TL;DR: Wide JSON's field count keeps growing, and the cost of storing and querying it grows with it. Apache Doris 4.1 introduces DOC mode and Storage Format V3 to keep write throughput, query latency, and resource overhead in balance at the same time. In a benchmark on a single 16-core, 64 GB, SSD machine over 100 million wide-JSON rows, Doris's overall performance-to-cost ratio outperforms typical alternatives including ClickHouse, PostgreSQL, and Elasticsearch on the same workload.
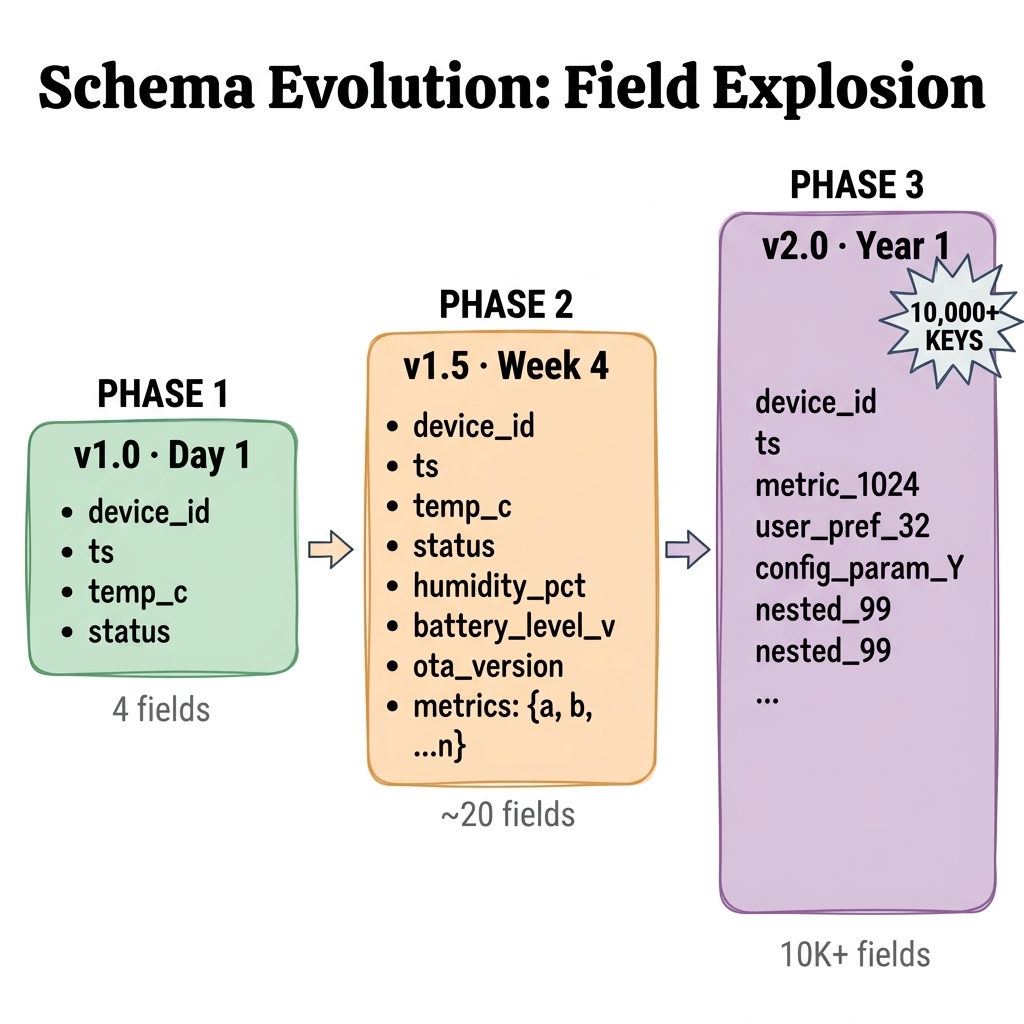
Picture a connected-vehicle platform ingesting telemetry from hundreds of vehicle models. Each model contributes its own sensor set. One model streams battery temperature, motor RPM, charging voltage, and roughly 200 other signals. Another reports tire pressure, suspension height, cabin temperature, and a different 180. Every six months, a new model joins the fleet with its own data types.
Volume compounds the complexity. Rivian, for example, streams more than 5,500 signals from each vehicle every five seconds. Multiply that across dozens of vehicle models and years of revisions, and the engineering team faces an ultra-wide table: more than 10,000 unique fields, only a few hundred populated per row, and a schema that changes every time a new vehicle model ships.
Most analytics platforms in this position store the payload as JSON for three reasons:
-
Schema evolution is constant. New signals appear the day a new SKU ships. Defining 10,000 typed columns up front, then migrating every time the schema shifts, is not realistic.
-
Producers and consumers evolve independently. JSON keeps the contract loose enough to ship features without lockstep coordination across firmware, ingestion, and analytics teams.
-
The JSON ecosystem is everywhere. Almost every device SDK, message bus, and stream processor speaks it natively.
JSON solves schema evolution. At 10,000+ fields, it creates a different problem: how do you keep writes, queries, and storage cost-effective at the same time?
This shape shows up everywhere data outpaces schema design below are some examples:
-
Connected vehicles. New models, hardware revisions, and OTA updates each add their own fields. Field counts reach the tens of thousands with significant variance across models.
-
Observability. Microservices and SDK iterations push the number of log and trace dimensions into the hundreds or thousands.
-
Behavior analytics. Business expansion widens the dimensions for analytics, with mature deployments typically running at 1000 to 5000 distinct fields, with each being a column
-
AI applications. Prompts and models iterate fast. Agent traces, tool calls, and evaluation results keep introducing new attributes
The workloads differ, but the engine-level pain is the same. Apache Doris 4.1 addresses it directly with DOC mode and Storage Format V3 to raise performance, scalability, and cost-efficiency in exactly the regime where naïve approaches fall apart.
1. The core performance bottlenecks
As throughput climbs and JSON paths reach the tens of thousands, two bottlenecks emerge:
-
Metadata bloat. As column and field counts grow, metadata (Footer, column meta) grows roughly linearly with column count, and pressure on the storage side grows. This is not a one-off issue; it is the universal cost of columnar storage at scale.
