


Streaming analytics is about analyzing data while it is still in motion, not after it has been stored and processed. As systems increasingly depend on real-time signals—from fraud detection to operational monitoring—latency becomes a critical constraint, and traditional batch analytics often falls short.
This article explains what streaming analytics is, how it works at a system level, and when it is the right choice over batch or micro-batch approaches. Drawing from real-world engineering experience, it also explores common architectures, use cases, and the trade-offs teams face when building streaming analytics at scale.
What Is Streaming Analytics?
Streaming analytics is the continuous analysis of data as it is generated, enabling systems to compute metrics, detect patterns, and trigger decisions with minimal latency. Unlike traditional analytics, which assumes data is first stored and then queried, streaming analytics treats data as an unbounded flow of events that must be processed incrementally and continuously.
From a system-level perspective, streaming analytics is defined by three core characteristics:
- Continuous data ingestion: Data arrives nonstop from sources such as application events, logs, sensors, or CDC streams. There is no natural “end” to the dataset.
- Low-latency processing and stateful computation: The system maintains evolving state over time—windows, aggregates, joins—so results can be updated as each new event arrives.
- Decision-oriented outputs: The goal is not just insight, but action: flagging anomalies, triggering alerts, updating downstream systems, or feeding real-time models.
In practice, streaming analytics exists because waiting to analyze data often destroys its value. When relevance depends on immediacy—seconds or milliseconds rather than minutes—batch-oriented approaches are fundamentally misaligned with the problem.
Streaming Analytics vs. Batch and Micro-Batch
This is where a lot of confusion starts.
Batch analytics assumes data is complete, stable, and ready to be queried. You collect data first, then analyze it later. Latency is measured in minutes or hours.
Micro-batch processing reduces batch size and runs jobs more frequently—every few seconds or minutes. While this improves freshness, it is still fundamentally batch-oriented.
Streaming analytics is different. It processes events one by one (or in very small increments), maintains state continuously, and produces results as events arrive.
In practice, micro-batch is often “good enough” for reporting. It is not good enough when decisions depend on what is happening right now.
When Streaming Analytics Is Needed
You need streaming analytics when understanding what is happening right now matters more than producing a perfectly complete historical view later. This usually becomes clear when system behavior, risk, or user experience can change meaningfully within short time windows.
Streaming analytics is a good fit if:
- Your data arrives continuously and never truly “settles”
- Decisions must be made while events are still unfolding
- Latency directly impacts outcomes, not just reporting freshness
- You need to correlate sequences of events over time, not just summarize them after the fact
Common signals that batch or micro-batch is no longer enough include growing alert delays, missed anomalies, or operational teams reacting after issues have already escalated.
On the other hand, streaming analytics may be unnecessary—or even counterproductive—if:
- Decisions can tolerate minutes or hours of delay
- Data volumes are moderate and predictable
- Analysis is primarily retrospective or exploratory
- Operational simplicity and cost efficiency matter more than immediacy
From experience, the most important question to ask is this:
Does acting late meaningfully reduce the value of the decision?
If the answer is yes, streaming analytics is usually worth the added complexity. If not, traditional batch analytics remains simpler, cheaper, and easier to operate.
