



JSON powers most modern data pipelines: from logs to events to IoT telemetry to user behavior data. Its schema-less nature enables rapid iteration, but many engineers face a trade-off when dealing with JSON: flexibility vs performance. Either store raw JSON and pay a high query cost, or lock in rigid schemas early on and give up the flexibility to evolve with the business.
Most data systems also force a trade-off when dealing with JSON: Elasticsearch favors flexibility but struggles with analytical performance at scale. Columnar systems like Snowflake and ClickHouse deliver fast analytics but require rigid schemas, impose column limits, or struggle with highly dynamic, ultra-wide JSON data.
Apache Doris uses the VARIANT data type to break this trade-off. By combining dynamic subcolumns, sparse columns, schema templates, lazy materialization, and path-based indexing, Apache Doris delivers both flexible JSON handling and high-performance columnar analytics, even at billions of rows of JSON data.
See how Apache Doris compares to ClickHouse, Elasticsearch, Snowflake, and Iceberg in JSON analytics:
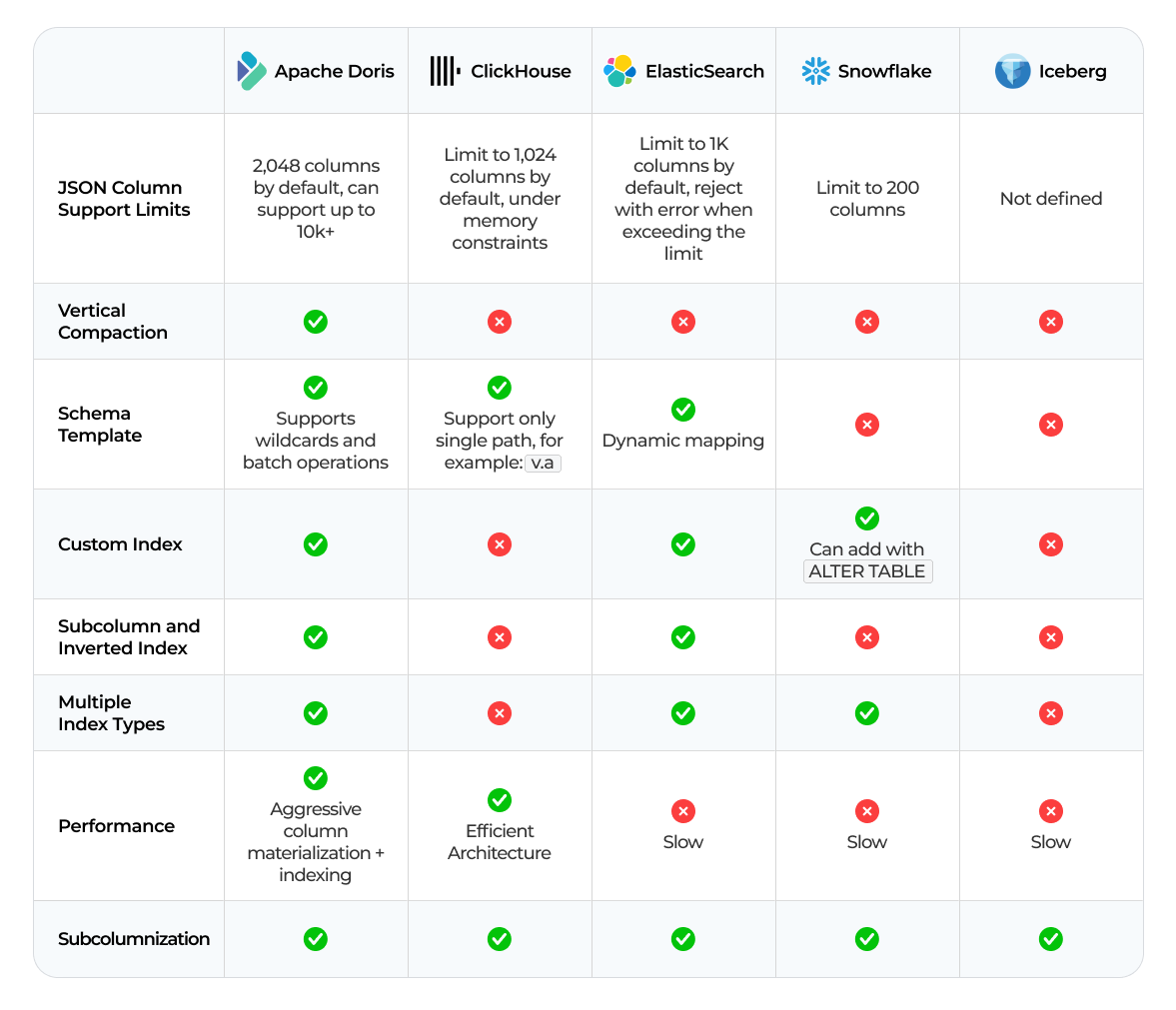
Apache Doris and VARIANT in benchmarks:
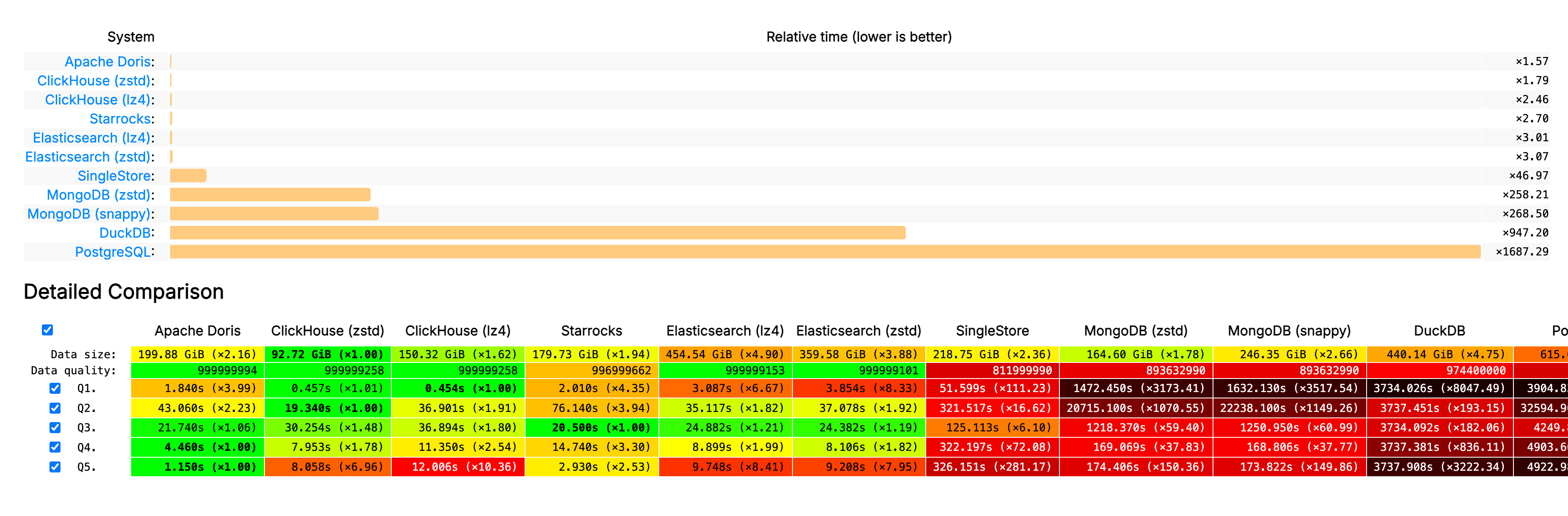
The performance Apache Doris and VARIANT has also been validated by several benchmarks, including the widely referenced JSONBench benchmark for semi-structured data workloads. In both cold and hot query scenarios, Doris consistently delivers strong and stable performance, outperforming Elasticsearch, MongoDB ...
