



NetEase Games is one of Asia's leading game developers, with popular titles including Where Winds Meet, Knives Out, and Naraka: Bladepoint, plus a deep portfolio spanning mobile and PC games across genres.
The data team behind those games runs a platform that handles 15 million queries per day across 200+ internal projects on petabyte-scale storage. As the portfolio expanded, daily ingestion grew into the hundreds of terabytes, and the original data stack could no longer keep up with the scale or the real-time demands of the business.
That original stack was built around six specialized systems: Hive and Spark for batch processing, Trino for ad-hoc queries, Elasticsearch and HBase for real-time lookups, and ClickHouse for analytics. It was expensive to build on, expensive to operate, and slower with every new terabyte of data.
To get to real-time analytics, support new AI workloads, and lower cost, NetEase Games decided to replace all six systems with Apache Doris in two phases:
-
Phase 1: Replace Elasticsearch, HBase, and ClickHouse with Doris, consolidating real-time analytics onto a single engine.
-
Phase 2 (starting on Apache Doris 2.1): Replace Hive, Spark, and Trino as well, building a unified lakehouse on Apache Doris and Apache Iceberg.
This article walks through the full migration: what the old architecture looked like, how each phase played out, and the use cases the team runs on the new stack today. The goal is a working case study for other large organizations facing the same tool sprawl and looking to consolidate.
Early Architecture and Pain Points
The original architecture split workloads across six engines. Batch queries ran through a Hive-based data layer, served by Hive, Spark, and Trino. Real-time queries fell to Elasticsearch, HBase, and ClickHouse.
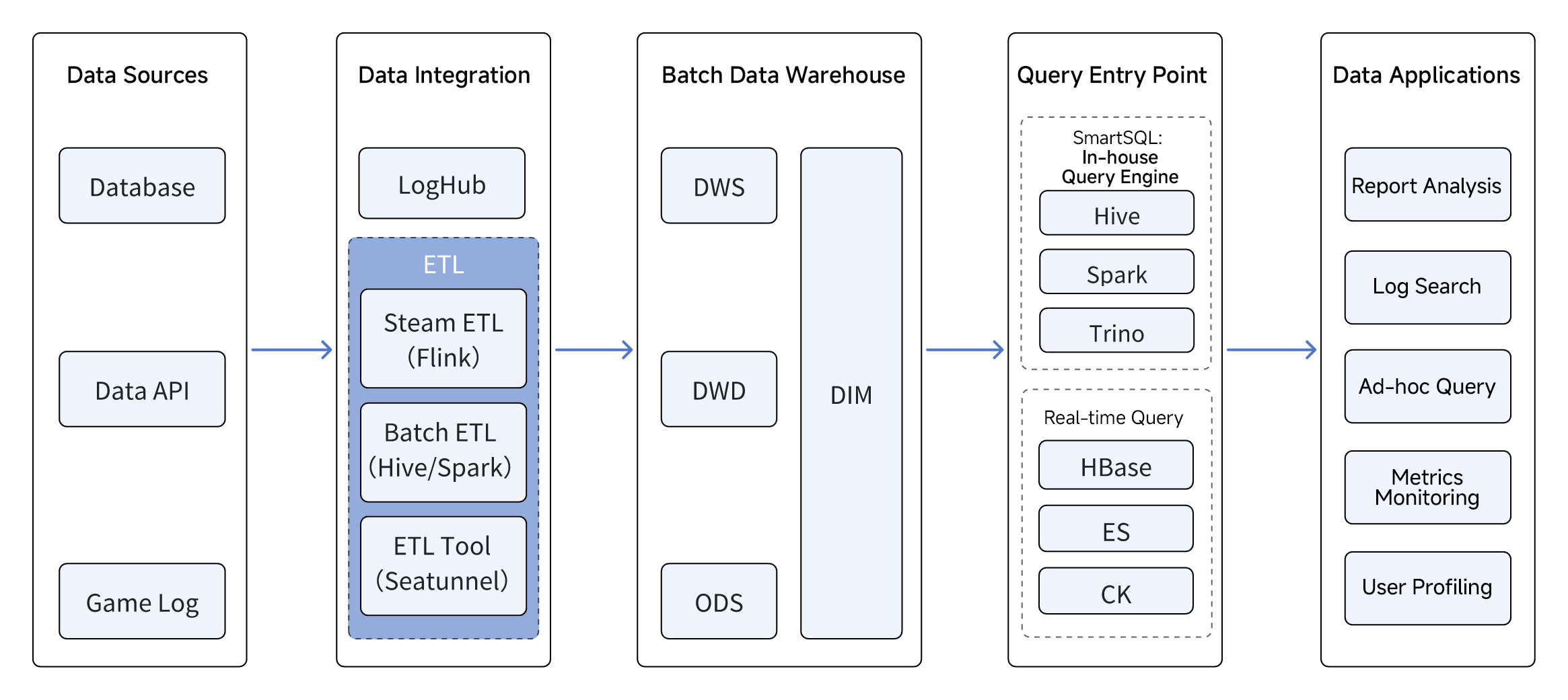
Four issues kept coming up:
-
Weak real-time performance. The data pipeline was long: data passed through multiple systems before reaching analysts, and the platform could not keep up with real-time analytics demand.
