


What is Paimon
Apache Paimon is a high-performance streaming-batch unified table format and data lake storage system designed specifically for real-time data processing. It supports transactions, consistent views, incremental read/write operations, and schema evolution, providing essential capabilities required by modern data lake architectures.
With the increasing demands for real-time analytics, stream processing, and unified data lake storage, traditional data formats that only support batch processing or weak streaming capabilities (such as Parquet and ORC) can no longer meet the requirements of modern data infrastructure. Apache Paimon provides a novel lake storage format that helps enterprises efficiently manage large-scale, high-frequency data changes.
1. Why Apache Paimon is Needed
In traditional data lake scenarios, users often face the following challenges:
- Difficult Incremental Data Processing: Solutions like Hive+Parquet lack native incremental read/write capabilities.
- Data Consistency Challenges: Write processes are prone to read-write conflicts and lack transactional guarantees.
- Insufficient Real-time Update Support: Unable to quickly reflect data changes, resulting in high latency.
- Complex Maintenance: Dependent on external tools for version management, data cleanup, schema compatibility, and more.
Apache Paimon effectively addresses these pain points by introducing table format metadata management, supporting unified streaming-batch read/write interfaces, native incremental reading capabilities, and ACID semantics, making it possible to build real-time data applications on the lake.
2. Apache Paimon Architecture and Core Components
Apache Paimon adopts a table format design philosophy and combines high-performance storage engines for data management. Its core architecture is illustrated in the following diagram:
Core Component Analysis
1. File Store
- Definition: Responsible for organizing and storing underlying data files.
- Functionality: Uses columnar storage (Parquet) or row-based storage (Avro) to persist data.
- Relationship: All written data is persisted to the File Store for consumption by readers.
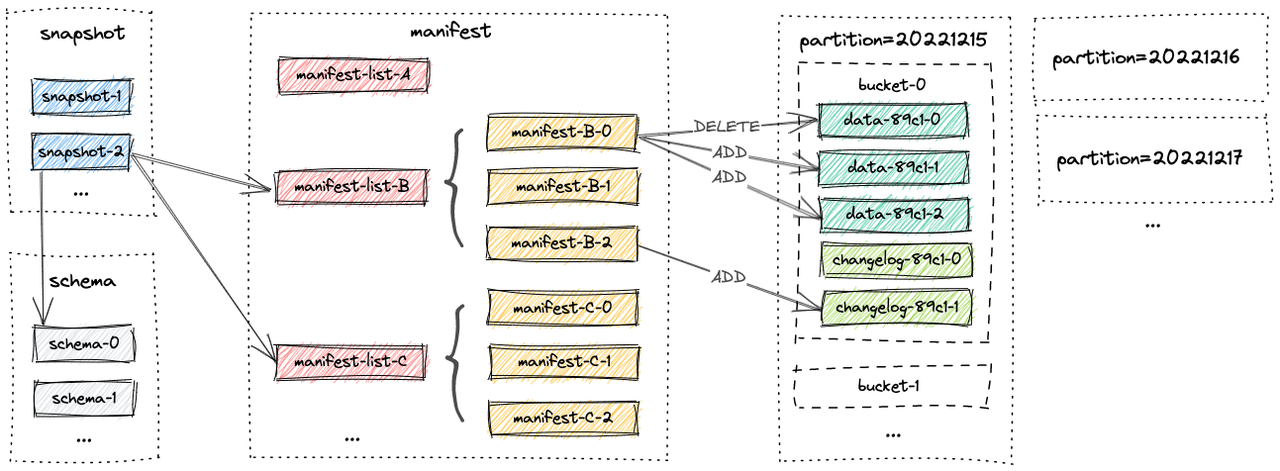
2. Snapshot and Manifest
- Definition: A metadata system that maintains data change history.
- Functionality: Each write operation generates a snapshot that records file information (manifest) for this change.
