


What is Apache Iceberg
Apache Iceberg is an open-source large-scale analytical table format initiated by Netflix and donated to Apache, designed to address the limitations of traditional Hive table formats in consistency, performance, and metadata management. In today's lakehouse architectures with multi-engine concurrent access and frequent schema evolution, Iceberg provides ACID transactions, hidden partitioning, time travel capabilities, making it highly sought after.
1. Why Apache Iceberg is Needed
Traditional Hive table formats face the following challenges:
- Performance bottlenecks: Directory scanning is time-consuming and cannot efficiently implement file-level pruning.
- Weak consistency: Cannot support transaction isolation for multi-engine concurrent read/write operations.
- Difficult schema and partition changes: Changes often require table rebuilding or data migration, which is complex and time-consuming.
Iceberg brings revolutionary improvements:
- Utilizes metadata + manifest for file-level filtering, optimizing query efficiency.
- Provides ACID transactions and snapshot isolation, ensuring safe multi-engine collaborative writing.
- Supports schema evolution and partition evolution without rewriting underlying data for flexible changes.
2. Apache Iceberg Architecture and Core Components
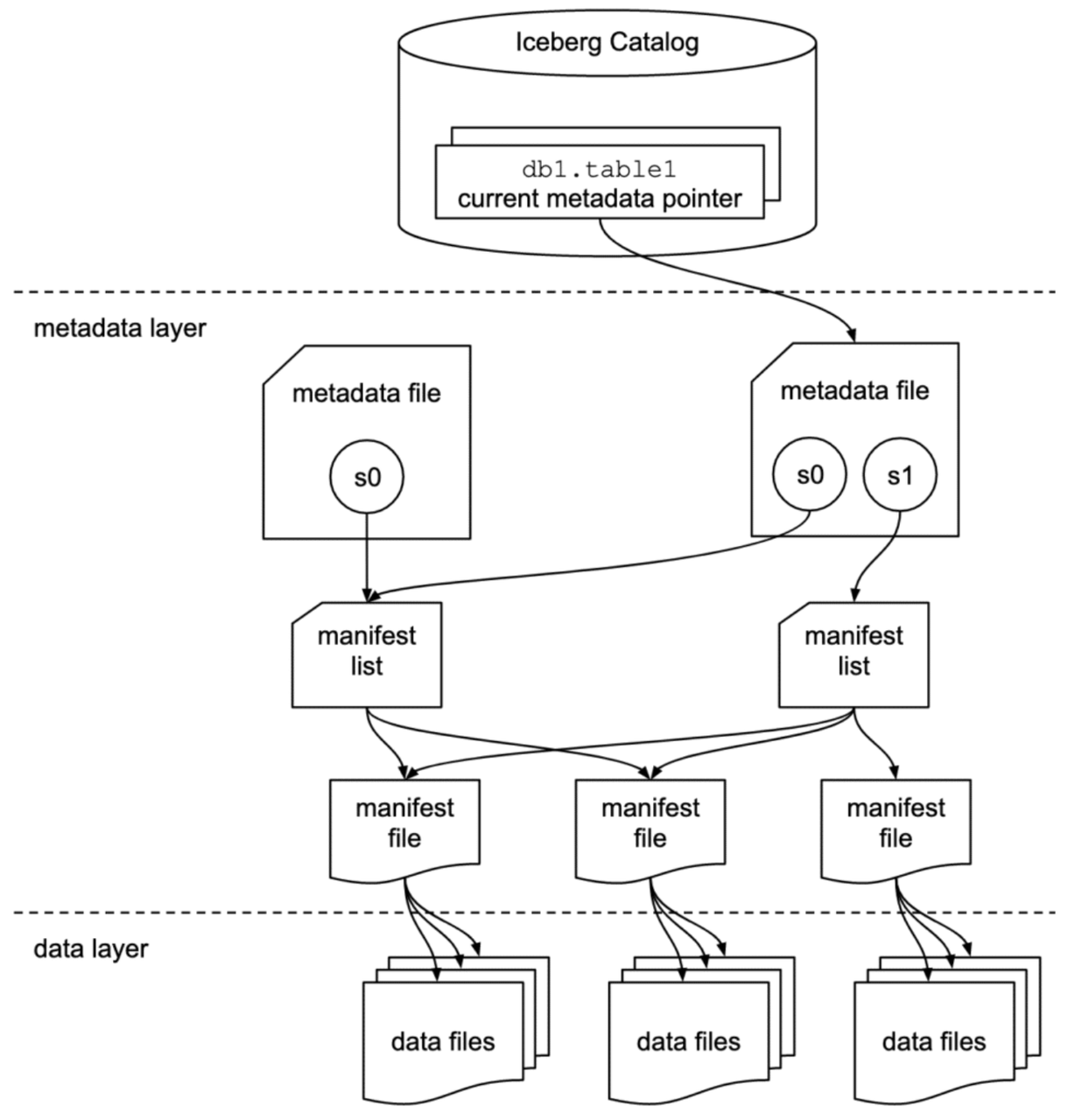
The diagram above shows the overall architecture of Iceberg tables, including the following three major levels and key components:
Catalog Layer
- Definition: Used to store the current metadata file pointer for each table.
- Function: Supports atomic updates of metadata pointers, ensuring transaction consistency. You can choose Hive Metastore, AWS Glue, Nessie, or Hadoop FS as the Catalog.
- Relationship with other components: Queries first access the Catalog to obtain the latest metadata file path.
Iceberg REST Catalog
Iceberg defines a Catalog implementation provided through HTTP REST API, compliant with the Iceberg OpenAPI specification. Typical products include Apache Polaris, Gravitino, Tabular, and Unity Catalog.
IRC brings the following advantages:
- Lightweight client, only requires HTTP calls;
- Server can use any language to implement abstraction and governance logic;