-
Eager JSON Shredding. To accelerate queries, some systems (early Doris VARIANT, Elasticsearch, and others) materialize each JSON path into its own column at write time. That puts pressure on both the write path and compaction.
In practice, the two bottlenecks create a negative feedback loop. Write-path bottlenecks cause file fragmentation, which amplifies metadata bloat.
2. Common approaches to dealing with ultra-wide JSON Tables s
Solutions handling wide JSON with more than 10,000 paths take different routes, and each route is a trade-off among flexibility, write cost, and query performance.
| System | Approach to semi-structured data | Strengths | What breaks at this scale |
|---|---|---|---|
| ClickHouse | JSON paths managed as dynamic subcolumns; once over the cap, paths fall into a Shared Data structure. | Strong path-based analytics, mature columnar execution. | Constant balancing between subcolumn count, Shared Data, and write cost. Once paths spill into Shared Data, query performance drops sharply. |
| HBase / PostgreSQL | Sparse wide-table model or JSONB to absorb large numbers of optional fields. | Sparse storage, point reads and writes by key. | High write throughput, but filters and aggregations on hot paths usually need a separate analytics engine. |
| Snowflake | VARIANT type as a first-class semi-structured citizen. | Flexible, low integration friction. | Hot-path low-latency queries usually still need manual column extraction and tuning. |
| Elasticsearch | Dynamic Mapping auto-detects fields. | Strong filtering when paired with the inverted index. | Mapping Explosion drives memory, CPU, and metadata costs through the roof; storage bloats accordingly. |
| Iceberg / Parquet | Newly defined Variant type; Parquet supports shredding. | Lakehouse use cases, cross-engine interoperability, semi-structured analytics. | Defines table and file semantics only. Dynamic-field governance and performance depend on the engine; column-count growth still hurts metadata performance. |
Two of these approaches are worth a closer look: ClickHouse's Advanced Serialization and PostgreSQL's JSONB.
2.1 ClickHouse: bounded column count, but encoding efficiency drops
ClickHouse v25.8 introduced the Advanced Shared Data serialization format (see Making complex JSON 58x faster) to mitigate the query performance collapse caused by too many JSON paths. The new format uses a fixed bucket count to cap the total file count, which fixes the worst case (the system being effectively unusable at high path counts).
Availability is better, but it ships with new costs. Because data is split across files, queries have to scan and jump around multiple times, and random reads increase. To keep both writes and merges fast, the system must maintain a copy of the original data, which increases storage costs. The pain is reduced, but at scale, query performance and resource overhead remain suboptimal.
2.2 PostgreSQL: document-friendly, analytics-limited
PostgreSQL's JSONB type parses JSON into a binary representation and supports GIN indexes for key-value lookups. For point queries and full-document reads (SELECT *), JSONB is excellent: the original document doesn't need to be reconstituted from a wall of subcolumns.
But JSONB is fundamentally row-based and lacks columnar optimizations. In analytics scenarios (filtering and aggregating by field), even a single-key query has to parse JSON row by row. There's no way to realize compression and vectorized execution the way a real column store can. As data scale grows, query latency rises significantly.
The pattern across these systems is consistent. Hot paths can be made fast everywhere. The wide tail is where they diverge, and where the cost lands: capped fields, expensive compaction, redundant copies, or row-by-row parsing on the read side. Doris 4.1 takes a different lane.
3. Doris 4.1: deferred materialization plus on-demand metadata loading
Apache Doris 4.1's design choice for handling ultra-wide JSON is not to choose between row- and columnar storage at write time. Let the data evolve toward the right physical shape over time. Two key features are used to support this paradigm
-
DOC mode (deferred JSON Shredding). On the write path, JSON lands in document form efficiently. JSON Shredding happens during compaction, only for hot paths. Write amplification and system pressure drop; throughput goes up.
-
Storage Format V3 (on-demand metadata loading). Column metadata, previously concentrated in the segment Footer, is split into a dedicated structure. At query time, only the relevant column's metadata loads. At 10,000+ paths, memory and I/O drop substantially.
Together, these two capabilities give Doris a more balanced profile across the three dimensions that matter for wide JSON: write throughput, query latency, and metadata/resource cost.
So how does Doris compare to typical alternatives like ClickHouse and PostgreSQL?
-
vs. ClickHouse: Once subcolumns are materialized, Doris uses pure columnar contiguous storage, avoiding the random-read amplification that comes with PAX-style layouts. By default, Doris does not maintain a redundant copy of the original data, which helps keep storage overhead more manageable.
-
vs. PostgreSQL (JSONB): Once a JSON path is materialized, Doris pulls all the levers a column store offers: compression, vectorized execution, predicate pushdown. JSONB stays inside its row-based model; its I/O pattern is a hard limit on analytical queries.
