



Xiaomi is a Fortune 500 tech company and the world's third-largest smartphone maker by market share, following Apple and Samsung. Beyond smartphones, Xiaomi also offers consumer IoT devices, electric vehicles, and other services in 100+ countries. With a global operation of this scale, Xiaomi generates massive volumes of data that power everything from product decisions to real-time operations.
Xiaomi first adopted Apache Doris in 2019 as one of several OLAP engines in its analytics stack. In six years, Apache Doris went from one option among many OLAP engines to the core of Xiaomi's Unified Data Platform.
Today, Xiaomi runs 40+ Apache Doris clusters, managing petabytes of data and serving 50 million queries per day, growing deployment footprint 80% year-over-year.
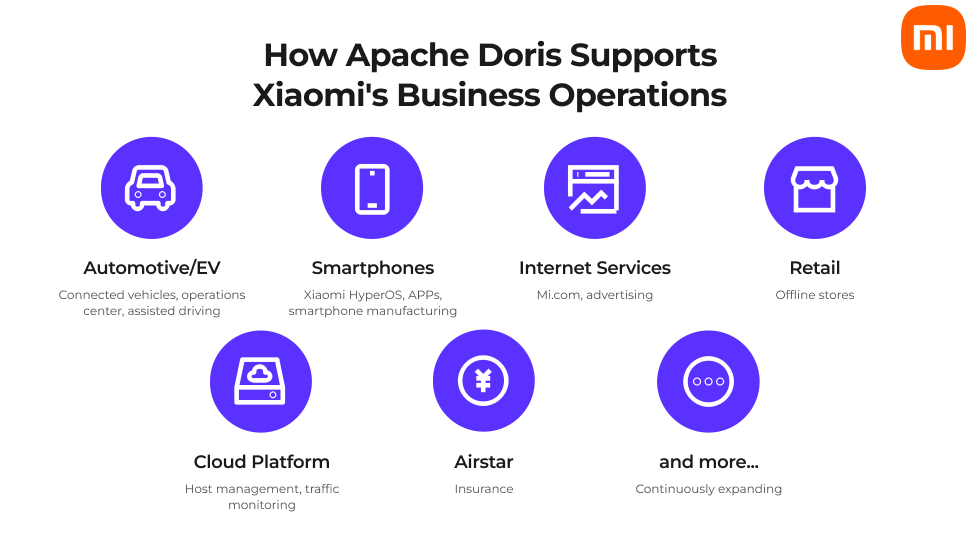
Xiaomi's early analytics architecture was fragmented: multiple OLAP engines, redundant data across systems, complex ETL pipelines bridging the data lake and OLAP layer. Bringing a new compute cluster online often took more than a week. As Xiaomi's business scale rapidly expanded, the complex data management operations became untenable.
Xiaomi was able to consolidate its analytic stack by leveraging the Lakehouse architecture that Apache Doris brings with storage, compute, and Catalog separation, democratizing data and metadata, while supporting a wide range of OLAP workloads.
In this article, we will walk through why Xiaomi's team chose Apache Doris and how its usage has expanded over the years, and share practical lessons from running Doris at this scale, including details on optimizing the query pipeline, resource management, and operations.
Challenges with the Multi-Engine Model
In Xiaomi's early OLAP architecture, the offline data warehouse was considered the "internal warehouse," while the OLAP service layer was the "external warehouse." Data flow between offline data and OLAP must rely on Flink and Spark. During this process, the team encountered several pain points:
1. Cross-System Data Integration
