Kevin Shen is a member of the Apache Doris team. The views expressed here draw on his experience building IBM watsonx.data and working across data infrastructure
I have always been fascinated by history because you can often borrow solutions from the past to address challenges in the present. In data infrastructure, this instinct has never felt more relevant. The database industry is repeating a cycle that started two decades ago, and if we recognize the pattern early enough, we can skip the painful middle chapters.
The cycle goes like this: consolidation breeds rigidity, rigidity breeds specialization, specialization breeds fragmentation, and fragmentation eventually demands a new kind of convergence. We lived through every stage of this cycle with data. Now, as AI agents become the primary consumers of information, we are about to live through it again with context.
Stonebraker's Prophecy and the Polyglot Era
In 2005, Michael Stonebraker published a paper that reshaped how the industry thinks about databases. The title said it all: "'One Size Fits All': An Idea Whose Time Has Come and Gone."
Stonebraker argued that the relational database, originally designed for business data processing, had been stretched to serve workloads it was never built for. The traditional RDBMS architecture had been used to support applications with wildly varying characteristics and requirements for 25 years. He predicted the market would fracture into a collection of independent, specialized database engines.
He was right. By 2013, he had refined the argument to "One Size Fits None," declaring that the foundational architectures of leading commercial products like Oracle, SQL Server, and DB2 were incapable of processing modern workloads with the performance and efficiency of purpose-built alternatives.
The industry responded. Over the next 15 years, we saw an explosion of specialized systems: columnar OLAP warehouses (Snowflake, ClickHouse), document stores (MongoDB), search engines (Elasticsearch), stream processors (Kafka, Flink), graph databases (Neo4j), and eventually vector databases (Pinecone, Milvus). Each system excelled at a specific workload. Each one solved a real problem.
This approach got a name: polyglot persistence, the practice of using multiple database technologies, each chosen for its strengths, within a single application or organization. It was the right philosophy for its moment. But it came with a cost that compounded quietly over time.
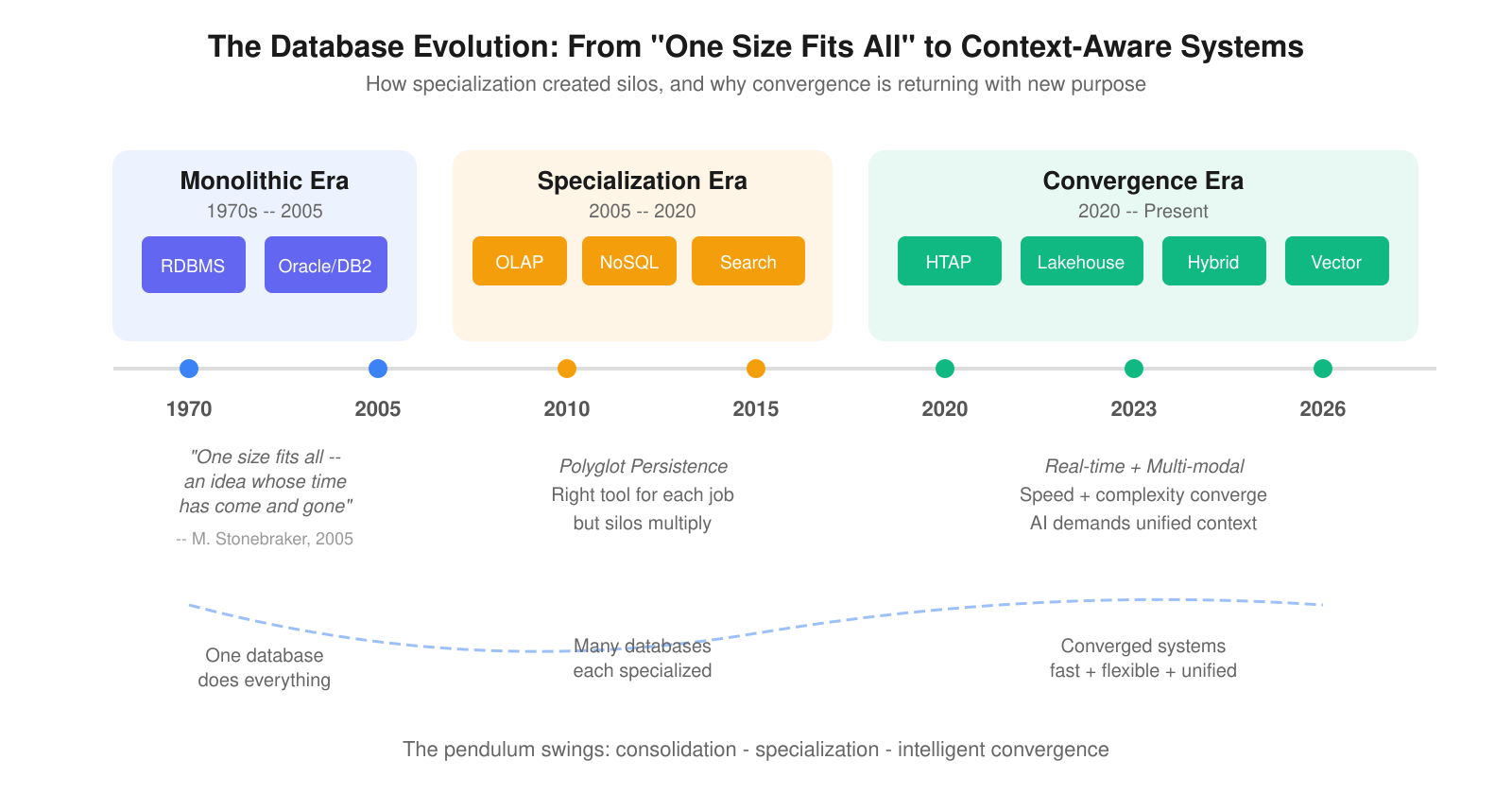
Figure 1: The database evolution from monolithic RDBMS to intelligent convergence
The Silo Problem We Already Solved (Mostly)
Polyglot persistence did not just introduce operational complexity. It created data silos.
