


Apache Parquet has become the de facto standard for storing analytical data in modern data lakes and data warehouses. If you're working with big data analytics, you've likely encountered Parquet files—but do you truly understand what makes this format so powerful?
In this comprehensive guide, we'll explore the Parquet format from the ground up, covering its architecture, benefits, use cases, and best practices. Whether you're a data engineer designing a new data pipeline or an analyst wondering why your queries are faster with Parquet, this article will provide the insights you need.
What Is the Parquet File Format?
Apache Parquet is an open-source columnar storage format designed specifically for efficient analytical querying of large-scale datasets. Unlike traditional row-based storage formats like CSV or JSON, Parquet organizes data by columns rather than rows, which fundamentally changes how data is stored, compressed, and queried.
Parquet was created to address the performance bottlenecks that traditional formats face when dealing with big data analytics. As data volumes grow exponentially, row-based storage becomes increasingly inefficient for analytical workloads that typically need to scan specific columns across millions or billions of rows.
The format is widely adopted across the big data ecosystem, with native support in Apache Spark, Apache Hive, Apache Doris, Trino, Presto, and many other analytical engines. Its columnar design enables powerful optimizations like column pruning (reading only needed columns) and predicate pushdown (filtering data before reading), resulting in dramatically faster queries and reduced storage costs.
From a practical standpoint, Parquet files are self-describing—they contain both the data and the schema information, making them portable across different systems and programming languages. This schema-on-read capability, combined with support for complex nested data types, makes Parquet ideal for modern data lake architectures where data structures may evolve over time.
How Parquet Works and Why It Is Fast
Parquet's performance comes from three core innovations: columnar storage, efficient file structure, and intelligent encoding. Let's explore how these work together.
Columnar storage vs row-based storage
Parquet organizes data by columns rather than rows, fundamentally changing how data is stored and queried. Consider a user behavior log table:
| user_id | age | gender | country | event_type | timestamp |
|---|---|---|---|---|---|
| 1001 | 25 | M | US | click | 2024-01-01 10:00:00 |
| 1002 | 32 | F | DE | purchase | 2024-01-01 10:01:12 |
| 1003 | 28 | M | US | click | 2024-01-01 10:02:05 |
Row-based storage (CSV/JSON) stores data sequentially: 1001,25,M,US,click,2024-01-01 10:00:00. To query just event_type and timestamp, you must read entire rows, wasting I/O.
Columnar storage (Parquet) stores each column separately: user_id: [1001, 1002, 1003], event_type: [click, purchase, click], etc. This enables:
- Column pruning: Only read needed columns, reducing I/O by 80-95% for wide tables
- Better compression: Similar data types together achieve higher compression ratios
- Vectorized execution: Batch operations on entire columns
- Page-level compression using Snappy, Gzip, or ZSTD
- Quick skipping of irrelevant columns using min/max statistics, dictionary filtering, and bloom filters
In practice, switching from CSV to Parquet typically reduces query times by 5-10x and storage costs by 60-80%.
Parquet file structure (row groups, column chunks, pages)
Parquet files use a hierarchical structure for efficient storage and parallel processing:
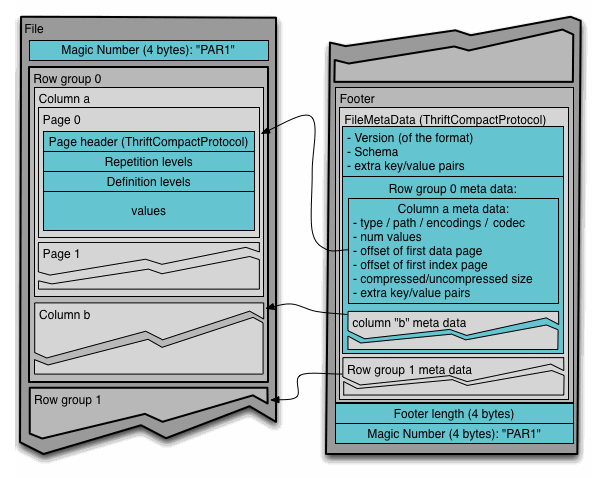 Structure hierarchy:
Structure hierarchy:
- File Footer: Contains metadata for all Row Groups, schema, and compression info
- Row Group: Basic data unit (128MB-1GB uncompressed), can be read in parallel
- Column Chunk: Column-stored blocks within a Row Group, contains min/max statistics
- Page: Smallest storage unit (8KB-1MB), includes Data Pages and Dictionary Pages This design enables query engines to skip entire Row Groups using statistics, read only needed Column Chunks, and decode Pages in parallel. For production, configure Row Group sizes between 256MB-512MB for optimal balance.
