


Apache Iceberg is a revolutionary open-source table format designed for large-scale data analytics. Originally developed by Netflix and now an Apache project, Iceberg addresses critical limitations of traditional Hive table formats. This guide goes beyond the typical feature list—focusing on real-world use cases where Iceberg delivers transformative value, including building high-availability lakehouse platforms, enabling multi-engine collaboration, and simplifying compliance governance. Whether you're evaluating Iceberg for your organization or planning a migration, you'll find practical insights from hands-on experience.
What is Apache Iceberg?
Apache Iceberg is an open-source large-scale analytical table format originally developed by Netflix and now maintained by the Apache Software Foundation. Designed to address the limitations of traditional Hive table formats in consistency, performance, and metadata management, Apache Iceberg has become a cornerstone of modern lakehouse architectures.
After working with various data lake technologies over the years, I've found that the real question isn't "what features does Iceberg have?" but rather "where does Iceberg actually make a difference?" This guide covers the technical fundamentals, but I'll focus especially on the practical use cases where I've seen Iceberg deliver transformative value—from building high-availability lakehouse platforms to enabling true multi-engine collaboration. If you're evaluating whether Iceberg is right for your organization, start with the use cases section—that's where theory meets reality.
How Does Apache Iceberg Work
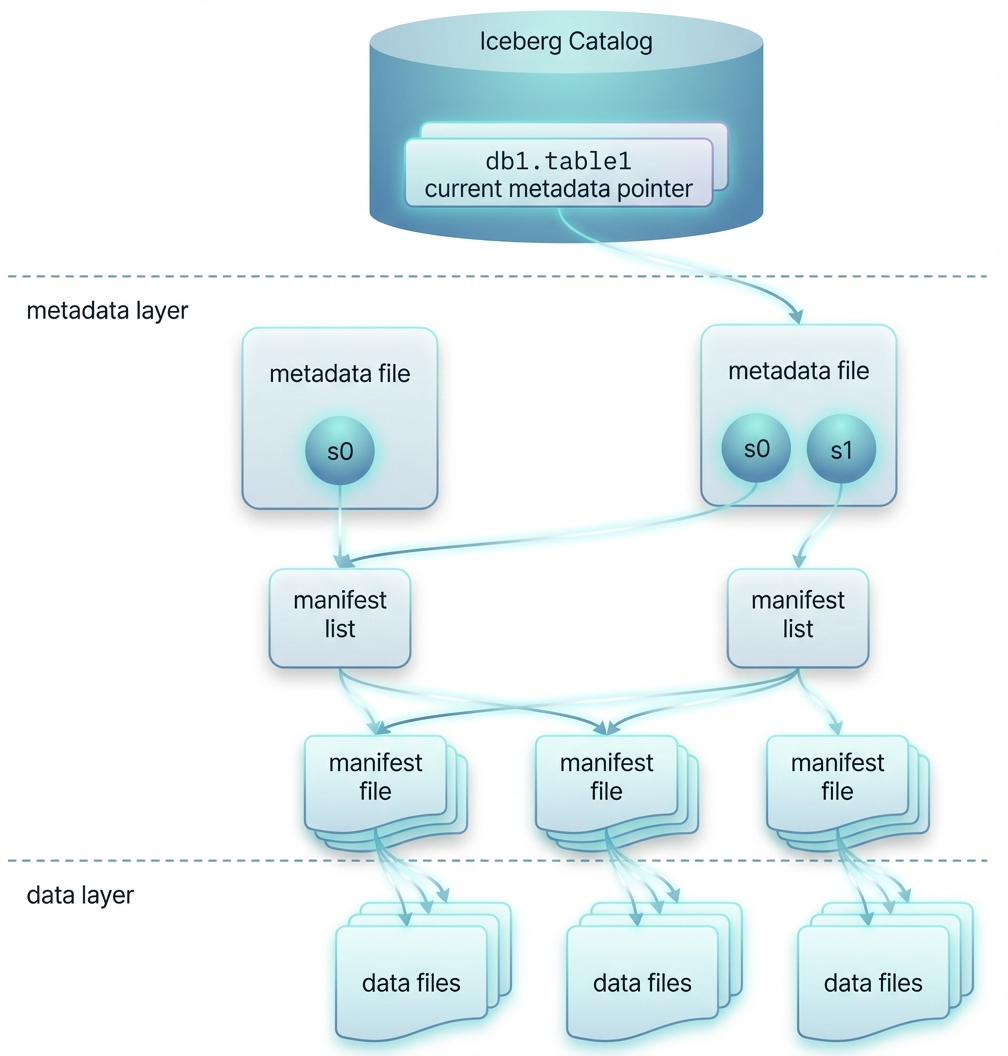 Apache Iceberg implements a sophisticated three-layer architecture that separates metadata management from data storage, enabling efficient query planning and file-level pruning without requiring full table scans.