- Relationship: Supports snapshot reading, time travel, and other features to ensure consistent views.
3. Schema Management
- Definition: A version management module for table structures.
- Functionality: Supports schema evolution, including field additions, renames, type modifications, etc.
- Relationship: Ensures compatibility between new and legacy data.
4. Streaming Coordinator
- Definition: Coordinates data merging and commit mechanisms for streaming writes.
- Functionality: Implements streaming data compaction, merge-on-write, update deduplication capabilities.
- Relationship: Works with stream processing engines like Flink to ensure end-to-end consistency.
5. Catalog System
- Definition: Used for unified metadata management across multiple tables.
- Functionality: Provides compatible interfaces for engines like Hive, Flink, and Spark.
- Relationship: Simplifies multi-engine access and sharing.
Paimon REST Catalog
Starting from version 1.x, Apache Paimon supports a lightweight REST Catalog for managing metadata directories through REST APIs. Its main features and functions include:
- Decoupled Metadata Storage
REST Catalog forwards metadata operations to remote Catalog services via HTTP protocol, achieving separation from underlying storage and supporting independent deployment and scaling.
- Language and Platform Agnostic
The metadata directory server can be implemented in any language, requiring only compliance with REST interface definitions. Clients perform DDL synchronization and table structure management through HTTP calls.
- Multiple Authentication Modes
REST Catalog supports various Token provider mechanisms, including Bear Token, Alibaba Cloud DLF authentication, STS temporary tokens, etc., adapting to different scenarios.
-
SQL Usage Example (Spark)
-- Configure Spark to use REST Catalog --conf spark.sql.catalog.paimon=org.apache.paimon.spark.SparkCatalog \ --conf spark.sql.catalog.paimon.metastore=rest \ --conf spark.sql.catalog.paimon.uri=<catalog server url> \ --conf spark.sql.catalog.paimon.token.provider=bear \ --conf spark.sql.catalog.paimon.token=<bear-token> USE paimon.default; CREATE TABLE ... ;
3. Key Features and Capabilities
ACID Transaction Support
- Supports atomic writes, snapshot isolation, and repeatable reads to ensure data consistency.
- Particularly suitable for high-concurrency write and update scenarios.
Unified Streaming-Batch Read/Write Interface
- Supports streaming writes, batch imports, and incremental reads for Flink and Spark.
- Can be used for real-time data ingestion, change data capture (CDC), and streaming data processing.
Native Incremental Reading
-
Supports snapshot-based incremental pulling without depending on log systems or full table comparisons.
-
Examples:
-- Flink SQL SELECT * FROM orders /*+ OPTIONS('scan.mode'='incremental') */; -- Doris SQL SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5', 'incrementalBetweenScanMode'='diff');
Schema Evolution
- Dynamically supports field additions, renames, type changes, etc., without rewriting historical data.
- Configuration example:
-- Flink SQL ALTER TABLE user_info ADD COLUMN city STRING;
Multi-Engine Compatibility
- Supports mainstream compute engines including Flink, Spark, Trino, Presto, Doris, and more.
- Provides unified catalog interfaces.
