Ave.ai is a fast-growing Web3 and DeFi trading platform based in Australia, with more than 10 million users and 500,000 daily active users globally. The platform is at the forefront of Web3 trading innovation, providing on-chain trading aggregation (integrating 190+ blockchains and 500+ DEXs), AI-driven analytics tracking on-chain activity (from whale moves to smart money), and developer APIs (data and trading APIs with MEV protection).
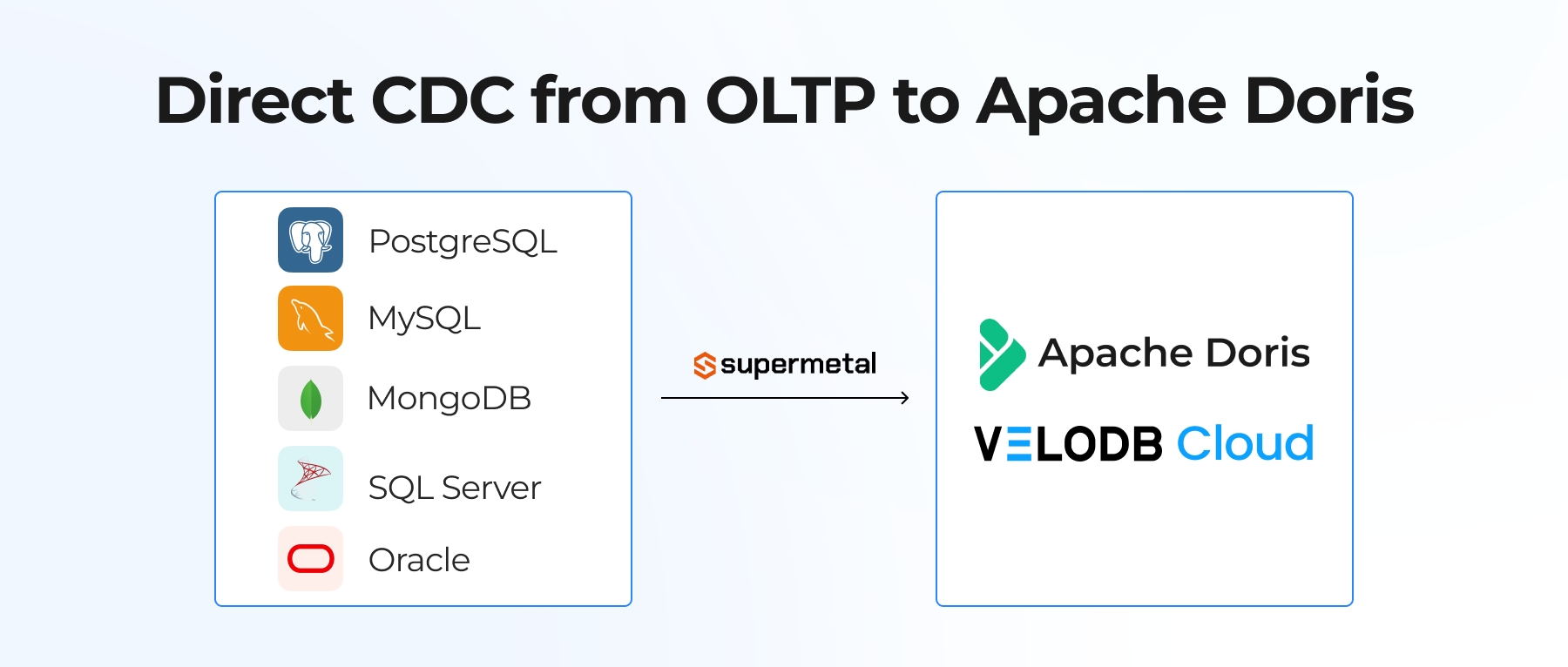
Ave.ai previously used PostgreSQL as its main analytical data infrastructure, but it could not keep pace with growing demands. So Ave.ai evaluated multiple solutions, including VeloDB, HBase, Snowflake, ClickHouse, Hologres, GaussDB, and TiDB, ultimately selecting VeloDB, a real-time search and analytics database powered by Apache Doris, to support their next phase of growth.
In this article, we'll dive into the data challenges Ave.ai faced and how VeloDB helped Ave.ai manage real-time on-chain data analytics for millions of users.
