- Products
- Solutions
Real-Time Analytics
Sub-second dashboards and data products on petabytes of data at any concurrency
Data Warehousing
Sub-second analytics on open lakehouse formats with no vendor lock-in
Observability in the AI Era
The most cost-effective alternative to Elasticsearch observability
Context Engineering
Hybrid search and fresh context for RAG, agents, and LLMs
- Docs
- Resources
- Pricing
- Contact us



Build a real-time, performant and cost-effective knowledge store with Apache Doris 4.0
Combine Vector Search, Full-Text Search, SQL, and fast ingestion for a real-time knowledge store on structured and unstructured data
Submit your product and service requirements,
our team will respond within 1 business day.
Apache Doris 4.0 Is Live on VeloDB!
Apache Doris 4.0 brings capabilities that enable organizations to build a knowledge store with real-time data. Learn more about the release here.
Hear from our users and partners on how Apache Doris 4.0 accelerates efforts to build a knowledge store and the real-time benefits they are realizing.
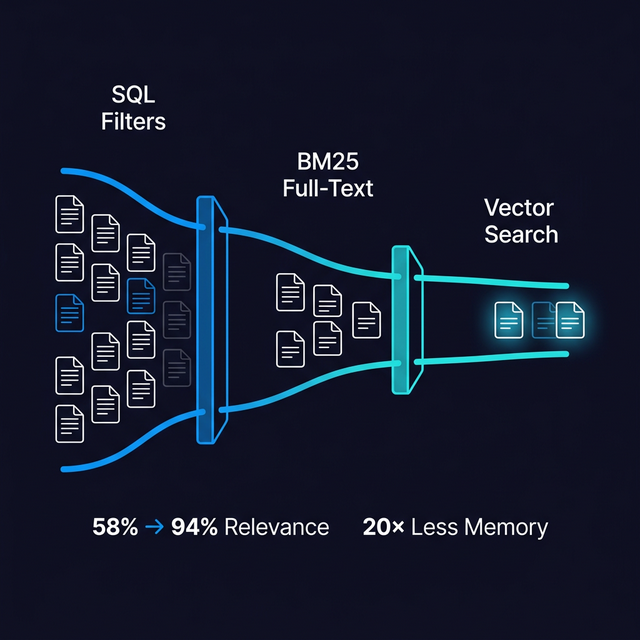
Vector search alone is not enough
Users and agents require precise deterministic answers, which is difficult to rely on similarity search alone. By combining SQL filtering, full-text search, and vector search, users will get exact matches, semantically relevant context, and precision from one retrieval system.
Similarity and vector search is expensive. Many RAG systems built on pure vector searches require high memory and a high-dimensional index to get the necessary accuracy. Hybrid search can reduce the cost massively by reducing the required vector search with cheaper methods first.
Learn about ByteDance improving accuracy and lowering cost with hybrid search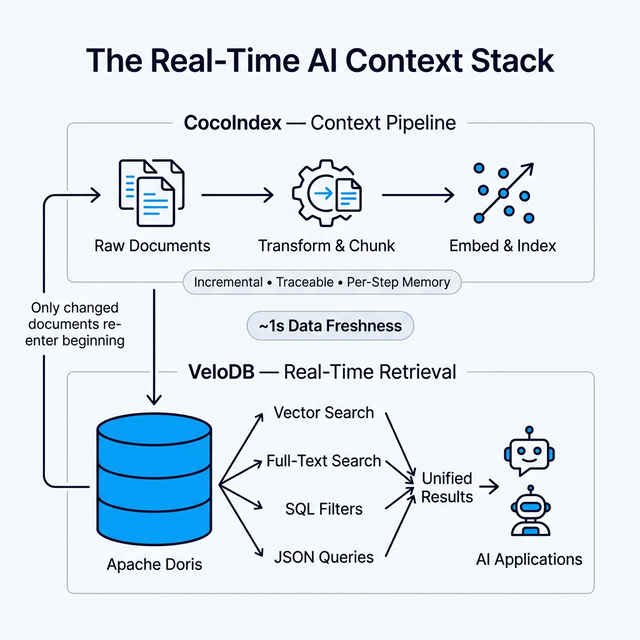
Real-time context is needed for real-time insights and action
Delivering real-time context is hard. Incremental indexing at scale, managing document versioning to prevent duplicate retrieval, and ensuring consistency across hybrid search indexes is costly and fragile.
VeloDB and CocoIndex form a two-layer context stack — CocoIndex owns the transformation pipeline with per-step memory, while VeloDB stores, indexes, and serves queries in real time. Changed documents sync in seconds, not days.
Learn more about the real-time AI context stack