


TL;DR: The RAG Architecture Quick Guide
- What it is: RAG (Retrieval-Augmented Generation) is an AI framework that retrieves facts from an external database and injects them into an LLM's prompt before generating a response.
- The Problem it Solves: It helps reduce hallucinations by grounding responses in external data and bypasses knowledge cutoffs by grounding answers in your private, real-time enterprise data.
- The Architecture: It relies on a coordinated workflow: Data Ingestion → Chunking & Embedding → Storage (Vector/Hybrid Database) → User Query → Context Retrieval → LLM Response.
- Scalable & Agentic RAG: Modern systems use real-time analytical databases (like VeloDB) for hybrid search, enabling advanced AI Agents to reason and retrieve context across massive datasets in milliseconds. A typical RAG system connects data pipelines, retrieval systems, and LLMs into a unified workflow for real-time knowledge access.
What Is RAG Architecture?
RAG architecture (Retrieval-Augmented Generation) is a system design pattern for building AI applications where large language models (LLMs) are combined with external data sources at query time.
Instead of relying only on pre-trained knowledge, a RAG system retrieves relevant information from external data (such as documents, logs, or databases) and injects it into the model’s prompt before generating a response.
This fundamentally changes how LLMs operate.
In a traditional setup, an LLM answers based only on what it learned during training. In a RAG architecture, the model can dynamically access up-to-date and context-specific information, making its outputs more accurate and grounded.
This approach addresses several key limitations of standalone LLMs:
- Knowledge cutoffs — models are trained on static datasets and may lack recent information
- Lack of proprietary data — models cannot access internal or domain-specific knowledge
- Hallucinations — models may generate plausible but incorrect answers without grounding
RAG architecture solves these issues by combining three core steps into a single workflow:
- retrieval — finding relevant information from external data sources
- augmentation — injecting that information into the prompt
- generation — producing a response based on both the query and retrieved context
In practice, RAG is not just a technique but a foundational architecture for modern AI systems.
RAG architecture enables LLMs to use external knowledge at query time, transforming them from static models into dynamic, data-aware systems.
Why RAG Architecture Matters
Modern AI applications require accurate, real-time, and context-aware responses.
Traditional LLM-only systems struggle because:
- knowledge becomes outdated
- domain-specific information is missing
- responses are not grounded in real data
RAG solves this by dynamically injecting relevant data into the model.
As a result:
- answers become more accurate
- outputs reflect current information
- systems can use private or internal datasets
RAG has become the default architecture for building production AI systems that require accurate and up-to-date information.
Core Components of RAG Architecture
A RAG system is not just a combination of retrieval and generation—it is a coordinated system where multiple components work together to turn raw data into usable context for AI models.
In production environments, the effectiveness of a RAG system depends less on any single component and more on how these components interact.
Retrieval Component
The retrieval layer is responsible for finding relevant information from external data sources.
It typically includes:
- embedding generation (converting text into vector representations)
- vector similarity search (finding semantically similar content)
- metadata filtering (e.g., time range, source, user context)
This layer determines what information the model sees.
In practice, retrieval is often more complex than simple similarity search. Real-world queries frequently require combining semantic relevance with structured constraints. As a result, modern systems rely on databases that can support both vector search and efficient filtering.
Generation Component
The generation layer uses an LLM to produce the final response.
It involves:
- constructing prompts
- injecting retrieved context
- generating outputs based on both the query and context
This layer determines how the information is used.
Even the most advanced models cannot compensate for poor retrieval. If the retrieved context is irrelevant, incomplete, or outdated, the final output will reflect those issues.
Analytics & Query Layer (Critical but Often Overlooked)
Many discussions of RAG simplify the architecture as “vector search + LLM.” In practice, this is not sufficient for production systems.
Real-world RAG applications often require:
- filtering by time, user, or metadata
- aggregating or ranking results
- querying logs or structured datasets
- combining semantic similarity with structured conditions
This is where an analytics and query layer becomes essential.
Instead of treating vector search and structured queries as separate systems, modern RAG architectures increasingly rely on unified analytical layers that can handle both.
In many production systems, this layer is implemented using real-time analytical databases such as VeloDB, which enable hybrid queries across vector data and structured metadata with low latency.
This allows RAG systems to retrieve not just similar content, but the most relevant content under real-world constraints.
A useful way to understand the relationship between these components is:
- the retrieval layer selects the candidate context
- the analytics layer refines and filters that context
- the generation layer turns it into a response
If any part of this chain is weak, the overall system quality degrades.