Benchmarks (10,000+ JSON paths, 100 million rows, single 16C / 64 GB / SSD machine, see Section 6 for full setup):
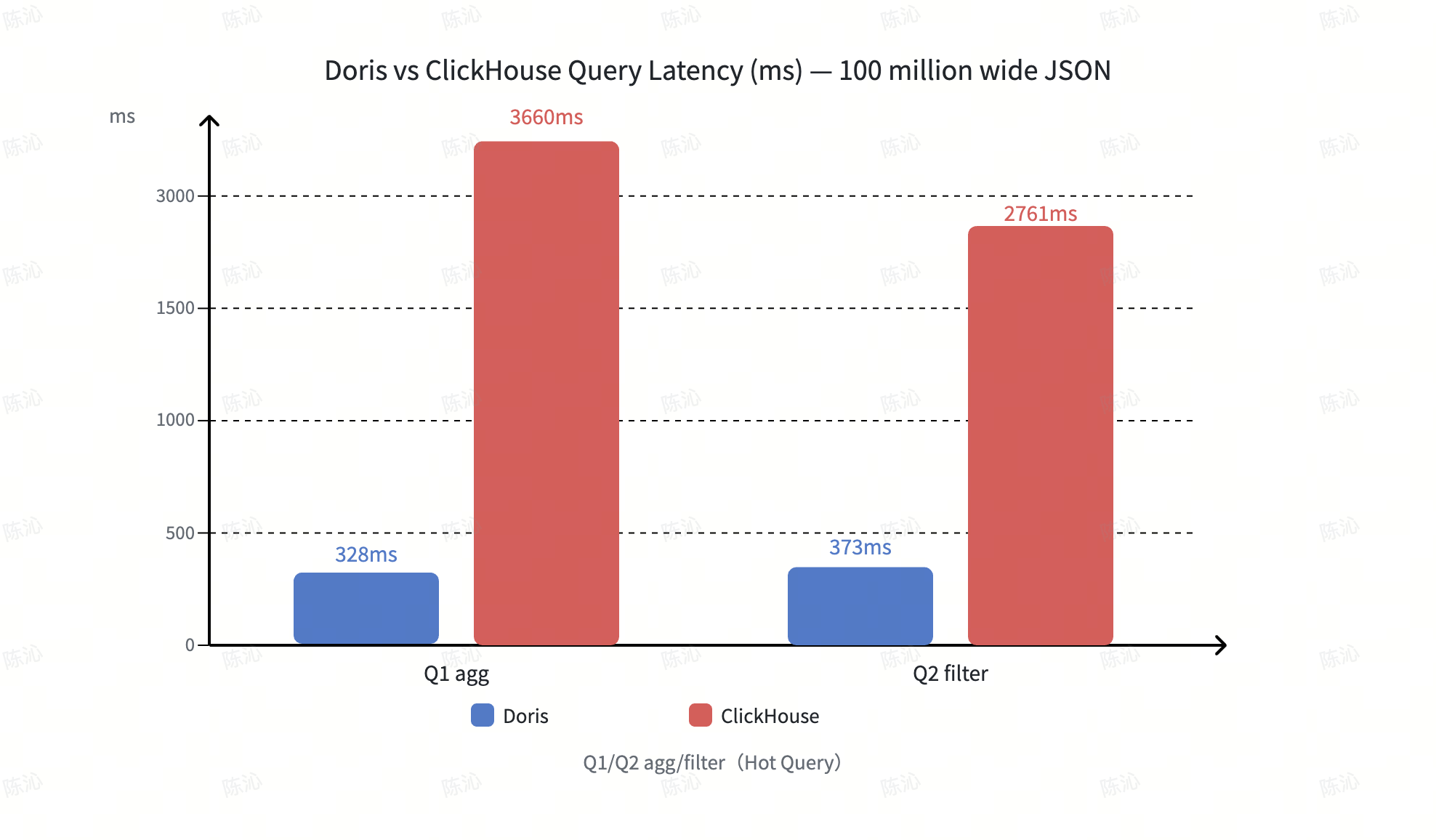
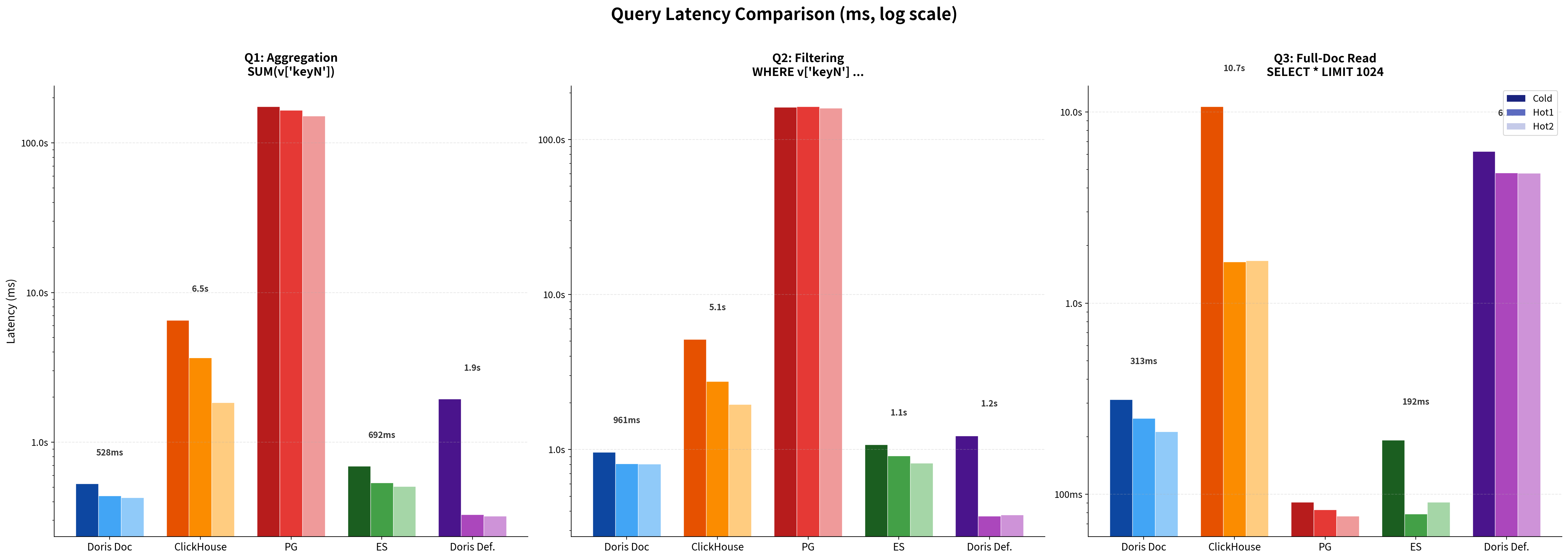
Doris vs. ClickHouse. On wide-JSON aggregation and filtering, Doris keeps query latency in the hundreds of milliseconds. ClickHouse, hit by random reads from the Advanced encoding, runs in seconds. With default configurations, Doris also uses about 60% of ClickHouse's storage.