How Streaming Analytics Works
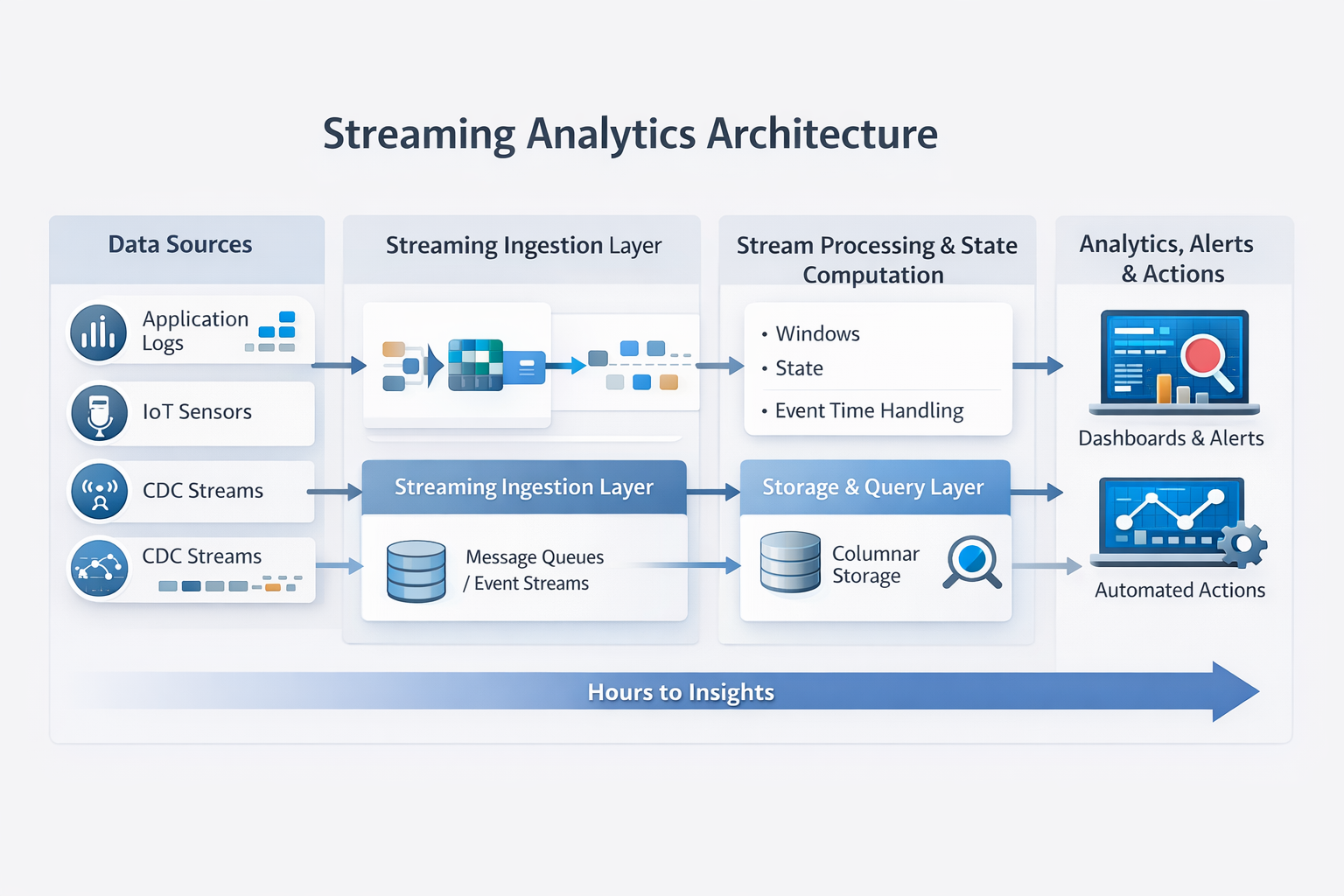 Streaming analytics works as an always-on, end-to-end system that continuously ingests events, maintains state, and produces results as data flows through the pipeline. Unlike batch architectures, there is no clear start or end point—each stage operates continuously and must be designed to handle variability, disorder, and failure without stopping the system.
Streaming analytics works as an always-on, end-to-end system that continuously ingests events, maintains state, and produces results as data flows through the pipeline. Unlike batch architectures, there is no clear start or end point—each stage operates continuously and must be designed to handle variability, disorder, and failure without stopping the system.
At a high level, a production streaming analytics architecture consists of four tightly coupled layers.
Continuous Data Ingestion from Live Sources
Streaming analytics starts with continuous ingestion of live data.
Typical data sources include:
- Application events and logs
- IoT devices and sensors
- Change Data Capture (CDC) from operational databases
Unlike batch ingestion, streaming ingestion must be resilient by default. In real systems, traffic is uneven and failure is normal. The ingestion layer must therefore handle:
- Bursty or spiky traffic from reconnecting producers
- Retries and duplicate events
- Partial outages without halting downstream processing
Stream Processing and Stateful Computation
Once ingested, events are processed continuously using stateful stream processing.
