



The Real Problem: Separating Search and Analytics
Search engines and data warehouses solve different problems. Search engines find the most relevant documents for a query. Data warehouses compute joins, filters, and aggregations across datasets.
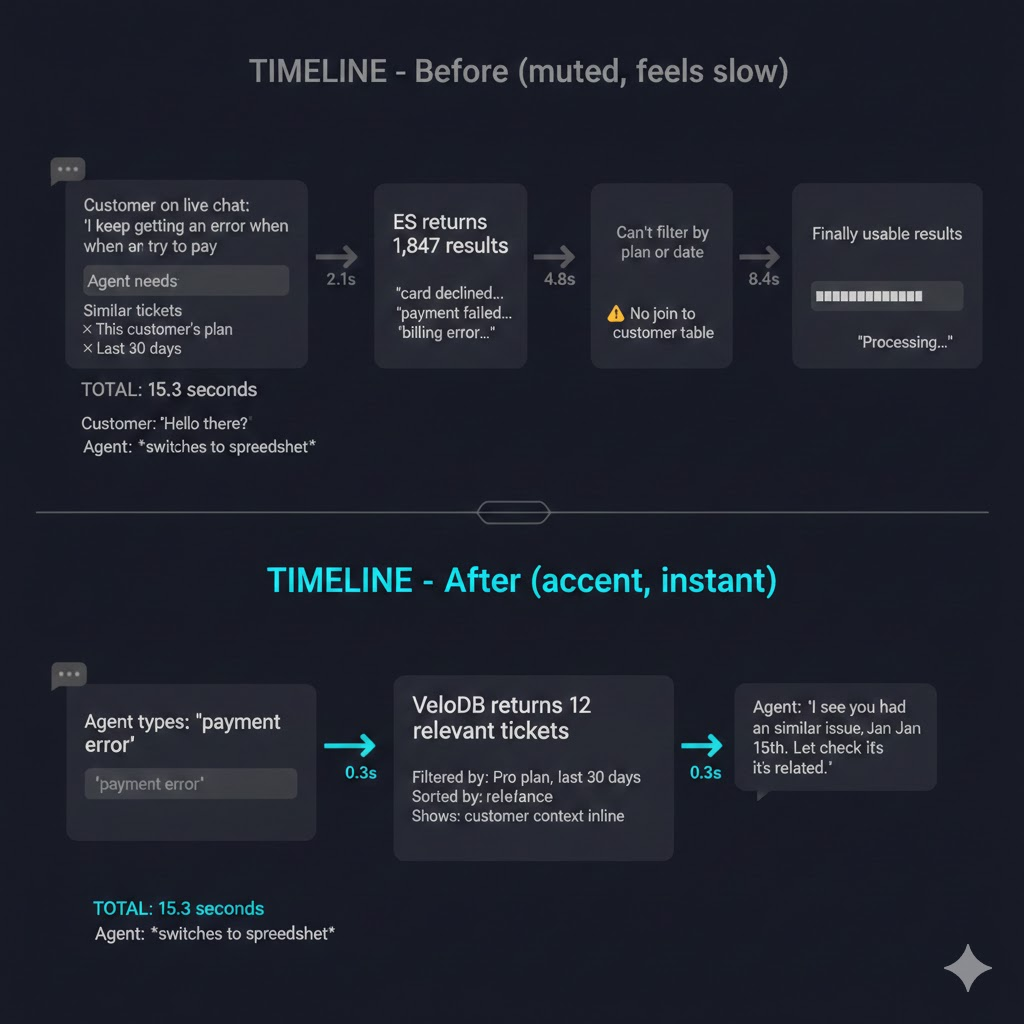
Most platforms need both search and analytics. Imagine a holiday sale at its peak. A customer searches for "blue running shoes under $100." To provide a great experience, your system must instantly perform a full-text search, filter for in-stock items, and apply personalized membership pricing.
Standard search engines handle this well. However, requirements rarely stay simple.
If Product Managers want to rank those results by real-time popularity, join your search index with a live stream of sales data from the last hour, then architecture begins to struggle.
Whether you try to flatten your data into wide tables, build complex sync pipelines, or merge results at the application layer, you eventually hit a ceiling. You aren't just managing latency; you’re navigating the fundamental limitations of a split system.