Challenge: Exploding Web3 Data and Struggling PostgreSQL
As Ave.ai's user base grows quickly, so does the complexity of its data infrastructure. Managing data from hundreds of public blockchains, each with its own architecture, transaction model, and growth pattern, meant handling hundreds of terabytes of on-chain data and hundreds of billions of transactions.
For Ave.ai, delivering fast, accurate transaction insights to more than 10 million users became increasingly difficult with their existing PostgreSQL infrastructure. Ave.ai's PostgreSQL-based system struggled with high-concurrency queries, real-time analytics, and elastic scalability.
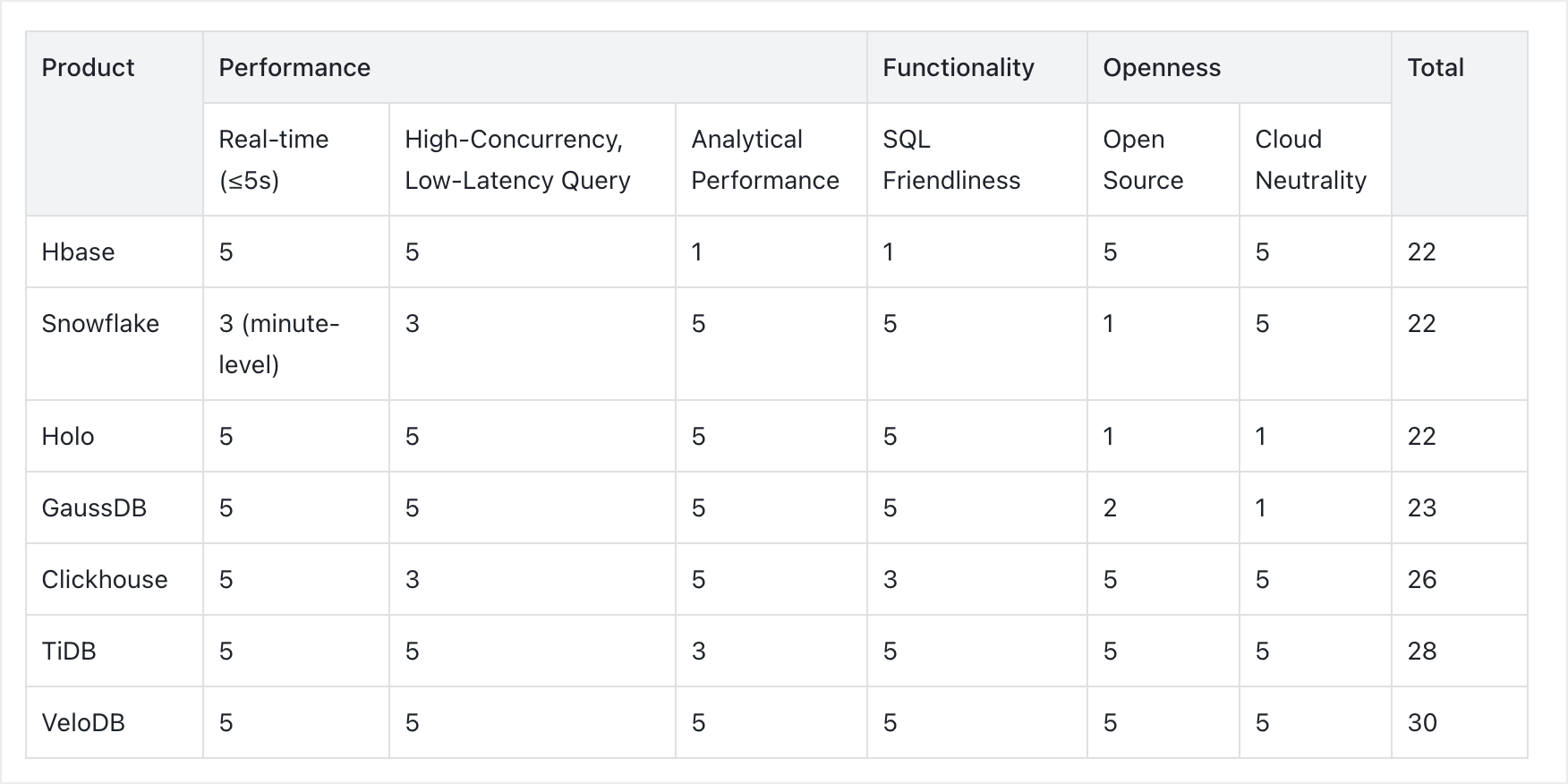
Therefore, Ave.ai started a comprehensive evaluation of alternatives, testing VeloDB, HBase, Snowflake, ClickHouse, Hologres, GaussDB, and TiDB. Their selection criteria focused on three areas:
- Real-Time Performance: The new system needs to deliver near real-time data availability (within 5 seconds), support high-concurrency, low-latency detail queries (over 1,000 QPS), and offer exceptional analytical performance (P99 query latency within 1 second), given that transaction analysis involves heavy analytical computation.
