



A stock trade prints at 10:31:00.250. The quote that explains its price arrived at 10:30:59.980. An equality join will never pair those two rows, because the timestamps differ by 270 milliseconds. The query you need says: for each trade, find the latest quote at or before the trade time, for the same ticker.
That lookup shows up across time-series workloads:
-
Transaction cost analysis. Match every trade to the prevailing quote to measure slippage and execution quality.
-
IoT and telemetry. Attach the most recent calibration record or device state to each sensor reading.
-
Observability. Enrich each error event with the latest deploy, config change, or feature flag that preceded it.
-
Event tracking. Join each order event to the latest status snapshot of the entity it belongs to.
SQL engines call this ASOF JOIN, and most major analytical databases now ship it. Writing the same logic without it takes a correlated subquery or a window-function detour, and both get expensive at billions of rows. An engine with native support can run the key match and the time lookup as a single operator.
Why We Benchmarked It
Apache Doris added ASOF JOIN in versions 4.0.5 and 4.1.0. Before recommending a new join type for production work, we wanted an objective answer to one question: whether it is fast enough, consistently enough, to sit in core query paths. Three things made a purpose-built benchmark necessary.
First, shared syntax hides divergent implementations. The operator behind ASOF JOIN involves real design choices: partition by key or globally, sort or hash, how to handle unordered input, how to manage per-key state when one key holds 100,000 rows and another holds exactly 1. Each choice shows up directly in query time, so a feature-list checkmark says little about speed.
Second, no standard suite measures it. TPC-H, TPC-DS, and similar industry benchmarks contain no ASOF JOIN queries, so performance claims for this operator have no public yardstick. We had to define one.
Third, the workloads that depend on this join carry hard latency expectations. Trade and quote matching, telemetry enrichment, and event correlation run on large, fast-growing tables, and the queries sit behind interactive dashboards and automated pipelines. An implementation that holds up only on small or tidy data would not be worth shipping.
So we analyzed the typical business scenarios for this join, defined 6 scenario families covering the factors that decide its cost (table size ratio, key cardinality, sequence length per key, physical data order, and post-join filtering), and used the suite in 2 ways: during development, to iterate on the implementation, and at release, to compare the result against 2 widely used analytical databases on identical hardware with equal thread counts.
Here is what to expect below: the join's semantics, the full test matrix, the environment and method (where both comparison systems are identified, with exact versions and settings), and per-scenario results for all 11 measurements. Doris posted the fastest time in every one. The narrowest gap was 16%, the widest 14x, and the test matrix is specific enough to reproduce.
The Semantics: Latest Available Fact
The trade and quote example translates directly to SQL:
SELECT t.trade_id, t.stock_id, t.trade_time, q.ask_price
FROM trade t
ASOF LEFT JOIN quote q
ON t.stock_id = q.stock_id
AND t.trade_time >= q.quote_time;
The ON clause does two jobs. The equality condition groups rows by business key: trades match quotes for the same stock_id. The inequality condition then picks a single row from that group: the quote with the largest quote_time that is still less than or equal to trade_time. Each left row gets at most one match.
The semantics are simple. Making them fast is the hard part, because production data is rarely tidy: per-key time chains can hold 100,000 entries or exactly 1, data lands on disk out of order, and key counts run from 100 to 10 million. The Doris team iterated the implementation against exactly those conditions, backed by 100+ regression tests plus large batches of randomly generated join tests for correctness.
Benchmark Design
Each scenario family isolates one factor that drives ASOF JOIN cost:
| Scenario | What it verifies | Left rows | Left NDV | Right rows | Right NDV | Data characteristics |
|---|---|---|---|---|---|---|
| Large vs small table | Probe efficiency against small reference series | 100M | 1k to 100M | 1k to 10M | 1k to 10M | Random distribution |
| 100M vs 100M | Large-scale joins; NDV impact on grouping and state | 100M | 100 to 10k | 100M | 100 to 10k | Random distribution |
| Long sequences | Lookup along long per-key time chains | 100M | 10k | 100M | 1k | 100k rows per right-table key |
| Short sequences | Sparse, high-cardinality matching | 100M | 10M | 10M | 10M | 1 row per right-table key |
| Out-of-order storage | Sensitivity to physical data layout | 100M | 10k | 100M | 10k | Join keys on non-prefix, unsorted columns; raw data unordered |
| Filtered queries | Execution with post-join filtering | 100M | 10k | 100M | 10k | WHERE filters at 75% to 100% selectivity |
The matrix covers LEFT and INNER join semantics. To keep the comparison about the join itself, all 3 systems used identical table schemas and identical data, and we verified after the runs that the ASOF JOIN operator accounted for the bulk of each query's cost, so scan-speed differences don't drive the rankings.