Each specialized database held a slice of the truth. Customer transactions lived in one system. Behavioral logs lived in another. Search data lived in a third. Getting a unified view required building and maintaining ETL pipelines, schema mappings, and governance frameworks across all of them.
The industry spent 15 years wrestling with four categories of challenges:
Movement. Getting data from where it was produced to where it needed to be analyzed meant building batch pipelines that introduced hours of latency. An entire industry (Informatica, Fivetran, dbt) emerged to solve this single problem.
Quality. Data that crossed system boundaries degraded. Schemas drifted, duplicates multiplied, and freshness decayed. Organizations invested heavily in validation, deduplication, and monitoring to keep their data trustworthy.
Governance. As data spread across systems, controlling access, tracking lineage, and maintaining compliance became exponentially harder. Data catalogs and governance platforms became a multi-billion-dollar market.
Interoperability. Different systems spoke different languages. Translating between SQL, document queries, and search APIs required specialized integration layers that added latency and complexity at every junction.
For a world where humans queried dashboards a few times a day and tolerated a few seconds of latency, this patchwork architecture worked well enough. Batch processing could paper over the gaps. The distributed nature of the data landscape could handle the load when systems operated on human timescales.
But the consumer of data is changing.
Enter the New Consumer: AI Agents
In October 2025, Gartner analyst Avivah Litan declared that "context engineering is in, and prompt engineering is out," signaling a fundamental shift in how organizations should approach enterprise AI. The term captures a fundamental shift: AI systems do not just need data. They need the right context, at the right time, in the right format.
Context is data, but it comes in more varied forms (text, vectors, metrics, logs, embeddings), grows at a greater velocity, and is consumed at speeds that make human analytics look glacial. A single autonomous agent can generate more queries in an hour than a human analyst team produces in a week.
We can give this problem a name: the context silo. Unlike a data silo, where information is trapped in one system and unavailable to others, a context silo is a retrieval failure. The information may technically be accessible, but not at the speed, in the format, or with the freshness that an autonomous agent requires to act correctly. Context silos do not just slow decisions; they corrupt them.
