Kwai, developer of the popular generative AI video tool Kling AI, is one of Asia's largest short-video and live-streaming platforms with over 400 million daily active users. Similar to TikTok, Kwai also operates a massive advertising business.
Previously, we covered Kwai's Apache Doris adoption to replace ClickHouse. In that migration, the team built a unified lakehouse that handled nearly 1 billion queries per day with up to 6x faster performance compared to the prior system. Since then, Kwai has expanded its use of Apache Doris, replacing not only ClickHouse but also Elasticsearch.
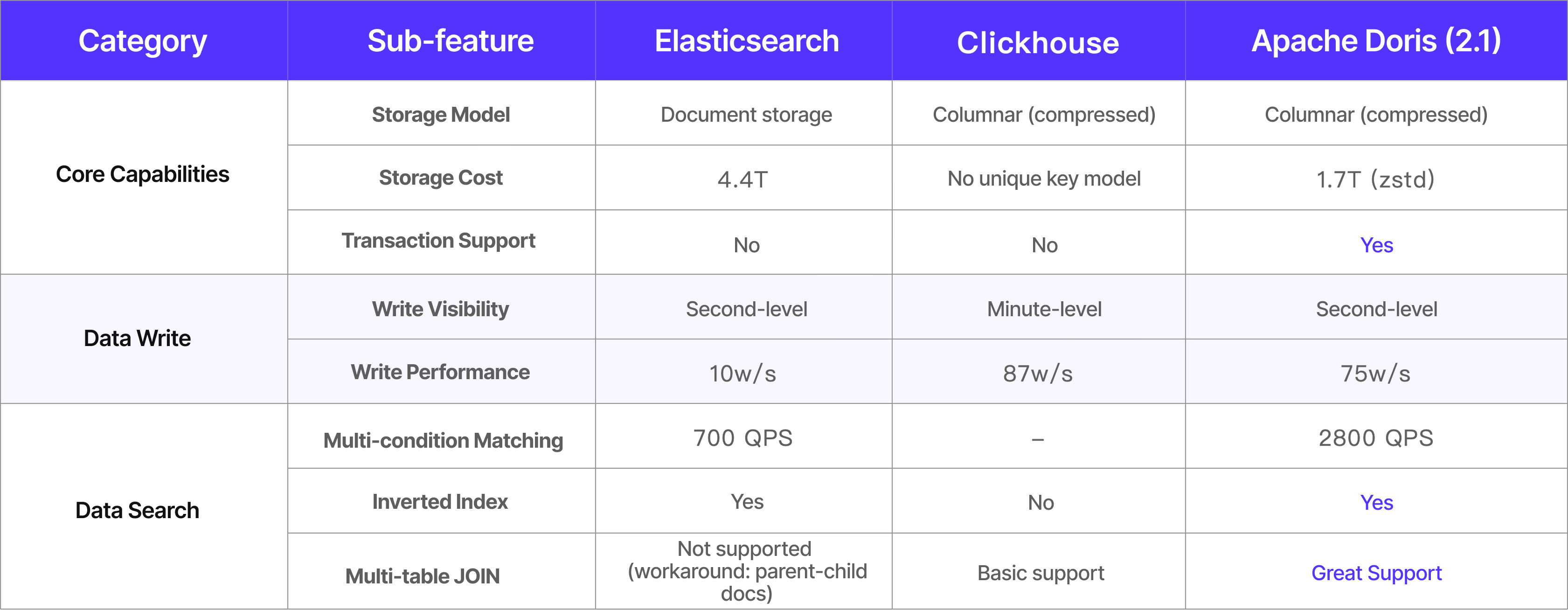
Kwai's ad platform previously relied on both ClickHouse and Elasticsearch. The former stored ad material data (text and documents), while the latter stored ad performance metrics. At query time, ClickHouse joined data from the two systems through its external table mechanism. As data volumes grew, Elasticsearch struggled to keep up: 35% of queries were slow, average query latency was 1.4 seconds, maintenance costs climbed, and the team lacked unified observability across ClickHouse and Elasticsearch.
To address these issues, the Kwai team evaluated Apache Doris, ClickHouse, and Elasticsearch head-to-head. The team eliminated ClickHouse first because it did not support unique key updates, which the ad material data update scenario required. Between Elasticsearch and Apache Doris, Doris won on write throughput, query performance, storage efficiency, and operational simplicity.