Feature Comparison: Apache Paimon vs Iceberg vs Hudi
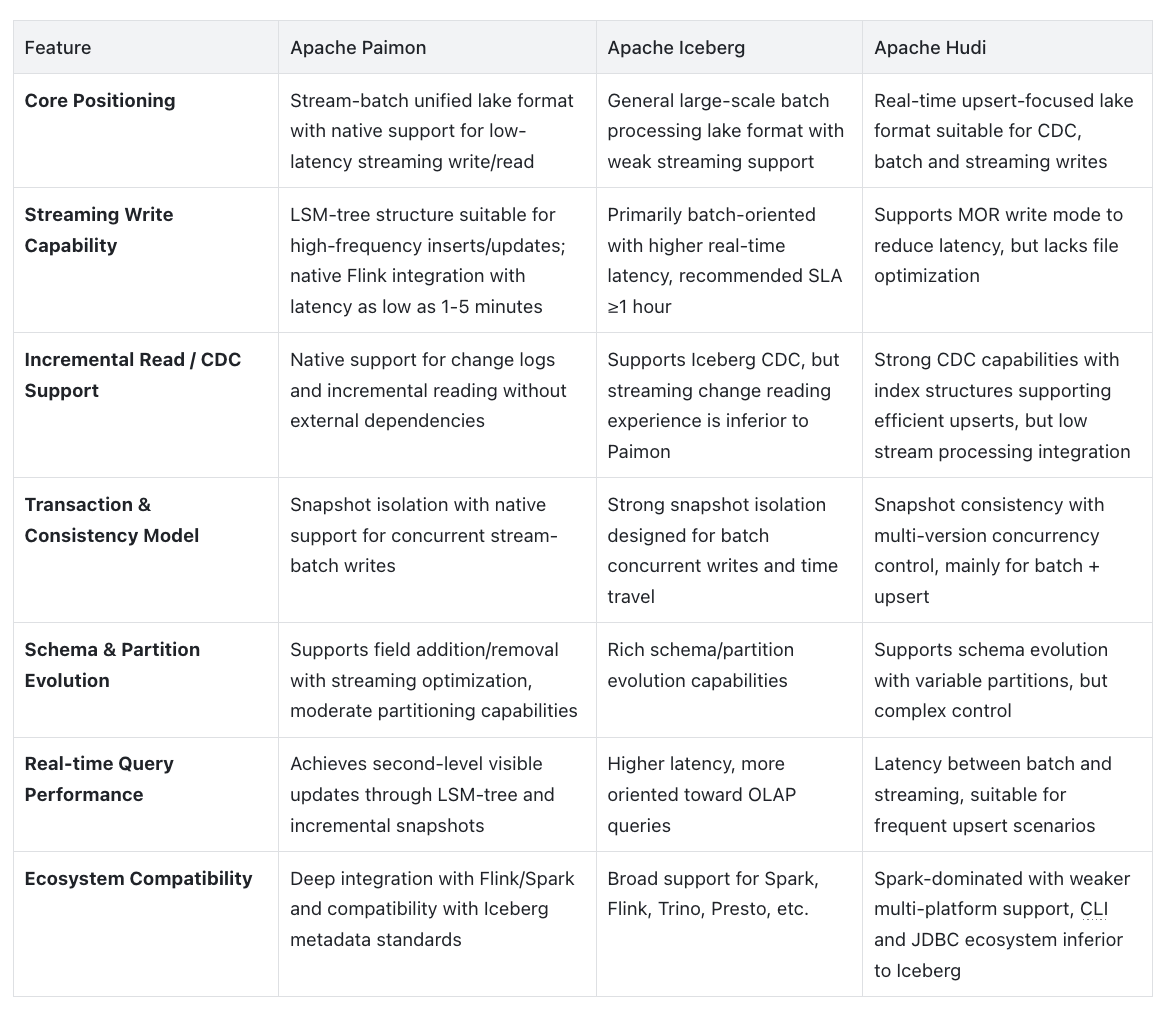
From the above comparison, Apache Paimon's performance in streaming real-time scenarios is particularly outstanding:
- Native support for high-frequency writes and incremental reads without external log systems;
- Close integration with Flink, achieving minute-level or even second-level data latency;
- LSM-tree structure suitable for real-time updates and queries;
- Maintains ACID and schema evolution capabilities simultaneously.
In contrast, Iceberg is better suited for large-scale batch processing tasks, while Hudi is more focused on upsert optimization.
4. Use Cases
1. Real-time CDC Data Ingestion + ODS Construction
Utilize Flink CDC to capture change streams from external databases (such as MySQL) and write real-time data to Paimon tables to build the ODS layer, maintaining low-latency mirrors of business sources (orders, users, logs, etc.).
