


What is Parquet Format
1. Background
Apache Parquet is an open-source columnar storage format optimized for large-scale data processing and analytics. It's widely adopted across big data ecosystems, including Apache Hive, Spark, Doris, Trino, Presto, and many others.
As data volumes grow exponentially, traditional row-based storage formats (like CSV and JSON) are hitting performance and compression bottlenecks. Parquet was designed to address these challenges, making data analytics more efficient and cost-effective.
Parquet not only boosts query performance but also significantly reduces storage costs, making it a cornerstone of modern data lake and data warehouse architectures.
2. Why Do We Need Apache Parquet?
In the big data analytics space, traditional row-based storage formats like CSV and JSON face several pain points:
- Large scan volumes: Reading specific columns still requires loading entire rows
- Poor compression: Mixed data types across columns make efficient encoding difficult
- Low query performance: Lacks support for predicate pushdown and column pruning optimizations
- Unsuitable for OLAP queries: Clear bottlenecks in aggregation and filtering performance
Row Storage vs. Column Storage
Let's consider a user behavior log table:
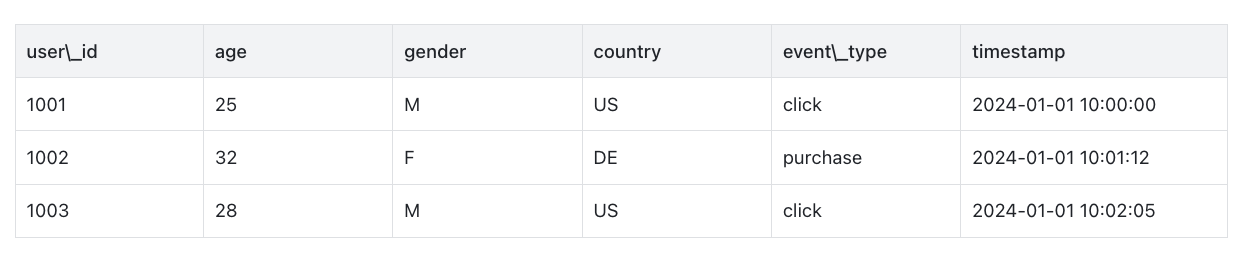
Row Storage (like CSV/JSON)
Data is written to disk row by row:
1001,25,M,US,click,2024-01-01 10:00:00
1002,32,F,DE,purchase,2024-01-01 10:01:12
1003,28,M,US,click,2024-01-01 10:02:05
If you only query event_type and timestamp, you still need to read entire rows (including irrelevant fields like user_id, age, gender). For millions of log entries, this creates serious I/O and memory waste.
Columnar Storage (like Parquet)
Data is stored separately by column:
user_idcolumn: [1001, 1002, 1003]agecolumn: [25, 32, 28]gendercolumn: [M, F, M]event_typecolumn: [click, purchase, click]timestampcolumn: [2024-01-01 10:00:00, ...]
Key advantages:

3. Parquet Architecture & Core Components
File Structure Hierarchy
1. File Footer
- Contains metadata for all Row Groups
- Includes schema and compression encoding information
- File reading typically starts from the footer to quickly obtain structural information
2. Row Group
- Basic unit of data in Parquet, each Row Group contains multiple records
- Row Groups can be read in parallel, facilitating distributed queries
3. Column Chunk
- Column-stored blocks within a Row Group
- One chunk per column, can be compressed/encoded independently
4. Page
- Smallest storage unit within column chunks
- Includes Data Pages, Dictionary Pages, etc.
Component Relationships Summary:
- One Parquet file ⟶ Multiple Row Groups
- Each Row Group ⟶ Multiple Column Chunks
- Each Column Chunk ⟶ Multiple Pages
4. Key Features and Capabilities
Efficient Columnar Storage
Parquet organizes data by columns rather than rows:
- Supports page-level compression (Snappy, Gzip, ZSTD, etc.)
- Can quickly skip irrelevant columns and non-matching data blocks (min/max, dictionary filtering, bloom filters, etc.)
