



What is Apache Hudi
Apache Hudi (Hadoop Upserts Deletes Incrementals) is an open-source data lake platform originally developed by Uber and became an Apache top-level project in 2019. By providing transactional capabilities, incremental processing, and consistency control for data lakes, it transforms traditional data lakes into modern lakehouses. As users increasingly focus on real-time capabilities, update functionality, and cost efficiency in massive data scenarios, Hudi emerges as the solution to address these pain points.
1. Why Do We Need Apache Hudi?
Current Challenges:
- Traditional data lakes (like Parquet + S3/HDFS) lack update and delete capabilities
- Batch processing has high latency and data freshness issues
- Poor data consistency and complex maintenance
- Query performance severely impacted by fragmentation and small files
Improvements Brought by Hudi:
- Supports ACID transactions with insert/upsert/delete operations, ensuring consistency
- Incremental processing mode that only handles changed data, significantly reducing data latency
- Supports multiple query types and table designs (Copy-on-write and Merge-on-read) for different scenarios
- Provides efficient indexing mechanisms to reduce scanning overhead and accelerate query response
2. Apache Hudi Architecture and Core Components
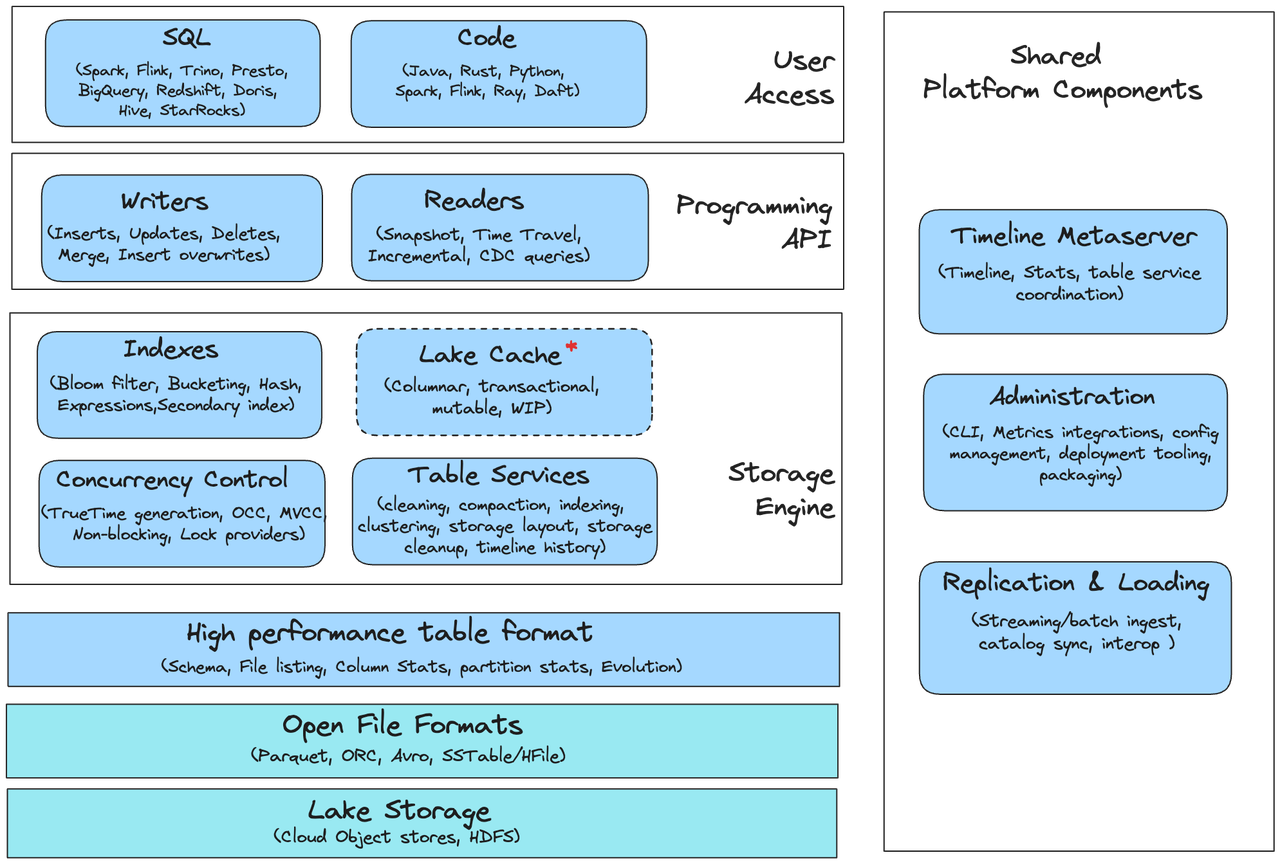
The diagram above illustrates Hudi's overall architecture, including the storage layer, indexing components, clients, table services, and query engine integration.