After migrating from ClickHouse and Elasticsearch to Apache Doris, Kwai achieved the following results:
-
Query latency decreased 64% to 90%. Average latency on the keyword promotion page dropped 64%, and creative promotion page latency dropped 90%.
-
Write throughput up 3x, with single-table real-time ingestion peaking at 3 million rows/sec per node
-
Storage efficiency up 60% compared to Elasticsearch. Using partitioning strategies and ZSTD compression, Doris comfortably supports trillion-row tables.
-
Slow query rate below 5% (down from 35%)
-
Troubleshooting time reduced 80% with unified observability
This article walks through Kwai's architecture evolution, migration process, and the optimization techniques they developed along the way, including strategies for data skew, partition pruning at 10,000+ partitions, and concurrency tuning.
From ClickHouse + Elasticsearch to a Unified Analytics Engine
Kwai's advertising platform serves all external advertisers and e-commerce sellers, who use it to create campaigns, manage ad materials, adjust bidding strategies, and track performance in real time. The scale of the advertising data is massive: trillions of rows of ad material data, 300 million new rows added per day, across about 700 core fields, and over 4,000 query templates.
Supporting ad campaigns and real-time analytics at this scale placed serious demands on the underlying data architecture. Kwai's ad data fell into two categories: material data (generated by the ad campaign system) and performance data (used for ad analytics). Three characteristics defined the core challenge:
-
Massive volume: Cumulative ad material data had already reached hundreds of billions of rows and was heading toward the trillions. This represented one of the largest data footprints at Kwai and posed a significant test of architectural scalability.
-
Rapid growth: In Q1 2025 alone, daily new ad material data grew 3.5x year-over-year. This growth rate required the underlying engine to handle high-throughput real-time writes and elastic scaling.
-
Complex data model: The full data schema covered roughly 700 core fields across materials, campaigns, users, and performance dimensions. Over time, more than 4,000 query templates accumulated to serve diverse analytics scenarios, placing significant pressure on query engine compatibility and performance.
The Architecture before Apache Doris
Before migrating to Apache Doris, Kwai stored ad material data across MySQL and Elasticsearch, while ad performance data (impressions, clicks, costs) resided in ClickHouse.
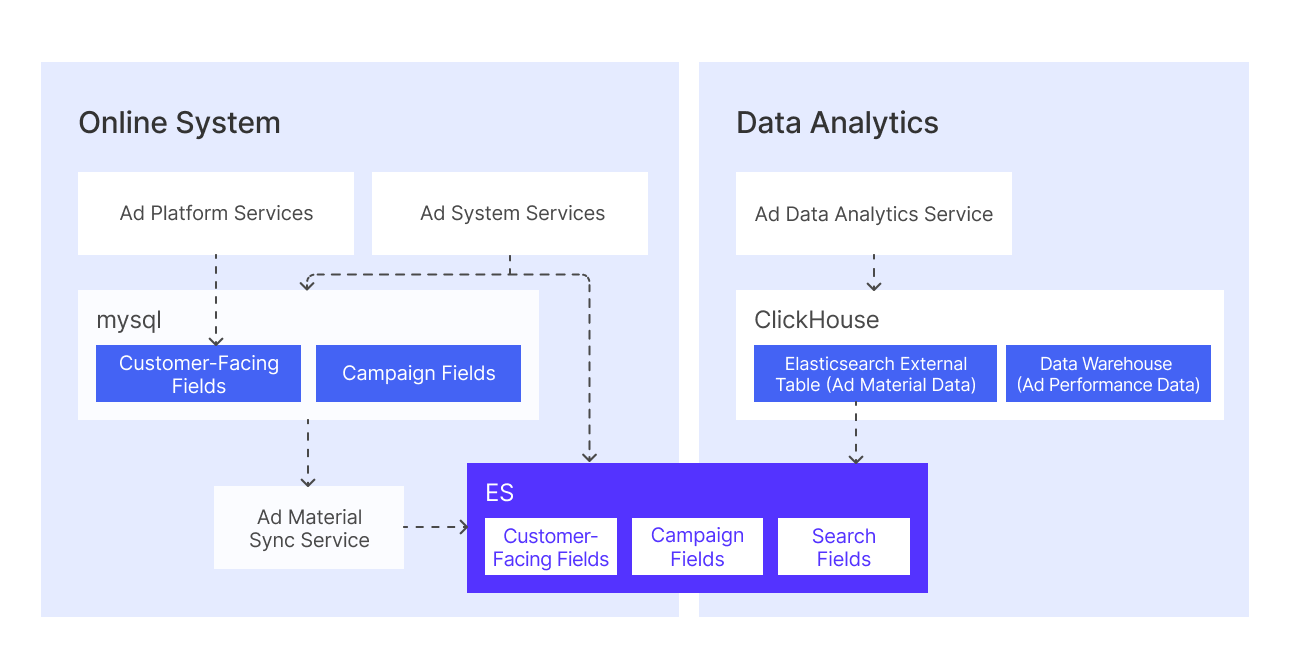
Under this architecture, generating ad performance reports required the system to join material data from Elasticsearch with performance data from ClickHouse. A typical user query referenced both an Elasticsearch external table (for material data) and a ClickHouse internal table (for performance data). ClickHouse handled the join by parsing the external table portion of the query, translating it into an Elasticsearch query, fetching the results via HTTP, converting them into internal data blocks, and then performing the join computation against the internal table.
