



Xiaomi is a leading global player in consumer electronics. Best known for its smartphones and smart home devices, Xiaomi is among the world's top three smartphone makers and continues to expand into new offerings like electric vehicles. With a global operation, Xiaomi requires an analytical data architecture that can support its growth and increasing demand. Their solution: Apache Doris + Apache Paimon.
At first, Xiaomi built its analytical data platform in a lakehouse architecture with Apache Doris as a query engine, and Apache Paimon as an open table format for its data lake. This combination delivers fast, real-time queries at scale, along with affordable and elastic storage.
Then, Xiaomi further utilized Apache Doris as a real-time data warehouse, achieving even faster and better query and computing performance than just using Doris as a query engine. Unlike query engines like Trino or Presto, Apache Doris offers its own storage layer with internal tables. This allows users to bring parts of their data into Doris, further utilizing its features, such as materialized views, advanced JOIN capabilities for faster queries, and computation. Doris also supports write-backs, allowing users to write query results back to external tables like Paimon and Iceberg, further bridging data lakes with data warehouses. This "better together" approach gives users the flexibility of data lakes (via Paimon) with higher performance and richer capabilities (via Doris), without adding complexity to the system (thanks to Doris' versatile query engine and data warehouse capabilities).
In this article, we will discuss in detail how Xiaomi built a unified lakehouse platform with Apache Doris and Apache Paimon, and share our learnings and optimizations developed along the way.
Better Together: Bridging Data Warehouse and Data Lake with Doris and Paimon
In most companies' data systems, a common dilemma is how to keep storage costs low while still getting fast, real-time analytics.
On one hand, businesses need low-cost, scalable storage to handle massive volumes of structured, semi-structured, and unstructured data (the strength of data lakes). On the other hand, businesses require real-time, low-latency analytics to drive decision-making (the strength of real-time data warehouses). Yet relying on either a data lake or a real-time data warehouse alone can't resolve this conflict.
Enter the lakehouse architecture, combining the best of data lake and data warehouse. Data lake storage formats like Apache Paimon provide open formats, elastic scaling, and affordable storage, but fall short on low-latency queries. Real-time data warehouses like Apache Doris excel at fast queries and analytics, but lack the flexibility of a data lake.
By integrating a data lake like Paimon with a data warehouse like Doris, users can have the best of both worlds: fast, real-time query performance at the low, manageable cost of data lake storage.
In Xiaomi's architecture, Doris and Paimon are used together to optimize both storage and query performance:
- Cold and historical data stored in Apache Paimon for cost efficiency and multi-engine compatibility.
- Hot and frequently queried data or core metrics requiring heavy aggregation are converted into Apache Doris' internal storage via materialized views and local caching, achieving optimal query performance.
What's Apache Paimon and Apache Doris?
Apache Paimon is a flexible open table format. It offers both batch and stream operations, making it suitable for processing real-time data directly on the data lake.
Apache Doris began supporting the Paimon Catalog since version 2.1, allowing it to access Paimon data directly and offer faster queries. In benchmark testing with the Paimon TPC-DS 1TB dataset, Apache Doris delivered 5X faster query performance than Trino.
Apache Doris has continued to improve its support for Paimon in versions 2.1, 3.0, and 3.1. These improvements include (but are not limited to):
- Optimize query efficiency by partitioning, bucketing, and applying predicate pushdown on Paimon data using metadata.
- Supports Paimon Deletion Vector reading, leveraging a vectorized C++ engine to accelerate data updates in Paimon.
- Supports local file caching for Paimon data, maximizing the use of high-speed local disks to speed up queries on hot data.
- Supports Paimon time travel, incremental data reads, and Branch/Tag data read for easier multi-version data management in Paimon.
- Materialized views are supported based on Paimon data, including partition-level incremental materialized view construction and snapshot-level incremental builds (more on that later in this article). It also offers strong consistency with transparent materialized view rewriting, deeply integrating data lake and data warehouse capabilities.
- Supports Paimon Rest Catalog (DLF), facilitating seamless integration into the Paimon ecosystem and unified metadata management.
Case Study: Apache Doris + Apache Paimon at Xiaomi
What Xiaomi Needs in an Analytical Data System
As a global giant with various product lines, including smartphones, IoT devices, and EVs, Xiaomi needs its online analytical processing system (OLAP) to meet several critical needs:
- Support multi-dimensional analytics in high-concurrency, low-latency aggregation queries (e.g., user behavior, device status, operations monitoring).