Key Components:
-
Write Client / Delta Streamer
- Definition: Used for ingesting batch or streaming data writes to Hudi tables
- Functionality: Supports insert, upsert, and delete operations, compatible with Spark batch processing or Kafka CDC streaming imports
- Relationship: Calls index queries to locate target file groups and writes changes to base files or log files
-
Index Layer
- Definition: Maps record-key + partition → file-group
- Functionality: Accelerates target location for updates, improves upsert performance, supports Bloom index and HBase index
- Relationship: Write Client queries the index before writing to locate existing file groups
-
Storage Layer & Storage Format
- Definition: Table storage structure based on Parquet/Avro, divided into Copy-on-Write or Merge-on-Read types
- Functionality: CoW synchronously writes Parquet files, MoR writes logs then compacts asynchronously. Supports MVCC and multi-version reads
- Relationship: Collaborates with table services through compaction/cleaning to manage file structure and storage fragmentation
-
Timeline Server / Table Services
- Definition: Manages the
.hoodietimeline directory, recording all commit actions - Functionality: Provides consistent views, supports time travel queries, and coordinates with cleaning/compaction services for automatic optimization
- Relationship: Serves as the metadata control center for the entire ecosystem, with both queries and client writes depending on it
- Definition: Manages the
-
Query Access Layer (Query Engine Interface)
- Definition: Supports query engines like Spark, Hive, Presto, Impala to read Hudi tables
- Functionality: Supports read-optimized, realtime, and incremental query modes, automatically merges base+log files
- Relationship: Works with the storage layer to parse timelines during reads and return correct data for different scenarios
3. Key Features and Capabilities
ACID Transactionality
Supports atomic insert/upsert/delete operations, ensuring data consistency with rollback mechanisms.
Incremental Processing & CDC Support
Processes only new or changed data, facilitating low-latency pipeline construction and machine learning training data lakes.
Multi-Table Type Design
- Copy-on-Write (CoW): Writes immediately rewrite Parquet files, offering strong query performance
- Merge-on-Read (MoR): Writes logs first, dynamically merges during queries, suitable for latency-sensitive scenarios
Advanced Indexing Mechanisms
Supports bloom indexes, expression indexes, and secondary indexes, dramatically reducing query scanning costs.
Time Travel Queries
Through timeline history, enables reading historical snapshot versions or incremental data, facilitating auditing and debugging.
Concurrency Control and Scalability
Hudi 1.0 introduces Non-Blocking Concurrency Control (NBCC), allowing multiple writers to concurrently write to the same table.
4. Use Cases
- Real-time Analytics: E-commerce clickstreams and transaction logs enable minute-level real-time analysis after data lake ingestion
- ML Feature Engineering: Continuously updated user behavior data for feature construction and model training
- Unified Customer Profiles: Cross-system data integration with full synchronization and updates
- Log Management & Auditing: Financial/security scenarios supporting deletion, change tracking, and time travel
5. Practical Examples
Spark Integration Example
Using Spark to write Kafka CDC data to Hudi tables and subsequently query snapshots:
val hudiOptions = Map(
"hoodie.table.name" -> "user_table",
"hoodie.datasource.write.recordkey.field" -> "user_id",
"hoodie.datasource.write.partitionpath.field" -> "dt",
"hoodie.datasource.write.precombine.field" -> "timestamp",
"hoodie.datasource.write.operation" -> "upsert",
"hoodie.datasource.write.table.type" -> "COPY_ON_WRITE"
)
spark.read.format("kafka")...load()
.selectExpr("CAST(value AS STRING)","timestamp")
.select(from_json(col("value"), schema) as "data", col("timestamp"))
.select("data.*","timestamp")
.write.format("hudi")
.options(hudiOptions)
.mode("append")
.save("s3://your-bucket/user_table/")
// Query latest snapshot
spark.read.format("hudi")
.load("s3://your-bucket/user_table/")
.createOrReplaceTempView("user_hudi")
spark.sql("SELECT count(*) FROM user_hudi").show()
Input: Kafka CDC JSON stream
Output: Total record count from latest Hudi table (supports upsert and schema evolution)
Doris Integration Example
Apache Doris leverages its Multi-Catalog functionality to directly access Hudi tables and perform federated queries without manual table creation.
-- Create Hudi Catalog connecting to Hive Metastore (for Hudi metadata management)
CREATE CATALOG hudi_catalog PROPERTIES (
'type' = 'hms',
'hive.metastore.uris' = 'thrift://your-hive-metastore:9083'
);
After setup, Doris automatically retrieves Hudi database and table information, accessible through hudi_catalog.
-- Switch catalog and query Hudi tables
SWITCH hudi_catalog;
USE your_hudi_db;
SELECT * FROM your_hudi_table LIMIT 10;
-- Or use fully qualified names for queries
SELECT * FROM hudi_catalog.your_hudi_db.your_hudi_table LIMIT 10;
Doris supports reading latest snapshots, time travel, and incremental reads, compatible with both Copy-on-Write and Merge-on-Read table types.
-- Query specific snapshot timeline
SELECT * FROM hudi_meta(
'table' = 'hudi_catalog.your_hudi_db.your_hudi_table',
'query_type' = 'timeline'
);
This functionality supports viewing Hudi table commit history for auditing or debugging purposes.
To import Hudi table data into Doris internal tables for deep analysis or materialized view reconstruction:
CREATE TABLE doris_hudi_01
PROPERTIES('replication_num' = '1')
AS SELECT * FROM hudi_catalog.your_hudi_db.your_hudi_table;
This imports Hudi table data as internal tables in Doris, supporting more complex analysis and modeling workflows (ZeroETL query approach).
6. Key Takeaways
- Apache Hudi brings database-level transactional capabilities, incremental processing, and update functionality to data lakes
- Supports CoW and MoR table types, adapting to different read/write scenarios
- Provides advanced indexing (Bloom/Expression/Secondary indexes) and time travel query capabilities
- Hudi 1.0 introduces NBCC concurrency capabilities and expression indexes, significantly improving performance and scalability
- Compatible with multiple compute engines (Spark, Hive, ClickHouse), enabling unified, operational data lakehouse architectures
7. FAQ
Q1: How does Hudi differ from Iceberg and Delta Lake?
A: Hudi focuses more on incremental processing, indexing support, and update efficiency; while Iceberg has more mature integration with query engines like Trino/Presto, Hudi offers higher update efficiency in certain scenarios.
