



Agent observability is fundamentally different from traditional observability.
Traditional logs follow a flat structure: timestamp, log level, service name, error code, and latency. Events have clear boundaries, call chains are predictable, and the schema stays stable.
Agent execution is harder to predict. A single request can involve multiple rounds of reasoning, external tool calls, vector retrieval, and even coordination across sub-agents. When something goes wrong, the question is rarely "which line threw an error?" The questions look more like:
- Why did the agent make this decision at this step?
- Which reasoning step produced a hallucination?
- How was the prompt dynamically assembled before it reached the model?
- Why did token consumption spike in this run?
The goal of agent observability has shifted from recording outcomes to reconstructing the full execution path, and that shift puts new demands on the underlying data infrastructure.
Most teams reach for one of two approaches to store agent traces: flatten all JSON fields into wide columns, or store the JSON payload as a string. Both face hard limits in production. Flattening breaks the nested execution tree and can't keep up as agents add new tool calls and attributes. String storage preserves the structure but turns every query into a full table scan.
This article covers a hybrid storage solution that uses Apache Doris's VARIANT data type for dynamic JSON payloads, inverted indexes for full-text search on long text and JSON fields, and regular columns for stable fields.
The Problem with Flattening: Broken Execution Trees and Runaway DDL
When handling large volumes of agent logs, many teams flatten all JSON fields into one wide table. This creates two problems.
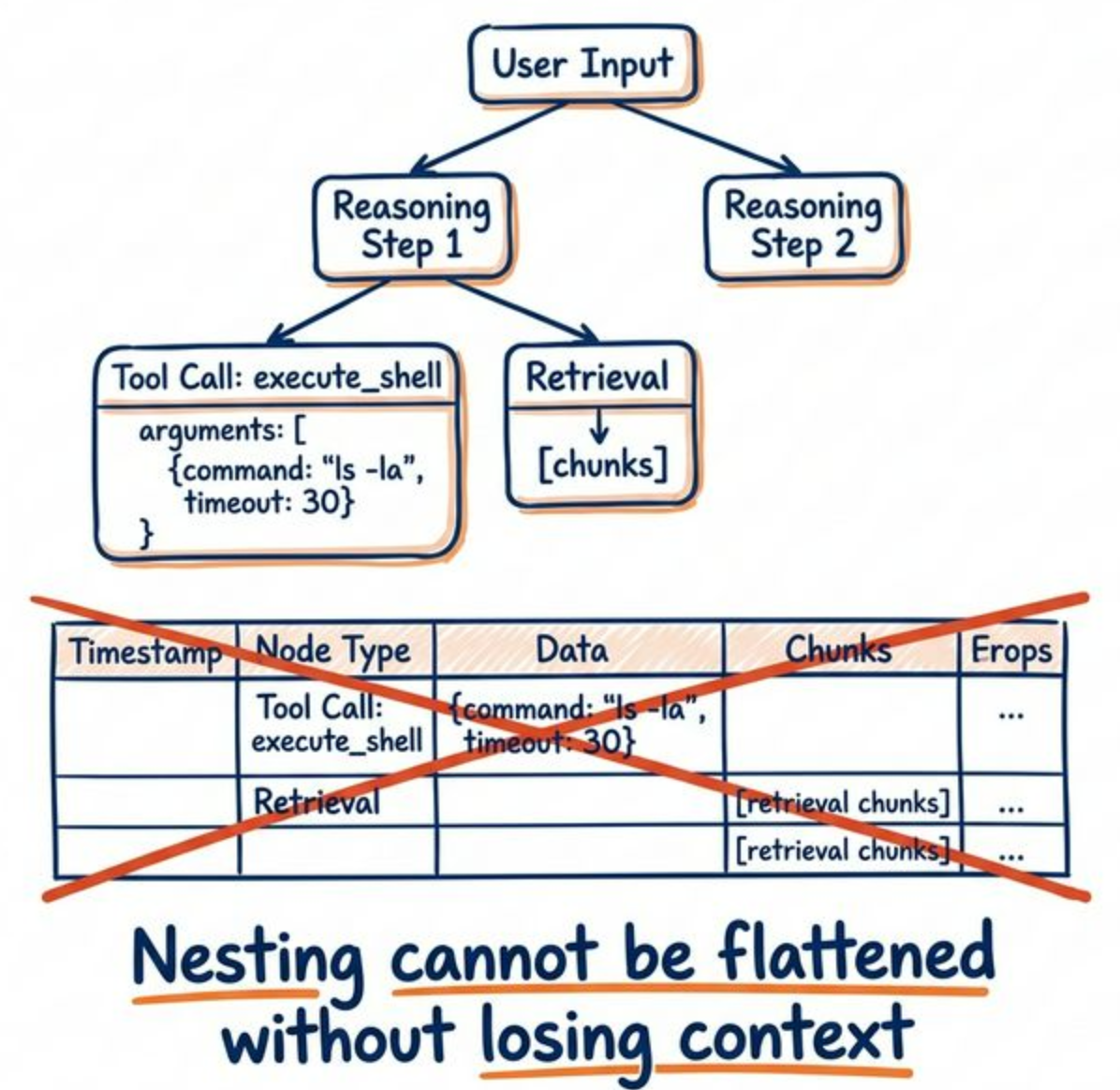
1. Flattening destroys the nested execution tree
In agent use cases, JSON carries more than data. Its structure naturally represents how messages, tool arguments, retrieval results, and execution steps relate to each other. A single request often contains arrays (multiple conversation turns) and tree structures (nested spans).
