



If you're building in Web3, managing massive amounts of data from blockchains is part of daily business. Bitcoin, Ethereum, Solana, BNB Chain...these public blockchains generate hundreds of millions of transactions every day and a continuous stream of data from transactions, smart contract interactions, NFT mint, DeFi swap, and asset transfers.
To stay competitive, Web3 businesses need more than just a database. They need a high-performance analytics platform for real-time applications like risk monitoring, transaction tracing, on-chain analytics, and cross-chain fund flow tracking.
But traditional databases like PostgreSQL can't keep up with real-time workloads at scale. They're too slow for real-time fraud alerts, too expensive at scale, and too rigid for the constant schema changes Web3 demands. Web3 builders need a database that can keep up with the blockchain without breaking the bank. And that could be VeloDB, a real-time analytics and search database powered by Apache Doris. See why:
Why VeloDB Works for Real-Time Blockchain Analysis
- High-Throughput Data Ingestion: Chains like Solana process tens of millions of transactions per day. Through features like Stream Load, Vertical Compaction, and merge-on-write, VeloDB delivers high-performance data ingestion. For example, with modest hardware like 16 cores and 128GB on the VeloDB Cloud service, VeloDB can ingest 150,000 records per second (100MB/s).
- Fast Queries: With inverted indexes, partitioning, bucketing, and vectorized execution, VeloDB lets you instantly pull up any wallet's transaction history or trace fund flows across multiple chains.
- Cuts storage costs in half: VeloDB separates compute from storage, keeping hot data fast while archiving history to cheaper object storage, helping users to cut storage costs by more than 50%. Ideal to handle the storage costs of ingesting hundreds of terabytes of data from multiple public blockchains.
- Dedicated Web3 features: Provides Decimal256 data type, supporting ultra-high-precision decimals (no rounding errors on token calculations), built-in functions for candlestick chart generation (open/close prices via
max_by/min_by), and materialized views that auto-refresh every minute for dashboard metrics. - Data consistency: Through a Unique Key model and UPSERT, VeloDB ensures no data duplication in the dataset. Using two-phase commit (2PC) with Flink checkpoints, users will never lose transactions or double-count them, even during crashes. VeloDB also uses a SEQUENCE column to handle out-of-order data.
A Typical Web3 Data Analytics Architecture
Before diving into VeloDB's solutions, let's look at a standard architecture for a Web3 data analytics platform:
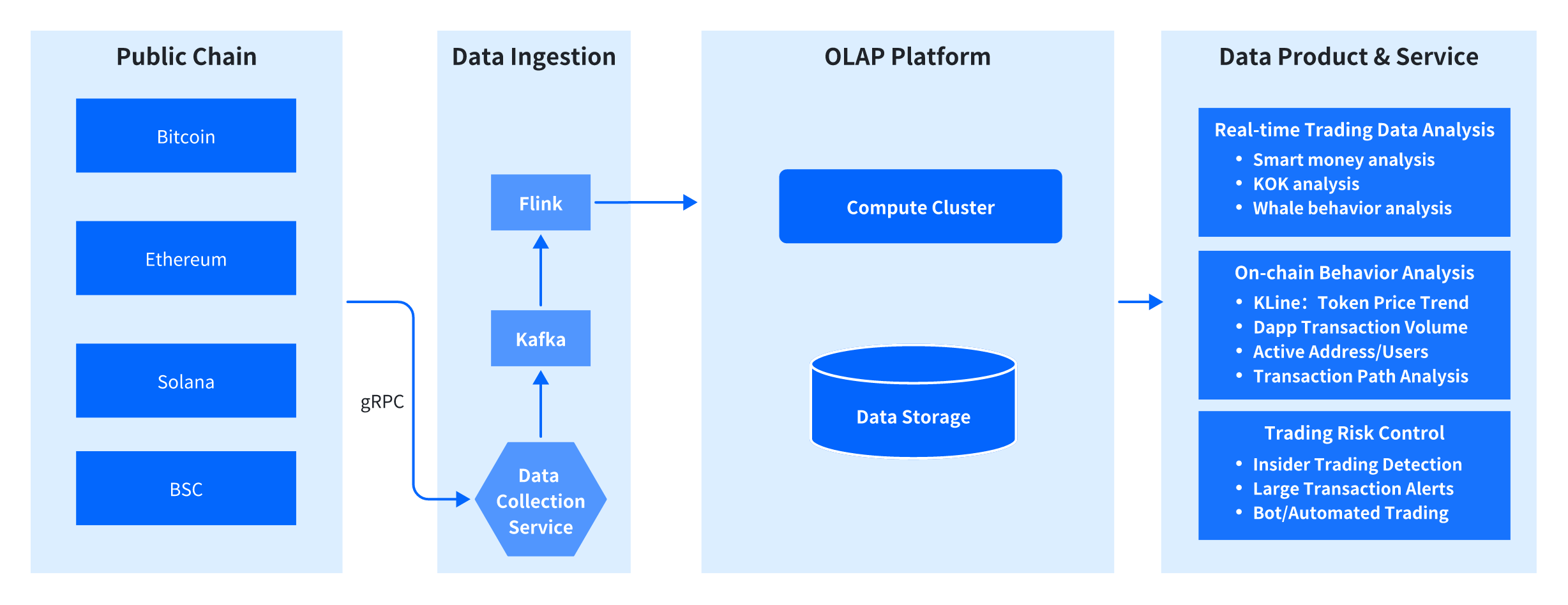
- Data Ingestion: A service, often written in Rust or another high-performance language, fetches data from the public chain via gRPC. The data is then standardized into JSON or Protobuf format and written into a message queue like Kafka.