In practice, the retrieval and analytics layers often have a greater impact on system performance than the model itself.
How RAG Architecture Works (Step-by-Step)
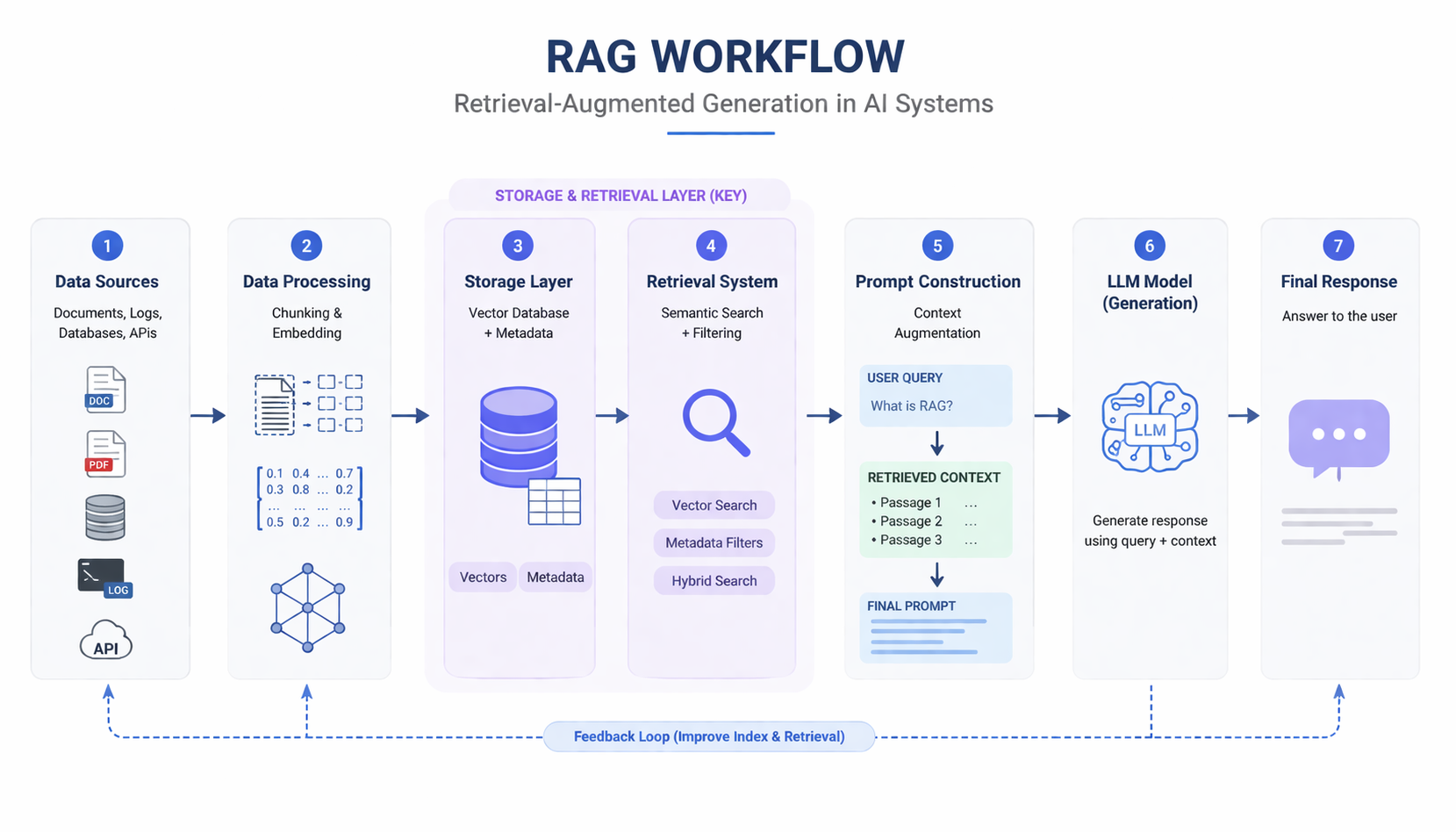
RAG architecture follows a structured workflow, but in modern systems it operates as a continuous process rather than a one-time pipeline.
The goal of this workflow is simple: retrieve the right context before generation so that the model can produce accurate and grounded responses.
1. Ingestion
The process begins with data ingestion.
Data is collected from multiple sources, such as:
- documents and knowledge bases
- application logs and events
- APIs and external systems
- databases
This step ensures that the system has access to all relevant information. In production environments, ingestion is often continuous so that the system stays up to date.