Encoding and compression techniques
Parquet uses multiple encoding and compression layers to minimize storage while maintaining performance, achieving 5-10x better compression than uncompressed formats. Encoding techniques:
- Dictionary Encoding: Maps repeated values (like country codes) to integers
- Run-Length Encoding (RLE): Stores value once with count for repeated sequences
- Delta Encoding: Stores differences between consecutive values for sorted numeric columns
- Bit Packing: Uses only needed bits for small integers
Compression algorithms (page-level):
- ZSTD: Best overall balance (recommended for most workloads)
- Snappy: Fastest decompression (good for real-time queries)
- Gzip: Highest compression (acceptable for batch processing)
- LZ4: Very fast, lower compression
- Brotli: High compression, slower
Together, encoding and compression reduce Parquet file sizes by 70-90% compared to uncompressed CSV, with minimal performance impact.
Column pruning and predicate pushdown
These optimizations minimize data reading and processing:
Column Pruning: When querying SELECT event_type, timestamp FROM logs, Parquet reads only those column chunks, skipping others. This reduces I/O by 80-95% for wide tables.
Predicate Pushdown: Parquet stores min/max statistics per column chunk. Query engines use these to skip entire row groups that can't match. For WHERE timestamp > '2024-02-01', if a row group's max timestamp is '2024-01-31', it's skipped entirely.
Together, these optimizations mean Parquet queries often read 10-100x less data than row-based formats.
Schema evolution support
Parquet handles schema changes without breaking existing data:
- Add new fields to existing tables without invalidating old data
- Reorder fields without data migration
- Type compatibility for certain changes (INT → LONG) based on reader tolerance
- Schema-on-read capability for data lake scenarios
This is crucial for real-world pipelines where schemas evolve. Teams can add new optional fields as needed without costly migrations.
Support for complex and nested types
Parquet natively supports nested structures, ideal for semi-structured data:
- List, Map, Struct and other nested types
- JSON-like hierarchical data efficiently encoded
- Store complex nested JSON directly without flattening, while benefiting from columnar optimizations
This makes Parquet perfect for modeling semi-structured data like logs, events, and telemetry.
What's Next for Parquet
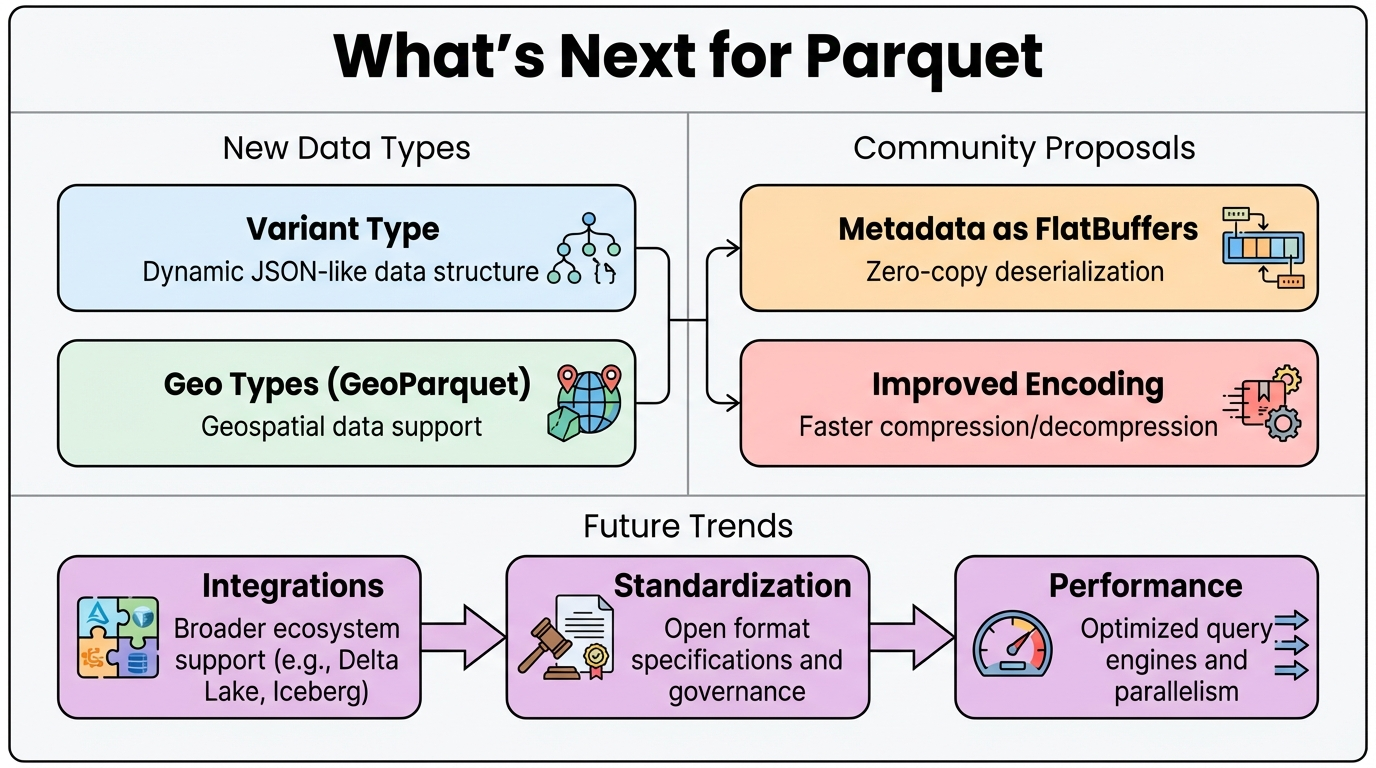 The Parquet community continues to evolve the format, introducing new data types and exploring architectural improvements to meet emerging data processing needs.