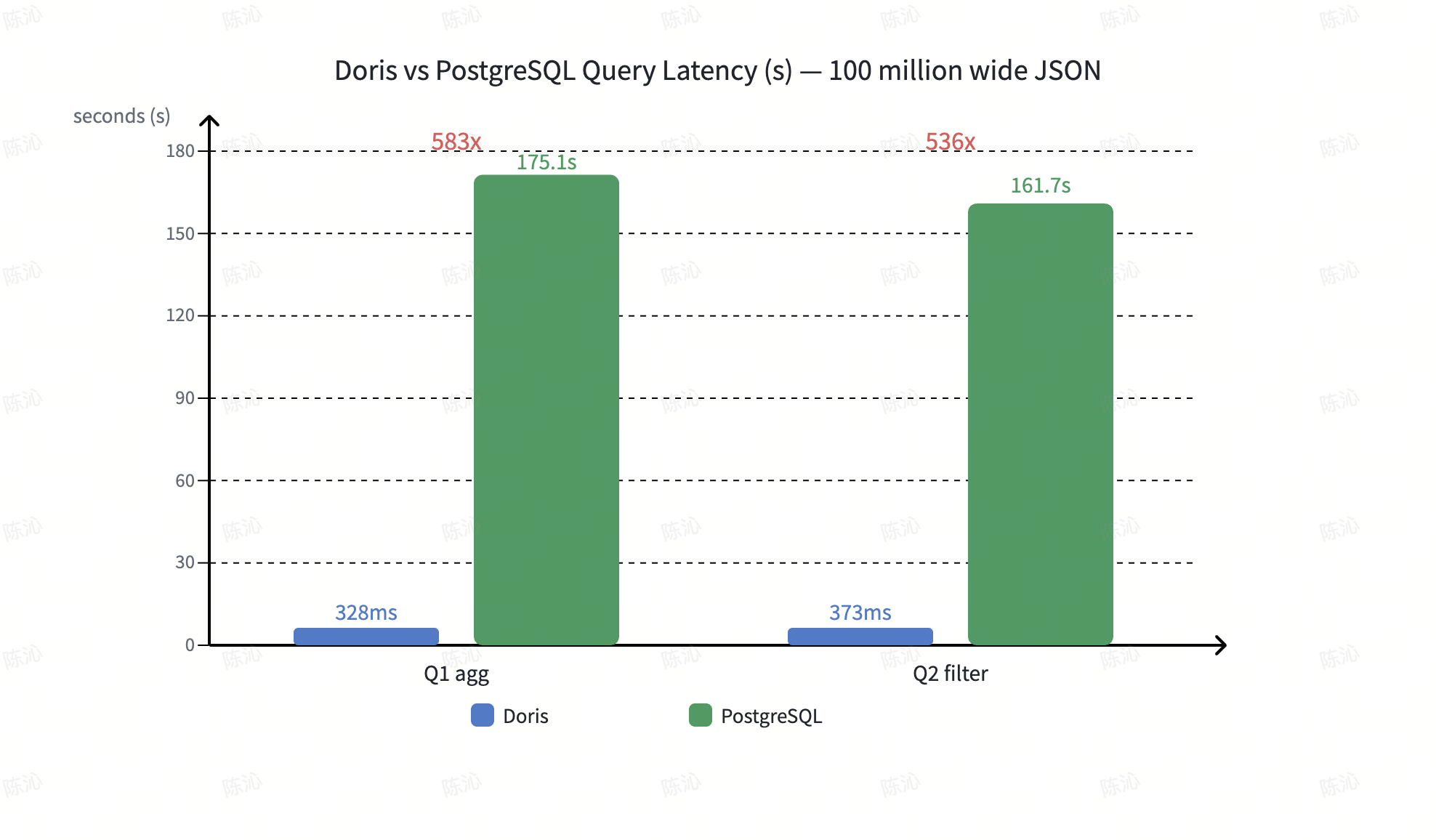
Doris vs. PostgreSQL. PostgreSQL stands out in full-row document reads (Q3). On aggregation and filtering (Q1, Q2), its query latency trails Doris by orders of magnitude, up to several hundred times.
4. DOC mode: Deferred JSON Shredding
In Doris 4.1, DOC mode decouples writes, compaction, and queries into three stages, so the system can sustain write throughput while query performance improves progressively over time:
-
Write stage: store JSON in document form only.
-
Compaction stage: materialize hot paths into subcolumns when the moment is right.
-
Query stage: based on each path's materialization state, pick the best execution path automatically.
4.1 Write stage: encode JSON keys into a hash-sharded doc map
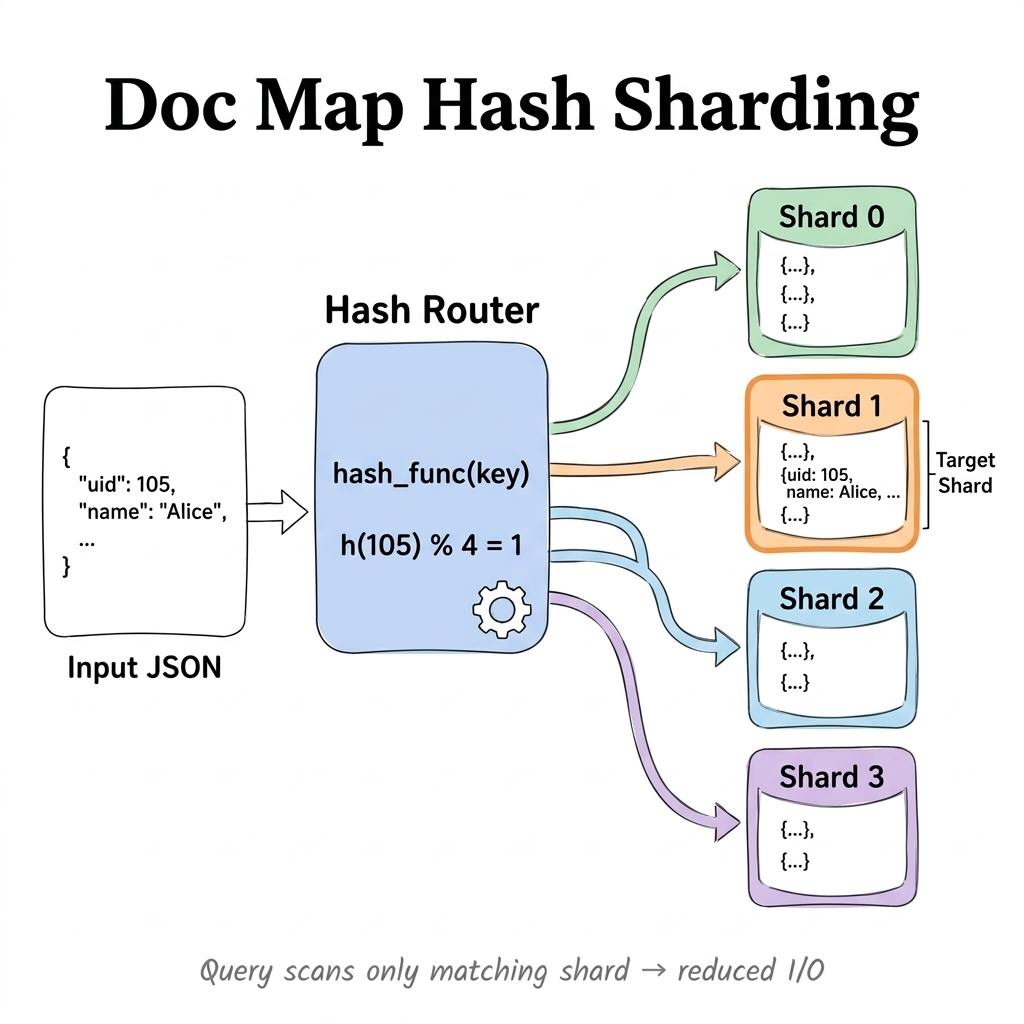
To prioritize write throughput, the engine encodes JSON into a Sharded Map and lays it out in hash-sharded form. The same structure supports efficient SELECT * full-row return and provides a uniform fallback for unmaterialized paths.