Apache Iceberg implements a sophisticated three-layer architecture that separates metadata management from data storage, enabling efficient query planning and file-level pruning without requiring full table scans.
Catalog Layer
The Catalog Layer stores the current metadata file pointer for each Apache Iceberg table. This layer supports atomic updates of metadata pointers, ensuring transaction consistency. You can choose from various catalog implementations including Hive Metastore, AWS Glue, Nessie, Hadoop FS, or the REST Catalog.
The Iceberg REST Catalog is a Catalog implementation provided through HTTP REST API, compliant with the Iceberg OpenAPI specification. Products implementing this include Apache Polaris, Gravitino, Tabular, and Unity Catalog. The REST Catalog brings several advantages:
- Lightweight client requiring only HTTP calls
- Server can use any language to implement abstraction and governance logic
- Easier support for multi-language, multi-engine Catalog access, reducing deployment complexity
- Supports view management for unified metadata access, suitable for data governance
Compared to HiveCatalog and GlueCatalog, this approach moves "atomicity, schema management, transaction conflict handling" and other logic down to a dedicated service layer, allowing clients to focus more on query planning.
Metadata Layer
The Metadata Layer in Apache Iceberg includes three key components:
- Metadata file: JSON format containing table schema, partition specification, current/historical snapshot lists, and pointers to manifest lists. New metadata files are generated after each change operation.
- Manifest list: Avro format listing all manifest file paths and summary information under a snapshot, enabling efficient snapshot-level filtering.
- Manifest file: Avro format listing specific data file and delete file paths, partition values, and statistical information (such as min/max) to assist with file-level pruning optimization.
Data Layer
The Data Layer stores actual data files in Parquet, ORC, or Avro formats, as well as delete files for soft deletion (positional/equality/delta vectors in V2, deletion vectors in V3). Apache Iceberg tables are tightly integrated with physical storage systems such as HDFS, Amazon S3, Azure ADLS, and Google Cloud Storage.
This multi-level metadata architecture allows Apache Iceberg to perform efficient query planning: queries first access the Catalog to get the latest metadata file path, then use manifest lists and manifest files to prune irrelevant data files before any actual data scanning occurs, significantly improving query performance.
Key Features of Apache Iceberg
 Apache Iceberg provides a comprehensive set of features that address the limitations of traditional data lake table formats. The key features of Apache Iceberg include:
Apache Iceberg provides a comprehensive set of features that address the limitations of traditional data lake table formats. The key features of Apache Iceberg include:
ACID Transactions
Apache Iceberg provides full ACID (Atomicity, Consistency, Isolation, Durability) transaction support using optimistic concurrency control. This makes Apache Iceberg tables suitable for multi-user concurrent write scenarios, ensuring data consistency even when multiple engines are writing to the same table simultaneously.
Schema Evolution
Apache Iceberg supports comprehensive schema evolution operations including adding, deleting, renaming, type widening, and column reordering—all without rewriting underlying data files. These operations are executed based on metadata changes, making schema evolution fast and cost-effective.
Partition Evolution and Hidden Partitioning
Apache Iceberg supports partition evolution, allowing you to change partition specifications over time. After a partition spec update, old data retains its original layout while new writes use the new layout, and queries can automatically prune across multiple specs.
Hidden partitioning is a key innovation in Apache Iceberg: queries don't need to specify additional partition columns. Iceberg automatically identifies and skips irrelevant files based on partition values, simplifying query writing while maintaining performance benefits.
Time Travel and Rollback
Apache Iceberg enables querying historical table states through snapshot ID or timestamp. This time travel capability makes error rollback, auditing, and data reproduction significantly more convenient. You can easily query data as it existed at any point in time or roll back to previous snapshots.
Data Compaction
Apache Iceberg supports bin-packing and sorting rewrite strategies to achieve file packing and organization. Regular compaction optimizes query efficiency and storage usage, maintaining performance as data grows.