The Parquet community continues to evolve the format, introducing new data types and exploring architectural improvements to meet emerging data processing needs.
New Data Types
Variant Type Variant provides native support for structurally unknown or dynamic data, similar to JSON's arbitrary structure. It eliminates the need to predefine schemas, making it ideal for logs, telemetry, IoT, and NoSQL data. Variant enables more efficient reading of semi-structured data compared to storing JSON blobs directly, and works seamlessly with table formats like Apache Iceberg for schema projection and pruning.
Geo Types (GeoParquet) GeoParquet extends Parquet for geospatial data, encoding geographic information (WKT/WKB/GeoJSON) while preserving spatial reference systems, coordinates, and metadata. The v1.0 specification is supported by GDAL, DuckDB, Apache Spark, BigQuery Geo, and other tools, with spatial indexing capabilities planned for future releases.
Community Proposals and Future Enhancements
Metadata as FlatBuffers: The Parquet community is exploring replacing the current Thrift-based metadata format with FlatBuffers. This change would improve metadata parsing performance, reduce memory footprint, and enable more efficient schema evolution. FlatBuffers provides zero-copy deserialization, which could significantly speed up file footer reading and metadata operations.
Other Active Discussions:
- Enhanced compression algorithms and encoding techniques
- Improved support for streaming and incremental writes
- Better integration with modern table formats and catalogs
- Performance optimizations for cloud storage backends
These ongoing developments ensure Parquet remains at the forefront of analytical data storage, adapting to new use cases while maintaining backward compatibility.
When Should You Use Parquet?
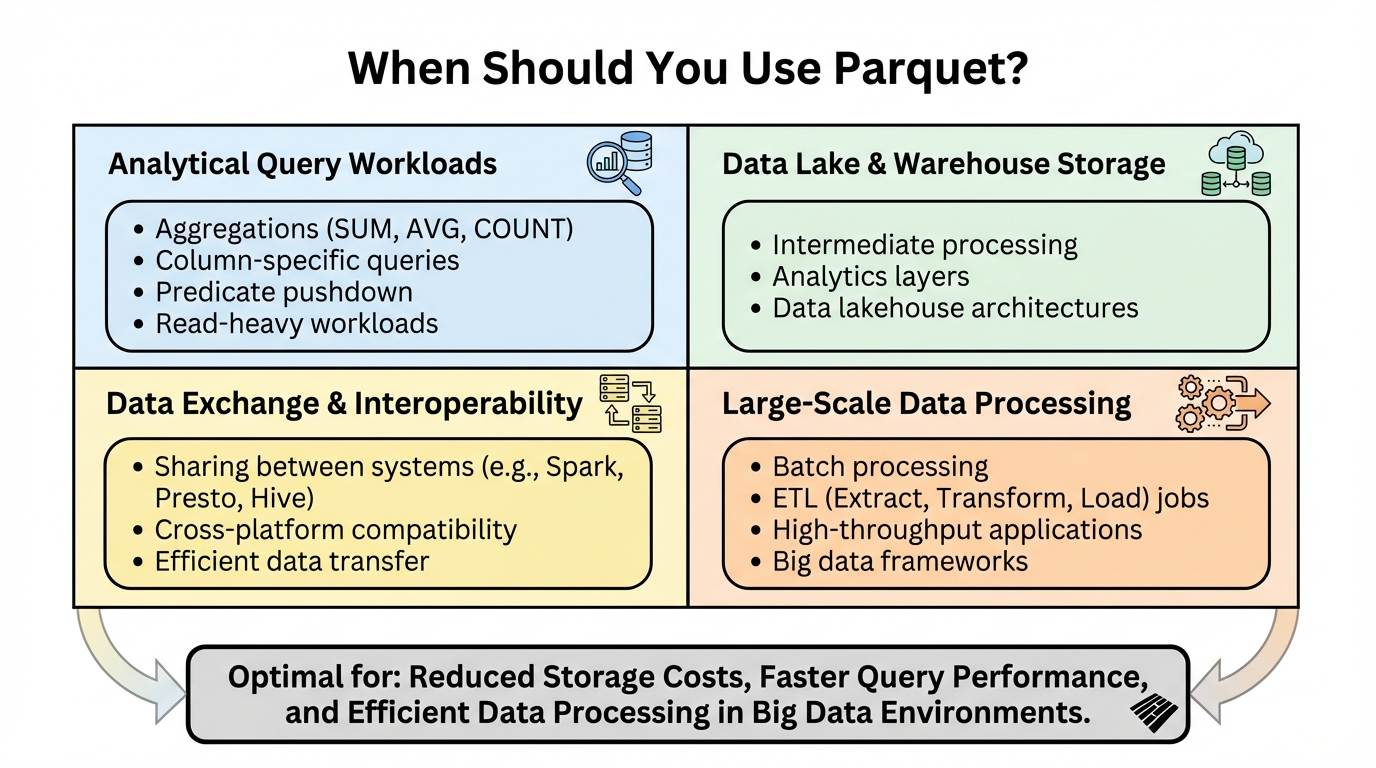 Parquet excels in specific scenarios. Understanding when to use it helps you make informed architectural decisions.