- Data Loading: A stream processing engine like Flink consumes data from Kafka and performs real-time loading into an OLAP analytics platform.
- Data Storage and Analytics: The OLAP platform stores and analyzes on-chain data, primarily supporting queries on detailed transaction records and generating analytical reports. To manage costs, a Time-to-Live (TTL) policy is often used to automatically purge historical data, while massive historical datasets are archived in object storage.
- Data-Driven Products and Services: This architecture powers various data products, including:
- Real-Time Transaction Analysis: Identifying "smart money" movements, tracking Key Opinion Leader (KOL) wallets, and monitoring whale behavior.
- Trading Behavior Analysis: Generating K-Line (candlestick) charts for token price trends, analyzing DApp transaction volumes, and tracking active user metrics.
- Transaction Risk Control: Detecting front-running (sandwich attacks), monitoring for anomalous large transactions, and identifying MEV bot activity.
Overcoming Web3 Data Challenges with VeloDB
Web3 data looks open on the surface, but it’s brutally hard to work with at scale. Public blockchains generate hundreds of millions of transactions and event logs every day. Teams are expected to store this data long term, query it flexibly, and still deliver near–real-time insights for use cases like risk monitoring and fund tracing. The data is transparent, but turning it into a fast, reliable analytical system is anything but simple.
Here, we'll explore the common data challenges for Web3 builders and VeloDB's solution.
1. High-Throughput, Low-Latency Data Ingestion
The Challenge
Public chains can generate tens of thousands of transactions and hundreds of thousands of event logs per second during peak periods. The Solana network, for example, can produce around 5,000 transactions per second, amounting to over 400 million transactions daily. Ingesting this massive volume of data in real-time is a significant hurdle for traditional databases and big data platforms.
VeloDB's Solution
VeloDB is architected for this exact scenario. It uses Stream Load for high-efficiency ingestion, leveraging vectorized parsing and a columnar storage format to achieve superior throughput. In our benchmark tests, a modest 16-core, 128GB VeloDB Cloud instance can support ingestion rates of 100 MB/s or 150,000 rows per second.
| Cluster Configuration | 16-Core 128GB |
|---|---|
| Ingestion Method | Kafka -> Flink -> VeloDB Cloud |
| Checkpoint Interval | 1s |
| Ingestion Performance | 150,000 rows/s |
Furthermore, on-chain data analysis demands that data be queryable within seconds of being written. VeloDB's Vertical Compaction mechanism enables efficient real-time data compression and indexing, ensuring data is visible and ready for analysis almost instantly after ingestion.
