A revenue alert fires at 2 a.m. The on-call ops agent picks it up and receives a direct question from the engineer they report to: “Find incidents from the past two weeks related to GPU failures that caused over $1M in revenue loss, and include similar historical cases.”
Before the agent can reason about a fix, it has to answer that. Answering it is mostly an analytics job. The agent filters incidents to the last two weeks, matches fault-log text for GPU failures, aggregates revenue impact above $1M, and then ranks past incidents by semantic similarity. Four of those five steps are filtering, time-windowing, and aggregation. One is vector retrieval.
Most teams build the data layer for agents in the reverse order of how agents use it. They start with semantic retrieval: vector databases, RAG frameworks, workflow orchestration. That work is real, and production agents do need it. The layer that gets under-built is the one the agent hits first: real-time analytics over concrete business facts.
Those facts are specific and operational: orders, user records, transactions, inventory levels, alerts. A customer service agent needs the current order status, shipping updates, and refund eligibility. A business analytics agent needs live revenue, conversion rates, and anomaly signals. An ops agent needs to know which alerts are firing and what they affect. Each task is a more automated version of real-time analytics that a human operator already runs.
Agents also push harder on that layer than people do. They fire many queries per task, expect fresh data, and run in parallel across thousands of sessions. Real-time ingestion, low latency, high concurrency, and unified querying become baseline requirements. Those are the defining capabilities of real-time analytics systems like Apache Doris.
The shift to agentic workloads changes what the data layer has to deliver. Here is the comparison at the workload level:
| Dimension | Traditional Real-Time Analytics | Agentic Analytics |
|---|---|---|
| Primary Consumers | Analysts, operations, business teams | Agents, AI applications, automated workflows |
| Core Requirement | Surface business facts | Continuously retrieve facts and context throughout the reasoning chain |
| Dominant Query Types | SQL, aggregation, filtering, drill-down | SQL + Vector + Full-text + Graph + Stream |
| Latency Requirements | Minutes to seconds | Seconds to sub-second |
| System Role | Analytics and decision support | Fact entry point for understanding, reasoning, memory, and action |
Agent queries are analytics queries first