- Easier support for multi-language, multi-engine Catalog access, reducing deployment complexity ([Tabular][1], [ApacheCon][5]);
- Supports view management (such as
/viewsinterface), unified metadata access, suitable for data governance ([Medium][6]).
Compared to HiveCatalog and GlueCatalog, this approach moves "atomicity, schema management, transaction conflict handling" and other logic down to a dedicated service layer, allowing clients to focus more on query planning.
Metadata Layer
Includes the following components:
- Metadata file: JSON format, contains table schema, partition spec, current/historical snapshot lists; points to manifest list. New metadata files are generated after changes.
- Manifest list: Avro format, lists all manifest file paths and summary information under a snapshot.
- Manifest file: Avro format, lists specific data file and delete file paths, partition values, and statistical information (such as min/max) to assist with pruning optimization.
Data Layer
- Stores data files in Parquet/ORC/Avro formats, as well as delete files for soft deletion (positional/equality/delta vectors).
- Tightly integrated with physical storage such as HDFS, Amazon S3, Azure ADLS, GCS.
3. Key Features and Capabilities
ACID Transactions
Supports atomicity, consistency, isolation, and durability, using optimistic concurrency control, suitable for multi-user concurrent write scenarios.
Schema Evolution
Supports adding, deleting, renaming, type widening, column reordering operations without rewriting data, executed based on metadata changes.
Partition Evolution + Hidden Partitioning
- After Partition Spec updates: Old data retains old layout, new writes use new layout, queries can automatically prune across multiple specs.
- Hidden partitioning: Queries don't need to specify additional partition columns, Iceberg automatically identifies and skips irrelevant files.
Time Travel and Rollback
Query historical table states through snapshot ID or timestamp. Error rollback, auditing, and data reproduction become more convenient.
Data Compaction
Supports bin-packing and sorting rewrite strategies to achieve file packing and organization, optimizing query efficiency and storage usage.