- Functionality: The team preferred a SQL-friendly system to ensure ease of use and compatibility with existing data workflows and tools.
- Openness: Avoid vendor lock-in. The team favored open-source and cloud-neutral solutions, allowing greater flexibility and choice for future deployment and scaling.
Choosing VeloDB
After rigorous proof-of-concept testing, three finalists emerged: ClickHouse, TiDB, and VeloDB. Among them, ClickHouse demonstrated weaker high-concurrency performance, while TiDB showed limitations in analytical computing performance. Considering overall performance, functionality, and openness, Ave.ai chose VeloDB as the final solution.
See the detailed comparison below. The table shows Ave.ai’s own comparison results, rated on a scale from 1 to 5, with one being the lowest and five the highest.
Ave's Web3 Use Cases with VeloDB
1. Real-time Transaction Data Analytics
Ave.ai utilizes VeloDB in three core analytical scenarios: real-time metrics, ratio-based analytics, and detailed queries:
- Real-time Metric Analytics: Computes 24-hour trading volume, total transaction fees, number of holders, short-term trading volumes (1 min / 5 min / 1 hr / 24 hr), net buy/sell volume, and holder statistics.
- Real-time Ratio Analytics: Tracks key ratios such as Top 10 holder shares and developer ownership ratios.
- Detailed Query Analytics: Powers real-time transaction lookups, developer activity queries, and new wallet insights. For example, identifying wallets that are active within the past 7 days.

2. Minute-level Transaction Tag Analysis
Using VeloDB’s real-time analytics power, Ave.ai also performs minute-level transaction tagging and behavioral analysis across several common scenarios, including:
- Sniper Analysis: Identifying wallets that buy tokens within the first three blocks after a token launch.
- Front-running / Insider Trading Detection: Identifying potential "rat-trading" or other suspicious pre-trade behaviors.
- Phishing Address Detection: Spotting wallets involved in malicious or fraudulent activities.
- Bundled Transaction Analysis: Uncovering linked or coordinated transactions across multiple wallets.
- KOL Analysis: Monitoring wallets associated with influencers (e.g., Twitter accounts with over 5,000 followers).
- Smart Money Tracking: Analyzing wallets that show consistently profitable trading patterns.
- Whale Analysis: Identifying large holders or wallets executing single trades above $10,000.
Results and Benefits
By upgrading to VeloDB Cloud, Ave.ai sees significant improvement in write performance, query speed, and cost efficiency. The platform also improved the user experience and reduced operational costs. The system also remains stable and reliable over long-term production workloads.
- Write Performance: With VeloDB’s write optimizations, the system now handles high-throughput ingestion from major blockchains, sustaining roughly 5,000 records per second. End-to-end data latency consistently stays under 5 seconds.