Parquet excels in specific scenarios. Understanding when to use it helps you make informed architectural decisions.
Analytical Query Workloads
Parquet is ideal when your primary use case involves:
- Aggregations and analytics: SUM, COUNT, AVG operations across large datasets
- Column-specific queries: Queries that access only a subset of columns
- Filtering and scanning: WHERE clauses that can leverage predicate pushdown
- Read-heavy workloads: Scenarios where data is written once and read many times
Data Lake and Data Warehouse Storage
Parquet is the preferred format for:
- Intermediate processing layers: After data cleansing, when structure becomes stable
- Analytics layers: Pre-aggregated or modeled data for BI and reporting
- Data lakehouse architectures: Combined with table formats like Apache Iceberg or Delta Lake
- Cloud storage optimization: Reducing storage costs in S3, Azure Blob, or GCS
Large-Scale Data Processing
Use Parquet when:
- Data volumes are large: Typically datasets in the hundreds of GB to petabytes range
- Query performance matters: Need fast analytical queries on big data
- Storage costs are a concern: Want to minimize cloud storage expenses
- Multiple systems need access: Data consumed by Apache Spark, Presto, Trino, Apache Doris, and other engines
Schema Evolution Requirements
Parquet fits well when:
- Schemas change over time: Need to add fields without breaking existing data
- Schema-on-read scenarios: Different consumers may interpret schemas differently
- Data lake flexibility: Want to store data before fully defining the schema
In practice, I recommend Parquet for any analytical workload where you're processing more than a few GB of data and queries typically access only a subset of columns. The performance and cost benefits become increasingly significant as data volume grows.
When Parquet Is Not a Good Fit
While Parquet is powerful, it's not a silver bullet. Understanding its limitations helps you choose the right tool for each job.
Transactional/OLTP Workloads
Parquet is not suitable for:
- Frequent row updates: Parquet files are immutable—updating a single row requires rewriting the entire file
- Real-time transactional queries: Designed for analytical, not transactional workloads
- Point lookups by primary key: Row-based formats or specialized databases are better for this
- High-frequency writes: Each write creates new files, leading to small file problems
If you need ACID transactions and row-level updates, consider combining Parquet with table formats like Apache Iceberg or Delta Lake, which add transaction management on top of Parquet files.
Small Datasets
For small datasets (typically under a few GB):
- Overhead outweighs benefits: Parquet's metadata and structure overhead may not be justified
- CSV or JSON may be simpler: Easier to inspect and debug
- Compression benefits minimal: Small files don't benefit as much from compression
- Schema complexity unnecessary: Simple formats may be more appropriate
Streaming/Real-Time Ingestion
Parquet has challenges with:
- Continuous streaming writes: Each batch creates new files, leading to many small files
- Low-latency requirements: Writing Parquet requires buffering and compression, adding latency
- Frequent schema changes: While schema evolution is supported, frequent changes create complexity
For streaming scenarios, consider formats like Apache Avro for the ingestion layer, then convert to Parquet in batch processes for analytics.
Unstructured or Unknown Schema Data
While Parquet supports Variant types, it's still challenging for:
- Completely unknown schemas: Raw data landing zones may be better as JSON or Avro
- Highly variable structures: If every record has a different structure, Parquet's benefits diminish
- Text-heavy content: Parquet excels with structured data, not free-form text
Write-Heavy Workloads
Parquet is optimized for read performance, which means:
- Writing is slower: Requires encoding, compression, and metadata generation
- Append operations: Creating new files rather than appending to existing ones
- Small file problem: Frequent small writes create many small files, hurting query performance
For write-heavy scenarios, consider writing to a staging format first, then periodically converting to Parquet in batch operations.
When Simplicity Matters
Sometimes simpler is better:
- Human readability: CSV is easier for humans to inspect and edit
- Interoperability: JSON is more universally understood
- Debugging: Simpler formats are easier to troubleshoot
- One-off analysis: For ad-hoc analysis of small datasets, CSV may be sufficient
Practical Recommendation: In my experience, the "sweet spot" for Parquet is analytical workloads on datasets larger than 10-50GB where queries access a subset of columns. For smaller datasets, transactional workloads, or highly unstructured data, other formats may be more appropriate.