2. Chunking
Raw data is rarely suitable for direct retrieval.
It is split into smaller, manageable segments (chunks), such as paragraphs or logical sections of text.
Proper chunking is critical:
- chunks that are too large reduce retrieval precision
- chunks that are too small lose context
This step directly affects how relevant the retrieved results will be.
3. Embedding
Each chunk is converted into a vector representation using an embedding model.
This allows the system to perform semantic search, meaning it can retrieve content based on meaning rather than exact keyword matches.
Embedding is what enables RAG systems to understand user intent beyond simple text matching.
4. Storage
The processed data is stored in a retrieval system.
This typically includes:
- vector representations (for similarity search)
- metadata (e.g., time, source, user context)
A well-designed storage layer allows the system to support both semantic retrieval and structured filtering, which becomes critical in real-world use cases.
5. Retrieval
When a user submits a query, the system retrieves the most relevant chunks.
This step may involve:
- vector similarity search (semantic matching)
- metadata filtering (e.g., time range, category)
- ranking or re-ranking results
Retrieval determines what information the model sees, making it one of the most important steps in the pipeline.
6. Augmentation
The retrieved content is then injected into the prompt.
Instead of answering based only on its internal knowledge, the model now has access to:
- relevant documents
- contextual data
- up-to-date information
This step bridges the gap between retrieval and generation.
7. Generation
Finally, the LLM generates a response using both:
- the original query
- the retrieved context
The result is a response that is:
- more accurate
- more context-aware
- less likely to hallucinate
In practice, most failures in RAG systems do not come from the model itself, but from earlier steps in the pipeline—especially retrieval quality and data preparation.
This is why optimizing the workflow often leads to larger improvements than simply upgrading the model.
Basic RAG vs. Scalable RAG Architecture
| Aspect | Basic RAG Architecture | Scalable RAG Architecture |
|---|---|---|
| Retrieval approach | Vector similarity search only | Hybrid search (vector + structured filtering) |
| Data handling | Static or batch data | Real-time + continuously updated data |
| Query complexity | Simple semantic queries | Complex queries (semantic + metadata + conditions) |
| Performance at scale | Degrades with large datasets | Designed for high-volume and high concurrency |
| System architecture | Multiple disconnected components | Unified analytics and retrieval layer |
| Latency | Can increase significantly under load | Optimized for low-latency queries |
| Use cases | Prototypes, small datasets | Production AI systems, RAG at scale |
| Example capability | “Find similar documents” | “Find recent error logs related to crashes in the last 24 hours” |
Not all RAG systems are created equal.
While basic RAG architectures work well for prototypes or small datasets, they often break down in real-world production environments where data volume, query complexity, and latency requirements increase significantly.
What Is Scalable RAG Architecture?
A scalable RAG architecture extends beyond simple vector similarity search.
It is designed to handle:
- massive and continuously growing datasets
- real-time data ingestion and updates
- high-concurrency user queries
- complex queries combining semantic and structured conditions
In practice, scalable RAG systems are built to operate under real-world constraints, where both accuracy and performance must be maintained at scale.
Limitations of Basic RAG
Early RAG implementations often rely primarily on vector databases.
While effective for simple semantic retrieval, this approach introduces several limitations:
- limited support for structured filtering (e.g., time, user, category)
- degraded performance under complex queries
- difficulty handling real-time or streaming data
- fragmented architectures when multiple systems are combined
For example, consider a query like:
“Find logs about system crashes in the last 24 hours”
This requires both:
- semantic understanding (“system crashes”)
- structured filtering (“last 24 hours”)
Pure vector-based systems often struggle to efficiently handle both at the same time, leading to slow or inaccurate results.
The Role of the Analytics Layer in Scalable RAG
To address these challenges, modern RAG architectures introduce an analytics and query layer.
Instead of separating vector search and structured queries into different systems, scalable architectures unify them into a single layer.
Systems like VeloDB enable this by supporting hybrid search:
- vector similarity search for semantic relevance
- structured filtering using SQL
- real-time data ingestion and querying
This unified approach:
- reduces architectural complexity
- improves query performance
- enables sub-second retrieval even under complex conditions
As a result, the system can retrieve not just similar content—but the most relevant content under real-world constraints.
How to Build a RAG Architecture
Building a RAG architecture is not just about connecting a vector database to an LLM. In practice, it means designing a system that can reliably retrieve the right context, deliver it with low latency, and keep improving over time.
A typical process includes the following steps:
1. Start with the data
Every RAG system begins with data.