- Handle multi-source data ingestion across batch and streaming frameworks like Flink, Spark, and Flink CDC, handling both offline and real-time data processing scenarios.
- Provide unified data access across engines and formats (Doris, Paimon, Iceberg). (e.g., Doris, Paimon, Iceberg).
- Reducing system complexity by consolidating tech stacks, unifying data modeling and governance, and improving operational efficiency of the data platform.
Challenges in the Previous Architecture
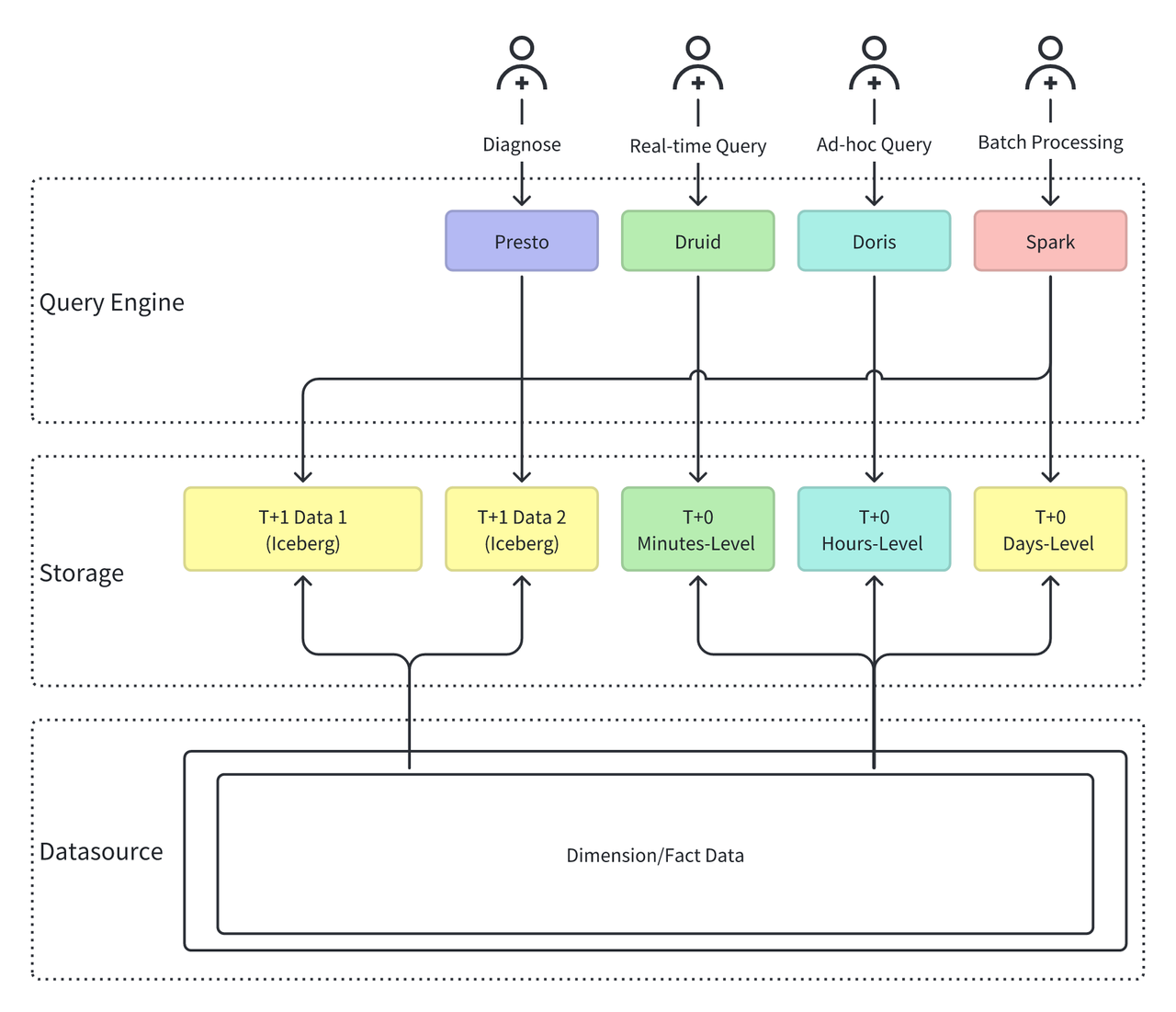
- Fragmented storage and redundant data: Different business operations require data from various time frames (minute, hourly, and daily), leading to Xiaomi storing data across multiple systems (Iceberg, Paimon, Druid, Doris), which causes redundancy and inconsistency.