Iceberg V2 and V3
As Iceberg continues to evolve, format versions are also continuously upgraded to meet the complex needs of modern data scenarios. V2 introduced row-level deletion (delete files) to support incremental updates, while V3 builds upon this foundation with more efficient deletion mechanisms, row-level lineage, diversified data types, significantly expanding Iceberg's application boundaries in real-time analytics, audit tracking, and semi-structured data processing. Here's a detailed comparison of V2 and V3 formats across key dimensions:
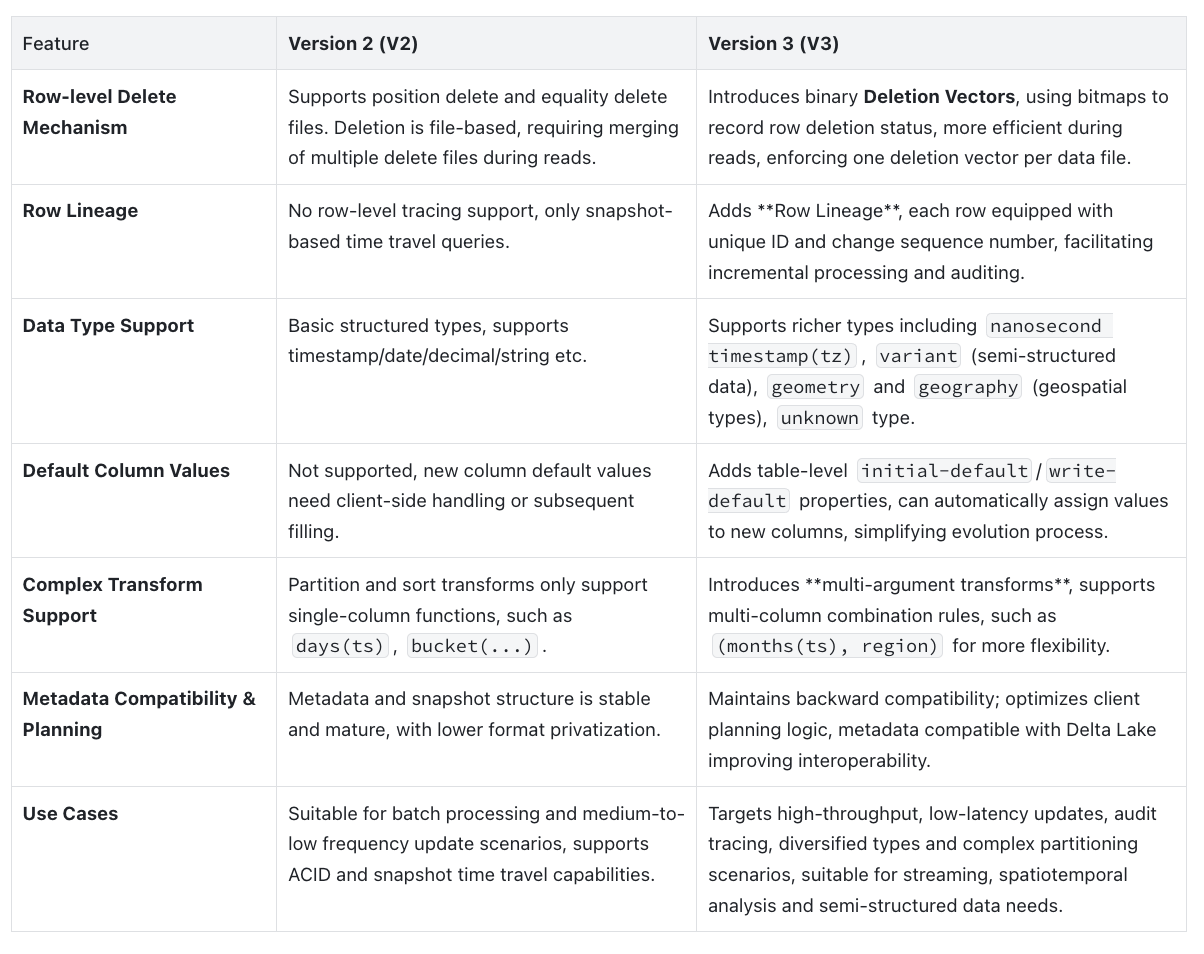
Summary:
- V2 introduced row-level deletion mechanisms, enabling "near real-time" data updates;
- V3 upgrades the deletion mechanism to efficient deletion vectors and supports row-level lineage;
- V3 also significantly enhances data type handling and schema evolution capabilities, making Iceberg more suitable for diverse modern data scenarios.