Apache Doris showed it's about 160x faster than MongoDB, and about 1000x faster than PostgreSQL in various JSON analytics scenarios.
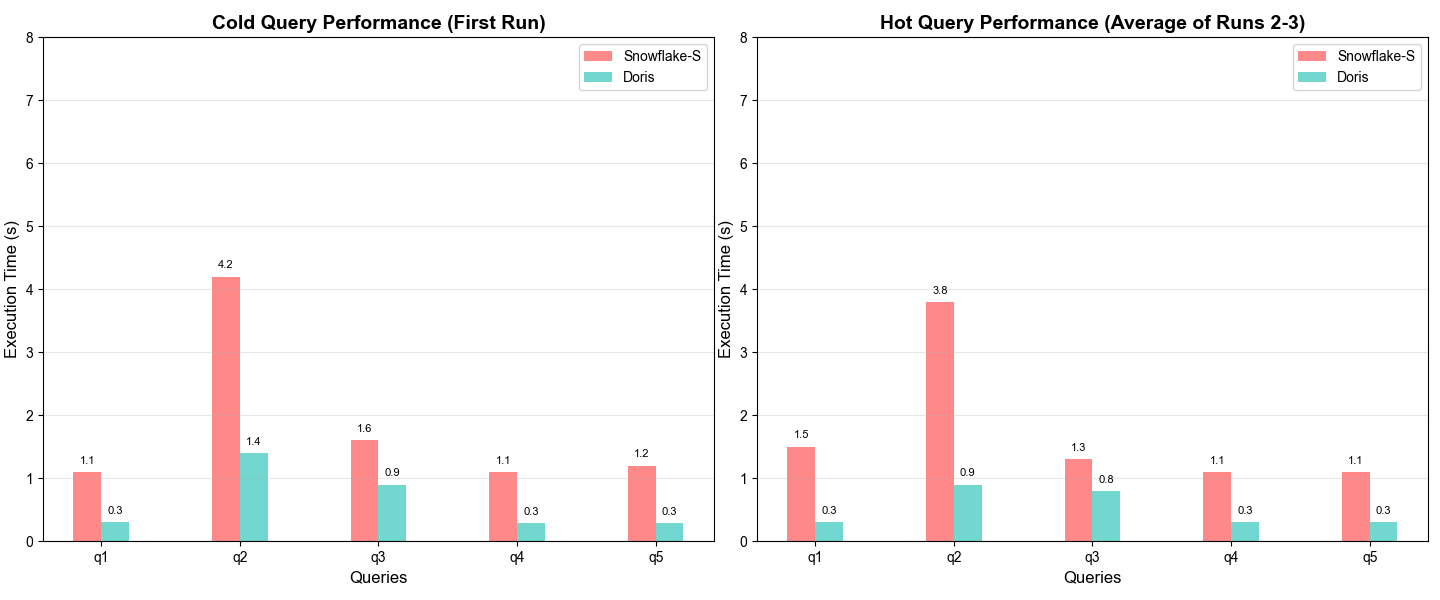
Moreover, Apache Doris delivered about 2–5x better query performance than Snowflake in both cold and hot queries in JSON analytics.
In this article, we'll dive into how VARIANT in Apache Doris is designed, how it compares with ClickHouse, Elasticsearch, Snowflake, and Iceberg, and why it can deliver high-performance JSON analytics without sacrificing its flexibility in real-world data workloads.
1. How Does Apache Doris Achieve Columnar Performance in JSON?
To achieve high-performance analytics on semi-structured data like JSON, a data system needs to treat it like structured data by building efficient columnar storage. This columnar foundation is what enables fast queries at scale.
In Apache Doris, semi-structured data is normalized using features such as dynamic subcolumns, compression, and column pruning, converting JSON fields into subcolumns with flexible schemas, enabling JSON data to fully benefit from columnar storage performance.