Iceberg Version 2 and Version 3
As Apache Iceberg continues to evolve, format versions have been continuously upgraded to meet complex modern data scenario needs:
Version 2 (V2) introduced:
- Row-level deletion mechanisms (position delete and equality delete files)
- Support for incremental updates
- Enhanced ACID capabilities for near real-time scenarios
Version 3 (V3)** builds upon V2 with:
- Deletion Vectors: Binary bitmaps to record row deletion status, more efficient during reads than V2's file-based deletion
- Row Lineage: Each row equipped with unique ID and change sequence number, facilitating incremental processing and auditing
- Enhanced data types:
nanosecond timestamp(tz),variant(semi-structured data),geometryandgeography(geospatial types) - Default column values: Table-level
initial-defaultandwrite-defaultproperties for automatic value assignment - Multi-argument transforms: Support for complex multi-column partition and sort combinations
V3 targets high-throughput, low-latency updates, audit tracing, diversified types, and complex partitioning scenarios, making Apache Iceberg suitable for streaming, spatiotemporal analysis, and semi-structured data processing.
Iceberg Version 4 (In Development)
The community is actively developing Version 4 (V4) with a focus on improving real-time processing capabilities. Key planned features include single-file commits to reduce metadata overhead, Parquet-based metadata storage for better compression, native index support, and a formal caching model. These improvements will make Apache Iceberg more efficient for streaming and high-frequency update scenarios.
Benefits of Using Apache Iceberg
Apache Iceberg delivers significant advantages over traditional data lake table formats. Here's a quick summary—I'll dive deeper into practical implications in the Use Cases section below.
Superior Query Performance
Multi-level metadata filtering enables file-level pruning without full table scans. Query planning completes on a single node, achieving low-latency planning phases.
Multi-Engine Collaboration
A truly open, vendor lock-in free format. Use Spark for ETL, Flink for streaming, Trino for interactive queries, and Doris for low-latency analytics—all on the same tables simultaneously.
Flexible Schema and Partition Management
Schema and partition evolution through metadata-only operations—no expensive data rewrites required.
Enhanced Data Governance
Time travel and snapshot capabilities enable compliance (GDPR, financial auditing) and easy rollback without complex backup procedures.
Cost Optimization
File-level pruning, hidden partitioning, and data compaction reduce storage and compute costs.
Common Use Cases of Apache Iceberg
In my experience working with data lake architectures over the past few years, Apache Iceberg has proven to be a game-changer for specific scenarios. While Iceberg offers many technical features, understanding where it truly shines is crucial for making the right architectural decisions. Here are the use cases where I've seen Apache Iceberg deliver the most value—and some honest insights from real-world implementations.
Building High-Availability Lakehouse Data Platforms
This is arguably the most impactful use case for Apache Iceberg, and it's where I recommend most teams start their Iceberg journey.
In traditional data lakes using Hive table formats, directory scanning and metadata synchronization often become performance bottlenecks. When we managed a data lake with over 500 tables and petabytes of data, the Hive Metastore became our constant headache—slow partition discovery, inconsistent metadata states during concurrent writes, and painful recovery after failures.
After migrating to Apache Iceberg, the transformation was dramatic:
- Metadata operations became 10-50x faster: Instead of scanning directories with millions of files, Iceberg reads compact manifest files. What used to take minutes now takes seconds.
- Concurrent write conflicts dropped to near zero: Iceberg's optimistic concurrency control handles multi-engine writes gracefully. We run Spark batch jobs and Flink streaming jobs writing to the same tables without coordination headaches.
- Failure recovery became trivial: With atomic commits and snapshot isolation, a failed job simply doesn't affect the table state. No more manual cleanup of partial writes.
Large companies like Airbnb and Netflix have documented similar experiences. After migrating from HDFS to S3, Airbnb improved metadata scheduling efficiency through Apache Iceberg, reducing pressure on Hive Metastore while achieving significant performance improvements.
My recommendation: If you're struggling with Hive Metastore performance, partition management complexity, or concurrent write issues, migrating to Iceberg should be your top priority. The ROI is immediate and substantial.