Parquet File Format vs Other Data Formats
Understanding how Parquet File Format compares to other formats helps you make informed choices in your data architecture.
Parquet vs ORC
Both are columnar formats with similar goals, but different ecosystems:
| Aspect | ORC | Parquet |
|---|---|---|
| Storage Model | Columnar | Columnar |
| Compression | Better compression in some Apache Hive scenarios | Good compression, widely optimized |
| ACID Support | More mature native ACID transaction support | Requires table formats (Iceberg, Delta) for ACID |
| Ecosystem | Strong in Apache Hive and Presto | Broader support (Apache Spark, Apache Doris, Trino, BigQuery, Snowflake, etc.) |
| Schema Evolution | Good | Better schema evolution capabilities |
| Development | Mature, stable | More active development and community |
| Use Cases | Primarily Apache Hive-based ecosystems, need native ACID support | Modern data lake architectures, multi-engine compatibility, schema evolution needs |
| Industry Adoption | Hive-centric environments | Standard format for data lakehouses |
For most new projects, Parquet is the safer choice due to its broader ecosystem support.
Parquet vs Avro
These formats serve different purposes:
| Aspect | Apache Avro | Parquet |
|---|---|---|
| Storage Model | Row-based | Columnar |
| Use Case | Streaming, serialization, message queues | Analytical queries, data warehousing |
| Schema Evolution | Backward/forward compatibility with schema registry | Schema evolution for analytical workloads |
| Data Access | Efficient point lookups and record-level access | Column pruning and predicate pushdown |
| Compression | Good for serialization | Better compression for analytical workloads |
| Query Performance | Optimized for record access | 10–100x faster for analytical queries |
| Best For | Streaming ingestion, message queues (Kafka), record-level processing, RPC | Analytical queries, OLAP workloads, data warehousing |
| Common Pattern | Used for ingestion layer | Used for storage and analytics layer |
A common pattern is using Apache Avro for ingestion (streaming, Kafka) and Parquet for storage (data lake, analytics), converting between formats in ETL pipelines.
Parquet vs Lance
Lance is an open lakehouse format specifically designed for multimodal AI workloads. While Parquet excels at traditional SQL analytics, Lance targets AI/ML use cases with specialized features.
| Aspect | Lance | Parquet |
|---|---|---|
| Design Focus | AI/ML-first, multimodal data | Traditional SQL analytics |
| Random Access | 100x faster for point lookups and sampling | Optimized for sequential scans |
| Vector Search | Native vector similarity search with accelerated indices | Not natively supported |
| Search Capabilities | Hybrid: vector search, full-text (BM25), and SQL | SQL analytics only |
| Multimodal Data | Native support for images, videos, audio, text, embeddings | Limited, requires flattening |
| Data Evolution | Efficient column addition without full table rewrites | Schema evolution support |
| Versioning | Zero-copy ACID transactions and time travel | Requires table formats for ACID |
| Ecosystem | Growing, focused on AI/ML tools | Universal support (Spark, Hive, Doris, Trino, Presto, BigQuery, Snowflake, etc.) |
| Maturity | Emerging format, actively developed | Battle-tested for over a decade |
| Community | Growing AI/ML community | Large, established community with extensive documentation |
| Best For | AI/ML workflows, vector search, fast random access, multimodal data, ML feature engineering | Traditional SQL analytics, data warehousing, broad ecosystem compatibility |
Practical Consideration: Lance can convert from Parquet in just 2 lines of code, making it easy to migrate specific datasets for AI workloads while keeping Parquet for traditional analytics. Many organizations use both: Parquet for analytical queries and Lance for AI/ML pipelines.
Parquet vs Vortex
Vortex is a highly performant, extensible columnar data format that positions itself as a next-generation alternative to Parquet, offering significant performance improvements across multiple dimensions.
| Aspect | Vortex | Parquet |
|---|---|---|
| Random Access | 100x faster point lookups | Optimized for sequential access |
| Scan Performance | 10–20x faster sequential scans | Mature, highly optimized scans |
| Write Performance | 5x faster writes | Slower writes, optimized for reads |
| Compression | Similar compression ratio to Parquet | Excellent compression with multiple codecs |
| Architecture | Modern, extensible design | Mature, proven architecture |
| Ecosystem | Limited, still developing | Universal support across all big data tools |
| Maturity | Incubating at Linux Foundation, active development | Battle-tested for over a decade, production-proven |
| Tooling | Growing ecosystem | Extensive tools, libraries, and integrations |
| Community | Emerging community | Large, active community with extensive resources |
| Documentation | Developing | Comprehensive documentation and tutorials |
| Industry Adoption | Early adopter phase | Industry standard, widely adopted |
| Best For | New projects prioritizing performance, fast random access needs | Production systems requiring maximum compatibility, established pipelines |
Practical Consideration: Vortex is currently incubating at the Linux Foundation, indicating it's still in active development. While performance benchmarks are impressive, Parquet's maturity and ecosystem support make it the safer choice for most production deployments. However, Vortex represents an interesting evolution of columnar formats and may become more viable as its ecosystem matures.