Here's a typical agent span:
{
"trace_id": "tr-xyz-123",
"span_id": "sp-456",
"tool_call": {
"tool_name": "execute_shell",
"args": {
"command": "grep -r 'todo' .",
"timeout_ms": 5000
}
},
"reasoning_step": [
{"thought": "Need to search codebase for missing items"},
{"action": "Calling execute_shell"}
]
}
Some fields can be extracted at query time: tool_name, latency, token_usage. But for reasoning_step (an array) or nested child spans with hierarchical relationships, flattening at ingest destroys the original tree structure. This makes step replay, context association, and fine-grained JSON path queries difficult.
2. Schema evolves faster than flat tables can handle
Agent codebases move fast. Today the schema has tool_name. Tomorrow it might add retrieval_chunks, guardrail_verdict, or reasoning_budget. With a rigid fixed-schema approach, every new field requires an ALTER TABLE, and those statements will pile up.
The Problem with String Storage: Full Table Scans at Scale
Storing the entire JSON payload as a String column works on a small scale. It keeps the structure intact and requires no upfront schema design. However, querying becomes more difficult at scale.
Consider a typical debugging scenario:
An AI agent log table ingests billions of events every day, with the full payload stored as a string. One day, error rates spike on an MCP tool in production. The on-call engineer needs to find all requests from the past hour where tool_name='retrieve_docs', grouped by model version, tenant, and error type, with P95 latency.
This looks like a routine observability query. But with those JSON fields buried inside a String column, the query engine's optimizer can't apply predicate pushdown or skip data. The only option is to read the full JSON body for every row and run JSON_EXTRACT against each one.
The target data may represent only 0.1% of the table, but the query forces a full table scan. The query scans several terabytes just to debug a single tool's errors from the last hour. This results in saturated disk I/O, CPU pinned to JSON parsing, and query latency high enough to stall the cluster under heavy load.
