


This cookbook covers chunk shaping, embedding selection, and ANN index scaling in Apache Doris for production-ready context retrieval.
Every AI system has a context problem
Your retrieval demo worked. The team loaded product docs, someone asked "How does authentication work?", and the assistant returned a clean paragraph. Then real users arrived, and the questions stopped sounding like demos. They became narrower, tied to specific code paths, policy exceptions, release versions, and source citations.
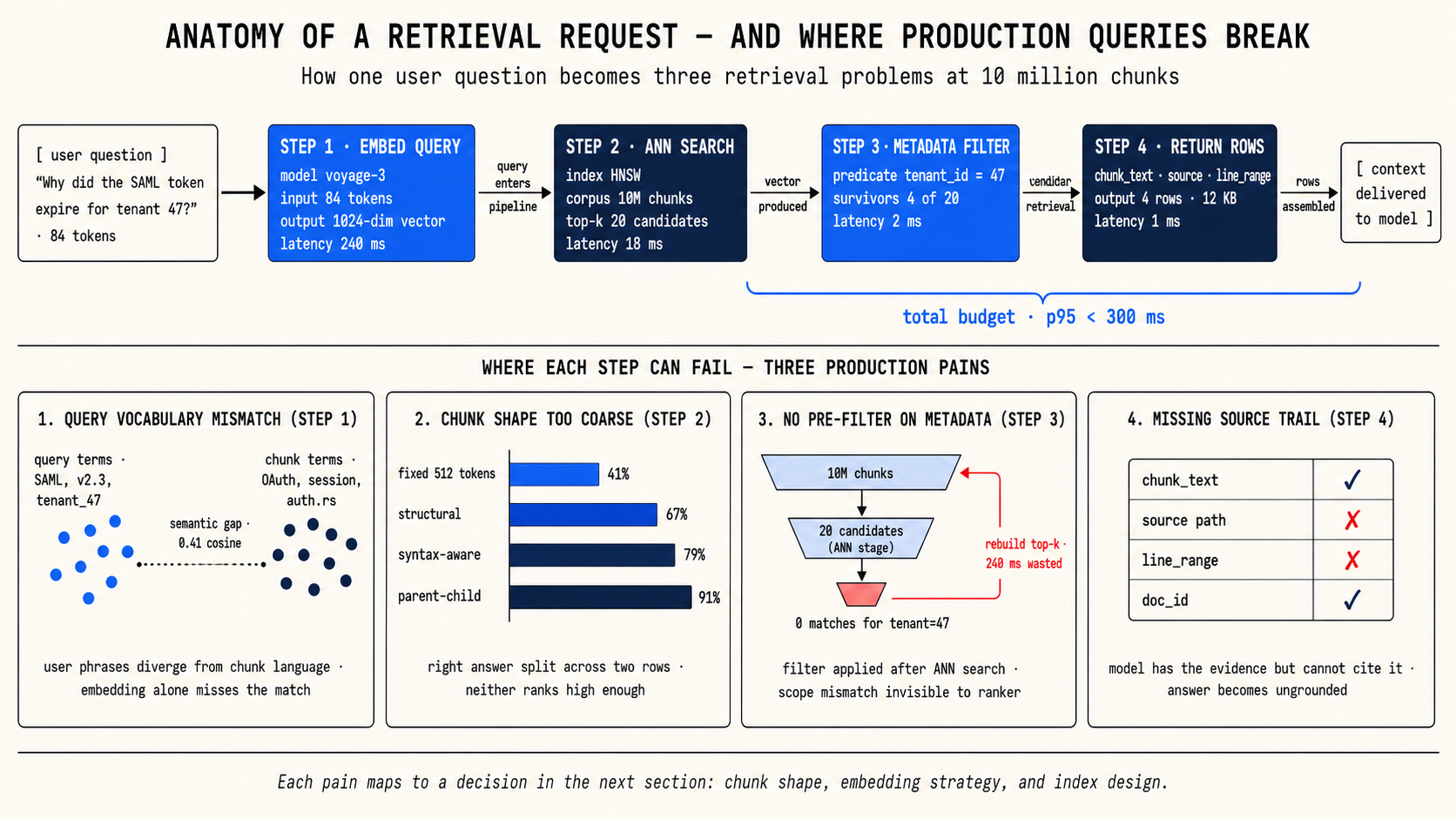
That gap between demo retrieval and production retrieval is what context engineering addresses. The term sounds abstract, but the work is concrete: decide how to split your source material into retrievable units, decide how to represent those units as vectors, and decide how to search those vectors at the scale your application actually needs. Each of those decisions shapes whether the model gets the right evidence before it answers.