Data was extracted from the offline internal warehouse into Apache Doris via Flink or Spark, resulting in data flows between multiple systems. This pattern brought several challenges:
-
Data redundancy: The same data is stored across multiple systems, increasing costs.
-
Inconsistent metrics: Different processing logic across systems led to discrepancies in results.
-
Difficult troubleshooting: When BI dashboard data showed inconsistencies, debugging required tracing across multiple systems.
-
Heavy development burden: Business teams had to maintain their own ETL pipelines and multiple query interfaces.
Take the advertising business as an example. Its data pipeline involved multiple storage systems (e.g., Iceberg, Druid) and sync tasks. Analysts had to choose different systems based on query granularity, making it significantly harder to operate. On the development side, engineers had to build custom logic for different data pipelines and duplicate dashboard work across multiple systems, resulting in redundant effort, long development cycles, and higher overall costs.
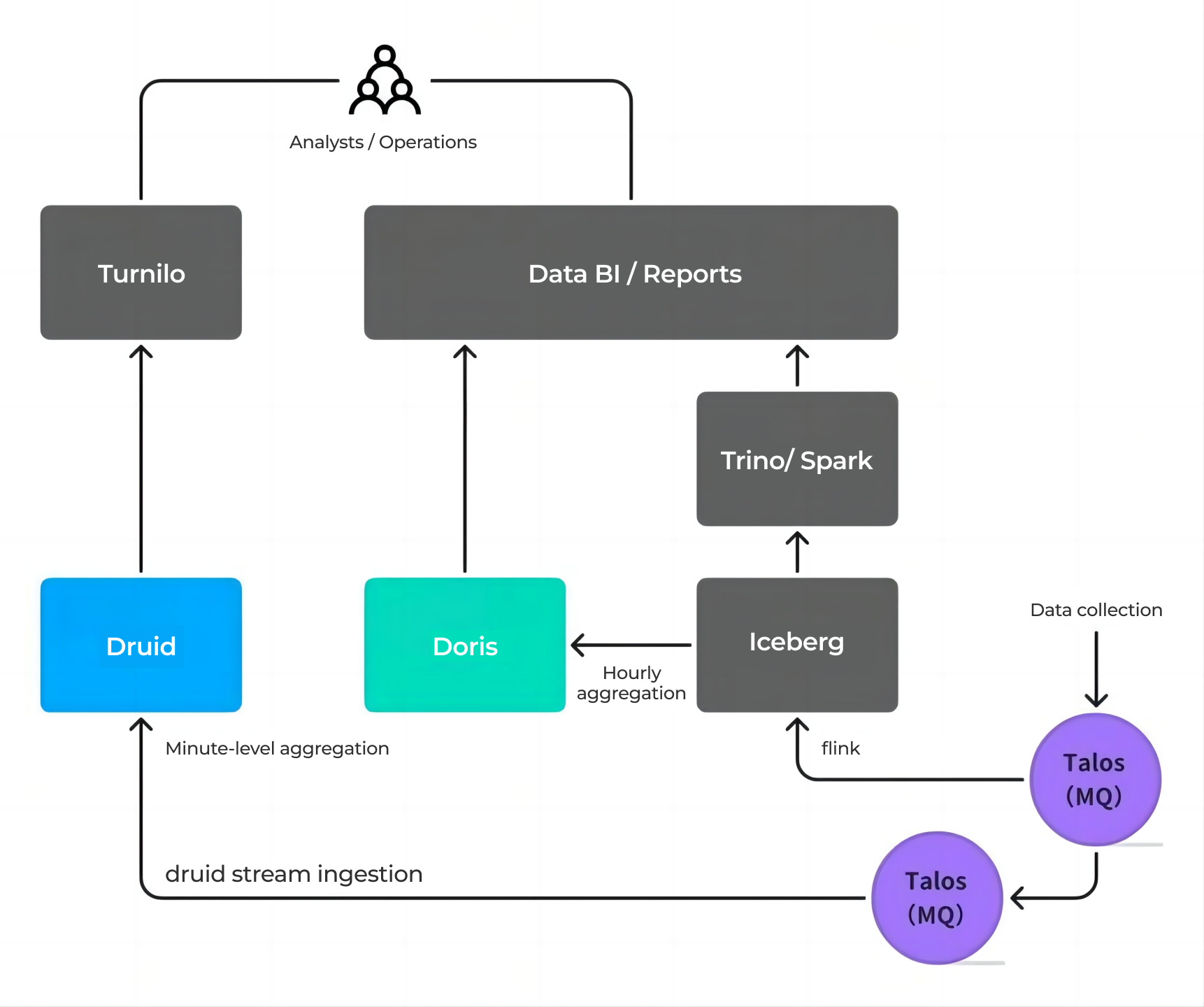
2. Limitations of the Coupled Compute-Storage Architecture
A. High Availability and Disaster Recovery
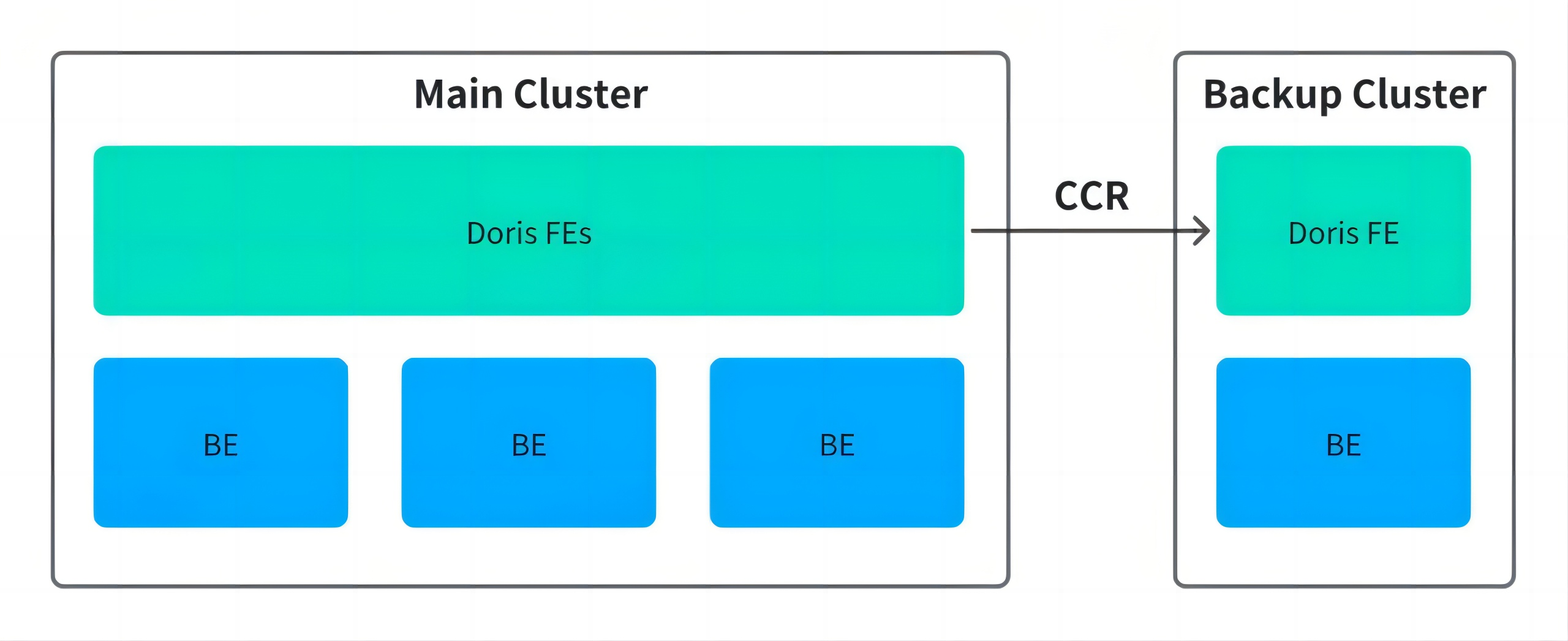
In 2023, a data center fire incident exposed Xiaomi to the fragility of the coupled compute-storage architecture. Although the data was eventually recovered, the incident prompted the team to reassess its high-availability strategy. The team operated on the Doris 2.x version and it evaluated two approaches:
- Cross-Cluster Replication (CCR): Required a newer version of Doris, lacked production validation, involved complex primary-standby switchover, required clients to connect to both clusters, and had long recovery times.
- Availability Zones Replica Distribution: Using Resource Groups to spread replicas across data centers. This avoided single points of failure but introduced performance overhead from reads and writes across data centers.
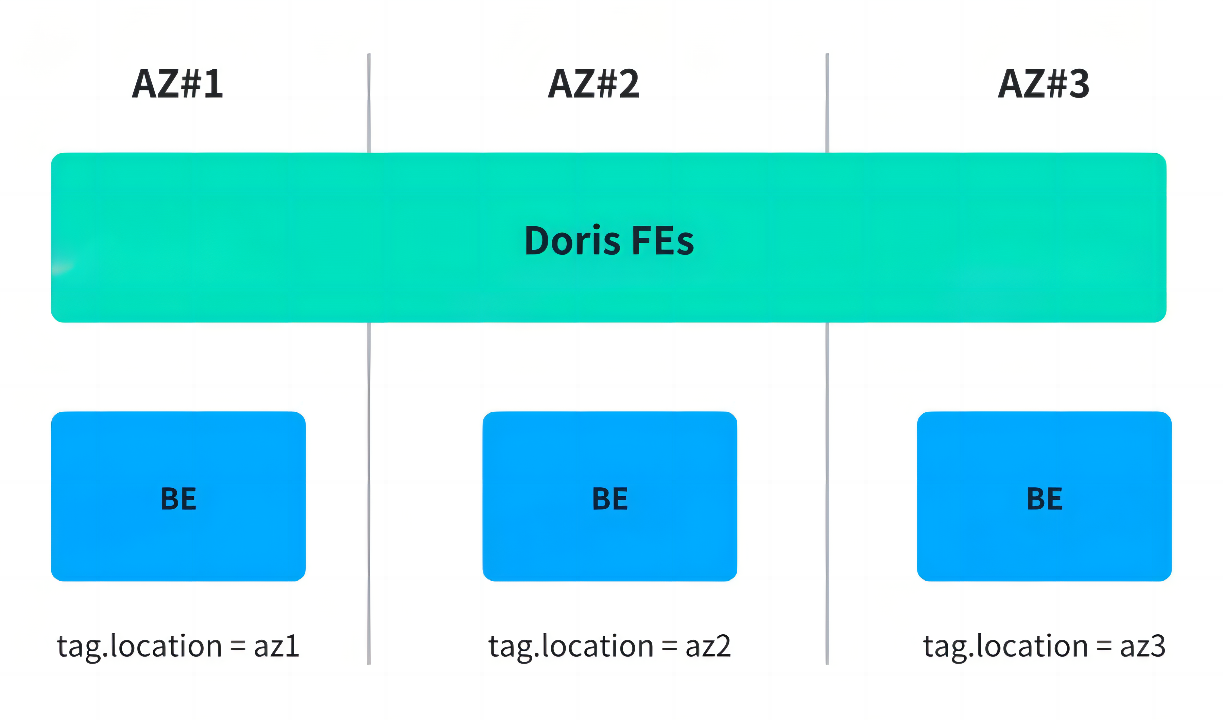
The team ultimately adopted the latter as a temporary solution, but it still didn't fundamentally resolve the tension between cost and availability.
