



Operational databases like PostgreSQL and MySQL are industry standards for handling high-concurrency transaction processing with strong consistency. Many teams also adopt a sharding strategy to scale PostgreSQL beyond the single-node limits, distributing data across multiple database instances and tables to handle high-concurrency, large-scale workloads.
But the same sharding strategy that works so well for transactions creates serious challenges when teams need real-time analytics: real-time operational dashboards, multi-dimensional business reporting, user behavior analysis, and live monitoring.
Cross-shard JOINs require stitching data from multiple nodes. Multi-dimensional aggregations become expensive and slow. And running heavy analytical queries on your production cluster risks destabilizing the very system that keeps your business running.
The solution isn't to stretch your PostgreSQL database into something it's not designed for. It's to add a dedicated analytical layer next to it. This article walks through how to pair PostgreSQL with Apache Doris to build a Hybrid Transactional/Analytical Processing (HTAP) architecture: letting PostgreSQL stay focused on transactions, while Apache Doris handles analytics with real-time data sync, high-speed aggregations, and high-concurrency query support.
We'll cover the architecture, sync strategies, table design, and real-world results from customers, such as 400% QPS improvement and 70% lower query latency.
Why Running Analytics on OLTP Database Can Break Down
Sharding effectively solves the transactional database scaling problem. It breaks through single-node storage limits, distributes high-concurrency requests (flash sales, peak-hour orders) across multiple nodes, maintains ACID guarantees after splitting, and scales horizontally as business grows.
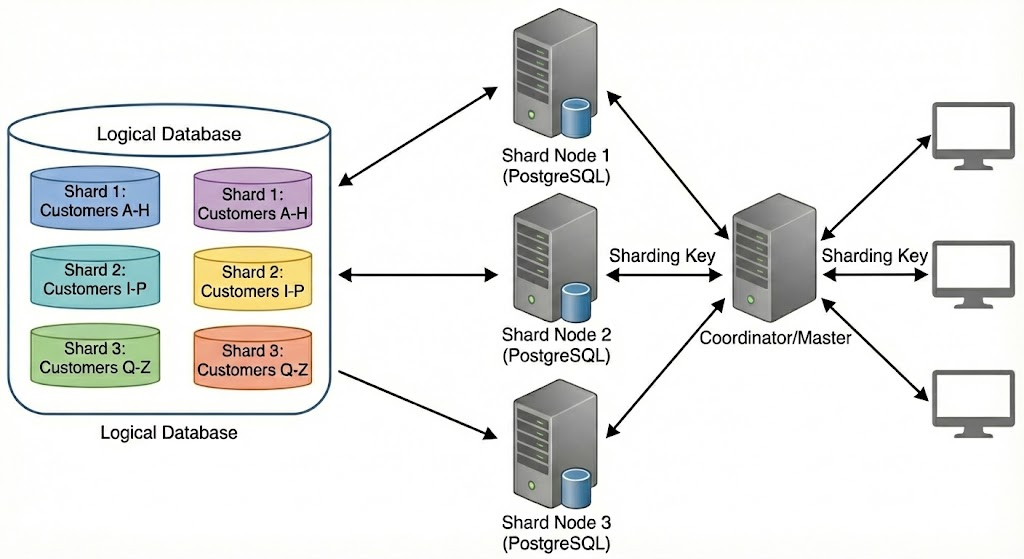
But as analytics demands increase, relying on the same OLTP system to handle both transactions and analytics exposes several fundamental limitations:
-
Slow and complex analytical queries. Cross-shard JOINs and multi-dimensional aggregations require manually stitching data from multiple nodes. The SQL is complex, cross-node data transfer is heavy, and query latency is high.
-
No resource isolation. Analytical workloads consume significant CPU, memory, and I/O. Running them on the same cluster as production transactions creates resource contention, which can slow down transaction processing or even cause timeouts and system instability.
-
Expensive storage for historical data. OLTP systems are optimized for transaction throughput, not storage efficiency. Keeping large volumes of historical data in these systems drives up storage costs significantly.
For PostgreSQL specifically, the challenges run deeper:
-
Table bloat from MVCC. PostgreSQL's Multi-Version Concurrency Control uses an append-only storage model. Every update copies the entire row, accumulating dead tuples that cause table bloat. Analytical queries must scan through this redundant data, driving up I/O costs and degrading query performance.