Below is a new section comparing Apache Iceberg with other mainstream lakehouse formats (Apache Hudi, Delta Lake, Apache Paimon), showing their differences in core functionality and applicable scenarios through tabular format.
Iceberg vs Other Lakehouse Formats: Hudi / Delta Lake / Paimon
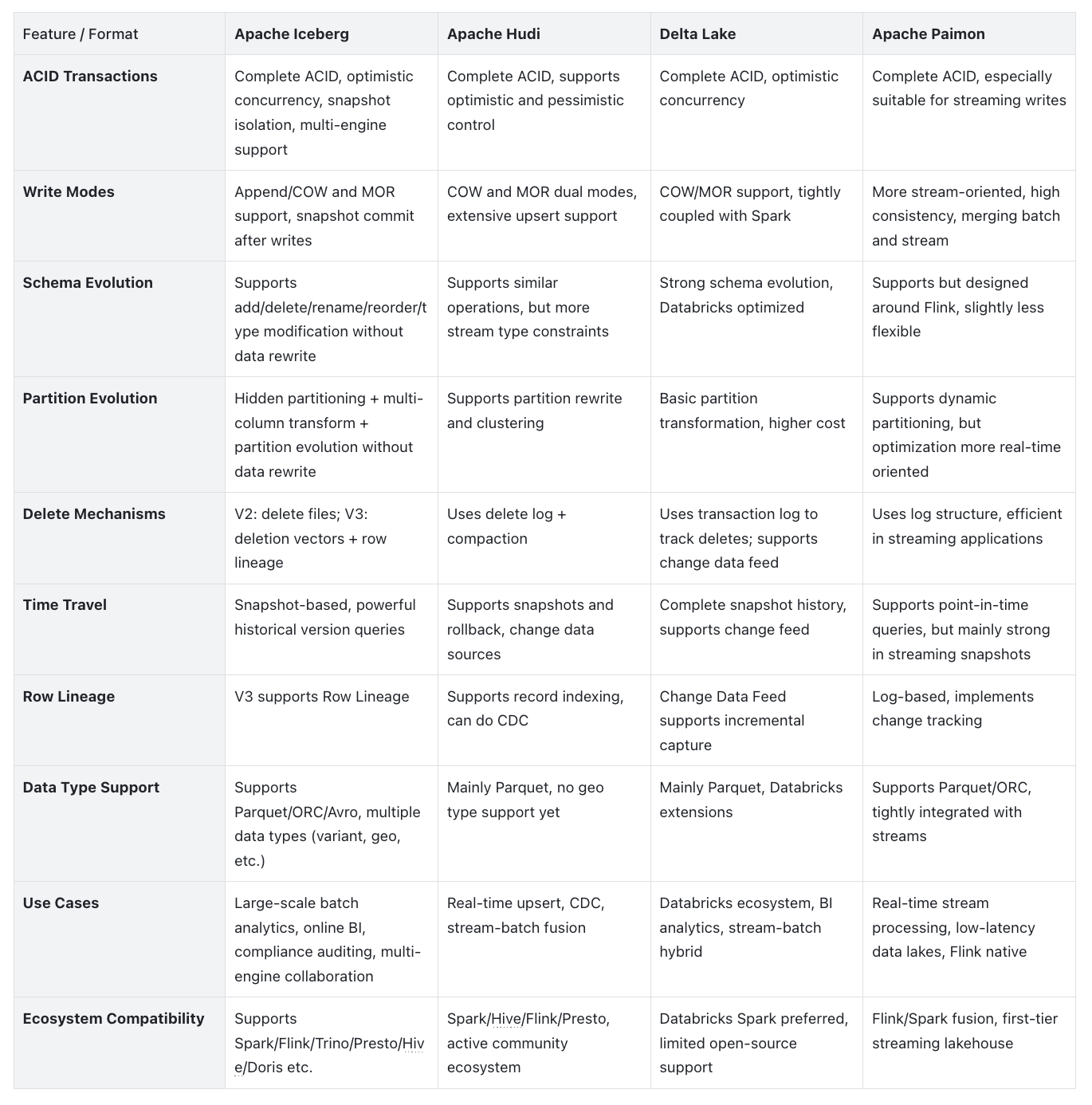
Summary:
- Iceberg focuses on large-scale analytics scenarios with superior multi-engine compatibility, transaction and query performance.
