



Chunking is a fundamental organizational strategy that involves breaking down large, complex streams of information into smaller, logically or semantically coherent units. Originating in cognitive psychology, Chunking has become a critical technique for achieving efficient information retrieval and processing in data management and Artificial Intelligence (AI) today.
This article will systematically introduce the universal principles of Chunking and delve into its specific applications in cognitive science and modern information technology.
I. What is Chunking? – The Core Methodology of Simplifying Complexity
The essence of Chunking lies in overcoming limitations and optimizing processing. Both the human brain and computer systems face constraints regarding capacity and time efficiency when handling information.
1.1 Universal Definition: Organizing Information into "Meaningful Units"
In its broadest sense, Chunking is the process of organizing multiple low-level information elements (like individual letters, numbers, or words) into a single memory unit that possesses an internal connection or a higher-level meaning, through encoding and grouping. These reorganized units are called Chunks.
1.2 The Core Principle of Chunking: Efficient Use of Limited Resources
Through Chunking, we can achieve:
- Capacity Expansion: Compressing large amounts of information into limited storage or processing space.
- Retrieval Simplification: During retrieval, we can directly recall a complex, meaningful Chunk instead of searching for and reconstructing all independent elements.
II. The Foundation of Cognition: Chunking and the Science of Memory (Cognitive Psychology Perspective)
Chunking holds foundational significance in cognitive science, as it is a central mechanism for how humans process, store, and recall information.
2.1 Overcoming the Short-Term Memory Bottleneck
In 1956, psychologist George A. Miller proposed the famous theory that human Short-Term Memory can reliably hold only about pieces of information. If the input exceeds this magical number, the error rate in recall increases dramatically.
Chunking is the effective strategy evolved by the brain to circumvent this limitation. It re-encodes information, binding multiple elements into a single higher-level abstraction—the "Chunk."
2.2 Psychological Practice: From Letters to Concepts
- Example 1: Memorizing a string of random letters .
- Unchunked: This is a 9-unit task, exceeding the limit, making memorization difficult.
- Chunked: The brain automatically recognizes and reorganizes them into three meaningful Chunks: (Federal Bureau of Investigation), (Central Intelligence Agency), and (National Broadcasting Company). The task is now reduced to memorizing 3 units, significantly lowering the difficulty.
- Application in Skill Learning: When mastering complex skills (like chess or playing a musical instrument), experts don't memorize every single move; they memorize a sequence of patterns or action sequences, which are themselves highly optimized "Chunks."
Summary: In the cognitive domain, Chunking is an intrinsic mechanism for increasing memory capacity and cognitive efficiency.
III. Technical Applications: AI and Vector Database Knowledge Management
In modern information technology, especially when dealing with massive amounts of unstructured text and building high-performance information retrieval systems, Chunking is an indispensable preprocessing step.
3.1 Chunking in the RAG Architecture
Retrieval-Augmented Generation (RAG) is an architecture that combines information retrieval with LLM generation capabilities. Chunking is the cornerstone of RAG's success, running through the entire workflow:
- Index Phase: The raw document is first broken down into smaller Chunks via Chunking. Subsequently, each Chunk is converted into a Vector Embedding by an Embedding Model and stored in a vector database. The quality of Chunking directly determines the precision of the vector index.
- Retrieval Phase: When the user enters a query, the system converts it into a query vector and searches the vector database for the most similar Chunks. Because the Chunks are granular and focused, the retrieved context is more accurate, eliminating irrelevant information.
- Generation Phase: The 1 to N retrieved Chunks are packaged as context and sent to the LLM along with the user's query. The LLM generates the final answer based on this external knowledge, significantly reducing the risk of "hallucinations" (fabricating facts).
3.2 The Relationship Between Chunking, Tokens, and Embeddings
To understand Chunking, one must deeply understand Tokens and Embeddings, as they form the three-tier structure of AI semantic understanding.
A. Token: The Atomic Unit of Text Processing for AI
- The Nature of Tokens: A Token is the smallest unit of text handled by LLMs and embedding models. A Token is typically a word, a piece of punctuation, or a character/phrase in languages like Chinese.
- The Tokenization Process: LLMs do not directly process string text. When text input is received, the Tokenizer breaks the text down into an ordered sequence of Tokens.
