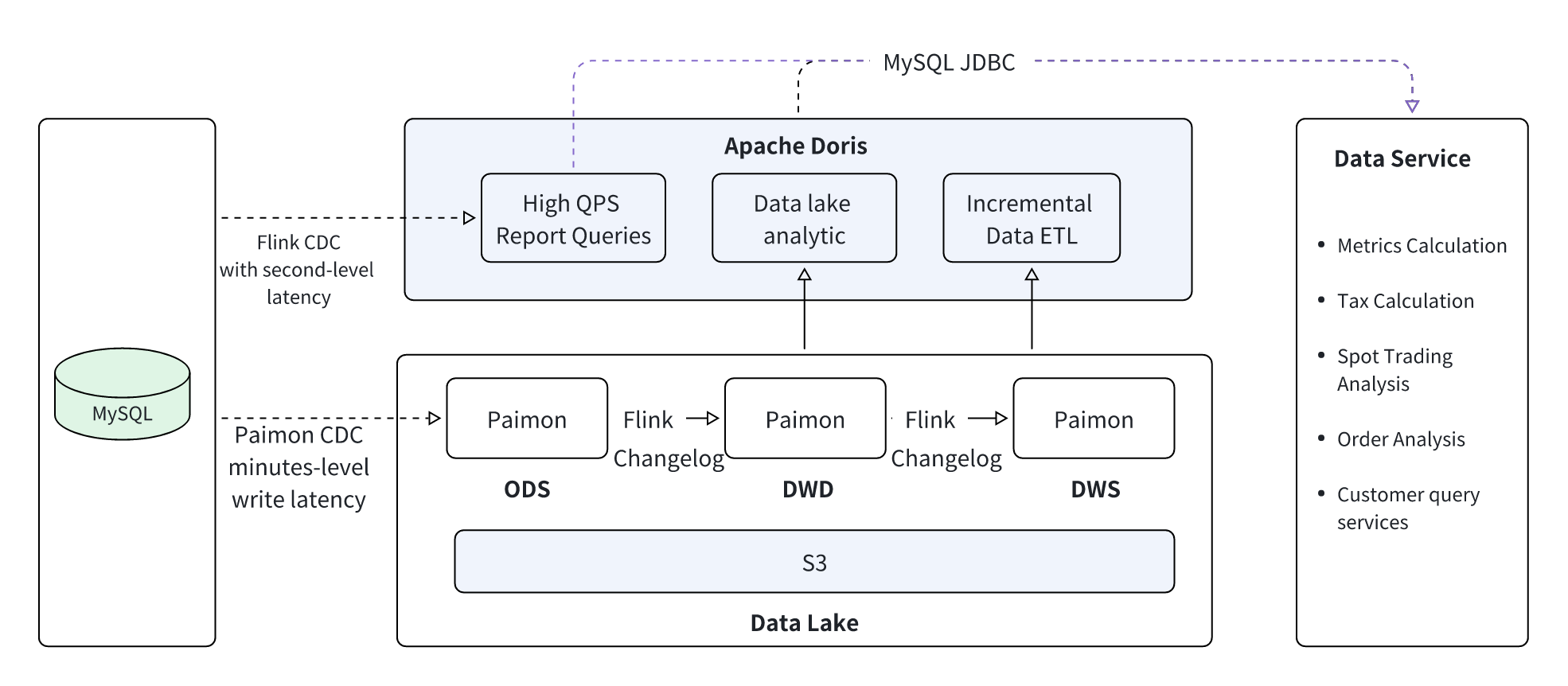
Three Core Data Pipelines
- High-Concurrency Reporting Service via Doris:
MySQL -> Flink CDC -> Doris Real-time Warehouse -> Client Application- This pipeline supports real-time, user-facing dashboards and reports.

- Data Processing on the Data Lake with Flink + Paimon:
ODS (on Paimon) -> Flink -> DWD (on Paimon) -> Flink -> DWS (on Paimon) -> ADS (on Doris) -> Client Application- This layered data processing pipeline is executed entirely on the data lake, with Flink for stream processing and Paimon as the storage layer.