At the query level, the pattern is clearer. Take the incident question from the top:
Find incidents from the past two weeks related to GPU failures that caused over $1M in revenue loss, and include similar historical cases.
Break it down by the capability each fragment needs:
| Query fragment | Underlying capability required |
|---|---|
| GPU failure related | Full-text search, keyword matching |
| Past two weeks | Time filtering, window constraint |
| Revenue loss over $1M | Aggregation, metric filtering |
| Incidents | Structured data access |
| Similar historical cases | Vector retrieval, semantic similarity search |
In practice, the query the agent generates against the data layer looks like this:
SELECT *
FROM incidents
WHERE l2_distance(description_embedding, query_embedding) < 0.1
AND MATCH(log_text, 'GPU overheating')
AND severity >= 4
AND revenue_impact > 1000000
ORDER BY timestamp DESC
LIMIT 10;
The structured filters and the aggregation run first. Vector similarity is one of several predicates. Result quality depends on complex filtering and aggregation at high concurrency over fresh data, with semantic search built into the same engine.
Standalone vector retrieval covers part of this and leaves the rest to other systems:
| Agent key requirement | Where standalone vector retrieval falls short | Where a real-time analytics engine fits better |
|---|---|---|
| Complex filtering and aggregation | Relies on external analytics systems to fill the gap | Core capability of an analytics engine |
| Real-time business facts | Longer sync path, harder to guarantee freshness | Natively close to real-time data consumption |
| High-concurrency short queries | Better suited for retrieval, not optimized for complex analytics loads | Better suited to handle large volumes of analytics-style tool calls |
| Result interpretability | Often requires stitching in structured evidence separately | Returns verifiable business facts directly |
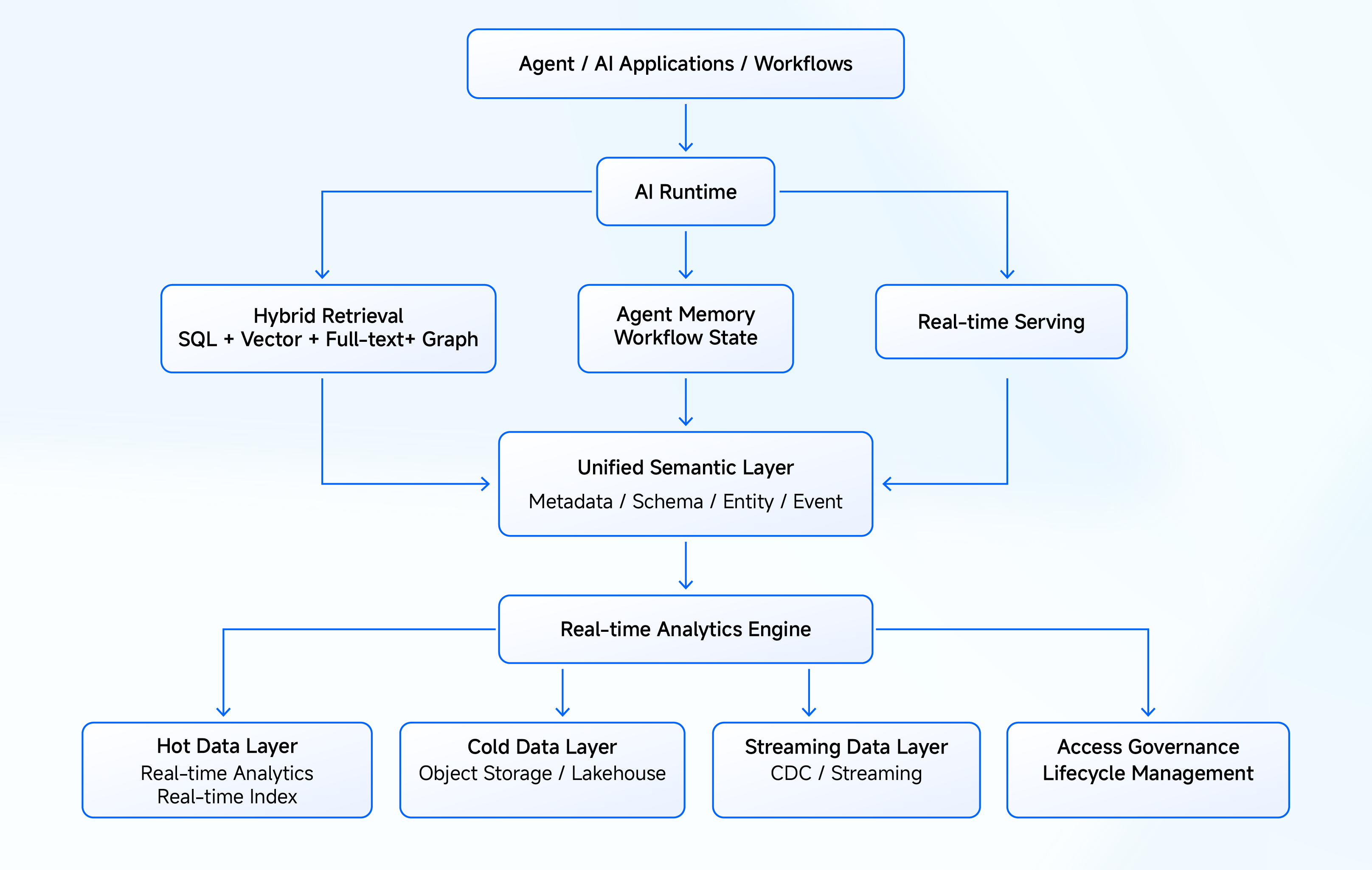
How Apache Doris bridges traditional and agentic analytics
We started building Apache Doris a decade ago as a real-time search and analytics database, built for high-concurrency, low-latency analytics at scale. We were not building for AI agents back then, but the same architectural choices we made for real-time analytics now match what agent workloads demand.
To serve agent workloads directly, Doris added hybrid search to its real-time analytics engine, combining native vector search and full-text search in a single system. Agents get the real-time performance Doris is known for, plus the hybrid search their queries require from a single engine.