The original JSON is split across multiple independent columnar Map<Binary, Binary> shards. The variant_doc_hash_shard_count parameter controls the shard count and keeps the data evenly distributed.
On query fallback, the engine only needs to target and scan the matching shard, avoiding the cost of full-data scans. As a result, write complexity shifts from "grows with unknown path count" to "works against a fixed shard structure," which materially improves stability and scalability.
4.2 Compaction stage: defer materialization
The variant_doc_materialization_min_rows parameter defines when paths get materialized. When a batch is small or hasn't settled yet, the data only writes to the Sharded Map. Hot paths only get extracted into independent subcolumns when compaction triggers and row count crosses the threshold. This deferred decision is significantly more stable than immediate JSON shredding under bursty writes.
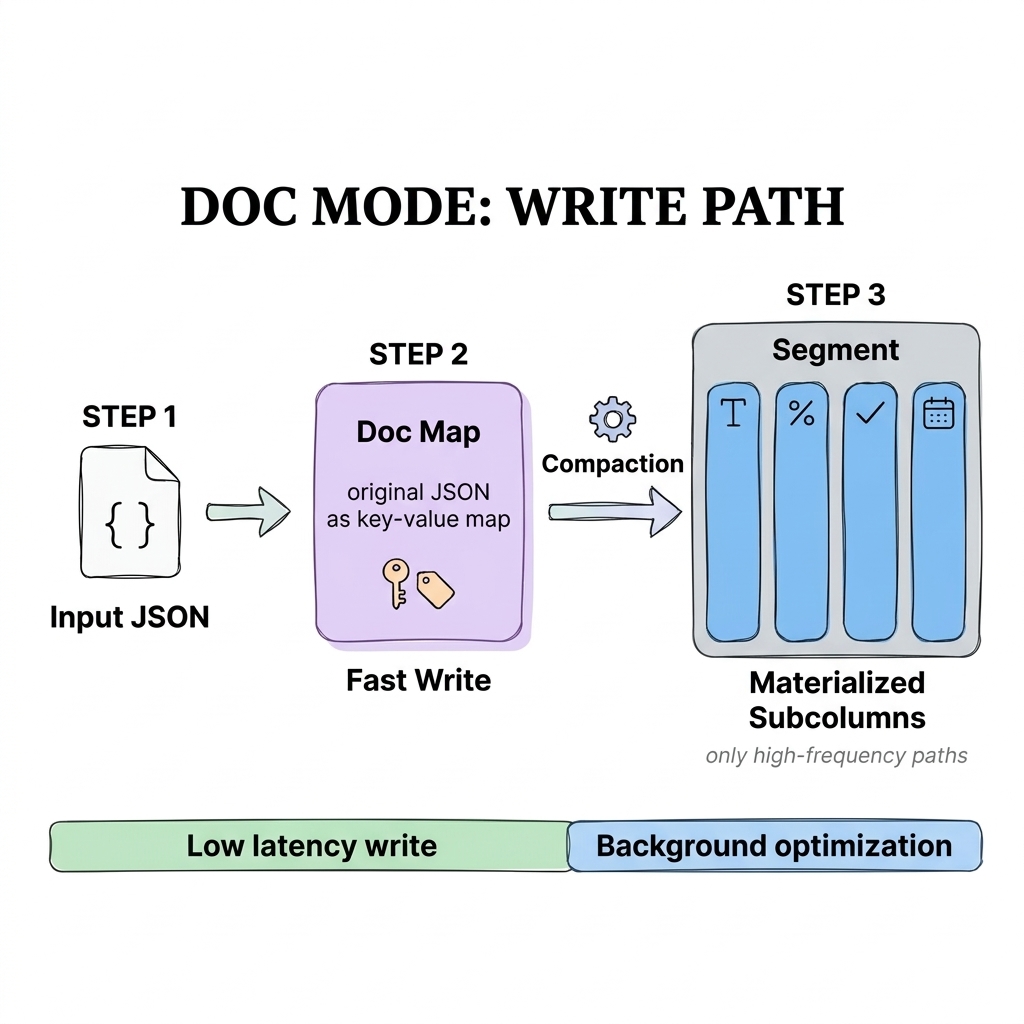
4.3 JSON key evolution constraints, for stability
In agent traces or upstream data without strict naming discipline, JSON keys keep evolving (for example, from score_* to tool_result.*) with no stable boundary. In these cases, raise variant_doc_materialization_min_rows. Most short-lived or low-frequency fields stay in doc-map form, and the system behaves more predictably:
-
Stable write path. The background avoids triggering large-scale field materialization and dictionary encoding constantly, which reduces write amplification and compaction pressure.
-
Efficient full-document reads.
SELECT *returns the original record directly, with no subcolumn reassembly. -
Controlled cold-field access. Low-frequency paths still go through the sharded doc map, slightly slower than columnar but immune to runaway column growth.
Strategically, this is a boundary constraint between performance and controllability: fields can keep evolving, but the storage structure and resource footprint stay bounded.
4.4 Query stage: automatic switching across three read paths
From the query engine's point of view, DOC mode routes each request to the most appropriate read path based on the path's materialization state, balancing performance with flexibility:
-
DOC Materialized. The hot path has already been extracted into a subcolumn. Reads go through the pure columnar path, with full access to optimizations like index pushdown.