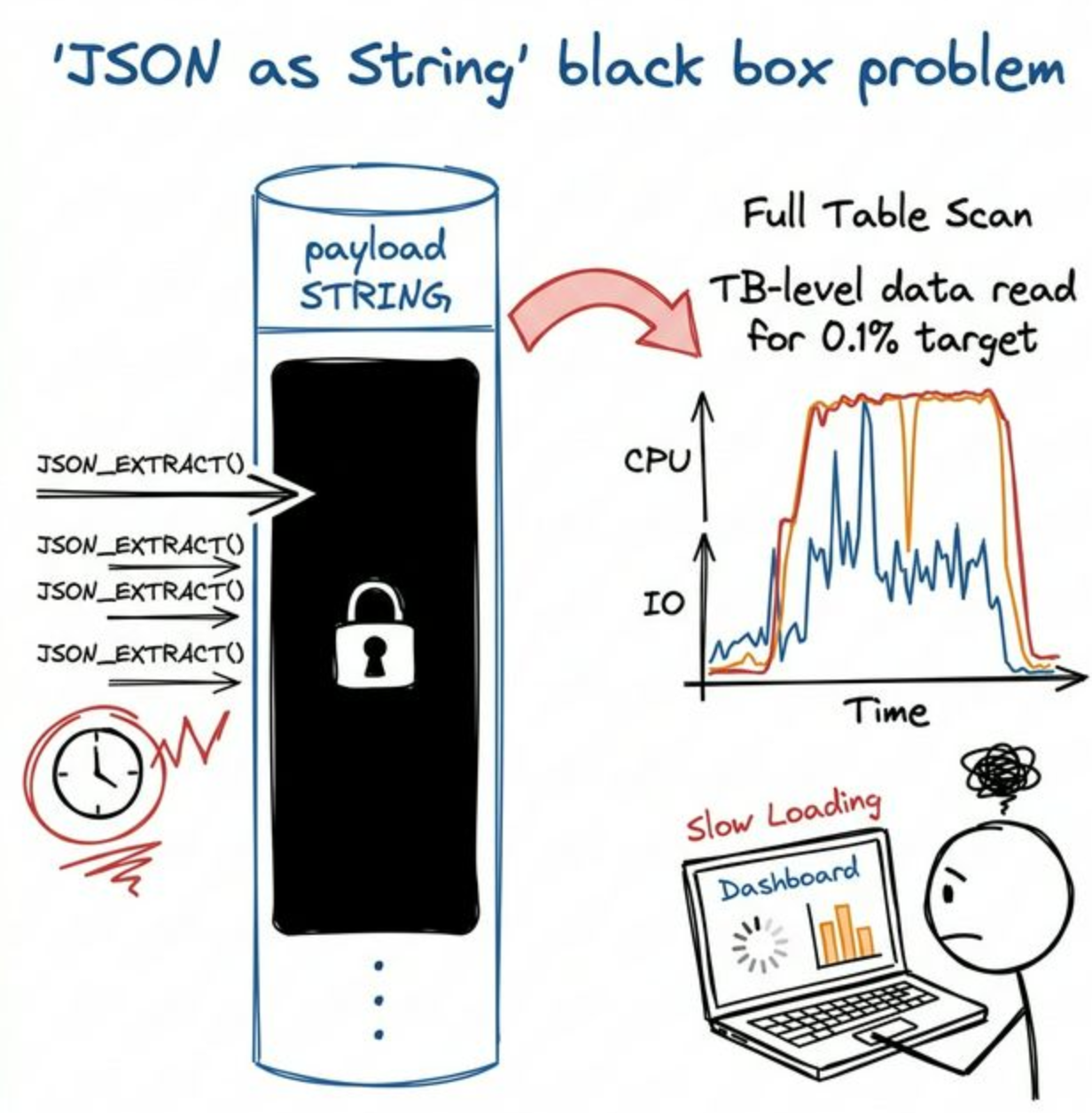
Apache Doris and ClickHouse documentation both draw this line clearly: if the workload is write-once, read-once retrieval, String storage is fine. For high-concurrency OLAP analysis on the internal fields of dynamic JSON, it becomes a hard bottleneck. Document databases like MongoDB or PostgreSQL don't solve this either, because they were never designed for complex aggregation workloads at a terabyte scale.
Handling Dynamic JSON with Columnar Performance: VARIANT and Inverted Indexes
The better approach: instead of reshaping JSON to fit the database, let the database adapt to JSON.
The solution is a storage type that gives dynamic JSON the query performance of a typed column. Apache Doris's VARIANT type and ClickHouse's JSON type both work this way: semi-structured on write, columnar on read.
Auto Subcolumn Extraction
The storage engine tracks which JSON paths appear frequently across rows. When payload["tool_args"]["command"] shows up consistently, the engine extracts it automatically and stores it as a dedicated physical column.
