


Apache Paimon is a high-performance streaming-batch unified table format and data lake storage system designed specifically for real-time data processing. It supports ACID transactions, consistent views, incremental read/write operations, and schema evolution—essential capabilities for modern lakehouse architectures.
This comprehensive guide explores Apache Paimon from its origins and architecture to practical use cases and ecosystem integration. Whether you're comparing lake formats or planning a streaming lakehouse deployment, you'll find the information needed to evaluate if Apache Paimon is the right choice for your workload.
Challenges in Streaming Computing and Storage
Before diving into Apache Paimon, it helps to understand the problems it was designed to solve. Modern data teams face significant friction when bridging streaming processing and batch storage.
The Gap Between Streaming Processing and Batch Storage
Streaming engines like Apache Flink excel at processing unbounded data in real time—capturing change streams, performing joins, and maintaining state. However, they traditionally rely on external storage systems that were built for batch workloads. Message queues like Apache Kafka provide low-latency streaming semantics but lack query capabilities and efficient historical storage. Batch storage formats like Parquet and ORC offer excellent analytical performance but have no native concept of incremental updates or changelogs.
This architectural split forces teams to maintain multiple systems: Kafka for streaming, Hive or S3 for batch storage, and complex ETL pipelines to bridge them. The result is operational complexity, data duplication, and latency that often exceeds business requirements.
Limitations of Traditional Data Lake Formats for Real-Time Workloads
Traditional data lake formats—built around Hive + Parquet or similar stacks—were designed for batch analytics. They struggle with real-time workloads in several ways:
- No Native Incremental Processing: Solutions like Hive+Parquet lack incremental read/write capabilities, forcing full table scans for change detection.
- Data Consistency Challenges: Write processes are prone to read-write conflicts and lack transactional guarantees.
- Insufficient Real-Time Update Support: Data changes cannot be quickly reflected, resulting in high latency for downstream consumers.
- Complex Maintenance: Teams depend on external tools for version management, data cleanup, schema compatibility, and more.
These limitations motivated the development of next-generation lake formats—including Apache Paimon—that unify streaming and batch semantics in a single table abstraction.
What Is Apache Paimon?
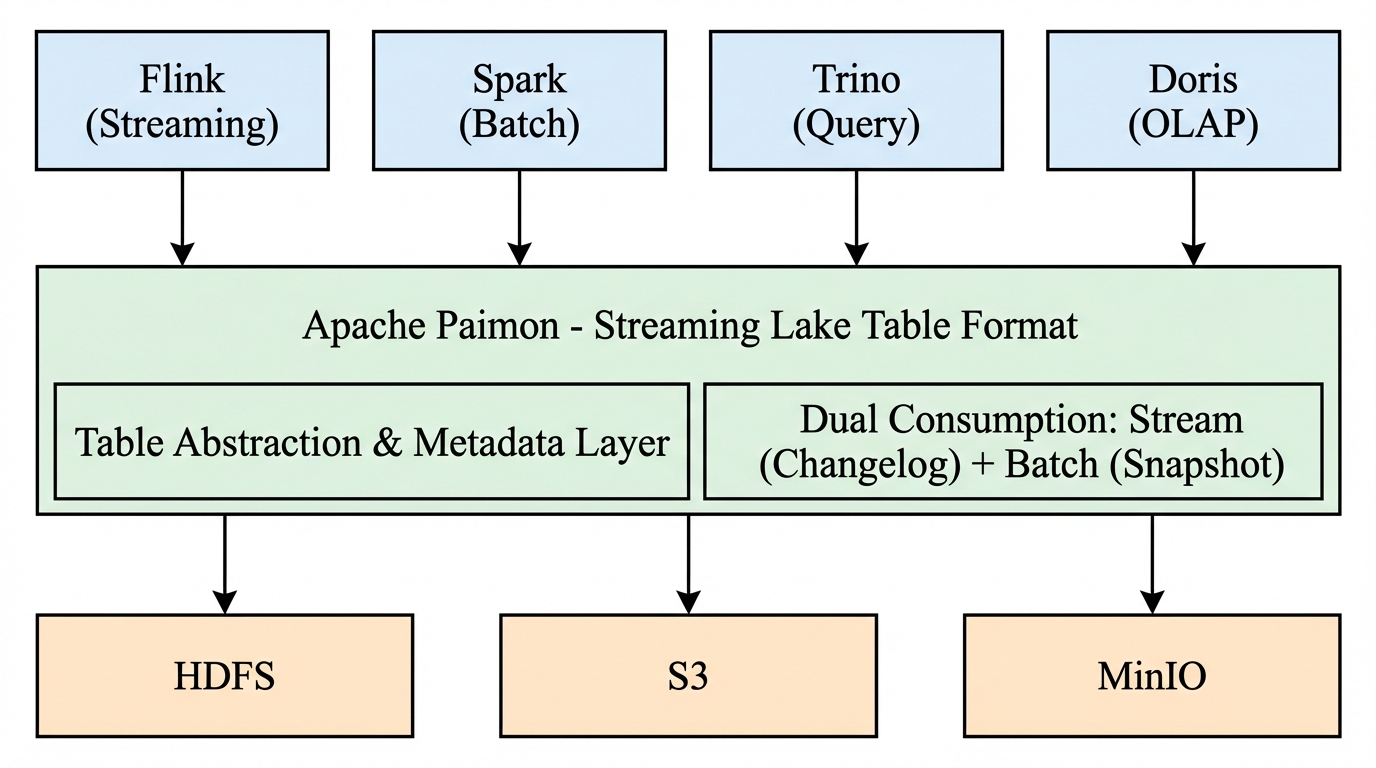 Apache Paimon fills the gap between streaming processing and batch storage by providing a table format that natively supports both modes. Here's how it positions itself in the data stack.