Common processing patterns include:
- Windowed aggregations (sliding, tumbling, session windows)
- Stateful joins across multiple streams
- Continuous filtering and enrichment
What fundamentally differentiates streaming analytics from simple event handling is state. The system must remember what has already happened—counts, aggregates, partial joins—and update that state incrementally as new events arrive.
Handling Out-of-Order Events and Late Data
Event disorder is the norm, not the exception.
In distributed systems, events routinely arrive late, out of order, or not at all due to network delays, retries, and asynchronous producers. A production-grade streaming analytics system must therefore operate on event time, not processing time.
Core mechanisms include:
- Watermarks to track event-time progress
- Late-event handling to update results correctly
- Retractions or corrections for previously emitted outputs
Many systems marketed as “real-time” quietly ignore these issues, trading correctness for lower latency.
Real-Time Analytics, Visualization, and Actions
The goal of streaming analytics is not dashboards—it is action.
Outputs of a streaming analytics system often include:
- Low-latency queries on live data
- Automated alerts and triggers
- Feedback loops into applications and services
Visualization helps operators understand system behavior, but the real value appears when systems can react while data is still in motion, rather than after it has been stored and analyzed.
Streaming Analytics vs Traditional Analytics
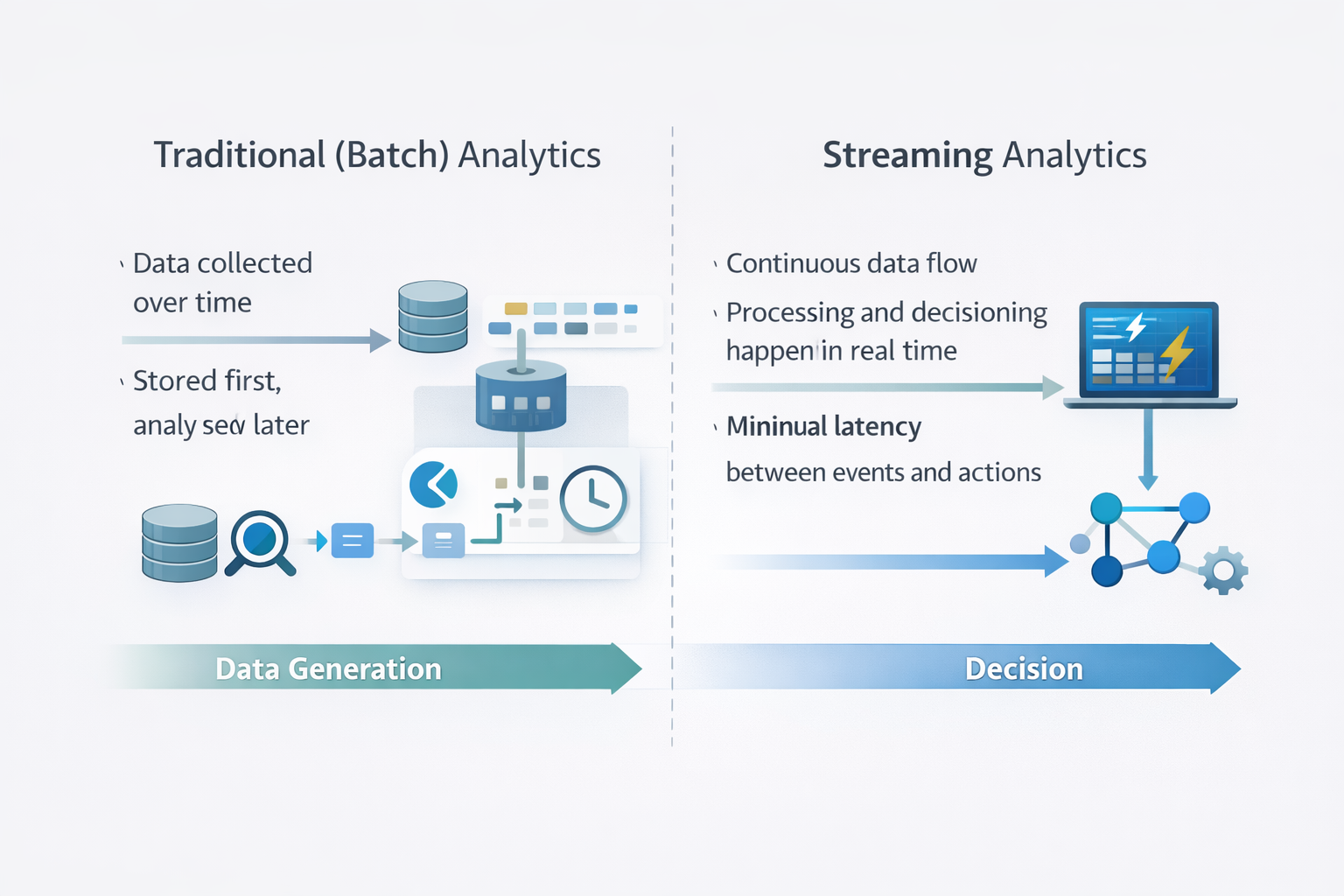 At a high level, the difference between streaming analytics and traditional analytics is not about tools, but about timing and intent. Both approaches analyze data, but they assume very different things about when data is complete and when decisions are made.
At a high level, the difference between streaming analytics and traditional analytics is not about tools, but about timing and intent. Both approaches analyze data, but they assume very different things about when data is complete and when decisions are made.
Traditional analytics is built around the idea that data can be collected, stored, and analyzed later. This works well for historical reporting, trend analysis, and offline optimization. Latency exists, but it is acceptable because decisions are not time-critical.
Streaming analytics starts from a different assumption: data is never complete, and waiting too long to analyze it reduces its value. Instead of asking “What happened?”, streaming analytics asks “What is happening right now, and what should we do about it?”
These differences shape everything—from data models and system architecture to cost structure and operational complexity.