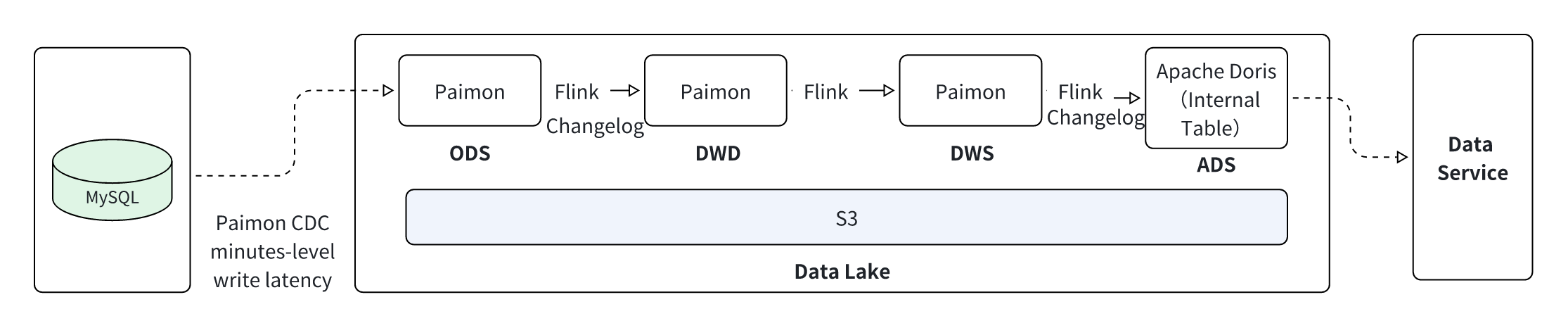
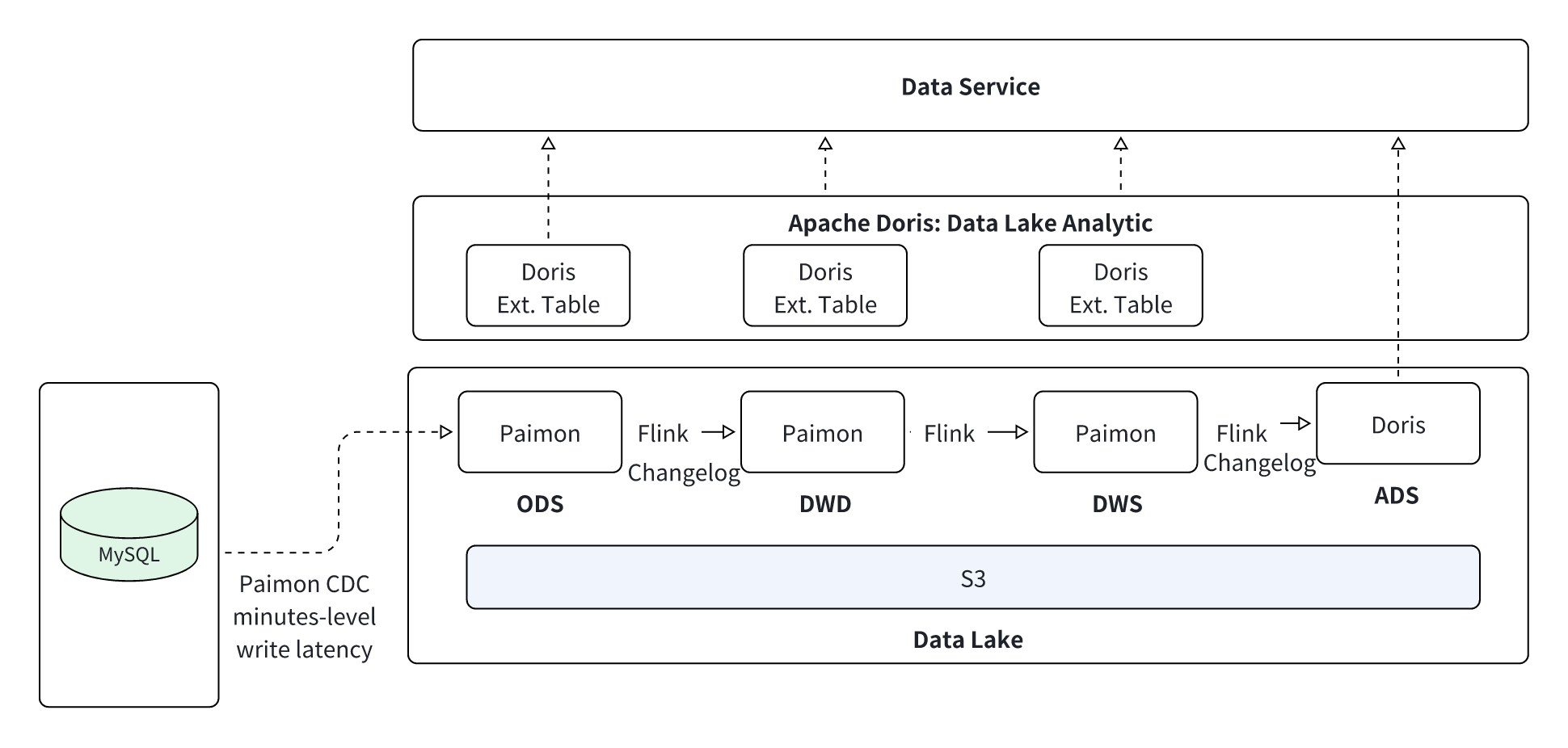
- Ad-Hoc Data Analysis on the Lake with Doris + Paimon:
- Apache Doris acts as the single query engine for analyzing data across all layers (ODS, DWD, DWS) stored in Paimon.
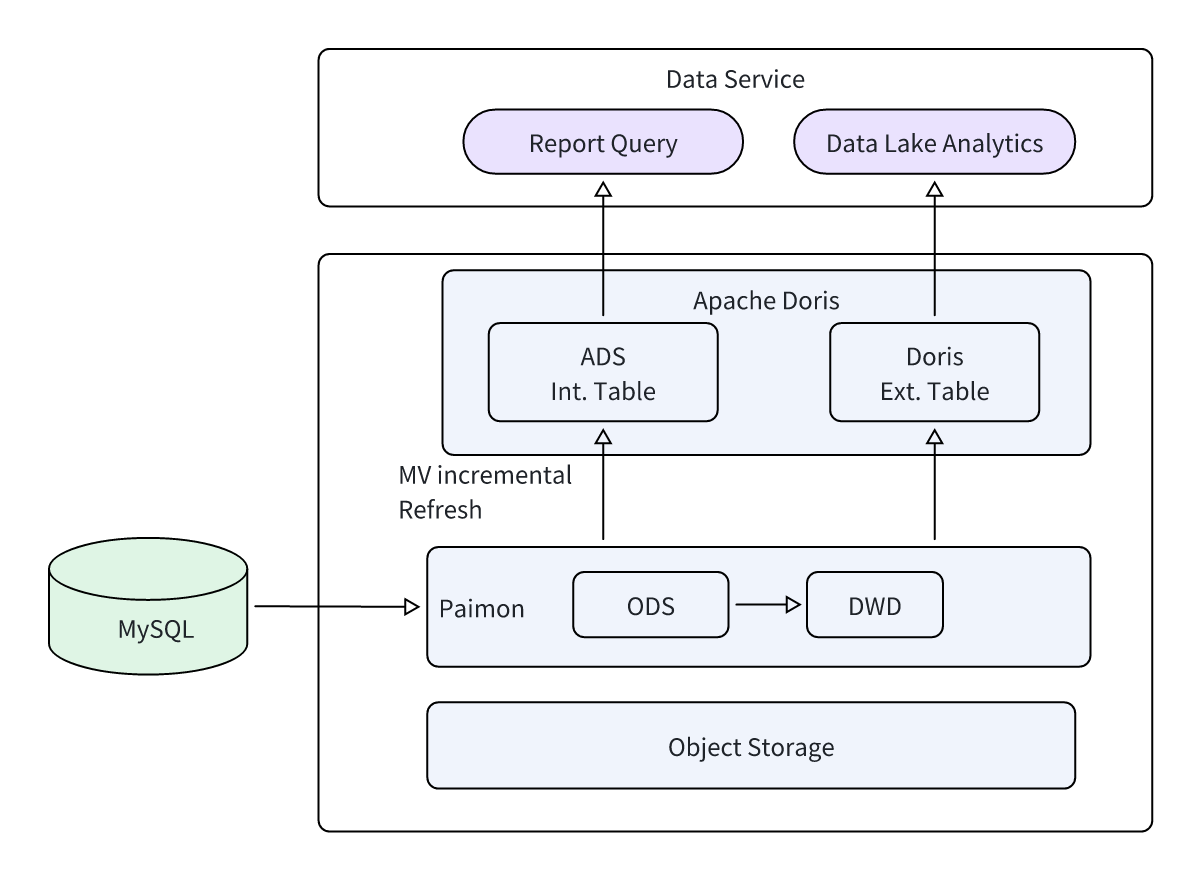
- Additionally, Apache Doris Materialized Views can incrementally process data from Paimon and store the results in Doris's internal tables for further acceleration:
Paimon -> Materialized View (Incremental Refresh) -> Doris Internal Table.
2. Apache Doris Core Capabilities in the Lakehouse
-
High-Concurrency Query Analysis: Apache Doris leverages partitioning, rich indexing, and a vectorized execution engine to deliver sub-second queries on billions of records at thousands of QPS. For complex reports, materialized views pre-compute and store results for instant responses.
-