A. Dynamic Subcolumns
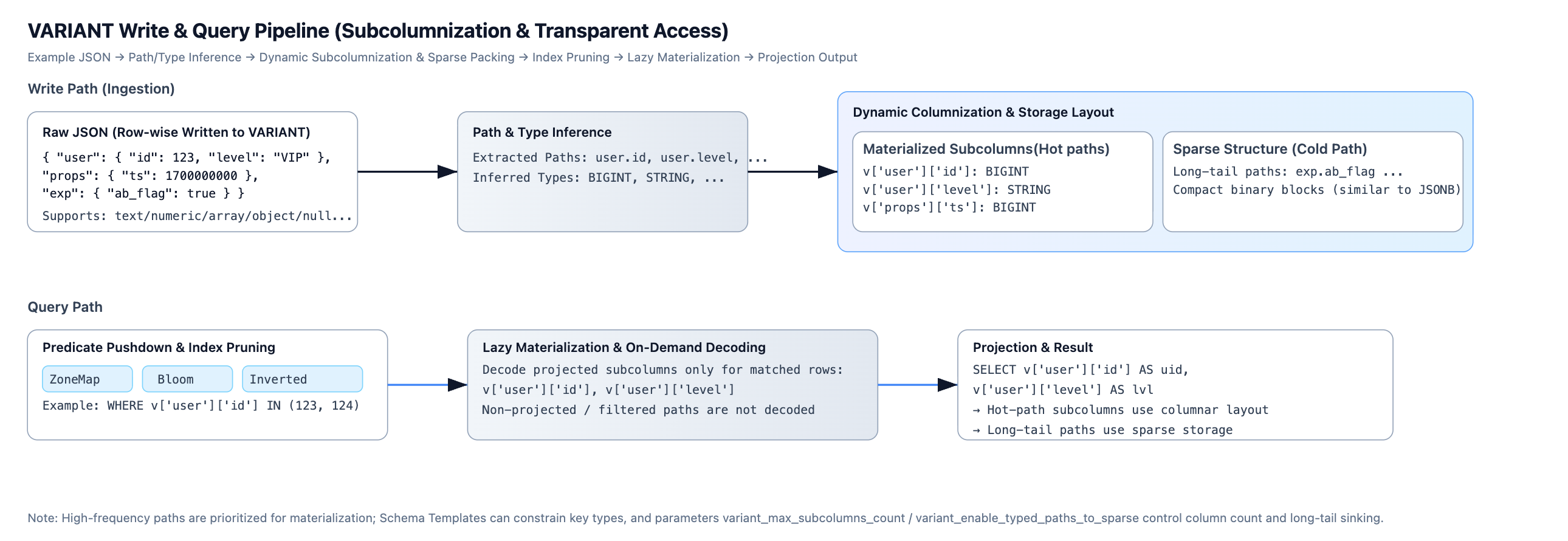
In systems like Snowflake, JSON storage is largely a black box: users have limited visibility and control, making query optimization and performance consistency difficult. To compare, when JSON data is written into a VARIANT column in Apache Doris, the system performs the following steps:
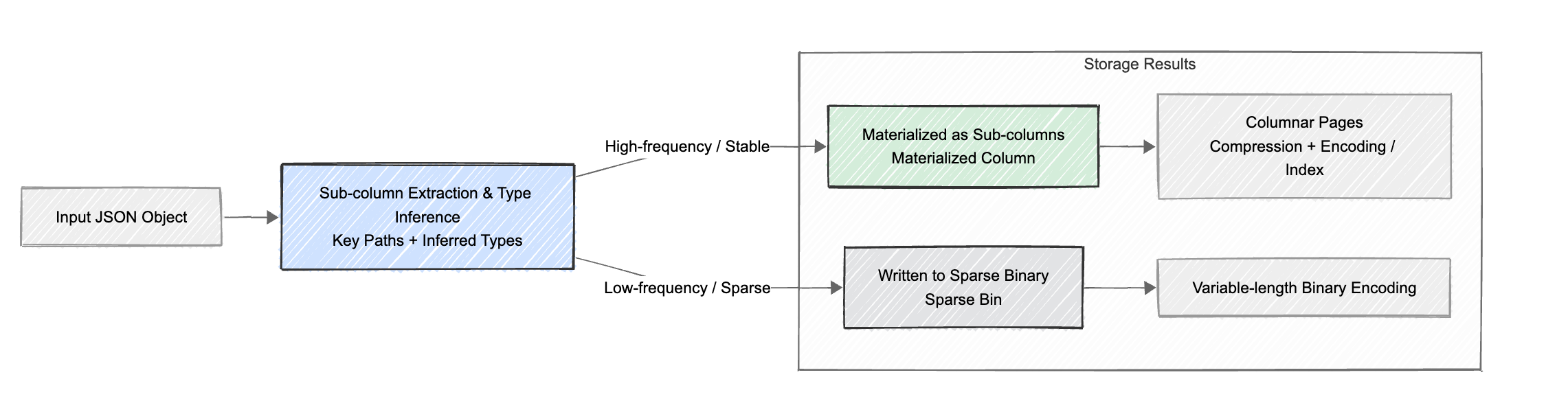
- Subcolumn extraction and type inference: Doris parses the JSON hierarchy, extracts all key paths (for example, user.id, event.properties.timestamp), and automatically infers the data type for each subcolumn (such as BIGINT, DOUBLE, STRING, etc.).
- Dynamic subcolumnization: Frequently occurring subcolumns are materialized as separate internal columns. For example, the nested field user.id will have its own BIGINT column in columnar format.
- Transparent access: This entire process is fully transparent to users. No predefined schema is required. The JSON field-to-columnar conversion occurs automatically on write. Users can still query using expressions like
v['user']['id'], while the query engine directly accesses the materializeduser.idsub‑column to fully leverage columnar storage and vectorized execution. - Sparse columns: For rarely occurring or highly complex fields, Apache Doris avoids creating separate subcolumns to prevent column explosion. Instead, these fields are efficiently stored in a binary, JSONB-like sparse column, preserving all data without incurring unnecessary column overhead.
Through these features, Apache Doris transforms semi-structured JSON data into formats similar to structured data during ingestion, laying a solid foundation for high-performance analytics.
B. Columnar Storage
Building on dynamic subcolumns, Apache Doris uses other columnar storage techniques to improve storage efficiency and I/O performance.
- Compression: Doris automatically selects the most appropriate compression algorithm for each subcolumn based on its data distribution. For example, dictionary encoding is used for low-cardinality fields, while run-length encoding (RLE) is applied to sequential numeric values. This results in more compact storage and lower read costs.
- Subcolumn-level I/O (Column Pruning): Queries read only the fields that are actually required, eliminating the traditional approach of loading and parsing entire JSON blobs. With path-level column pruning and lazy materialization, Doris loads only the necessary JSON subcolumns, effectively reducing read amplification.
Through these techniques, Apache Doris enables users to enjoy the flexibility of JSON while leveraging the high performance of columnar storage and simplified schema management. No more trade-offs, just efficient analytics on semi-structured data.

C. High Performance for Large-Scale JSON in Thousands of Columns
As data models evolve from wide to ultra-wide, new challenges emerge. Apache Doris VARIANT is designed to handle metadata explosion and the high cost of compaction with ease.