Multi-Engine Collaboration: The Real Power of Open Formats
One thing I've learned the hard way: in any organization beyond a startup, you will inevitably have multiple teams using different tools. Data engineers love Spark, data scientists want Python notebooks, BI teams need SQL tools, and real-time applications require low-latency engines. Apache Iceberg enables truly unified data platforms where different teams and tools can collaborate seamlessly—and this isn't just marketing speak. In one project, we had:
- ETL team using Apache Spark for nightly batch processing, writing 50+ million records daily
- Data science team reading the same tables via PyIceberg in Jupyter notebooks for model training
- BI team running ad-hoc queries through Trino for executive dashboards
- Operations team using Apache Doris for real-time monitoring with sub-second query latency
All of this worked without any data synchronization, ETL pipelines between systems, or complex orchestration. The table is the single source of truth. The key insight here is that Apache Iceberg's true value isn't just "supporting multiple engines"—it's eliminating the data copies, sync jobs, and coordination overhead that typically plague multi-tool environments. In our case, we estimated this saved us 40+ hours of engineering time per week that would have been spent on data pipeline maintenance.
A practical tip: Start with a shared catalog (I recommend REST Catalog for new deployments). Having a unified catalog is essential for multi-engine collaboration—without it, you'll spend more time on catalog synchronization than on actual data work.
Compliance Governance and Data Auditing
If your organization operates in regulated industries (finance, healthcare, e-commerce with GDPR requirements), Apache Iceberg's time travel and audit capabilities aren't just nice-to-have—they're essential.
In scenarios with strict regulatory requirements (such as GDPR, financial auditing), Apache Iceberg's time travel and DELETE operations enable precise deletion of sensitive data with complete audit trails. Here's a real example of how we handle GDPR deletion requests:
-- Step 1: Record the current snapshot before deletion for audit
SELECT snapshot_id FROM table$snapshots ORDER BY committed_at DESC LIMIT 1;
-- Step 2: Delete user data as required by GDPR
DELETE FROM user_events WHERE user_id = 'user_to_forget';
-- Step 3: Verify deletion was successful
SELECT COUNT(*) FROM user_events WHERE user_id = 'user_to_forget'; -- Should return 0
-- Step 4: For compliance audit, we can still prove what was deleted
SELECT COUNT(*) FROM user_events
FOR VERSION AS OF [previous_snapshot_id]
WHERE user_id = 'user_to_forget'; -- Shows original count
This pattern—delete the data but maintain audit trail of what was deleted—has been invaluable for compliance reviews. Auditors can verify both that we deleted what was required AND that we have proper records of the deletion.
An important caveat: Time travel queries show historical data, so make sure your snapshot expiration policies align with your compliance requirements. We typically keep 90 days of snapshots for audit purposes, then expire older ones to manage storage costs.
Real-Time Analytics with Batch Processing (Lambda Architecture Made Simple)
Apache Iceberg V3's deletion vectors and row lineage make it suitable for near real-time analytics scenarios where you need to combine streaming updates with batch processing. The classic Lambda architecture—maintaining separate batch and speed layers—has always been operationally painful. With Apache Iceberg, we've found a much simpler approach:
- Flink writes streaming updates to Iceberg tables with small commit intervals (1-5 minutes)
- Spark runs nightly compaction and quality checks on the same tables
- Doris provides real-time queries with sub-second latency
The format supports incremental updates while maintaining query performance through efficient deletion tracking. This isn't quite "real-time" in the millisecond sense—but for analytics use cases where 1-5 minute latency is acceptable, it's a significant simplification over maintaining separate systems.
Data Lake Modernization: A Practical Migration Path
Organizations migrating from traditional data lakes to modern lakehouse architectures choose Apache Iceberg for its open format, multi-engine support, and superior performance. If you're sitting on a legacy Hive-based data lake, here's the migration strategy that has worked well for us:
- Start with read-heavy tables first: Migrate tables that are frequently queried but rarely written. This gives you immediate query performance benefits with minimal risk.
- Use Iceberg's migration procedures:
-- Migrate existing Parquet/Hive table to Iceberg (Spark syntax)
CALL system.migrate('database.table_name');
This is a metadata-only operation—no data rewriting required. 3. Validate before switching production workloads: Run parallel queries against both old and new tables to verify correctness. 4. Migrate write pipelines last: Once reads are validated, switch write jobs to target Iceberg tables.
The format provides a migration path that preserves existing data while adding modern capabilities. Most importantly, you can do this incrementally—there's no need for a "big bang" migration that risks your entire data platform.