B. Low Resource Utilization
With physical machine deployments, building a highly available Apache Doris cluster requires at least 3 FE + 3 BE nodes. For small-to-medium workloads, this configuration far exceeded actual needs, leading to significant resource waste. Creating independent clusters for each small business would lead to cluster sprawl and operational burden. Sharing clusters, on the other hand, introduced resource contention, poor isolation, and unclear cost attribution.
These issues were not resolved until the team adopted Apache Doris 3.0, which introduced a compute-storage separation architecture that addressed both high availability and resource elasticity. We'll cover this in detail in the next section.
3. Low Cluster Operations Efficiency
The coupled compute-storage architecture relies on a legacy deployment process that uses physical machines and manual setups. It typically took over a week from resource request to bringing a cluster online. As Xiaomi's business demand grew rapidly, this model could no longer meet its delivery requirements.
Journey from Engine to Data Platform
In its early days, Xiaomi's data stack was a patchwork of OLAP engines and data systems running in parallel, including Apache Kylin, Druid, Apache Kudu, Spark, and Trino. This multi-engine, multi-system setup created real problems: data pipelines were fragmented across systems, query experiences were inconsistent, and data could fall out of sync between engines.
On the development side, teams had to build and maintain separate data pipelines for different throughput needs, duplicate dashboard work across systems, and troubleshoot issues across multiple platforms.
Xiaomi first adopted Apache Doris in 2019 as one of its many OLAP engines. As Apache Doris proved its query performance and compatibility with the broader ecosystem, Xiaomi expanded its use.
Over the years, Apache Doris gradually consolidated Xiaomi's scattered OLAP workloads and emerged as the core analytical engine, working alongside Spark, Trino, Iceberg, and Paimon in a simplified architecture.
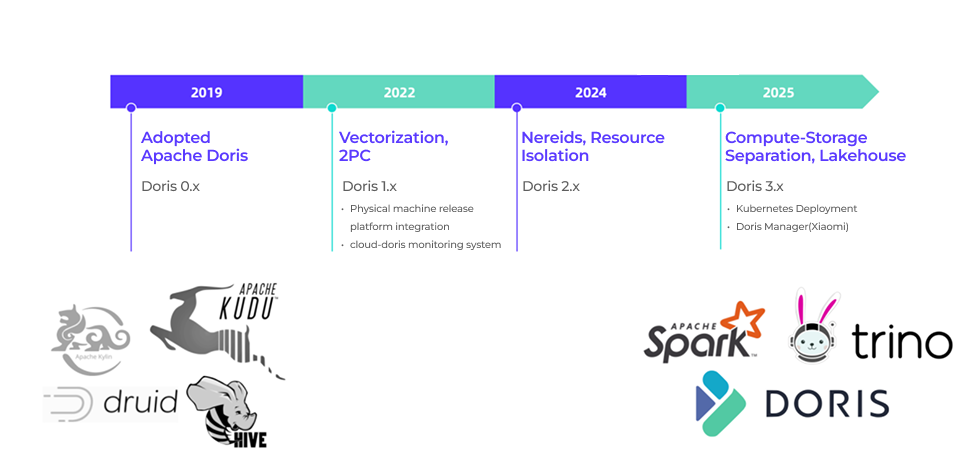
By 2022, Apache Doris had become a key part of Xiaomi's internal infrastructure: clusters were automatically deployed and managed on physical machines through an internal release platform, and integrated into the internal monitoring system to ensure observability and stability.
In 2025, Xiaomi officially upgraded to Apache Doris 3.0, which brought better lakehouse integration and compute-storage separation capabilities. Doris 3.0 now runs alongside version 2.1. On the management side, Xiaomi made significant changes based on Doris 3.0: introducing a cluster orchestration system and developing a custom cluster management system based on Doris Manager, providing more comprehensive and standardized operations and observability.
Building a Unified Platform with Apache Doris
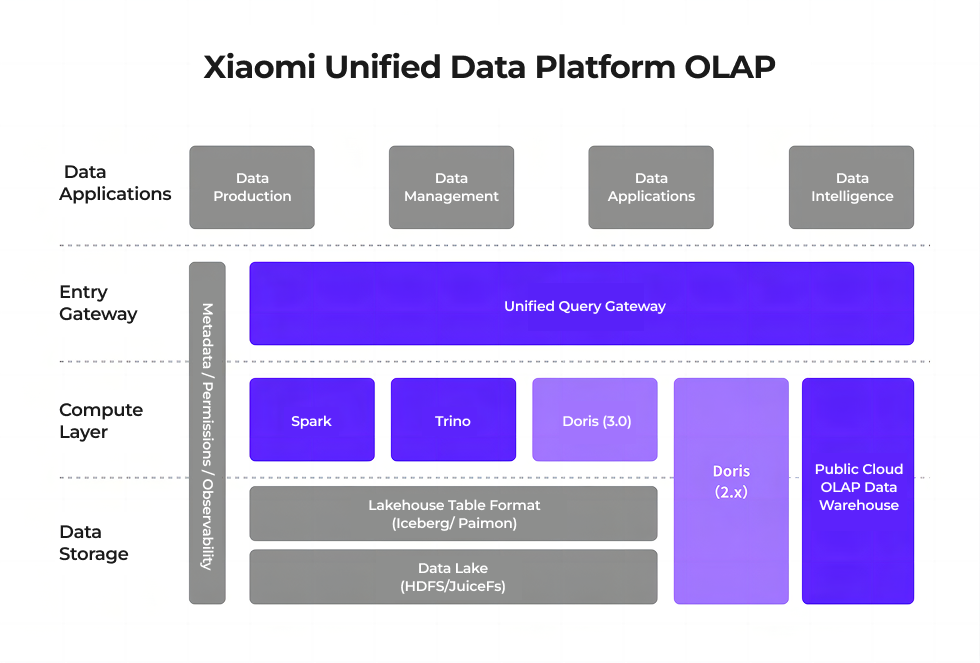
Apache Doris 3.0 brought major upgrades, with compute-storage separation, lakehouse integration, and cluster automation. After validation, the team planned an architecture in which Apache 3.0 runs in parallel with earlier versions and made significant optimizations to the design and usage patterns.