-
Vacuum overhead. PostgreSQL relies on Autovacuum to clean up dead tuples, but this mechanism is notoriously difficult to tune and easily blocked by the long-running transactions common in analytical workloads. Worse, regular
VACUUMcan't reclaim disk space. That requiresVACUUM FULL, a resource-intensive operation that impacts production availability. -
Connection bottleneck under concurrency. PostgreSQL's process-per-connection model degrades quickly under high-concurrency analytical queries, making it difficult to scale concurrent workloads linearly.
The HTAP Architecture: PostgreSQL + Apache Doris
Apache Doris is a real-time analytical and search database built on MPP (Massively Parallel Processing) architecture. It's designed for high-speed complex queries, real-time data updates, high-concurrency workloads, and is often used in scenarios such as real-time reporting and analytics, real-time monitoring, and user profiling. Doris also integrates well with mainstream data sync tools out of the box.
The core idea of this HTAP architecture is straightforward: physically separate transactions from analytics. PostgreSQL handles online transaction processing. Apache Doris handles analytics. Data flows from PostgreSQL to Apache Doris through sync tools like Kafka, Flink CDC, DataX, or Apache SeaTunnel, keeping the analytical layer up to date without touching the transactional system.
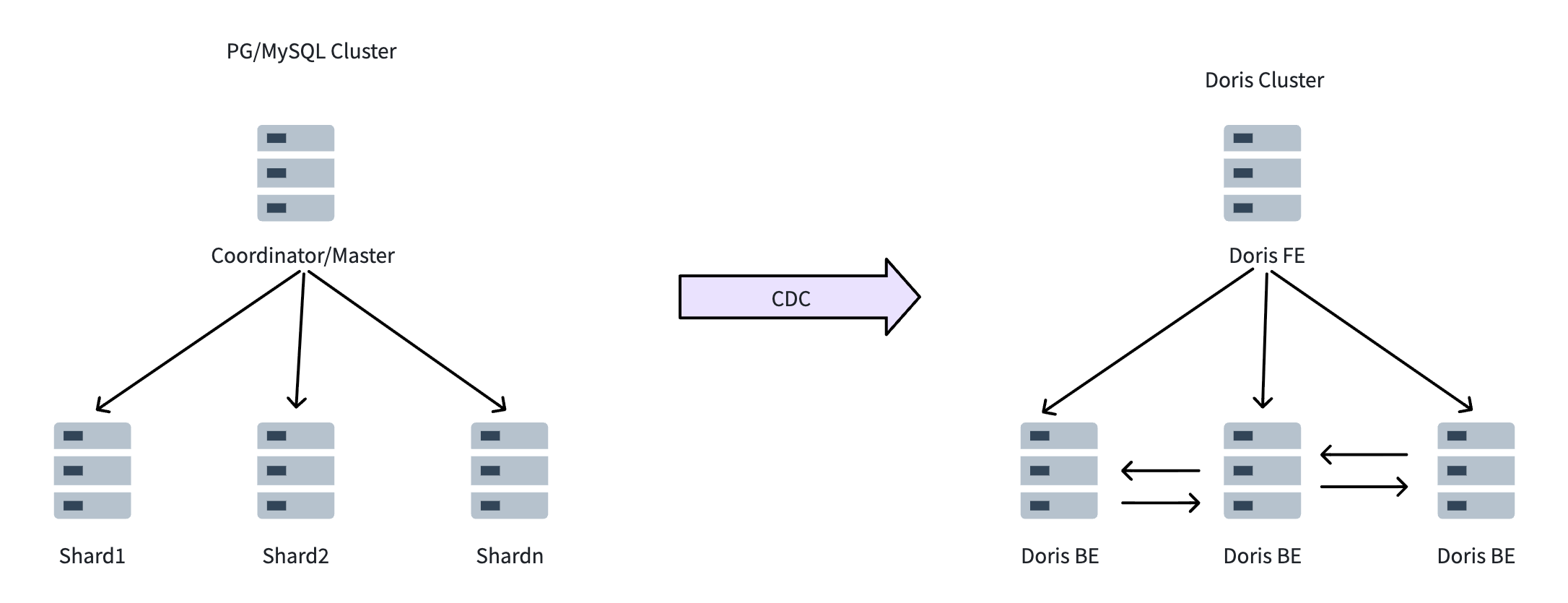
Data Sync Strategy
Data sync is the backbone of this architecture. The right strategy depends on your data and use case:
-
Full sync is used for initial data loading. Tools like DataX or Sqoop read the full dataset from your PostgreSQL/MySQL shards, transform it to match the Apache Doris table schema, and bulk-load it into Doris.