Performance Trade-offs: While Vortex shows impressive performance improvements, it's important to evaluate these gains in the context of your specific workload. For pure analytical scans, Parquet's mature optimizations and broad support often outweigh raw performance differences. For workloads requiring frequent random access, Vortex's 100x improvement could be transformative.
Parquet in Modern Data Architectures
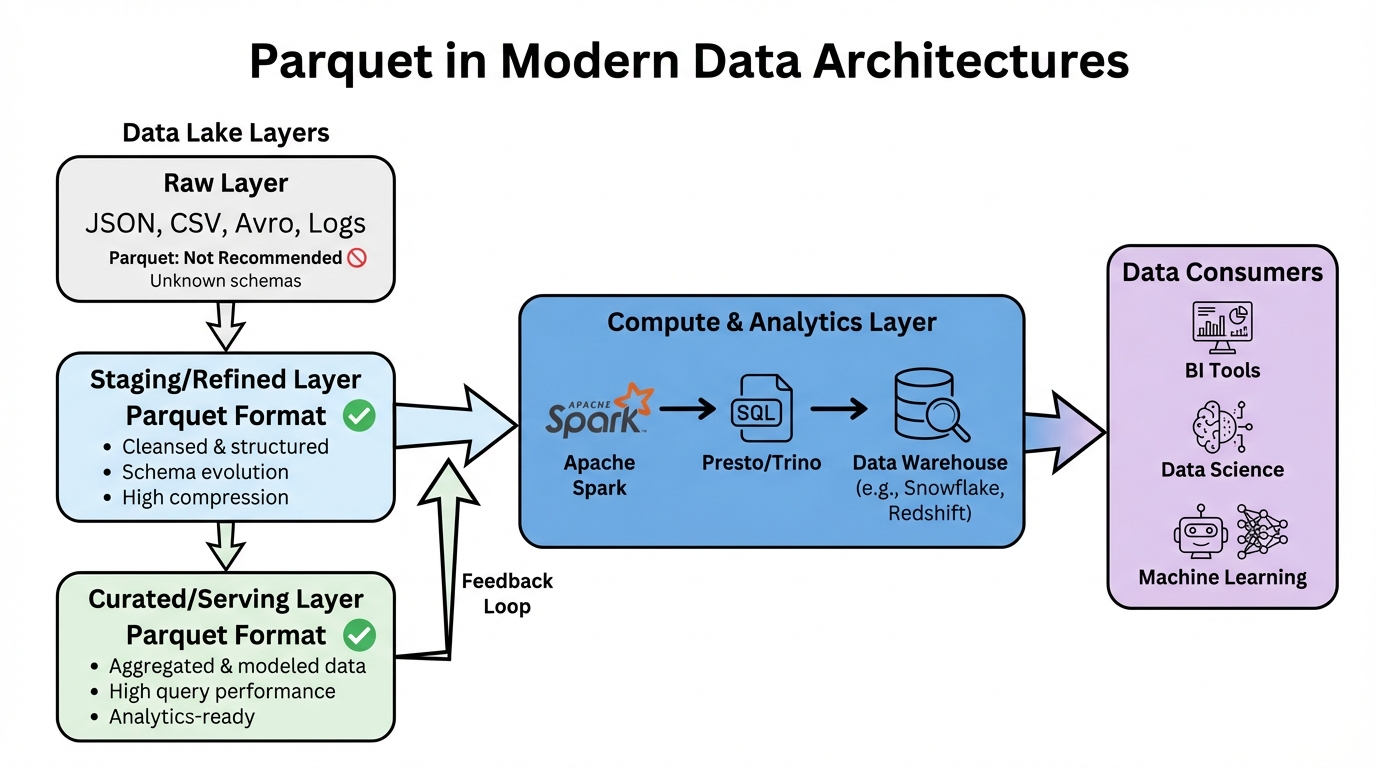 Parquet has become foundational to modern data architectures. Let's explore its role in different layers and patterns.
Parquet has become foundational to modern data architectures. Let's explore its role in different layers and patterns.