- No unified interface, multiple query engines: Xiaomi used multiple engines (Presto, Druid, Doris, Spark) for data queries, each with independent data modeling, maintenance, and access control, resulting in high governance costs and inconsistent usage.
These issues increase the platform's burden and limit the stability and scalability of the overall OLAP architecture in large-scale, real-time applications
Solution: Apache Doris + Apache Paimon
Xiaomi adopted Doris + Paimon architecture as the future of its OLAP platform:
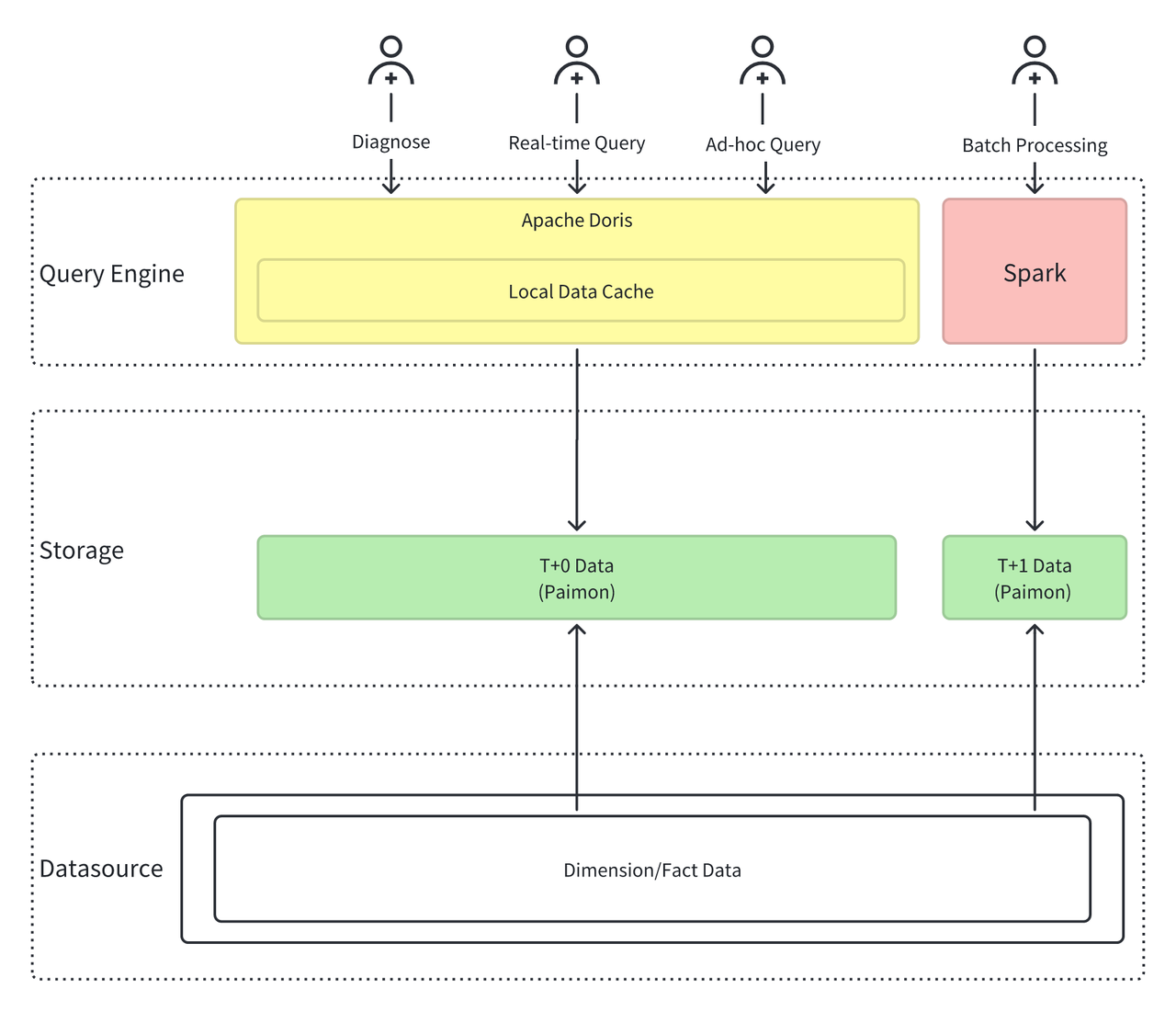
To address these challenges, Xiaomi built a simplified architecture based on Apache Doris and Apache Paimon, leading the way for the next-generation OLAP platform.