2. Ensuring Data Integrity and Consistency
The Challenge
Data pipelines can be fragile. Network issues, service restarts, or exceptions in parsing logic can lead to duplicate or out-of-order data, compromising the integrity of analytics.
VeloDB's Solutions
VeloDB offers a multi-layered approach to guarantee data consistency.
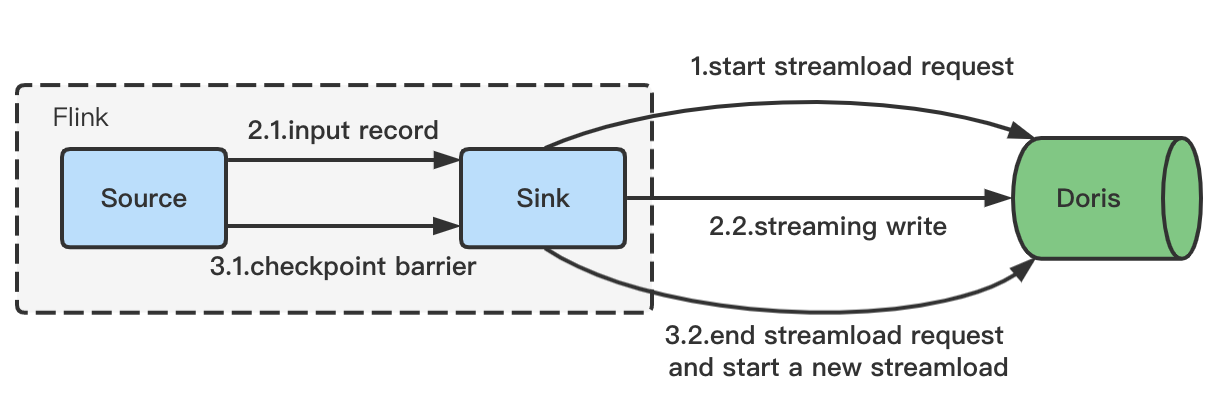
A. Exactly-Once Semantics with 2PC
By integrating with Flink's checkpointing mechanism, VeloDB uses a Two-Phase Commit (2PC) protocol to achieve exactly-once write guarantees from end to end. Data is continuously streamed via HTTP Chunked transfer, and writes are committed in coordination with Flink's checkpoint, ensuring that data is never lost or duplicated during ingestion.
B. Global Deduplication with the UNIQUE KEY Model
In cases where upstream services might send duplicate data, VeloDB's UNIQUE KEY table model provides built-in UPSERT functionality. This allows you to define a unique key (e.g., transaction hash and date). If a new record arrives with a key that already exists, VeloDB will automatically update the existing record rather than insert a duplicate, ensuring global data uniqueness.
CREATE TABLE `solana_events` (
`tx_hash` varchar(256) NOT NULL,
`date` date NOT NULL,
`fee_payer` varchar(128) NULL,
`main_event_type` varchar(64) NULL,
`block_time` bigint NULL,
`block_number` bigint NULL,
`event_type` array<varchar(64)> NULL,
`status` boolean NULL,
`seq` int NULL,
`fee` int NULL,
`priority_fee` varchar(16384) NULL,
`total_fee_u` varchar(16384) NULL,
`signers` array<varchar(128)> NULL,
`contracts` array<varchar(128)> NULL,
`called_methods` array<varchar(64)> NULL,
`parameters` varchar(65533) NULL,
`tx_type` varchar(64) NULL,
`extra` varchar(65533) NULL,
`nonce` int NULL,
`gas_limit` bigint NULL,
`gas_price` bigint NULL,
`gas_consumed` bigint NULL,
INDEX idx_sol_block_number (`block_number`) USING INVERTED,
INDEX idx_sol_main_event_type (`main_event_type`) USING INVERTED,
INDEX idx_sol_fee (`fee`) USING INVERTED,
INDEX idx_sol_fee_payer (`fee_payer`) USING INVERTED
) ENGINE=OLAP
UNIQUE KEY(`tx_hash`, `date`)
PARTITION BY RANGE(`date`)()
DISTRIBUTED BY HASH(`tx_hash`) BUCKETS 32
PROPERTIES (
"enable_unique_key_merge_on_write" = "true",
"dynamic_partition.enable" = "true",
"dynamic_partition.time_unit" = "DAY",
"dynamic_partition.start" = "-265",
"dynamic_partition.end" = "10",
"dynamic_partition.prefix" = "p"
);
C. Handling Out-of-Order Data with a Sequence Column
Network latency can cause events to arrive out of order. For use cases that require only the latest state (e.g., the most recent transaction for a specific token), VeloDB allows you to designate a sequence column (such as block_number). VeloDB will automatically use this column to resolve conflicts and discard stale or out-of-order records.