| Dimension | Streaming Analytics | Traditional (Batch) Analytics |
|---|---|---|
| Latency | Milliseconds to seconds | Minutes to hours |
| Data model | Unbounded event streams | Finite datasets |
| Cost profile | Always-on compute | Periodic compute |
| Complexity | Higher (state, ordering) | Lower |
| Decision use cases | Real-time reactions | Retrospective analysis |
In practice, this means streaming analytics systems are optimized for continuous computation and fast feedback, while traditional analytics systems are optimized for throughput, simplicity, and cost efficiency.
It’s also important to note that this is not an either-or choice. Most mature data architectures use both:
- Streaming analytics to power real-time detection, monitoring, and decisioning
- Traditional analytics to support reporting, historical analysis, and long-term planning
The key is understanding which decisions cannot wait. When delay directly impacts outcomes, streaming analytics is the right tool. When time is less critical, batch analytics remains simpler and more economical.
Streaming Analytics Use Cases
Not every analytics use case requires streaming, but the ones that do share a common trait: the value of the data drops rapidly over time. In these scenarios, waiting for data to be collected, stored, and analyzed later often means reacting too late. Streaming analytics is most effective when decisions must be made while events are still unfolding, not after the fact.
The following use cases illustrate where streaming analytics becomes a necessity rather than an optimization.
1. Fraud Detection and Risk Monitoring
Fraud rarely appears as a single suspicious transaction. Instead, it emerges as a pattern across multiple events—unusual sequences, abnormal frequencies, or deviations from typical behavior.
Streaming analytics enables systems to:
- Correlate transactions in real time
- Maintain state across user sessions or accounts
- Detect suspicious patterns as they form
Batch analytics is not enough here because delayed detection often means the damage is already done. Once funds are transferred or accounts are compromised, the opportunity to prevent loss has passed.
2. IoT and Operational Monitoring
IoT and operational systems generate continuous streams of telemetry from machines, sensors, and infrastructure components. In these environments, anomalies often signal early warnings, not immediate failures.
Streaming analytics allows teams to:
- Detect abnormal trends as they develop
- Correlate signals across devices and locations
- React before minor issues escalate into outages or safety incidents
Batch analytics falls short when downtime, equipment damage, or safety risks escalate in real time. By the time a batch job runs, the system may already be in a degraded or dangerous state.