The Cost of Running Search and Analytics Separately
When you force search and analytics to work together in separate environments, you pay three "taxes" that stall growth:
- Capability Gaps: You lose the ability to perform native, cross-system queries. Without a unified engine, "joining" search relevance with live analytical aggregates becomes a manual coding nightmare rather than a simple query.
- Operational drag. The sync pipeline needs monitoring, alerting, backfill logic, and schema migration handling. One engineer loses 15-20% of their time here instead of building features.
- Incident surface. Elasticsearch mappings are schema-on-write—field types lock on first index. Dynamic fields from integrations or user customization multiply mapping conflicts. One platform with 2,400 custom fields had a 4-hour outage from a single type mismatch.
VeloDB eliminates the split by embedding inverted indexes in the columnar engine. The cross-entity query becomes SQL:
SELECT t.*, c.tier, c.ltv
FROM tickets t
JOIN customers c ON t.customer_id = c.id
WHERE t.content MATCH_PHRASE 'payment failed'
AND c.tier = 'enterprise'
AND c.ltv > 50000
No sync pipeline. No application-side joins. One query, one system.
Unifying Search and Analytics with VeloDB
VeloDB embeds inverted indexes directly in the columnar storage engine. This isn't a bolt-on—the two structures share segment files, memory management, and query planning.
This single architectural change enables three capabilities:
-
Search as SQL predicate. The
MATCH_PHRASEoperator returns a bitmap of matching row IDs. That bitmap feeds directly into the query planner alongside columnar filters. JOINs, WHERE clauses, and relevance scoring execute in one pass. -
Unified storage. Inverted index and columnar data live in the same segment files. A write is immediately visible to both search and analytical queries. No replication lag because there's nothing to replicate.
-
Pattern-based indexing. Instead of declaring each field, you define patterns:
text_*gets full-text search,phone_*gets prefix matching. New fields inherit behavior automatically based on naming convention.
The following sections explain each mechanism in detail.
Search as SQL Predicate

The MATCH_PHRASE operator integrates text search into SQL query planning. Here's how execution works:
- Index evaluation happens first. When the query planner sees
MATCH_PHRASE 'payment failed', it reads the inverted index and produces a bitmap—a compressed list of matching row IDs. This is an O(terms) lookup, not a table scan. - The bitmap becomes a filter. Before any join executes, the bitmap filters the probe side. A 500M-row tickets table with 50K matches becomes a 50K-row input to the join. The columnar engine never touches the other 499.95M rows.
- Columnar predicates apply next. Filters like
c.tier = 'enterprise'run on column segments using SIMD operations. The engine intersects these results with the text-match bitmap. - Joins execute on the reduced set. The hash join builds on the smaller, filtered dataset. This means joining 50K ticket rows against a 2M customer table—not 500M against 2M.
BM25 relevance scores compute during index evaluation and expose through score(). You can sort by relevance, filter by score threshold, or return it as a column.