Core Advantages of Apache Doris
The compute-storage separation deployment model in Apache Doris 3.0 relies on Compute Groups for resource isolation. By decoupling the compute layer from the storage layer, BE nodes become stateless. With Kubernetes as the underlying orchestration layer, clusters can scale elastically to meet the needs of different workloads.
At the same time, Doris natively supports lakehouse query capabilities. In compute-storage separation mode, it can directly access external data lakes, effectively breaking down data silos. This not only simplifies traditional data pipelines but also reduces data redundancy caused by multi-layer replication, enabling a true lakehouse architecture in practice.
With these capabilities, Apache Doris is no longer limited to the traditional OLAP warehouse role. Instead, it has evolved into a unified query engine layer, decoupled from underlying lake formats like Iceberg and Paimon, performing federated queries directly while leveraging its own data caching and materialized views to accelerate hot data. This delivers both flexibility and high performance.
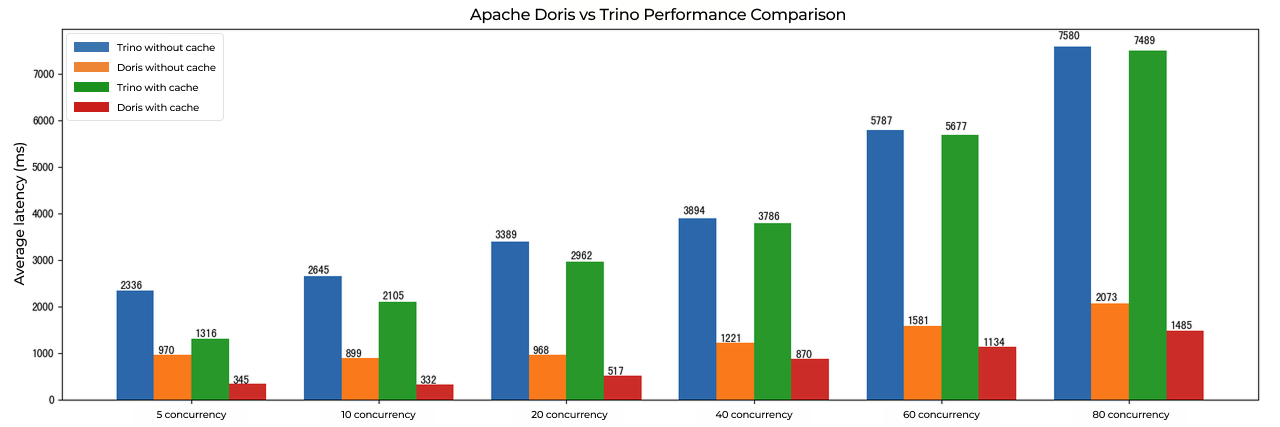
Doris vs. Trino: Faster Lakehouse Queries
In the TPC-DS 1TB benchmark, Apache Doris showed a clear advantage over Trino across the board. In complex multi-table joins, aggregation analysis, and high-concurrency response efficiency, Doris is faster and more resource-efficient, and with significantly lower average query latency. This makes Doris particularly well-suited for real-time analytics scenarios with demanding performance requirements.
- Table: TPC-DS 1TB benchmark, Apache Doris outperforms Trino across the board
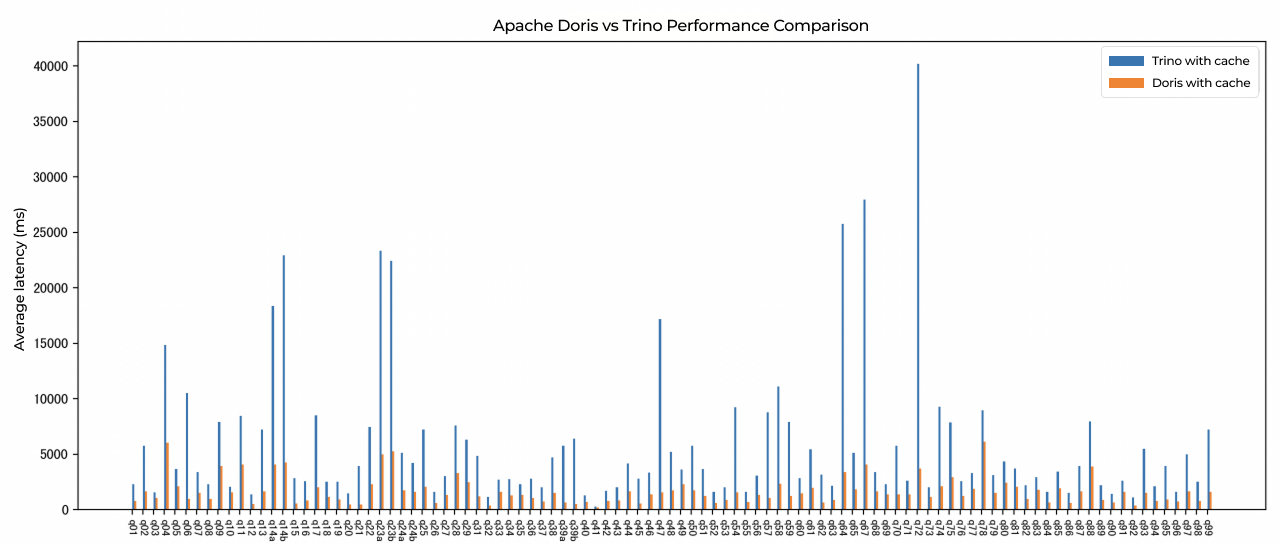
In Xiaomi's internal query scenarios covering common operations such as multi-table joins, aggregation, and predicate pushdown, Apache Doris delivered 3-5x faster data lake query performance than Trino.