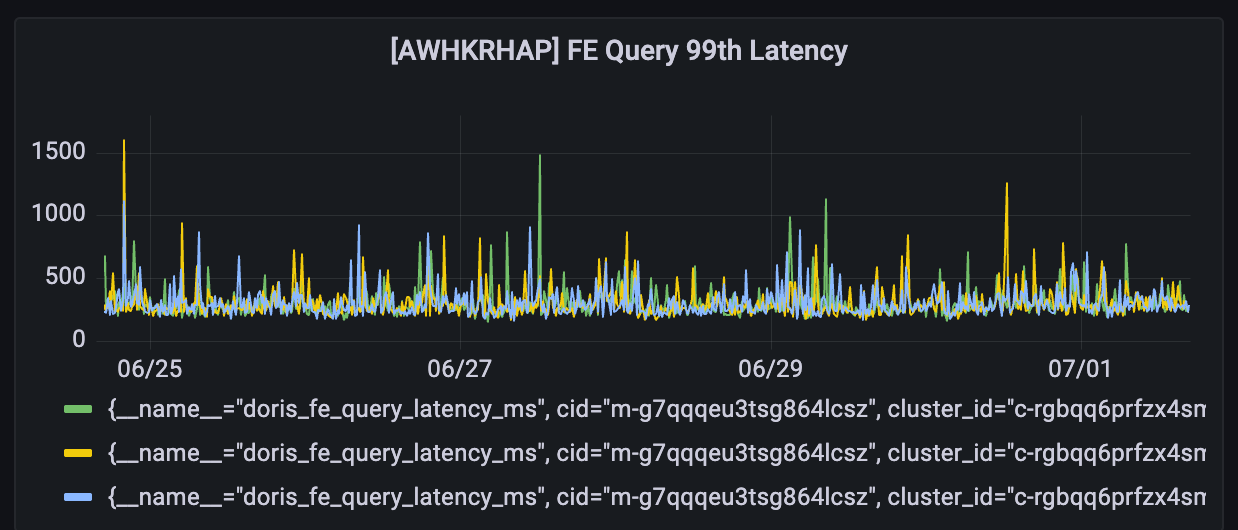
- Query Performance: After specific tuning on slow queries, Ave.ai can now process close to 1,000 QPS with P99 latency within 1 second, even during prolonged peak periods.
- Cost Efficiency: VeloDB Cloud offers storage–compute separation, enabling smooth, reliable scaling. Ave.ai can now handle traffic spikes without wasting resources upfront, cutting overall operating costs by more than 50% without reducing capacity.
The picture below shows monitoring data from a past week, showing a consistent write throughput of 5,000 records per second.

The picture below shows stable query traffic, with P99 latency consistently around 1 second.
Solution Details: Architecture, Tech Implementation, and Highlights
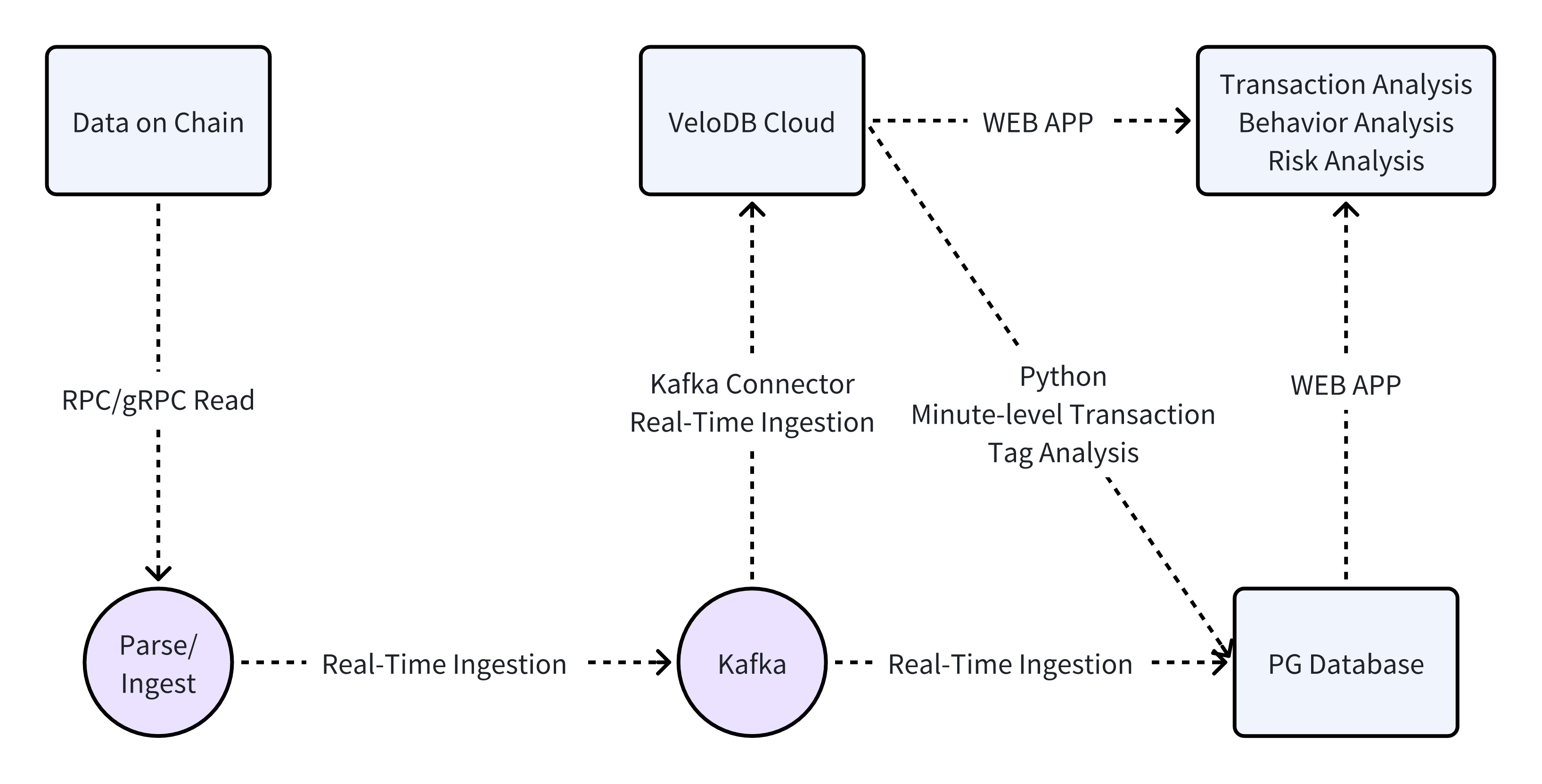
1. System Architecture
The architecture of Ave.ai’s real-time transaction query and analytics system is simple yet powerful, consisting of three core components: Kafka, VeloDB Kafka Connector, and VeloDB Cloud.
This architecture supports key business scenarios such as real-time transaction analytics and minute-level transaction tag processing.
- Kafka: serves as a temporary data buffer and helps smooth traffic spikes during high-volume periods, ensuring stability for downstream systems.
- VeloDB Kafka Connector: A client tool that streams data from Kafka to VeloDB Cloud with latency under 5 seconds, enabling near real-time data ingestion.