This may include:
- internal documents
- product manuals
- knowledge bases
- logs and support tickets
- databases or API-fed content
At this stage, the goal is to identify what knowledge the model needs access to and how often that data changes. Static documentation and fast-changing operational data place very different demands on the architecture.
2. Prepare the data for retrieval
Raw data is rarely usable as-is.
Before retrieval, it usually needs to be:
- cleaned and normalized
- split into chunks
- enriched with metadata
- converted into embeddings
This step is critical because retrieval quality depends heavily on how the data is prepared. Poor chunking or missing metadata often leads to irrelevant context, even if the retrieval engine itself is fast.
3. Choose the retrieval and analytics layer
This is one of the most important decisions in the entire architecture.
A basic RAG setup may work with a simple vector database, but production systems usually need more than vector similarity alone. Real-world queries often require:
- semantic search
- metadata filtering
- time-based constraints
- real-time updates
- fast querying under concurrency
That is why many modern RAG systems rely on a retrieval layer that also functions as an analytics layer.
Systems such as VeloDB are especially useful here because they support:
- vector similarity search
- structured SQL filtering
- real-time ingestion
- low-latency analytical queries
This allows teams to simplify architecture and avoid stitching together separate systems for vectors, metadata, and operational data.
4. Build the prompt pipeline
Once retrieval is in place, the next step is constructing the prompt pipeline.
This includes:
- passing the user query into the retriever
- selecting the most relevant context
- injecting that context into the prompt
- controlling how much information is sent to the LLM
The goal is not to retrieve the most data, but the most useful data. A well-designed prompt pipeline improves grounding while avoiding prompt overload.
5. Add generation logic and response handling
The LLM then generates a response based on:
- the original user query
- the retrieved context
- system instructions or prompt templates
In many systems, this stage also includes post-processing such as:
- formatting
- citation handling
- answer filtering
- fallback logic when retrieval confidence is low
This is where the retrieved knowledge becomes a usable output.
6. Add evaluation and monitoring
A RAG system is not complete once it produces answers. It must also be evaluated in production.
Key signals to monitor include:
- retrieval relevance
- answer quality
- latency
- hallucination rate
- query and cost efficiency
Without evaluation, teams often struggle to understand whether problems come from the retriever, the prompt design, or the model itself.
7. Optimize for scale and real-world usage
As usage grows, a RAG architecture must handle:
- larger datasets
- more concurrent users
- more complex filtering
- more frequent data updates
This is where many early RAG systems break down. Architectures that look simple in prototypes become difficult to scale when retrieval, analytics, and monitoring are spread across too many systems.
In practice, scalable RAG systems work best when retrieval and analytics are tightly integrated rather than treated as separate problems.
Building a RAG architecture is less about choosing a single model and more about designing the retrieval, analytics, and feedback layers around real-world constraints.
Choosing a system that supports hybrid queries and real-time analytics—such as VeloDB—can significantly simplify the architecture and improve production performance.
Common Challenges in RAG Architecture
Despite its advantages, building a reliable RAG architecture is not straightforward in practice.
The challenge is not just retrieving data—but retrieving the right data, at the right time, under real-world constraints.
Retrieval Quality
Retrieval quality is the most common—and most critical—issue.
If the system retrieves irrelevant, incomplete, or outdated context, the model will produce poor outputs regardless of its capabilities.
In many cases, improving retrieval quality has a larger impact than upgrading the model itself.
Latency and Performance
RAG systems introduce additional steps before generation, especially during retrieval.
If retrieval is slow, the entire user experience suffers.
This becomes more challenging when:
- datasets grow large
- queries become more complex
- real-time filtering is required
Balancing retrieval accuracy with low latency is one of the core trade-offs in RAG system design.
Context Window Limitations
LLMs can only process a limited amount of context.
Even if the system retrieves large amounts of relevant data, only a subset can be passed into the prompt.
This creates a new challenge:
- selecting the most useful context
- avoiding redundant or noisy information
Effective ranking and filtering become essential at this stage.
Hallucinations and Incomplete Grounding
RAG reduces hallucinations, but it does not eliminate them.
If retrieval fails—or returns weak signals—the model may still generate incorrect or unsupported answers.
This is especially common when:
- the query is ambiguous
- relevant data is missing
- retrieved context is partially relevant
System Complexity
As RAG systems evolve, they often involve multiple components:
- ingestion pipelines
- embedding models
- vector databases
- analytics layers
- monitoring systems
Without careful design, this can lead to:
- fragmented architectures
- data inconsistencies
- operational overhead
In practice, most RAG challenges are not caused by the model itself, but by the layers around it—especially retrieval and data handling.