- Ideal for big data OLAP query scenarios
Schema Evolution Support
- Can add new fields to existing Parquet tables without breaking old data
- Supports field reordering
- Field type changes (like INT → LONG) have certain compatibility (based on reader tolerance)
- Widely used in data lake scenarios for schema-on-read and schema evolution
Support for Complex and Nested Types
Parquet natively supports nested structures, including:
List,Map,Struct, and other nested types- JSON-like hierarchical data can be efficiently encoded
- Widely used for modeling semi-structured data like logs, events, and telemetry
Emerging Features: Variant and Geo Types
The Parquet community is actively advancing support for more complex data types to better accommodate semi-structured (JSON) data and geospatial information:
Variant Type
Variant is a variable-structure data type, similar to JSON's arbitrary hierarchical structure, designed to provide:
- Native support for structurally unknown or dynamic structure data
- No need to predefine schema, suitable for logs, telemetry, IoT, NoSQL data
- Improved reading efficiency for semi-structured data, more optimized than storing JSON blobs directly
- Collaboration with table formats like Iceberg, supporting schema projection and pruning
Example:
{
"event": "click",
"metadata": {
"browser": "Chrome",
"screen": {
"width": 1920,
"height": 1080
}
}
}
This structure can be directly written to Parquet as a Variant type field. Parquet automatically splits or reorganizes fields and stores them in columnar format, improving query efficiency. Currently, mainstream analytical engines like Snowflake, Doris, and Spark have introduced Variant data types to enhance analysis and storage capabilities for semi-structured data.
References:
Geo Types (GeoParquet)
Geospatial data (points, lines, polygons) is widely used in mapping analytics, LBS applications, and remote sensing. Traditional formats like Shapefile and GeoJSON aren't conducive to large-scale processing.
GeoParquet is an extension standard promoted by the Parquet community, supporting:
- Encoding geographic data (WKT/WKB/GeoJSON, etc.) as Parquet table fields
- Preserving spatial reference systems (CRS), coordinates, bounds, and other metadata
- Compatibility with GDAL, DuckDB, Spark, BigQuery Geo, and other tools
- Support for spatial indexing to accelerate queries (future direction)
- Avoiding fragmentation and format inconsistencies of traditional GIS files
Example fields:
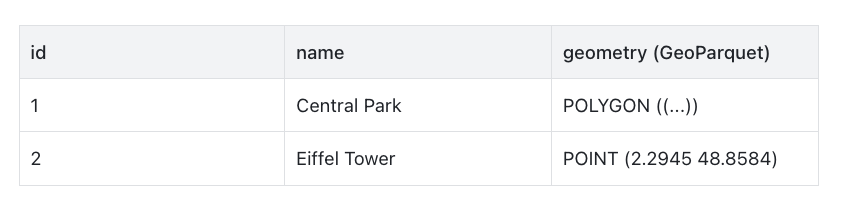
GeoParquet has released the v1.0 specification and is supported by multiple mainstream tools (like GDAL, DuckDB, Spark 3.5+), gradually becoming the standard format for large-scale spatial data processing.
5. Use Cases and Applications
Preferred Format in Data Lake and Data Lakehouse Architectures
In modern Data Lake and Lakehouse architectures, Parquet is widely adopted as the underlying storage format for several reasons:
- Efficient columnar storage and compression: Parquet's columnar structure only reads required columns, helping reduce I/O; combined with compression schemes like Snappy, Gzip, ZSTD, it greatly saves cloud storage costs, particularly suitable for massive data operational environments.
- Predicate pushdown and partition pruning: Parquet files store column statistics (like min/max, dictionary/bloom filters), allowing query engines to skip irrelevant files or row groups, improving query efficiency.
- Schema evolution and complex type support: Parquet can adapt to added or changed fields while supporting nested structures (Lists, Structs, Maps, etc.), smoothly handling data model changes across different stages.
- Broad ecosystem compatibility: Mainstream compute engines like Apache Spark, Hive, Flink, Presto, Dremio, Trino natively support Parquet. Whether for batch processing or interactive queries, they provide seamless integration experience.