This cookbook walks through those decisions in order. It is written for practitioners building RAG or agentic systems who need to move past the demo and ship a retrieval pipeline that holds up under real queries, real corpus sizes, and real accuracy requirements.
Why Apache Doris makes a good context store
Most retrieval stacks split the work across multiple systems: a vector database for embeddings, a search engine for keyword matching, a relational store for metadata filters, and glue code to combine results. That architecture works until you need to debug why the right chunk did not surface for a query. The answer usually involves a mismatch between systems, and fixing it means coordinating changes across all of them.
Apache Doris keeps the pieces together. One table holds the chunk text the model reads, the embedding the ANN index searches, the metadata the application filters on, the inverted index for keyword matching, and the source fields the application cites. When retrieval fails, the fix is a data change in one place, not a coordination exercise across three services.
That design gives your application three things that matter in production:
Complete, citable results. Each retrieved row can carry everything the model needs: the text to read, the source to cite, and the metadata to filter. You do not need a second lookup to assemble a usable answer.
Hybrid retrieval in one query. Doris can combine ANN vector search with BM25 full-text search and SQL filters in a single query. When vector search alone misses a result because the user's phrasing diverges from the chunk's language, keyword matching can catch it, and vice versa.
A single system to scale. As the corpus grows from thousands of chunks to hundreds of millions, you change the index strategy within Doris rather than migrating to a different system. ByteDance runs billion-scale vector search on Doris with hybrid retrieval latency around 400 ms p95, on a single server.
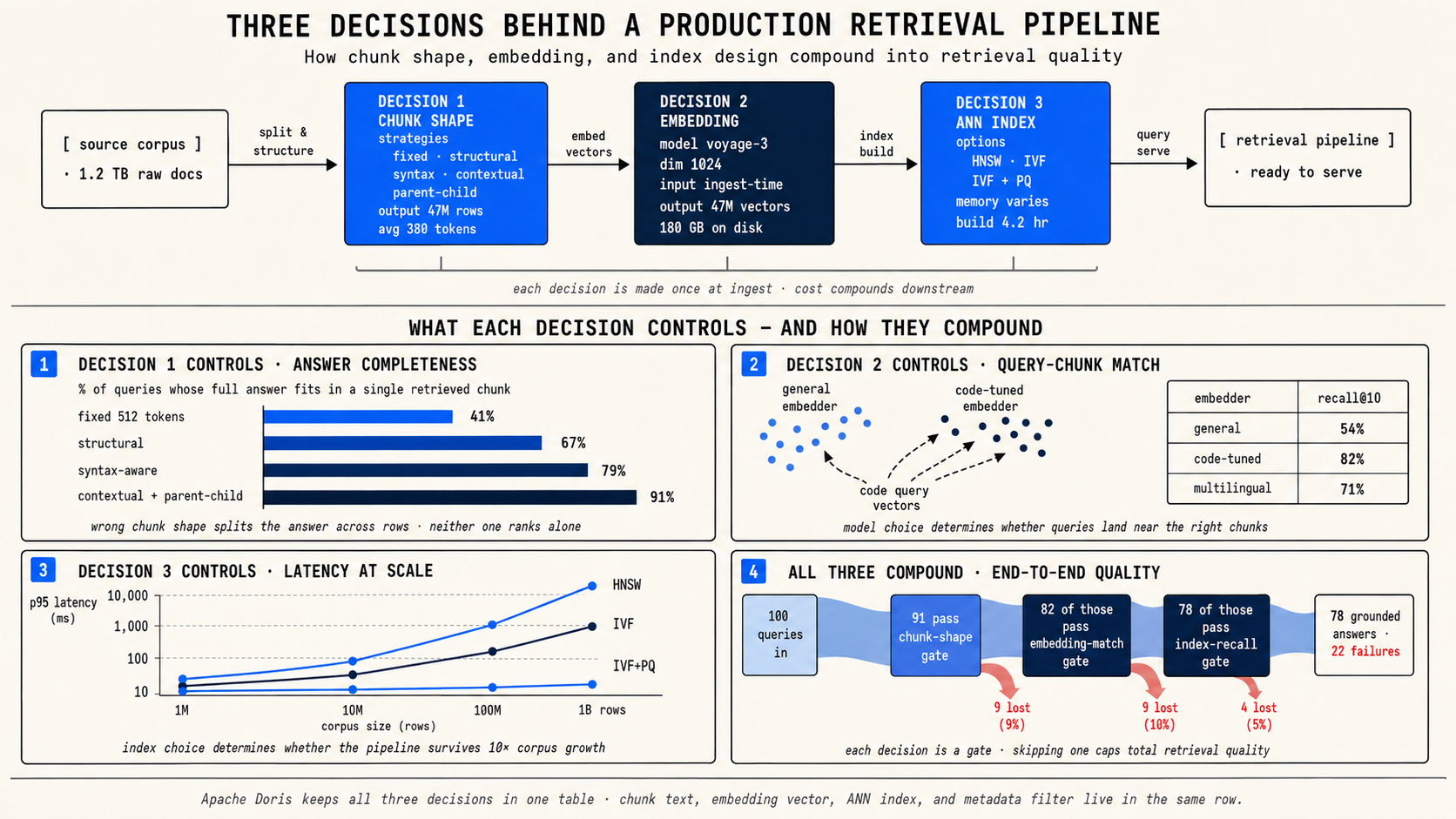
Three decisions shape your retrieval quality
Before you write any code, you need to make three decisions. They are sequential: each one builds on the previous.
Decision 1: How should you shape each chunk? This determines what one retrievable row represents. The chunk shape controls whether a retrieved result is complete enough to answer, narrow enough to stay relevant, and rich enough to cite.
Decision 2: How should you create and store embeddings? This determines whether the vector can match the way users actually ask questions. The embedding model, the input text you feed it, and the vector dimensions you store all affect retrieval accuracy.