- Hudi excels at real-time upsert and stream-batch merging, suitable for real-time cleaning/writing scenarios.
- Delta Lake is deeply coupled with Databricks, suitable for Spark-heavy and ADLS/S3-based BI architectures.
- Paimon targets Flink-native streaming scenarios, emphasizing low latency and stream-batch fusion.
4. Use Cases
1. Building High-Availability Lakehouse Data Platforms
In traditional data lakes using Hive table formats, directory scanning and metadata synchronization often become performance bottlenecks. Large companies like Airbnb, after migrating from HDFS to S3, improved metadata scheduling efficiency through Iceberg, reduced pressure on Hive Metastore, achieving 50% compute resource savings and 40% reduction in data ingestion task duration ([upsolver.com][1]).
2. Multi-Engine Collaboration and Data Platform Integration
Iceberg is a truly open, vendor lock-in free table format that supports engines like Spark, Flink, Trino, Presto, Hive, Impala, Doris sharing the same tables.
For example, data scientists can train models using Python/ML tools, while BI teams run SQL analytics, all efficiently collaborating on the same Iceberg tables.
3. Compliance Governance and Data Auditing
In scenarios with strict regulatory requirements (such as GDPR, financial auditing), Iceberg's Time Travel + DELETE operations can be used to precisely delete sensitive data and audit change history. For example, establishing compliance pipelines to delete certain columns or records according to regulatory requests while maintaining complete snapshots for subsequent review.
5. Practical Examples
The following examples demonstrate workflows for operating Iceberg tables using Spark and Doris:
Apache Spark
-- Configure Spark to use Hive Metastore as Iceberg catalog
SET spark.sql.catalog.spark_catalog=org.apache.iceberg.spark.SparkSessionCatalog;
-- Create table
CREATE TABLE spark_catalog.db1.logs (
id BIGINT,
ts TIMESTAMP,
level STRING
)
USING iceberg
PARTITIONED BY (days(ts));
-- Insert data
INSERT INTO db1.logs VALUES
(1, TIMESTAMP '2025-07-01 12:00:00', 'INFO'),
(2, TIMESTAMP '2025-07-01 13:00:00', 'ERROR');
-- Time travel query
SELECT * FROM db1.logs FOR TIMESTAMP AS OF TIMESTAMP '2025-07-01 12:30:00';
Apache Doris
-- Create catalog
CREATE CATALOG iceberg_catalog PROPERTIES (
'type' = 'iceberg',
'iceberg.catalog.type' = 'rest',
'warehouse' = 's3://warehouse/',
'uri' = 'http://rest:8181',
's3.access_key' = 'admin',
's3.secret_key' = 'password',
's3.endpoint' = 'http://minio:9000'
);
-- Switch to catalog and create database
SWITCH iceberg_catalog;
CREATE DATABASE nyc;
-- Create table
CREATE TABLE iceberg.nyc.taxis (
vendor_id BIGINT,
trip_id BIGINT,
trip_distance FLOAT,
fare_amount DOUBLE,
store_and_fwd_flag STRING,
ts DATETIME
)
PARTITION BY LIST (vendor_id, DAY(ts))
PROPERTIES (
'compression-codec' = 'zstd',
'write-format' = 'parquet'
);
-- Insert data
INSERT INTO iceberg.nyc.taxis VALUES
(1, 1000371, 1.8, 15.32, 'N', '2024-01-01 09:15:23'),
(2, 1000372, 2.5, 22.15, 'N', '2024-01-02 12:10:11');
-- Query
SELECT * FROM iceberg.nyc.taxis;
-- View snapshots
SELECT * FROM iceberg.nyc.taxis$snapshots;
-- Time travel
SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 6834769222601914216;
Through Spark + Doris, you can implement a unified lakehouse architecture with Iceberg: Spark handles ETL + batch processing, Doris handles interactive query analytics. Both share Iceberg tables based on the same metadata, compatible with schema evolution, time travel, secure transactions, and other capabilities. One dataset, multi-engine efficient access, easily handling complex analytics scenarios.