- Unified Compute Engine: Apache Doris + Spark Doris handles real-time and interactive analytics, supporting high-concurrency queries. Spark manages offline batch processing.
- Unified Data Lake Storage: Apache Paimon Paimon serves as the unified data storage format, handling both batch and streaming data storage, providing unified data management.
This new architecture drastically simplified the system:
- Compute engines reduced from Presto, Druid, and Doris to Doris and Spark.
- Storage formats consolidated from Iceberg, Paimon, Doris, and Druid to Doris and Paimon.
Division of Roles in the architecture:
Apache Paimon focuses on storage and acts as a low-cost, unified storage foundation for diverse data. It offers:
- Open table format, compatible with Spark, Flink, Trino, and more
- Petabyte-scale storage on S3/HDFS with elastic scaling
- Native support for transactions and schema evolution
- Acts as a low-cost, unified storage foundation for diverse data
Apache Doris focuses on computation and serves as the high-performance compute engine for real-time analytics. It offers:
- Distributed parallel query engine
- Vectorized execution framework
- Operator-level optimizations for complex aggregations
- Millisecond to second-level query latency
More Than a Query Engine, Apache Doris as a Real-Time Data Warehouse in the Lakehouse
With the above architecture, Xiaomi solved the problem of large-scale data storage, but still faced three major bottlenecks when running real business workloads:
- Slow Aggregation: Doris's capability of reading Paimon Merge-on-Read tables was limited by the single-threaded Paimon SDK (Java), which is slow for multi-file sorting and merging, and can't meet "second-level" query demands under high concurrency.
- Costly materialized view updates: Partition-level incremental updates can meet some use cases, but non-partitioned tables or large single-partition tables still generate high costs.
- Unstable HDFS read latency: HDFS's default 60-second timeout and network fluctuations cause significant query latency variability, holding up fast decision-making.
To address these real-world issues, Xiaomi went further than using Doris as just a query engine on top of data lake storage format Paimon. It leveraged the full capability of Apache Doris, utilizing Doris' own storage layer to achieve a more optimal query and computation speed that meets its demanding business needs. This approach allowed Xiaomi to fully leverage Doris features like advanced JOIN capability, materialized views, and write-backs to data lake formats, maximizing query speed and performance.
See how Xiaomi addressed each of these challenges utilizing more capabilities from Apache Doris:
1. Using Apache Doris compute engine to speed up Paimon aggregation
Apache Doris comes with powerful built-in aggregation capabilities and supports the Aggregate Key table model, which closely resembles Paimon's aggregation tables. This makes Doris a strong complement to Paimon in such scenarios.
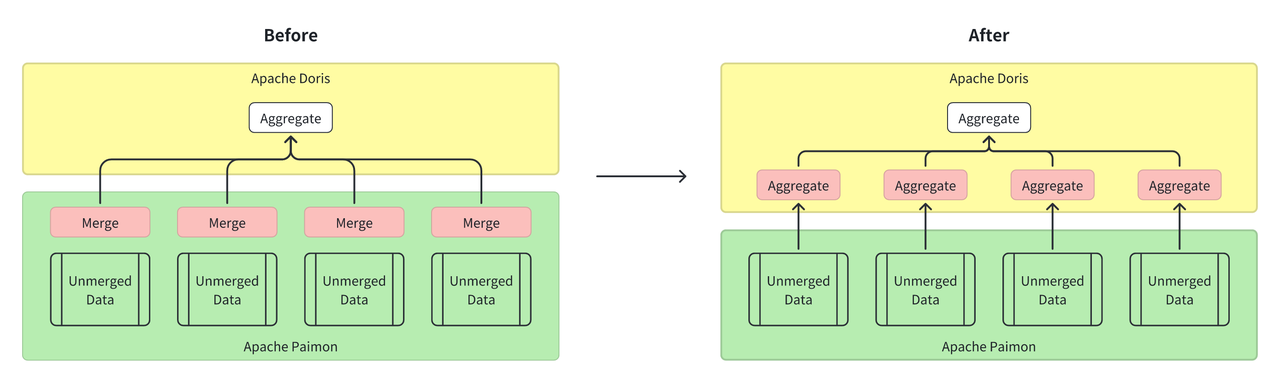
To address the previous performance bottleneck issues when Doris queried Paimon aggregation tables, Xiaomi adopted a new approach: moving file merge and sorting logic "up" into Doris' query engine. By leveraging Doris' distributed parallel processing and vectorized execution, the aggregation speed is no longer limited by the single-threaded processing mode of the Paimon SDK. Specifically:
- Instead of using JNI calls to the Paimon Java SDK, Doris now reads Paimon data files directly with its native Parquet Reader.