Getting Started with Apache Iceberg
Getting started with Apache Iceberg is straightforward when you understand the prerequisites and setup requirements. This section provides a practical guide to help you begin using Apache Iceberg in your data platform:
Prerequisites
Before getting started with Apache Iceberg, you'll need:
- A data storage system (S3, HDFS, Azure ADLS, or GCS)
- A catalog service (Hive Metastore, AWS Glue, or REST Catalog)
- A query engine that supports Apache Iceberg (Spark, Flink, Trino, Presto, or Doris)
Using Apache Iceberg with Apache Spark
Here's a complete example of using Apache Iceberg with Apache Spark:
-- Configure Spark to use Hive Metastore as Iceberg catalog
SET spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog;
-- Create an Apache Iceberg table
CREATE TABLE spark_catalog.db1.logs (
id BIGINT,
ts TIMESTAMP,
level STRING
)
USING iceberg
PARTITIONED BY (days(ts));
-- Insert data into the Apache Iceberg table
INSERT INTO db1.logs VALUES
(1, TIMESTAMP '2025-07-01 12:00:00', 'INFO'),
(2, TIMESTAMP '2025-07-01 13:00:00', 'ERROR');
-- Query the Apache Iceberg table
SELECT * FROM db1.logs;
-- Time travel query using Apache Iceberg
SELECT * FROM db1.logs FOR TIMESTAMP AS OF TIMESTAMP '2025-07-01 12:30:00';
Using Apache Iceberg with Apache Doris
Apache Iceberg integrates seamlessly with Apache Doris for interactive analytics:
-- Create Apache Iceberg catalog in Doris
CREATE CATALOG iceberg_catalog PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'warehouse' = 's3://warehouse/',
'uri' = 'http://rest:8181',
's3.access_key' = 'admin',
's3.secret_key' = 'password',
's3.endpoint' = 'http://minio:9000'
);
-- Switch to the Apache Iceberg catalog and create database
SWITCH iceberg_catalog;
CREATE DATABASE nyc;
-- Create an Apache Iceberg table
CREATE TABLE iceberg.nyc.taxis (
vendor_id BIGINT,
trip_id BIGINT,
trip_distance FLOAT,
fare_amount DOUBLE,
store_and_fwd_flag STRING,
ts DATETIME
)
PARTITION BY LIST (vendor_id, DAY(ts))
PROPERTIES (
'compression-codec' = 'zstd',
'write-format' = 'parquet'
);
-- Insert data into the Apache Iceberg table
INSERT INTO iceberg.nyc.taxis VALUES
(1, 1000371, 1.8, 15.32, 'N', '2024-01-01 09:15:23'),
(2, 1000372, 2.5, 22.15, 'N', '2024-01-02 12:10:11');
-- Query the Apache Iceberg table
SELECT * FROM iceberg.nyc.taxis;
-- View snapshots in Apache Iceberg
SELECT * FROM iceberg.nyc.taxis$snapshots;
-- Time travel query using Apache Iceberg
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 6834769222601914216;
Through Spark + Doris integration, you can implement a unified lakehouse architecture with Apache Iceberg: Spark handles ETL and batch processing, while Doris handles interactive query analytics. Both engines share Apache Iceberg tables based on the same metadata, compatible with schema evolution, time travel, secure transactions, and other capabilities.
Best Practices for Getting Started
- Start with a pilot project: Choose a non-critical dataset to test Apache Iceberg capabilities
- Choose the right catalog: For new deployments, consider REST Catalog for better multi-engine support
- Plan your partition strategy: Leverage hidden partitioning to simplify queries while maintaining performance
- Set up compaction schedules: Regular compaction maintains query performance as data grows
- Monitor metadata growth: Keep an eye on metadata file sizes and implement cleanup strategies
Limitations and Challenges of Apache Iceberg
While Apache Iceberg provides many advantages, it's important to understand its limitations:
Real-Time Write Performance
Apache Iceberg is optimized for large-scale batch analytics. For high-frequency, row-by-row real-time writes, it generates delete files (V2) or frequent metadata file writes, which can cause performance degradation and metadata bloat. In such scenarios, regular compaction optimization is essential, and you may need to consider alternative formats like Apache Paimon for streaming-heavy workloads.
Learning Curve
Migrating from traditional Hive tables to Apache Iceberg requires understanding new concepts like snapshots, manifests, and hidden partitioning. Teams need training and time to adapt to the new operational model.
Engine Feature Parity
While Apache Iceberg supports many engines, not all features are equally supported across engines. Spark and Flink have complete write and schema evolution capabilities, while some lightweight query engines (like DuckDB or ClickHouse) may only support reading with incomplete delete functionality.
Metadata Management Overhead
As tables grow and accumulate many snapshots, metadata files can become large. Without proper maintenance (snapshot expiration, metadata cleanup), this can impact query planning performance. Regular metadata management is necessary for optimal performance.
