



I. The Problem RAG Solves: Limitations of Foundational Large Language Models
Retrieval-Augmented Generation (RAG) is an AI framework designed to enhance the quality and reliability of responses generated by Large Language Models (LLMs) by integrating external knowledge sources. RAG emerged as a necessity to address several core challenges inherent in relying solely on foundational models.
A. Static Knowledge and Timeliness Issues
Foundational LLMs are trained on a fixed "snapshot" of data, meaning their knowledge is subject to a "knowledge cutoff."
- Lack of Current Information: When asked about recent events, updated policies, or dynamic data, the model may be unable to answer or confidently generate outdated or incorrect information due to its knowledge gap.
- High Cost of Continuous Retraining: Traditional solutions often require expensive and time-consuming retraining (fine-tuning) of the entire model to incorporate new information. RAG offers a more economical solution by updating the external knowledge base instead, lowering the computational and financial burden of continuous updates.
B. Hallucination and Missing Content Trust
A primary risk associated with LLMs is "hallucination," where the model generates factually inaccurate or misleading content that sounds plausible.
- Unreliable Content Generation: LLMs predict the next word based on statistical relationships learned from vast data, not genuine factual understanding. When faced with complex or ambiguous questions, they may fall back on information "baked into their parameters," leading to erroneous output.
- Lack of Verifiability: Since basic LLMs typically cannot cite their specific sources, users must verify the information themselves, eroding trust. RAG mitigates hallucination by grounding the LLM's response in external, verifiable facts.
C. Lack of Domain-Specific Knowledge and Data Security
While general LLMs possess broad knowledge, they inherently lack deep understanding of specific industries, internal corporate processes, or proprietary data.
- Inability to Access Private Data: Corporate internal documents, policies, and business secrets are inaccessible to public foundational models. Forcing this sensitive data into the model's training process risks data leakage and compliance issues.
- RAG's Solution: RAG architecture separates knowledge from the model's parameters, allowing the LLM to securely access private, up-to-date, and proprietary knowledge bases, significantly increasing accuracy and trustworthiness in enterprise applications.
II. How RAG Works: The Two-Phase Workflow
The RAG framework introduces an external information retrieval component to decouple knowledge acquisition from content generation. The process is divided into two primary stages: The Knowledge Ingestion Phase (building the knowledge base) and The Real-Time Workflow Phase (retrieval and generation).
A. The Knowledge Ingestion Phase: Building the Searchable Knowledge Base
This is an offline process that converts unstructured, fragmented external data into a format that the AI model can efficiently retrieve.
- Data Preparation and Chunking: Raw data (e.g., documents, files, database records) is loaded, cleaned, and then divided into smaller, manageable text chunks. This chunking strategy is crucial; it ensures each piece contains sufficient contextual information while remaining small enough to fit within the LLM's input limit.
- Vector Embedding: An Embedding Language Model converts each text chunk into a high-dimensional numerical vector (embedding). These vectors represent the semantic meaning of the text; semantically similar chunks have vectors that are closer together in the mathematical space. .
- Vector Database Storage and Indexing: The resulting vector embeddings are stored and indexed in a vector database. These databases are optimized for high-dimensional similarity searches, utilizing indexing structures (like HNSW or IVF) to enable fast Approximate Nearest Neighbor (ANN) search.
- Knowledge Base Updates: To ensure information remains current, documents and their corresponding vector embeddings are asynchronously updated in the knowledge base whenever the external source data changes.
B. The Real-Time Workflow Phase: Retrieval, Augmentation, and Generation
When a user submits a query, the RAG system executes the real-time workflow.
- Query Vectorization and Retrieval: The user's input is instantly converted into a query vector. The system uses this query vector to perform a relevance search against the vector database. This search relies on mathematical vector calculations to capture the semantic intent of the query, not just keyword matching. The system returns the top few document fragments most similar to the query vector.
- Context Augmentation: The retrieved relevant information fragments are attached to the user's original query. Using prompt engineering, these external facts are integrated into an "augmented prompt," which serves as the factual basis provided to the LLM.
- Model Synthesis and Generation: Upon receiving the augmented prompt, the LLM uses its language capabilities, combined with the newly provided external knowledge, to synthesize a tailored, accurate response. The final answer can be delivered along with source links or references, ensuring verifiability and building user trust.