These advantages make Parquet the bottom-layer storage format for many data lake table formats (like Iceberg, Delta Lake, Hudi): these formats add a layer of transaction, snapshot, and metadata management on top of Parquet files, implementing ACID properties, time travel, version control, and other features.
Raw and Analytics Layer Storage in Data Lakes
In modern data lake architectures, data is typically organized into multiple layers (like raw layer, cleansing layer, analytics layer, etc.) to meet different data management and analytics needs. Apache Parquet plays a crucial role in these layers, especially becoming the de facto standard in intermediate processing layers and analytics layers.
Raw Layer
- Data typically lands as-is in JSON, CSV, Avro, or log formats
- Convenient for preserving original data snapshots for backtracking
- But has poor read performance, large space consumption, and lacks structured capabilities
- Direct use of Parquet is generally not recommended at this layer due to unstable or completely unknown schemas
Staging / Refined Layer
- After data cleansing and parsing, structure becomes relatively stable
- Commonly transforms semi-structured raw data into structured table formats
- Parquet is the preferred format for this layer for reasons including:
- Good integration with streaming/batch compute frameworks like Spark/Flink
- High compression ratio, saving storage
- Clear structure, supports schema evolution
- Suitable for subsequent dimensional modeling or downstream lake queries
Query / BI Layer
- Oriented toward query services, reporting systems, AI/ML feature extraction, etc.
- Usually data that has been modeled (like star schema, wide tables)
- Parquet provides extremely fast query performance, especially combined with:
- Column pruning + predicate pushdown
- Metadata acceleration
- Incremental reading and snapshot access based on table formats (like Iceberg, Delta)
- Can be directly read/written by Apache Doris, Trino, Presto, ClickHouse, BigQuery, and other engines without import
Summary Overview

6. Practical Examples
-
Creating Parquet format Iceberg tables in Doris
CREATE TABLE partition_table ( `ts` DATETIME COMMENT 'ts', `col1` BOOLEAN COMMENT 'col1', `col2` INT COMMENT 'col2', `col3` BIGINT COMMENT 'col3', `pt1` STRING COMMENT 'pt1', `pt2` STRING COMMENT 'pt2' ) PARTITION BY LIST (day(ts), pt1, pt2) () PROPERTIES ( 'write-format'='parquet' );
Reference: Iceberg Catalog
-
Reading Parquet format data in Doris
SELECT * FROM S3 ( 'uri' = 's3://bucket/path/to/tvf_test/test.parquet', 'format' = 'parquet', 's3.endpoint' = 'https://s3.us-east-1.amazonaws.com', 's3.region' = 'us-east-1', 's3.access_key' = 'ak', 's3.secret_key'='sk' ); -
Exporting data to Parquet format in Doris
SELECT k1 FROM tbl1 UNION SELECT k2 FROM tbl1 INTO OUTFILE "s3://bucket/result_" FORMAT AS PARQUET PROPERTIES ( 's3.endpoint' = 'https://s3.us-east-1.amazonaws.com', 's3.region' = 'us-east-1', 's3.access_key' = 'ak', 's3.secret_key'='sk' )
7. Key Takeaways
- Apache Parquet is a columnar storage format ideal for analytical queries.
- Excellent compression performance, saves storage space.
- Seamless integration with Spark, Hive**, Doris, and other ecosystems.**
- Supports complex nested types with strong compatibility.
- One of the standard formats for modern data lakes and OLAP systems.
8. FAQ
-
Q: What's the difference between Parquet and ORC?
- A: Both are columnar formats. Parquet is more widely used in Spark, Doris, and other ecosystems, while ORC is more common in Hive/Presto.
-
Q: Does Parquet support row updates?
- A: Not natively. Requires combination with table formats like Iceberg, Delta to implement ACID updates.
-
Q: How does Parquet compare to Avro/JSON?
- A: JSON is a row-based text format suitable for small data; Avro focuses on serialization, while Parquet is better suited for analytical queries.

{kind=link}