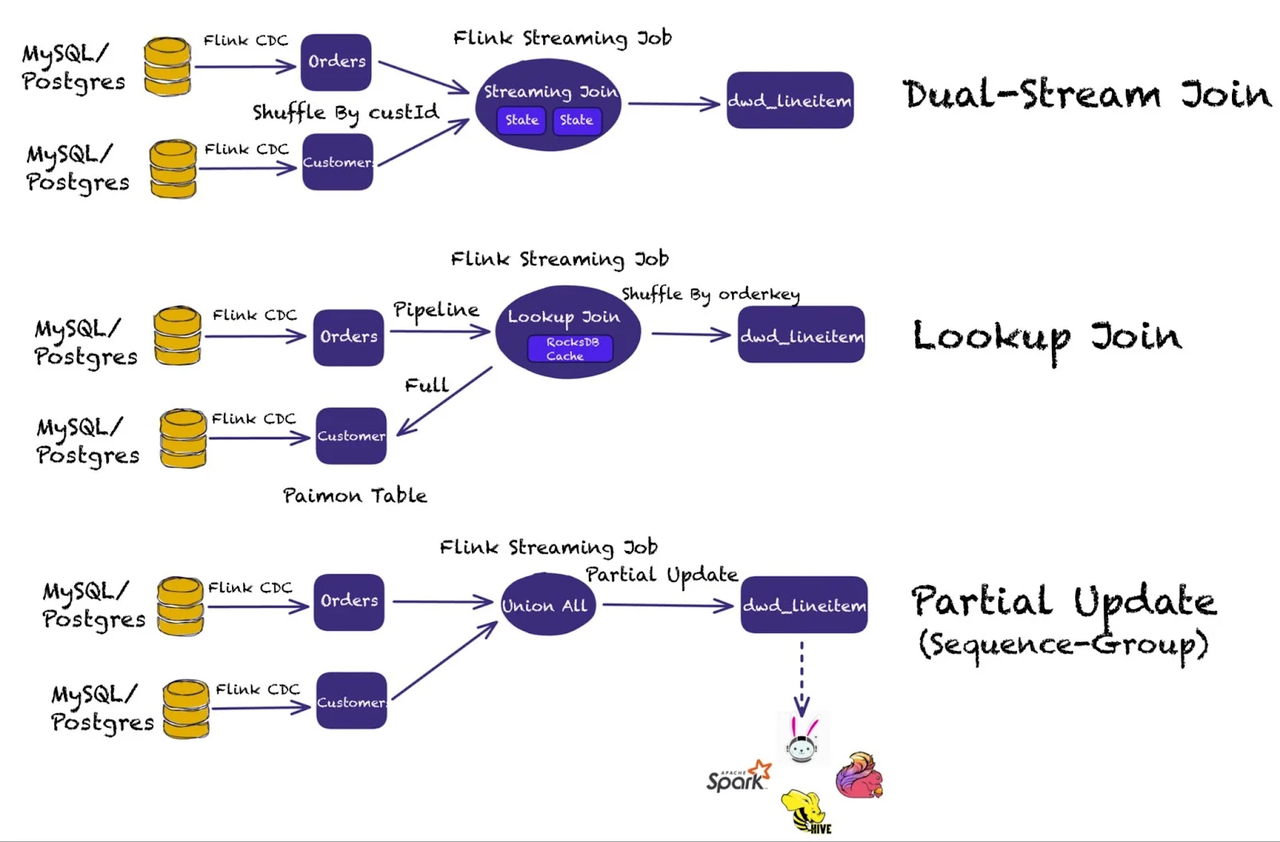
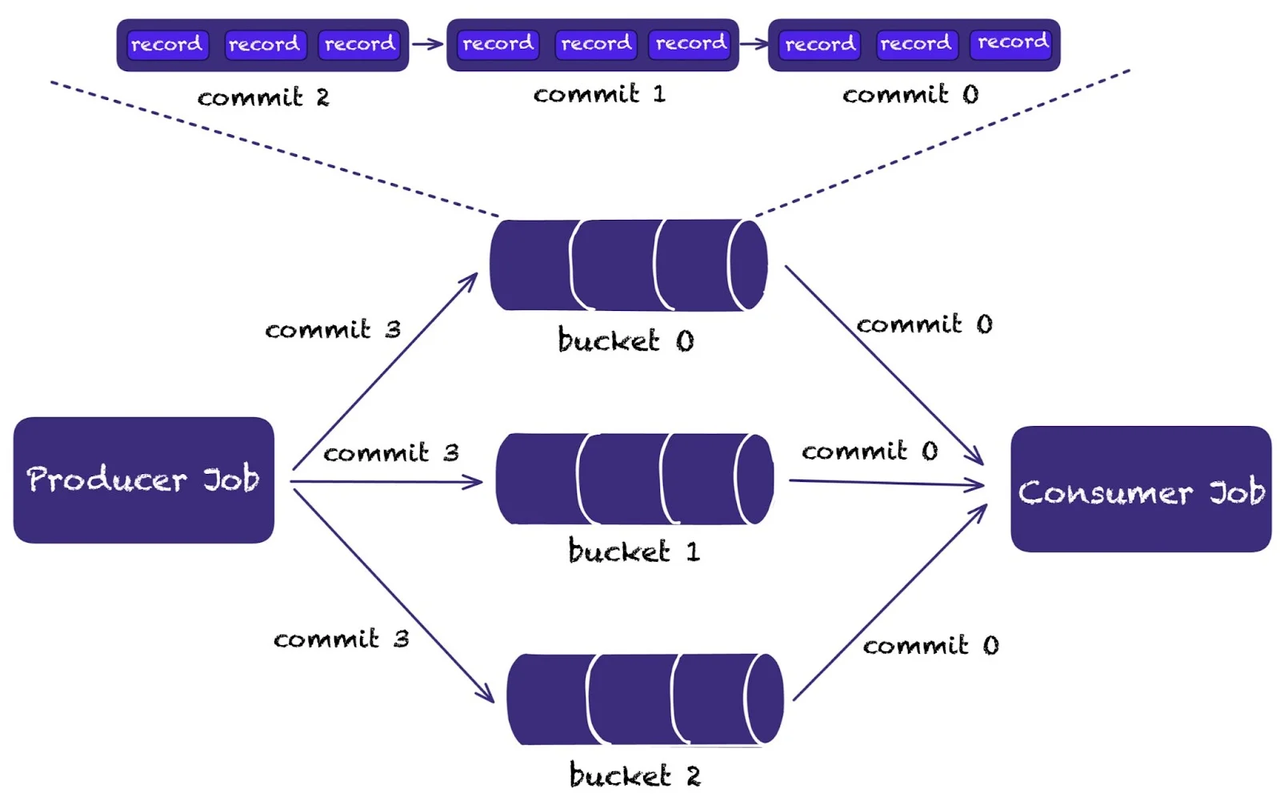
Core Advantages:
- Native CDC support: Automatically generates change logs (changelog producer) without requiring external message queue systems.
- Snapshot isolation and multi-stream joins ensure data consistency and correct concurrent write operations.
2. Layered Data ETL: ODS→DWD→DWS
Build layered ETL (including DWD, DWS) based on ODS tables in Paimon. Flink jobs subscribe to ODS changelog, perform transformations, and write to downstream, triggering new changelogs for further downstream processing.