Query Data Lake Faster: Apache Doris provides native support for Paimon Catalog, enabling Doris to query data directly in Paimon without data movement. Doris also uses push-down predicates and partition pruning to optimize performance. When analyzing terabyte-scale data, these optimizations make Doris 2x faster than Trino at locating and retrieving data.
-
Lightweight Data Processing: Apache Doris can also replace Spark for many lightweight ETL tasks like data cleansing and aggregation. Its asynchronous materialized views support minute-level incremental computation, automatically updating in the background as source data changes. The results can be written directly into Doris internal tables for fast subsequent analysis.
-
Lakehouse Data Integration: Using external materialized views, Apache Doris automates data integration from the data lake. The MV can automatically detect changes in Paimon data, perform incremental computations, and synchronize the results to Doris. This reduces manual ETL development, ensures data consistency, and allows business users to make decisions based on the freshest data.
3. Paimon Core Capabilities
| Paimon Core Capability | Description |
|---|---|
| Primary Key Table Updates | Paimon uses an LSM Tree data structure under the hood, enabling highly efficient data updates and upserts. For more details, see Primary Key Table and File Layouts. |
| Changelog Producer | Paimon can produce a complete changelog (update_before and update_after values) for any input data stream, ensuring that data changes are passed downstream completely and accurately. |
| Merge Engine | When a Paimon primary key table receives multiple records with the same key, its merge engine combines them into a single record to maintain key uniqueness. Paimon supports various merge behaviors like deduplication, partial updates, and pre-aggregation. |