Environment and Method
All 3 engines ran on the same single machine:
| Item | Spec |
|---|---|
| Machines | 1 |
| Instance type | ecs.g7.4xlarge |
| CPU cores | 16 |
| Memory | 64 GB |
| Disk | 1x ESSD PL0 cloud disk, 500 GB |
DuckDB runs in process and ClickHouse ran as a single server, so a 1-node deployment keeps the comparison fair. Doris FE and BE shared the node.
| Product | Apache Doris | ClickHouse | DuckDB |
|---|---|---|---|
| Version | 4.1.0 | v26.3.3.20 | 1.5.1 |
| Parallelism | parallel_pipeline_task_num = 16 | max_threads = 16 | threads = 16 |
Doris defaults to a different degree of parallelism than the other 2 engines, so we pinned all 3 to 16 threads. Every query ran at single concurrency: 1 cold run, then 3 hot runs, taking the fastest hot time as the result.
Results
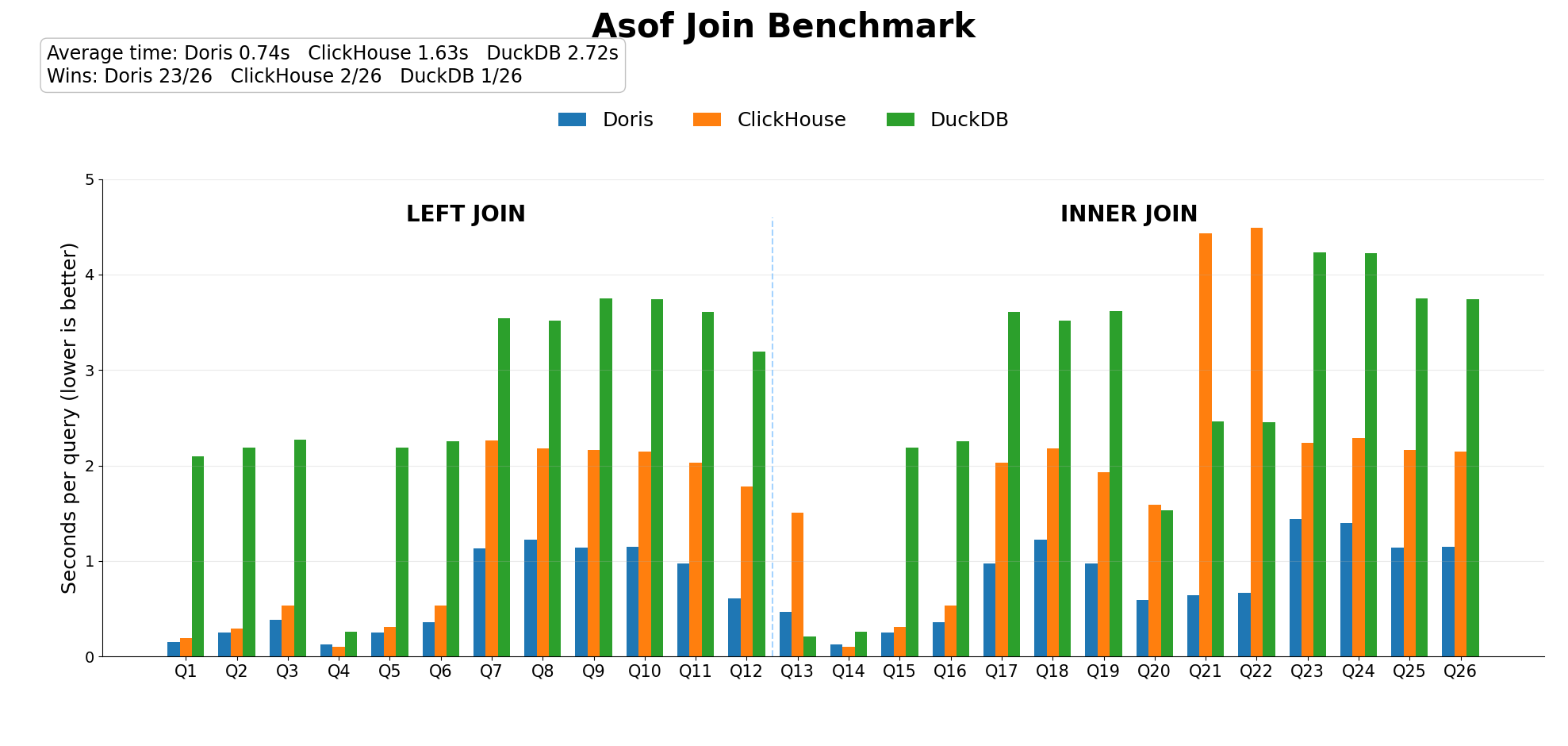
| Scenario | Doris (s) | ClickHouse (s) | DuckDB (s) |
|---|---|---|---|
| 100M vs 10M | 0.38 | 0.53 | 2.27 |
| 100M vs 100k | 0.25 | 0.29 | 2.19 |
| 100M vs 1k | 0.15 | 0.19 | 2.10 |
| 10M vs 100M | 0.52 | 1.55 | 1.69 |
| 100k vs 100M | 0.47 | 1.68 | 1.43 |
| 100M vs 100M, standard NDV | 0.97 | 1.93 | 3.62 |
| 100M vs 100M, low NDV | 1.13 | 2.26 | 3.54 |
| Long sequences | 0.59 to 0.61 | 1.59 to 1.78 | 1.53 to 3.19 |
| Short sequences | 0.64 to 0.67 | 4.43 to 4.49 | 2.45 to 2.46 |
| Out-of-order storage | 1.40 to 1.44 | 2.24 to 2.29 | 4.22 to 4.23 |
| Filtered queries | 1.14 to 1.15 | 2.15 to 2.16 | 3.74 to 3.75 |
Large Fact Table, Small Reference Table
This is the most common production shape: a high-frequency event stream joined to a smaller reference series, like trades to quotes or events to dimension snapshots.