-
DOC Map. For
SELECT *or full-document reads, the original document is returned directly. No subcolumn reassembly, very low overhead. -
DOC Map (Sharded). For unmaterialized cold-path queries that can't be returned as a full document, the request routes to the matching hash shard and scans only that shard, which dramatically reduces wasted scanning.
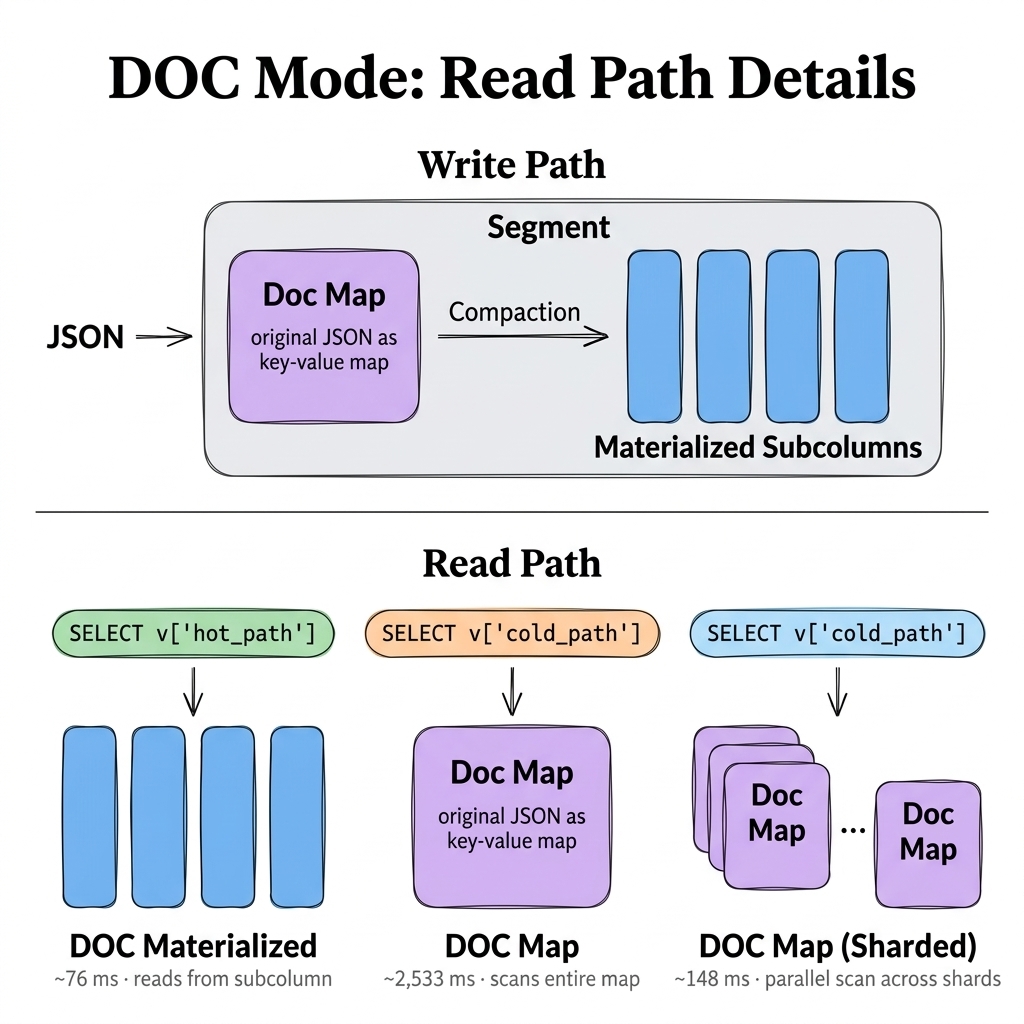
Notes on the figure:
-
Materialized fields take the columnar path (~76 ms), with full column-store advantages.
-
Sharded but unmaterialized fields take a single-shard scan (~148 ms).
-
Everything else falls back to a full doc-map scan (~2,533 ms).
As compaction keeps running in the background, frequently-accessed fields gradually move into the columnar path. Without sacrificing write efficiency, the system optimizes query performance over time and balances reads and writes dynamically.
4.5 When DOC mode pays off
DOC mode delivers a meaningful lift in three classes of workload:
-
High-sparsity logs and event data. The field union is enormous, but each record only fills a few keys, and the structure is highly scattered.
-
Heavy writes plus field bloat. High-throughput ingest combined with rapid field growth has produced visible compaction backlog or write amplification.
-
Mixed access patterns (analytics + full-document reads). Workloads need both field-level analytics and occasional full-document retrieval (SELECT *).
5. Storage Format V3: on-demand metadata
Before Doris 4.1, the system used Segment V2: all column metadata was concentrated in the segment Footer. That layout works well for large sequential scans, but for random reads or narrow queries, it forces the system to load the full Footer every time, with significant I/O and parsing overhead. At wide-JSON scale, this becomes a bottleneck.
Doris 4.1 introduces Storage Format V3 (also known as Segment V3), inspired by file formats such as Lance and Vortex. Metadata is split out of the Footer and loaded on demand. That solves the problems most likely to surface at wide-JSON scale: metadata bloat, slow file open, and high random-read cost. The improvement is most pronounced at initial read time. It's a fit for ultra-wide tables, large numbers of VARIANT subcolumns, object-storage cold starts, and random-read-heavy AI and connected-vehicle semi-structured workloads.
With Storage Format V3 enabled, Doris's cold and hot query performance for DOC mode is more even, with no obvious performance cliff.