Apache Paimon fills the gap between streaming processing and batch storage by providing a table format that natively supports both modes. Here's how it positions itself in the data stack.
Apache Paimon Definition
Apache Paimon is a high-performance streaming-batch unified table format and data lake storage system. It supports:
- ACID transactions for data consistency
- Consistent views via snapshot isolation
- Incremental read/write operations without external log systems
- Schema evolution including field additions, renames, and type modifications
Traditional formats like Parquet and ORC excel at batch analytics but lack native streaming capabilities. Apache Paimon provides a novel lake storage format that helps enterprises efficiently manage large-scale, high-frequency data changes.
Apache Paimon as a Streaming Lake Table Format
For streaming engines like Flink, Paimon acts as a message queue—you can subscribe to changelogs and consume incremental updates. For batch engines like Spark or Trino, it acts like a Hive table—query the latest snapshot or historical data with full SQL support. This dual nature is what makes Paimon a true streaming lake table format: one table, multiple consumption patterns.
In practice, we've found Paimon particularly valuable when building real-time ODS layers—it eliminates the need for intermediate Kafka topics while maintaining low-latency data visibility.
Positioning Apache Paimon in the Data Stack
Apache Paimon sits between compute engines (Flink, Spark, Doris, Trino) and underlying storage (HDFS, S3, MinIO). It provides the table abstraction and metadata layer that enables unified streaming-batch semantics. Unlike a traditional data warehouse or OLAP system, Paimon is a table format—it defines how data is organized, versioned, and consumed, while remaining engine-agnostic for both reads and writes.
Why Apache Paimon?
Understanding when Apache Paimon makes sense—and when it doesn't—helps you make informed architecture decisions.
Design Goals of Apache Paimon
Apache Paimon was designed with several core goals:
- Streaming-First: Native support for high-frequency writes, incremental reads, and changelog consumption without external log systems.
- Unified Interface: Single table format for both batch and streaming workloads, reducing architectural complexity.
- Low Latency: LSM-tree structure combined with incremental snapshots achieves second-level or minute-level data visibility.
- Multi-Engine Compatibility: Works with Flink, Spark, Trino, Presto, Doris, StarRocks, and Hive through unified catalog interfaces.
When Apache Paimon Makes Sense
Apache Paimon is an excellent fit when:
- Real-time CDC and ODS construction are primary requirements—ingesting change streams from MySQL, PostgreSQL, or other databases.