- VeloDB Cloud: The core data warehouse powering Ave.ai’s real-time transaction analytics. It provides real-time data visibility, stable high-concurrency and low-latency queries, great analytical performance, and elastic scalability to meet business demands.
2. Technical Highlights
VeloDB’s mature architecture and advanced product features were major reasons Ave.ai chose to adopt it. Key advantages include:
- Second-level Elastic Scaling: The Web3 space is fast-moving and hard to predict, often forcing companies to provision clusters based on peak usage, resulting in significant wasted resources. With VeloDB Cloud’s storage–compute separation, scaling is fast, stable, and reliable, validated by hundreds of production users. This allows Ave.ai to avoid peak-based overprovisioning and reduce costs by roughly 50% while maintaining the same workload capacity.
- TopN Query Optimization: Trading scenarios frequently rely on queries like
ORDER BY createTime DESC LIMIT 1000 OFFSET 100andORDER BY createTime ASC LIMIT 1000 OFFSET 100. VeloDB Cloud implements targeted TopN query optimizations, delivering performance that meets Ave.ai’s business requirements (read more in our documentation). - High-Precision Decimal Support: Many core trading metrics require extremely high precision, sometimes more than 60 digits. VeloDB’s decimal256 ensures accurate calculations and prevents settlement errors caused by rounding or precision loss.