Version Compatibility
When using Apache Iceberg V3 features (like deletion vectors or row lineage), ensure all accessing engines support these features. Mixing engines with different version support can lead to compatibility issues.
Frequently Asked Questions About Apache Iceberg
Which Engines Can Access Apache Iceberg?
Apache Iceberg is a truly open-source standard with broad engine support:
| Category | Engines |
|---|---|
| Full write/read support | Spark, Flink, Doris, Trino, Presto, Hive, Impala, Dremio |
| Cloud services | Snowflake, Databricks, AWS Athena, Google BigQuery, VeloDB |
How Does Apache Iceberg Compare to Delta Lake, Apache Hudi, and Paimon?
Based on my experience, here's how to choose between these formats:
| Format | Best For | My Take |
|---|---|---|
| Apache Iceberg | Multi-engine lakehouse, large-scale analytics | Best choice for open, vendor-neutral architectures |
| Delta Lake | Databricks/Spark-heavy environments | Great if you're all-in on Databricks ecosystem |
| Apache Hudi | Real-time upserts, CDC workloads | Strongest for high-frequency update scenarios |
| Apache Paimon | Flink-native streaming | Best fit for Flink-centric stream-batch unification |
If you're unsure, start with Apache Iceberg—it has the broadest engine support and the most active open-source community. You can always specialize later if your use case demands it.
Using Apache Iceberg with Doris
Apache Iceberg integrates seamlessly with Apache Doris to provide a unified lakehouse analytics platform. Doris's high-performance columnar storage engine combined with Apache Iceberg's table format creates a powerful solution for interactive analytics on large-scale data lakes.
Why Use Apache Doris for Iceberg Analytics
Apache Iceberg provides the open table format with ACID transactions, schema evolution, and time travel. But to unlock its full potential for interactive analytics, you need a powerful query engine—and that's where Apache Doris shines:
- Unified Analytics Engine: Doris isn't just an Iceberg reader—it's a federated query engine. You can JOIN Apache Iceberg tables with data from MySQL, Hive, Elasticsearch, and other sources in a single query. This eliminates the need for complex ETL pipelines to consolidate data before analysis.
- High-Performance Real-Time Analytics: Doris delivers sub-second query latency on large-scale Apache Iceberg tables through vectorized execution, intelligent caching, and advanced query optimization. Whether you're running ad-hoc queries on billions of rows or powering real-time dashboards, Doris provides the performance that interactive analytics demands.
- Multi-Catalog Integration: Doris supports connecting to multiple catalogs simultaneously—Iceberg REST Catalog, Hive Metastore, AWS Glue, and more. This means you can manage and analyze data across different lakehouse environments from a single Doris cluster, providing unified data governance without data migration.
Integration Architecture
When using Apache Iceberg with Doris:
- Data ingestion: Use Spark, Flink, or other engines to write data to Apache Iceberg tables
- Catalog integration: Configure Doris to connect to your Apache Iceberg catalog (REST Catalog, Hive Metastore, or AWS Glue)
- Query execution: Doris reads Apache Iceberg metadata to optimize queries, performing file-level pruning before data scanning
- Performance optimization: Leverage Doris's vectorized execution engine with Apache Iceberg's efficient metadata structure
This combination provides the best of both worlds: Apache Iceberg's open format and governance capabilities with Doris's high-performance query engine, creating an ideal solution for modern data lakehouse architectures.
Conclusion
After working with Apache Iceberg across multiple production environments, my takeaway is this: Iceberg isn't just a better Hive table format—it's a fundamental shift in how we think about data lake architecture.
If I had to recommend just one reason to adopt Iceberg, it would be multi-engine collaboration. The ability to have Spark, Flink, Trino, and Doris all working on the same tables—without synchronization overhead, without data copies, without coordination nightmares—is transformative for organizations that have outgrown single-engine architectures.
That said, Iceberg isn't perfect for every use case. If you need sub-second row-level updates or are deeply invested in Flink streaming, you might find Apache Paimon or Hudi better suited to your needs. But for the vast majority of analytical workloads—especially those requiring open formats, compliance governance, and operational simplicity—Apache Iceberg is my default recommendation.
The best way to get started? Pick a read-heavy table in your existing data lake, migrate it to Iceberg using the simple migration procedure, and see the difference yourself. The proof is in the performance—and once you experience the improvement, you'll want to migrate everything else.