- Streaming ETL pipelines (ODS→DWD→DWS) need to flow data between layers without Kafka or similar intermediaries.
- Real-time BI and OLAP require low-latency visibility (minute-level or second-level) on streaming data.
- Unified stream-batch architecture is a goal—one table format for both historical analytics and real-time consumption.
When Apache Paimon Is Not the Best Fit
Apache Paimon may not be the best choice when:
- Pure batch workloads dominate—Apache Iceberg offers richer partition evolution and a more mature ecosystem for large-scale batch processing.
- Spark-only teams with no Flink expertise—Paimon's strongest integration is with Flink; Iceberg or Delta Lake may have more mature Spark support.
- Sub-second latency is required—Paimon achieves minute-level or second-level visibility; true sub-second streaming may still need Kafka.
Understanding Apache Paimon's Core Architecture
Apache Paimon adopts a table format design philosophy combined with high-performance storage engines. Its architecture enables the streaming-batch unification that sets it apart from traditional formats.
The Streaming Lakehouse Paradigm
Paimon implements the streaming lakehouse paradigm: a single table that serves as both a message queue (for streaming consumption) and a batch table (for analytical queries). In batch mode, it behaves like a Hive table—query the latest snapshot with full SQL. In streaming mode, it behaves like a message queue—subscribe to changelogs with historical data that never expires.
Unified Storage Design
Under the hood, Paimon stores columnar files (Parquet) or row-based files (Avro) on the filesystem or object store. Metadata is saved in manifest files, enabling large-scale storage and data skipping. For primary key tables, Paimon uses an LSM-tree structure to support high-volume updates and high-performance queries.
The architecture consists of several core components:
- File Store: Organizes and stores underlying data files using Parquet or Avro.
- Snapshot & Manifest: Maintains data change history; each write generates a snapshot with file information.
- Schema Management: Version control for table structures with schema evolution support.
- Streaming Coordinator: Handles data merging, compaction, and commit mechanisms for streaming writes.
- Catalog System: Unified metadata management with interfaces for Hive, Flink, Spark, Doris, and more.
LSM-Tree: The Foundation of Real-Time Performance
For primary key tables, Apache Paimon uses an LSM-tree (Log-Structured Merge-Tree) structure internally. This design is critical for real-time performance:
- High-Frequency Writes: LSM-trees buffer writes in memory and flush to disk in sorted runs, enabling high throughput for inserts and updates.
- Incremental Compaction: Background compaction merges small files, optimizing read performance without blocking writes.
- Snapshot Isolation: Each commit produces a new snapshot; readers see consistent views without blocking writers.
The LSM-tree structure allows Paimon to achieve minute-level or second-level data visibility—a key differentiator from batch-oriented formats like Iceberg.
Performance Benchmarking and Validation
Apache Paimon's performance characteristics have been validated in production deployments. Key metrics include:
- Streaming write latency: 1–5 minutes for Flink integration in recommended production configurations (theoretical minimums can be lower; vs. ≥1 hour recommended for Iceberg streaming).
- Real-time query: Second-level visibility through LSM-tree and incremental snapshots.
- Incremental read: Native snapshot-based pulling without external log systems.
For teams evaluating Paimon, the official documentation and Flink quick start provide hands-on benchmarks.