Web3 Lakehouse Analytics Use Cases
1. Tax Data Processing for Exchanges
-
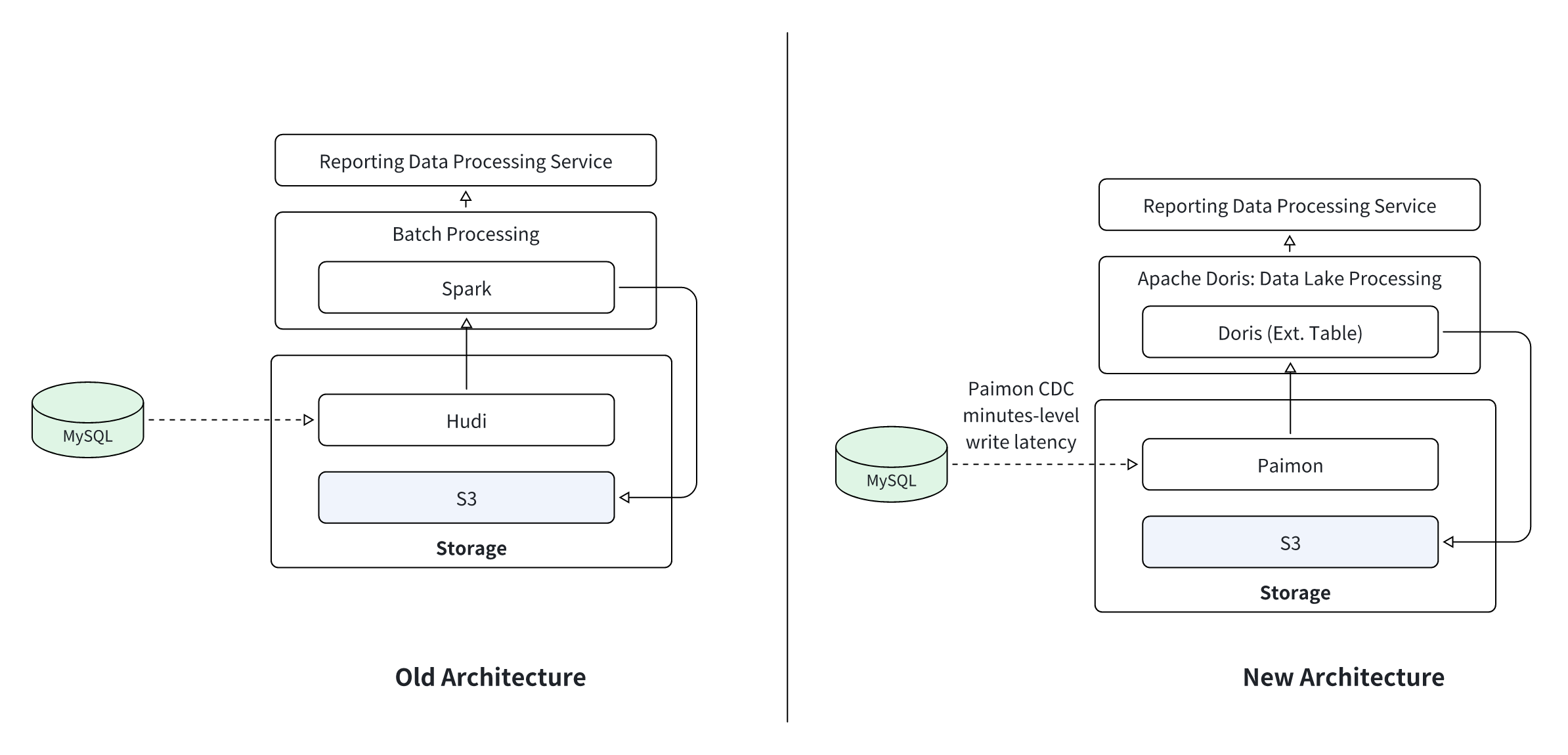
Scenario: A crypto exchange processes tens of millions of transaction records daily. This data must be aggregated according to tax rules and exported to S3. The original architecture used Hudi, which suffered from severe write amplification with upsert, and a Spark job that took 15 minutes to run.
-
Solution Design: The storage layer was migrated to Paimon, which uses a Copy-on-Write (CoW) mechanism to eliminate the upsert write amplification issue and supports deduplication on billions of records. Apache Doris replaced Spark for the computation, and its
OUTFILEfeature exports the aggregated results directly to S3, skipping intermediate steps that previously needed in the Spark-Hudi-S3 pipeline.