- Distributed aggregation is performed through Doris' Hash operator, eliminating the need for sorting and taking full advantage of the C++ engine performance.
Result: Aggregation Query time dropped from 40s to 8s, making it 5x faster.
2. Snapshot-Level Incremental Materialized Views for Efficient Updates
Apache Doris supports asynchronous materialized views on data lake table formats such as Paimon and Iceberg. It also enables partition-level incremental refresh and transparent query rewrite. Materialized views (as a direct bridge between databases and data lakes) play a key role in query acceleration.
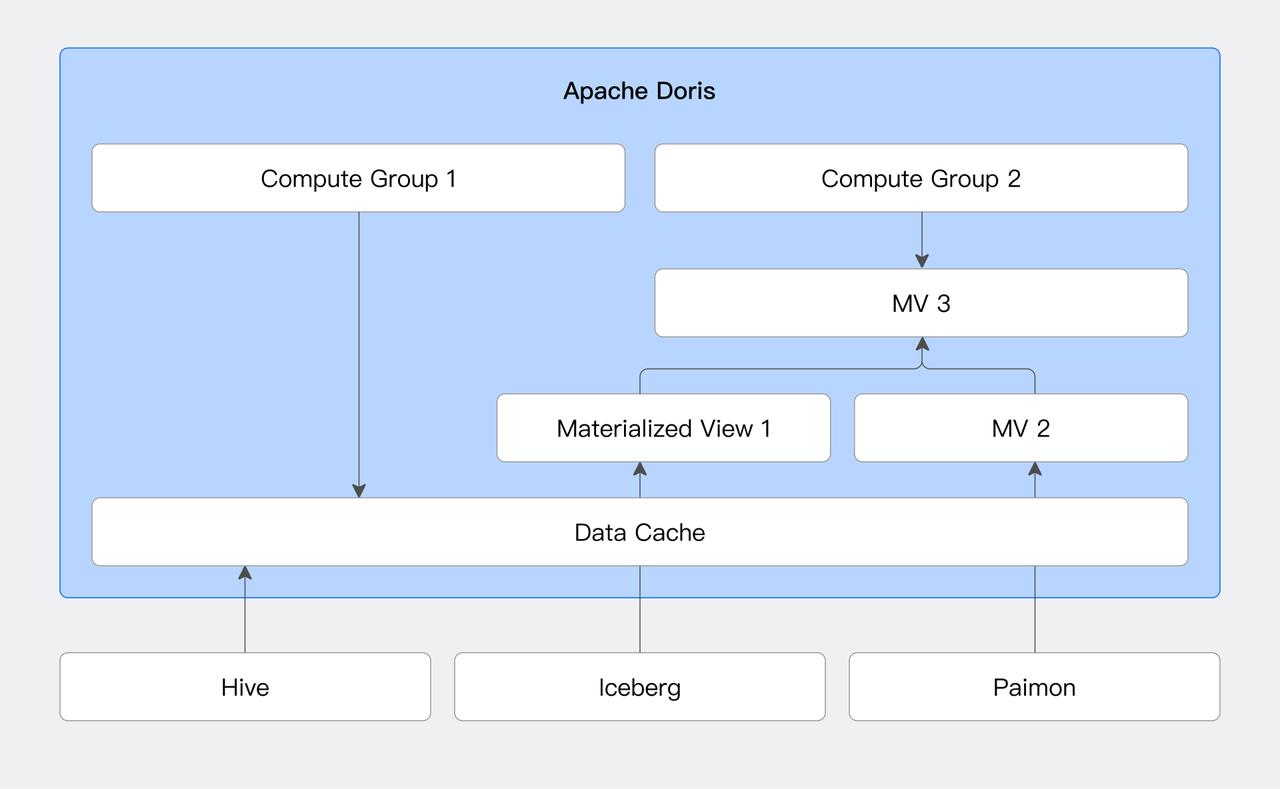
To further improve freshness and reduce the overhead of materialized view updates, Xiaomi developed snapshot-level incremental refresh for materialized views and contributed this feature back to the Apache Doris community.