Key Concepts in Apache Paimon
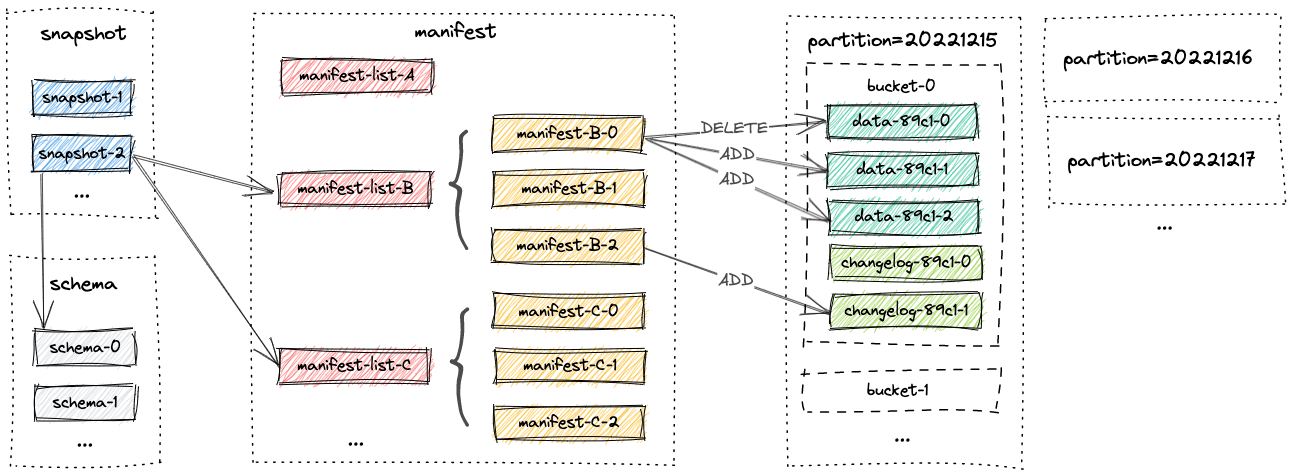 Understanding Paimon's core concepts helps you design effective tables and pipelines.
Understanding Paimon's core concepts helps you design effective tables and pipelines.
Snapshots
A snapshot represents a consistent view of the table at a point in time. Each write operation (batch or streaming) generates a new snapshot. Snapshots enable:
- Snapshot reading: Query the table as it existed at a specific snapshot ID.
- Time travel: Access historical data for debugging or reprocessing.
- Incremental reads: Consume only the delta between two snapshots.
Partitions
Partitions divide table data by partition columns (e.g., date, region). Partitioning improves query performance by enabling partition pruning—skipping irrelevant data during scans. Paimon supports dynamic partition discovery and partition evolution, though partition capabilities are more moderate compared to Iceberg's rich partition evolution.
Buckets
Buckets subdivide partitions (or the entire table if unpartitioned) into fixed groups. Each bucket is an independent LSM-tree. Buckets are defined at table creation:
CREATE TABLE my_table (
order_id STRING,
user_id STRING,
ts TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'bucket' = '4'
);
Records in the same bucket are strictly ordered; records across buckets have no ordering guarantee. Bucketing affects write parallelism and read performance—choose bucket count based on data volume and concurrency.
Consistency Guarantees
Apache Paimon provides ACID semantics:
- Atomicity: Writes are all-or-nothing.
- Consistency: Readers see consistent snapshots.
- Isolation: Snapshot isolation supports concurrent stream-batch writes.
- Durability: Committed data is persisted to storage.
Apache Paimon Table Types
Apache Paimon supports different table types for different workload patterns.
Primary Key Tables
Primary key tables consist of columns that contain unique values for each record. Key characteristics:
- Streaming updates: Support high-frequency inserts and updates via Flink streaming.
- Changelog consumption: Readers can subscribe to changelogs (INSERT, UPDATE, DELETE).
- Data ordering: Paimon sorts by primary key within each bucket.
- Merge engines: Flexible deduplication—last row, partial update, aggregation, or first row.
-- Flink SQL
CREATE TABLE my_paimon.orders (
order_id STRING,
user_id STRING,
ts TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'bucket' = '4'
);
Primary key tables are ideal for CDC ingestion, real-time dimension tables, and any scenario requiring upserts.
Append-Only Tables
Append-only tables (tables without primary keys) accept only append data. They cannot receive changelogs or support streaming upserts. Characteristics:
- Append-only writes: Suitable for log data, event streams, and immutable datasets.
- Batch operations: Still support DELETE, UPDATE, and MERGE-INTO in batch mode.
- Automatic compaction: Small file merging and z-order sorting for optimized layout.
- Streaming read/write: Can act like a queue for append-only streaming.
CREATE TABLE my_table (
a INT,
b STRING
);
Append-only tables are simpler to operate and ideal when updates are not required.