Decision 3: Which ANN index fits your corpus size? This determines whether search stays fast and affordable as the corpus grows. The index type, the quantizer, and the tuning parameters trade off memory, build cost, and recall.
Decision 1: How should you shape each chunk?
Start by asking what one row should represent. A chunking strategy succeeds when retrieved rows are complete enough to answer, narrow enough to stay relevant, and rich enough to cite.
Choose the simplest strategy that fixes the failure you can measure. Do not over-engineer the chunk shape before you have real queries failing.
Start with fixed-token windows
Cut every N tokens with overlap. This is the default. It works well when answers are local: a single paragraph or a few sentences contain the full evidence.
Use LangChain's RecursiveCharacterTextSplitter, Unstructured, Docling, or your own parser. Load the rows into Doris with INSERT...VALUES or Stream Load.
When to move on: If the splitter cuts answers across rows, and you can see that a single function, a single table, or a single policy section should have stayed together.
Preserve document structure
Cut on headings, lists, tables, and code blocks so prose structure survives the split. This keeps a section with its heading, a table with its caption, and a code block with its surrounding explanation.
When to move on: If code citations matter (file path, line range), or if the chunks need syntax-aware boundaries rather than just heading-aware ones.
Split code by syntax
For source code, use a syntax-aware splitter like tree-sitter. Each chunk carries the repository name, file path, start line, end line, and the code text. That gives the application a clickable citation and a stable handle for fetching surrounding lines.
This is critical for code search assistants. A chunk that says "set the token expiry to 30 minutes" is useless if the developer cannot find it in the codebase. A chunk that says auth.rs:112-188 is actionable.
When to move on: If the right chunk exists in the table but does not rank for the query because the local text uses different words than the user.
Enrich the embedding input (contextual retrieval)
Sometimes a chunk answers the question, but the embedding misses the query because the chunk text alone lacks the connecting language. A runbook step that says "restart the worker deployment" should answer "How do I rotate the OpenAI key for the retrieval service?" but the vector computed from the local instruction alone has no provider, key-rotation, or retrieval-service language.
The fix is to separate render text from retrieval text. Store the original chunk for display. Compute the embedding from the chunk plus a short, LLM-generated context line that connects it to its section title, document title, or surrounding content.