-
Slow query performance. Hive, Spark, and Trino's performance on interactive queries were not sufficient, while HBase, Elasticsearch, and ClickHouse offered limited support for complex joins.
-
High operational cost. Six components meant six sets of dedicated expertise, which drove up ops complexity and headcount.
-
High development cost. Every new requirement meant writing separate jobs for Spark, Trino, and HBase, plus Elasticsearch DSL queries. Analysts had to learn multiple tools and data models, which made development slow and expensive.
Apache Doris was already one of the most widely used OLAP engines elsewhere in NetEase, and its growing lakehouse capabilities made it the natural choice for consolidating the stack and moving toward a real-time-first architecture.
Phase 1: Building a Real-Time Data Warehouse with Apache Doris
In Phase 1, NetEase Games left the batch layer (Hive, Spark, and the rest) untouched and introduced Apache Doris as a new real-time layer, replacing Elasticsearch, HBase, and ClickHouse.
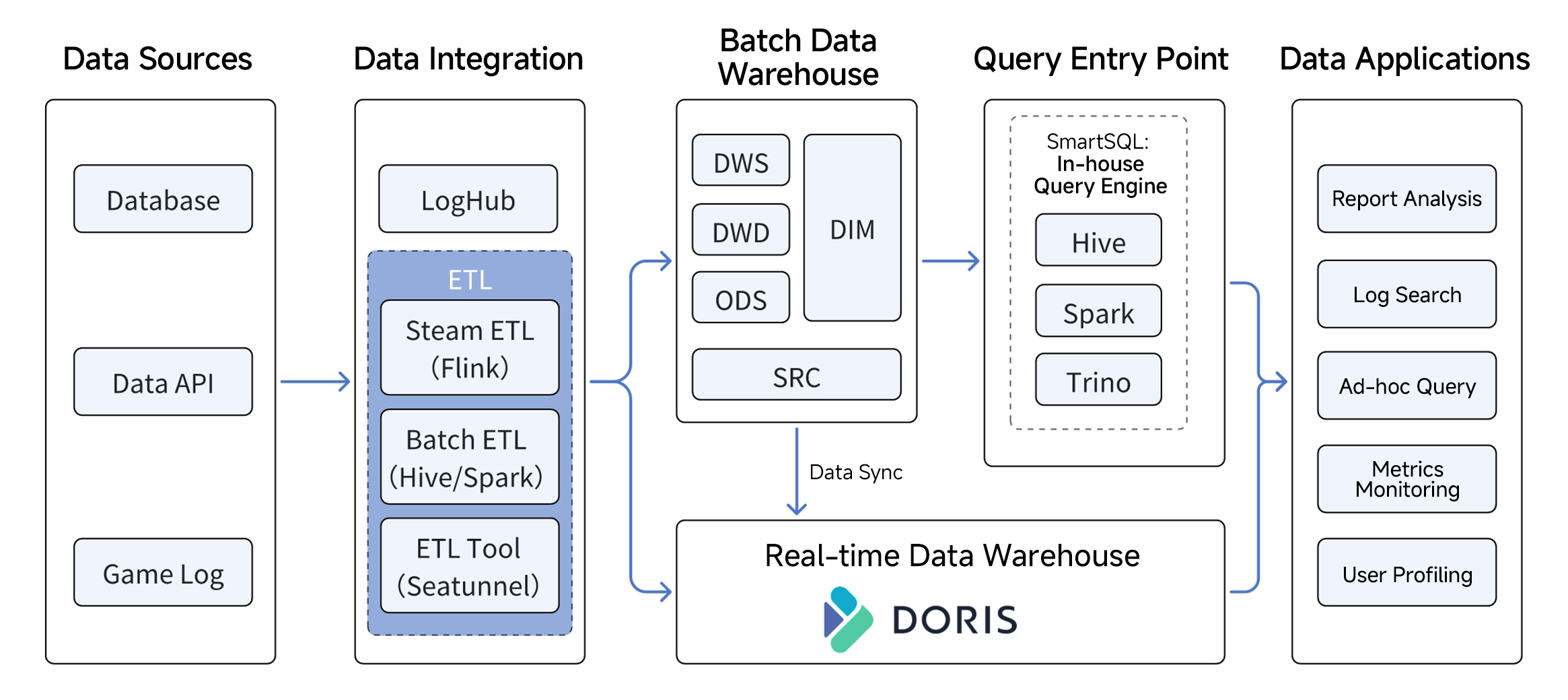
The result: data ingested directly into Doris became queryable within seconds. Batch data could also be loaded into Doris via Broker Load or SeaTunnel. Across many analytics workloads, response times improved sharply, and the overall architecture got noticeably simpler.
Phase 2: Building a Unified Lakehouse with Apache Doris
In Phase 2, NetEase Games also replaced Hive, Spark, and Trino, merging the batch and real-time layers into a single unified lakehouse with Apache Doris at its core. Materialized views were used to accelerate data lake queries and simplify data modeling.
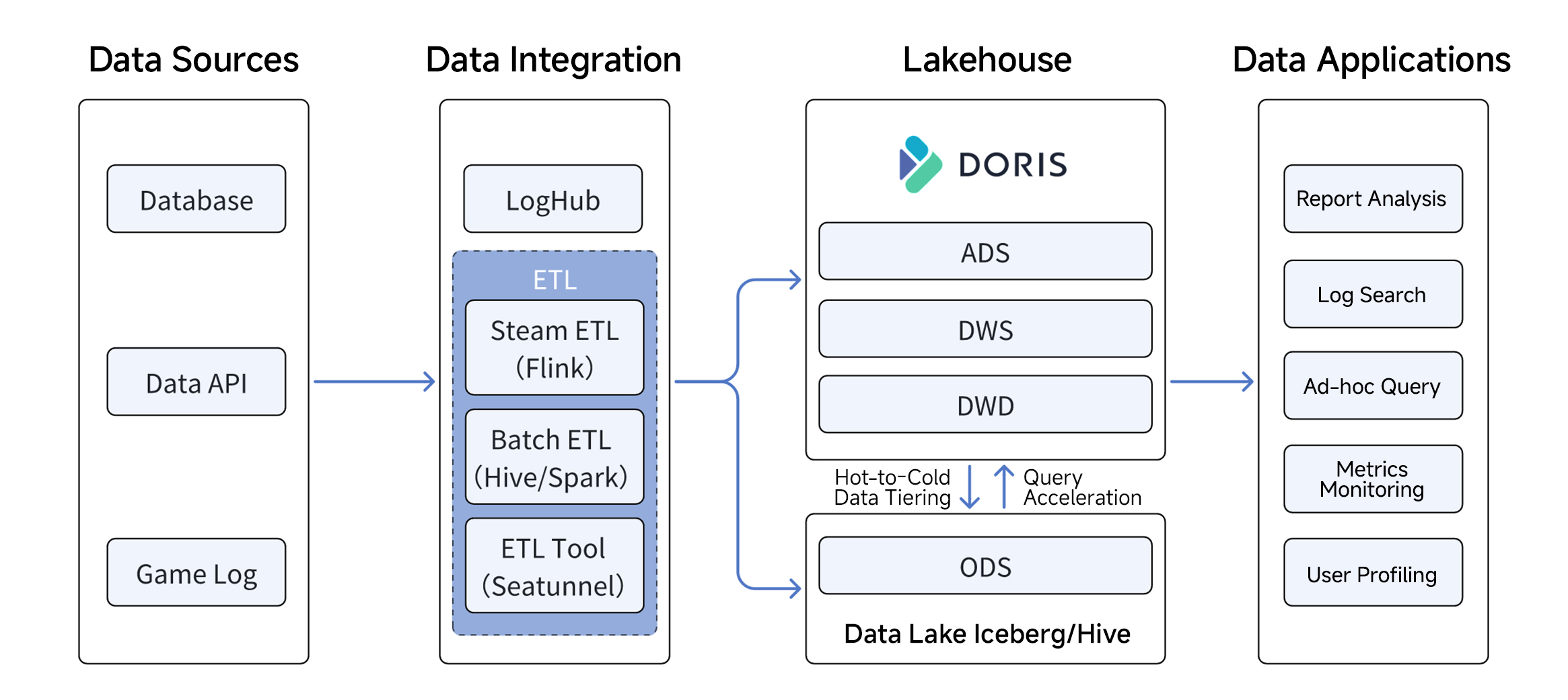
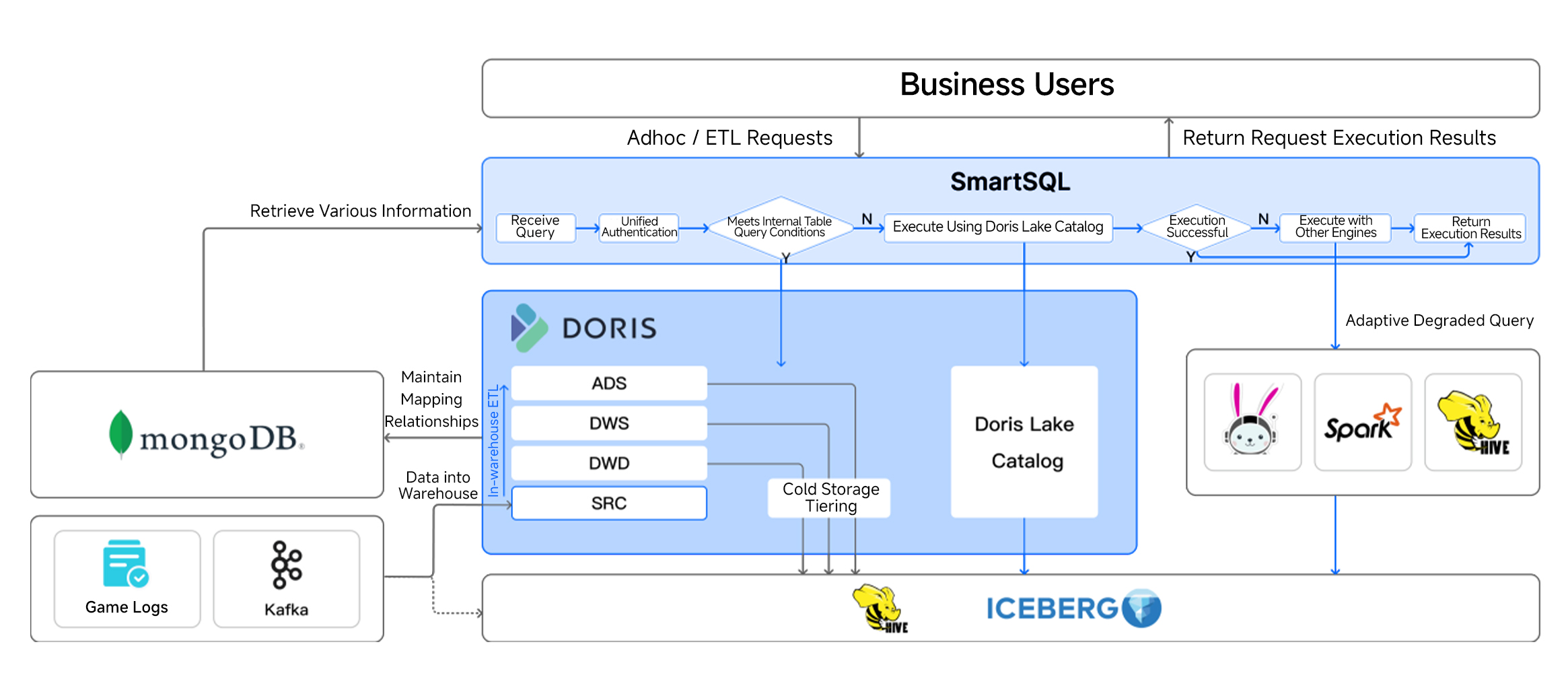
To keep the architecture flexible across business teams, NetEase Games also built SmartSQL, an internal query routing engine. SmartSQL supports two lakehouse patterns, both in production today:
-
Apache Doris as a query engine on top of an existing data lake, consuming open tables.
-
Apache Doris as a unified lakehouse, writing data in native format with additional performance accelerations.
Different teams adopt whichever pattern fits their priorities. SmartSQL itself provides multi-engine SQL dialect compatibility, query optimization for cost and efficiency, unified access control with row- and column-level encryption, and a unified integration layer for complex scenarios. The team is now exploring LLM-based extensions to SmartSQL as well.
Apache Doris as a Query Engine
In this pattern, data flows through the existing pipeline into Hive or Iceberg tables. Apache Doris sits on top as a query acceleration layer: its external table materialized view capability periodically syncs data from Hive or Iceberg into Doris internal tables.
When a query comes in, SmartSQL checks whether it hits a materialized view. If it does, the query runs against Doris internal tables for the fastest performance. If it does not, SmartSQL uses Doris Catalog to query the lake directly. For extremely large ETL jobs, SmartSQL falls back to the original Hive, Spark, and Trino engine pool to make sure the job completes.
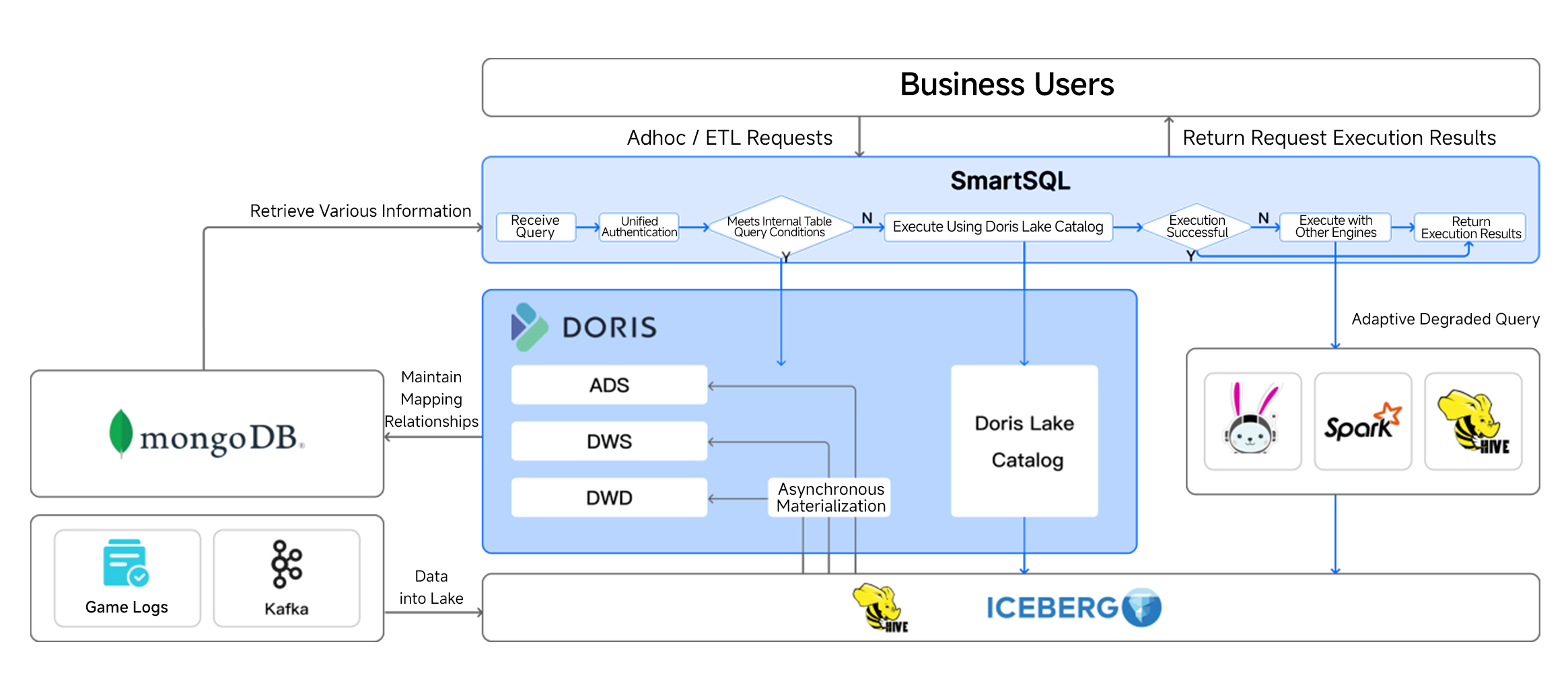
Unified Lakehouse with Apache Doris
In the unified lakehouse pattern, data lands in Apache Doris first, and both ETL and query workloads run there. This pattern delivers the best real-time and query performance, which makes it the right fit for real-time analytics workloads. As data ages and turns cold, the team uses Doris' data lake write-back capability to tier it out to Iceberg for long-term storage.
Integration Work
SQL Compatibility
SQL compatibility was critical for moving existing analytics tools and business logic onto the new architecture. Apache Doris held up on two fronts:
-
Hive UDF compatibility. Doris was designed to be compatible with Hive UDFs from the start. Migrating both generic and business-specific UDFs required only minimal changes.
-
SQL dialect conversion. For queries that do not match Doris syntax natively, Doris provides SQL dialect conversion for Presto/Trino, Hive, PostgreSQL, and ClickHouse, with compatibility rates landing at 99%+ in production.
Resource Isolation
Apache Doris now covers most workloads that previously ran on Trino. Because Trino was configured with a long list of resource-limit parameters to prevent large queries from monopolizing the cluster, ensuring Doris had an equivalent solution was essential.
After evaluating Apache Doris' Workload Group feature, the team found that all Trino-equivalent resource limits were supported, with some hard resource isolation scenarios performing even better than Trino. The table below maps Trino parameters to their Doris equivalents, useful for teams navigating a similar migration from Trino to Apache Doris.