6. Key Takeaways
- Iceberg is a modern table format specification that supports ACID, schema/partition evolution, and time travel.
- It implements efficient file-level pruning and transaction isolation through metadata layer and manifest mechanisms.
- Supports multi-engine shared tables (Spark, Flink, Trino, Hive, Impala, Doris, etc.)
- Excellent query performance with flexible change operations and no data migration overhead.
- Suitable for cloud data lakes, large-scale analytics scenarios, and long-term data governance.
7. FAQ
Q1: Is Iceberg suitable for real-time data processing?
A1: Iceberg is essentially a data table format oriented towards large-scale batch analytics, supporting snapshot isolation, schema evolution, and time travel, suitable for batch processing, ETL, and analytical workloads. However, for real-time writes (such as high-frequency row-by-row updates), it generates delete files or frequent metadata file writes, causing performance and metadata bloat issues. In such scenarios, regular compaction optimization is usually needed, otherwise small-scale frequent write performance degrades significantly.
Q2: Which engines can access Iceberg?
A2: Iceberg is a truly open-source standard table format with broad support across multiple engines: including Spark, Flink, Trino (Presto), Hive, Impala, Dremio, StarRocks, Doris, Snowflake, AWS Athena, Google BigQuery, DuckDB, etc. Specific feature support varies by engine - Spark and Flink have complete write & schema evolution capabilities, while some lightweight query engines (like DuckDB or ClickHouse) only support reading with incomplete delete functionality.
Q3: Can Iceberg completely replace Hive ?
A3: Iceberg can replace Hive's table format and metadata functionality, especially when using Iceberg catalog (such as REST Catalog), no longer depending on Hive Metastore. However, the Hive engine still has many integration scenarios, such as security management, permission control frameworks (Ranger/Atlas), and Tez/MapReduce backend execution features, which Iceberg itself doesn't provide.
If your goal is to replace traditional Hive table structures and migrate to more modern lakehouse architectures, Iceberg is worth adopting, but Hive as an execution engine or governance component still has value.
Q4: Why does Iceberg improve query performance?
A4: Iceberg's query performance improvements are mainly due to the following mechanisms:
- Multi-level metadata filtering (manifest list + manifest files), which can use partition value ranges and column statistical information to quickly prune irrelevant data files before queries, avoiding full table scans.
- Scan planning can be completed on a single node, without distributed coordination, achieving low-latency planning phases.
- Supports sorted compaction / z-order arrangement (such as AWS Glue support) to improve query hit rates and reduce the number of scanned files.
8. Additional Resources and CTA
Official Documentation and Tutorials
- Apache Iceberg Official Documentation
- Mastering Apache Iceberg for Scalable Data Lake Management (DigitalOcean)
- Doris Iceberg Catalog
Practice and Best Practices Guides
- Using Doris & Iceberg
- Iceberg, Right Ahead! 7 Apache Iceberg Best Practices for Smooth Data Sailing (Monte Carlo Data)
- Apache Iceberg 101 – Your Guide to Learning Apache Iceberg Concepts and Practices (Dremio)
- Apache Iceberg: The Definitive Guide
Tutorial Series and Beginner-Friendly Resources
- Ultimate Directory of Apache Iceberg Resources
- Iceberg Tables: Comprehensive Guide to Features, Benefits, and Best Practices