Integration with External Log Systems
Apache Paimon can integrate with external log systems (e.g., Kafka) for CDC ingestion. Flink CDC connectors capture change streams from MySQL, PostgreSQL, and other databases, writing directly to Paimon tables. Paimon also supports reading from and writing to Kafka when hybrid architectures are needed—though a key benefit of Paimon is reducing dependence on Kafka for many use cases.
Advanced Features for Streaming Data Ingestion
Apache Paimon offers several advanced features that simplify streaming data pipelines.
Change Data Capture (CDC)
Paimon natively supports Change Data Capture without external message queues. Key capabilities:
- Changelog producer: Automatically generates changelogs (INSERT, UPDATE, DELETE) for downstream consumption.
- Flink CDC integration: Capture change streams from MySQL, PostgreSQL, MongoDB, and more—write directly to Paimon.
- Snapshot isolation: Multi-stream joins and concurrent writes maintain data consistency.
In our ODS layer migration, we eliminated Kafka by using Flink CDC + Paimon—reducing operational complexity and cost while maintaining minute-level latency.
Streaming Schema Evolution
Paimon supports schema evolution in streaming mode. Add columns, rename fields, or change types without rewriting historical data:
ALTER TABLE user_info ADD COLUMN city STRING;
New and legacy data remain compatible; downstream consumers can adapt incrementally.
Tags and Time Travel
Tags allow naming specific snapshots for reproducibility (e.g., "v1.0-release"). Time travel enables querying historical snapshots:
-- Flink SQL
SELECT * FROM orders /*+ OPTIONS('scan.snapshot-id' = '12345') */;
-- Doris SQL
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5');
LSM and Hierarchical File Reuse
Paimon's LSM structure supports hierarchical file organization and file reuse during compaction. Small files are merged into larger ones; compaction strategies (merge-on-read, copy-on-write, merge-on-write with deletion vectors) balance read and write performance.
Core Use Cases of Apache Paimon
Apache Paimon excels in several practical scenarios. These align with production deployments across industries.
Stream Processing and Streaming Joins
Use Flink to perform streaming joins on Paimon tables. Multiple streams can join on primary keys with consistent results—Paimon's snapshot isolation ensures correct semantics. This enables real-time dimension table lookups and streaming fact-dimension joins without Kafka.
Real-Time Data Warehousing
Build real-time data warehouses with Paimon as the storage layer. Ingest CDC data into ODS tables, then flow through DWD and DWS layers via Flink jobs. Each layer subscribes to the changelog of the upstream layer—data flows automatically with minute-level latency. Eliminate intermediate Kafka topics and simplify architecture.
Paimon as a Message Queue
Paimon can act as a message queue for streaming consumption. In streaming mode, querying a Paimon table returns a changelog stream—similar to consuming from Kafka. Historical data never expires; you can replay from any snapshot. This is particularly useful when you need both streaming consumption and batch backfill from the same table.
Real-Time Analytics Pipelines
Use OLAP engines like Apache Doris, Trino, or Spark to query Paimon tables in real time. Second-level data visibility coexists with streaming endpoints. The unified table format is transparent to BI tools—enable low-latency dashboards without offline ETL.
Ecosystem Integration and Compatibility
Apache Paimon integrates with major compute engines and cloud platforms.
Apache Flink Integration
Apache Flink is Paimon's primary integration. Flink provides:
- Streaming writes and CDC ingestion
- Incremental reads and changelog consumption
- Streaming SQL with full DDL support
The Paimon Flink Quick Start is the recommended entry point for Flink users.
Query Engine Compatibility (Doris, Trino, Spark)
Paimon supports read and write from multiple query engines:
- Apache Doris: Query Paimon tables via catalog; supports incremental snapshot queries.
- Trino / Presto: Read Paimon tables for ad-hoc analytics.
- Apache Spark: Batch and streaming reads/writes; useful for ETL and backfills.
Each engine connects through Paimon's unified catalog interface.