3. Table Design Optimization
Creating tables in VeloDB is straightforward, following several key principles:
- Primary Key Field Order (Prefix Indexing)
- Partitioning and Bucketing Design
- Use of Secondary Indexes
- Field Type Selection
As an example, consider Ave.ai’s large blockchain trade table blockchain_l1_events, which exceeds 10TB of data. The core table creation statement is as follows:
-- blockchain_l1_events DDL
CREATE TABLE `blockchain_l1_events` (
-- ignored columns
-- ignored inverted index
) ENGINE=OLAP
UNIQUE KEY(`account_address`, `block_number`, `event_id`, `date`)
PARTITION BY RANGE(`date`)
(PARTITION p20241004 VALUES [('2024-10-04'), ('2024-10-05')),
-- ignored partitions
)
DISTRIBUTED BY HASH(`account_address`) BUCKETS 64
PROPERTIES (
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
-- ignored properties
);
The following are examples of typical queries commonly used:
SELECT account_address, date, block_number, event_id
FROM blockchain_l1_events
WHERE account_address = 'xxx'
AND block_number > 100 AND block_number < 1000
ORDER BY block_number DESC, event_id DESC
LIMIT 100;
SELECT * FROM blockchain_l1_events
WHERE account_address = 'xxx'
AND event_type = 'SWAP'
AND amount > 100 AND amount < 1000
AND volume >= -1.0;
A. Primary Key Field Order and Partitioning/Bucketing Design
- We defined the primary key as:
UNIQUE KEY(account_address, block_number, event_id, date). This ordering is based on a deep analysis of query patterns, rather than arbitrary field placement. Most queries exactly matchaccount_address, filter or sort byblock_number, useevent_idprimarily for sorting or uniqueness, and utilizedatefor partition pruning. With this key order, queries filtered byaccount_addressand ablock_numberrange can directly leverage the primary key index, significantly reducing the scanned data volume. - Given the table size of nearly 10TB, proper partitioning and bucketing are crucial for performance. We use dynamic range partitions based on