First, Xiaomi implemented snapshot-level incremental reads for Paimon tables, allowing the system to read only the data within a specified snapshot range.
SELECT * FROM paimon_table@incr('startSnapshotId'='0', 'endSnapshotId'='5')
Building on this, Xiaomi developed snapshot-level incremental materialized views:
- Create an aggregation table in Paimon
CREATE TABLE paimon_aggregate_table (
dt bigint,
k1 bigint
k2 string,
v1 int,
v2 double
)
USING paimon
PARTITIONED BY (dt)
TBLPROPERTIES (
'bucket' = '2',
'bucket-key' = 'k1,k2',
'fields.v1.aggregate-function' = 'sum',
'fields.v2.aggregate-function' = 'max',
'merge-engine' = 'aggregation',
'primary-key' = 'dt,k1,k2'
);
- Create the corresponding materialized view in Doris
CREATE MATERIALIZED VIEW paimon_aggregate_table_mv
BUILD DEFERRED
REFRESH INCREMENTAL
PARTITION BY (dt)
DISTRIBUTED BY RANDOM BUCKETS 2
AS
SELECT dt, k1, SUM(a1) AS a1
FROM paimon_aggregate_table
GROUP BY dt, k1;
Doris' asynchronous materialized view framework then runs scheduled jobs in the background:
INSERT INTO paimon_aggregate_table_mv
SELECT dt, k1, SUM(a1) AS a1
paimon_aggregate_table@INCR('startSnapshotId'='1', 'endSnapshotId'='2')
GROUP BY dt, k1;
Combining the snapshot reads and Doris' aggregation capabilities, it incrementally updates the materialized view in near real time, avoiding full recomputation.
Results: This approach significantly reduces update costs and improves data freshness. Thanks to Doris' optimized transparent query rewrite capability, users can enjoy the acceleration of materialized views automatically, without needing to modify their SQL.
3. HDFS Long-Tail Latency Optimization and Caching Mechanism
To address the issue of unstable HDFS read latency, Xiaomi adopted two key methods:
-
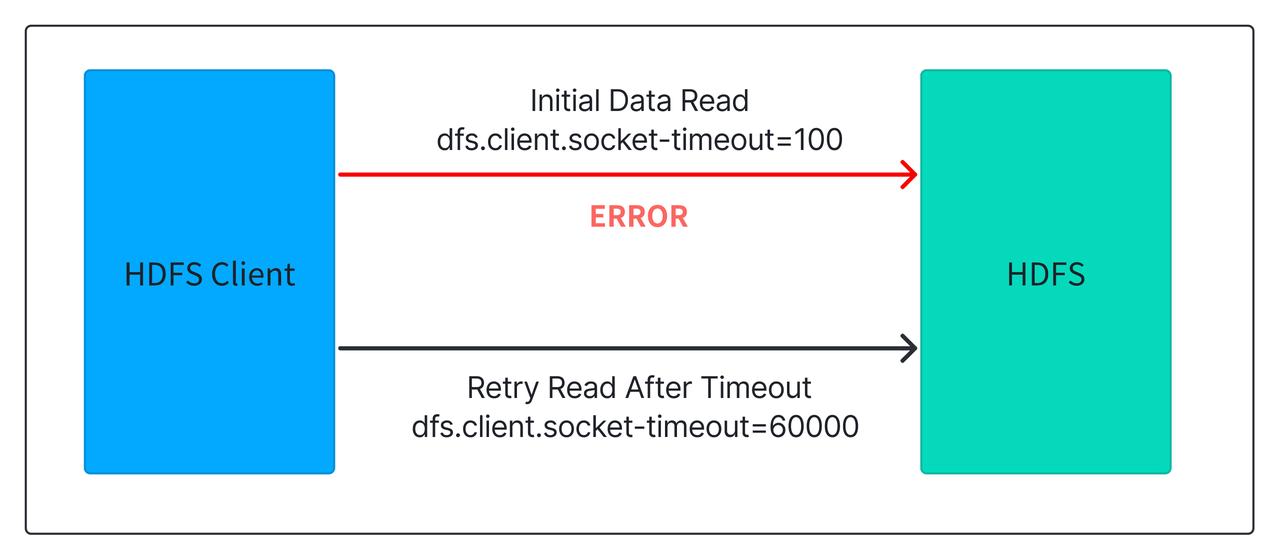
Fast Timeout and Retry for HDFS Reads
HDFS relies on a multi-replica mechanism when reading data. If one replica takes too long to respond, it switches to another replica. By default, the timeout threshold is controlled by the parameter
dfs.client.socket-utilized Apache Doris'sout, default is set at 60 seconds. This long initial timeout often causes significant query delays under HDFS jitter or heavy load. Xiaomi reduced this threshold to 100 milliseconds, enabling much faster retries across replicas. As a result, long-tail latencies were dramatically reduced, with P99 performance doubling and overall performance improving by 10%.