| Trino Parameter | Meaning | Doris Implementation |
|---|---|---|
| query.max-scan-physical-bytes | Controls the maximum data volume scanned by a single query to prevent large queries from consuming too many resources. | be_scan_rows: tracks data scanned per query on the BE. Example: create workload policy canal_scan_1g_query conditions(be_scan_rows > 1073741824) actions(cancel_query) |
| query.max-memory | Limits the maximum memory a single query can use; queries exceeding this limit will be terminated. | Implemented natively. |
| query.max-memory-per-node | Defines the maximum memory each node can use per query, controlling per-node memory usage. | query_be_memory_bytes: tracks memory usage per query on the BE. Example: create workload policy canal_10g_query conditions(query_be_memory_bytes > 10240) actions(cancel_query) |
| query.max-execution-time | Limits the maximum execution time for a single query, including queue time and run time; timed-out queries are terminated. | query_timeout: specifies the maximum query duration. |
| query.low-memory-killer.policy | When system memory is insufficient, the system terminates queries to free up memory. | workload group: when a Workload Group's memory usage exceeds its configured limit, the system terminates queries to reclaim memory and prevent OOM. |
| query.queue-config-file | Specifies a file path containing query queue configuration, used to manage query queuing policies. | max_concurrency: maximum number of concurrent queries. max_queue_size: length of the query queue. |
Elastic Compute Resources
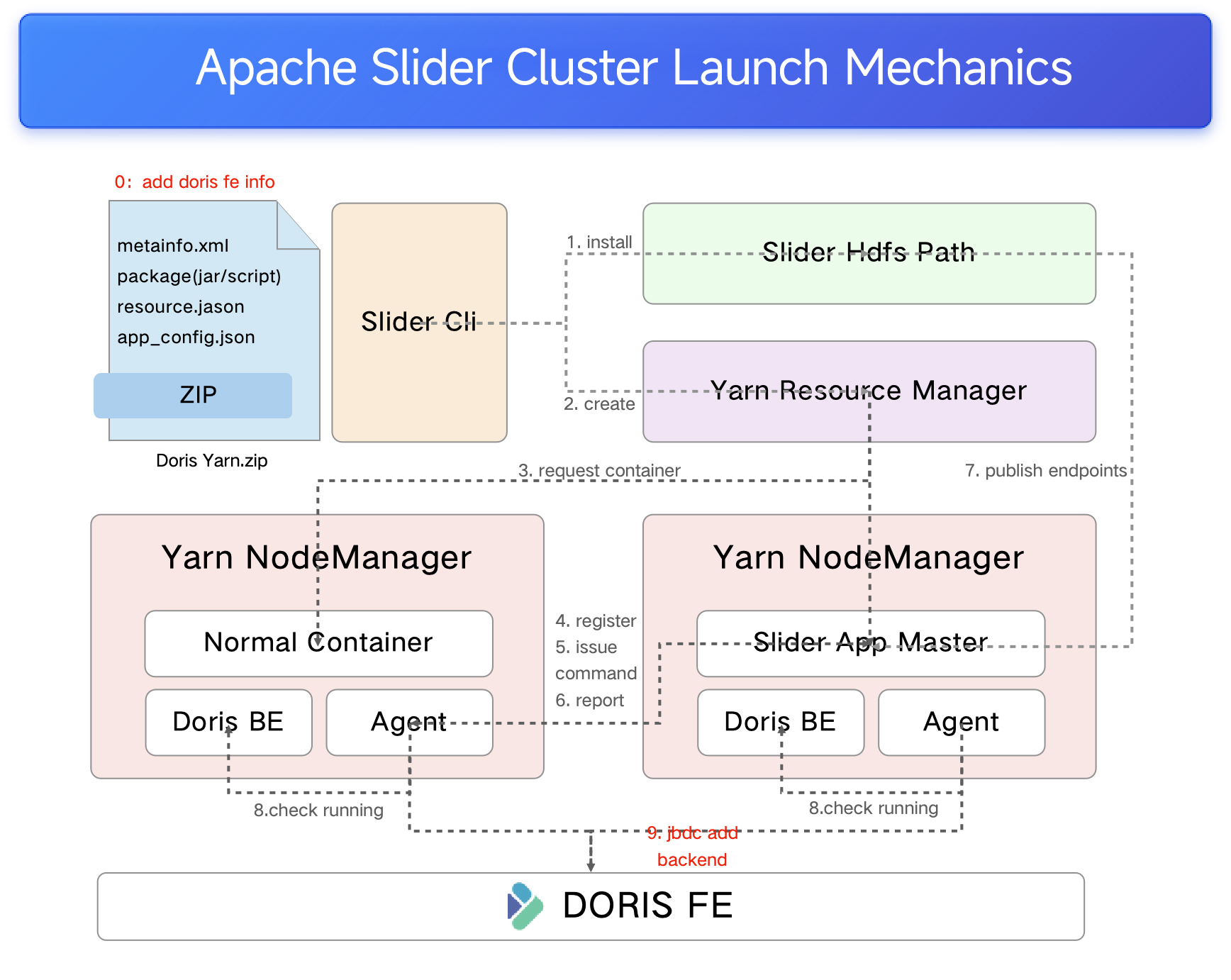
Apache Doris also offers the Doris Kubernetes Operator for elastic nodes. However, NetEase Games runs its own Hadoop cluster with a tidal pattern: low resource utilization during the day, high consumption overnight. To make more use of available compute resources, the team deployed elastic nodes on YARN instead.