The same core capabilities carry from analytics to agents:
| Apache Doris core capability | Value in traditional analytics | Extended value in agent workloads |
|---|---|---|
| Real-time ingestion and updates | Makes the latest orders, transactions, and metrics immediately available | Keeps agents reasoning on the most current business facts |
| Low-latency OLAP | Powers reports, dashboards, and ad-hoc queries | Supports frequent tool calls throughout the agent reasoning chain |
| High-concurrency queries | Serves large numbers of analysts and business applications | Serves hundreds or thousands of agents and automated workflows |
| Semi-structured processing | Handles JSON, Variant, and other flexible data formats | Ingests tool outputs, event payloads, and AI-generated structures |
| Lakehouse and multi-source unified access | Consolidates data from different sources | Makes cold knowledge and hot data easier to consume together |
| Ongoing fusion of full-text and vector capabilities | Expands the analytics boundary | Brings hybrid search closer to a single unified entry point |
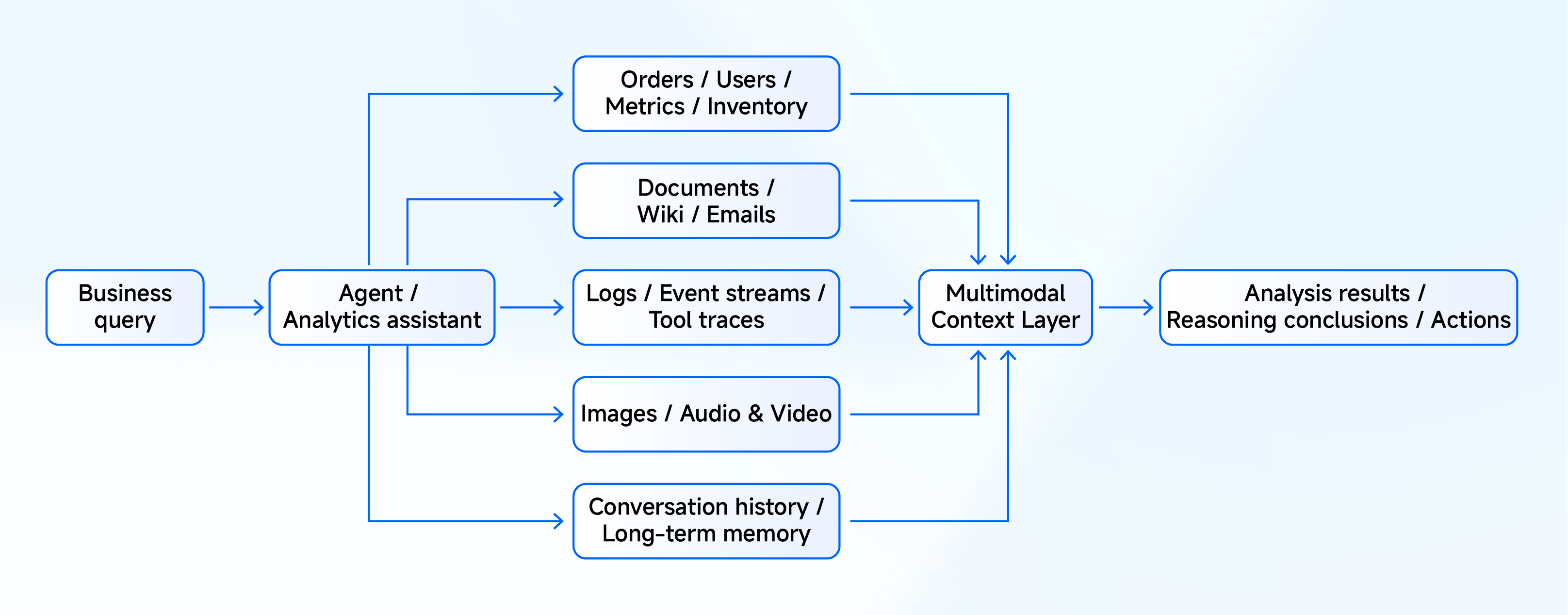
Multimodal context: building a unified context layer
Zoom out from the single query, and we see a second need. Teams often file multimodal data under a separate category from analytics, as if vectors and knowledge graphs belong in a different tier from OLAP. The value of multimodal data becomes apparent when it is used alongside structured data, as this combination brings analytics closer to live business operations.
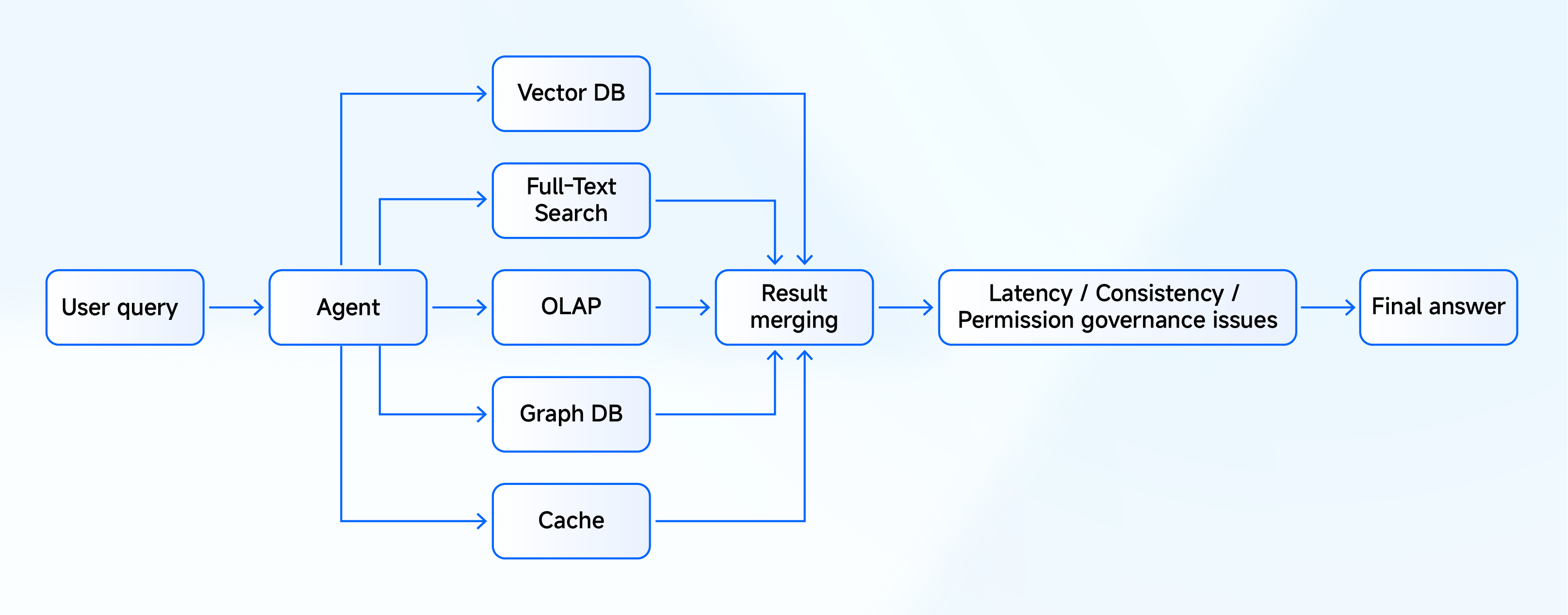
Structured data provides agents with a factual foundation, while semi-structured data modality provides models with information to understand, explain, and act, which is also known as context. An ops agent needs to know whether revenue loss crossed a threshold, which is the fact, and it needs the related fault logs, similar past incidents, and runbooks, which are the context. Both the fact and context are needed to construct a coherent and accurate output or action.
Multimodal context is about more than supporting more data types. It is a unified context layer that agents can reliably consume, holding facts, explanations, behaviors, memory, and semantics within a single system. That role pushes a real-time analytics engine like Doris to grow from a search-and-analytics system into a context system.
Here is how the context layers break down:
| Data layer | Typical contents | Role for the agent | Why combine with analytics |
|---|---|---|---|
| Fact layer | Orders, transactions, metrics, inventory, incidents | Answers “what happened” | Requires filtering, aggregation, joins, and real-time queries |
| Explanation layer | Documents, tickets, emails, comments, knowledge bases | Answers “why it happened” | Needs to be returned alongside fact results |