1. Metadata Storage Optimization
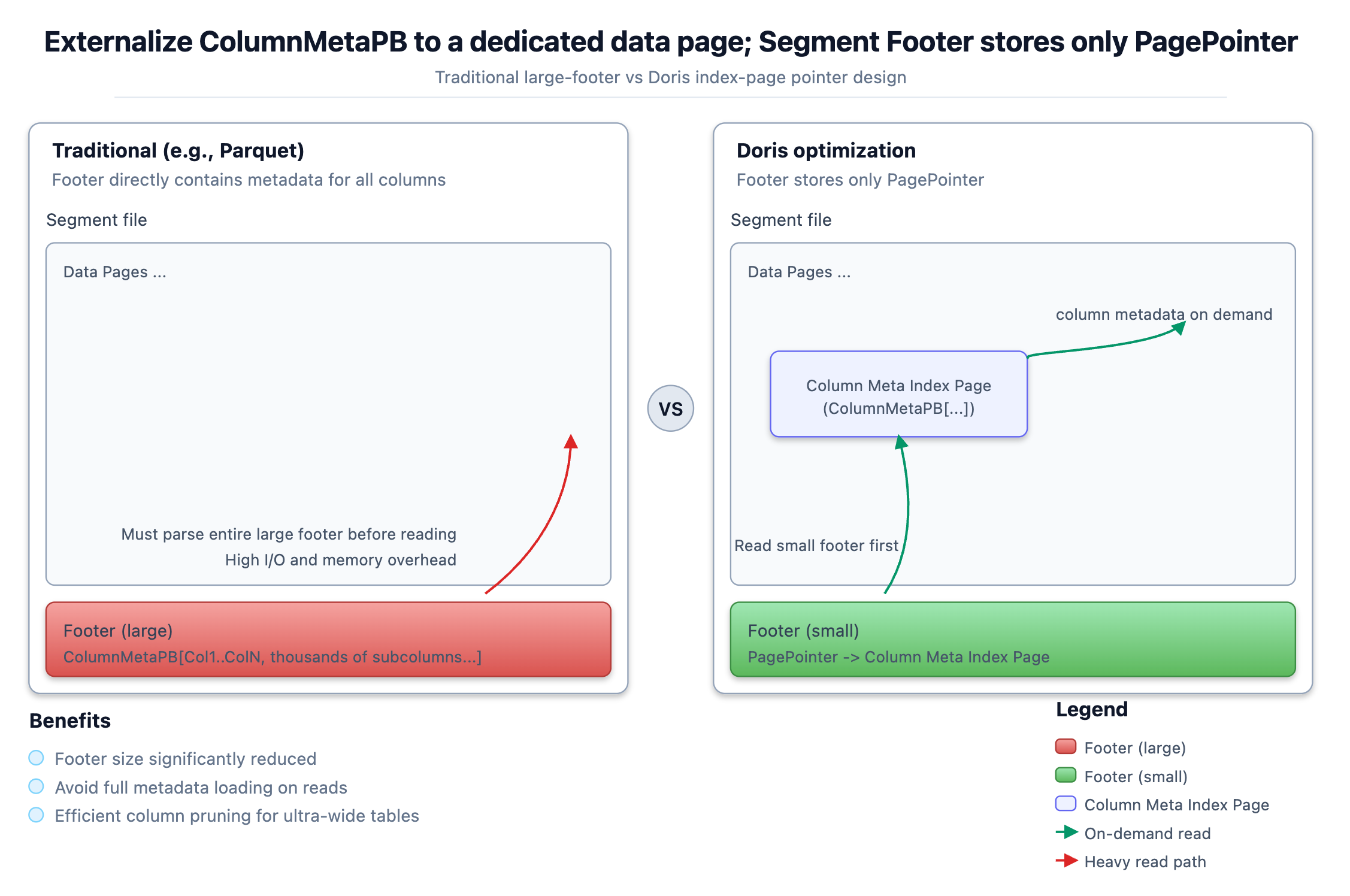
Ultra-wide table is common in log analytics and user profiling scenarios. A single table can easily contain thousands of columns. Even when a query only needs to access a small subset of columns, traditional columnar formats require loading and parsing a massive Footer containing metadata for all columns. This leads to excessive I/O, deserialization overhead, and memory consumption.
To address this, Apache Doris introduces a key optimization at the Segment file format level: it decouples column metadata from the Footer and stores it in dedicated data pages (like a metadata index page). The Footer retains only lightweight pointers to these pages. At read time, Doris first loads the minimal Footer and then locates and loads only the metadata for the columns actually accessed. This design fundamentally eliminates metadata bloat in wide-table scenarios, ensuring efficient column pruning.
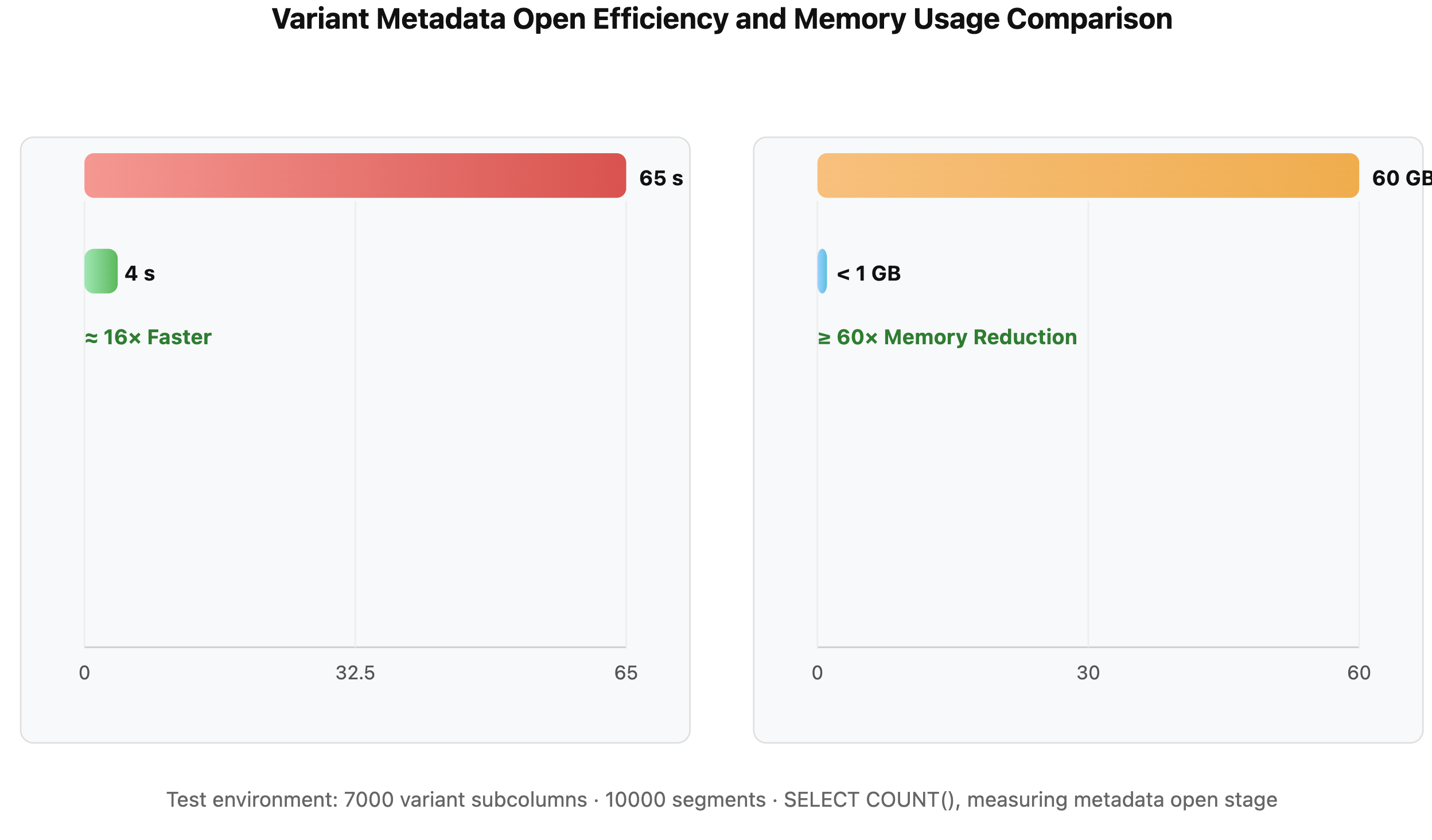
Below is a comparison of VARIANT metadata open efficiency under the following test conditions:
- 10,000 Segments
- Each Segment contains 7,000 JSON paths
- All paths are materialized as subcolumns
Before optimization: The engine had to parse a massive Footer containing metadata for all columns, resulting in heavy unnecessary I/O, extensive deserialization, and severe memory pressure. I/O became the primary performance bottleneck.