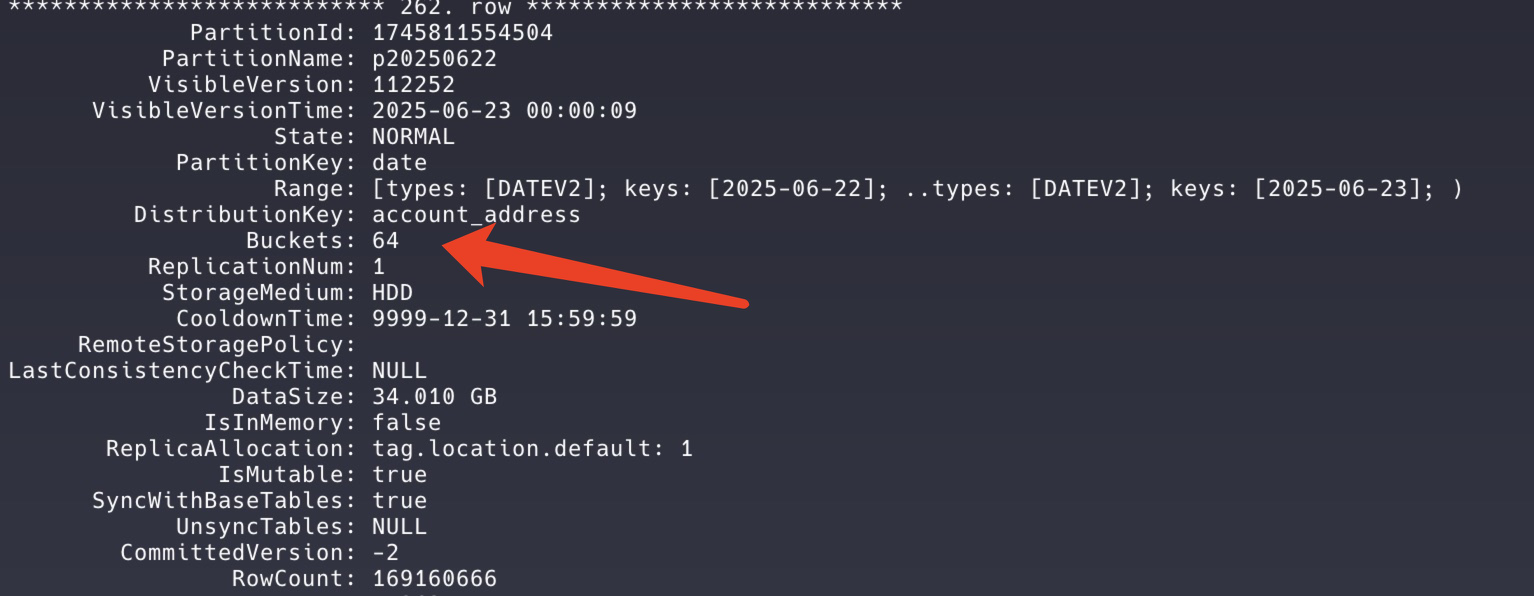
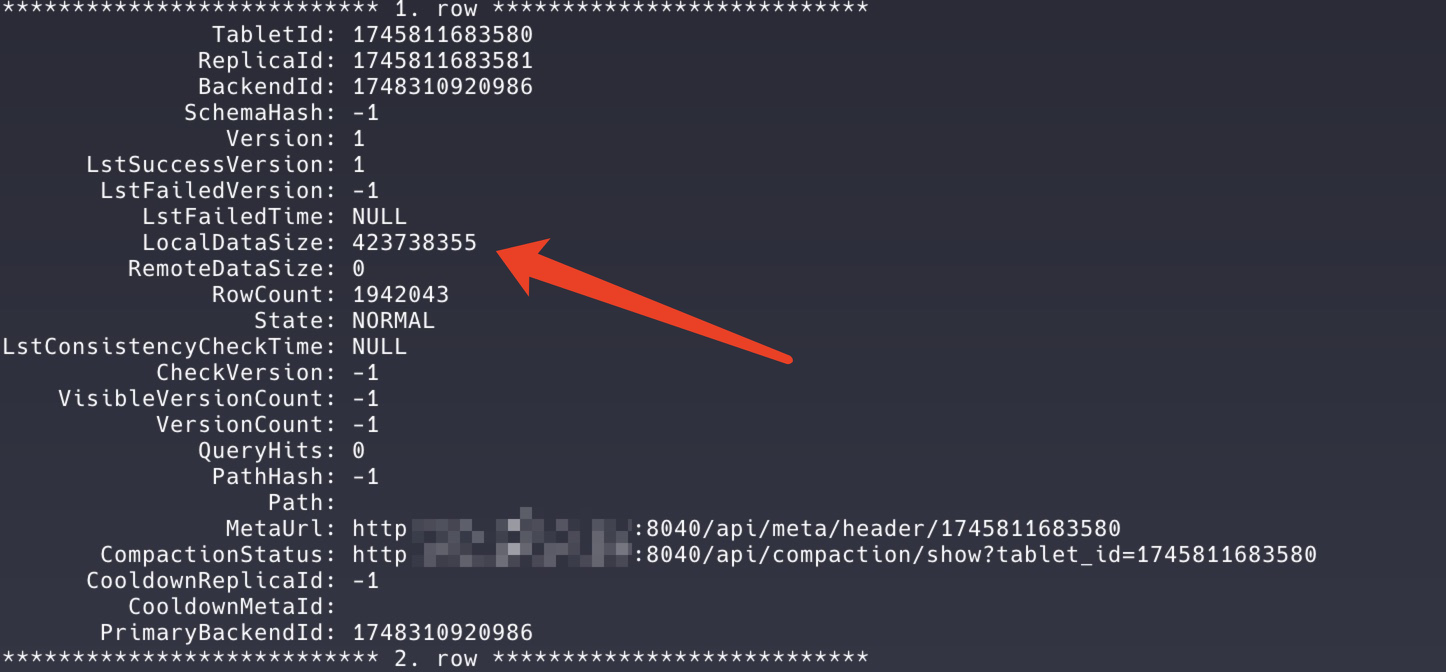
date(PARTITION BY RANGE(date)), allowing VeloDB to automatically manage partitions without manual intervention. We apply hash bucketing onaccount_address(DISTRIBUTED BY HASH(account_address) BUCKETS 64). The number of buckets is chosen considering table size and query characteristics, with each bucket ideally occupying 1–10GB. As shown in the diagram, we use 64 buckets, most containing 400–600MB of data and 2–3 million rows each. This design ensures balanced data distribution while avoiding excessive metadata overhead caused by too many small shards.
B. Secondary Indexes
For secondary indexing, we use VeloDB’s Inverted Index feature. High-frequency filter columns in the blockchain_l1_events table were indexed with inverted indexes to accelerate query performance.
INDEX idx_event_type (`event_type`) USING INVERTED,
INDEX idx_block_number (`block_number`) USING INVERTED,
INDEX idx_event_id (`event_id`) USING INVERTED,
INDEX idx_volume (`volume`) USING INVERTED,
INDEX idx_amount (`amount`) USING INVERTED,
INDEX idx_block_time (`block_time`) USING INVERTED,
INDEX idx_token_address (`token_address`) USING INVERTED,
INDEX idx_tx_hash (`tx_hash`) USING INVERTED,
INDEX idx_opponent_address (`opponent_address`) USING INVERTED,
INDEX idx_pair_address (`pair_address`) USING INVERTED
The choice of inverted indexes over bitmap indexes was driven by our query patterns, which often involve range filters(e.g., amount > 100 AND amount < 1000) and multi-condition compound filters. Inverted indexes offer significant performance advantages for high-cardinality columns and complex filter combinations, substantially reducing unnecessary data scans.