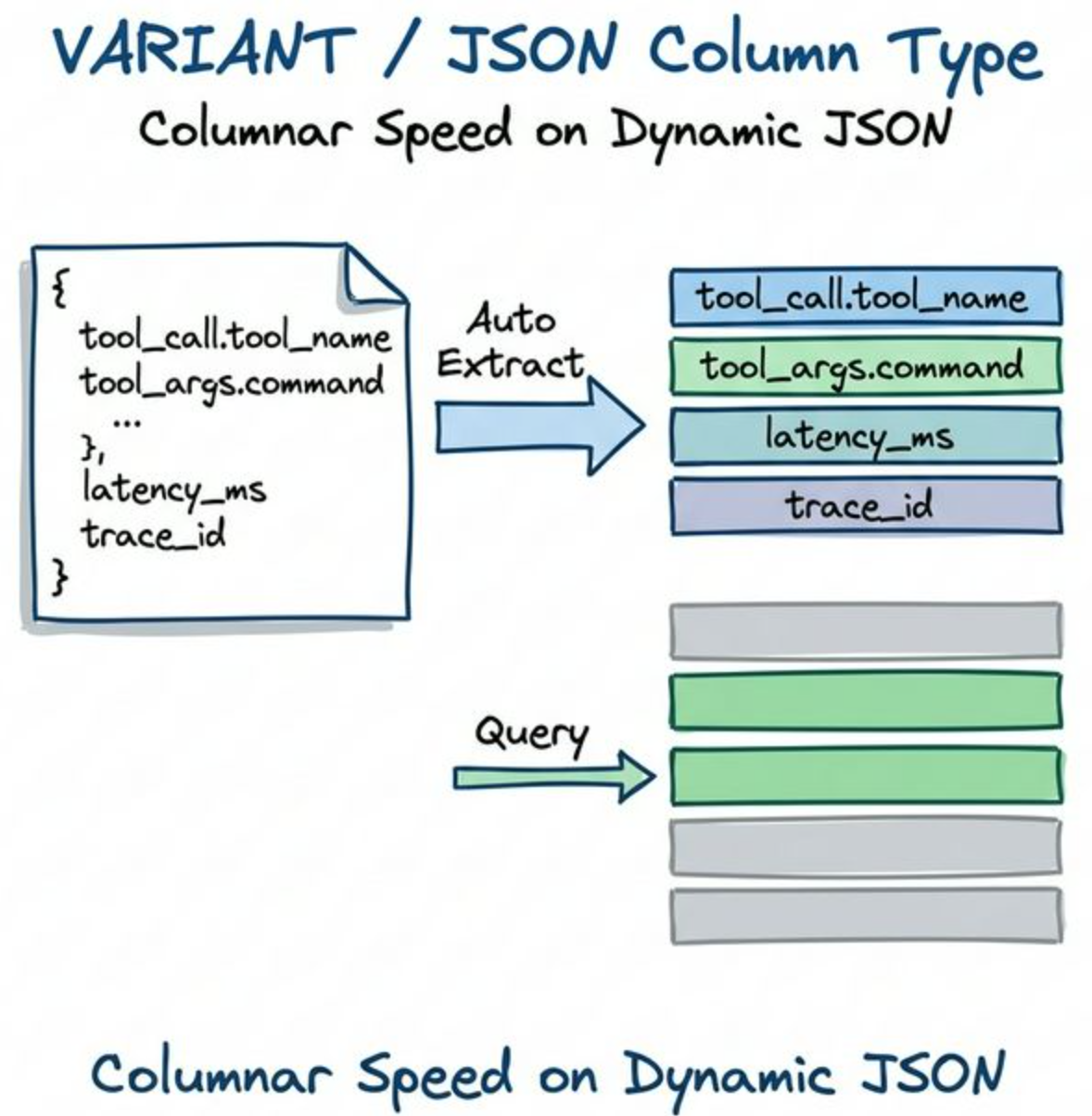
This gives the same scan performance and compression ratio as a traditionally declared column. In Apache Doris, queries against dynamic JSON stay clean and efficient:
-- Column pruning and predicate pushdown on VARIANT data
SELECT
payload["tool_call"]["tool_name"] AS tool,
AVG(cast(payload["latency_ms"] as int)) AS avg_latency
FROM agent_traces
WHERE payload["trace_id"] = 'tr-xyz-123'
GROUP BY 1
ORDER BY avg_latency DESC;
This avoids the limits of the String storage approach, turning the JSON payload from an opaque text blob into a prunable, accelerated, schema-free columnar structure.
Inverted Index for Full-Text Search
Beyond aggregation, the most common debugging operation is keyword retrieval: finding which conversation triggered a permission denied error, or which prompt contained a specific entity.
Running LIKE against TB-scale text fields means a full table scan on every query.
Apache Doris addresses this with native inverted indexes, which work on both long text fields and VARIANT columns:
-
On long text fields: build an inverted index on prompt, completion, or error_message for keyword search comparable to Elasticsearch's native MATCH queries.