Best Practices for RAG Architecture
Effective RAG systems are not defined by how many components they include, but by how well those components work together.
The goal is to maximize retrieval quality while maintaining performance and simplicity.
Focus on Retrieval First
In most cases, improving retrieval quality leads to the biggest gains.
This includes:
- better chunking strategies
- higher-quality embeddings
- more accurate filtering
A strong retrieval layer often matters more than using a larger or more advanced model.
Optimize Data Preparation
Data preparation directly affects how well the system retrieves context.
Best practices include:
- splitting data into meaningful chunks
- adding structured metadata (time, source, category)
- maintaining clean and consistent data formats
Well-prepared data makes retrieval more precise and predictable.
Use Hybrid Search (Vector + Structured Filtering)
Pure vector search is often insufficient for real-world use cases.
Combining:
- semantic similarity (vector search)
- structured conditions (SQL filtering)
allows the system to retrieve results that are both relevant and contextually correct.
Design for Real-Time and Scalability
Many RAG systems start as prototypes but fail to scale.
To avoid this, design for:
- real-time data ingestion
- low-latency queries
- high concurrency
Architectures that unify retrieval and analytics—such as those built on systems like VeloDB—can simplify scaling and improve performance.
Monitor Outputs, Not Just Metrics
Traditional monitoring focuses on system metrics such as latency and throughput.
RAG systems must also monitor:
- answer relevance
- correctness
- hallucination rates
This helps identify whether issues come from retrieval, prompt design, or the model itself.
Agentic RAG Architecture: The Next Evolution
Traditional RAG follows a linear workflow:
Query → Retrieve → Generate
Agentic RAG extends this by introducing AI agents that can dynamically control retrieval.
Instead of a single step, the system can:
- decide when to retrieve data
- select different data sources
- perform multi-step retrieval and refinement
In practice, this turns RAG into an iterative process:
retrieve → analyze → refine → generate
This approach is especially useful for complex queries and multi-step reasoning tasks.
Agentic RAG enables AI systems to move beyond simple question answering and handle:
- multi-hop queries
- decision-making workflows
- interactions across multiple data sources
Because retrieval happens multiple times, agentic RAG requires:
- low-latency query performance
- flexible filtering and retrieval
- real-time data access
This makes the underlying data and analytics layer critical.
Systems such as VeloDB support these requirements by enabling hybrid queries (vector + structured filtering) with low latency, making them well-suited for agentic RAG systems.
FAQ
What is RAG architecture in LLMs?
RAG architecture in LLMs is a system design where a language model retrieves external data before generating a response.
Instead of relying only on pre-trained knowledge, the model:
- retrieves relevant information from databases or documents
- injects that context into the prompt
- generates answers based on both the query and retrieved data
This allows LLMs to produce responses that are more accurate, up-to-date, and grounded in real data.
A simple way to understand it is:
- the LLM handles reasoning
- the retrieval system provides knowledge
What is agentic RAG architecture?
Agentic RAG architecture is an advanced RAG approach where AI systems can dynamically decide when and how to retrieve information, enabling multi-step reasoning and iterative refinement.
- Traditional RAG: retrieve once, then generate
- Agentic RAG: retrieve, reason, and refine in a loop
What is scalable RAG architecture?
Scalable RAG architecture refers to systems that can handle large datasets, real-time updates, and complex queries without performance degradation.
It typically includes hybrid search (vector + structured filtering) and is designed for low-latency, high-concurrency environments.
How does RAG architecture work?
RAG works by retrieving relevant context before generation.
The system:
- retrieves relevant data
- adds it to the prompt
- generates a response using an LLM
This process helps ensure that outputs are grounded in external knowledge rather than relying only on model memory.
What is RAG architecture in AI?
RAG architecture is a design pattern in AI systems that combines retrieval and generation.
It enables models to access external data sources at query time, improving accuracy, relevance, and freshness of responses.
Conclusion
RAG architecture has become a foundational pattern for building modern AI systems.
By combining retrieval and generation, it allows LLMs to produce more accurate, up-to-date, and context-aware responses.
In practice, the effectiveness of a RAG system depends not just on the model, but on the underlying architecture—especially the retrieval and analytics layers.
As AI systems evolve, three trends are becoming clear:
- RAG is becoming the default architecture
- analytics layers are critical for performance and accuracy
- real-time, agentic systems are the next step
Designing RAG systems with these principles in mind is key to building scalable and reliable AI applications.