- Table: Internal query scenarios, Apache Doris is 3-5x faster than Trino in data lake queries
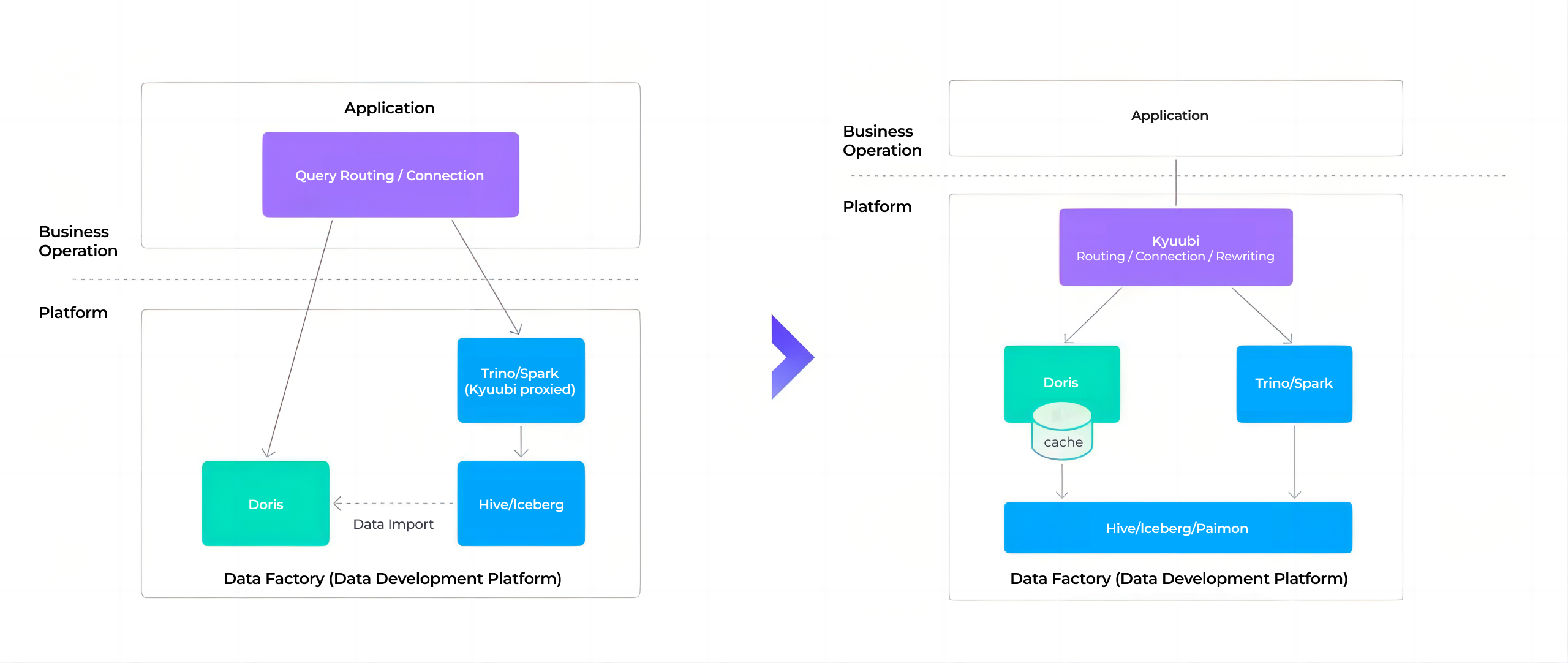
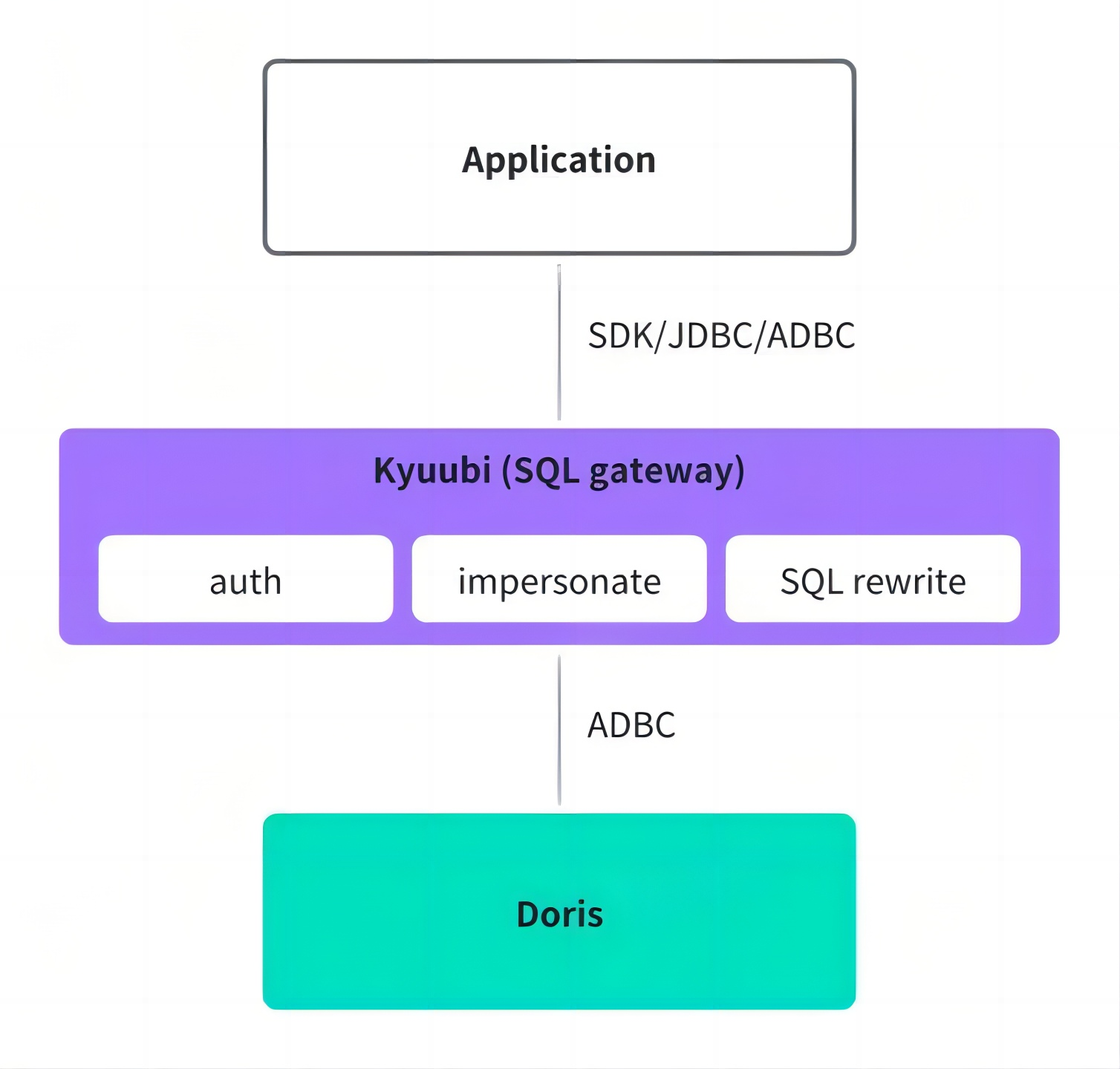
Unified Query Gateway
-
Unified authentication and authorization: At the connection layer, Xiaomi built a gateway to manage the authentication and permission systems of different engines. Users query through the gateway without worrying about engine-specific access controls.