-
Data Caching in Apache Doris
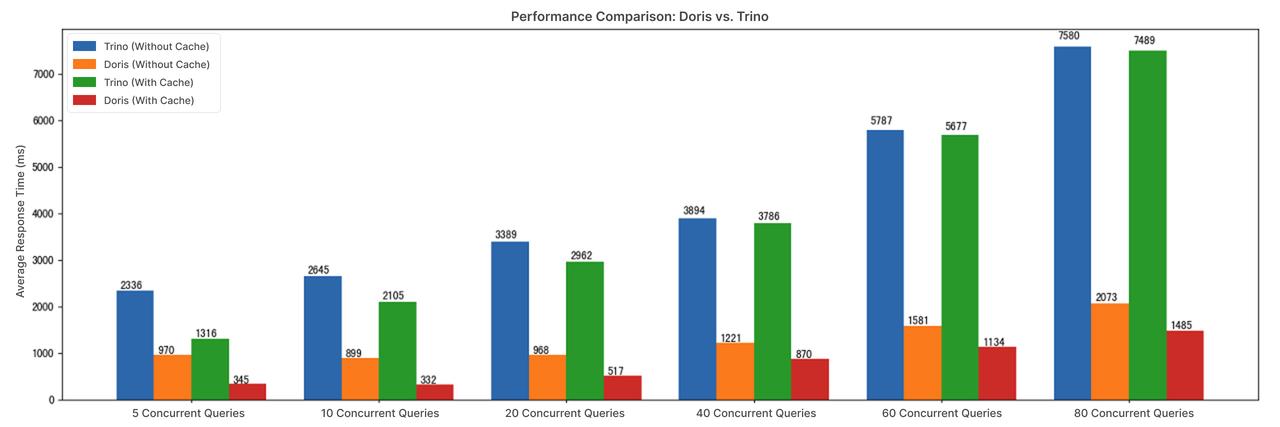
In high-concurrency scenarios, simply lowering the HDFS retry timeout threshold is not enough to resolve latency issues. To address this, Xiaomi utilized Apache Doris' data caching capability, storing hot data on local high-speed disks. This effectively eliminated query delays under heavy concurrency. With caching enabled, query latency was reduced to 25%-75% of the original, and concurrency handling scaled from 5 to 80 concurrent queries. Combined with Doris's data pruning and high-performance operators, the overall query concurrency capability proved to be 5× that of Presto.
Results and Future Outlook
Xiaomi's deep integration of Apache Doris + Apache Paimon brought significant business benefits to the company:
- Average query latency cut down from 60s to 10s — a 6× improvement.
- In high-concurrency scenarios (5 to 80 concurrent queries), query latency was reduced to 25%-75% of the original
- 5× higher concurrency throughput compared to Presto, cutting compute costs.
All of these improvements have been contributed back to the Apache Doris community.
Looking ahead, Xiaomi plans to further expand Apache Doris in lakehouse analytics, including:
- Replacing Presto clusters with Doris to reduce costs and improve efficiency.
- Enhancing incremental materialized views for lake formats like Paimon and Iceberg.
- Containerizing Doris lakehouse architecture for more flexible deployment.
- Leveraging the Compute Group capability in Apache Doris to isolate resources across workloads, improve utilization, and lower maintenance costs.
Learn more about the Apache Doris lakehouse solution in our documentation. Join the Apache Doris community on Slack, where you can connect with Doris experts and other users. If you're looking for a fully-managed, cloud-native version of Apache Doris, contact the VeloDB team.


