


Xanh SM is a leading electric vehicle ride-hailing platform in Vietnam. I was part of the team that built a system providing real-time personalized location recommendations to users.
This recommendation system started from a casual conversation. One day, my colleague noticed that most of the popular destination lists on other ride-hailing apps barely ever changed. Same places, every day, regardless of what was actually happening in the city. "What if we could make our app update in real time and personalize it? That would set us apart," he said.
We loved the idea. If a popular concert was happening across town, or the National Day parade rehearsal, users could benefit from knowing about it and plan their trips accordingly.
That idea set our research in motion. After evaluating the technical requirements, we identified four problems we needed to solve:
-
How do we collect data to identify popular user locations in real time?
-
Can the system handle up to 20,000 messages per second (MPS)?
-
Can the system simultaneously handle analytics, data transformation, and response to service queries?
-
How do we get query response times under 100ms?
Here is how we built it.
Real-Time Destination Recommendation Architecture
To address these requirements, we designed an architecture that runs on two connected pipelines. The first pipeline captures and stores user activity as it happens. The second transforms that raw data into pre-computed results and serves them to users on demand.
Pipeline 1: User click events → Kafka → Flink → Apache Doris
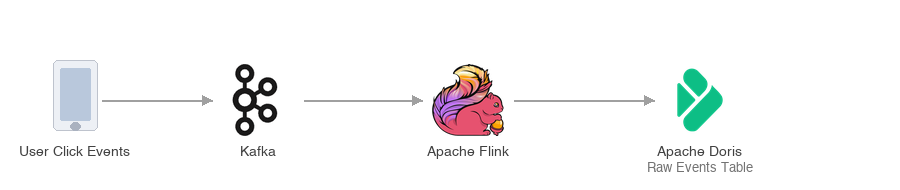
Every time a user clicks a destination in the app, the system sends that event via webhook and pushes it to Kafka in real time. Kafka acts as the ingestion buffer, absorbing spikes of up to 20,000 events per second without overwhelming anything downstream.
Apache Flink then consumes from Kafka and handles preprocessing: cleaning events, filtering noise, and structuring the raw data into a consistent format. Flink writes the output into Apache Doris in real time as a raw events table.
Pipeline 2: Doris raw table → Process Data Service → Doris results table → Suggestion API → User

The raw events table in Apache Doris feeds our analytics work. Our Process Data Service runs ETL jobs that read from this table, aggregate and rank locations by recent activity, apply personalization logic, and write the computed output into a separate results table, also in Apache Doris. This results table is what the Suggestion API queries.
When a user opens the destination screen, the Suggestion API (the recommendation service endpoint) queries the pre-computed results table in Apache Doris and returns a personalized, ranked list in under 100ms.
Why Apache Doris for both pipelines?
This architecture would normally require two separate systems: an OLAP data warehouse for the ETL analytics work, and a serving database like MySQL/Redis for fast API queries. These workloads have different resource profiles: ETL jobs are CPU-heavy and run in bursts, while API serving needs consistent low latency under concurrent load. On a traditional coupled database, they would compete for the same resources.
We chose Apache Doris in Compute-Storage Decouple Mode to avoid that trade-off. In this setup, storage is shared across all workloads, but compute is split into separate node groups: one dedicated to the ETL analytics jobs, one dedicated to serving queries. Each group has its own CPU and memory allocation, so a heavy aggregation job cannot slow down a live user request. Apache Doris provides one storage layer with isolated compute, so we did not need to manage separate systems.
Results
After deploying the system, the location recommendation feature went live and worked the way we hoped. The app now surfaces the latest trending locations instead of a static, dated list.