After optimization: The engine first reads a compact Footer containing only page pointers, and then loads metadata on demand for the referenced columns. Open time was reduced from 65 seconds to 4 seconds (≈16× faster), while memory usage dropped from ~60 GB to under 1 GB.
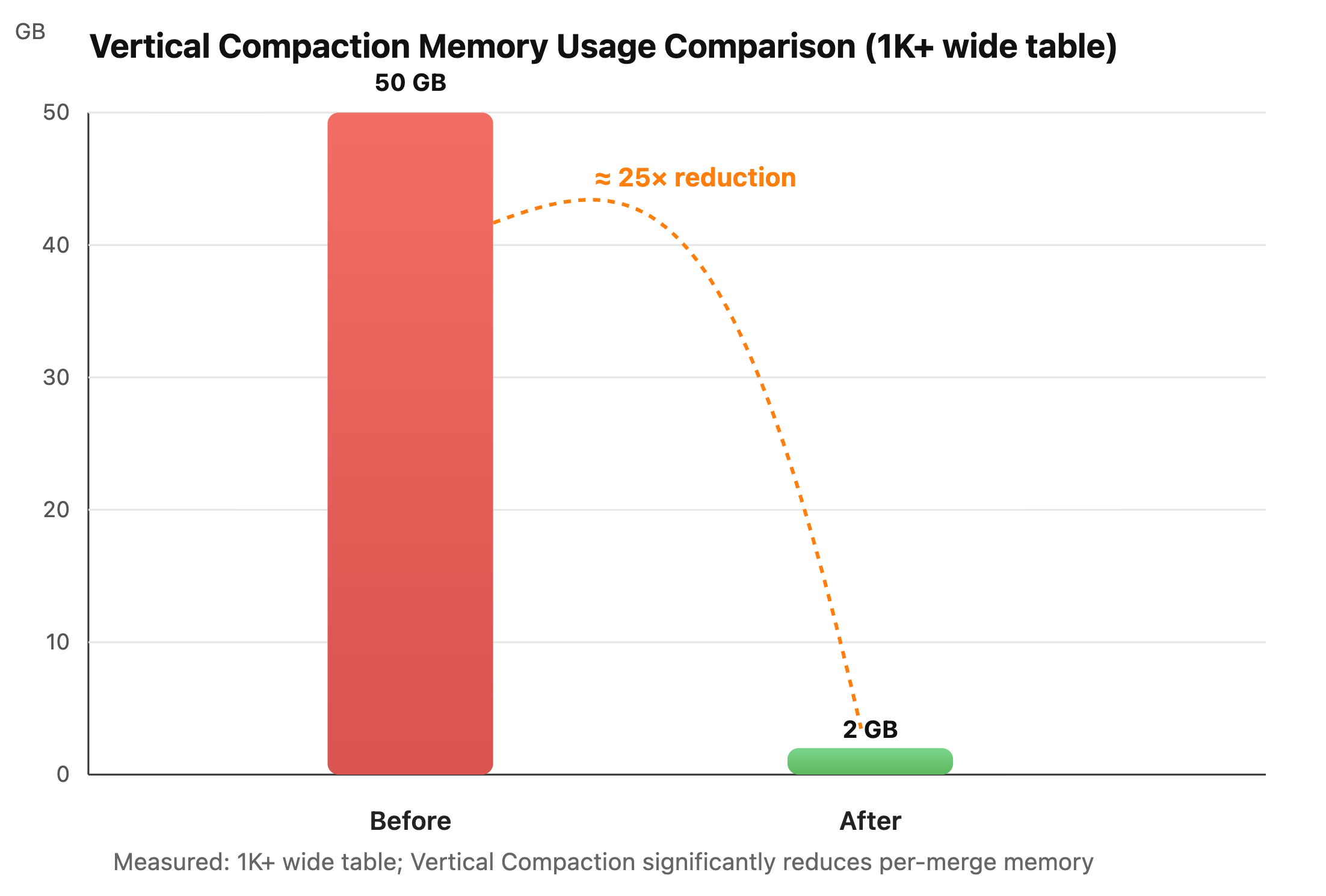
2. Vertical Compaction
In ultra-wide table scenarios, data compaction has always been a major challenge.
As the number of columns reaches thousands or even tens of thousands, traditional compaction strategies face two critical issues: First, every compaction must scan and rewrite all columns, even when most fields remain unchanged. Second, the massive column metadata and segment files drive up both I/O and memory costs.