Data Lake Layers
In modern data lake architectures, data flows through multiple layers, each with different format requirements: Raw Layer:
- Data typically lands as JSON, CSV, Avro, or log formats
- Preserves original data snapshots for backtracking
- Parquet generally not recommended due to unstable or unknown schemas
- Direct use of Parquet is challenging when schemas are completely unknown
Staging/Refined Layer:
- After data cleansing and parsing, structure becomes relatively stable
- Commonly transforms semi-structured raw data into structured table formats
- Parquet is the preferred format for this layer because:
- Good integration with streaming/batch compute frameworks like Spark/Flink
- High compression ratio, saving storage
- Clear structure, supports schema evolution
- Suitable for subsequent dimensional modeling or downstream lake queries
Query/BI Layer:
- Oriented toward query services, reporting systems, AI/ML feature extraction
- Usually data that has been modeled (like star schema, wide tables)
- Parquet provides extremely fast query performance, especially combined with:
- Column pruning + predicate pushdown
- Metadata acceleration
- Incremental reading and snapshot access based on table formats (like Iceberg, Delta)
- Can be directly read/written by Apache Doris, Trino, Presto, ClickHouse, BigQuery, and other engines without import
Table Formats (Delta Lake and Apache Iceberg): Modern table formats like Delta Lake and Apache Iceberg use Parquet as their underlying storage format while adding critical capabilities:
- What Table Formats Add: ACID transactions, time travel, schema enforcement, metadata management, and small file compaction
- Parquet's Role: Provides actual data storage, enables columnar query performance, supports compression and encoding, and serves as the foundation for table format optimizations
In Apache Doris, you can create Apache Iceberg tables with Parquet format:
CREATE TABLE partition_table (
`ts` DATETIME COMMENT 'ts',
`col1` BOOLEAN COMMENT 'col1',
`col2` INT COMMENT 'col2',
`col3` BIGINT COMMENT 'col3',
`pt1` STRING COMMENT 'pt1',
`pt2` STRING COMMENT 'pt2'
)
PARTITION BY LIST (day(ts), pt1, pt2) ()
PROPERTIES (
'write-format'='parquet'
);
This combination provides Parquet's analytical performance with table format transaction capabilities.
Integration with Analytics Engines
Parquet's broad ecosystem support makes it the universal format for analytics:
- Apache Spark: Native Parquet support, optimized readers and writers
- Apache Doris: Direct querying of Parquet files, Apache Iceberg catalog support
- Trino/Presto: High-performance Parquet readers with predicate pushdown
- Apache Hive: Parquet as preferred format for analytical tables
- BigQuery, Snowflake: Native support for Parquet import and export
This universal compatibility means you can write Parquet files from one system and query them with another, enabling flexible, multi-engine architectures.
Best Practices When Working with Parquet
Based on real-world experience, here are practical recommendations for getting the most out of Parquet.
File Size and Row Group Configuration
Optimal File Sizes:
- Target 128MB to 1GB per Parquet file (uncompressed)
- Avoid files smaller than 64MB (too many small files hurt query performance)
- Avoid files larger than 2GB (slower to process, less parallelism) Row Group Sizes:
- Configure 256MB to 512MB per row group
- Larger row groups = better compression but less granular predicate pushdown
- Smaller row groups = more parallelism but more metadata overhead Practical Tip: When writing Parquet files, I typically use Spark's coalesce() or repartition() to control output file sizes, aiming for 256MB compressed files.
Compression Codec Selection
Choose based on your workload:
- ZSTD (level 5-6): Best overall balance for most analytical workloads
- Snappy: Fastest decompression, good for real-time queries
- Gzip: Highest compression, acceptable for batch processing
- LZ4: Very fast, use when compression ratio is less important
Recommendation: Start with ZSTD level 5 for production workloads. It provides excellent compression (often 10-15% better than Snappy) with decompression speeds that are still very fast.
Partitioning Strategy
Effective partitioning is crucial for performance:
- Partition by high-cardinality columns used in WHERE clauses (date, region, etc.)
- Avoid over-partitioning: Too many partitions create small file problems
- Use hierarchical partitioning: e.g.,
year=2024/month=01/day=15 - Align partitions with query patterns: Partition by what you filter on
Common Pattern: Partition by date (year/month/day) and a business dimension (region, product_category), keeping partition counts between 100 and 10,000 for optimal performance.
Schema Design
Best practices for Parquet schemas:
- Use appropriate data types: Don't use STRING for dates or numbers
- Leverage nested types: Use Struct/List/Map for related data instead of flattening
- Add field comments: Document column meanings for future users
- Plan for schema evolution: Make new fields optional when possible
Example: Instead of flattening nested JSON, preserve structure:
-- Good: Nested structure
metadata STRUCT<
browser: STRING,
screen: STRUCT<width: INT, height: INT>
>
-- Avoid: Overly flattened
metadata_browser STRING,
metadata_screen_width INT,
metadata_screen_height INT
Writing Parquet Files
Optimize write operations:
- Batch writes: Write multiple rows at once rather than row-by-row
- Control parallelism: Use appropriate number of partitions to avoid small files
- Set compression: Explicitly set compression codec rather than using default
- Include statistics: Ensure min/max statistics are generated for predicate pushdown
Reading Parquet Files
Optimize read operations:
- Specify columns explicitly: Use column pruning by selecting only needed columns
- Push predicates down: Use WHERE clauses that can leverage min/max statistics
- Use predicate pushdown: Filter early in the query plan
- Leverage partitioning: Query engines can skip entire partitions
Example in Apache Doris:
SELECT event_type, timestamp
FROM S3 (
'uri' = 's3://bucket/path/to/tvf_test/test.parquet',
'format' = 'parquet',
's3.endpoint' = 'https://s3.us-east-1.amazonaws.com',
's3.region' = 'us-east-1',
's3.access_key' = 'ak',
's3.secret_key'='sk'
)
WHERE timestamp > '2024-01-01'
Monitoring and Maintenance
Keep Parquet files healthy:
- Monitor file sizes: Alert on files that are too small or too large
- Compact small files: Periodically merge small files into larger ones
- Update statistics: Ensure min/max statistics are accurate after data updates
- Validate schemas: Check for schema drift in production pipelines
Common Issue: The "small file problem" occurs when streaming writes create many tiny Parquet files. Solution: Use batch compaction jobs to merge small files periodically.