B. Embedding: The Numerical Representation of Semantics
- Definition of Embedding: A Vector Embedding is a high-dimensional numerical representation (a list of numbers) that captures the semantic meaning and contextual relationships of the text.
- Generation Process: During the RAG Index Phase, the entire Chunk (i.e., the Token sequence within the Chunk) is fed into the Embedding Model. The model outputs a single vector that represents the overall semantics of that Chunk.
- Core Value: Embeddings allow the "meaning" of text to be mathematically computed (e.g., using cosine similarity) and stored in a vector database.
C. The Three-Way Relationship: Conversion from Macro to Micro
- Chunking (Macro): Determines the granularity and boundary of knowledge. It defines the text fragment to be embedded.
- Tokens (Micro): Are the constituent elements of the Chunk. They are the input used by the model for Embedding calculation.
- Embedding (Abstraction): Is the digital outcome of the Chunk's semantics. It is the actual basis for RAG retrieval.
D. Relationship Diagram: The Knowledge Digitization Flow
To clarify this conversion process, we can view Chunking as a three-step process of knowledge digitization:
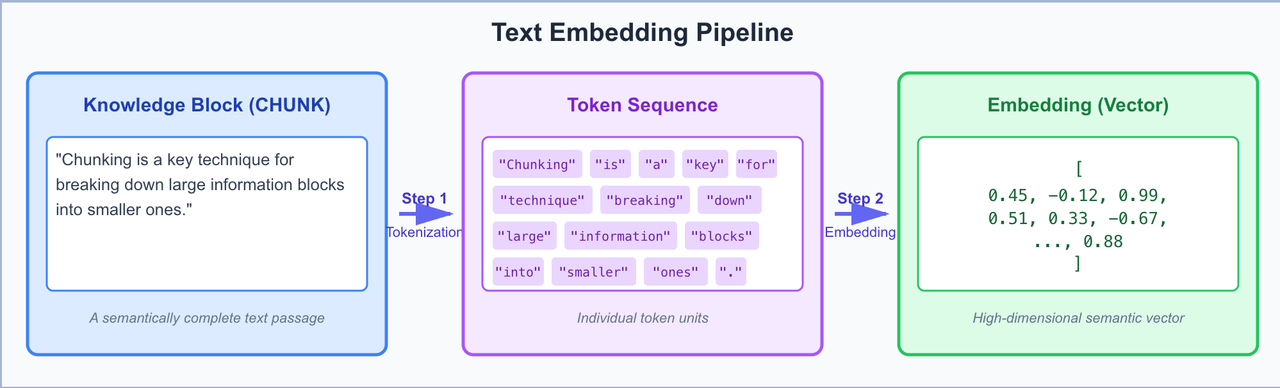
E. How LLMs Use Tokens
All computation and understanding by LLMs are based on the numerical representation of Tokens:
- Semantic Understanding (Internal): Each Token ID is mapped internally by the model to a vector embedding. The LLM processes and aggregates these Token embeddings to form a semantic understanding of the input text.
- Text Generation (Prediction): When the LLM needs to generate text, it calculates the most likely next Token based on the current Token sequence and the context (including Chunks from RAG). This process loops until a complete response is generated.
F. Chunking Measurement Standard
- Size Measurement: The context window limit of an LLM is essentially a Token count limit. Therefore, the Chunk Size must be measured in Token counts, not simple character or word counts.
- The Nature of the Constraint: The purpose of Chunking is to ensure that the Token count of each block stays within the LLM's acceptable range while maximizing its semantic value, guaranteeing the RAG process is highly efficient.
3.3 Leveraging VeloDB: The Power of Hybrid Search in RAG
While Vector Search (Semantic Search) based on Embeddings excels at understanding the meaning of a query, it can sometimes struggle with exact keyword matches or specific entities, especially for rare terms or new jargon. This is where **Hybrid Search **in advanced vector databases like velodb becomes critical for robust RAG systems.
A. What is Hybrid Search?
Hybrid Search combines two powerful retrieval methods:
- Semantic Search (Vector Search): Uses embeddings to find Chunks that are semantically similar to the query, even if they don't share exact keywords. This captures the underlying intent.
- Keyword Search (Lexical Search): Uses traditional text-matching techniques (like BM25) to find Chunks that contain the exact keywords from the query. This ensures precise recall of specific terms.