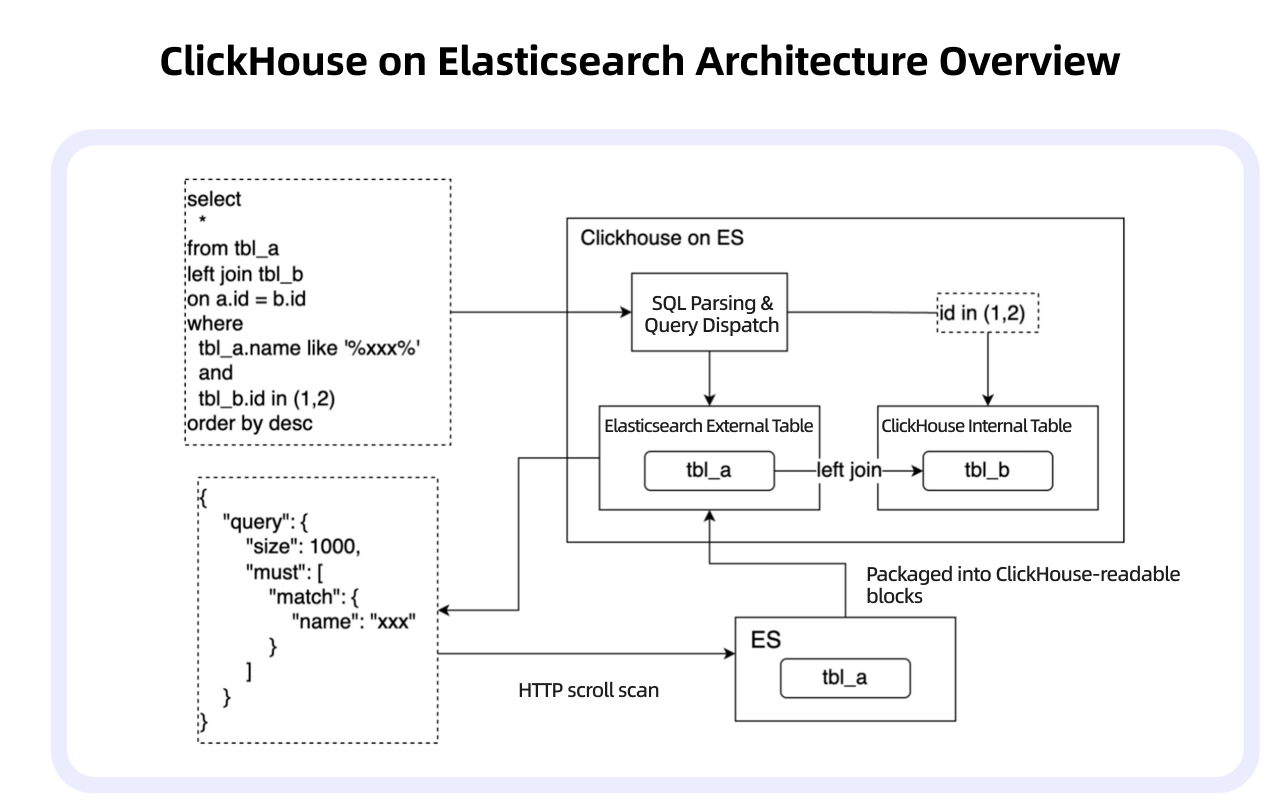
However, as data volumes in Elasticsearch grew, this architecture hit several walls:
-
Query degradation: The slow query rate climbed to 35%, and average query latency reached 1.4 seconds.