ALTER TABLE solana_events ENABLE FEATURE "SEQUENCE_LOAD"
WITH PROPERTIES (
"function_column.sequence_col" = "block_number",
"function_column.sequence_type" = "BIGINT"
);
3. High-Performance Ad-Hoc and Detailed Queries
The Challenge
Web3 analytics requires querying detailed data with high performance, but this can be difficult to achieve when data is also being ingested at a high rate. Additionally, users need the flexibility to query data across many different dimensions.
VeloDB's Solutions
A. Merge-on-Write for Stable Query Performance
In many databases, frequent data ingestion and merging can degrade query performance. VeloDB's UNIQUE KEY model offers a Merge-on-Write option that completes data merging during the write stage, ensuring that queries always run on fully compacted, optimized data, delivering stable, predictable performance.
"enable_unique_key_merge_on_write" = "true"
B. Prefix Keys and Partitioning for Fast Lookups
By defining a primary key with a common query field like account_address as the prefix, combined with date-based partitioning, VeloDB can rapidly locate and retrieve records for a specific address within a given time range.
UNIQUE KEY(`tx_hash`, `date`)
C. Inverted Indexes for Flexible Multi-Dimensional Queries
While prefix keys are great for known access patterns, users often need to filter on other fields, like block_number or event_type. For these scenarios, VeloDB provides inverted indexes, adding an inverted index to a column enables efficient, high-concurrency lookups on that dimension without sacrificing performance on primary key queries.
INDEX idx_sol_block_number (`block_number`) USING INVERTED
4. Real-Time Metrics and High-Concurrency Dashboards
The Challenge
Many Web3 dashboards require pre-aggregated metrics (like K-Line data or token holder statistics) and must support thousands of queries per second (QPS) from user-facing applications.
VeloDB's Solutions
A. Asynchronous Materialized Views for Pre-Aggregation
VeloDB's asynchronous materialized views can automatically pre-aggregate raw data into summary tables. For example, a materialized view can be scheduled to run every minute to transform raw trade data into K-Line data (open, high, low, close prices) at various time granularities (1-minute, 5-minute, 1-hour, 4-hour, etc).