-
SQL rewriting: Apache Doris' SQL rewriting capability is also implemented into the gateway, enabling users to switch between engines smoothly without running into SQL incompatibility errors.
-
Connection protocol optimization: By adopting the Arrow Flight SQL transfer protocol and ADBC connections, data transfer efficiency is over 10x higher than JDBC. In real business scenarios, query latency decreased by 36%, Kyuubi gateway instance memory usage dropped by 50%, and proxy service management efficiency improved significantly.
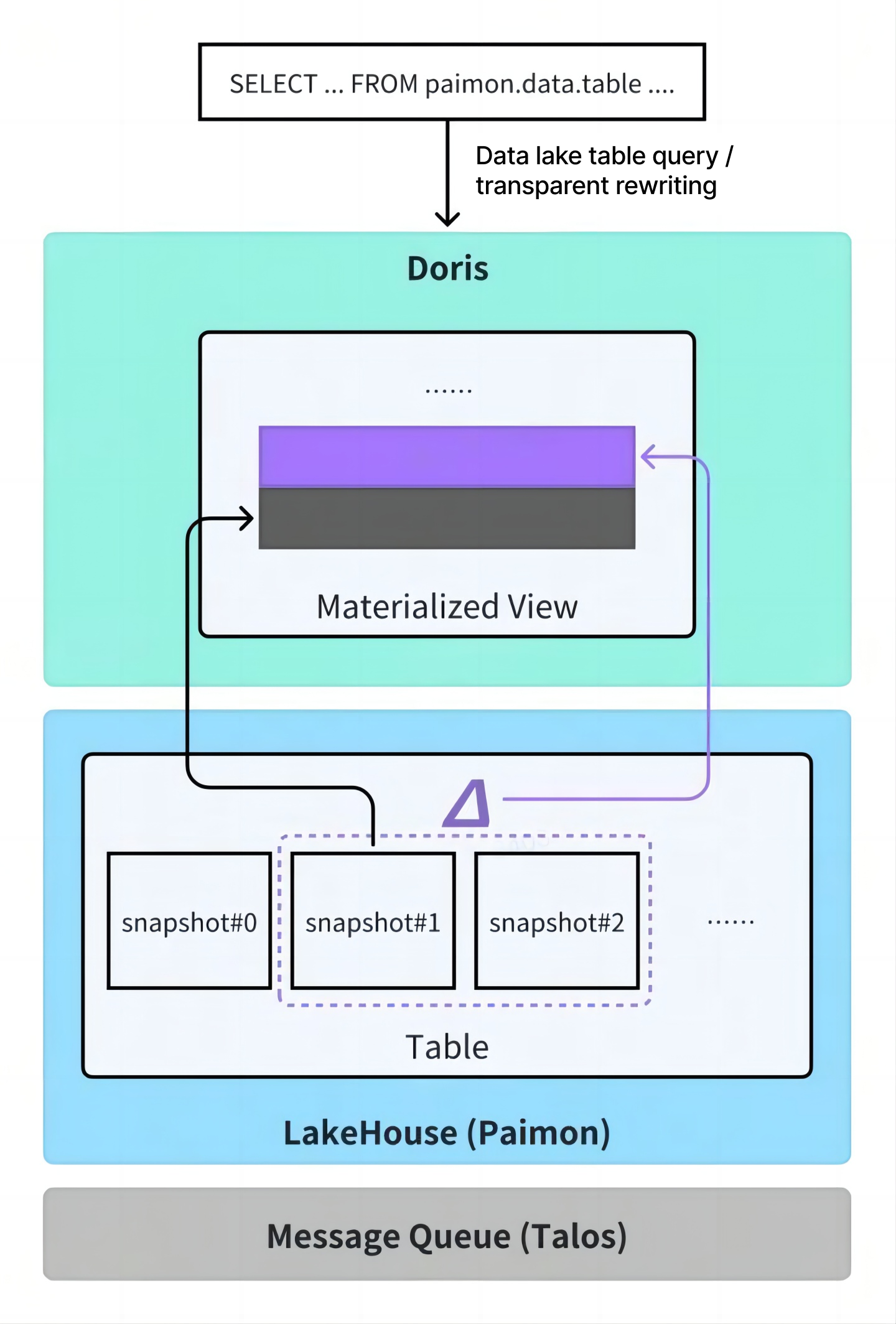
Using Apache Doris Materialized Views to Replace Import Jobs
Take the advertising business as an example. When querying minute-level data was slow, the typical approach was to pre-aggregate raw data into hourly rollups and periodically import them into Apache Doris. This required developing and maintaining complex scheduling tasks, with high operational costs.
Since Apache Doris 2.1 introduced asynchronous materialized views, users only need to define a materialized view in Doris, and the system automatically handles incremental syncing from external data lakes (e.g., Iceberg), data aggregation, and refresh scheduling. No additional ETL pipeline development is needed, and users don't have to worry about the underlying execution details, significantly reducing both development and operational burden.
Apache Doris also supports transparent query rewriting for materialized views. Users can keep querying the original tables with their existing SQL, and Doris automatically routes those queries to the corresponding materialized view for faster results. Currently, this works with incremental, append-only scenarios; support for update scenarios is still under development.
Here is an example of creating an asynchronous materialized view:
CREATE MATERIALIZED VIEW mv
BUILD DEFERRED
REFRESH INCREMENTAL
ON COMMIT
PARTITION BY (date)
DISTRIBUTED BY RANDOM BUCKETS 4
PROPERTIES ('replication_num' = '3')
AS
SELECT
date,
k1+1 AS k2,
SUM(a1) AS a2
FROM
paimon.data.table
WHERE date >= 20250222
GROUP BY 1, 2;
Better Resource Management
To optimize resource management and operations workflows, Xiaomi developed a custom Doris Manager cluster management service. This service turns operational tasks into self-service operations, leveraging the community's open-source Doris Operator to automatically handle resource provisioning and release on Kubernetes. Users would submit resource requests directly through the platform, without waiting for machine provisioning, initialization, deployment, and go-live steps. The delivery time for cluster scaling was reduced from approximately one week to minutes, significantly improving operational responsiveness and efficiency.
Doris Manager also handles automatic cluster registration and discovery. When a new cluster is created, it registers its Catalog with the metadata center and is automatically picked up by the query gateway. Users can start querying through the unified access endpoint without any additional configuration.