-
Storage bottleneck: A single Elasticsearch shard couldn't handle datasets exceeding 1 billion rows. Scaling out meant costly data redistribution.
-
Operational complexity: The multi-component data pipeline increased monitoring and maintenance overhead.
-
Observability problems: Because no end-to-end observability existed between ClickHouse and Elasticsearch, diagnosing latency spikes or data inconsistencies required lengthy cross-system investigation.
Evaluating Alternatives
These challenges prompted the team to set clear targets for a replacement system:
-
Slow query rate below 5%
-
Troubleshooting time reduced to minutes
-
Support for trillion-row single tables
-
Data freshness within 5 minutes
With these targets established, Kwai benchmarked Apache Doris, ClickHouse, Elasticsearch, and other mainstream OLAP engines in comprehensive stress tests. The team compared write throughput, query latency, storage compression, and full-text search performance.
The team eliminated ClickHouse early because it did not support unique key models, and ad material data required frequent primary key updates. The evaluation then focused on Elasticsearch versus Apache Doris.
Across the board, Apache Doris outperformed Elasticsearch in write throughput, query efficiency, storage cost, and operational simplicity. Because Doris met or exceeded every target, the team selected it as the next-generation ad analytics engine.
Bleem: The Unified Analytics Engine on Apache Doris
With the evaluation complete, the Kwai team replaced both ClickHouse and Elasticsearch with Apache Doris and built a unified analytics engine called Bleem. Bleem added a data caching layer and a metadata service layer for external tables, which brought query performance on external data lake tables up to par with internal tables.
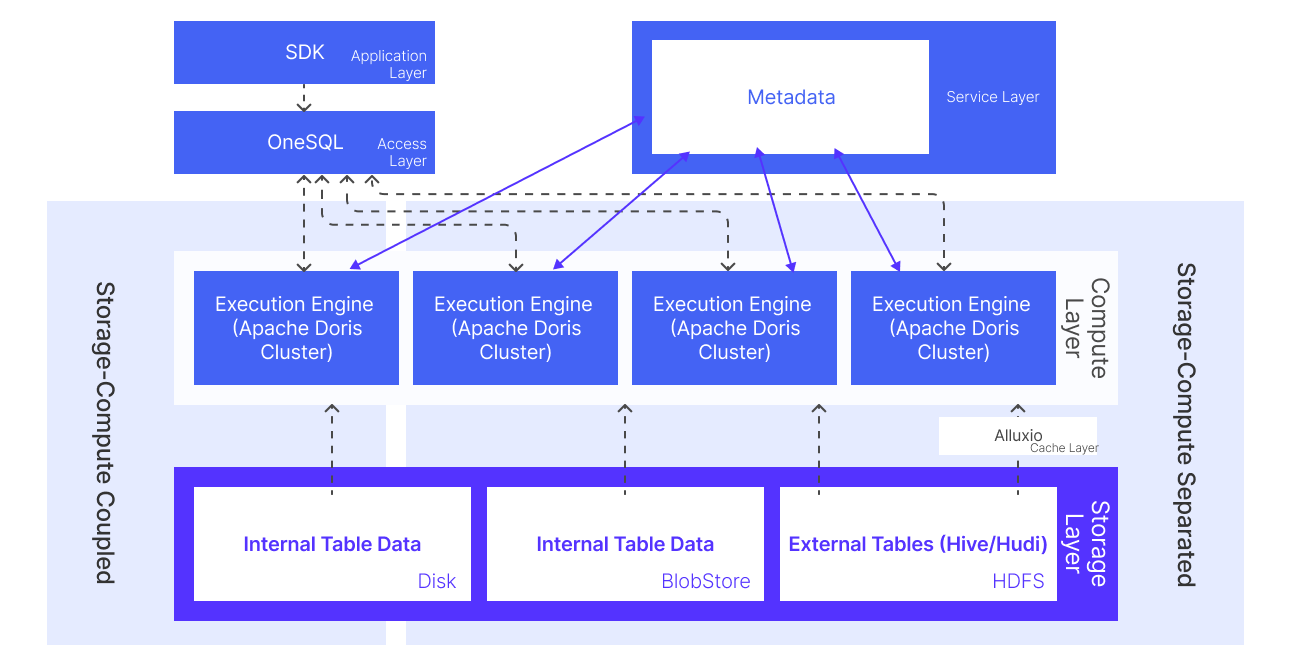
Bleem's architecture consisted of five layers, from bottom to top:
-
Storage layer: The team stored Hive/Hudi data in the data lake on HDFS. Internal table data resided on object storage in storage-compute separation mode, or on local disk in storage-compute coupled mode.