CREATE MATERIALIZED VIEW mv_sol_trades_hour
BUILD DEFERRED
REFRESH COMPLETE
ON SCHEDULE EVERY 1 MINUTE
PARTITION BY (block_time_minute)
DISTRIBUTED BY HASH(`token_address`) BUCKETS 2
AS
SELECT
token_address,
side_token_address,
date_trunc(block_timestamp, 'hour') as block_time_minute,
min(token_price_in_usd),
max(token_price_in_usd),
-- Calculate open price
min_by(token_price_in_native, block_timestamp),
-- Calculate close price
max_by(token_price_in_native, block_timestamp)
FROM sol_trades
GROUP BY date_trunc(block_timestamp, 'hour'), token_address, side_token_address;
B. High-QPS Point Queries with Row-Column Hybrid Storage
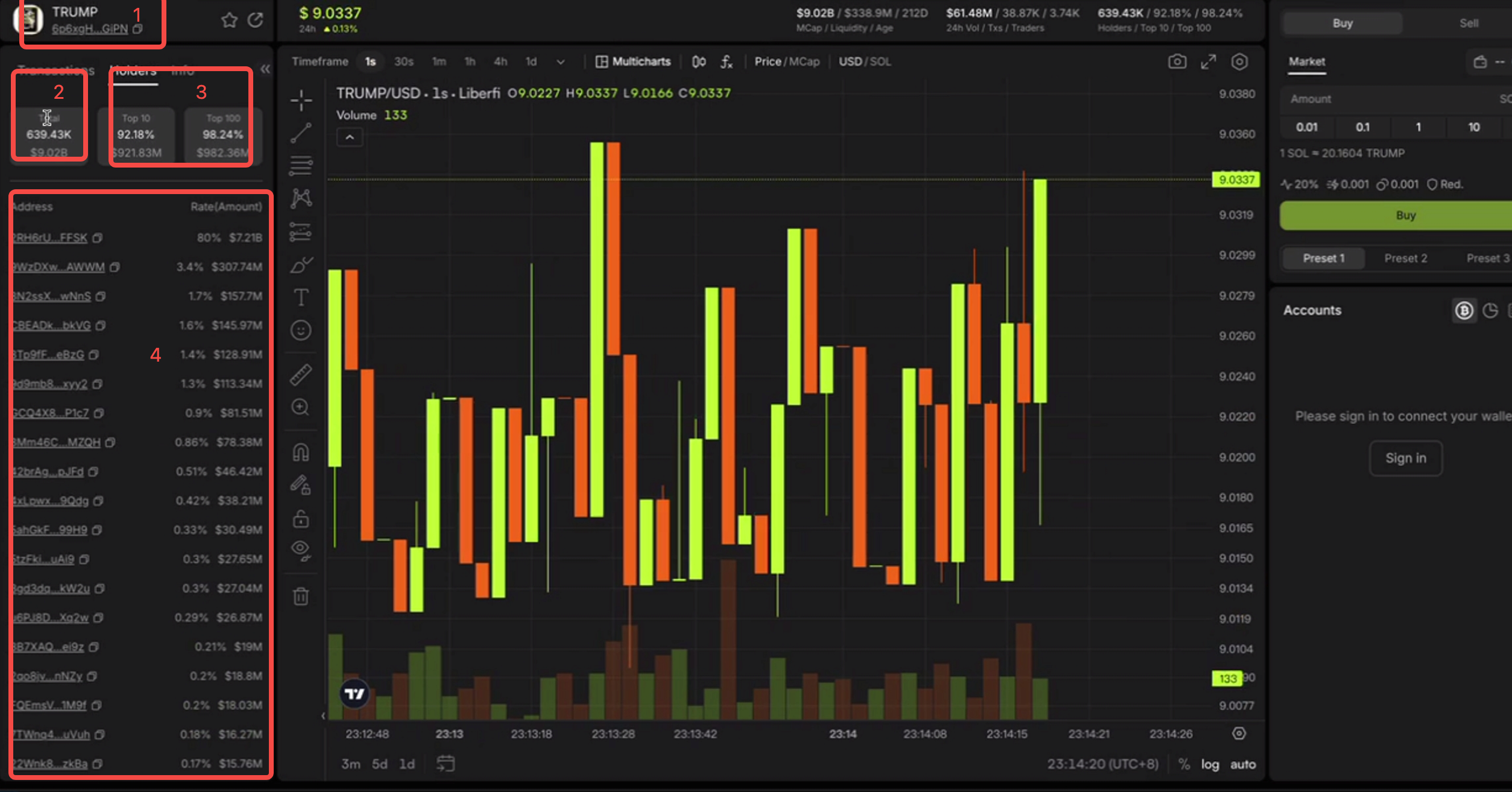
For extreme QPS requirements, such as displaying token holder statistics on a popular analytics site, you can run a periodic ETL job to calculate metrics and store them in a VeloDB table optimized for fast lookups. By enabling the store_row_column property, VeloDB caches data in both row and column formats, delivering over 100,000 QPS for key-value lookups.