Frequently Asked Questions About Parquet File Format
How does Parquet handle schema evolution?
Parquet supports schema evolution through its flexible schema system:
Adding Fields:
- New fields can be added to existing Parquet files
- Fields should be optional (nullable) for backward compatibility
- Old readers ignore new fields they don't recognize
- New readers can handle missing fields if they're optional
Field Reordering:
- Parquet supports reading columns in any order
- Physical storage order doesn't need to match logical schema order
- Query engines handle column mapping automatically
Type Changes:
- Some type changes are compatible (INT → LONG, FLOAT → DOUBLE)
- Incompatible changes (STRING → INT) require data migration
- Readers may have different tolerance levels for type compatibility
Best Practice: When evolving schemas, always add new fields as optional, and avoid removing or changing types of existing fields. For breaking changes, create new Parquet files with the updated schema.
Is Parquet secure by default?
Short answer: No. Parquet files are not encrypted by default, though Parquet does include built-in modular encryption mechanisms that can be enabled.
Parquet's Built-in Security Features:
- Modular encryption: Parquet supports column-level, page-level, and metadata encryption, but these features must be explicitly enabled
- Column-level encryption: Different columns can use different encryption keys, allowing partial encryption
- Compatible with all Parquet features: Encryption works with compression, encoding, and all query optimizations
Additional Security Options:
- Storage layer encryption: S3 server-side encryption, Azure Blob encryption
- Filesystem encryption: Encrypted filesystems at the OS level
- Query engine security: Access control, authentication, and authorization in systems like Apache Doris
- Network encryption: TLS/SSL for data in transit
For sensitive data:
- Enable Parquet modular encryption for native column-level encryption support
- Alternative: Storage layer encryption if your tools don't support Parquet modular encryption
- Implement access controls at the query engine and storage levels
- Consider data masking in query results for PII or sensitive information
Can Parquet files be updated?
Parquet files are immutable—you cannot update individual rows within an existing file. To "update" data:
- Rewrite the file: Read, modify, write new file (expensive for large files)
- Use table formats: Delta Lake or Apache Iceberg add update capabilities on top of Parquet
- Partition strategy: Store updates in new partitions, query engine merges results
- Append new files: Write new Parquet files with updated data, handle merges in queries
This immutability is by design—it enables the columnar optimizations that make Parquet fast. For update-heavy workloads, consider table formats like Apache Iceberg that add transaction management.
What compression should I use for Parquet?
Recommendations by use case:
- General analytics: ZSTD (level 5-6) - best balance of compression and speed
- Real-time queries: Snappy - fastest decompression
- Archive/long-term storage: Gzip - highest compression, acceptable read speed
- Write-heavy workloads: LZ4 - very fast compression
Default: If unsure, start with ZSTD level 5. It typically provides 10-15% better compression than Snappy with decompression speeds that are still very fast.
Final Thoughts
Apache Parquet has revolutionized how we store and query analytical data. Its columnar design, combined with intelligent encoding and compression, delivers performance improvements that are hard to achieve with traditional formats. As data volumes continue to grow, Parquet's benefits become increasingly significant.
The key to success with Parquet lies in understanding when to use it—analytical workloads on large datasets where queries access subsets of columns—and when other formats might be more appropriate. By following best practices around file sizing, compression, partitioning, and schema design, you can maximize Parquet's performance benefits.
Looking forward, Parquet continues to evolve with new features like Variant types for semi-structured data and GeoParquet for geospatial analytics. Combined with table formats like Apache Iceberg and Delta Lake, Parquet provides a solid foundation for modern data lakehouse architectures.
Whether you're building a new data pipeline or optimizing an existing one, Parquet should be a serious consideration for any analytical workload. The performance and cost benefits are simply too significant to ignore in today's data-driven world.
Ready to get started with Parquet? Explore how Apache Doris integrates with Parquet format for high-performance analytics, or dive into the official Parquet documentation to learn more about advanced features and optimizations.