Apache Paimon vs Apache Iceberg
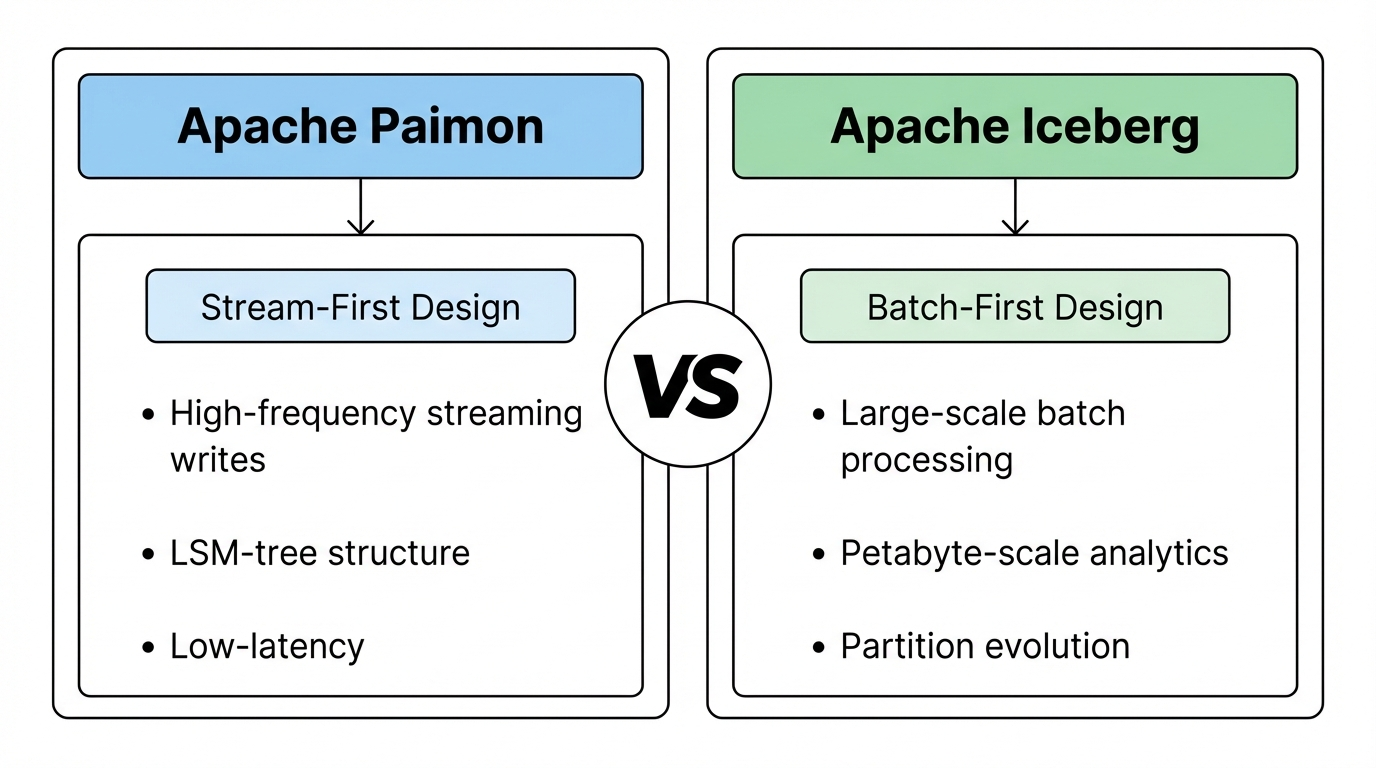 When choosing a lake format, understanding the trade-offs between Paimon and Iceberg is critical. This section provides a detailed comparison—especially important for teams evaluating both options.
When choosing a lake format, understanding the trade-offs between Paimon and Iceberg is critical. This section provides a detailed comparison—especially important for teams evaluating both options.
Design Philosophy: Stream-First vs Batch-First
Apache Paimon is designed stream-first: native support for high-frequency streaming writes, incremental reads, and changelog consumption. The LSM-tree structure and Flink integration prioritize low-latency streaming.
Apache Iceberg is designed batch-first: optimized for large-scale batch processing, with streaming support added later. Its architecture excels at petabyte-scale analytics and complex partition evolution. Note: Iceberg's streaming capabilities continue to improve with each release—this comparison reflects current state and may evolve over time.