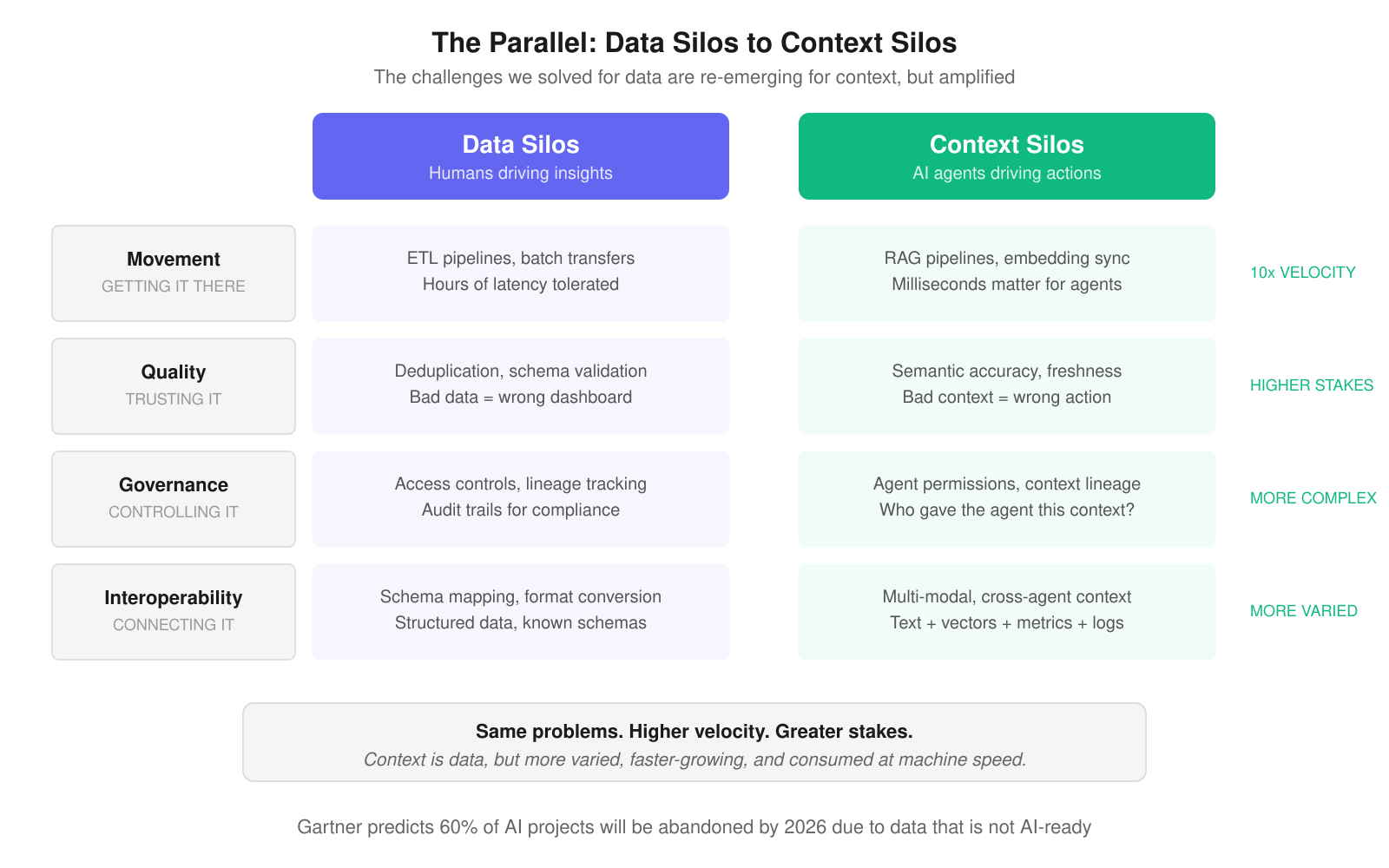
Figure 2: The same four challenges, amplified for the AI era
The same challenges we wrestled with for data (movement, quality, governance, and interoperability) apply directly to context. But the stakes are higher. Bad data produced a wrong dashboard. Bad context produces a wrong action. When an AI agent makes a decision based on stale or incomplete context, the consequences are not a misleading chart. They are an incorrect fraud flag, a misrouted support ticket, or a failed autonomous workflow.
Research from McKinsey confirms this: eight in ten companies cite data limitations as a roadblock to scaling agentic AI. That finding points to a specific failure mode: not missing data, but inaccessible data -- context that exists somewhere in the organization but cannot be retrieved fast enough, in the right format, at query time. That is precisely the architectural gap a unified context store is designed to close. Gartner predicts that through 2026, organizations will abandon 60% of AI projects unsupported by AI-ready data. The data silo problem, left unaddressed, is becoming the context silo problem, and it threatens to stall the most important technology shift of the decade.
In today's multi-agent architectures, the fragmentation is already visible. As one analysis put it, contextual information is fragmented and repeatedly implemented in each AI agent without any method to facilitate communication and extract information from one another. AI agent systems are often built in silos, without shared context, consistent governance, or coordination.
Why Batch Tolerance Breaks Down
For a while, the distributed nature of the current data landscape may handle context challenges well enough when systems operate in batches. We have decades of experience managing batch data movement, and the tooling is mature.
However, as we have seen with data applications moving to real-time with on-the-fly analytics, latency and consolidation become critical. Each hop between systems introduces lag, and lag is a critical issue for action-oriented systems.