To address this, Apache Doris VARIANT introduces column-level vertical compaction, breaking a single compaction into multiple rounds, each operating on a subset of columns (e.g., 10 at a time) until the whole table is merged. This approach delivers two key benefits:
- Significantly lower memory peaks: Each round only holds intermediate data for a small group of columns, avoiding the memory spikes caused by merging all columns simultaneously.
- More controlled I/O: Processing smaller column groups allows better alignment with disk scheduling and parallel background writes.
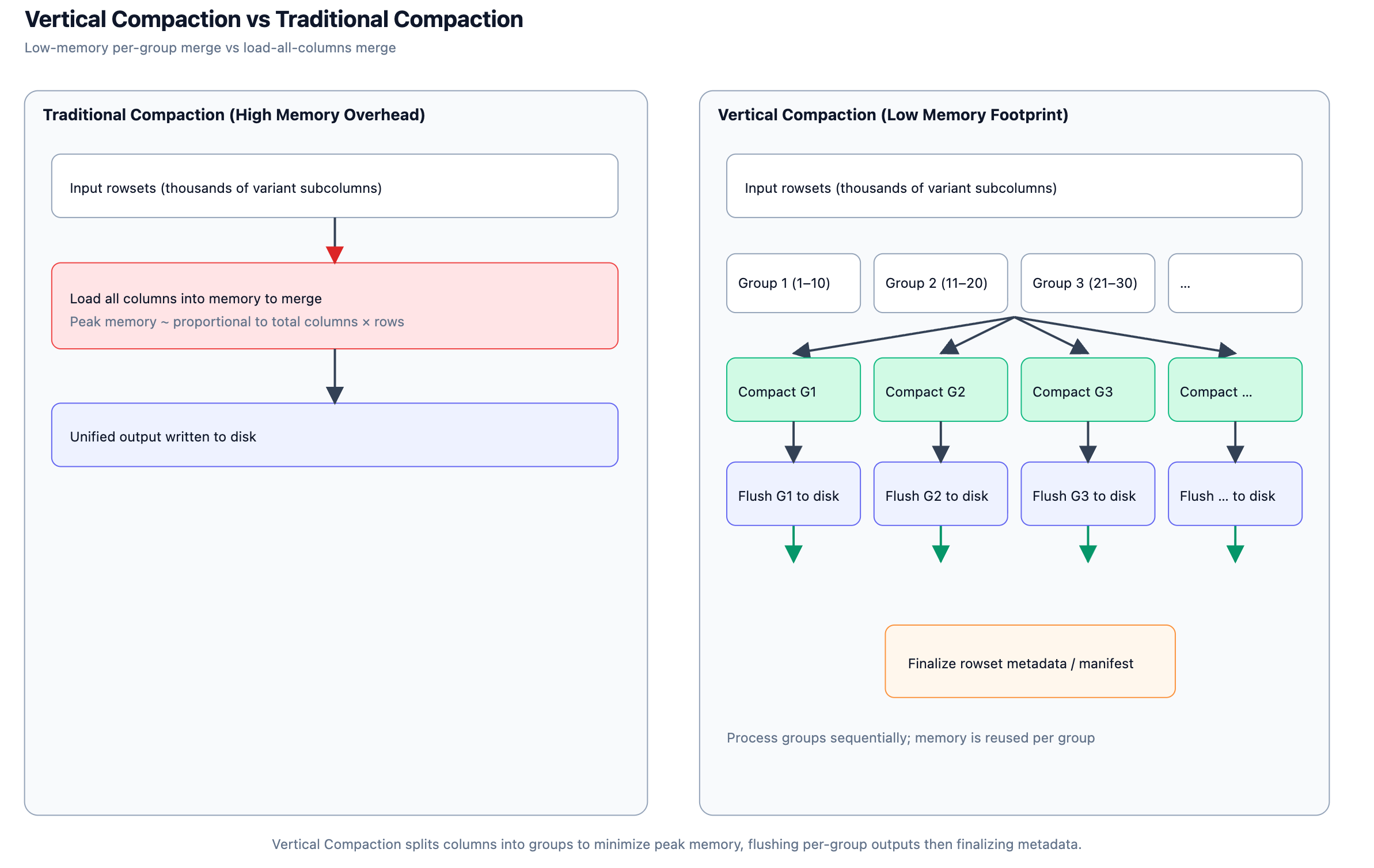
Benchmarks show that for tables with over 1,000 columns, enabling vertical compaction reduces memory usage for a single compaction from roughly 50 GB to about 2 GB, a nearly 25x reduction, while maintaining almost the same overall throughput.
Moreover, vertical compaction ensures that VARIANT tables are not just capable of storing JSON, but can also run stably over the long term in ultra-wide, dynamically changing schemas, a weak point for most columnar engines.
2. Structured Queries + Full-Text Search
Dynamic subcolumn feature in Apache Doris solves the performance bottleneck problems of JSON in large-scale scans and aggregations. Building on this foundation, Apache Doris added a highly customizable indexing framework that delivers fast responses for both point lookups and full-text search. Inspired by Elasticsearch's dynamic mapping, this design provides out-of-the-box, high-performance indexing without sacrificing flexibility.