By intelligently blending these two approaches, Hybrid Search mitigates the weaknesses of each, offering a more comprehensive and accurate retrieval of relevant Chunks.
B. Building RAG with velodb Hybrid Search: A Visual Workflow
Here’s how velodb's Hybrid Search enhances the RAG architecture:
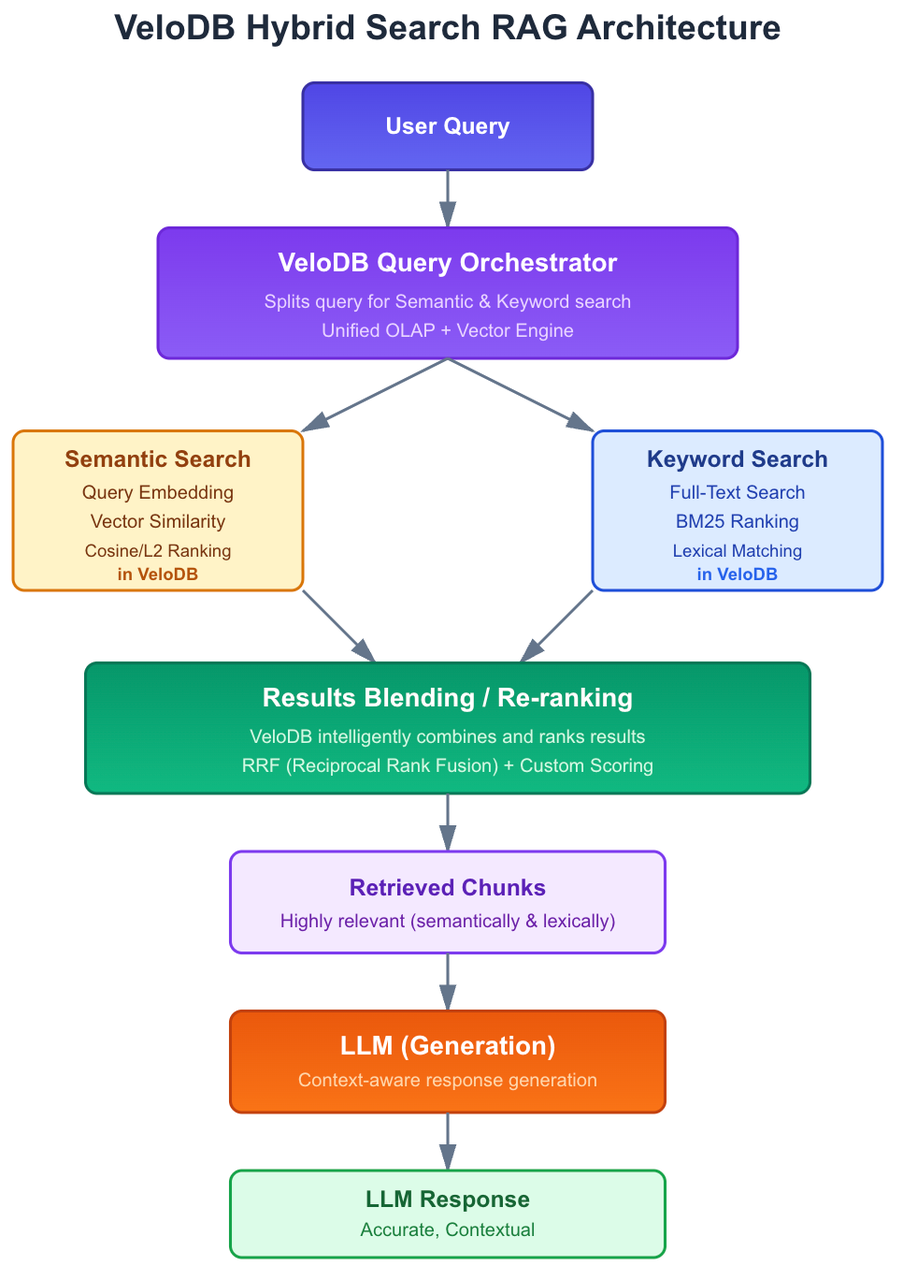
By integrating Hybrid Search, velodb ensures that your RAG system can handle a wider range of queries with superior precision, leveraging both the nuanced understanding of semantics and the exactness of keyword matching.