3. Customer-Facing and Real-Time Personalization
User behavior changes from moment to moment—what a user clicks, searches, or abandons provides immediate context that quickly becomes stale.
Streaming analytics makes it possible to:
- Update recommendations based on live behavior
- Adjust pricing, promotions, or content in real time
- Respond to user intent while it is still relevant
Batch analytics is not enough when relevance depends on current context. Decisions based on yesterday’s behavior often feel disconnected or ineffective in fast-moving user interactions.
4. Supply Chain and Operational Intelligence
Supply chains operate as interconnected systems where disruptions propagate quickly. A delay in one location can cascade into shortages, missed deliveries, or increased costs elsewhere.
With streaming analytics, organizations can:
- Monitor events across suppliers, logistics, and inventory in real time
- Detect emerging bottlenecks or delays early
- Take corrective action before downstream impact spreads
Batch analytics is not enough when decisions must be made before ripple effects compound. Acting late often means reacting to symptoms rather than preventing the root cause.
Key Benefits of Streaming Analytics
Streaming analytics fundamentally changes when and how systems respond to data. Instead of analyzing events after the fact, it enables systems to react while signals are still forming. When applied to the right problems, the benefits are significant—but they only emerge in always-on, low-latency environments.
Low-latency insights while data is still actionable
The most immediate benefit of streaming analytics is speed. By processing data as it arrives, systems can detect signals and anomalies before their relevance fades. In domains such as fraud detection, operations, and real-time personalization, this timing difference often determines whether an action is effective or already too late.
Continuous visibility into system behavior
Streaming analytics provides a continuously updated view of system behavior rather than periodic snapshots. This makes it easier to observe gradual drift, emerging trends, and correlated issues that are difficult—or impossible—to identify through batch reports alone.
Faster decisions, often automated
Because streaming analytics runs continuously, it naturally supports automation. Alerts, triggers, and feedback loops can execute without human intervention, reducing reaction time and operational overhead. Over time, analytics shifts from a passive reporting role to an active component of system control.
Challenges in Implementing Streaming Analytics at Scale
Streaming analytics systems often work well in early prototypes. The real challenges emerge as data volumes grow, workloads diversify, and correctness and reliability become non-negotiable—especially as expectations around latency and debuggability continue to rise.
1. Out-of-Order Data and Event Time
Correctness under disorder is one of the hardest problems in streaming analytics—and one of the easiest to overlook.
In distributed systems, events arrive late or out of order due to network delays, retries, and asynchronous producers. Handling this correctly requires reasoning in event time, not processing time, and implementing mechanisms such as watermarks and late-event handling. Cutting corners here may improve apparent latency, but it almost always introduces subtle correctness bugs.
2. Schema Evolution and Data Quality
Schemas change, and streaming systems must evolve without downtime.
New fields appear, formats change, and data quality degrades over time. In a streaming context, there is no convenient pause button. Systems must tolerate schema evolution gracefully, validate incoming data, and isolate bad records without disrupting the entire pipeline.
This is particularly challenging when multiple producers evolve independently.
3. Operational Complexity and Observability
Streaming systems are long-running and stateful, which makes failures harder to diagnose.
Latency spikes, backpressure, and unbounded state growth can develop gradually and remain invisible without proper observability. Metrics, logs, and traces are not optional—they are essential tools for understanding system health and behavior over time.
As a rule, if you cannot explain why latency changed, you cannot reliably operate a streaming system.
Another often overlooked challenge in streaming analytics is reproducibility. Because data is unbounded and constantly changing, reproducing past states or replaying queries with identical inputs is difficult. This complicates root-cause analysis, as teams must rely on approximations rather than deterministic re-execution. Systems that persist data in queryable form avoid this limitation by enabling historical replay and validation.
4. The Cost of “Always-On” Analytics
Streaming analytics never sleeps.
Because pipelines run continuously, costs accumulate even during periods of low activity. Efficient resource utilization, retention policies, and query optimization become first-class engineering concerns. Without deliberate cost controls, streaming systems can quietly become some of the most expensive components in a data stack.