-
Cache layer: Hive/Hudi external table data was cached in Alluxio to stabilize I/O and improve read performance.
-
Compute layer: Apache Doris served as the core engine. Different operational teams ran on separate Doris clusters to ensure physical resource isolation, and each team could request additional compute resources on demand. Doris' lakehouse query capabilities allowed it to query both internal tables and external Hive/Hudi data directly, supporting both storage-compute coupled and storage-compute separated deployment modes.
-
Service layer: A metadata caching service listened for Hive metadata changes in real time and synced them to cache, which improved external table query efficiency.
-
Access layer: OneSQL served as the unified query gateway, handling cluster routing, query rewriting, materialized view rewriting, query authorization, rate limiting, and circuit breaking.
With this architecture, Kwai consolidated multiple previously fragmented workloads into a single engine. Apache Doris now unified data lake analytics, real-time OLAP queries, online reporting, and full-text search.
The migration delivered the following architecture-level gains:
-
Slow query rate dropped below 5%, overall query performance up 20% to 90%.
-
Horizontal scaling 10x more efficient than Elasticsearch, and the system supported trillion-row tables
-
Simplified operations: one engine covered all query scenarios with fewer system dependencies.
-
Full observability: Apache Doris' end-to-end tracing and monitoring reduced average troubleshooting time by 80%
Migration and Optimization
The team carried out the migration in three phases to ensure a smooth business transition:
-
Phase 1, Trial Validation: The team selected the keyword promotion scenario as a pilot. They ran full and incremental data import pipelines and set up dual-pipeline parallel validation to confirm data consistency and query correctness.
-
Phase 2, Core Migration: The team migrated the ClickHouse-on-Elasticsearch query pipeline and imported all ad material data from Elasticsearch into Apache Doris. Once the cutover was complete, they decommissioned the Elasticsearch cluster.
-
Phase 3, Full Implementation: The team migrated the remaining ClickHouse-only scenarios, including queries and data that did not involve Elasticsearch joins, which completed the full unified architecture.
The following sections describe the key optimization techniques the team developed during this migration.
Ensuring Data Consistency with Distributed Locks
One of the first challenges the team addressed was data consistency during ingestion. They used Apache SeaTunnel for streaming data synchronization, with overwrite semantics for batch scenarios. All imports used two-phase commit to ensure eventual consistency.
However, during SeaTunnel and Spark-based synchronization, the team encountered data duplication in certain edge cases:
-
Speculative execution: Spark could launch duplicate tasks to hedge against slow executors. If two tasks both raced to completion and both finished Apache Doris' two-phase commit, the data was written twice, even though the Driver only counted one task as successful.
-
Task failure after commit: If a Spark task was preempted or crashed after completing its Doris commit but before reporting success back to the Driver, the Driver assumed the task had failed and retried it, writing and committing the same data a second time.