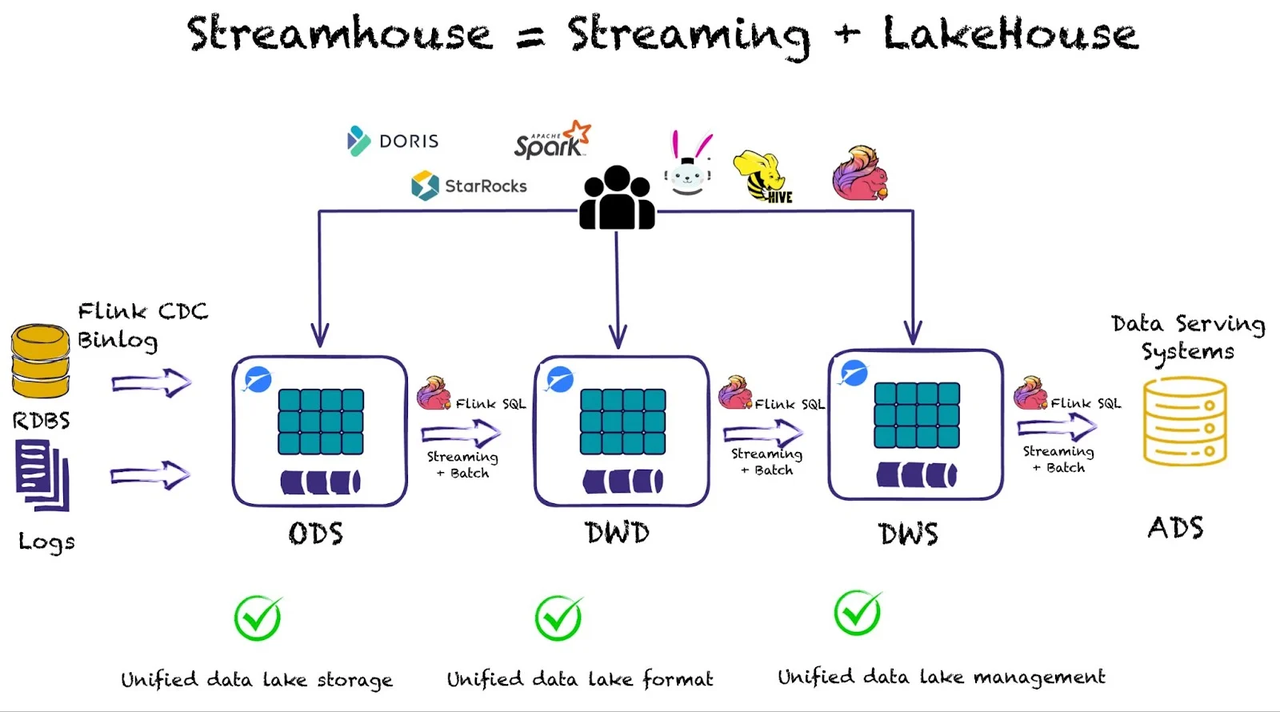
Core Advantages:
- Support for multi-engine streaming write and subscription: ODS→DWD→DWS stages flow automatically with each layer's latency controllable to minute-level.
- Eliminates intermediate mediums like Kafka, simplifying architecture and costs.
3. Real-time OLAP / BI Queries + Incremental Analysis
Use OLAP engines like Trino, Spark, and Doris on the unified streaming-batch data lake to query the latest Paimon table snapshots/incremental updates in real-time for business reports and real-time statistical insights.