In Doris 4.1, you can run this enrichment during ingest with AI_GENERATE and EMBED:
WITH enriched AS (
SELECT
doc_id, chunk_id, chunk_text, meta,
AI_GENERATE('ctx_gen', CONCAT(
'Write one short retrieval context for this chunk. Title: ',
CAST(meta['title'] AS STRING),
'. Chunk: ', chunk_text)) AS retrieval_context
FROM staging_chunks
)
INSERT INTO chunks (doc_id, chunk_id, chunk_text, embedding, meta, ts)
SELECT
doc_id, chunk_id, chunk_text,
EMBED('ctx_embed', CONCAT(retrieval_context, '\n\n', chunk_text)),
meta, CURRENT_TIMESTAMP()
FROM enriched;
When to move on: If small chunks rank well but lack enough surrounding context for the model to reason confidently.
Match small chunks, return large sections (parent-child retrieval)
Sometimes the matching span is precise but incomplete. The line "restart the worker deployment" is the best semantic match, but the model also needs the steps before and after it.
Store both sizes in the same table. Rows at level=1 are small leaf chunks the ANN index searches. Rows at level=0 are larger parent sections the query returns. The query searches leaves, then joins each matched leaf to its parent:
WITH child_hits AS (
SELECT doc_id, node_id, parent_id,
inner_product_approximate(embedding, :query_vec) AS sim
FROM chunk_nodes
WHERE level = 1
ORDER BY sim DESC
LIMIT 20
)
SELECT
p.doc_id,
p.node_id AS parent_node_id,
p.body AS parent_context,
MAX(c.sim) AS best_child_score
FROM child_hits c
JOIN chunk_nodes p
ON p.doc_id = c.doc_id AND p.node_id = c.parent_id
GROUP BY p.doc_id, p.node_id, p.body
ORDER BY best_child_score DESC
LIMIT 5;
Decision 2: How should you create and store embeddings?
Once you know the chunk shape, decide how to turn those chunks into vectors. Three sub-decisions matter here.
Embed at ingest, not at query time
Create chunk embeddings in your ingestion pipeline and load the finished vectors into Doris. Do not call EMBED() on stored rows during search. On a 10M-row corpus, that turns one search into millions of embedding API calls before Doris can rank results.
The cost model is simple: pay once when a chunk changes, then pay once per user query to embed the query text. CocoIndex tracks which source files changed, re-embeds only changed chunks, and upserts updated rows through Stream Load.
At query time, embed the user's question once with the same model and pass the vector to Doris:
SELECT chunk_id, chunk_text, meta,
inner_product_approximate(embedding, :query_vec) AS sim
FROM chunks
ORDER BY sim DESC
LIMIT 10;
Pick one embedding model per corpus
The model defines the vector space. Do not mix embeddings from different models in the same column, even if the dimensions match. Changing models later means re-embedding every stored chunk.
Choose based on your workload, not leaderboard rank:
-
Modality. Text-only corpora can use text embedders like OpenAI text-embedding-3, BGE, mxbai, Nomic, or Cohere Embed. If the corpus includes images, PDFs, or screenshots, use a multimodal embedder like Gemini Embedding 2.
-
Domain. General text embedders work well for product docs. Source code needs a code-tuned model like voyage-code-3 or jina-embeddings-v2-code.
-
Language. Mixed-language corpora need a multilingual model. Do not rely on English embeddings plus query-time translation.
-
Input window. The chunk must fit inside the model's input limit. A 512-token embedder silently truncates a 1,024-token chunk, so the vector never sees the second half.
-
Dimensions. The output dimension must match the Doris ANN index declaration. Higher dimensions can improve recall but increase storage.
Shrink the vector, then rescore
A 3,072-dim FLOAT32 vector is 12 KB per row. At 10M rows, that is 120 GB of vectors before any index overhead. You can reduce this if your embedding model supports Matryoshka Representation Learning (MRL).
MRL trains each prefix of the vector to work on its own. A 256-dim prefix from a 3,072-dim MRL model behaves like a valid embedding, not a random truncation. Models that support this include text-embedding-3, Cohere Embed v3+, Nomic Embed v1.5, and Gemini Embedding 2.
The pattern: store two vector columns. embedding_256 is the smaller vector with an ANN index for fast candidate search. embedding_full is the full vector without an ANN index for accurate rescoring:
WITH cand AS (
SELECT chunk_id, chunk_text, embedding_full,
inner_product_approximate(embedding_256, :q256) AS approx_sim
FROM chunks
ORDER BY approx_sim DESC
LIMIT 200
)
SELECT chunk_id, chunk_text,
inner_product(embedding_full, :q_full) AS exact_sim
FROM cand
ORDER BY exact_sim DESC
LIMIT 10;
Decision 3: Which ANN index fits your corpus size?