Traditionally, we separated two fundamental workloads. Transaction and operational data were handled by one system (OLTP), while analytics occurred in another (OLAP). This separation made sense because the workloads had fundamentally different storage, I/O, and concurrency requirements. No single engine could serve both without compromise, so ETL processes periodically moved data from transactional databases into analytical warehouses.
Transaction systems are lightning fast, but they are constrained to a very narrow workload. They can process thousands of small writes per second, but ask them to aggregate a billion rows and they collapse.
Today, the demand for speed is paired with complexity. A single database query may add only milliseconds to an agent's response time -- negligible on its own. But modern AI agents do not make a single retrieval call. They iterate: retrieving context, reasoning, identifying gaps, retrieving again. Across five or ten rounds of this loop, latency compounds. What started as an invisible overhead becomes a delay the user can feel -- and in production systems handling thousands of concurrent agents, it becomes a throughput ceiling.
Consider what each retrieval round requires. An AI agent performing fraud detection does not just need the latest transaction. It needs the customer's historical pattern, their geographic context, the merchant's risk profile, and real-time behavioral signals. When those signals live in separate systems, every round of retrieval multiplies the number of cross-system hops.
The polyglot persistence approach introduces a structural problem at this speed. When a single decision reads from multiple data stores, each read reflects a different moment in time, evaluating a composite state that never actually existed. No pipeline connecting them can simulate a shared transaction boundary. At human speed, this inconsistency is tolerable. At machine speed, it is a fundamental failure mode.
The convergence signals are already appearing. In mid-2025, Databricks acquired Neon and Snowflake acquired Crunchy Data, each buying a PostgreSQL-native company rather than continuing to build OLTP capabilities into their analytical engines. Whether these acquisitions lead to true architectural convergence or simply add OLTP as another modular layer remains to be seen. But the signal is clear: the major platforms have concluded that serving AI workloads requires closing the gap between transactional and analytical systems -- and they are willing to pay a billion dollars to do it faster.
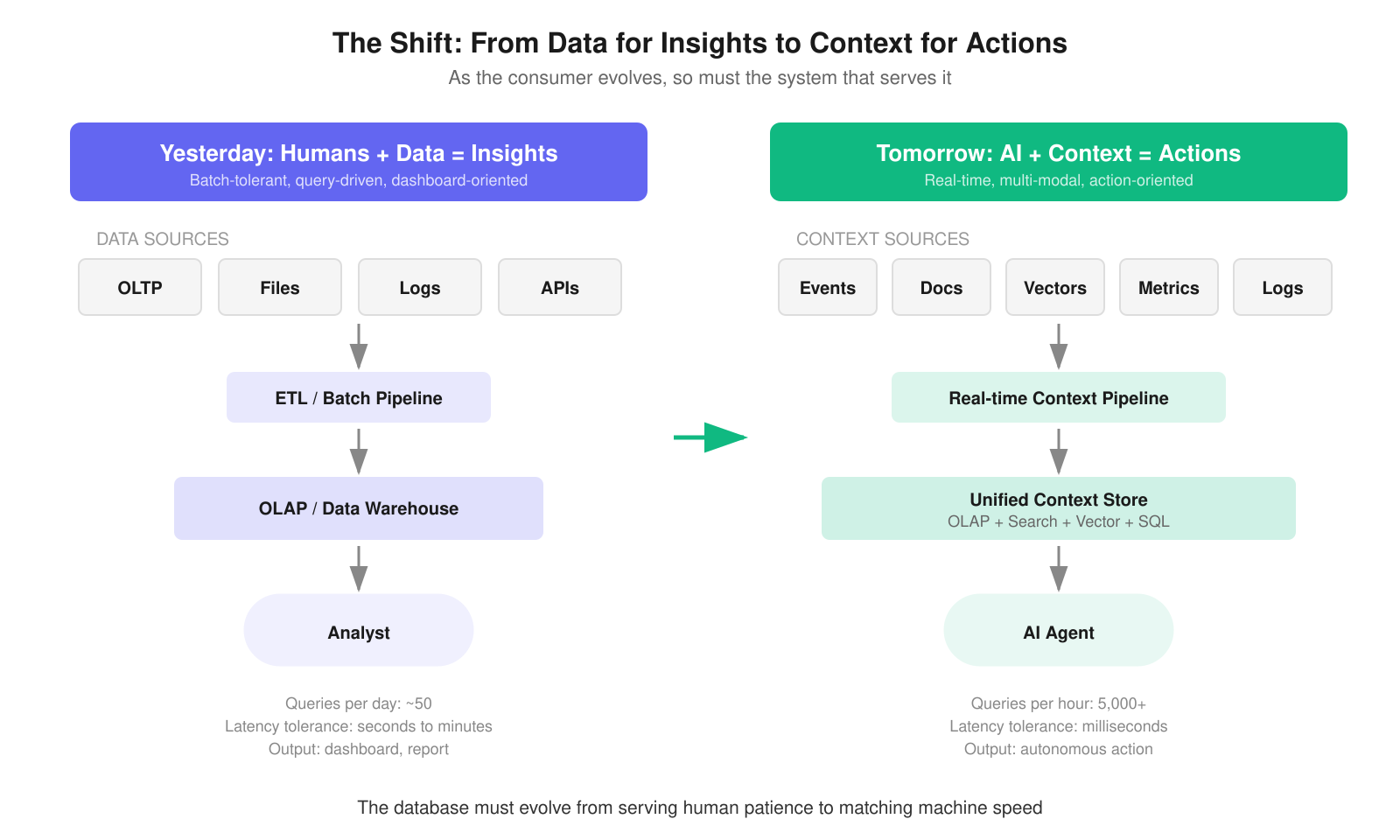
Figure 3: The evolution from human-driven insights to AI-driven actions
The Case for Convergence
The need for a fast, multi-modal, and flexible database is greater than ever as the data consumer evolves from humans using data to drive insights to AI using context to drive actions.
This is not a return to Stonebraker's "one size fits all." That monolithic approach failed because it forced compromises across every workload. What the AI era demands is intelligent convergence: systems that can handle analytical aggregation, full-text search, vector similarity, and structured SQL queries in a single system, without forcing the user to move data between specialized engines.