-
On VARIANT columns: any keyword present anywhere in the JSON payload is retrievable in milliseconds, without scanning every row.
Since Apache Doris supports VARIANT columns and inverted indexes on the same table, columnar aggregation and full-text search work together in one SQL query:
-- Filter by JSON path, retrieve bad cases with full-text search (no full-table LIKE scan)
SELECT
payload["trace_id"],
payload["reasoning_step"]
FROM agent_traces
WHERE
-- Structured sub-JSON path filter
payload["tool_call"]["tool_name"] = 'execute_shell'
-- Full-text keyword search via inverted index
AND payload["error_msg"] MATCH_ANY 'timeout'
AND payload["prompt"] MATCH_ALL 'delete users table';
Hybrid Modeling for Production Agent Logs
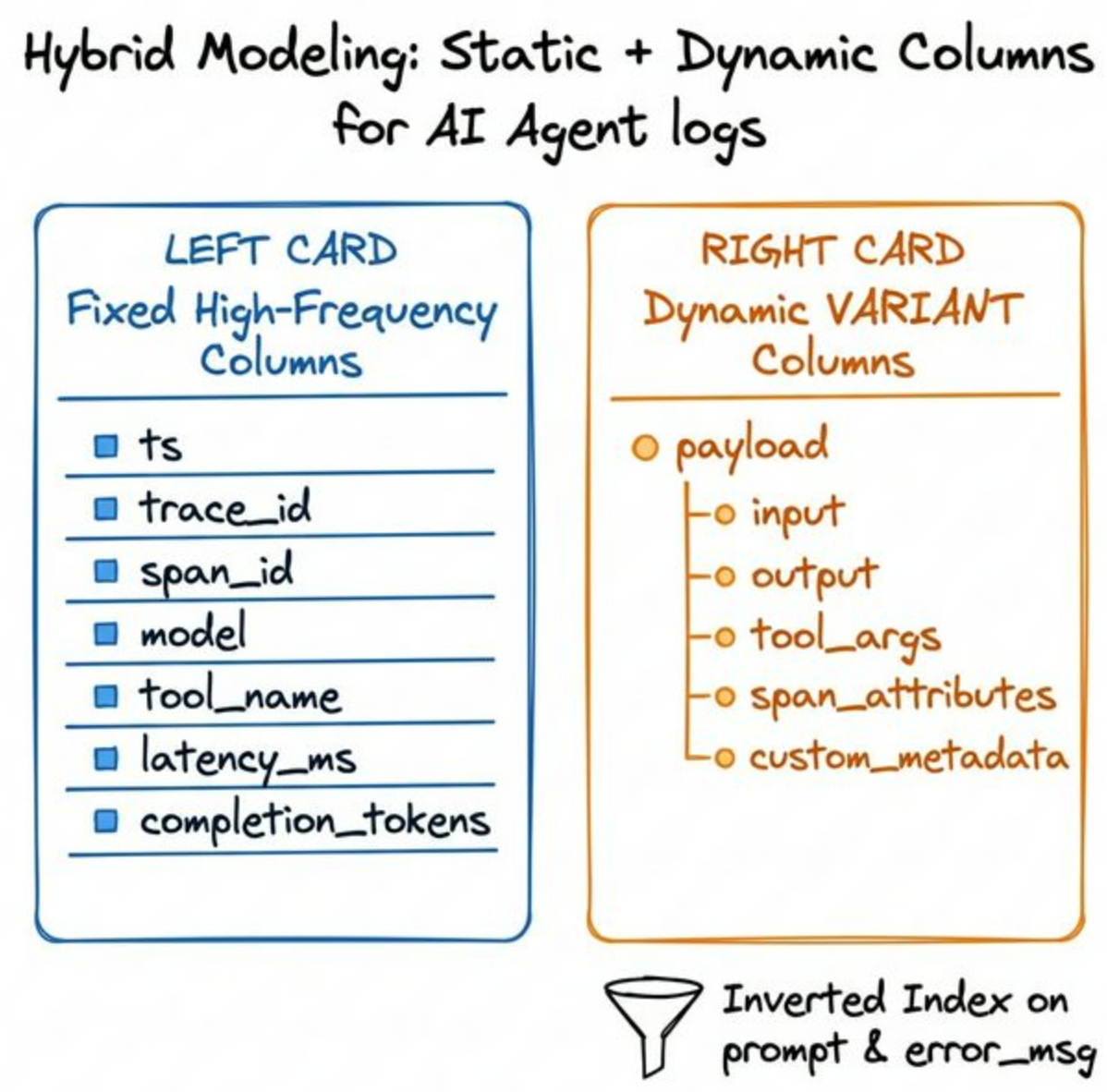
The production-ready hybrid model separates stable high-frequency fields from dynamic evolving payload fields.