The ANN index determines how Doris searches your vectors. The right choice depends on two things: how many vectors you have, and how much memory you can afford.
Understand the building blocks
-
HNSW builds an in-memory graph of nearby vectors. Queries walk the graph to find nearest neighbors. Fast and accurate when the graph fits in memory. The cost is memory and build time at large scale.
-
IVF clusters vectors into partitions. A query finds the closest clusters first, then searches only those clusters. Uses less memory than HNSW. Recall depends on how many clusters you probe.
-
PQ (Product Quantization) is compression, not a search structure. It splits each vector into sub-vectors and replaces each with a compact code. PQ pairs with IVF to reduce how many bytes each searched vector occupies.
A practical ladder
Treat these as starting points, not guarantees. The right breakpoints depend on dimension, recall target, hardware, and latency budget.
Up to ~10M rows: HNSW + SQ8. Low latency, simple tuning. This is the default for most production RAG systems.
INDEX ann_emb (embedding) USING ANN PROPERTIES (
"index_type"="hnsw", "metric_type"="inner_product",
"dim"="1024", "quantizer"="sq8",
"max_degree"="32", "ef_construction"="40"
)
10M to 100M rows: IVF. When HNSW memory or build cost becomes uncomfortable, switch to IVF. nlist (number of clusters) is a build-time choice. ivf_nprobe (clusters searched per query) is a query-time knob you can raise without rebuilding.
100M+ rows: IVF + PQ. When the working set no longer fits cleanly in memory, add product quantization. ByteDance's Doris deployment shows this at scale: one billion 768-dim vectors, ~500 GB memory, ~400 ms p95 hybrid retrieval on a single server.
INDEX ann_emb (embedding) USING ANN PROPERTIES (
"index_type"="ivf", "metric_type"="inner_product",
"dim"="768", "quantizer"="pq",
"nlist"="10000", "pq_m"="8", "pq_nbits"="8"
)
The base chunks table
Before the worked example, here is the base table that all the recipes above extend. It has three jobs: chunk_text holds what the model reads, embedding holds the vector Doris searches, and meta holds sparse source-specific fields without forcing a new schema for every corpus.
CREATE TABLE chunks (
doc_id BIGINT NOT NULL,
chunk_id BIGINT NOT NULL,
chunk_text STRING NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
meta VARIANT,
ts DATETIME,
INDEX ann_emb (embedding) USING ANN
PROPERTIES (
"index_type"="hnsw", "metric_type"="inner_product",
"dim"="1024", "quantizer"="sq8"),
INDEX inv_text (chunk_text) USING INVERTED
PROPERTIES (
"parser"="english", "support_phrase"="true")
)
ENGINE=OLAP
DUPLICATE KEY(doc_id, chunk_id)
DISTRIBUTED BY HASH(doc_id) BUCKETS 4
PROPERTIES (
"storage_format"="V3",
"inverted_index_storage_format"="V3",
"replication_num"="1"
);
Worked example: chunking a code repository
Let's walk through the three decisions for a concrete use case. You are building a code search assistant that helps developers find relevant code and understand how systems work. The corpus is a source code repository.
Decision 1: Chunk shape
The corpus is source code, so you need syntax-aware splitting. Each chunk should represent a complete function or logical code block, and every chunk must carry the file path and line range so the application can cite auth.rs:112-188 directly.
Fixed-token windows would cut functions in half. Structure-aware splitting would miss syntax boundaries. Tree-sitter gives you boundaries that match the code's actual structure.
You do not need contextual retrieval or parent-child retrieval for the initial pipeline. Code chunks carry their own context through identifiers, imports, and function signatures. If you later find that chunks miss queries phrased in natural language, you can add contextual embedding enrichment at that point.
Decision 2: Embedding model and strategy
The corpus is source code, so you pick a code-tuned embedding model like voyage-code-3. General text embedders underperform on code because they were not trained on the patterns that matter for code search: function names, variable naming conventions, import structures, and the relationship between natural-language questions and code.
You embed at ingest time using CocoIndex. CocoIndex memoizes the processing function per file, so each pipeline run skips unchanged files and only re-embeds files whose content changed. This keeps the cost proportional to what actually changes in the repo.