After moving to Kubernetes, resource scheduling became much more granular. Instead of allocating entire physical machines, resources can now be assigned at the level of CPU cores, memory, and disk capacity, making it easy to allocations for different workloads and improve overall utilization.
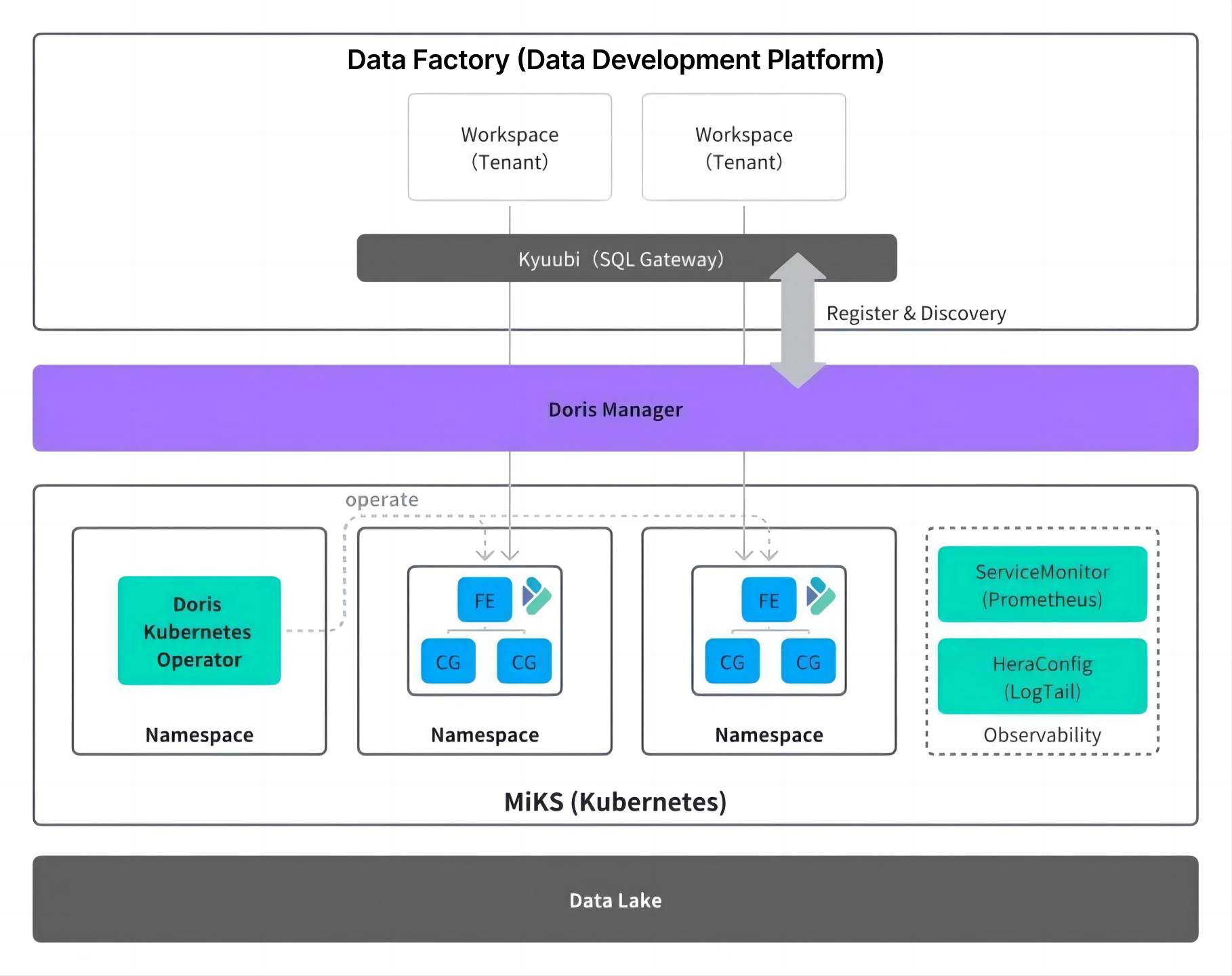
Improved Observability
To improve cluster observability, Xiaomi upgraded the Apache Doris monitoring stack using Kubernetes' standardized components and following the OpenTelemetry specifications. Doris component performance metrics are collected through Prometheus' ServiceMonitor, providing users with comprehensive, fine-grained monitoring data.
For log collection, Xiaomi uses its in-house Hera (a log tail component) for efficient collection. Following the community's best practices for log search scenarios, Apache Doris itself serves as the storage backend for OpenTelemetry: logs generated by Doris are collected and stored back into Doris internal tables, forming a closed loop of log generation → collection → storage → query.
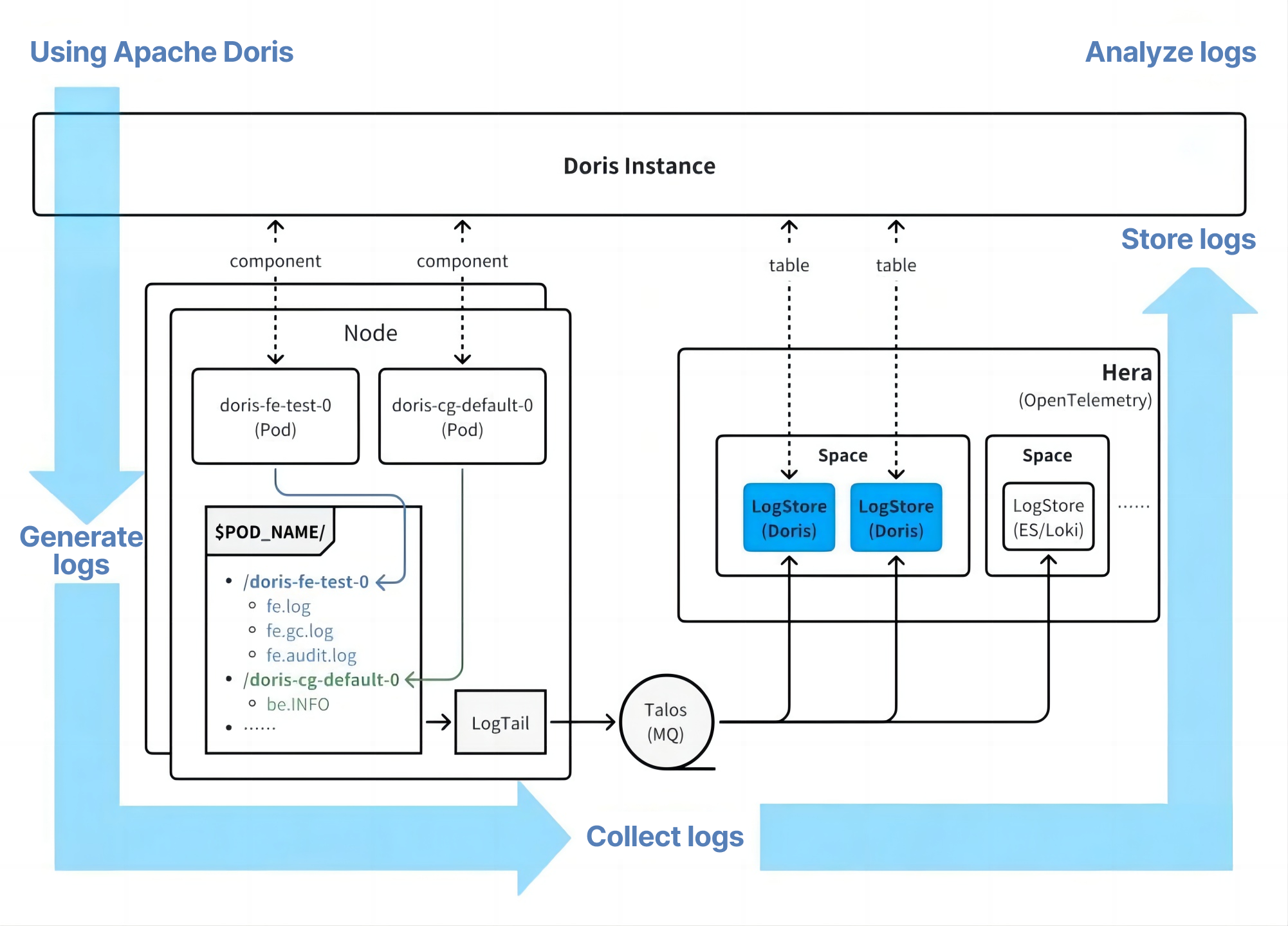