This convergence is not without engineering trade-offs. A system that handles columnar analytics, full-text search, and vector retrieval simultaneously must make deliberate choices about storage layout, memory allocation, and index maintenance. The question is whether the cost of those trade-offs is lower than the cost of operating and synchronizing four separate systems, and for most AI agent workloads, the answer is increasingly yes.
Consider what a modern AI agent stack requires. A lakehouse engine handles ad hoc analytical queries. A real-time database serves last-mile dashboards. A search engine powers log analysis. A vector database stores embeddings for RAG retrieval. That is four systems, four sets of pipelines, four governance models, and four sources of latency.
The context engineering framework emerging in enterprise AI recognizes this challenge. It spans five operational phases, from inventorying existing metadata through integration, packaging context products, runtime orchestration, and governing the context lifecycle. But every one of those phases becomes exponentially harder when context is scattered across purpose-built silos.
The databases that will win the AI era are the ones that collapse this stack. They will combine columnar analytics for speed, inverted indexes for search, vector indexes for semantic retrieval, and standard SQL for interoperability. They will handle high concurrency (thousands of agent queries per second), tolerate heavy data updates (because context changes constantly), and support complex joins (because decisions require correlating multiple signals).
The Lesson from History
History tells us that the database industry moves in cycles. Monolithic systems give way to specialized ones. Specialized systems create fragmentation. Fragmentation eventually drives a new wave of convergence. We are at that inflection point again, but the stakes are higher because the consumer demanding convergence is not a human analyst with patience for latency. It is an AI agent that needs answers in milliseconds and acts on them autonomously.
This architectural direction is no longer a contrarian bet; it is becoming the consensus. ClickHouse has expanded into full-text search and semi-structured data. SingleStore has long positioned itself as an HTAP solution. Snowflake and Databricks are both acquiring transactional database companies to close the gap. The entire industry is converging on the same conclusion.
This is why projects like Apache Doris excite me. I first encountered it while building IBM watsonx.data at IBM, so when the chance came up to work with the project's creators at VeloDB, I couldn't say no. Apache Doris has been ahead of this curve, shipping unified analytical, search, and vector capabilities ahead of the broader market. It represents the kind of intelligent convergence the AI era demands: real-time OLAP performance, full-text search, hybrid vector retrieval, and standard SQL in a single system. Not "one size fits all" in the old sense, but a unified foundation that eliminates context silos before they calcify into the next generation of infrastructure debt, which means the infrastructure organizations build on it today is aligned with where the industry is heading tomorrow.
The organizations that recognize this pattern early and consolidate their analytical and contextual infrastructure before fragmentation becomes unmanageable will be best positioned to scale AI from pilot projects to production systems.
Join the Apache Doris community and learn more today →https://doris.apache.org/