III. RAG Construction Example based on VeloDB: The Knowledge Base Architecture
For enterprise RAG implementations, the knowledge base must meet stringent requirements for low latency, high concurrency, and real-time updates. The VeloDB real-time analytics database provides an architecturally optimized foundation for high-performance RAG systems.
A. Unified Knowledge Management and Comprehensive Data Ingestion
RAG systems must efficiently process various data formats—structured, semi-structured, and unstructured—within the enterprise. VeloDB is designed to provide a Unified Data Management Framework, capable of ingesting and integrating knowledge from:
- Traditional Databases and Data Warehouses: Such as MySQL, PostgreSQL, and Redshift, connecting via JDBC/ODBC protocols.
- Data Lake Analytics (Lakehouse): Supporting federated analysis across external data lakes (e.g., Hive, Iceberg, Hudi).
- Cloud Storage and Unstructured Data: Including S3, files, and logs.
This comprehensive data integration ensures that vector embeddings, original text chunks, and critical structural metadata (e.g., permissions, timestamps) are managed efficiently within a single platform.
B. High Performance, Real-Time Guarantees, and Hybrid Search
VeloDB's architectural commitments are tailored to demanding RAG applications:
- Ultra-Low Latency Retrieval: The average query latency target is < 100 ms, preventing retrieval from becoming a bottleneck in the LLM's response time.
- High Concurrency: It supports a maximum query concurrency of over 10,000 QPS, suitable for high-traffic or multi-AI Agent scenarios.
- Knowledge Freshness: Minimum data latency is approximately ∼1 s, ensuring the retrieved knowledge is near-real-time.
VeloDB supports high-performance vector workloads through:
- Storage-Compute Separation: It uses a cloud-native architecture with low-cost object storage for the shared storage layer, optimizing costs for storing PB-scale vector embeddings.
- Execution Acceleration: It leverages a Massively Parallel Processing (MPP) architecture and an optimized Vectorized Execution Engine to accelerate the compute-intensive vector similarity calculations at the hardware level, ensuring rapid ANN retrieval.
- Hybrid Search Capability: Recognizing the limitations of purely semantic search, VeloDB supports Hybrid Search, which combines highly effective full-text search with high-performance vector search. This fusion ensures that the retrieval system can balance deep semantic understanding with precise keyword and entity matching, leading to more accurate and relevant context for the LLM.
IV. VeloDB RAG Architecture Diagrams (Flow Descriptions)
The following structured diagrams (tables) describe the end-to-end system flow for building a RAG knowledge base using the VeloDB real-time data warehouse.
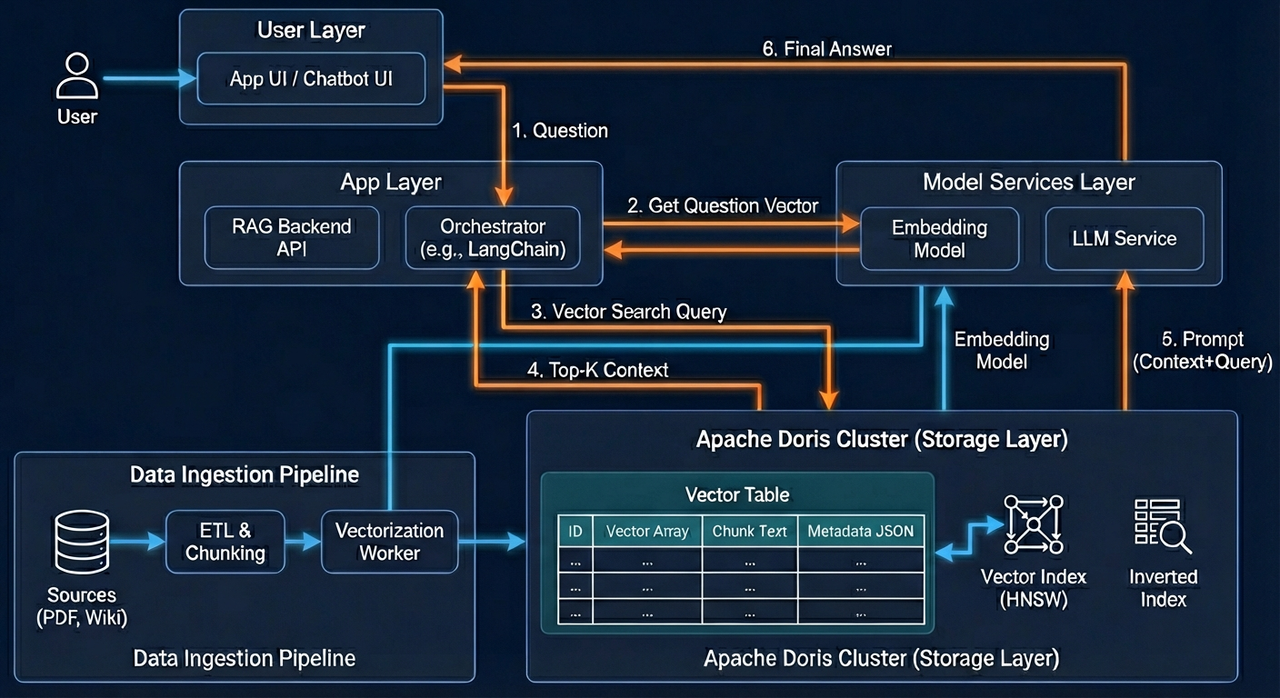
A. Knowledge Ingestion Flow (Building the Knowledge Base)