The clearest proof came during Vietnam's National Day on September 2, 2025. Without any manual input, the app recommended the exact venues where events were happening in real time:
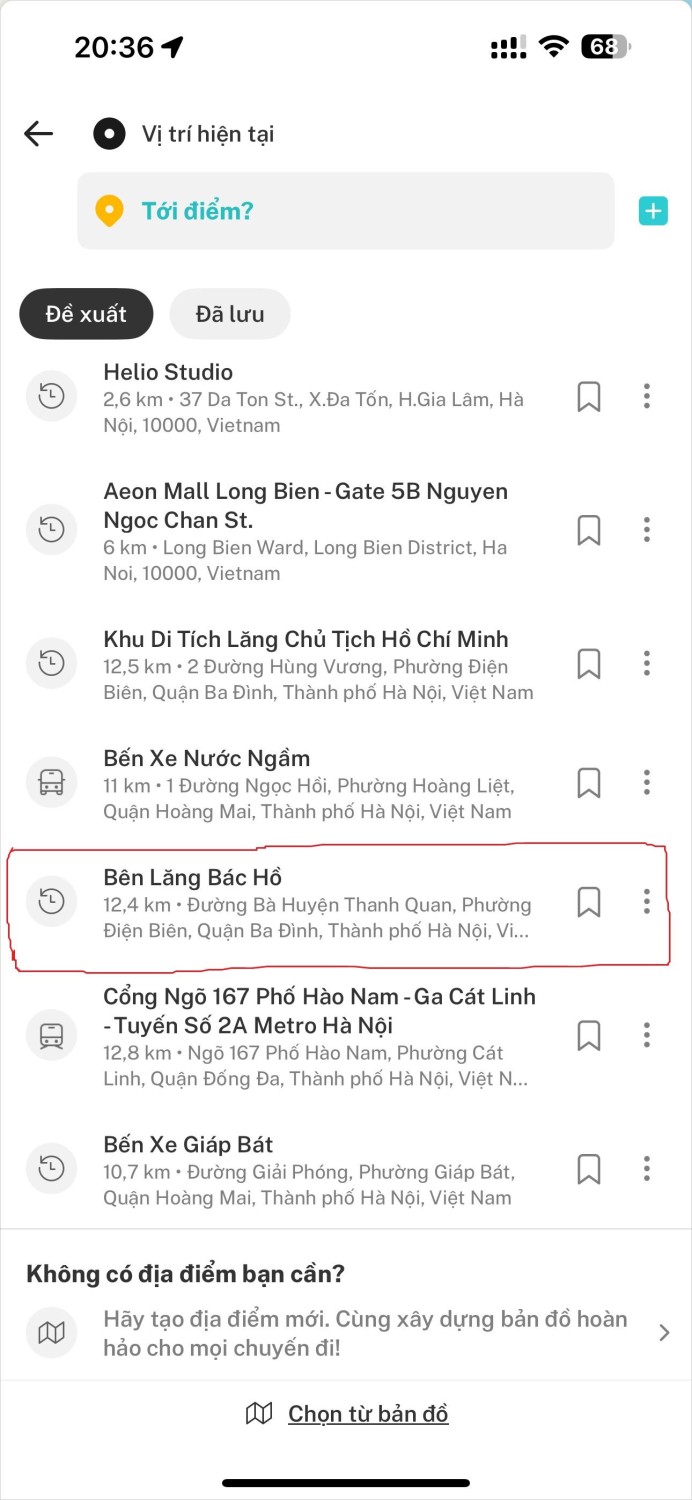
- Ho Chi Minh Mausoleum: the venue for the A80 military parade rehearsal.