For example, when executing the queries above, VeloDB can leverage both the primary key prefix index (based on account_address) and the inverted indexes (on amount, volume, etc.) to perform multi-condition coordinated filtering, greatly improving query efficiency. This index optimization is especially critical for TB-scale data, reducing query response times from minutes to milliseconds.
4. Query Optimization
Ave.ai had several slow queries that were optimized on VeloDB. Below is an example of a multi-condition OR query:
SELECT tx_hash,
COALESCE(total_fee_u, 0) AS total_fee_u,
(COALESCE(fee, 0) + COALESCE(priority_fee, 0)) / 1000000000 AS total_fee
FROM blockchain_events.blockchain_l0_events
WHERE (date = '2025-05-01' AND tx_hash = '<hash1>' AND block_number = 342534861)
OR (date = '2025-05-02' AND tx_hash = '<hash2>' AND block_number = 342534858)
OR ...
OR (date = '2025-06-08' AND tx_hash = '<hash39>' AND block_number = 342516688)
ORDER BY block_number;
blockchain_events.blockchain_l0_events DDL is as follows:
CREATE TABLE `blockchain_l0_events` (
-- ignored columns
-- ignored inverted index
) ENGINE=OLAP
PRIMARY KEY(`tx_hash`, `date`)
COMMENT "OLAP"
PARTITION BY (`date`)
DISTRIBUTED BY HASH(`tx_hash`) BUCKETS 32
This query originally used multiple OR conditions combining 39 specific filters (on date, tx_hash, and block_number). In VeloDB, the query optimizer treats complex OR conditions as a single logical block, which prevents effective use of prefix indexes for segment filtering, bucketing, or partition pruning. As a result, a large amount of data must be scanned, increasing I/O and computational overhead, leading to slower query performance.
To address this, we optimized the query using UNION ALL, rewriting the SQL as follows:
SELECT tx_hash, COALESCE(total_fee_u, 0) AS total_fee_u, (COALESCE(fee, 0) + COALESCE(priority_fee, 0)) / 1000000000 AS total_fee
FROM blockchain_events.blockchain_l0_events
WHERE date = '2025-05-01' AND tx_hash = '<hash1>' AND block_number = 342534861
UNION ALL
SELECT tx_hash, COALESCE(total_fee_u, 0) AS total_fee_u, (COALESCE(fee, 0) + COALESCE(priority_fee, 0)) / 1000000000 AS total_fee
FROM blockchain_events.blockchain_l0_events
WHERE date = '2025-05-02' AND tx_hash = '<hash2>' AND block_number = 342534858
UNION ALL
...
UNION ALL
SELECT tx_hash, COALESCE(total_fee_u, 0) AS total_fee_u, (COALESCE(fee, 0) + COALESCE(priority_fee, 0)) / 1000000000 AS total_fee
FROM blockchain_events.blockchain_l0_events
WHERE date = '2025-06-08' AND tx_hash = '<hash39>' AND block_number = 342516688
ORDER BY block_number;
By using UNION ALL to connect subqueries, the query optimizer can treat each subquery as an independent query task. Each subquery’s condition (e.g., date = '2025-05-26' AND tx_hash = '<hash>' AND block_number = <number>) is highly selective, allowing VeloDB to efficiently leverage partition pruning, bucket pruning, and indexes:
- Partition Pruning: The condition
date = '2025-05-01'directly targets the relevant partition, reducing the number of partitions scanned. - Bucket Pruning: The condition
tx_hash = '<hash>'utilizes the hash bucket ontx_hashfor precise bucket-level filtering. - Prefix Index: Since the user key is
tx_hash, VeloDB can continue to use the prefix index for binary search.
Each subquery effectively performs a point query, targeting a specific date and tx_hash, involving minimal data. This allows VeloDB’s pipeline engine to execute subqueries in parallel with high concurrency, greatly improving query performance.
Summary
As Ave.ai continues to scale its analytics stack for Web3 and DeFi, VeloDB provides a solid foundation that can keep pace with its data growth and product plans.
Beyond performance and cost gains, VeloDB gives Ave.ai a future-proof path: a real-time data warehouse available across all major cloud providers, a SQL-friendly engine, and support for high concurrency and low latency. These features allow the Ave.ai team to focus on building new trading insights and user experiences, without being constrained by infrastructure limits.
If you want to learn more about VeloDB, contact the VeloDB team to discuss with technical experts and connect with other users, or join the Apache Doris community.