-
Incremental sync captures ongoing changes in real time. Flink CDC monitors INSERT, UPDATE, and DELETE operations from the PostgreSQL log and streams them to Apache Doris. Flink CDC supports checkpoint recovery and deduplication, ensuring data completeness and consistency.
-
Sync frequency should match data volatility. For high-frequency data like order status changes, use real-time sync with latency under 10 seconds. For slower-changing data like user profiles, scheduling an incremental sync every 5 minutes strikes a good balance between freshness and resource usage.
Table Design in Apache Doris
To get the most out of Apache Doris for this architecture, table design should follow these principles:
-
Partitioning: Partition tables by time (e.g., daily) or business dimensions (e.g., region, product line) to reduce the scan range for analytical queries.
-
Bucketing: For large tables, bucket by frequently queried columns like user ID or order ID. This distributes data evenly across Doris nodes and takes full advantage of MPP parallel computation.
-
Table engine selection. Use the Merge-on-Write (MOW) model for core business tables that need real-time, row-level updates. Use the Aggregate model for batch analytics tables where pre-aggregation can speed up queries.
Core Advantages
Real-Time Data Updates
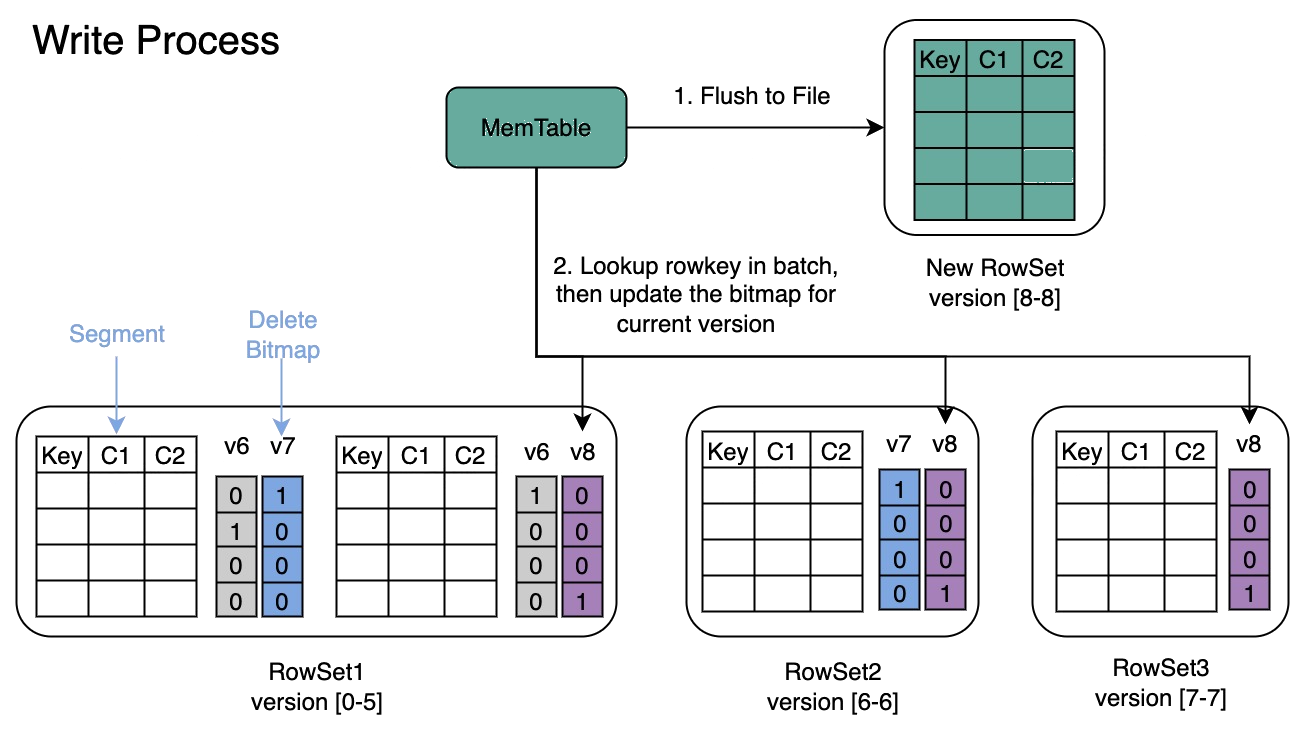
Apache Doris' Merge-on-Write (MOW) engine is built specifically for real-time update scenarios. Unlike traditional approaches that rely on heavy background compaction, MOW merges data at write time: updates are applied to the target data blocks during ingestion, making changes visible within seconds.