-- Create a Paimon catalog in Doris
CREATE CATALOG `paimon_catalog` PROPERTIES (
"type" = "paimon",
"warehouse" = "s3://warehouse/wh/",
"s3.endpoint"="http://minio:9000",
"s3.access_key"="admin",
"s3.secret_key"="password",
"s3.region"="us-east-1"
);
-- Enable parallel export and write data directly from Paimon to S3
set enable_parallel_outfile = true;
SELECT * FROM paimon_catalog.ods.tax_order where dt='2025-10-17'
into outfile "s3://my_bucket/export/my_file_"
format as csv
properties
(
"s3.endpoint" = "https://s3.us-east-1.amazonaws.com",
"s3.access_key" = "your_ak",
"s3.secret_key" = "your_sk",
"s3.region" = "us-east-1"
);
- Results:
- Data write time reduced from 10 minutes to 2 minutes.
- Storage costs decreased by 40%.
- Tax reporting data latency improved from T+1 to minute-level, meeting compliance requirements and reducing tax risk.
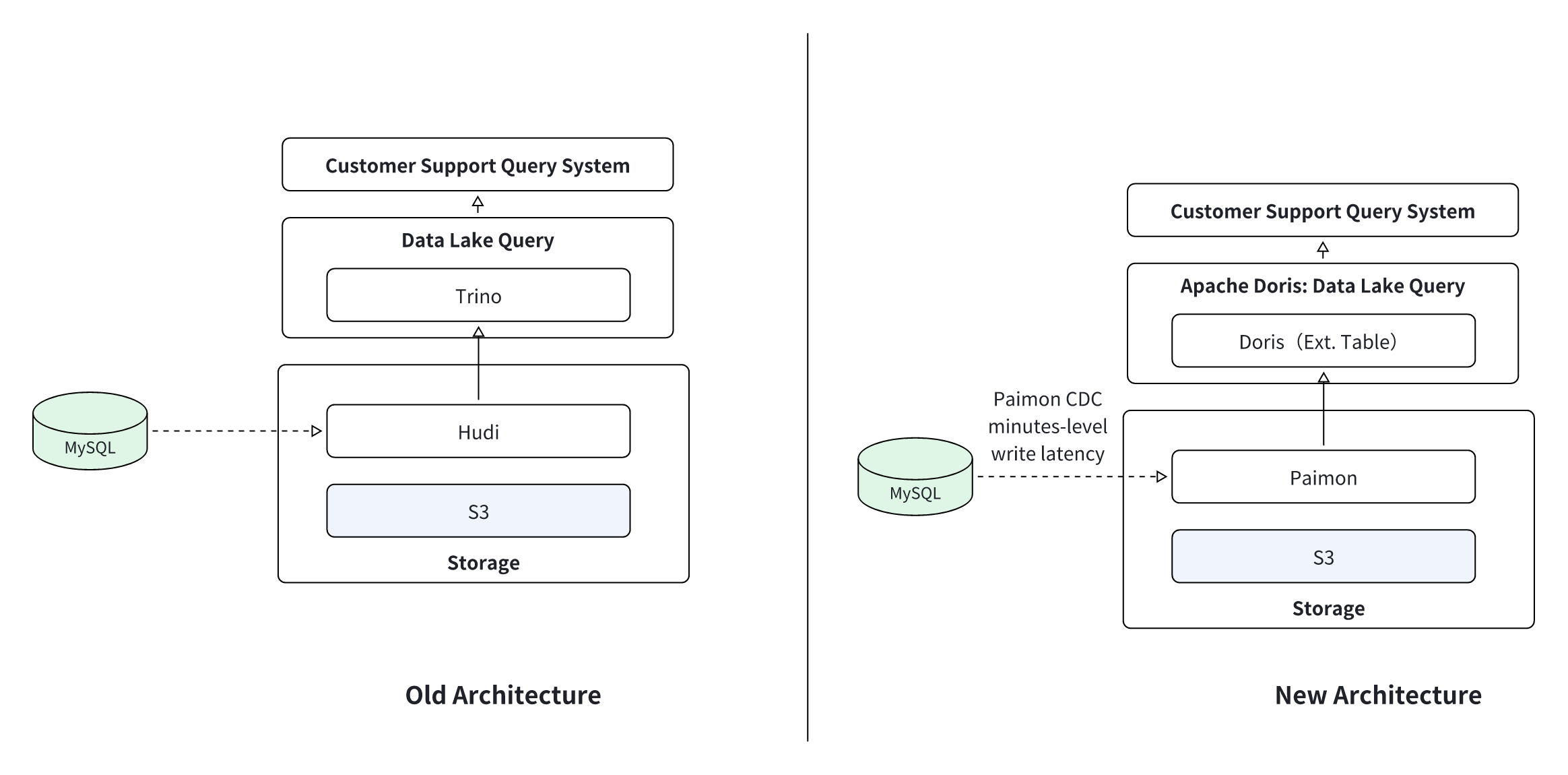
2. Real-Time Customer Support System
-
Scenario: A customer support team needs to quickly look up user transaction details and account histories. The previous architecture, based on Trino, had unstable query latencies of 5-10 seconds, dragging support efficiency.