This flow focuses on securely and efficiently transforming enterprise knowledge into a searchable vector format and persisting it in VeloDB's low-cost storage layer.
| Step | Component | Description |
|---|---|---|
| 1. Data Source Integration | Structured/Unstructured Data Sources (Lakehouse, JDBC, S3, Files, Logs) | Collects diverse raw enterprise data, including data from data lakes, various relational databases (via JDBC/ODBC), and unstructured documents. |
| 2. Pre-processing & Chunking | Pre-processing Service, Embedding Model | Raw documents are cleaned, chunked, and then converted via the Embedding Model into high-dimensional Vector Embeddings and associated Structural Metadata (e.g., permissions, timestamps). |
| 3. High-Speed Ingestion | Real-Time Data Pipeline (High Throughput) | Vector embeddings, raw text chunks, and metadata are imported into the VeloDB Computing Cluster via a high-throughput channel. |
| 4. Indexing & Caching | VeloDB Computing Cluster (MPP), Hot Data Cache | The cluster synchronously builds vector indexes (e.g., HNSW) and metadata indexes. The latest/most frequent indexes and data blocks are loaded into the Hot Data Cache (high-speed disk) for low-latency access. |
| 5. Knowledge Persistence | VeloDB Shared Storage Layer (Object Storage) | The full dataset, including vectors, raw text, and index structures, is permanently persisted to low-cost, high-reliability Object Storage, enabling PB-scale expansion and data security. |
B. Real-Time Query Flow (Retrieval and Generation)
This flow focuses on executing searches with ultra-low latency (target < 100 ms) and using the results to augment the LLM's generation process.
| Step | Component | Description |
|---|---|---|
| 1. Query Vectorization | User/Agent Interface, Query Embedding Service | The user's natural language query is converted into a Query Vector via the Embedding Service. |
| 2. Pre-filtering & Cache Check | VeloDB Computing Cluster, Query Optimizer, Hot Data Cache | The cluster receives the query vector. The Optimizer first performs precise filtering (pruning) based on metadata (e.g., user permissions). The system then prioritizes checking the Hot Data Cache for ultra-fast retrieval. |
| 3. Similarity Computation & Retrieval | VeloDB Computing Cluster (Vectorized Engine, MPP) | The cluster executes parallel ANN search combined with Full-Text Search to enable Hybrid Search. The Vectorized Execution Engine computes similarity at high speed, returning the Top-K most relevant and precise document chunks. |
| 4. Context Augmentation | Retrieved Top-K Document Chunks | The retrieved text context (Facts) is extracted and combined with the user's original query to form an Augmented Prompt containing rich background knowledge. |
| 5. LLM Generation | LLM Generation Service | The LLM receives the Augmented Prompt, performs reasoning and language synthesis based on the external facts, and generates the final accurate answer. The answer may include source links for verification. |