Compared to the previous Falcon system, which only supported basic metric collection, the Hera architecture covers audit logs, monitoring metrics, runtime logs, profiling results, and distributed tracing information (still being improved), providing much more comprehensive diagnostic capabilities.
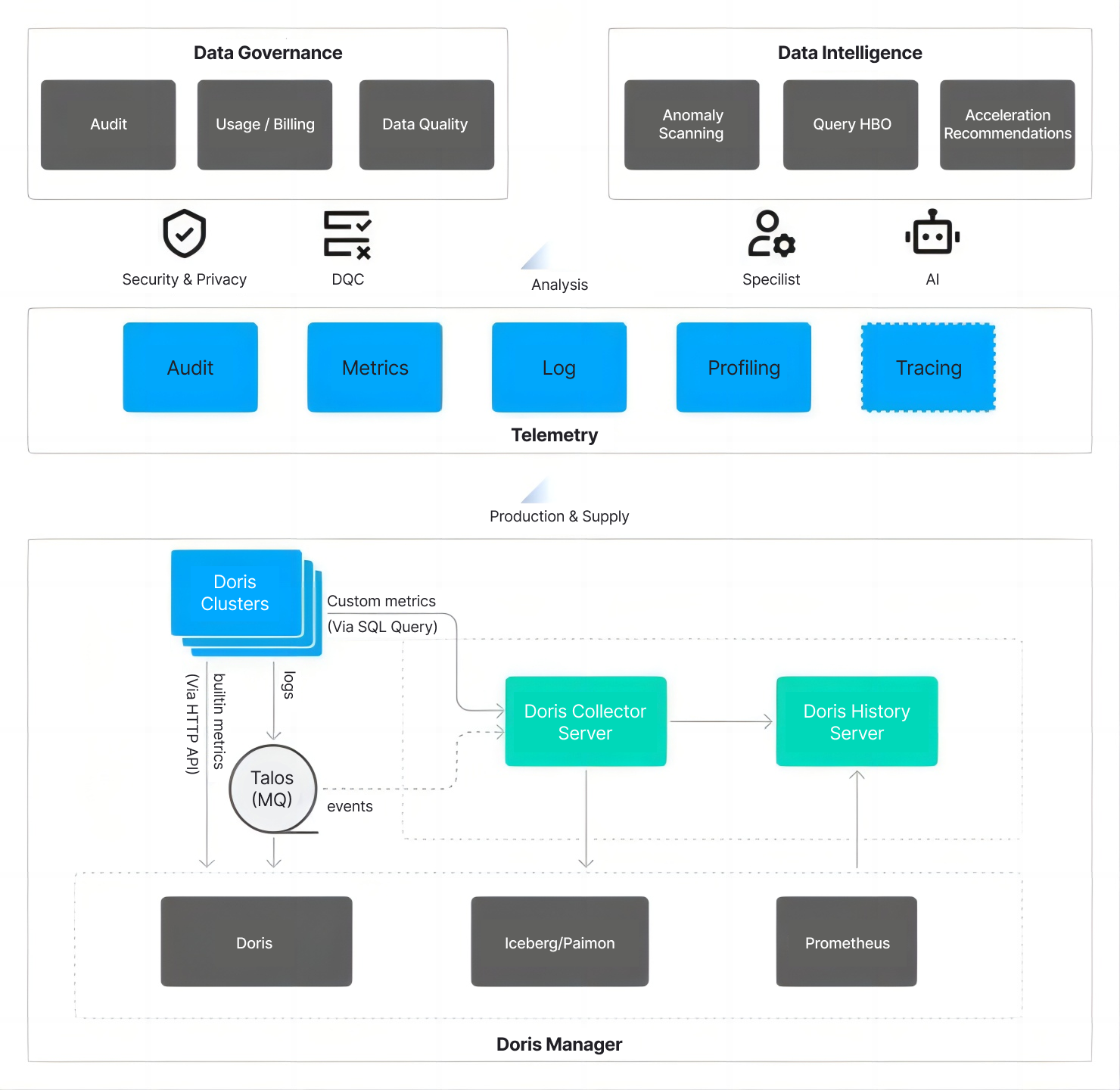
Future Plans
Xiaomi appreciated the Apache Doris community for maintaining a consistent release cadence and for its focus on stability. Looking ahead, Xiaomi plans to focus on the following areas:
-
Complete Apache Doris version consolidation: Converge core functionality to versions 2.1 and 3.0, unify toolchain dependencies to reduce environment differences, and significantly improve development iteration efficiency as a foundation for future feature work.
-
Deepen lakehouse capabilities: Improve the completeness and stability of lakehouse support, drive large-scale adoption of the Apache Doris compute-storage separation architecture, and expand incremental computation capabilities to meet real-time data processing demands in complex scenarios.
-
Expand into new scenarios and AI integration: Create log and tracing storage capabilities, explore more AI integration with Apache Doris.
Join the Apache Doris community on Slack and connect with Doris experts and users. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.