Write Path and Update Performance
Paimon achieves minute-level or second-level visibility for streaming writes; Iceberg is better suited for batch-oriented write patterns.
| Aspect | Apache Paimon | Apache Iceberg |
|---|---|---|
| Streaming write | LSM-tree; 1–5 min latency | Batch-oriented; ≥1 hour recommended |
| Update support | Native high-frequency upserts | Supports updates; higher latency |
| Write amplification | Configurable (MOR, COW, MOW) | Copy-on-write or merge-on-read |
Streaming and CDC Capabilities
Paimon natively generates changelogs and supports incremental reads without Kafka or similar systems. Iceberg can achieve similar outcomes but with more configuration and less streamlined streaming semantics.
| Aspect | Apache Paimon | Apache Iceberg |
|---|---|---|
| Incremental read | Native snapshot-based; no external log | Iceberg CDC available; streaming experience inferior |
| Changelog | Native changelog producer | Requires additional configuration |
| Flink integration | Deep, first-class | Good; streaming less mature |
Query and Ecosystem Compatibility
Iceberg has a larger ecosystem and more third-party integrations. Paimon offers deeper Flink integration and compatibility with Iceberg metadata in some scenarios.
| Aspect | Apache Paimon | Apache Iceberg |
|---|---|---|
| Query engines | Flink, Spark, Doris, Trino, Hive | Broader; Spark, Flink, Trino, Presto, etc. |
| Ecosystem maturity | Growing; Flink-centric | More mature; broader vendor support |
| Partition evolution | Moderate | Rich |
When to Choose Apache Paimon
Choose Apache Paimon when:
- Streaming and real-time visibility are primary requirements
- You use Flink for stream processing
- CDC ingestion and incremental reads are core use cases
- You want to reduce or eliminate Kafka for many pipelines
When Apache Iceberg Is a Better Fit
Choose Apache Iceberg when:
- Large-scale batch processing dominates
- Rich partition evolution is critical
- You need broad vendor and ecosystem support
- Your team is Spark-centric with limited Flink expertise
Limitations and Trade-offs of Apache Paimon
While Apache Paimon excels in streaming scenarios, it's important to understand its limitations.
Operational Complexity
LSM-tree compaction and streaming coordinator behavior require tuning. Teams should expect an initial learning period when optimizing for their workload. Compaction strategies (MOR, COW, MOW) affect read and write performance—choose based on your access patterns.
Query Engine Dependencies
Paimon's strongest integration is with Apache Flink. Teams standardized on Spark-only may find Iceberg or Delta Lake more mature for Spark-centric workflows. For OLAP, Doris, Trino, and Spark all support Paimon—but Flink remains the primary write path.
Non-Streaming-Oriented Workloads
For pure batch workloads with no streaming requirements, Iceberg or Parquet may be simpler. Paimon's streaming-first design adds complexity that may not pay off if you never need incremental reads or changelog consumption. Similarly, if sub-second latency is required, Kafka or similar systems may still be necessary.
Frequently Asked Questions About Apache Paimon
How Does Apache Paimon's LSM-Tree Architecture Improve Performance?
Apache Paimon uses an LSM-tree structure for primary key tables. This design improves performance by:
- Buffering writes in memory before flushing to disk, enabling high throughput for inserts and updates
- Enabling incremental compaction that merges small files in the background without blocking writes
- Supporting snapshot isolation so each commit produces a consistent view for readers
The LSM-tree allows Paimon to achieve minute-level or second-level data visibility—significantly faster than batch-oriented formats that require full table rewrites for updates.
Can Apache Paimon Replace Existing Iceberg Deployments?
It depends on your workload. Apache Paimon is a strong replacement when:
- You need better streaming write and incremental read performance
- Flink is your primary compute engine
- CDC and real-time visibility are critical
Apache Iceberg may remain the better choice when:
- You have large-scale batch workloads with complex partition evolution
- Your ecosystem is Spark-centric
- You need the broadest vendor support
Migration from Iceberg to Paimon typically requires data migration and pipeline changes—evaluate the trade-offs before committing.