The corpus is under 1M chunks, so you do not need MRL truncation or two-column rescoring. Store one embedding column at the model's native dimension.
Decision 3: ANN index
The corpus is well under 10M rows, so HNSW + SQ8 is the right starting point. Simple to configure, low latency, and you can tune max_degree and ef_construction later if recall needs improvement.
Concrete Doris table
For this repository example, specialize the base chunks contract into typed columns the application projects on every result. The repo predicate is indexed, so the query can filter to one repository without turning the ANN search into a full scan.
CREATE TABLE code_chunks (
id STRING NOT NULL,
repo STRING NOT NULL,
path STRING NOT NULL,
start_line BIGINT NOT NULL,
end_line BIGINT NOT NULL,
code STRING NOT NULL,
embedding ARRAY<FLOAT> NOT NULL,
INDEX ann_code (embedding) USING ANN
PROPERTIES (
"index_type"="hnsw", "metric_type"="inner_product",
"dim"="1024", "quantizer"="sq8"),
INDEX inv_repo (repo) USING INVERTED
)
ENGINE=OLAP
DUPLICATE KEY(repo, id)
DISTRIBUTED BY HASH(repo) BUCKETS 8
PROPERTIES (
"storage_format"="V3",
"inverted_index_storage_format"="V3",
"replication_num"="1"
);
The CocoIndex pipeline
With the table shape fixed, the ingestion path is straightforward: read source files, detect language, split on syntax boundaries with tree-sitter, embed each chunk with the code model, and declare one Doris row per chunk.
# Setup omitted:
# - files: raw source files from localfs.walk_dir(...).items()
# - code_chunks: mounted Doris table target
# - splitter / embedder: configured once for the pipeline
# - REPO_NAME: stable repo identifier stored with each chunk
# - embedder.embed(): normalized 1024-dim vectors from voyage-code-3
@coco.fn(memo=True)
async def process_code_file(file, code_chunks) -> None:
path = str(file.file_path.path)
text = await file.read_text()
language = detect_code_language(filename=path)
for chunk in splitter.split(
text,
chunk_size=12000, # bytes, not tokens
chunk_overlap=1200,
language=language
):
start_line = chunk.start.line
end_line = chunk.end.line
code_chunks.declare_row(row={
"id": f"{REPO_NAME}:{path}:{start_line}",
"repo": REPO_NAME,
"path": path,
"start_line": start_line,
"end_line": end_line,
"code": chunk.text,
"embedding": await embedder.embed(chunk.text),
})
# In the app entrypoint:
await coco.mount_each(process_code_file, files.items(), code_chunks)
CocoIndex exposes source positions as chunk.start.line and chunk.end.line. Store those as normal columns, not JSON metadata, because every code-search answer needs them for citations.
Concrete result
Suppose a developer asks, "Where do we validate session token expiry?" The application embeds that question with the same code model and runs:
SELECT path, start_line, end_line, code,
inner_product_approximate(embedding, :query_vec) AS sim
FROM code_chunks
WHERE repo = 'my-service'
ORDER BY sim DESC
LIMIT 10;
A good top result is concrete enough to cite and open directly:
+-------------+------------+----------+------+
| path | start_line | end_line | sim |
+-------------+------------+----------+------+
| src/auth.rs | 112 | 188 | 0.82 |
+-------------+------------+----------+------+
The model receives the matched code body, while the UI renders src/auth.rs:112-188 as a clickable source link. That is the reason the row contract matters: retrieval returns evidence and a source trail in one result.
Context is a managed asset, not a lucky retrieval
The shift this cookbook describes is simple: stop treating a chunk as loose text that a model might rescue later. In Doris, a chunk becomes a managed row with a deliberate shape, a source trail, a vector, and an index strategy you chose for the corpus.
That turns context engineering into a set of database decisions you can test and adjust:
Missing evidence? Change the chunk shape or return a larger parent section.
Poor ranking? Enrich the embedding input so the vector matches how users actually ask.
Scaling bottleneck? Reduce the vector footprint or switch the ANN index layout.
The value is not that one chunking strategy, embedding model, or index type works forever. The value is that Doris makes failures diagnosable. When rows split the answer, change the row shape. When the right row does not rank, change the embedding input. When the corpus outgrows the index, change the vector and ANN design. Doris keeps those levers together, so retrieved text becomes production context: evidence the system can find, cite, match, and scale.