3.4 Core Strategy: The Art of Cutting – The Key to Retrieval Accuracy
In information technology, Chunking strategies aim to achieve semantic coherence and structural integrity. Choosing the right cutting strategy is the core challenge in building efficient AI knowledge systems, as it directly impacts the quality of information retrieval.
| Strategy Name | Mechanism and Principle | Applicable Scenarios |
|---|---|---|
| Fixed-size Chunking | Mechanical cutting according to a preset fixed length (e.g., 256 or 512 Tokens). | Data with uniform format, simple text not highly dependent on context. (WARNING: Easily breaks semantic integrity) |
| Structured/Delimiter-based Chunking | Using inherent structural elements of the document (e.g., Markdown headings, paragraph breaks) as split points. | Webpages, code, technical documentation with clear hierarchy. Preserves logical structure. |
| Recursive Chunking | Employing a hierarchical list of delimiters. First attempts to split using the largest logical delimiter, and recursively uses smaller ones (like sentences or words) if the block remains too large. | The most commonly used and robust strategy, maximizing the preservation of the document's logical flow. |
| Semantic Chunking | Using the embedding model to calculate the similarity between sentences, splitting where the topic shifts or semantic change is sudden. | Advanced RAG systems that require extremely high conceptual purity for each Chunk. |
3.5 Key Parameters: The Trade-off Between Size and Overlap – Avoiding Context Loss
Chunking is not just about cutting the document; it’s about finding the optimal balance to prevent information loss.
- Chunk Size: This is a core trade-off. Too small leads to a loss of necessary context, making the Chunk meaningless in isolation; too large introduces significant irrelevant information, degrading retrieval accuracy.
- Chunk Overlap: A small amount of shared text between adjacent Chunks. Appropriate overlap is necessary to ensure that crucial concepts or transitional sentences that cross the split point are present in both Chunks, preventing information from being cut off at the edges.
IV. Conclusion: The Universal Value of Chunking
Chunking is a universal optimization method that transcends disciplines. Its value lies in enabling information to be fully utilized and accurately retrieved by limited resources (whether the human brain or the LLM's context window) through efficient organization and encoding. In the AI era, mastering the art of Chunking is the foundation for building efficient and accurate knowledge management systems.
V. Frequently Asked Questions (FAQ Section)
Internal FAQs (Focusing on Implementation and Strategy)
- Q: How do I determine the optimal Chunk Size?
- A: There is no single fixed answer for the optimal Chunk Size. It depends on three factors: document type (complex documents need larger Chunks to maintain context), the Embedding Model's performance (stronger models can handle larger Chunks), and the target LLM's context window limits. It is generally recommended to start testing with 256 to 512 Tokens and iteratively optimize based on retrieval accuracy.
- Q: Why shouldn't we always use the simplest Fixed-size Chunking?
- A: Fixed-size Chunking may abruptly truncate text mid-sentence or mid-paragraph, leading to incomplete semantics where a key concept is split in two. This severely degrades the semantic accuracy of the block's vector, causing RAG retrieval failure. Therefore, we prioritize the use of Recursive Chunking to preserve the document's logical structure.
- Q: What is the necessity of Chunk Overlap?
- A: The primary purpose of overlap is to capture cross-chunk context during retrieval. If the critical information in a user's query is located right at the boundary between two Chunks, appropriate overlap ensures that the complete context is retrieved simultaneously, preventing information loss.
External FAQs (Focusing on User Value and Concepts)
- Q: Does Chunking affect the accuracy of the answers the LLM gives me?
- A: Yes, significantly. The quality of Chunking directly determines whether the RAG system can accurately retrieve relevant information from your knowledge base. If Chunking is poor, the context received by the LLM will be incomplete or contain excessive noise, leading to reduced answer quality or outright errors.
- Q: Is Chunking only necessary for very long documents?
- A: Not entirely. While primarily used for long documents, even medium-to-short documents that cover multiple unrelated topics require Chunking. The core purpose is to ensure that each block is semantically focused, not just to reduce length.
- Q: Why can't I just send the entire document to the LLM?
- A: Even if the LLM's context window is large enough, sending the entire document leads to two issues: 1. High Cost (more Tokens equal higher expense). 2. Performance Degradation (the LLM struggles to focus on relevant information in ultra-long text, leading to reduced retrieval accuracy—the "needle in a haystack" problem). Chunking ensures the LLM receives only refined and relevant context.