| Behavior layer | Logs, event streams, tool call traces | Answers “how the sequence unfolded” | Requires time-based and entity-based joins |
| Memory layer | User profiles, conversation history, task state | Answers “what happened before and what comes next” | Requires continuous updates integrated with current queries |
| Semantic layer | Embeddings, entity relationships, knowledge graphs | Answers “what’s related” | Needs to work alongside structured filtering and analytics |
Why fragmented multi-database systems break down for agent workloads
Most enterprise stacks assemble that context from separate systems: a vector store for embeddings, a search engine for full-text, an OLAP system for aggregations, and a separate store for semi-structured data. A human operator bridges the gaps between them by hand. An agent has no such bridge.
Agents need the shortest data path possible. When one task hops across multiple backends, three problems compound:
-
Context fragmentation: the data exists, but the agent sees pieces instead of the whole picture.
-
Consistency drift: each system runs its own sync cadence, index refresh, and permission model, and every gap degrades the reasoning.
-
Latency and cost: one logical query fans out into multiple network calls and result-merging rounds, which slows or breaks the chain.
That is why we added native full-text search and vector search to Doris, giving it one engine for full-text search, vector search, and semi-structured data. The result is a shorter, more stable data path for agents.
Inside that unified engine, Doris takes on context retrieval, hybrid query planning, and agent memory alongside its analytics work. Expanding outward from a mature real-time analytics engine is more practical than stitching specialist systems together from the outside.
Here is what one unified engine replaces:
| Capability module | Previously provided by | Unified real-time engine |
|---|---|---|
| OLAP | Data Warehouse / Analytical DB | Real-time fact retrieval and aggregation analytics |
| Full-text Search | Search Engine | Keyword recall and evidence retrieval |
| Vector Search | Vector DB | Semantic similarity and relevance retrieval |
| Streaming | Kafka / Apache Flink | Real-time events and incremental updates |
| Semi-structured Processing | JSON / Variant Engine | Flexible inputs and tool data |
| Memory Store | Session / Agent Store | Long-term memory and task state |
| Semantic Layer | Metadata / Governance System | Making data stably interpretable by machines |
Summary
Production AI agents are analytics consumers first. The queries they generate span structured data, full-text search, and vector retrieval in a single step, and they need answers in real time, not from batch sync.
Apache Doris combines real-time analytics with native hybrid search in one engine, giving production agents a unified data path across structured, semi-structured, and vector data.
Explore Apache Doris or join the community on Slack to learn more.