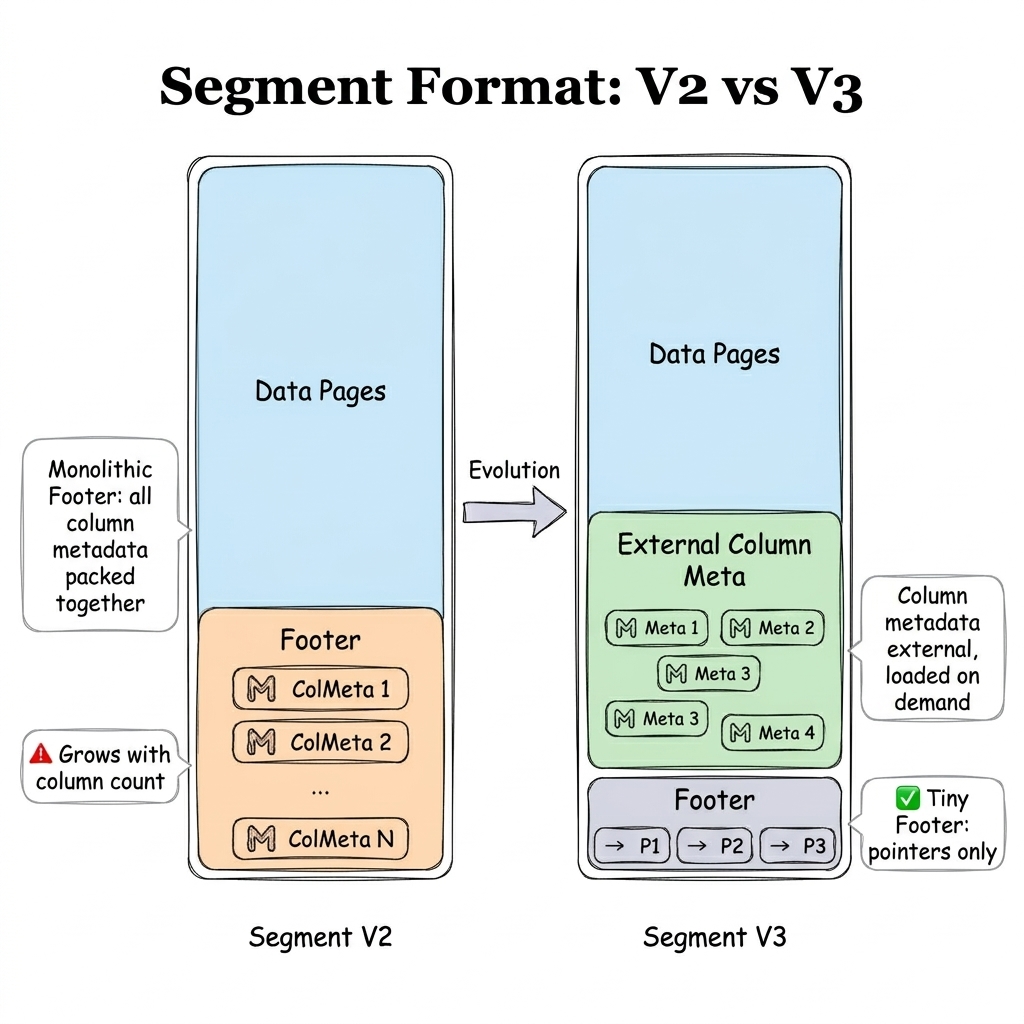
Take an ultra-wide table with 7,000 columns and 10,000 segments. At segment-open time, V3 is dramatically better than V2:
-
Open speed: up to 16× faster.
-
Memory usage: up to 60× lower.
In ultra-wide and high-concurrency workloads, that translates into faster response and lower resource cost.

6. End-to-end performance benchmark
Deferred materialization keeps writes cheap and queries fast at scale. The benchmark below tests whether that holds when ClickHouse, Elasticsearch, and PostgreSQL share the same wide-JSON workload. We mirrored common production conditions: high-concurrency ingestion, random-field queries, and a mix of analytics and full-document reads.
Data shape
-
JSON key union: ~10,000 paths (no schema can be defined in advance).
-
Each row randomly fills 100 keys with random numeric values, simulating high-sparsity wide tables.
-
Total dataset: 100 million rows (~160 GB), split into 1,000 files to simulate frequent ingestion.
Hardware
- Single machine, 16 cores, 64 GB RAM, SSD.
Systems and configurations
| System | Version | Configuration |
|---|---|---|
| Apache Doris | 4.1.0 | VARIANT default (no V3); VARIANT with DOC mode (V3 enabled) |
| ClickHouse | 26.3 | JSON(max_dynamic_paths = 0) + object_shared_data_serialization_version = 'advanced' (the default config produced "Too many open files" errors) |
| Elasticsearch | 9.3.0 | Dynamic Mapping |
| PostgreSQL | 14.4.0 | JSONB type |
Access pattern
High-concurrency writes plus random-field queries (no field-specific tuning).
| Query | SQL pattern | Semantics |
|---|---|---|
| Q1 | SUM(CAST(v['keyN'] AS BIGINT)) | Aggregate analytics on a randomly chosen key |
| Q2 | WHERE CAST(v['keyN'] AS BIGINT) IS NOT NULL AND ... | Filter on a randomly chosen key |
| Q3 | SELECT * ORDER BY ID LIMIT 1024 | Full-document retrieval |
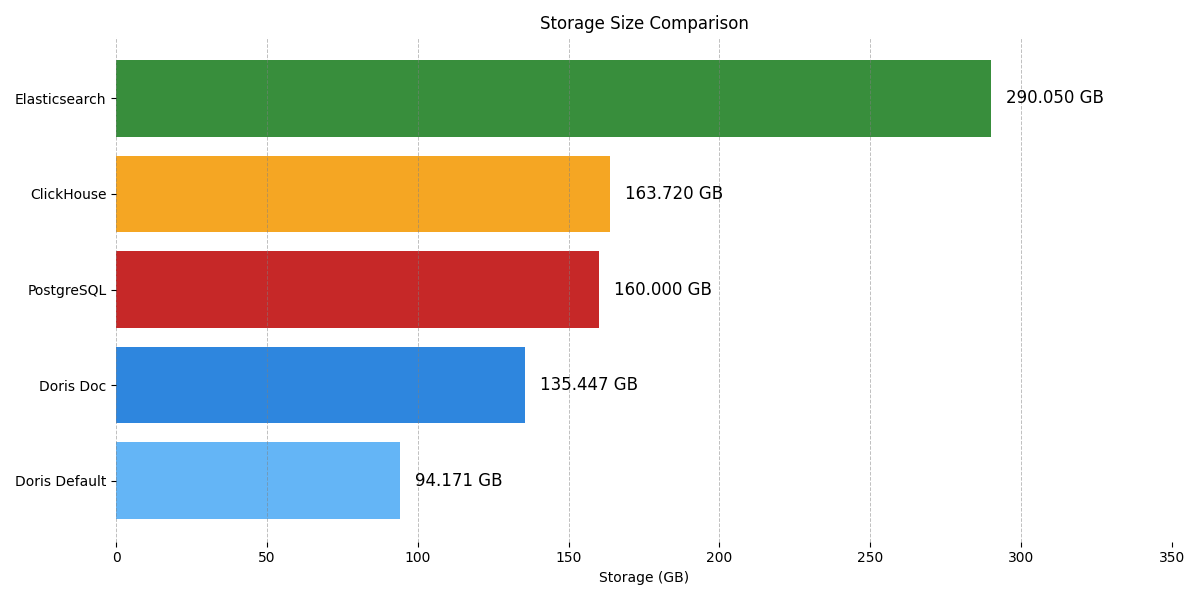
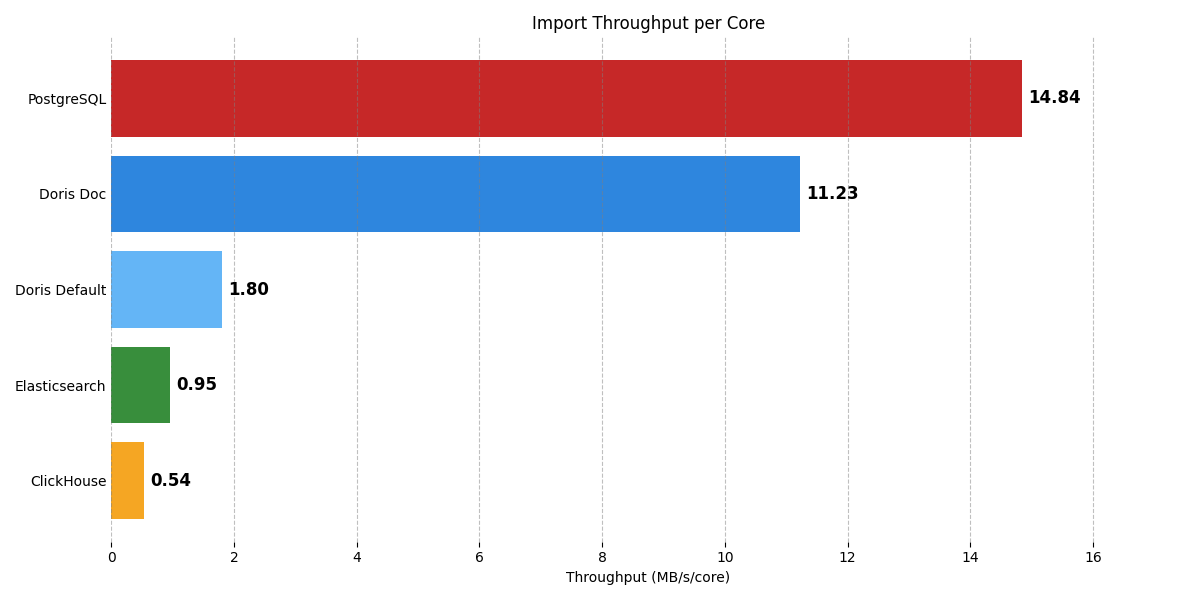
6.1 Storage and import performance
-
Storage usage. Doris with default VARIANT is the most compact, thanks to fully columnar storage and no redundant data, although import is slower.
-
Import performance. PostgreSQL (JSONB) is highest, followed by VARIANT with DOC mode. Both are clearly ahead of ClickHouse, Elasticsearch, and Doris default.
6.2 Query latency (cold and hot)
6.3 Putting it together
Looking at the benchmarks one capability at a time, every system has a strong point:
-
PostgreSQL excels at document storage and full-row reads (Q3).
-
ClickHouse is strong on analytics when the field count is bounded.
-
Elasticsearch has the edge on retrieval-style workloads.