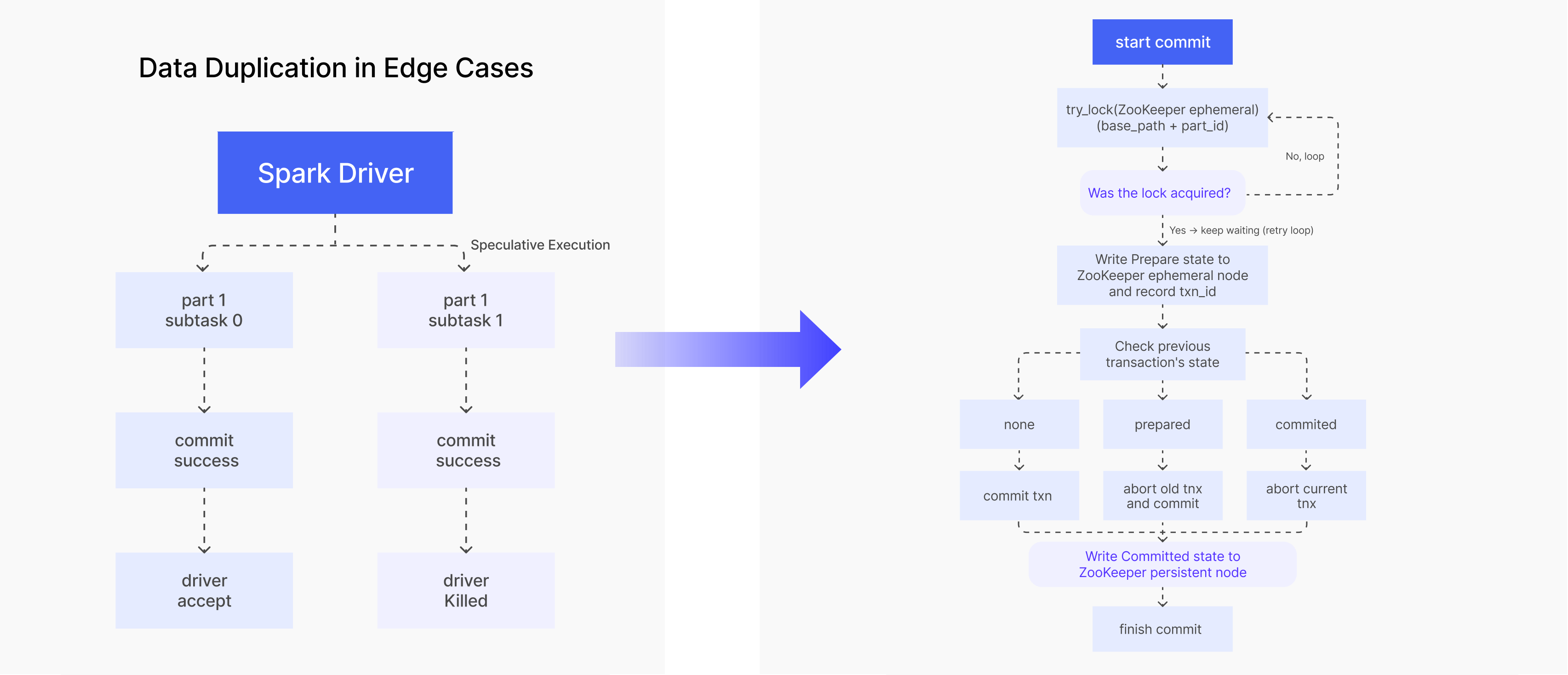
To solve this, the team introduced a ZooKeeper distributed lock in the two-phase commit process:
-
Before committing, acquire a ZooKeeper ephemeral lock and ensure only one transaction enters the commit flow at a time.
-
After acquiring the lock, write the
Preparestate and current transaction ID to a ZooKeeper ephemeral node. -
Check the previous transaction's state:
-
If no previous transaction exists, commit the current transaction.
-
If the previous transaction is in
Preparestate, roll it back first, then commit the current transaction. -
If the previous transaction is already
Committed, roll back the current transaction (it's a duplicate).
-
-
Write the
Commitstate to a ZooKeeper persistent node to finalize the operation.