<img style={{margin:"auto"}} src="https://cdn.selectdb.com/static/pic_3_9718eb4edb.jpeg" alt="pic_3.jpeg" width="300" height="400" />
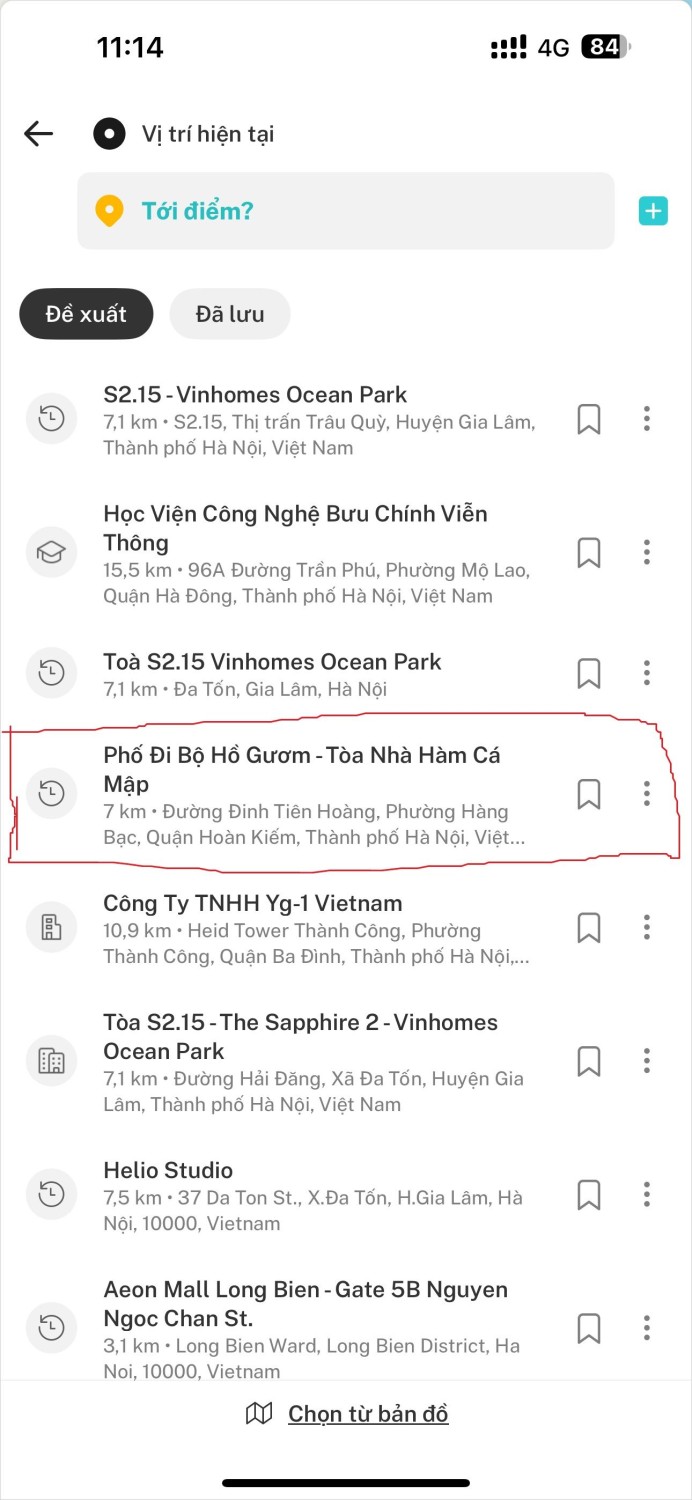
- Hoan Kiem Lake Pedestrian Street: the location of the A80 parade rehearsal at the corresponding time.
<img style={{margin:"auto"}} src="https://cdn.selectdb.com/static/pic_4_75b8bffbed.jpeg" alt="pic_4.jpeg" width="300" height="400" />
- The same pattern held during the G-Dragon concert. The app had already surfaced the concert venue as users started heading there.
<img style={{margin:"auto"}} src="https://cdn.selectdb.com/static/pic_5_bb9d572d22.jpeg" alt="pic_5.jpeg" width="300" height="400" />
Performance:
-
175,000 records written per second in under 1 second
-
P9999 query latency occasionally exceeded 100ms, but average query latency held at ~76ms across most time windows.
These results validated our approach, and we continue to work with Apache Doris to push performance further.
Building this system taught us a valuable lesson: the assumption that analytics and real-time serving require separate systems is not always true. Apache Doris and its Compute-Storage Decouple Mode allowed us to run both workloads from a single storage layer, cutting infrastructure cost and complexity without sacrificing performance.
Join the Apache Doris community on Slack to connect with Doris experts and users. If you are looking for a fully managed Apache Doris cloud service, contact the VeloDB team.

{kind=link}
{kind=link}
{kind=link}