5. Latency Expectations and the Limits of Streaming Architectures
Streaming analytics is often associated with “real-time,” but in practice, many streaming systems struggle to meet modern latency expectations at scale.
Traditional stream processing architectures introduce inherent delays through buffering, windowing, watermark progression, and checkpointing. These mechanisms are necessary for correctness, but they also mean that end-to-end freshness often settles at seconds, not milliseconds.
In contrast, modern SQL-based analytical systems designed for real-time ingestion can achieve sub-second data freshness while still supporting interactive queries. As a result, streaming analytics is no longer automatically the fastest way to access fresh data—it is simply a different trade-off between latency, correctness, and processing semantics.
This gap has become increasingly visible as teams compare streaming pipelines with systems that ingest events continuously but query them using low-latency analytical engines.
How to Choose a Streaming Analytics Platform
Choosing a streaming analytics platform is less about finding the “best” product and more about understanding which architectural approach fits your data characteristics, latency requirements, and operational constraints. As streaming systems move from experiments to production-critical infrastructure, platform choice becomes a long-term engineering decision rather than a tooling preference.
Core Capabilities to Look For
When evaluating streaming analytics platforms, it helps to focus on a small set of non-negotiable capabilities rather than long feature lists.
Scalable and resilient ingestion The platform must handle bursty traffic, retries, and duplicates without collapsing under load. In real systems, smooth data flow is the exception, not the rule.
Stateful stream processing Support for windows, joins, and long-lived state is essential. Stateless event handling may look simpler, but it quickly becomes limiting once real analytics requirements emerge.
Low-latency analytical queries Streaming analytics is not only about processing events—it is also about querying results while data is still fresh. The ability to run ad-hoc or interactive queries on live data often determines whether insights are actually usable.
Strong observability and debugging tools When something goes wrong, you need to understand why. Metrics, logs, and tracing across ingestion, processing, and state are critical for operating streaming systems reliably.
Across all of these, architecture matters far more than individual features. Platforms designed around batch assumptions tend to struggle once latency and correctness become non-negotiable.
When Unified Streaming + Analytics Platforms Make Sense
As streaming systems scale, many teams discover that separating stream processing from analytics introduces unnecessary latency, duplication, and operational overhead. Data is processed in one system, stored in another, and queried in a third—each boundary adding complexity.
In response, some teams adopt unified streaming and analytics platforms, where live data can be ingested, processed, and queried within the same system. This approach reduces data movement, simplifies operations, and enables faster feedback loops between ingestion, processing, and analysis.
Platforms like VeloDB are used in these scenarios to support real-time analytics on streaming data, particularly when low-latency queries and interactive exploration are required alongside continuous ingestion. The key advantage is not consolidation for its own sake, but tighter coupling between streaming computation and analytical decisioning.
People Also Ask About Streaming Analytics
What is streaming data analytics?
Streaming data analytics refers to analyzing unbounded streams of data in motion, such as events, logs, or sensor readings. It emphasizes continuous processing, stateful computation, and real-time outputs rather than retrospective analysis of static datasets.
What are examples of streaming analytics?
Common examples of streaming analytics include fraud detection, IoT and operational monitoring, real-time personalization, and automated alerting systems. In each case, the value of the data depends on reacting quickly, not on analyzing it after the fact.
When is micro-batch still enough?
Micro-batch processing is sufficient when seconds-level latency is acceptable and decisions do not depend on immediate reaction. For reporting, dashboards, and non-critical monitoring, micro-batch often provides a simpler and more cost-effective solution.
How is streaming analytics different from real-time analytics?
Streaming analytics focuses on continuous event processing and stateful computation over unbounded data streams. “Real-time analytics,” by contrast, is often used more loosely to describe low-latency querying, even when the underlying data is processed in batches.
Conclusion
Streaming analytics is not about processing data faster for its own sake. It exists because some decisions lose value the moment you delay them. When systems depend on what is happening right now, streaming analytics becomes a foundational capability—not a nice-to-have.