-
Solution Design: Paimon was adopted as the unified storage layer for all detailed transaction data. Apache Doris serves as the query engine, using partition pushdown and vectorized execution to achieve stable query latencies of less than 2 seconds.
-- Query Paimon data directly through the catalog
mysql> use paimon_catalog.ods;
mysql> select * from paimon_catalog.ods.tax_order limit 10;
- Results:
- Customer issue resolution efficiency increased by 50%. Improved customer satisfaction.
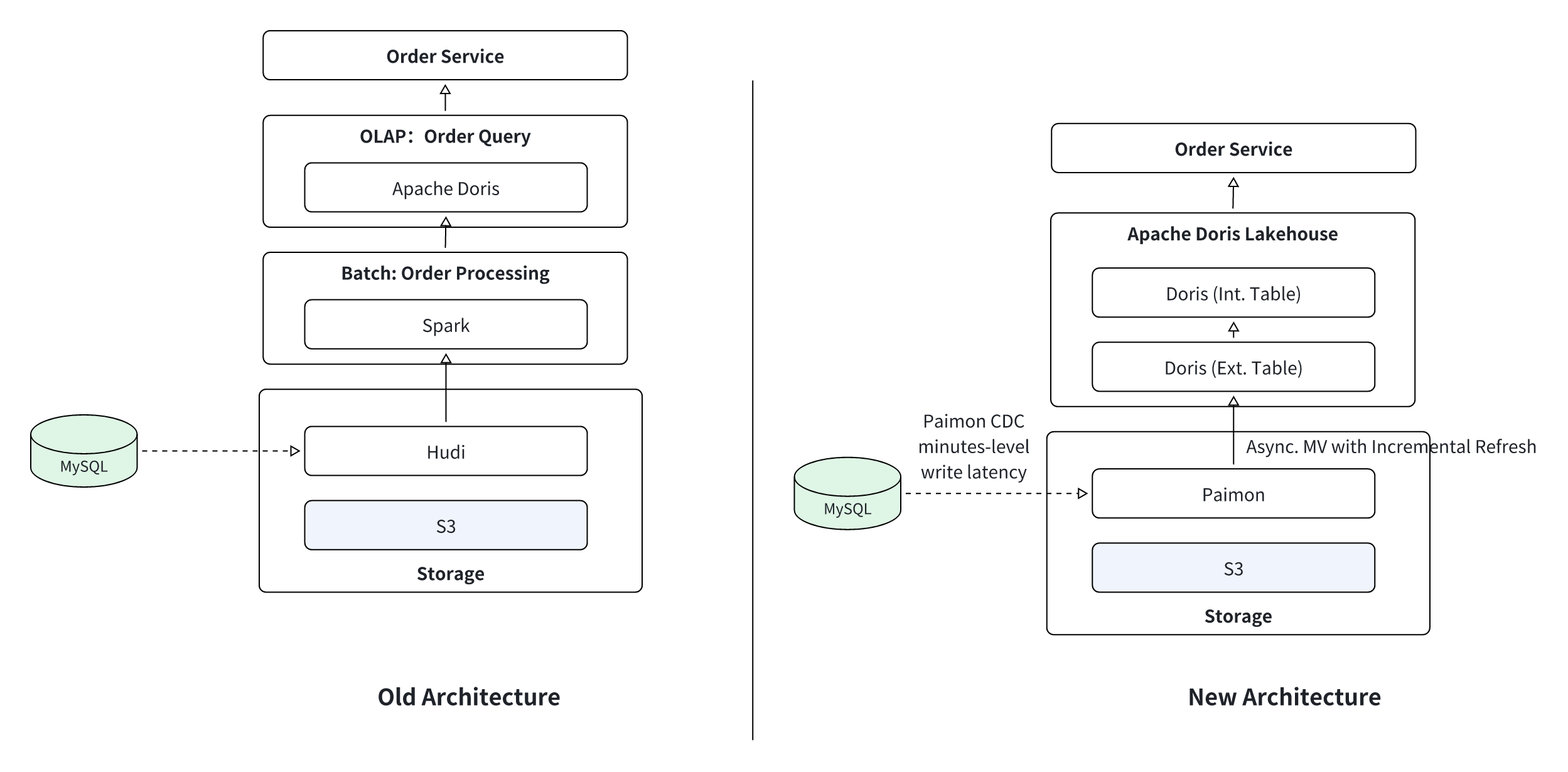
3. Order Calculation and Analytics
-
Scenario: An exchange calculated order metrics (e.g., fulfillment time, refund rate) using a daily offline Spark batch job that ran at midnight and had a data latency of over 1 hour. This process was difficult to develop, complex to maintain, and provided stale data.
-
Solution Design: An Apache Doris external materialized view replaced the Spark ETL pipeline. The MV is configured with a partition-based incremental refresh policy, triggering a computation every 5 minutes. The results are written directly into a Doris internal table, which serves high-concurrency queries for the metrics dashboard.
CREATE MATERIALIZED VIEW order_finish_mv (
order_id COMMENT 'Unique order system ID',
create_time COMMENT 'Creation time',
...
position_id COMMENT 'Position ID',
order_status COMMENT 'Order status',
deriver_source COMMENT 'Derivative source',
deriver_detail COMMENT 'Derivative detail',
traded_volume COMMENT 'Traded volume',
remain_volume COMMENT 'Remaining volume',
cancled_volume COMMENT 'Canceled volume',
...
)
BUILD IMMEDIATE
REFRESH AUTO ON SCHEDULE EVERY 5 MINUTE
DUPLICATE KEY(`order_id`)
COMMENT 'Materialized view for completed contract orders'
PARTITION BY (`create_time`)
DISTRIBUTED BY HASH(`order_id`) BUCKETS AUTO