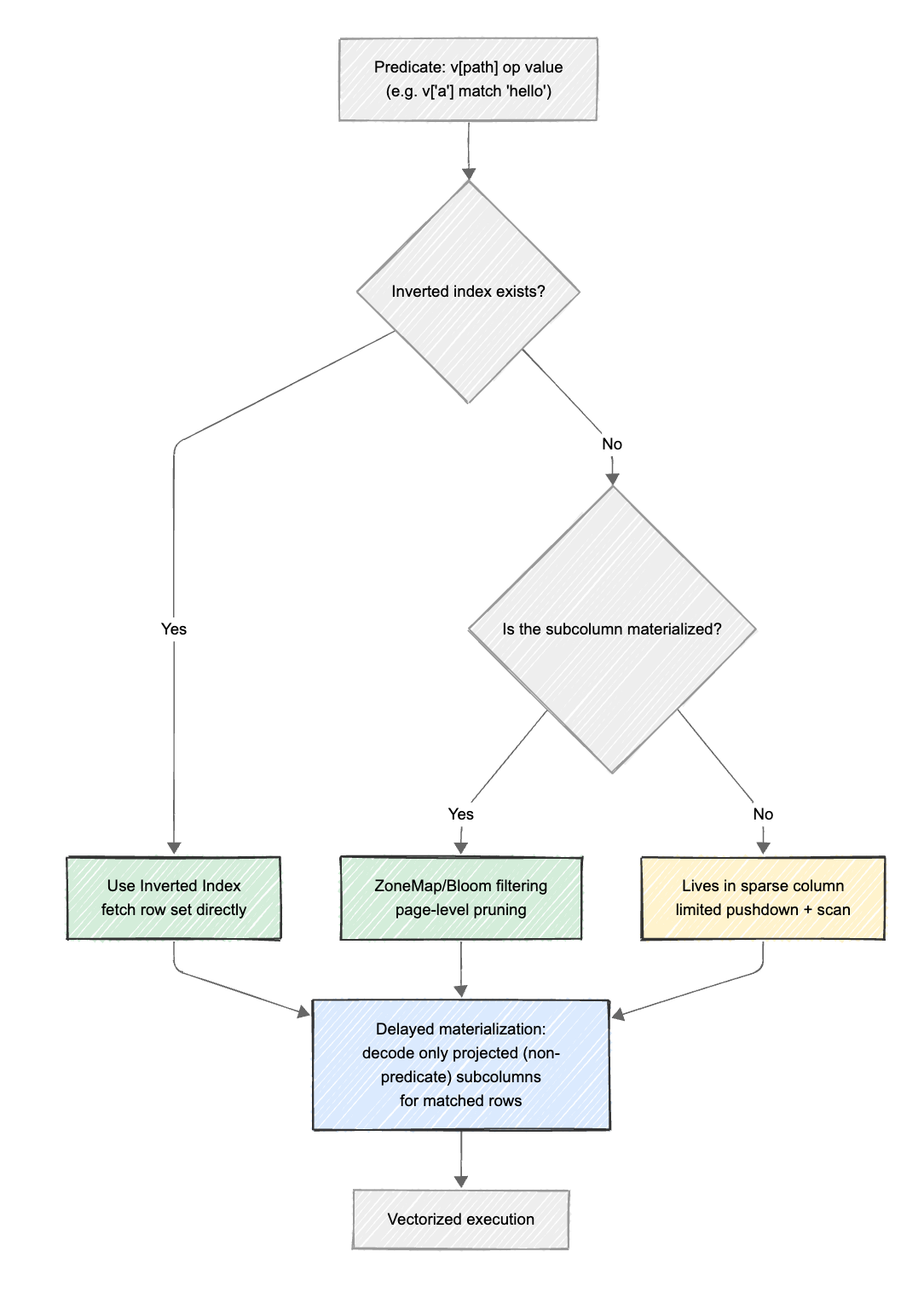
The goal of the Apache Doris VARIANT indexing system is to combine structured filtering and full-text search. It can efficiently filter structured fields like a columnar engine, while also supporting keyword and phrase searches like a search engine. To achieve this, Apache Doris integrates inverted indexes directly into the storage layer, and works with native indexes such as ZoneMaps, Bloom Filters, and lazy materialization. Together, they enable multi-level pruning and fast, precise data access from file-level to row-level.
Let's walk through the key mechanisms behind this design:
A. Integrating Inverted Indexes
- How it works:
VARIANTallows users to create inverted indexes on any subcolumn. For example:CREATE INDEX idx ON tbl(v) USING INVERTED PROPERTIES ("parser" = "english"). During data ingestion, Apache Doris automatically extracts values from the VARIANT subcolumns and builds a mapping from terms to row IDs, applying tokenization when needed or indexing raw values directly. - Query execution: For predicates such as
WHERE v['message'] MATCH_ANY 'error'orv['level'] = 'FATAL', the query engine can skip full table scans entirely. Instead, it leverages the inverted index to directly locate matching rows with keywordserrororFATAL, reducing query complexity from O(N) to O(log N) or even O(1).
B. Working with Built-in Indexes
Apache Doris materializes frequently accessed subcolumns as internal columns. Because of that, these columns automatically benefit from Doris's native indexing mechanisms:
- ZoneMap indexes: Enabled by default, ZoneMaps record the minimum and maximum values of each subcolumn within a data page. For range predicates such as
WHERE v['properties']['price'] > 1000, Doris can quickly skip pages or entire files that cannot satisfy the condition. - Bloom filter indexes: For high-cardinality subcolumns (e.g.,
user_id), Bloom filters can be used to quickly determine whether a value exists, eliminating unnecessary data reads. - Lazy materialization with indexes: Apache Doris first applies ZoneMaps, Bloom filters, and inverted indexes to perform pruning and lookup at the file, page, and row levels. Only after matching rows are identified does it decode non-predicate subcolumns on demand, avoiding unnecessary decoding of filtered-out or non-projected fields. This significantly reduces both CPU and I/O overhead.
C. Schema Templates and Path-Level Indexing
Schema templates and path-level indexes are key to precise and effective index pushdown. Schema templates define which JSON subcolumns should be explicitly recognized and optimized, while path-level indexes specify how those subcolumns are indexed and matched during query execution.
With schema templates, users can declare in advance the data types and index properties for key JSON subcolumns. So the engine can identify and optimize these key JSON subcolumns during both reading and writing. After that, path-level indexing uses multiple indexing strategies, such as inverted indexes, Bloom filters, and ZoneMaps, to optimize queries.
Typical configuration examples:
CREATE TABLE IF NOT EXISTS tbl (
k BIGINT,
v VARIANT<'content' : STRING>,
INDEX idx_tokenized(v) USING INVERTED PROPERTIES(
"parser" = "english",
"field_pattern" = "content",
"support_phrase" = "true"
),
INDEX idx_keyword(v) USING INVERTED PROPERTIES(
"field_pattern" = "content"
)
);
-- tokenized for MATCH; keyword for exact equality
SELECT * FROM tbl WHERE v['content'] MATCH 'Doris';
SELECT * FROM tbl WHERE v['content'] = 'Doris';
tokenized is used for
MATCHqueries, while keyword is used for exact matching.
Wildcard paths:
INDEX idx_logs(v) USING INVERTED PROPERTIES(
"field_pattern" = "logs.*"
);
For more usage patterns and configuration details, refer to the VARIANT documentation.
3. Typical Use Cases of VARIANT in Apache Doris
A. Log Analytics
Many log analytics platforms are built on Elasticsearch or ClickHouse. But they come with drawbacks: high write costs, difficult schema management as fields change, and unstable query throughput.
With Apache Doris, users can ingest raw JSON logs directly using the VARIANT data type. There's no need for complex ETL pipelines, schema flattening, or heavy upfront schema design. You can filter and run full-text searches on any log field with high performance out of the box.