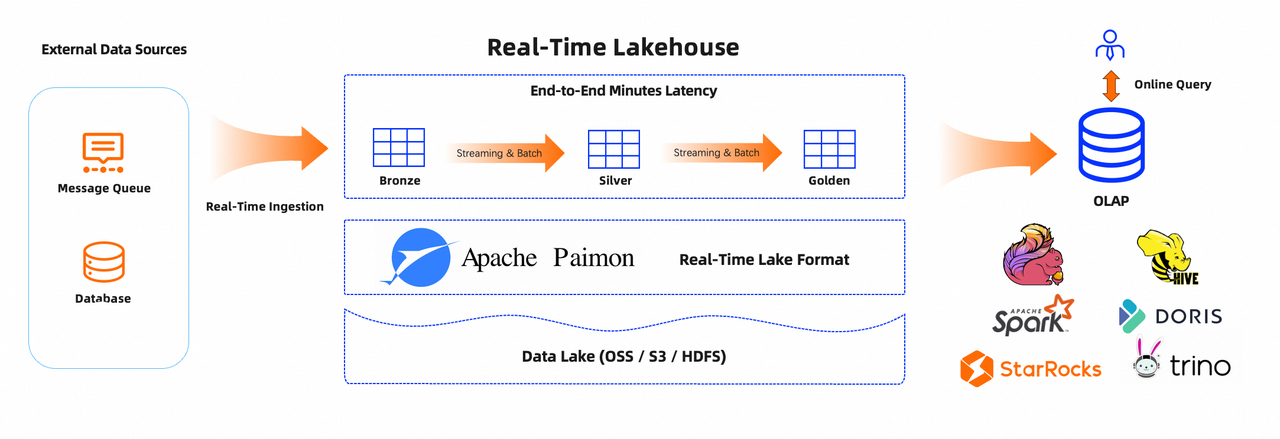
Core Advantages:
- Second-level data visibility, coexisting with real-time endpoints.
- Uses unified table format, transparent to BI engines and compatible with ACID and schema evolution.
- Provides low-latency BI capabilities without offline ETL requirements.
5. Practical Examples
Doris + Paimon
-- Create Catalog
CREATE CATALOG paimon_fs PROPERTIES (
"type" = "paimon",
"warehouse" = "s3://paimon-bucket/warehouse",
"s3.endpoint" = "http://minio:9000",
"s3.access_key" = "minioadmin",
"s3.secret_key" = "minioadmin"
);
-- Switch to Paimon catalog and query
SWITCH paimon_fs;
USE db1;
SELECT * FROM customer;
-- Query between snapshots [0, 5)
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5');
Flink + Paimon
-- Create catalog
CREATE CATALOG my_paimon WITH (
'type' = 'paimon',
'warehouse' = 'hdfs:///warehouse/paimon'
);
-- Create table
CREATE TABLE my_paimon.orders (
order_id STRING,
user_id STRING,
ts TIMESTAMP(3),
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'bucket' = '4'
);
-- Streaming write
INSERT INTO my_paimon.orders
SELECT order_id, user_id, ts FROM kafka_orders;
-- Incremental read
SELECT * FROM my_paimon.orders /*+ OPTIONS('scan.mode'='incremental') */;
6. Key Takeaways
- Apache Paimon is a high-performance table format system built for real-time data lakes.
- Supports ACID, schema evolution, incremental reading, and unified stream-batch processing.
- Seamlessly integrates with Flink, Spark, Trino, and more, suitable for real-time data warehousing, CDC scenarios.
- Simplifies real-time data architecture while improving consistency and maintainability.
- A future-oriented data lake standard that is rapidly evolving.
7. FAQ
Q1: Why choose Apache Paimon over Iceberg or Hudi?
A1: Compared to Iceberg and Hudi, Paimon natively supports streaming writes and incremental reads, uses LSM-Tree design to achieve low-latency data writes and visibility, making it particularly suitable for real-time CDC scenarios and unified stream-batch data lake architectures.
Q2: How is the performance for real-time statistics and OLAP queries?
A2: Paimon combines LSM-Tree with columnar storage formats to effectively organize update and query paths, achieving second-level update visibility while being compatible with OLAP engines like Spark, Trino, and Doris. It's suitable for building real-time BI or real-time monitoring dashboard solutions.
8. Additional Resources and CTA
- Apache Paimon Official Website
- Paimon Flink Integration Documentation
- GitHub Source Code
- Want to learn more about streaming lakehouse practices? Read our series of articles on Real-time Data Warehouse Construction Guide.
- Follow our blog for the latest lakehouse technology updates!