Tuning Stream Load for High-Throughput Ingestion
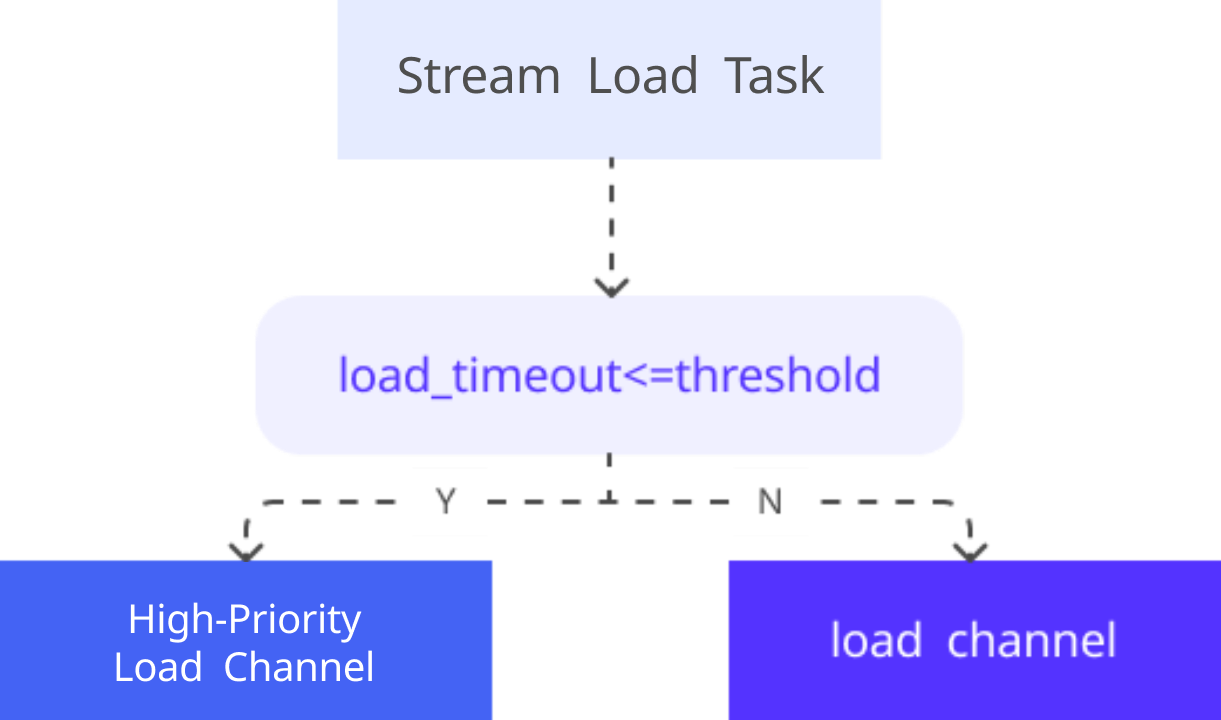
To handle high-concurrency data ingestion, the team tuned Apache Doris' Stream Load mechanism. By configuring task priorities and compaction parameters, they improved write throughput and stability.
Apache Doris used Load Channel for task scheduling, distinguishing between high-priority and normal-priority channels. When a Stream Load task's specified timeout was less than 300 seconds, the system classifies it as high-priority and routes it to the high-priority channel.
Key parameter tuning:
load_task_high_priority_threshold_second=300
compaction_task_num_per_fast_disk=16
max_base_compaction_threads=8
max_cumu_compaction_threads=8
Table Design: Ad Material Tables and Ad Performance Tables
With ingestion optimized, the team turned to table design, which heavily influences query performance in an OLAP engine. They adopted different strategies for the two main data types:
Ad Material Table: high-frequency updates + large-scale search:
This table holds massive volumes of ad material data with frequent real-time updates. Business queries primarily filter by account_id rather than MySQL's auto-increment id. To leverage Apache Doris' prefix index and sort key, the team used account_id and id as a composite primary key, with account_id as the leading sort key and bucket key, significantly improving filter efficiency. Inverted indexes support multi-dimensional search, and ZSTD compression balances storage size with I/O performance.
-- Ad Material table: Unique Key model with inverted index
CREATE TABLE ad_core_winfo
(account_id BIGINT NOT NULL,
id BIGINT NOT NULL,
word STRING,
INDEX idx_word (`word`) USING INVERTED...)
UNIQUE KEY(account_id, id)
DISTRIBUTED BY HASH(account_id) BUCKETS 1000;
Ad Performance table: multi-dimensional aggregation:
Unlike the ad material table, the ad performance table focused on metric aggregation (impressions, clicks, costs). It used the Aggregate model with auto-partitioning by day or hour granularity.
-- Performance table: Aggregate model with auto-partitioning
CREATE TABLE ad_dsp_report
(__time DATETIME,
account_id BIGINT, ...
`ad_dsp_cost` BIGINT SUM,
...)
AGG KEY(__time, account_id, ...)
AUTO PARTITION BY RANGE(date_trunc(`__time`, 'hour'))()
DISTRIBUTED BY HASH(account_id) BUCKETS 2;
Handling Data Skew Across Large Accounts
During stress testing, the team discovered another challenge: significant data volume disparity across Account IDs, ranging from single-digit rows to millions. This disparity caused severe CPU load imbalance across BE nodes. SHOW DATA SKEW confirmed the problem: large tablets reached 3–4 GB while small ones were only 100–200 MB, and large-account queries ran noticeably slower.