Example: table creation
CREATE TABLE access_log (
dt DATE,
log VARIANT
)
DUPLICATE KEY(dt)
DISTRIBUTED BY HASH(dt)
PROPERTIES ("replication_num" = "1");
CREATE INDEX idx_log ON access_log(log) USING INVERTED;
Real-time log ingestion via Stream Load
curl -u user:password \
-T access.json \
-H "format: json" \
http://fe_host:8030/api/db/access_log/_stream_load
Querying logs just like structured data
SELECT
log['status'] AS status,COUNT(*) AS cnt
FROM access_log
WHERE log['region'] = 'US'
GROUP BY status;
In this setup, Apache Doris automatically converts frequently used keys, such as region and statusinto columnar storage, enabling sub-second aggregation performance. When new fields appear in the log structure (for example, latency or trace_id), Doris automatically creates the corresponding columns and indexes. No manual ALTER TABLE or data reloading is required.
Benchmark results show that, using the same hardware, Apache Doris delivers 2–3x faster log aggregation queries than Elasticsearch, reduces ingestion latency by more than 80%, and cuts storage usage by about 70–80%.
B. Dynamic User Profiles
In a user profiling system, each user typically has hundreds or even thousands of attributes, such as region, interests, preferences, activity level, and acquisition channel. These attributes change frequently, with new tags constantly being added or updated. In traditional column-based modeling, this means repeatedly altering table schemas or maintaining hundreds of wide tables, which are highly inefficient.
With Apache Doris, a single VARIANT column (for example, profile) is enough to store all user attributes.
Table creation example:
CREATE TABLE user_profile (
user_id BIGINT,
profile VARIANT
)
DUPLICATE KEY(user_id)
DISTRIBUTED BY HASH(user_id);
Insert JSON data directly at write time:
INSERT INTO user_profile VALUES
(1001, '{"region": "US", "age": 28, "interest": ["movie","sports"]}'),
(1002, '{"region": "CA", "vip": true, "device": "ios"}');
Aggregate efficiently at query time, no schema expansion required:
SELECT
CAST(profile['region'] AS String) AS region,COUNT(*) AS cnt
FROM user_profile
WHERE profile['vip'] = true
GROUP BY region;
Behind the scenes, Apache Doris automatically detects newly appearing keys (such as region or vip) and materializes them as independent columns (supporting thousands of such columns). Extremely low-frequency fields are kept in a fallback sparse column. As a result, even when the number of tags grows into the thousands, query performance remains close to that of a standard structured table.
In real-world tests, a user profile table with 7,000 dynamic tags achieved sub-second average response times when querying the Top 10 attribute distributions.
C. Customer Use Cases
1. Du Xiaoman: From Greenplum to Apache Doris
Du Xiaoman, a fintech company in Asia, migrated from Greenplum to Apache Doris and built a large-scale analytics platform. By leveraging the built-in VARIANT data type, the system efficiently stores and queries 20,000–30,000 JSON keys at petabyte scale. Overall system performance improved by 20–30x, JSON query performance by 10×, and storage usage dropped to 1/10 that of traditional JSON storage.
Under high-concurrency, real-time queries and complex analytics workloads, the platform now supports financial-grade metrics and real-time data services, helping the company transform from offline analytics to real-time insights.
2. A major tech company: From HBase + Elasticsearch + Snowflake to Apache Doris
A major tech company consolidated three separate systems (HBase, Elasticsearch, and Snowflake) into a single platform based on Apache Doris, unifying search and analytics. Apache Doris's VARIANT columnar data type enables efficient storage and querying of high-dimensional, dynamic JSON, allowing columnar processing of unstructured attributes across tens of billions of objects.
With sub-column indexing and pruning, query latency dropped from seconds to hundreds of milliseconds, while concurrent writes and complex joins improved significantly. The result: lower overall costs, simpler architecture, and major gains in stability and consistency.
3. Guance (Observability Platform): From Elasticsearch to Apache Doris
Guance, a full-stack observability platform, originally built a system based on Elasticsearch. But the system saw Elasticsearch's dynamic mapping causing frequent field conflicts, high resource consumption, and limited aggregation performance. Guance migrated to Apache Doris for its VARIANT data type and inverted indexes, and built an elastic hot–cold tiered architecture on S3 object storage.
Query efficiency for logs and behavioral data improved dramatically. After the upgrade, machine costs were reduced by 70%, overall query performance doubled, and simple queries ran 4x faster. The platform saw performance improved by multiple times with only a third of its original cost.
4. Smart Manufacturing Company: From Hive/Kudu + Impala/Presto to Apache Doris
A global leader in new energy and smart manufacturing migrated from a Hive/Kudu + Impala/Presto stack to Apache Doris, building a real-time analytics platform covering vehicle connectivity and the full lifecycle of industrial equipment.
Powered by Apache Doris's built-in VARIANT type, the platform efficiently processes JSON and semi-structured data at petabyte scale, achieving second-level ingestion and millisecond-level query latency. In core business operations such as real-time dashboards, end-to-end tracing, and equipment health analysis, complex JSON queries ran 3–10x faster, high-concurrency performance improved significantly, and storage usage dropped to one-third of traditional solutions.
A unified engine based on Apache Doris enabled the shift from batch processing to real-time insights, while greatly reducing architectural complexity and operational costs.
5. Leapmotor (EV automaker): Apache Doris + S3
Facing tens of terabytes of daily signal data generated by millions of connected vehicles, Leapmotor built a unified data foundation using Apache Doris' VARIANT dynamic columnar storage and S3 object storage. This platform supports smart cockpit features, remote diagnostics, and user behavior analytics.
Combined with Doris' materialized views and elastic compute, it delivers millisecond-level queries, automatic scaling, and 60% lower storage costs. The team is now validating a serverless model that leverages S3's elasticity and Apache Doris's high performance.
4. Conclusion
Apache Doris's VARIANT data type allows semi-structured data to be processed naturally within a columnar engine. Through features such as dynamic sub-columns, sparse column storage, late materialization, and path-based indexing, Apache Doris unifies JSON parsing, column pruning, and index pushdown into a single system, so users no longer need to choose between schema flexibility and columnar performance.
Looking ahead, Apache Doris will further improve automatic schema inference for VARIANT, support richer data types, build more powerful sub-column indexing, and continue optimizing query performance over sparse columns.
Want to learn more about Apache Doris and its VARIANT feature? Join the Apache Doris community on Slack and connect with Doris experts and users. If you're looking for a fully-managed, cloud-native version of Apache Doris, contact the VeloDB team.