This dashboard below shows key holder metrics, such as the total number of holders and the percentage of supply held by the top 10 and top 100 holders, which helps identify potential whale concentration or front-running risks.
CREATE TABLE `sol_trades_metrics` (
`token_address` VARCHAR(128) NULL,
`top_10_holdings` DECIMAL(27, 9) NULL,
`top_100_holdings` DECIMAL(27, 9) NULL,
...
) ENGINE=OLAP
UNIQUE KEY(`token_address`)
DISTRIBUTED BY HASH(`token_address`) BUCKETS 5
PROPERTIES (
"replication_allocation" = "tag.location.default: 1",
"enable_unique_key_merge_on_write" = "true",
"light_schema_change" = "true",
"store_row_column" = "true" -- Enable hybrid storage for high QPS
);
5. Specialized Data Types and Functions for Web3
The Challenge
Web3 calculations demand extreme precision. A standard float or double is insufficient for handling tokenomics, where a single token can be divisible to 18 decimal places. Financial calculations like interest rates and exchange rates also require exact precision to avoid rounding errors.
VeloDB's Solutions
A. High-Precision DecimalV3 and Decimal256
VeloDB provides robust support for high-precision decimal types, including DecimalV3 (up to 38 digits) and an optional Decimal256 (up to 76 digits), ensuring that all financial and token-related calculations are performed without any loss of precision.
| Type Name | Storage (bytes) | Description |
|---|---|---|
DECIMAL | 4/8/16/32 | An exact fixed-point number defined by precision (total number of digits) and scale (number of digits to the right of the decimal point). Format: DECIMAL(P[,S]). The range for P is [1, 38] by default, and can be extended to 76 by enabling enable_decimal256=true. Setting this to true ensures higher accuracy at the cost of some performance. Storage requirements vary based on precision: 4 bytes (P< =9), 8 bytes (P< =18), 16 bytes (P< =38), 32 bytes (P< =76). |
B. Rich Analytical Functions
VeloDB includes a rich library of functions designed specifically for financial and time-series analysis. For example, when calculating K-Line data, you can use:
MIN()andMAX()to find the lowest and highest prices.MIN_BY(price, timestamp)to find the open price (the price associated with the earliest timestamp in the period).MAX_BY(price, timestamp)to find the close price (the price associated with the latest timestamp in the period).
-- An example of calculating K-Line data
SELECT
date_trunc(block_timestamp, 'second') as block_time_minute,
token_address,
min(token_price_in_usd), -- Low price
max(token_price_in_usd), -- High price
min_by(token_price_in_usd, block_timestamp), -- Open price
max_by(token_price_in_usd, block_timestamp) -- Close price
FROM sol_trades
GROUP BY date_trunc(block_timestamp, 'second'), token_address, side_token_address
ORDER BY date_trunc(block_timestamp, 'second'), token_address, side_token_address;
6. Save on Storage Costs
The Challenge
Storing terabytes of on-chain data, especially across multiple blockchains, on high-performance SSDs can be quite expensive.