The deployment uses Apache Slider, which provides a predefined lifecycle for creating, starting, and destroying cluster components, simplifying deployment on YARN. Supporting multiple YARN environments requires minimal setup: startup scripts plus Slider's create and destroy methods are sufficient to bring Apache Doris up quickly.
Apache Doris Use Cases
1. Wide Table Analytics
For wide table workloads, including survey data and CDN analytics, the team replaced ClickHouse with Apache Doris. Query performance is comparable between the two, but Apache Doris is significantly easier to operate: it lowers the technical bar for ops staff and reduces the operational risk that comes with ClickHouse's more demanding maintenance requirements.
2. User Behavior Analysis
User behavior analysis covers click tracking, payment event monitoring, and user profiling. Apache Doris' Bitmap index performance and Bitmap function support drove significant efficiency gains in these workloads.
Let's take player unique visitor (UV) tracking as an example. When a game rolls out a new update, the data team needs to monitor the conversion funnel from game patch download to final login, quantifying drop-off at each step. This requires precise deduplication of player device IDs across datasets of 1 billion records.
The team implemented two Bitmap optimization approaches for different scenarios:
-
Option A: Build a global dictionary table for player device IDs in Apache Hive, then import it into the corresponding Bitmap column in the Doris table.
-
Option B: Create a materialized view on the detail table using the
bitmap_hash64function to convert string IDs to Bitmap type. The team usedbitmap_hash64rather thanbitmap_hashbecausebitmap_hashproduces significant hash collisions above 20 million records, leading to inaccurate results.
After optimization, on a 1.4 billion record dataset: Bitmap query peak memory usage dropped from 54GB to 4.2GB, and query time dropped from 20 seconds to under 2 seconds.
3. Apache Doris as Unified SQL Engine
Apache Doris also serves as a unified SQL query engine, connecting different data sources for federated analysis. The team has implemented federated queries across Apache Doris, MySQL, Apache Hive, and Apache Iceberg.
Apache Doris' built-in federated query module handles cross-source queries efficiently, replacing Presto/Trino in these scenarios. Query performance outpaces Presto by 2-3x.
AI ChatBI Execution Engine
The team also used Apache Doris in AI and agent workloads. Doris is both the execution engine for ChatBI queries and the metadata store that powers the agents. When a user submits a question, SmartSQL agents query Doris to retrieve relevant metadata as context. That context feeds SQL pre-estimation, SQL rewriting, optimization, and error diagnosis.
What's Next
NetEase Games now runs 20+ Apache Doris clusters across hundreds of nodes, serving 200+ internal projects with 15 million daily queries on petabyte-scale storage. In the future, the team plans to focus on four areas:
-
Expanding the lakehouse solution: Bringing Apache Doris unified lakehouse to more business units and use cases to reduce costs and improve efficiency.
-
Smart materialized views: Continue to improve Apache Doris' materialized views to accelerate data lake queries. The next priority is using query job history to automatically identify and materialize hot SQL fragments.
-
Internal Doris Manager improvements: The internal Doris Manager will be updated to support new features in versions 2.1 and 3.0, with a focus on key capabilities that users care most about.
-
Apache Doris New Version: Apache Doris 3.0 introduces compute-storage separation architecture, opening up new deployment models for data lake scenarios. Apache Doris 4.0 brings hybrid search, vector search, full-text search, and more AI features. The team plans to evaluate these versions.
Join the Apache Doris community on Slack and connect with Doris experts and users. If you're looking for a fully managed Apache Doris cloud service, contact the VeloDB team.