Unified Storage
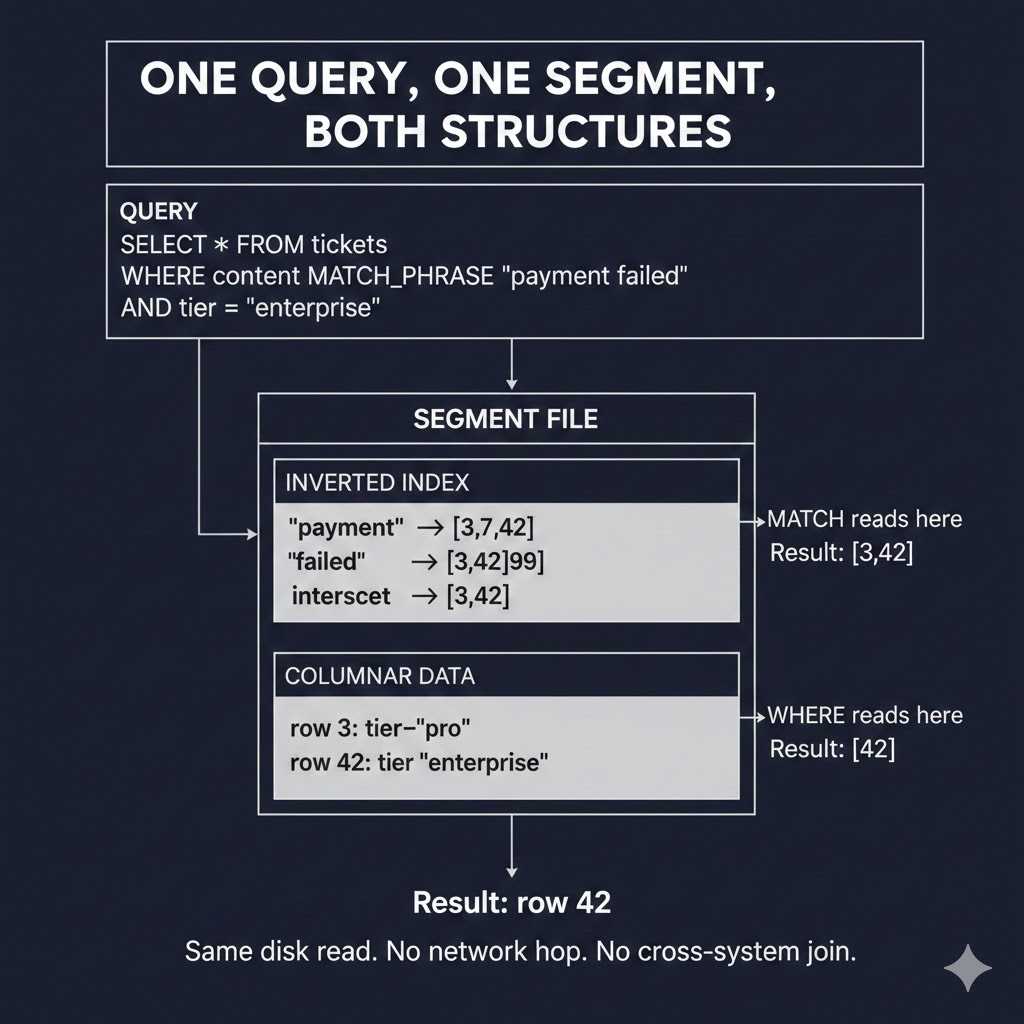
Inverted index and columnar data live in the same segment files. This eliminates sync lag because there's no second system to sync to.
Here's what happens on write:
- Data lands in a write-ahead log (shared by both index types)
- The columnar segment builder extracts column values
- The inverted index builder tokenizes text fields and updates term dictionaries
- Both structures flush to the same segment file
A row written at T+0 is queryable by both SELECT and MATCH_PHRASE at T+0. No background job. No eventual consistency window.
Users searching for a record updated seconds ago will find it. Queries work the same way: a MATCH_PHRASE predicate reads from the inverted index, a WHERE clause reads from columnar storage, and both happen in one query against one data source.
One observability platform replaced 30+ Elasticsearch clusters and a data warehouse with a single system of VeloDB Enterprise: 200 billion records, 47% reduction in compute. The sync pipeline team moved to feature development.
Pattern-Based Indexing
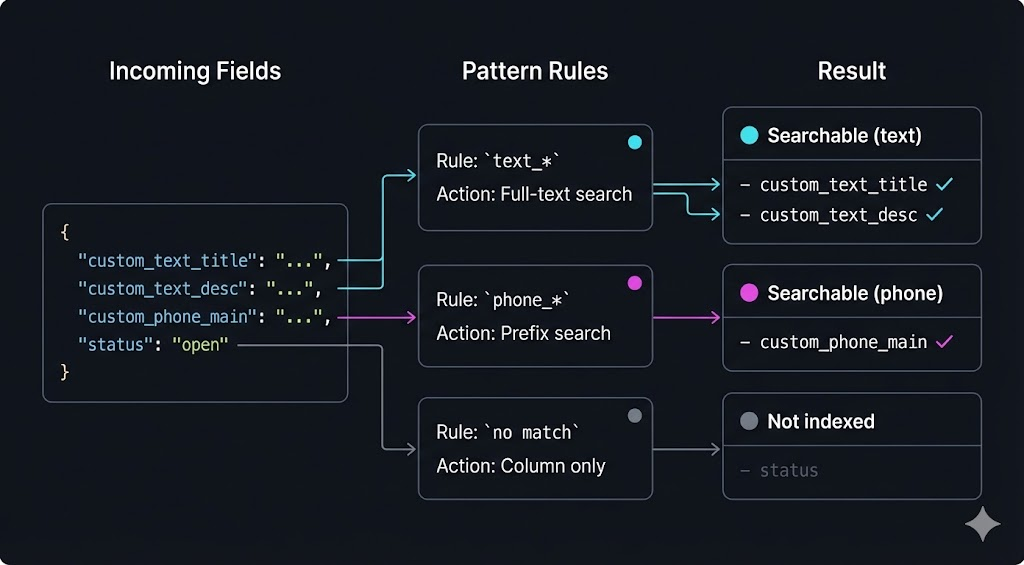
Instead of declaring each field individually, you define patterns. New fields inherit index behavior automatically based on naming conventions.