But on the combined wide-JSON workload (high writes + sparse fields + random queries + occasional full-document reads), Doris shows a more balanced profile. Deferred materialization (DOC mode) plus on-demand metadata loading (Storage Format V3) hit a better point on the throughput / latency / resource curve. Specifically:
-
Write performance is close to a document database.
-
Analytical performance is close to a column store.
-
Full-document read efficiency is significantly better than a typical column store.
-
Metadata and column-count bloat stay bounded.
7. Try it on your data
If your JSON keys keep growing and you want to verify the approach quickly, this minimal viable configuration is enough to start:
CREATE TABLE IF NOT EXISTS sensor_data (
ts DATETIME NOT NULL,
device_id VARCHAR(64) NOT NULL,
model VARCHAR(128),
data VARIANT< -- Schema Template, set column attributes as needed
'bat_temp' : DOUBLE,
properties(
'variant_enable_doc_mode' = 'true'
)
>,
INDEX idx_data(data) USING INVERTED PROPERTIES("field_pattern" = "status")
)
DUPLICATE KEY(`ts`, `device_id`)
DISTRIBUTED BY HASH(`device_id`) BUCKETS 16
PROPERTIES (
"replication_num" = "1",
"storage_format" = "V3"
);
Note: in future releases, storage_format = "V3" is expected to become the default for wide-table workloads.
Query syntax stays simple:
SELECT
ts,
CAST(data['bat_temp'] AS DOUBLE) AS bat_temp
FROM sensor_data
WHERE bat_temp > 60
ORDER BY ts DESC
LIMIT 100;
8. Closing
Wide JSON has a single recognizable shape and a recognizable set of wrong answers. Capped-field columnar pushes the long tail into a slow fallback. Row-based JSONB collapses on analytics. Aggressive shredding accelerates hot paths but assumes you can name them up front, and pays for it in compaction at scale.
Apache Doris 4.1's VARIANT, with DOC mode and Storage Format V3, picks a different lane. Writes stay fast because JSON shredding is deferred to compaction. Queries stay fast because materialized paths run at native columnar speed and unmaterialized paths fall back to a sharded doc map rather than a full document scan. Metadata stays small because column metadata is externalized. The result is a wide-JSON system that does not force a tradeoff between write throughput, query latency, and storage cost at 10,000+ paths and 99%+ sparsity.
If your data was JSON because it had to be and the field count keeps climbing, you don't have to absorb the cost of that growth. Spin up VeloDB Cloud, the managed Apache Doris 4.1 service, point it at your real data, and set VARIANT DOC mode and Storage Format V3 in your CREATE TABLE properties. The faster you get out of "this is too wide" and into "this is just a query at the right cost," the better.