


1. What is Apache ORC
Apache ORC (Optimized Row Columnar) is an open-source columnar storage format optimized for large-scale data storage and analytics. Developed by Hortonworks in 2013, it has become an Apache top-level project and is widely used in big data ecosystems including Apache Hive, Spark, Presto, Trino, and more.
As the native storage format for the Hive ecosystem, ORC has deep roots in the Hadoop ecosystem. It inherits the advantages of RCFile while making significant improvements in compression efficiency, query performance, and storage optimization, making it a crucial choice for enterprise-grade data warehouses.
ORC not only provides excellent compression ratios and query performance but also includes rich built-in statistics and indexing mechanisms, making it one of the core storage formats in modern data lake and data warehouse architectures.
2. Why Apache ORC is Needed
In the big data processing domain, traditional row storage formats have numerous limitations, and ORC's design goals are specifically to address these issues:
- Low storage efficiency: Traditional formats have poor compression ratios, leading to high storage costs
- Query performance bottlenecks: Unable to effectively leverage columnar storage advantages for query optimization
- Lack of intelligent indexing: No built-in statistics and indexing mechanisms
- Insufficient ACID support: Lack of transaction-level data consistency guarantees
Row Storage vs Columnar Storage ORC Optimization
Consider a sales data table:

Traditional Row Storage Issues
1001,C001,Laptop,999.0,1,2024-01-01 09:30:00
1002,C002,Mouse,25.5,2,2024-01-01 10:15:30
1003,C001,Keyboard,89.9,1,2024-01-01 11:22:45
When executing queries like SELECT SUM(price) FROM sales WHERE order_date > '2024-01-01', you must read entire rows of data, including unnecessary fields like customer_id, product_name, etc.
ORC Columnar Storage Advantages
ORC organizes data by columns:
order_idcolumn: [1001, 1002, 1003]pricecolumn: [999.0, 25.5, 89.9]order_datecolumn: [2024-01-01 09:30:00, ...]

3. ORC Architecture and Core Components
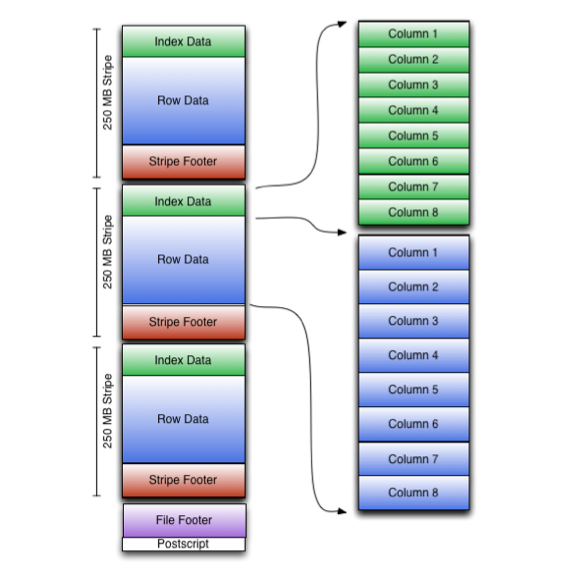
File Structure Hierarchy
1. File Footer
- Contains file metadata information such as schema, compression types, statistics, etc.
- Stores location and size information for all Stripes
- File reading starts from the Footer to quickly obtain file structure
2. Stripe
- Basic storage unit of ORC files, similar to Parquet's Row Group
- Default size is 64MB, configurable
- Each Stripe contains multiple rows of data, supports parallel reading
3. Column Data
- Column-stored data blocks within Stripes
- Each column is independently compressed and encoded
- Supports multiple encoding methods: dictionary encoding, RLE, Delta encoding, etc.
4. Index Data
- Contains Row Group Index and Bloom Filter
- Provides fine-grained data filtering capabilities
- Supports skipping unnecessary data block reads
Component Relationship Summary:
- One ORC File → Multiple Stripes
- Each Stripe → Multiple Column Data + Index Data
- Each Column Data → Multiple Row Groups (default 10,000 rows)
4. Key Features & Characteristics
Efficient Columnar Storage and Compression
ORC employs advanced compression and encoding techniques:
- Multi-level compression: Supports ZLIB, Snappy, LZ4, ZSTD compression algorithms
- Smart encoding: Dictionary encoding, Run Length Encoding (RLE), Delta encoding, bit packing, etc.
- Adaptive compression: Automatically selects optimal encoding based on data characteristics
- Excellent compression ratio: Typically saves 75%+ storage space compared to uncompressed text formats
ACID Transaction Support
ORC is the foundation for Hive ACID features:
- Atomicity: Supports transaction-level data writes
- Consistency: Ensures consistent data states
- Isolation: Supports Multi-Version Concurrency Control (MVCC)
- Durability: Ensures persistence of committed transactions
Built-in Statistics and Indexing
ORC files include rich built-in statistics:
- Column statistics: min/max values, null counts, distinct value estimates
- Bloom Filter: Quick determination of value existence, reducing unnecessary disk reads
- Row Group Index: Creates indexes every 10,000 rows, supports fast skipping
- Predicate Pushdown: Push filter conditions down to the storage layer
Schema Evolution Support
- Add columns: Can add new columns at the end of files without affecting existing data
- Remove columns: Ignore unnecessary columns through schema projection
- Rename columns: Support column name changes (through position mapping)
- Type promotion: Support compatible type conversions (e.g., INT → BIGINT)
5. Use Cases / Application Scenarios
Enterprise Data Warehouses
ORC has significant advantages in enterprise data warehouses:
- Deep Hive ecosystem integration: As Hive's default storage format, seamlessly works with Hive MetaStore and HiveQL
- Enterprise-grade features: Supports ACID transactions, row-level updates/deletes, meeting traditional data warehouse requirements
- High compression ratio: Significantly reduces storage costs, especially suitable for long-term data archiving
- Mature and stable: Long-term validation in Hadoop ecosystem, lower enterprise adoption risk
Batch Processing ETL Scenarios
In large-scale ETL processing, ORC provides excellent performance:
- High-throughput writes: Optimized write paths supporting large batch data imports
- Incremental updates: Combined with Hive ACID, supports INSERT, UPDATE, DELETE operations
- Partition support: Perfect integration with Hive partitioned tables, supports partition pruning optimization
- Compressed transmission: Reduces network transmission overhead, accelerates distributed computing
OLAP Analytical Queries
ORC's design is specifically optimized for analytical queries:
- Column pruning: Only read columns involved in queries, significantly reducing I/O
- Predicate pushdown: Utilize statistics and Bloom Filters for fast data filtering
- Vectorized execution: Support SIMD instructions, improving CPU utilization
- Parallel reading: Stripe-level parallel processing, fully utilizing multi-core resources
Integration with Table Formats
While ORC is powerful on its own, in modern data lake architectures, it's often combined with table formats:

6. Practical Examples
Reading ORC Format Data in Doris
SELECT * FROM S3 (
'uri' = 's3://bucket/path/to/data.orc',
'format' = 'orc',
's3.endpoint' = 'https://s3.us-east-1.amazonaws.com',
's3.region' = 'us-east-1',
's3.access_key' = 'ak',
's3.secret_key' = 'sk'
);
Exporting Data as ORC Format in Doris
SELECT customer_id, SUM(amount) as total_amount
FROM orders
WHERE order_date >= '2024-01-01'
GROUP BY customer_id
INTO OUTFILE "s3://bucket/result_"
FORMAT AS ORC
PROPERTIES (
's3.endpoint' = 'https://s3.us-east-1.amazonaws.com',
's3.region' = 'us-east-1',
's3.access_key' = 'ak',
's3.secret_key' = 'sk',
'orc.compress' = 'ZSTD'
);
Creating ORC Tables in Hive
CREATE TABLE sales_orc (
order_id BIGINT,
customer_id STRING,
product_name STRING,
price DECIMAL(10,2),
quantity INT,
order_date TIMESTAMP
)
STORED AS ORC
TBLPROPERTIES (
'orc.compress'='ZLIB',
'orc.bloom.filter.columns'='customer_id,product_name'
);
Enabling ACID Transaction Support
-- Enable Hive ACID transactions
SET hive.support.concurrency=true;
SET hive.enforce.bucketing=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
SET hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
-- Create ACID-enabled ORC table
CREATE TABLE sales_acid (
order_id BIGINT,
customer_id STRING,
amount DECIMAL(10,2),
order_date DATE
)
CLUSTERED BY (order_id) INTO 10 BUCKETS
STORED AS ORC
TBLPROPERTIES ('transactional'='true');
7. Key Takeaways
- Apache ORC is a columnar storage format optimized specifically for the Hadoop ecosystem
- Provides excellent compression ratios and query performance
- Built-in rich statistics and indexing mechanisms
- Native ACID transaction support, suitable for enterprise data warehouses
- Deep integration with Hive ecosystem, mature and stable
- Excellent performance in batch ETL and OLAP analytical scenarios
8. FAQ
Q: What are the differences between ORC and Parquet?
A: Both are columnar formats, but they have different strengths:
- ORC: Better support in Hive ecosystem, built-in ACID transactions, higher compression ratios
- Parquet: Broader ecosystem, better Spark integration, stronger cross-platform compatibility
Q: Does ORC support nested data types?
A: Yes, ORC supports complex data types including:
- STRUCT (structures)
- ARRAY (arrays)
- MAP (mappings)
- UNION (union types)
Q: How to choose ORC compression algorithms?
A: Recommendations based on scenarios:
- ZLIB: Balanced compression ratio and speed, default choice
- Snappy: Fast compression/decompression speed, medium compression ratio
- LZ4: Extremely fast decompression speed, suitable for frequently accessed data
- ZSTD: Best compression ratio, suitable for archived data
Q: Are ORC files compatible across different versions?
A: ORC is backward compatible; newer versions can read older version files. However, it's recommended to:
- Maintain ORC version consistency
- Use schema evolution features for structural changes
- Test compatibility in production environments