PROPERTIES (
"storage_medium" = "hdd",
"storage_format" = "V2"
) AS
SELECT
`OrderSysID` AS `order_id`,
`CreateTime` AS `create_time`,
...
`Price` AS `price`,
`Volume` AS `volume`,
...
FROM catalog_paimon_finishorder;
- Results:
- Data latency reduced from 1 hour to 5 minutes.
- Calculation performance improved by over 5x compared to Spark.
- Achieved seamless lakehouse fusion, allowing business users to access near-real-time order metrics.
4. Real-Time Spot Trading Analysis
-
Scenario: A real-time dashboard for spot trading required second-level updates for metrics like average transaction price. The existing Trino-based queries had high latency (5-8 seconds) and could not meet the requirement.
-
Solution Design: Transaction details are stored in a Paimon data lake. An Apache Doris external materialized view performs partition-based incremental calculations and writes aggregated statistics into a Doris internal table. The dashboard queries the internal table for statistical data and queries the external Paimon table for drill-down details.
-
Results:
- Complex detail queries are now 2x faster than on Trino.
- Metric queries saw a 5x performance improvement and 8x higher concurrency.
Conclusion
By integrating Apache Doris and Apache Paimon, Web3 organizations can build a modern, unified data platform that is simpler, faster, and more flexible than traditional multi-engine solutions. This approach consolidates computation into a single engine of Apache Doris, breaks down data silos between the data lake and warehouse, and provides the performance needed for real-time on-chain analytics, from compliance to customer support to real-time trading dashboards.
Join the Apache Doris community on Slack to connect with Doris experts and users. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.