Two optimizations addressed this:
A. Range partitioning by Account ID
Account IDs are 5–8 digit numbers (and won't exceed 10 digits). The team used FROM_UNIXTIME to convert Account IDs to Datetime type and partitioned by month, creating 33 historical partitions. Each partition held up to 2,592,000 Account IDs, so a new partition was only needed every 2 million new accounts. The team manually bucketed historical partitions based on data volume, while new partitions defaulted to 256 buckets.
This approach enabled effective partition pruning, filtering out irrelevant data while leaving room for future growth. Because the material table added 300 million rows per day, this design maintained high query performance even as the number of partitions scaled.
B. Secondary hashing on Account ID
To address uneven distribution within partitions caused by large advertisers, the team computed ID MOD 7 (using the id field, which is independent of account_id) to produce a mod field with values 0–6. The bucket key was changed from account_id alone to (account_id, mod), distributing a single account's data across 7 BE nodes.

After these optimizations, tablet sizes stabilized around 1 GB each. Data storage and query load distributed evenly across BE nodes, which resolved the CPU imbalance.
Optimizing Query Planning at 10,000+ Partitions
As the data skew optimizations increased the number of partitions, a new bottleneck emerged. With partition counts reaching the tens of thousands, simple point queries took 250 milliseconds, well above the 100ms target. In Apache Doris version 2.1, partition pruning worked by linearly scanning through all partitions to find matching ones. With tens of thousands of partitions, this sequential scan became expensive.
The fix was straightforward. The team sorted the partitions first and then used binary search to locate the target partition instead of scanning through all of them. This change brought time complexity down from O(n) to O(log n), and query latency dropped from 250ms to 12ms, a 20x improvement. The fix has since been merged into the Apache Doris 3.1 release.
Concurrency Tuning
The final optimization addressed query concurrency. During query optimization, the team noticed something counterintuitive: most queries, even for large advertiser accounts, hit only a few million rows after filtering. Yet query profiles showed Total Instance counts as high as 800. This was the result of a default concurrency setting of 32, which caused significant over-parallelization for what were effectively small result sets.
Reducing concurrency:
set global parallel_exchange_instance_num=5;
set global parallel_pipeline_task_num=2;
After tuning, the Total Instance count dropped from 800 to 17. The takeaway was clear: for point queries that returned a small amount of data, high concurrency did not help. Instead, it multiplied RPC calls and added latency. Dialing it back brought query latency from 220ms down to 147ms and also improved overall system QPS capacity.
Results and What's Next
After completing the full architecture migration and applying all optimizations, the team achieved significant improvements:
-
Query latency decreased 64% to 90%. Average latency on the keyword promotion page dropped 64%, and on the creative promotion page, it dropped over 90%.
-
Write throughput increased more than 3x, with single-table real-time ingestion peaking at 3 million rows/sec per node.
-
Storage efficiency improved approximately 60% compared to Elasticsearch. Using partitioning strategies and ZSTD compression, the system comfortably supported trillion-row tables.
Looking ahead, the team plans to explore two additional areas with Apache Doris:
-
Enhanced full-text search and tokenization: The team plans to adopt BM25 scoring (introduced in Apache Doris 4.0) and additional tokenizer components like the IK analyzer, enabling flexible tokenization strategies for different business scenarios.
-
Vector index capabilities: The team also aims to leverage Apache Doris 4.0 to validate and optimize vector search performance for both internal tables and data lake external tables.
Summary
Kwai's ad platform migration demonstrates what is possible when an organization consolidates ClickHouse and Elasticsearch into a single engine. Apache Doris now handles ad material search, performance analytics, data lake queries, and online reporting, delivering better query performance, lower storage costs, and full observability across the stack.
Looking ahead, the team plans to explore two additional capabilities with Apache Doris 4.0:
-
Enhanced full-text search: The team plans to adopt BM25 scoring (introduced in Apache Doris 4.0) and additional tokenizer components like the IK analyzer to support flexible, scenario-specific tokenization.
-
Vector index capabilities: The team also aims to leverage Apache Doris 4.0 to validate and optimize vector search performance for both internal tables and data lake external tables.
For more details on Apache Doris, join the Apache Doris community on Slack. If you're interested in a fully managed experience, check out VeloDB Cloud.