VeloDB's Solution
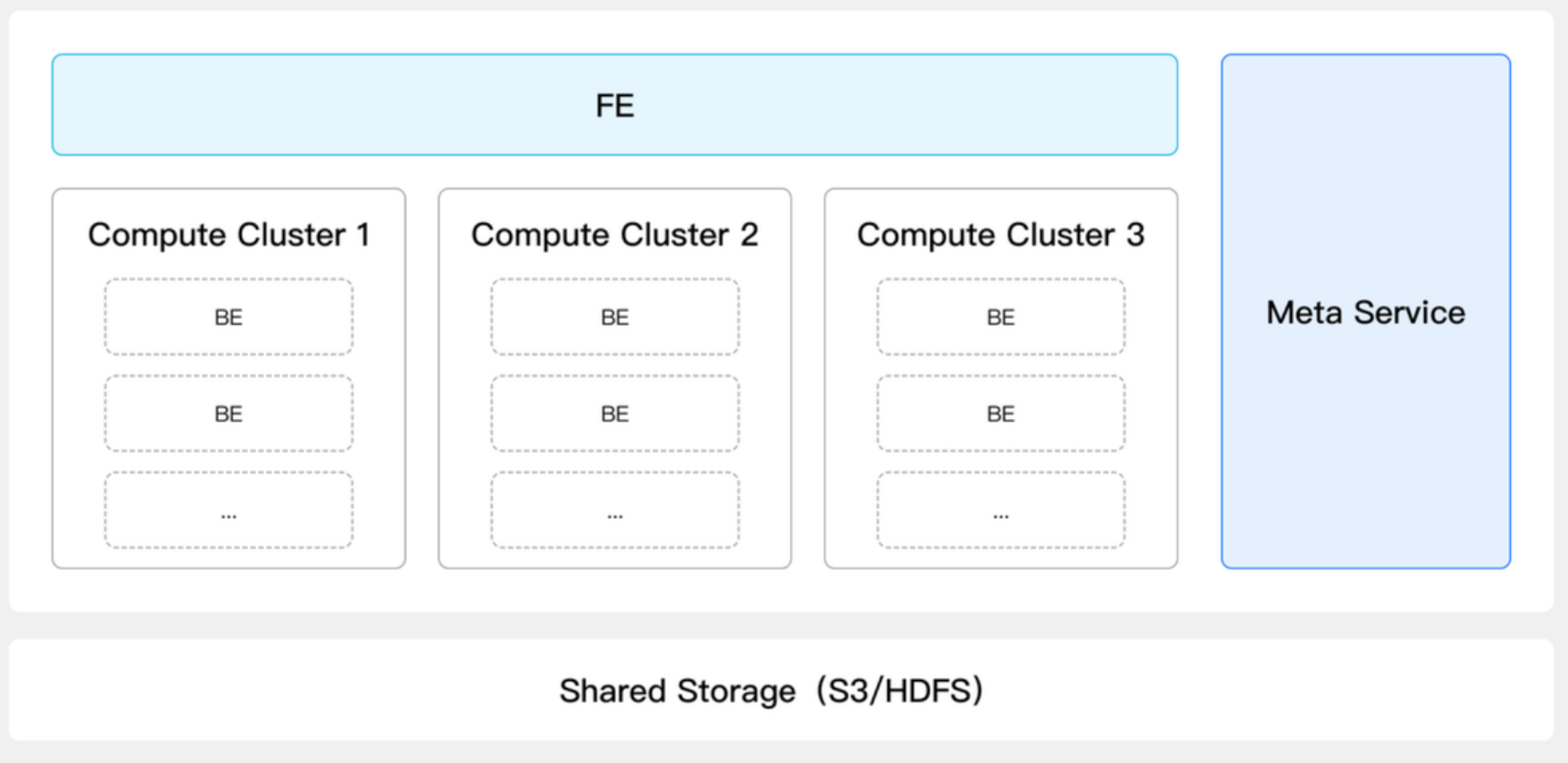
VeloDB features a storage-compute separation architecture, allowing you to store cold or historical data on low-cost object storage (like AWS S3, Google GCS, or MinIO) while keeping hot data on local SSDs for fast access. This hybrid storage model can reduce storage costs by over 50% without sacrificing query performance for recent data.
Conclusion
The Web3 data landscape is defined by massive scale, real-time demands, and complex analytical needs. Building a responsive, reliable, and cost-effective on-chain analytics platform requires a real-time database that's designed from the ground up to handle these challenges.
VeloDB provides a comprehensive and battle-tested solution, offering:
- High-throughput ingestion to keep up with any blockchain.
- Guaranteed data consistency for reliable analytics.
- Flexible and powerful querying capabilities for deep exploration.
- High-concurrency performance to power user-facing applications.
- Significant cost savings through its storage-compute separation architecture.
By leveraging VeloDB, Web3 developers and data companies can stop troubleshooting data infrastructure and focus on what truly matters: building innovative products that deliver valuable insights from on-chain data. Contact the VeloDB team to learn more about Web3 use cases.