This design is a natural fit for syncing transactional data, such as real-time order status changes. MOW supports the full range of DML operations (INSERT, DELETE, UPDATE, UPSERT) and works seamlessly with CDC tools and other data ingestion pipelines. Existing SQL queries and key Doris features (vectorized execution engine, materialized views, partition TTL, and more) work with MOW tables out of the box, with no additional adaptation required.
High-Speed Analytical Queries
Most database benchmarks run on static datasets. But in production, data is constantly being updated. Performance under active updates is what actually matters.
For example, on the Star Schema Benchmark (SSB) SF100 dataset, with 25% of the data under continuous updates, Apache Doris is 25x faster than ClickHouse in overall performance, showing a significant advantage in real-world, update-heavy scenarios.
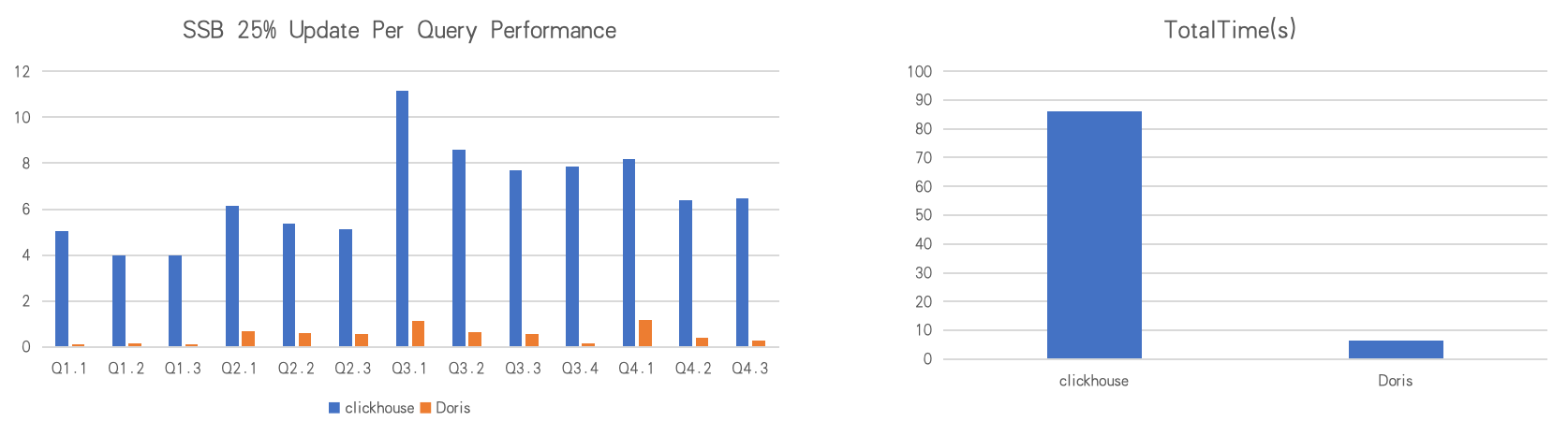
Reference: Apache Doris vs. ClickHouse in Real-Time Updates
Apache Doris' performance advantage comes from two areas:
First, the query engine. Apache Doris uses a vectorized execution engine that processes data in batches to reduce per-instruction overhead. Its cost-based optimizer (CBO) analyzes data statistics to automatically select optimal query plans, including JOIN ordering, scan strategies, and aggregation approaches, minimizing execution cost for complex queries.