Elasticsearch uses schema-on-write: the first document defines field types, and conflicts cause failures. Teams with dynamic fields—user-created attributes, integration metadata, product customization—hit mapping explosions.
VeloDB inverts this with pattern matching on VARIANT columns:
CREATE TABLE tickets (
id BIGINT,
content TEXT,
custom_fields VARIANT NOT NULL,
INDEX idx_content (content) USING INVERTED
PROPERTIES("parser" = "unicode", "support_phrase" = "true"),
INDEX idx_text (custom_fields) USING INVERTED
PROPERTIES("field_pattern" = "text_*", "parser" = "unicode", "support_phrase" = "true"),
INDEX idx_phone (custom_fields) USING INVERTED
PROPERTIES("field_pattern" = "phone_*", "support_phrase" = "false"),
INDEX idx_id (custom_fields) USING INVERTED
PROPERTIES("field_pattern" = "id_*")
) DUPLICATE KEY(id)
DISTRIBUTED BY HASH(id) BUCKETS 16;
When a field named text_customer_notes arrives in the VARIANT column, it matches text_* and inherits full-text search with Unicode tokenization. A field named phone_mobile matches phone_* and gets prefix-optimized indexing—users can type "415" to find "+1-415-555-1234". No manual mapping. No reindex job.
One deployment manages 8,000+ dynamic fields per object type. Schema changes that previously required a support ticket and 2-day turnaround now deploy automatically.
When Unified Search and Analytics Is the Right Fit
Three signals that unified search-analytics fits your platform:
-
Search + filter in one query. Your users don't just search—they search, then filter by business data, then sort by metrics. Today this requires exporting IDs from search, querying the warehouse, joining in application code. If that workflow exists, this replaces it.
-
Redundant infrastructure. You maintain Elasticsearch for search and a warehouse for analytics. Unified storage consolidates both workloads—fewer machines, no sync pipelines, less operational labor.
-
Schema incidents. Mapping conflicts have caused outages. Adding searchable fields requires coordination. If schema management consumes meaningful engineering time, pattern-based indexing removes it.
If you recognize one or more of these, this architecture fits your workload.
Conclusion
When users need to simultaneously perform search, filtering, joining, and aggregation within a single workflow, running search and analytics as separate systems transforms simple problems into complex processes: latency increases, schemas break, and engineering time is spent on synchronization tasks rather than feature development.
Unified search and analytics bridges this gap.
By embedding inverted indexes directly into the columnar engine, search becomes a standard predicate within SQL statements. Data written becomes instantly queryable, schema evolution requires no reindexing, and queries that once demanded multi-system coordination now converge into a single execution plan. This isn't adding a new component to your tech stack, it's eliminating an entire category of operational and architectural complexity.
If your platform is suffering from the costs of running search and analytics separately, VeloDB Cloud is designed to eliminate this pain point.
Start your free trial on VeloDB Cloud — includes hands-on tutorials for:
- Setting up full-text search indexes
- Writing MATCH queries with JOINs and aggregations
- Configuring pattern-based indexing for dynamic schemas
- Migrating from Elasticsearch
No credit card required. Your first query runs in minutes.