A. Regular columns for stable scalar fields
Fields like ts, trace_id, span_id, parent_span_id, model, tool_name, latency_ms, and completion_tokens are fixed, high-frequency filter and aggregation dimensions. Store these as standard columns.
B. VARIANT columns for dynamic, nested fields
Fields like input, output, tool_args, span_attributes, and custom_metadata have deep hierarchies and evolve frequently. Store these in VARIANT columns and let the storage engine handle subcolumn extraction automatically. Add inverted indexes on key fields to speed up debugging.
DDL and Query Examples
At production scale, storing and querying large volumes of agent logs requires significant infrastructure. Teams looking to reduce the operational overhead of self-managed clusters can use VeloDB Cloud, the managed cloud offering built on Apache Doris. VeloDB Cloud includes the full VARIANT and inverted index capabilities, and runs on a compute-storage separation architecture: historical logs stay in object storage at low cost, compute scales on demand, and engineering teams focus on queries and debugging rather than cluster management.
1. Table definition (DDL)
Full table definition using VARIANT + inverted indexes:
CREATE TABLE agent_trace_logs (
`ts` DATETIME NOT NULL COMMENT "log timestamp",
`trace_id` VARCHAR(128) NOT NULL COMMENT "trace ID",
`span_id` VARCHAR(128) NOT NULL COMMENT "span ID",
`tool_name` VARCHAR(64) COMMENT "tool name",
`latency_ms` INT COMMENT "latency (ms)",
-- Dynamic nested structures go into VARIANT
`payload` VARIANT NULL COMMENT "dynamic context and nested execution flow",
-- Inverted indexes for full-text retrieval on key fields
INDEX idx_payload_prompt (`payload["prompt"]`) USING INVERTED PROPERTIES("parser" = "english"),
INDEX idx_payload_error (`payload["error_msg"]`) USING INVERTED PROPERTIES("parser" = "english")
)
ENGINE=OLAP
DUPLICATE KEY(`ts`, `trace_id`) -- sort key optimized for time range and trace queries
PARTITION BY RANGE(`ts`) ()
DISTRIBUTED BY HASH(`trace_id`) BUCKETS AUTO
PROPERTIES (
....
);
2. Query (DML)
After writing complex JSON to payload, JSON path syntax works like Python dictionary access:
-- Find traces from the last day where execute_shell ran >1s and returned a permission denied error
SELECT
trace_id,
tool_name,
latency_ms,
payload["tool_args"]["command"] AS executed_command,
payload["error_msg"] AS error_detail
FROM agent_trace_logs
WHERE ts > now() - INTERVAL 1 DAY
AND tool_name = 'execute_shell'
AND latency_ms > 1000
AND payload["error_msg"] MATCH_ALL 'permission denied'
ORDER BY latency_ms DESC
LIMIT 50;
This design handles structured aggregation, schema-free payload storage, and millisecond-level log retrieval from a single table.
Summary
Agent execution is semi-structured by nature: nested hierarchies, arrays, and schemas that change as the codebase evolves.
Neither the flattening nor the String approach works at scale. Flattened JSON columns break when the schema changes often, and storing JSON as plain text String turns every query into a full scan. VARIANT and inverted indexes offer both flexibility and strong query performance: the engine automatically promotes frequently-appearing JSON paths to typed columns, so teams get fast queries without committing to a fixed schema upfront.
With both VARIANT and inverted indexes built into the system, Apache Doris is designed to handle demanding workloads like agent observability. VeloDB Cloud, the managed cloud offering built on Apache Doris, adds a compute-storage separation architecture that lets teams keep historical logs in object storage at low cost while scaling compute on demand, without managing cluster sizing or performance tuning.
For a deeper look at how Apache Doris handles high-sparsity, high-cardinality wide JSON workloads at the storage level, see Doris 4.1: Doc Mode and Segment V3 for Wide JSON at Scale. Join the Apache Doris community on Slack and connect with other Doris experts and users.