Second, the storage architecture. The MOW engine sorts, encodes, and merges data at write time, producing clean, well-organized storage structures. At query time, there are no scattered delta logs to scan and no on-the-fly merge calculations. This "merge at write, lightweight at read" design approach keeps query latency stable and predictable, which is critical for latency-sensitive use cases like real-time dashboards and SLA-bound reporting.
Workload Isolation
By moving analytical workloads to Apache Doris, transactions and analytics run on physically separate clusters. This eliminates the resource contention that occurs when both workloads share the same system: no more analytical queries consuming CPU and memory that production transactions need, no more risk of transaction timeouts caused by a heavy report running at the wrong time.
PostgreSQL stays focused on what it does best: processing transactions. Apache Doris handles all the analytical heavy lifting independently. Each system gets its own resources, and neither interferes with the other.
Lower Storage Costs
Apache Doris supports tiered storage in both its deployment modes to optimize cost:
In compute-storage separated mode, hot data (frequently accessed, latency-sensitive) is cached on local disks at the compute nodes for fast response. Cold data (infrequently accessed, large volumes) is stored in S3-compatible object storage (AWS S3, MinIO, etc.), removing local storage constraints and significantly reducing long-term storage costs.
In compute-storage coupled mode, Apache Doris supports multi-tier storage across different media: hot data on SSDs for high IOPS and low latency, cold data on HDDs for lower hardware and maintenance costs.
Both modes use intelligent data tiering based on access patterns, achieving the same goal: high performance for hot data, low cost for cold data.
Real-World Usecases and Results
Semir: 400% QPS Improvement (MySQL)
Semir is a leading apparel and clothing retailer in Asia, with 8,000+ stores across online and offline channels. To support its omnichannel inventory management platform, Semir replaced its Elasticsearch + distributed MySQL architecture with VeloDB (cloud service powered by Apache Doris), unifying analytics across 16+ core business lines.
Results:
-
400% QPS improvement for complex queries, reaching 200+ QPS
-
Resource isolation between online order queries and batch BI analytics using separate compute groups on a compute-storage separated architecture
-
Elastic scaling during important livestream sales events, with no downtime or data migration required
-
Simplified architecture replacing a dual-system setup, supporting everything from simple filters to complex multi-table JOINs in one system
Key Improvement: Billion-row inventory aggregation queries are now complete in under 8 seconds, operational overhead dropped significantly, and the system runs stably during peak business periods, providing reliable high-concurrency analytics across all retail channels.
Tianyancha: 70% Lower Query Latency (PostgreSQL)
Tianyancha is an enterprise data service company in Asia, providing commercial, financial, and legal information on 300+ million companies across 300+ data dimensions. As the platform's due diligence capabilities expanded, it needed to support ad-hoc queries and user segmentation for internal marketing and operations teams.
Tianyancha replaced its mixed architecture of Apache Hive, MySQL, PostgreSQL, and Elasticsearch with Apache Doris.
Results:
-
Ad-hoc query capability: Previously, every new analytics request required building and testing a data model in Hive, then scheduling the job in MySQL. Now, with all detailed data in Apache Doris, new requests only need query conditions configured to run ad-hoc queries, with no custom development required.
-
Fast user segmentation: For segmentation tasks with result sets under 5 million, Apache Doris delivers millisecond-level response. Through optimized continuous user ID mapping, segmentation latency dropped by 70%.
-
Simplified architecture: Eliminated complex read/write operations across multiple components. User tags no longer need to be predefined; they're generated automatically based on task conditions, which streamlined the segmentation workflow and made A/B testing far more flexible.
-
Stable high-volume ingestion: Handles nearly 1 billion new records per day, using different data models for different scenarios: Unique model for MySQL data, Duplicate model for logs, and Aggregate model for DWS-layer data.
Summary
PostgreSQL and MySQL with sharding remain the proven choice for high-concurrency transaction processing. But they were never designed for the real-time analytics demands that modern businesses face. This HTAP architecture, pairing your OLTP system with Apache Doris, separates transactions from analytics at the infrastructure level: each system does what it's best at, without compromising the other.
The result is faster analytical queries, stable transaction performance, and lower storage costs. If you're running analytical workloads on your PostgreSQL or MySQL cluster and feeling the strain, this architecture is worth exploring.
To learn more about Apache Doris, join the community on Slack. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.