With a 100M-row left table, Doris held 0.15s to 0.38s as the right table grew from 1k to 10M rows. ClickHouse stayed close here, within 16% to 39% of Doris. DuckDB ran 6x to 14x behind. Doris's latency falling smoothly as the right table shrinks points to low fixed overhead, which is what keeps this query shape inside interactive dashboard budgets.
Flipping the ratio separates the engines. At 10M vs 100M, Doris ran 0.52s against 1.55s for ClickHouse and 1.69s for DuckDB. At 100k vs 100M, Doris ran 0.47s against 1.68s and 1.43s. Once the right side carries the bulk of the data, Doris holds about a 3x lead or better over both.
100M Rows on Both Sides
At standard NDV (10,000 keys), Doris finished in 0.97s, against 1.93s for ClickHouse and 3.62s for DuckDB. A sub-second result on a 100M x 100M time-series join, on 1 machine with 16 cores, is the headline number of this benchmark.
Low NDV (100 keys) concentrates all 100M rows into a few heavy groups, which stresses per-group state and tends to expose execution hot spots. Doris moved from 0.97s to 1.13s, a 16% shift, while ClickHouse ran 2.26s and DuckDB 3.54s. Production key distributions are rarely ideal, so how little a result moves between NDV 10,000 and NDV 100 matters as much as the absolute time.
Sequences, Ordering, and Filters
The remaining scenarios test the data shapes that benchmarks often skip.
Long sequences (100,000 rows per right-table key, the shape of dense market data or high-frequency metrics): Doris held 0.59s to 0.61s, ClickHouse 1.59s to 1.78s, DuckDB 1.53s to 3.19s.
Short sequences (10M keys with exactly 1 right-table row each, the shape of sparse device fleets or wide user dimensions): Doris held 0.64s to 0.67s. ClickHouse slowed to 4.43s to 4.49s, its weakest result in the benchmark at roughly 7x behind. DuckDB ran 2.45s to 2.46s.
Out-of-order storage (join keys on non-prefix, unsorted columns): Doris held 1.40s to 1.44s, against 2.24s to 2.29s for ClickHouse and 4.22s to 4.23s for DuckDB. Real ingestion rarely lands sorted, so a result that survives unordered input lowers the engineering cost of adopting the feature.
Filtered queries (WHERE conditions at 75% to 100% selectivity): Doris held 1.14s to 1.15s, against 2.15s to 2.16s and 3.74s to 3.75s. Real analyses filter and aggregate after they join, so the operator has to stay fast inside a larger plan.
Reading the Results
Doris was fastest in all 11 measurements, and the shape of the lead tells you more than any single row:
-
ClickHouse stayed within 40% of Doris when the right table was small, and ran 1.6x to 7x behind everywhere else.
-
DuckDB ran 2.5x to 14x behind, with most scenarios at 3x or worse.
-
Across every scenario, Doris stayed between 0.15s and 1.44s. That narrow band, held across NDV swings, unordered input, and sequence-length extremes, is the property that decides whether you can put a feature in a core query path.
Initial production tests with financial-industry users matched these results. The usual caveats apply: these numbers come from the listed versions, configuration, and generated datasets, and your own data distribution will shift them. The test matrix above is specific enough to reproduce.
Try It
ASOF JOIN ships in Apache Doris 4.0.5 and 4.1.0. Download the latest 4.x release from the Apache Doris site and follow the join documentation to run it on your own trade, telemetry, or log data.
To run the same engine without managing the cluster, VeloDB Cloud runs Apache Doris as a managed service, with a free trial to test ASOF JOIN against your own workload. If you hit problems with either, join the Apache Doris community on Slack or contact the VeloDB team.