Apache Paimon and Apache Fluss
Apache Fluss (incubating) and Apache Paimon are complementary projects that together form a tiered streaming lakehouse: Fluss is not a competitor to Paimon but a partner for ultra-low-latency "hot" data.
How they fit together:
- Fluss acts as a columnar streaming storage engine for real-time data with sub-second query latency. It holds the most recent writes in the Fluss cluster.
- Paimon serves as the lakehouse storage for longer-term data with minute-level latency. A tiering service continuously moves data from Fluss into Paimon tables.
When you create a Fluss table with 'table.datalake.enabled' = 'true', Fluss automatically creates a corresponding Paimon table at the same path. The Paimon table gets the same schema plus three system columns—__bucket, __offset, and __timestamp—so Fluss clients can consume data from Paimon in a streaming way (e.g., seek by bucket, offset, or timestamp). For primary key tables, changelogs are written in Paimon format, enabling stream-based consumption via Paimon APIs. The table.datalake.freshness option controls how often data is tiered from Fluss to Paimon (default: 3 minutes).
Query options: You can query a Paimon-only view (better analytics performance, minute-level freshness) or a combined Fluss + Paimon view (second-level latency with unified access). Data tiered to Paimon is stored as a standard Paimon table, so any engine that supports Paimon (e.g., Flink, Spark, StarRocks, Doris) can read it. For details, see Paimon integration in Apache Fluss.
What's Next in Paimon
The Apache Paimon community is actively evolving the format to address emerging use cases. Two notable improvements under development are multimodal data support and global indexing.
Multimodal Data Support (PIP-35)
As AI and analytics workloads increasingly combine structured data with multimedia—images, audio, video, and embedding vectors—Paimon is introducing a Blob storage\mechanism. Instead of embedding large binary data in Parquet files (which risks OOM and format complexity) or storing files externally (which fragments metadata and causes excessive I/O), Paimon proposes:
- Independent blob file format: Blob columns are stored in dedicated blob files, while Parquet holds all structured and auxiliary fields.
- Data Evolution integration: Leveraging the existing Data Evolution mode, blob columns can be split out and managed separately, with decoupled compaction.
- New BlobType: A
BlobTypein the Java API andblob-fieldoption in Flink/Spark SQL allow tables to store multimedia data with lazy, streaming reads.
This design targets high-throughput writes and low-latency reads for mixed workloads of small and large multimodal files—critical for AI and big data pipelines. See PIP-35: Introduce Blob to store multimodal data for details.
Global Index (PIP-38)
Traditional file-level indexes can fragment in distributed scenarios and limit query flexibility. Paimon is proposing a Global Index that:
- Unified metadata management: Manages indexes at the table level rather than per-file, reducing fragmentation.
- Optimized query patterns: Improves performance for field-equivalence queries, range queries, and complex filtering.
- Bitmap index type: Extends the existing Index Manifest (e.g., DELETION_VECTORS, HASH) with a BITMAP type for efficient lookups.
- Row-tracking dependency: Requires
row-tracking.enabledto maintain the mapping between index fields and global row IDs.
Build, drop, and query through the global index via stored procedures and session settings. See PIP-38: Introduce Global Index for Paimon Table for the full proposal.
Summary: Is Apache Paimon the Right Streaming Lake Format for You?
Apache Paimon is a high-performance table format built for real-time data lakes. It supports ACID, schema evolution, incremental reading, and unified stream-batch processing. Deep integration with Flink, Spark, Doris, and Trino makes it suitable for real-time data warehousing, CDC scenarios, and streaming ETL.
Choose Apache Paimon when streaming and real-time visibility are core requirements. The ability to achieve minute-level data visibility without Kafka—while maintaining ACID and schema evolution—can significantly simplify your architecture.
Consider alternatives (Iceberg, Hudi, Delta Lake) when batch workloads dominate, when you need the broadest ecosystem support, or when your team lacks Flink expertise.
Start with the Apache Paimon official documentation and the Flink quick start to explore further. The project's active community and production adoption at major enterprises make it a compelling option for streaming lakehouse architectures.
